

AIガードレールとは何ですか?
AIガードレール(LLMガードレールやGenAIガードレールとも呼ばれる)は、 予防的安全管理 AIシステムの振る舞いを定められたポリシーの範囲内で制約するものです。 モデルが何を見たり、何をしたり、何を返してくれたりできるかを形作り、モデル実行時の有害、偏り、またはポリシー違反の出力のリスクを減らします。
ガードレールは以下の通りです 予防的管理 推論の前および推論中に適用されます。 彼らは共に働いています 探偵管制 例えば、記録、監視、警告など、違反が発生した後に特定できる機能など、 ガバナンス管理 例えば、ポリシー、ドキュメント、監査要件などです。
実際には、3層のガードレールが一緒に使用されます。
入力ガードレール: プロンプトがモデルに届く前にフィルタリング、検証、再構成を行います。
処理のガードレール: モデルがアクセスできるコンテキスト、データ、ツールを制御し、推論中にビジネスルールを強制します。
出力ガードレール: モデルの応答を評価し、ブロック、修正、または拒否してからユーザーに返します。
これらのガードレールは従来のアプリケーションセキュリティとは異なります。 従来のコントロールは決定的なコードやフォームフィールドやJSONのような構造化入力を保護します。 AIガードレールは、同じリクエストが毎回異なる出力を生み出し、文脈の埋め込みやプロンプト注入によってモデルの挙動に影響を与える非決定性システムや自然言語を管理しなければなりません。
特に規制されたデータや顧客対応のワークフローを扱う企業にとって、ガードレールはその手段です プロトタイプを量産システムに変える. これらは安全、セキュリティ、コンプライアンスの要件を厳格に強化しつつ、強力な基盤モデルの上にチームが構築できるようにします。
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

なぜAIガードレールがクラウドセキュリティに重要なのか
クラウドにAIを展開すると、2つの難しい特性を組み合わせることになります。 信頼できない自然言語入力 そして 機密データやシステムへのアクセス. モデルは任意のテキストに影響を受けることがありますが、共有インフラ上で、公開または内部APIの背後で動作し、しばしば実際のビジネスデータにアクセスしています。 これは従来のセキュリティ管理の多くの前提を打ち破ります。
クラウドAIシステムは個人情報、財務記録、機密文書などの機密データを扱います。 ネットワークルールやファイアウォールのような従来のコントロール プロンプト、コンテキストウィンドウ、モデルの挙動を評価できませんつまり、プロンプト注入、回収操作、予期せぬツール使用などの攻撃を防ぐことはできません。 主要なクラウドプロバイダーは現在、AIサービスに安全管理(例:Amazon BedrockのGuardrails、Azure OpenAIのコンテンツフィルター、Google Vertex AIの安全フィルター)を組み込んでいますが、これらは統合する必要があります 組織固有のポリシー、IAM制御、ランタイム監視 効果的であるために。
