LLMジャッキとは?
LLMジャッキングは、サイバー犯罪者が企業のクラウドベースのLLM(大規模言語モデル)を操作し、悪用するために使用する攻撃手法です。 LLMジャッキングとは、クラウドアカウントの認証情報を盗んで販売し、企業のLLMへの悪意のあるアクセスを可能にする一方で、被害者が知らず知らずのうちに消費コストを負担するというものです。
我が 研究 によると、10社中7社の企業が、Amazon BedrockやAmazon BedrockなどのクラウドプロバイダーからのジェネレーティブAI(GenAI)サービスを含む人工知能(AI)サービスを活用しています。 セージメーカー、Google Vertex AI、Azure OpenAI サービスです。 これらのサービスにより、開発者はClaude、Jurassic-2、GPTシリーズ、DALL-E、OpenAI Codex、Amazon Titan、Stable DiffusionなどのLLMモデルにアクセスできます。 LLMモデルへのアクセスを販売することで、サイバー犯罪者は複数の組織の柱に損害を与えるドミノ効果を開始することができます。
脅威アクターは、自分でデータを盗むためにLLMジャッキング攻撃を行うこともありますが、多くの場合、LLMアクセスをより大きなサイバー犯罪者に販売します。 これは、潜在的な攻撃の範囲と規模を拡大するため、さらに危険です。 企業のLLMを乗っ取ることで、クラウドベースのLLM認証情報を購入したサイバー犯罪者は、独自の攻撃を仕掛けることができます。
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

LLMジャッキング攻撃の潜在的な結果は何ですか?
消費コストの増加
サイバー犯罪者がLLMジャッキング攻撃を行うと、最初の影響は過剰な消費コストです。 これは、クラウドベースのGenAIおよびLLMサービスは、有益であると同時に、企業がホストするにはかなりの費用がかかる可能性があるためです。 したがって、敵対者がこれらのサービスへのアクセスを販売し、秘密裏で悪意のある使用を可能にすると、コストが加算される可能性があります。 聞いたところでは 研究、LLMジャッキング攻撃により、1日あたり最大46,000ドルの消費コストが発生する可能性があります。 この金額は、LLM の価格モデルによって変動する可能性があります。
エンタープライズLLMの武器化
企業のLLMモデルが整合性を欠いていたり、堅牢なガードレールを備えていなかったりすると、有害な出力が生成される可能性があります。 組織固有のLLMモデルをハイジャックしたり、LLMアーキテクチャをリバースエンジニアリングしたりすることで、敵対者は企業のGenAIエコシステムを悪意のある攻撃や活動の武器として使用できます。 たとえば、脅威アクターは、エンタープライズLLMを操作することで、バックエンドと顧客向けのユースケースの両方で、誤った出力または悪意のある出力を生成させることができます。 企業がこの種のハイジャックを特定するには時間がかかる場合があり、その頃までに損害が発生することがよくあります。
既存のLLMの脆弱性の悪化
LLM の採用には、固有のセキュリティ上の課題があります。 聞いたところでは オワスプでは、LLM の上位 10 件の脆弱性には、プロンプト インジェクション、トレーニング データ ポイズニング、モデルのサービス拒否、機密情報の漏洩、過剰なエージェンシー、過度の依存、モデルの盗難などがあります。 サイバー犯罪者がLLMジャッキング攻撃を使用すると、LLMに関連する固有のリスクと脆弱性が大幅に悪化します。
高レベルの降雪効果
企業がミッションクリティカルな状況でGenAIとLLMを急速に取り入れていることを考えると、LLMジャッキング攻撃は深刻な高レベルかつ長期的な影響を与える可能性があります。 たとえば、LLMジャッキングは企業の攻撃対象領域を拡大し、データ侵害やその他の主要なエクスプロイトを引き起こす可能性があります。
さらに、AIの習熟度は今日の企業にとって重要な評判指標であるため、LLMジャッキング攻撃は、同業者や一般の人々からの信頼と尊敬を失う可能性があります。 LLMジャッキングの壊滅的な経済的影響、これには、利益率の低下、データ損失、ダウンタイムコスト、弁護士費用など、忘れないでください。
LLMジャッキング攻撃の仕組みは?
原則として、LLMジャッキングは次のような攻撃と似ています クリプトジャッキングでは、脅威アクターが企業の処理能力を使用して暗号通貨を密かにマイニングします。 どちらの場合も、脅威アクターは組織のリソースとインフラストラクチャを使用します。 しかし、LLMジャッキング攻撃では、ハッカーの照準はクラウドでホストされているLLMサービスとクラウドアカウントの所有者にしっかりと照準を合わせています。
LLMジャッキングの仕組みを理解するために、2つの視点から見てみましょう。 まず、企業がLLMをどのように使用しているかを探り、次に脅威アクターがLLMをどのように悪用するかについて説明します。
企業はクラウドでホストされるLLMサービスとどのようにやり取りしますか?
ほとんどのクラウドプロバイダーは、アジャイルLLMの採用のために設計された使いやすいインターフェイスとシンプルな機能を企業に提供します。 ただし、これらのサードパーティモデルは自動的に使用できるわけではありません。 まず、アクティベーションが必要です。
LLMをアクティブ化するには、開発者はクラウドプロバイダーにリクエストを行う必要があります。 開発者は、単純なリクエストフォームなど、いくつかの異なる方法でリクエストを行うことができます。 開発者がこれらのリクエストフォームを送信すると、クラウドプロバイダーはLLMサービスを迅速にアクティブ化できます。 アクティベーション後、開発者はコマンドラインインターフェイス(CLI)コマンドを使用してクラウドベースのLLMと対話できます。
アクティベーションリクエストフォームをクラウドプロバイダーに送信するプロセスは、万全のセキュリティレイヤーによって保護されていないことに注意してください。 脅威アクターも簡単に同じことができるため、企業は追加の種類のAIおよびLLMセキュリティに焦点を当てる必要があります。
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

脅威アクターはどのようにLLMジャッキング攻撃を行うのか?