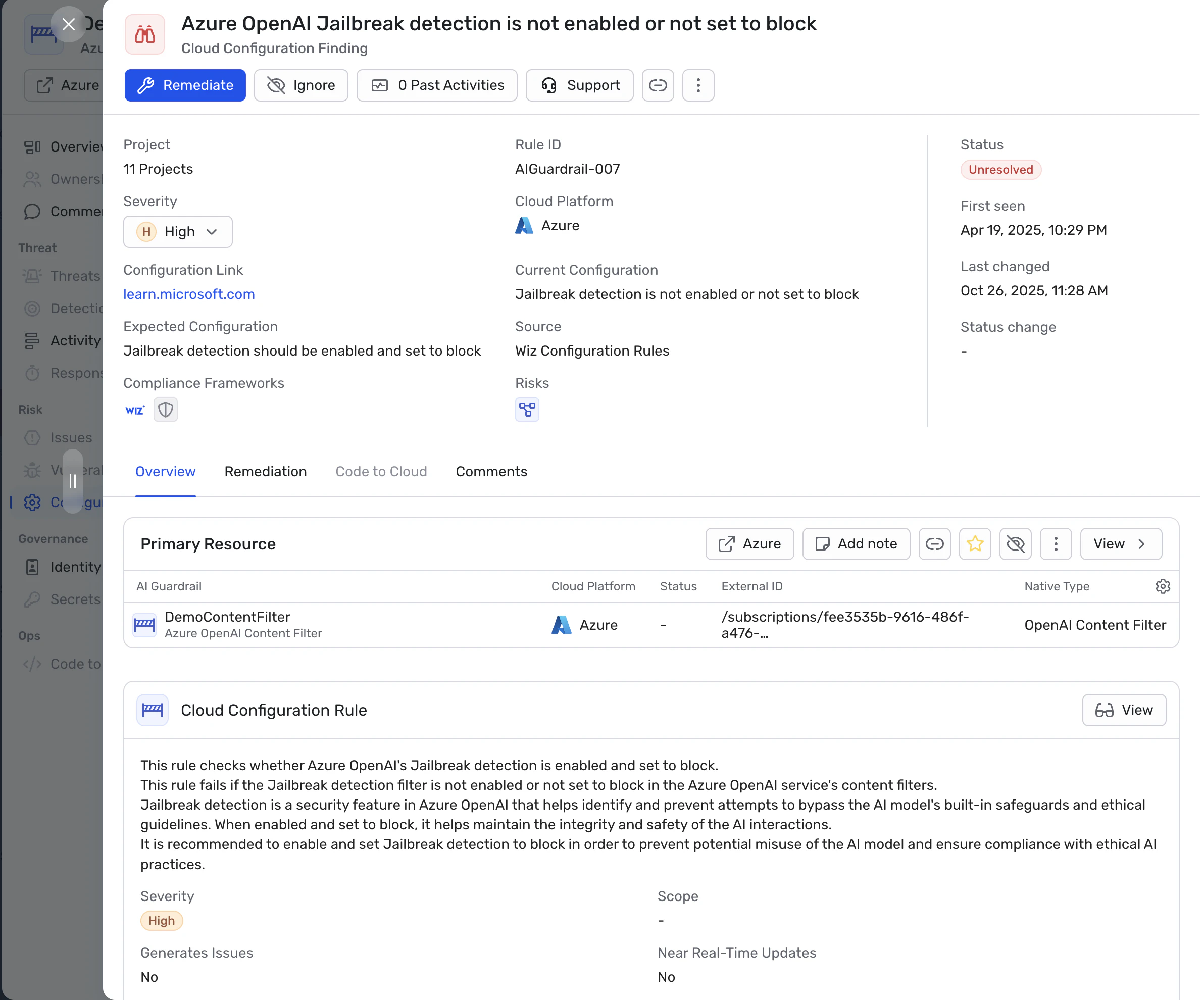
クラウド環境では、 AIの攻撃面 現在は以下のものを含みます:
モデル: ホストされたLLM、ファインチューニングモデル、カスタム埋め込みなどが含まれます。
トレーニングおよび推論データ: 機密コンテンツを含む可能性のあるデータレイク、ベクターストア、ログなどです。
推論エンドポイント: チャット、検索、ツール呼び出しのための公開および内部APIです。
エージェントとオーケストレーション: モデルが内部ツールや外部サービスを呼び出せるコード。
モデルアーティファクト: 重量、検問所、コンテナ画像など、サプライチェーン内で改ざんされる可能性があります。
ガードレールがなければ、通常のAIの挙動がセキュリティインシデントに発展し、プロンプトインジェクション攻撃でベクターストアから機密データが取得されたり、エージェントが内部APIに対して意図しない操作を実行したり、誤設定されたエンドポイントが顧客情報を漏らしたりします。 これらの失敗は、モデルの出力がユーザーに直接見えるため、セキュリティリスクとブランドリスクの両方を生み出します。
規制対象の産業の企業はすでに多層のガードレールを用いて展開の安全性を確保しています。 例えば、自動車メーカーは厳格な入力フィルタリング、車両データへのアクセス管理、運転者への応答を実行時にチェックするクラウドベースのアシスタントを運用しています。 これにより、厳格な安全とコンプライアンスの境界を守りながら、先進的なモデルを採用できます。
AIガードレールの種類
実用的なガードレールは パイプライン. 入力はモデルに到達する前にチェックされ、モデルは制御された実行コンテキスト内で実行され、出力はユーザーや下流システムに届く前に検証されます。
1. 入力ガードレール
入力ガードレールは受信要求を評価し、再構成します 推論の前. これは安全でない行動に対する最初の予防層です。
一般的な入力ガードレールには以下が含まれます:
迅速な注入と脱獄検出: システム命令の上書きや制限データへのアクセスを試みる試みを特定します。
機密データのスキャン: プロンプト内のPII、PHI、認証情報、キーを検出・編集できます。
違法または禁止されたコンテンツ: 有害な指示や禁止資料を求めるリクエストはブロックしてください。
管理の乱用と誤用: レート制限の厳格化、異常な使用状況の特定、安全フィルターに対する力任せのブロック。
実際には、入力ガードレールはプロンプトを拒否したり、明確化を求めたり、 入力をサニティ化してください (例:マスキング識別子)をモデルに送る前に。
2. 処理ガードレール
処理ガードレールは、モデルが動作する実行コンテキストを形作ります。 モデルが何にアクセスし、どのように動作できるかを決定し、プロンプトのテキストを超えて決定します。
処理ガードレールには通常以下が含まれます:
コンテキストコントロール: 各リクエストごとにモデルに提供できる文書、フィールド、ログを制限します。
RAGの安全性: 検索パイプラインがクエリできるコレクション、使用可能な結果数、取得したコンテンツへのフィルタリングを制限します。
ポリシーの執行: 「このモデルは本番の支払いAPIにアクセスできない」や「同じ地域からしかデータを返せない」といったビジネスルールをエンコードします。
アイデンティティおよび最小権限管理: IAMポリシーを使って、モデルのサービスアカウントが不正なデータソースやサービスにアクセスするのを制限します。
ツールおよびエージェントのガードレール: AIエージェントが呼び出せるツール、人間の承認が必要な動作、実行前にパラメータの検証方法を定義します。
クラウドプロバイダーの安全機能(例:Azure OpenAI、Bedrock、Vertex AIのコンテンツフィルターやトピックフィルター)はこのレイヤーをサポートできますが、組み合わせて行うべきです
3. 出力ガードレール
出力ガードレールはモデルの応答を評価する
一般的な出力ガードレールには以下が含まれます:
毒性と内容の安全性: ヘイト、嫌がらせ、自傷行為のコンテンツ、その他禁止されているカテゴリーを検出してください。
幻覚検出: 主張を信頼できる情報源や取得した文脈と比較し、裏付けられない主張を特定しましょう。
機密データの漏洩: 出力でPII、PHI、認証情報、秘密情報をスキャンし、必要に応じて削除またはブロックします。
ブランドとポリシーの整合性: トーンを調整し、必要な開示を盛り込み、規制ドメインにおけるコンプライアンスルールの施行を行う。
出力ガードレールは応答をブロックしたり、確認を求めたり、
多くのチームはルールベースのチェック(パターンの許可・拒否、編集ルール、プロンプトポリシー)と機械学習ベースの分類器(毒性検出、脱獄検出、個人情報検出)を組み合わせています。 他の企業は、モデレーションAPIやオープンソースのガードレールフレームワークを用いて、ベンダーモデルをプロバイダー間で一貫した安全層でラップしています。
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

ガードレールはそのAIリスクに対処するために設計されています
AIのガードレールは特定の故障クラスを防ぐために存在します。 これらの脅威を理解することで、データとインフラの両方を守るコントロールを設計できます。
ほとんどのAIリスクは、 4つのカテゴリー:
1. モデルの動作操作