企業が通常、クラウドでホストされるLLMサービスとどのようにやり取りするかを理解したところで、脅威アクターがLLMジャッキング攻撃をどのように促進するかを見てみましょう。
ここでは、脅威アクターがLLMジャッキング攻撃を指揮するために実行する手順をご紹介します。
クラウドの認証情報を販売するには、脅威アクターはまず認証情報を盗む必要があります。 研究者が最初にLLMジャッキング攻撃手法を発見したとき、彼らは盗まれた資格情報を脆弱なバージョンのLaravel(CVE-2021-3129).
脅威アクターが脆弱なシステムから認証情報を盗むと、違法なマーケットプレイスで他のサイバー犯罪者に販売し、他のサイバー犯罪者がそれを購入し、より高度な攻撃に利用することができます。
盗まれたクラウドの認証情報を手に入れた脅威アクターは、アクセス権限と管理権限を評価する必要があります。 サイバー攻撃者は、クラウドアクセス権限の制限を密かに評価するために、
InvokeModel API呼び出し。にもかかわらず、
InvokeModel APIcall が有効なリクエストである場合、脅威アクターはmax_tokens_to_sampleを -1 に設定します。 この手順は、盗まれた資格情報がLLMサービスにアクセスできるかどうかを確認するためのものです。 逆に、「AccessDenied」エラーが表示された場合、脅威アクターは、盗まれた資格情報が'悪用可能なアクセス権限はありません。
敵対者は、 GetModelInvocationLoggingConfiguration を使用して、企業のクラウドでホストされている AI サービスの構成設定を把握します。 この手順は、個々のクラウド プロバイダーとサービスのガードレールと機能に依存することに注意してください。 そのため、場合によっては、脅威アクターが企業のLLMの入力と出力を完全に把握していない可能性があります。
LLMジャッキング攻撃を行っても、脅威アクターの収益化が保証されるわけではありません. ただし、脅威アクターがLLMジャッキングが有益であることを確認できる方法がいくつかあります。 LLMジャッキング攻撃の剖検中に、研究者は、敵対者がオープンソースのOAIリバースプロキシサーバーを一元化されたパネルとして使用して、盗まれたクラウド資格情報をLLMアクセス権限で管理できる可能性があることを発見しました。