攻撃者はモデル命令に影響を与えたり、上書きしたりして安全でないアクションや出力を生成しようとします。
迅速な注射: システム命令を上書きし、データを抽出したり、許可されていない行動をトリガーする入力をクラフトする。
間接プロンプトインジェクション: 悪意のある命令を文書やデータ内に埋め込み、モデルが後で取得やコンテキストを通じて取り込むこと。
脱獄: ロールプレイング、翻訳、その他の間接的な要求パターンを用いて、モデルに組み込みの安全制約を無視させること。
対立的なプロンプト: 悪意に見えずに誤った出力を引き起こすための微妙なプロンプトパターン。
これらのリスクは主に以下で対処されます
2. データとコンテキストの操作
敵対者はモデルを直接攻撃するのではなく、 データパイプライン その形は行動をモデルにしています。
データポイゾン: 悪意あるまたは偏ったデータを訓練セットやファインチューニングに注入し、モデルが安全でないパターンを学習させる。
コンテキスト中毒: RAGシステムで使用される文書や検索インデックスを操作して応答に影響を与えること。
ラグ中毒: どの文書が取得されるかを制御し、モデルが誤解を招く情報を繰り返すようにします。
ファインチューンハイジャック: バックドアを挿入するためにファインチューニングを妥協すること。
これらの脅威は必要とします
3. 機密情報と知的財産の抽出
攻撃者はモデルやその支援コンポーネントからデータを回復しようと試みます。
モデル抽出: 独自モデルの挙動を繰り返しクエリで再現すること。
メンバーシップの推論: モデルの応答を探ることで、特定の記録がトレーニングデータの一部かどうかを判定すること。
機密データの漏洩: このモデルはログ、トレーニングデータ、またはベクターストアから暗記した内容を再現します。
これらのリスクは、
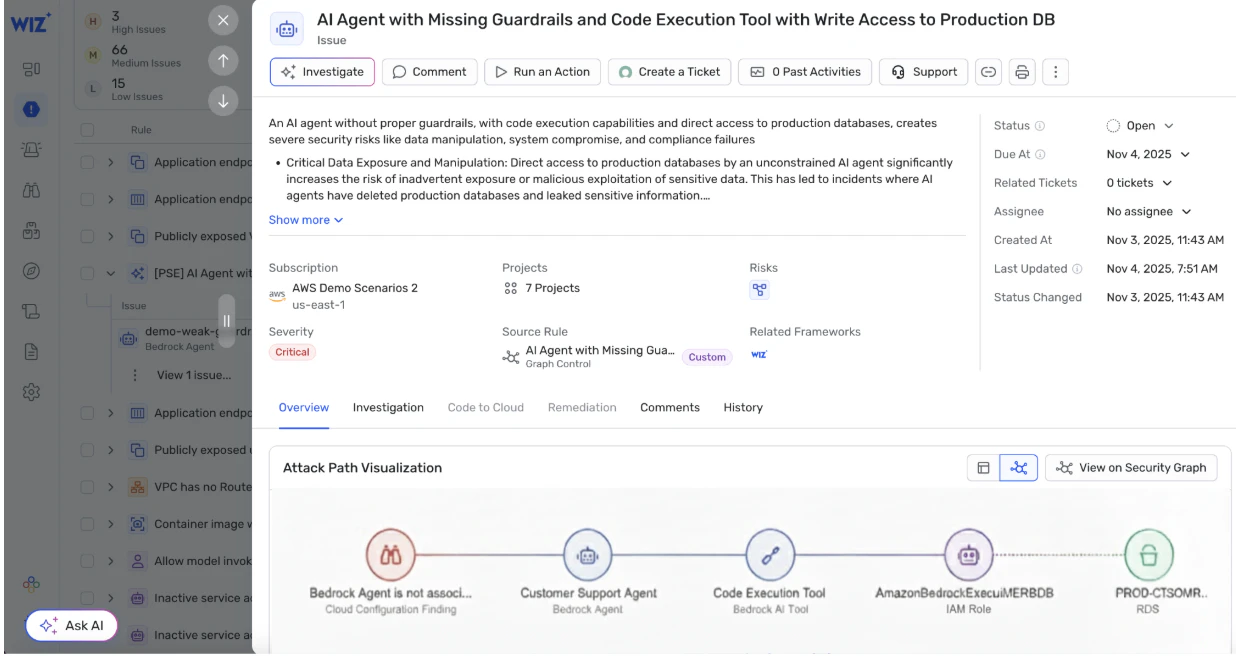
4. エージェントやツールを通じたアクセスの悪用
最も急速に成長しているリスクのカテゴリーは、
過剰な権限を持つエージェント: 内部API、データベース、クラウドサービスに広くアクセスできるエージェントです。
道具の乱用: 予期せぬ方法で使用されたツールが、無許可の操作につながった。
アイデンティティのエスカレーション: 適切な隔離なしに特権サービスアカウントの下で行動するモデル。
これらのリスクは必要です
Sample AI Security Assessment
Get a glimpse into how Wiz surfaces AI risks with AI-BOM visibility, real-world findings from the Wiz Security Graph, and a first look at AI-specific Issues and threat detection rules.