脅威アクターがLLMジャッキング攻撃を収益化し、企業のLLMモデルへのアクセスを販売すると、どのような被害が生じるかを予測する方法はありません。 さまざまな背景を持ち、さまざまな動機を持つ他の敵対者は、知らないうちにLLMアクセスを購入し、企業のGenAIインフラストラクチャを使用することができます。 LLMジャッキング攻撃の結果は最初は隠されたままかもしれませんが、その影響は壊滅的なものになる可能性があります。


LLMジャッキングの防止と検出の戦術
ここでは、企業がLLMジャッキング攻撃から身を守るための強力な方法をいくつか紹介します。
予防戦術
ロバストなモデルトレーニング:
多様で高品質なデータセット: バイアスや脆弱性を防ぐために、モデルが幅広いデータでトレーニングされていることを確認します。
敵対的トレーニング: モデルを悪意のある入力にさらして、回復性を向上させます。
ヒューマンフィードバックからの強化学習 (RLHF): モデルを整列させる'人間の価値観と期待を出力します。
厳密な入力検証:
フィルタリング: フィルターを実装して、有害または悪意のあるプロンプトをブロックします。
消毒:入力をクレンジングして、潜在的に有害な要素を取り除きます。
レート制限: 不正使用を防ぐために、リクエストの数を制限します。
定期的なモデル監査:
脆弱性評価: モデルの潜在的な弱点を特定します。
バイアス検出: モデル内の意図しないバイアスを監視します'の出力。
パフォーマンスの監視: モデルのパフォーマンスを経時的に追跡して、異常を検出します。
透明なモデルドキュメント:
明確なガイドライン: 責任を持ってモデルを使用する方法について明確な指示を提供します。
制限事項: モデルの伝達'の制限と潜在的なバイアス。
継続的な学習と適応:
最新情報を入手:最新のLLMの脅威と対策について常に最新の情報を入手してください。
モデルの更新: 新しい脆弱性に対処するために、モデルを定期的に更新します。
検出戦術
異常検出:
外れ値の特定: 通常とは異なる、または予期しないモデルの動作を特定します。
統計分析:統計的手法を使用して、通常のパターンからの逸脱を検出します。
コンテンツ監視:
キーワードフィルタリング:有害なコンテンツに関連付けられた特定のキーワードまたはフレーズの出力を監視します。
感情分析: 生成されたコンテンツの感情を分析して、潜在的な問題を特定します。
スタイル分析: 生成されたコンテンツの書体に異常を検出します。
ユーザー行動分析:
異常なパターン: 迅速なリクエストや繰り返しのプロンプトなど、異常なユーザー行動を特定します。
アカウントの監視: ユーザー アカウントの不審なアクティビティを監視します。
Human-in-the-Loop検証:
品質保証: 生成されたコンテンツの品質と安全性を評価するために、人間のレビュアーを雇います。
フィードバック メカニズム: ユーザー フィードバックを収集して、潜在的な問題を特定します。
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

WizがLLMジャッキング攻撃を防ぐ方法
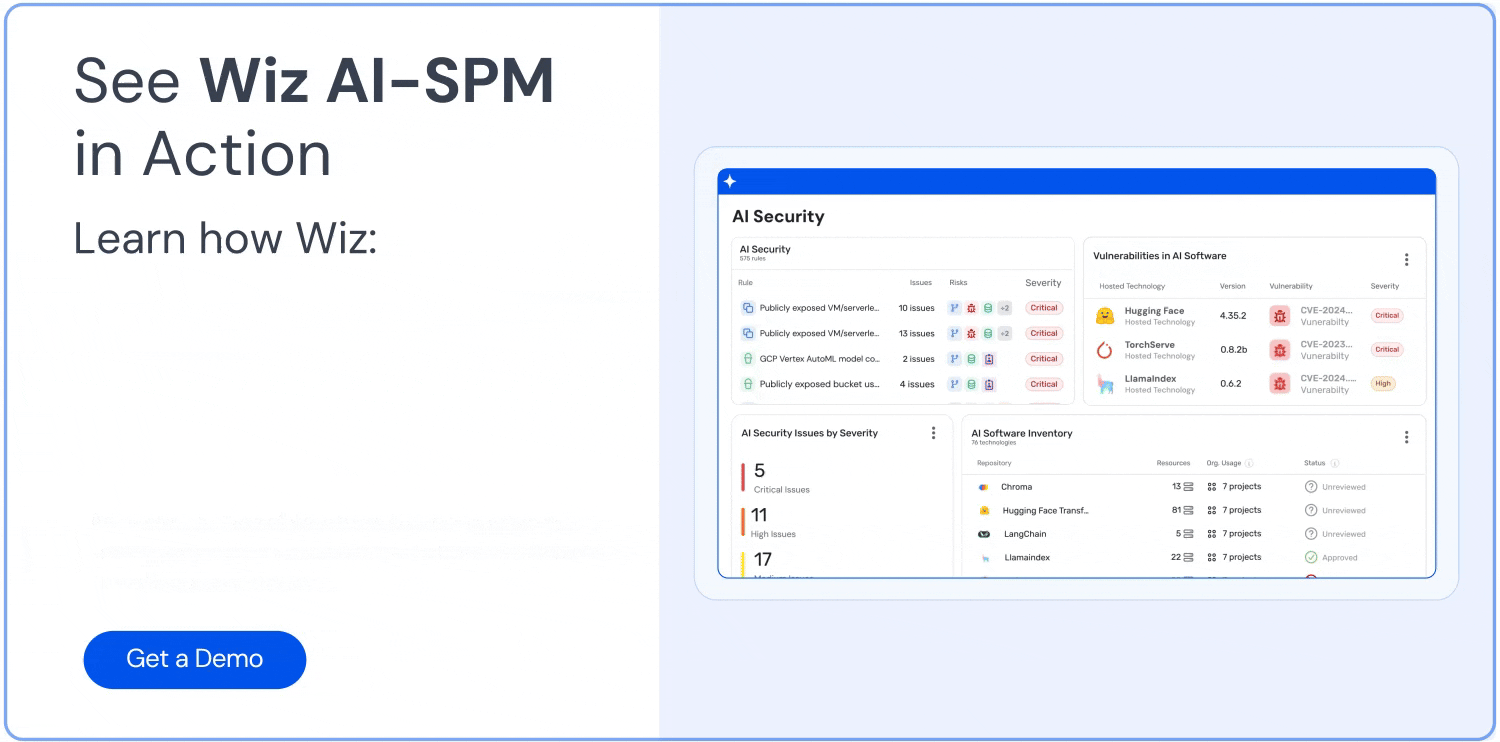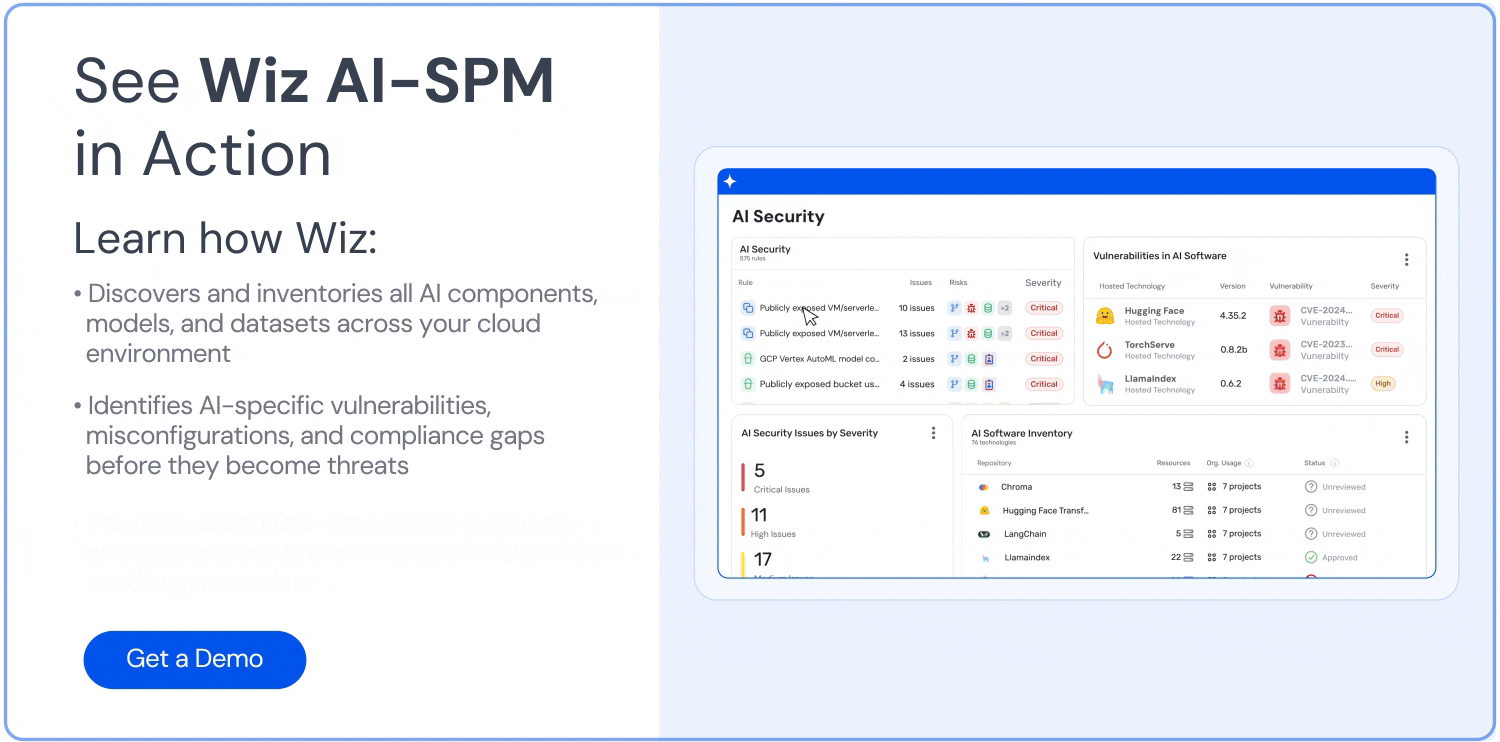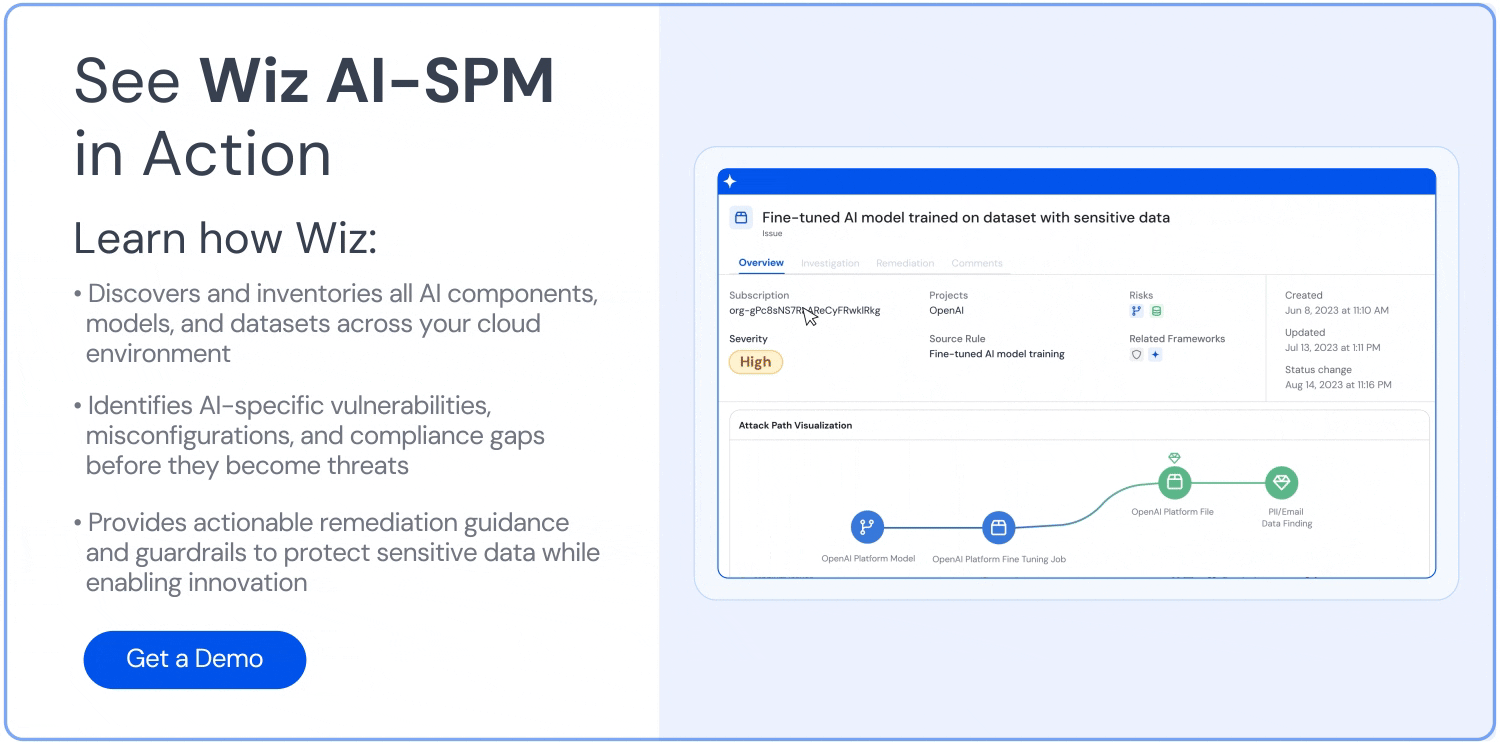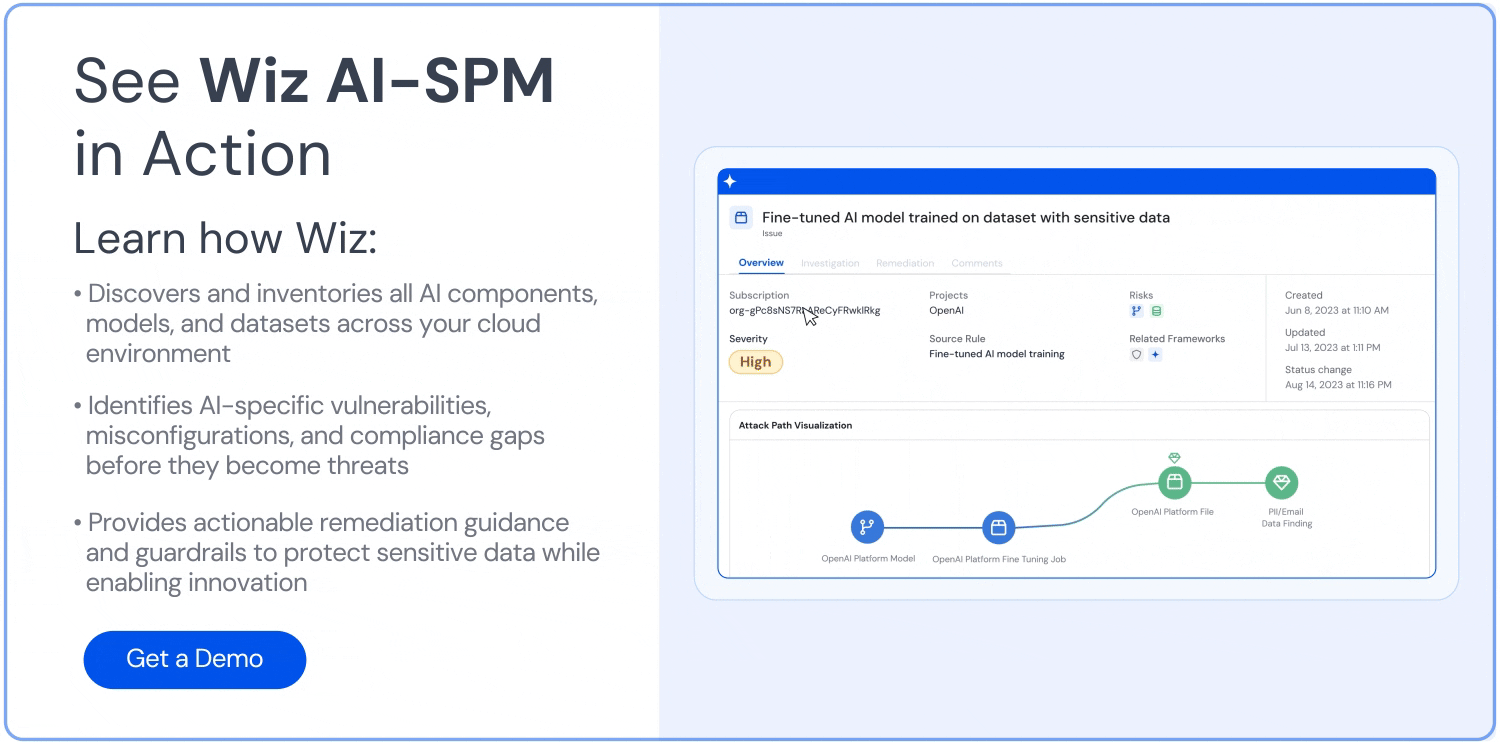
Wizの画期的なAI-SPMツールソリューション LLMジャッキング攻撃が大規模な災害にエスカレートするのを防ぎ、軽減するのに役立ちます。 Wiz AI-SPMは、いくつかの方法でLLMジャッキングに対する防御を支援します。
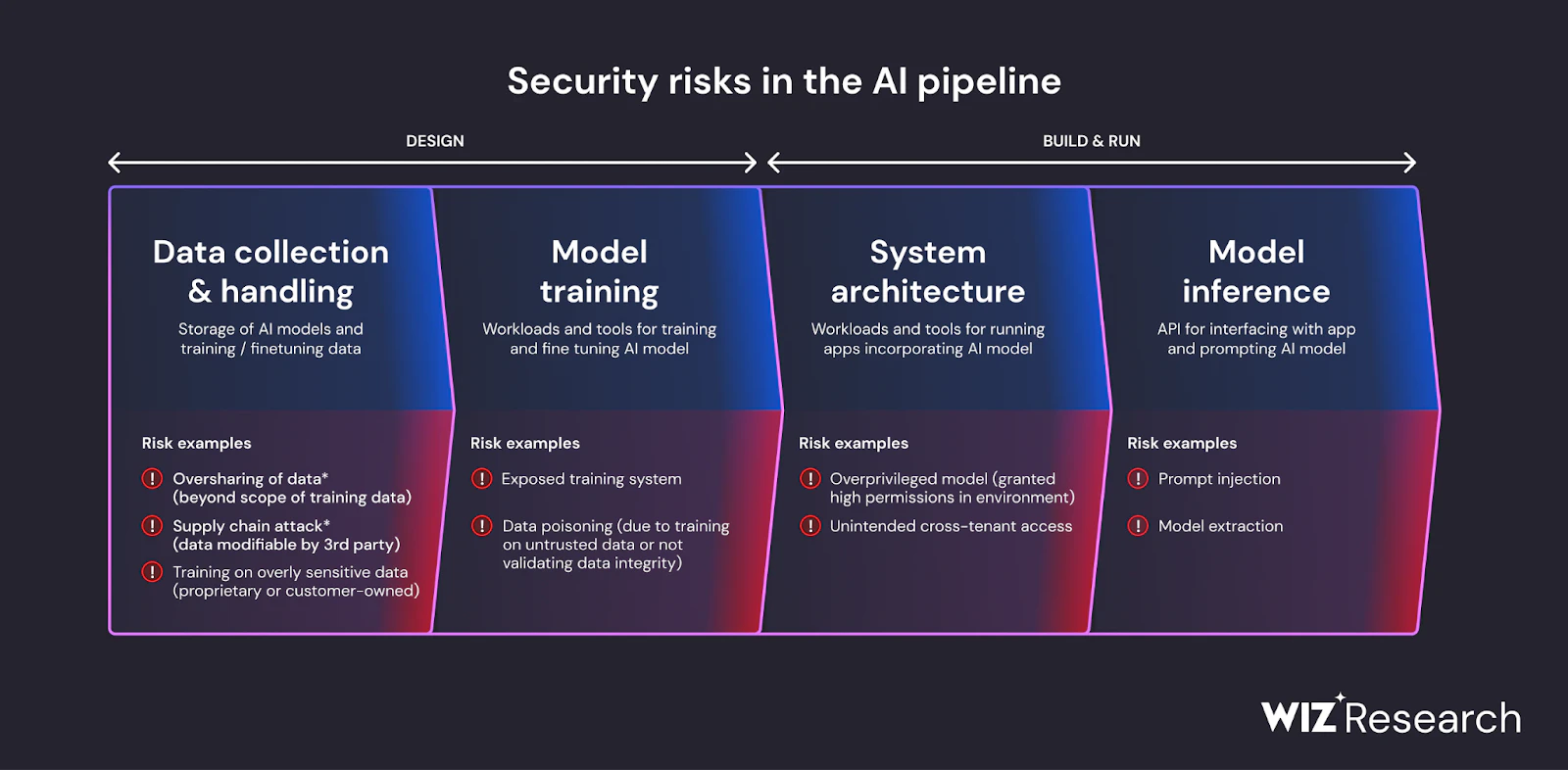