Get Sample Report

AIガードレールの実際の仕組み
実際のシステムでは、ガードレールは最後に付け加える単一のフィルターではありません。 APIのエントリポイントから出力検証まで、リクエストパス全体に複数のコントロールが適用されるものです。 各層は異なるリスクのクラスを除去します。
共通 ガードレールを用いた推論フロー こんな感じです:
ユーザー要望: ユーザーはプロンプトまたはAPIコールを送信します。
入力ガードレール: リクエストはモデルに届く前に検証、サニティ、または却下されます。
コンテキスト構成(RAG): 検索を使用する場合は、承認されたデータソースと文書のみが取得・フィルタリングされます。
ポリシーの執行: ビジネスルールやセキュリティチェックは、モデルがアクセスできるものや呼び出すツールを形作ります。
モデル推論: モデルはこれらの制約の中で応答を生成します。
ツール実行(エージェント): モデルがアクションを要求した場合、パラメータは最小権限で検証・実行されるか、人間の承認が必要です。
出力ガードレール: 回答は安全性、対応された主張、機密データ、コンプライアンスの確認を経てユーザーに返送されます。
記録と監視: 分析、アラート、改善のために全てのやり取りが記録されます。
このパターンにより、危険な行動が起こる前に防ぎ、見逃された問題を察知できます。
ガードレールが施行される場所
ガードレールはアーキテクチャのいくつかのポイントに統合できます:
APIゲートウェイ: 認証、レート制限、粗いコンテンツチェック。
オーケストレーションレイヤー: チェーン、ミドルウェア、そしてプロンプトフィルター、コンテキストコントロール、ポリシーロジックを実装するバリデータ。
クラウドサービス: 推論中に動作する提供者安全フィルター(例:毒性フィルターやトピックフィルター)。
恒等層: IAMポリシーは、モデルのサービスアカウントがアクセスできるデータソース、API、ツールを定義します。
道具の境界: エージェントのアクションに対する検証および承認の流れ。
ベクターストア: アクセス制御と文書レベルのフィルタリングによるコンテキストポイズニングやデータ漏洩を防ぎます。
出力フィルター: 安全でない回答をブロックまたは書き換える分類モデルやルール。
各層は異なるリスククラスを除去するよう設計されており、ある層の故障は別の層に受け止められます。
Wizがセキュリティライフサイクル全体にわたる包括的なAIガードレールを可能にする方法