包括的な可視性: Wiz AI-SPM は、エージェントを必要とせずに、AI サービス、テクノロジー、SDK などの AI パイプラインをフルスタックで可視化します。 この可視性により、組織はLLMを含む環境内のすべてのAIコンポーネントを検出して監視し、攻撃者が未知のAIコンポーネントや シャドーAI リソース。
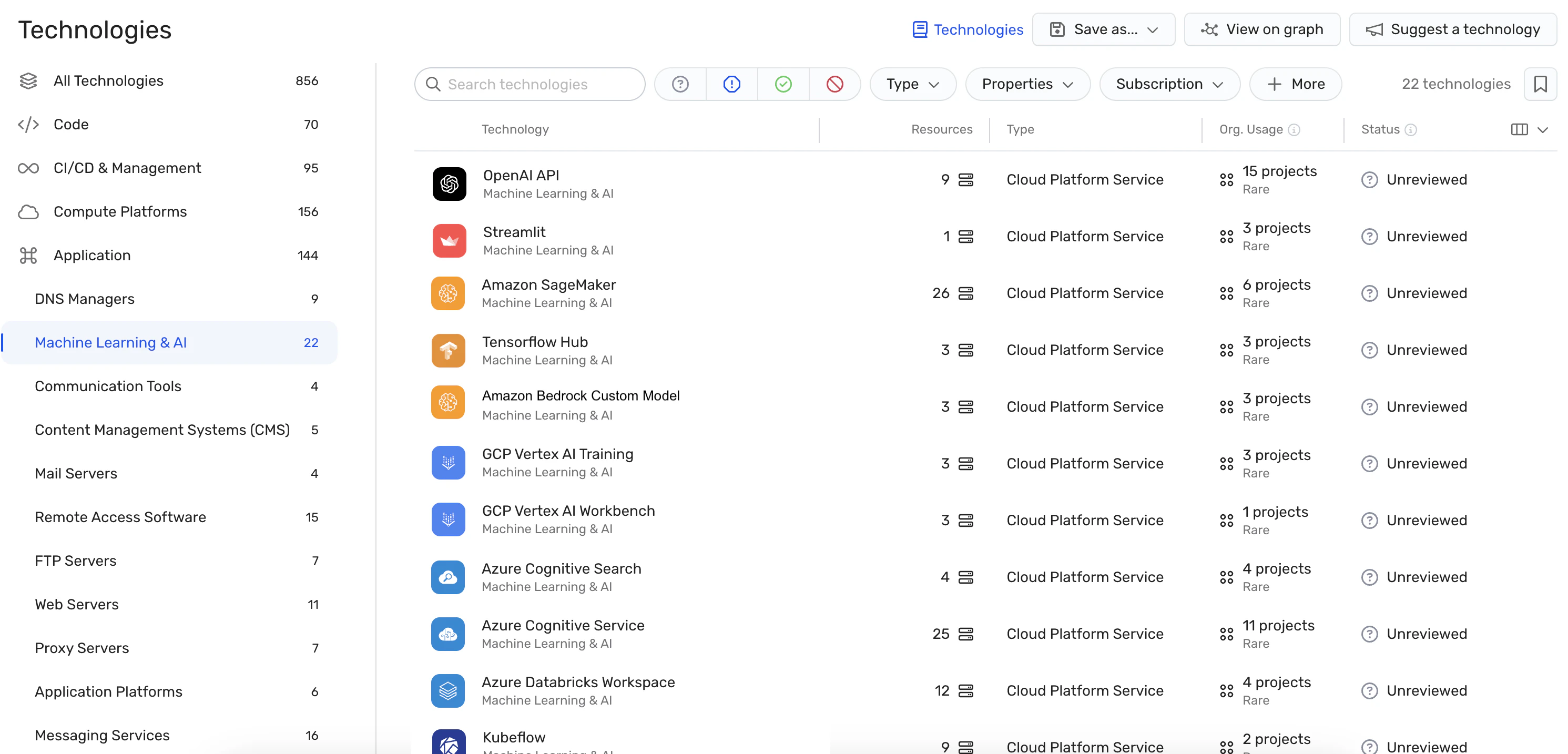
設定ミスの検出: プラットフォームは、 AI セキュリティのベスト プラクティス 組み込みルールを使用してAIサービスの設定ミスを検出します。 これにより、LLMジャッキング攻撃で悪用される可能性のある脆弱性を防ぐことができます。
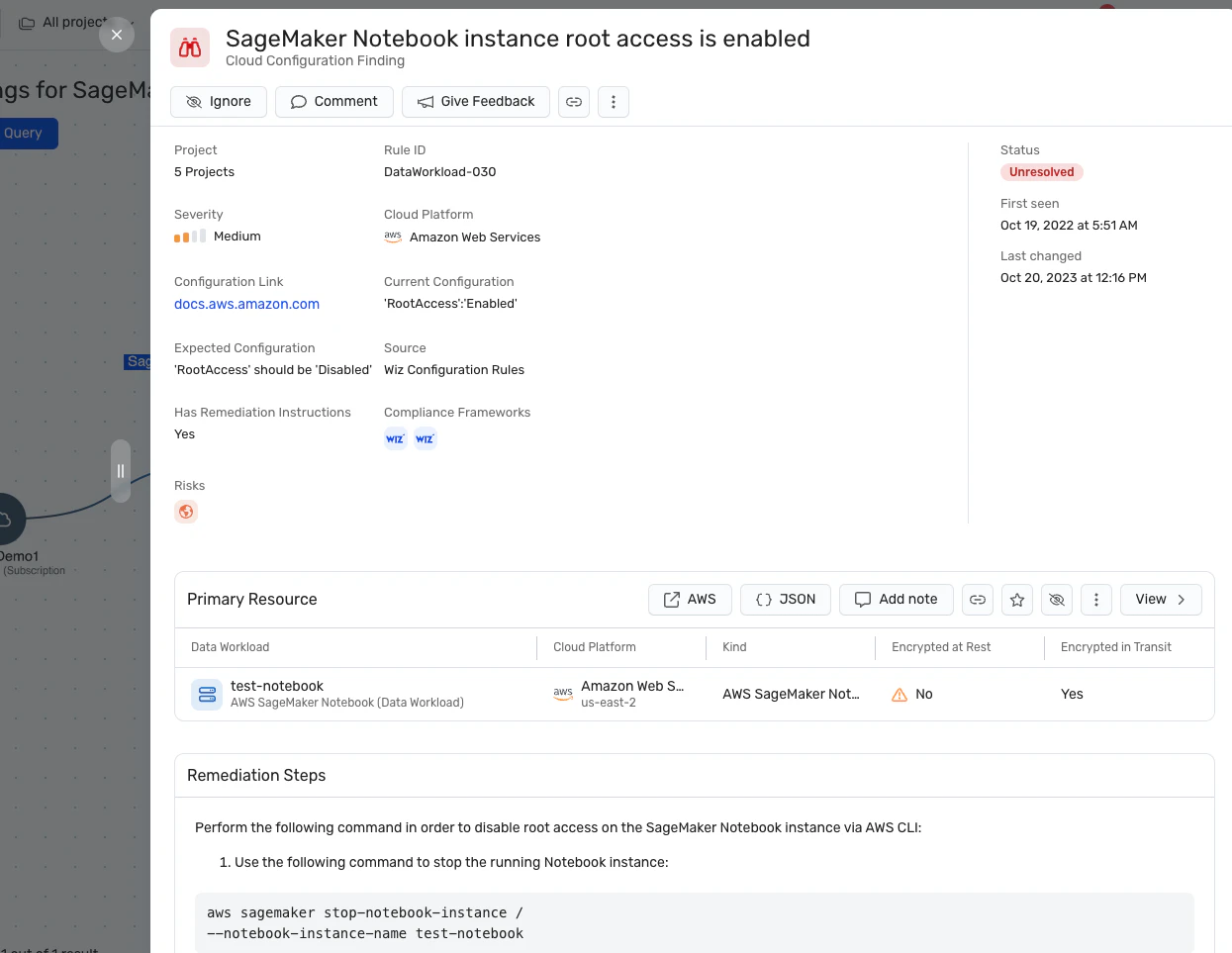
攻撃パス分析: Wiz AI-SPMは、脆弱性、ID、インターネットへの露出、データ、設定ミス、シークレットを評価することで、AIモデルへの攻撃パスをプロアクティブに特定し、削除します。 この包括的な分析は、LLMジャッキングの試みの潜在的な侵入ポイントを防ぐのに役立ちます。
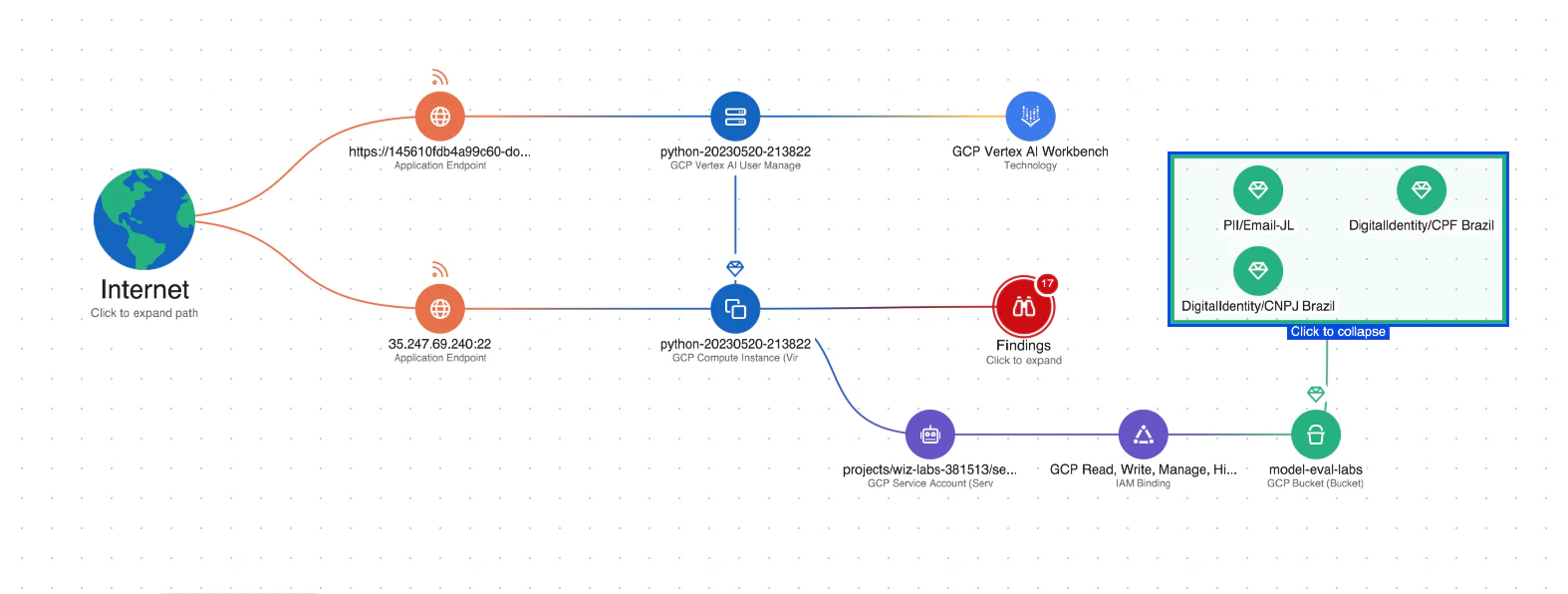