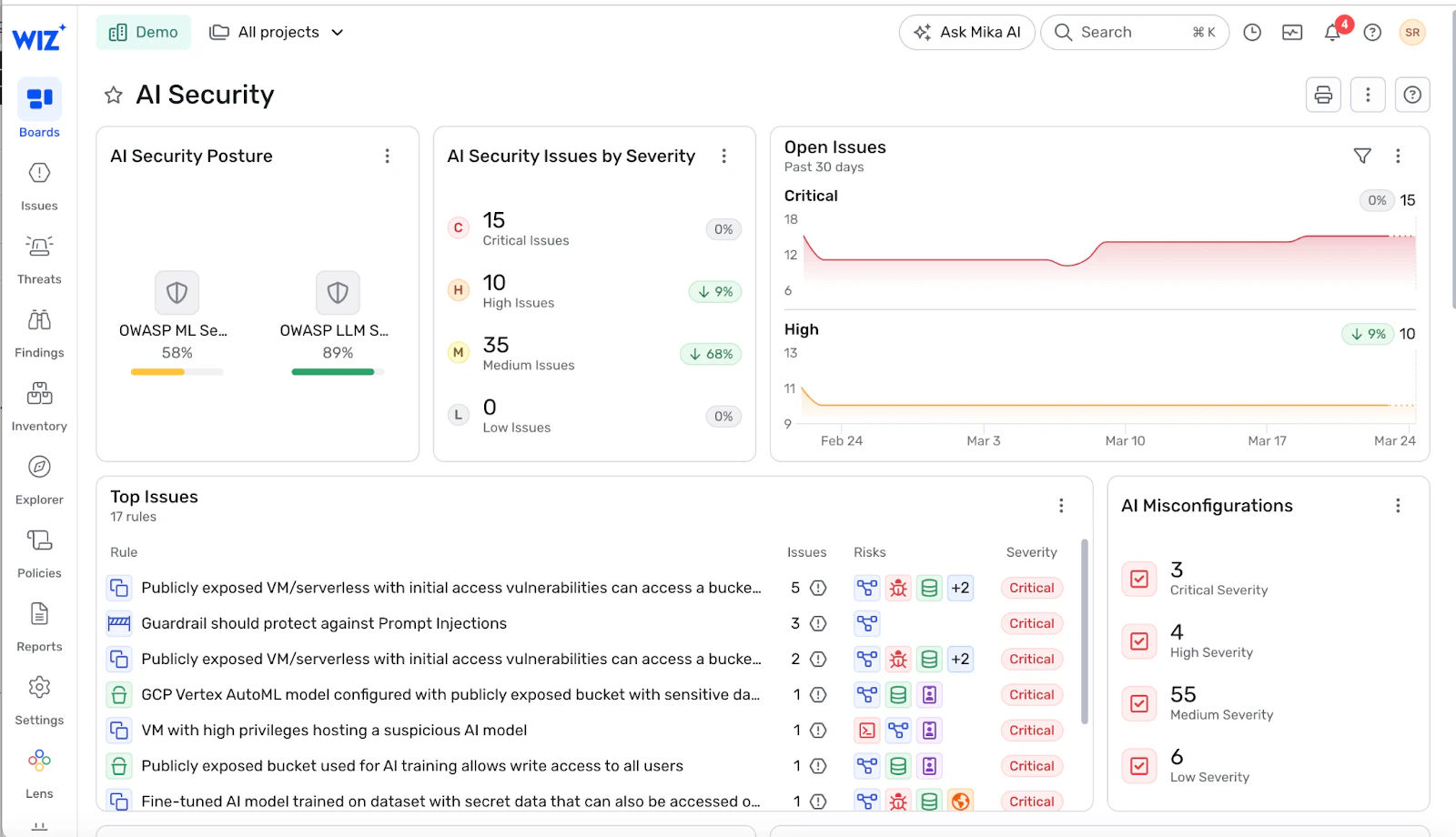
Wiz AI-SPM AWS、Azure、GCPにわたるAI資産のエンドツーエンドの可視化を提供します。マネージドAIサービスや推論エンドポイントから、検索パイプラインやその背後にあるアイデンティティまで。 WizはAmazon SageMaker、Azure OpenAI、Google Vertex AIのようなプラットフォームの誤設定を検出します。例えば、機密データにアクセスできるパブリックエンドポイントや、過剰権限で動作するエージェントなど、ガードレールを回避する可能性があります。
その Wizセキュリティグラフ インフラ、アイデンティティ、データ、AIワークロードがどのように相互作用するかをマッピングします。 これにより、環境に隠れた有害な組み合わせを見抜くことができます。例えば、エージェントに紐づけられた広範なサービスアカウントを通じてアクセス可能な、機密訓練データで満たされたベクターストアと通信する露出したエンドポイントです。 Wizはこれらのリスクを表面化し、ガードレールの下にあるバイパス経路を取り除くことができます。
Wizはこれらのコントロールを開発および実行時のライフサイクル全体にわたって拡張しています。 ウィズコード IaCやAIインフラを定義するアプリケーションコードをスキャンし、ハードコードされたモデルキー、リスクの高いネットワークルール、誤設定のAIサービスなどの問題を展開前に検出します。 ウィズ・ディフェンド AI関連ワークロードを実行時に監視し、異常なAPIパターン、不正なデータアクセス、モデルの挙動に関連した潜在的な流出の試みを監視します。 内蔵 DSPM 能力はトレーニングや推論に使われる機密データを分類し、それがモデルやエンドポイントにどのように流れ込むかを示すことで、現実に基づいたデータ重視のガードレールを構築できます。
これらすべてのコンテキストが一つのプラットフォームに集まるため、組織はコードリポジトリ、CI/CDパイプライン、クラウドリソース、ランタイム環境間で統一されたAIセキュリティポリシーを適用できます。 言い換えれば、Wizはあなたのガードレールのためのガードレールを提供します。 モデル周辺のインフラ、データパス、アイデンティティが適切に設定され、監視され、保護されることを保証します。
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