AIのデータセキュリティ: このプラットフォームには、Data Security Posture Management(DSPMの)の機能をAI専用に使用し、機密性の高いトレーニングデータを自動的に検出し、それへの攻撃経路を削除できます。 これにより、 データ漏洩 これは、LLMジャッキング攻撃に使用される可能性があります。
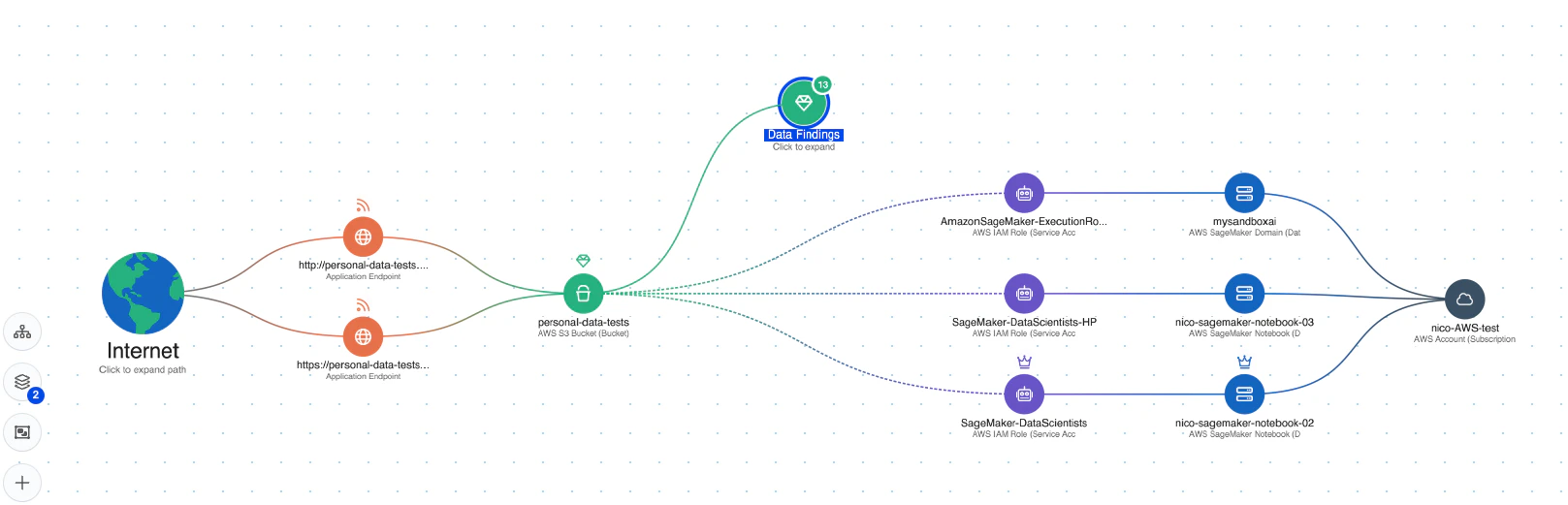
リアルタイムの脅威検出: Wiz AI-SPMは、AIモデルに起因する疑わしい動作に対するランタイム保護を提供します。 この機能により、LLM ジャッキングの試みをリアルタイムで検出して対応し、潜在的な影響を最小限に抑えることができます。
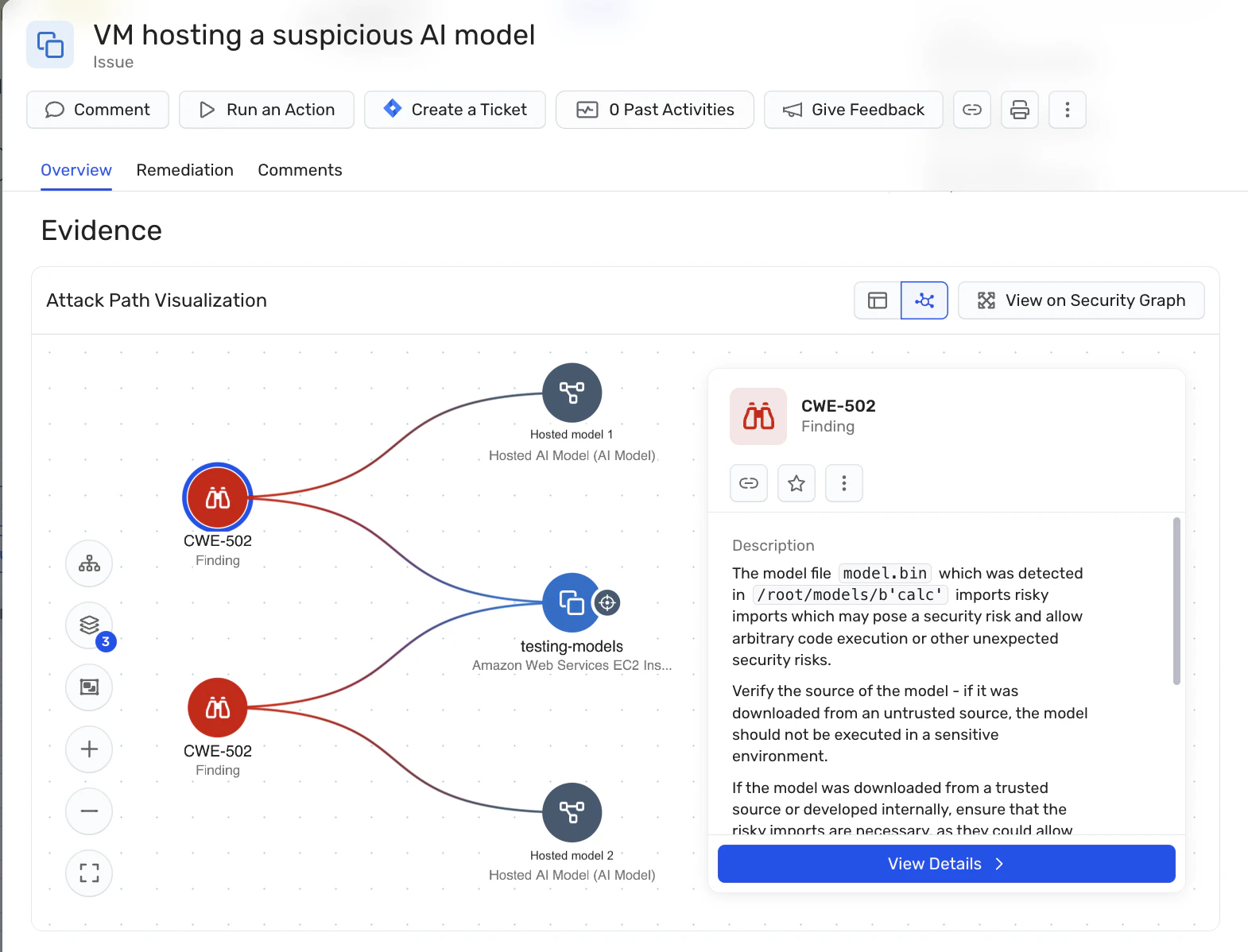
モデルスキャン: このプラットフォームは、ホストされたAIモデルの識別とスキャンをサポートしているため、組織はLLMジャッキング攻撃に使用される可能性のある悪意のあるモデルを検出できます。 これは、オープンソースモデルに関連するサプライチェーンのリスクに対処するのに役立つため、AIモデルをセルフホストする組織にとって特に重要です。
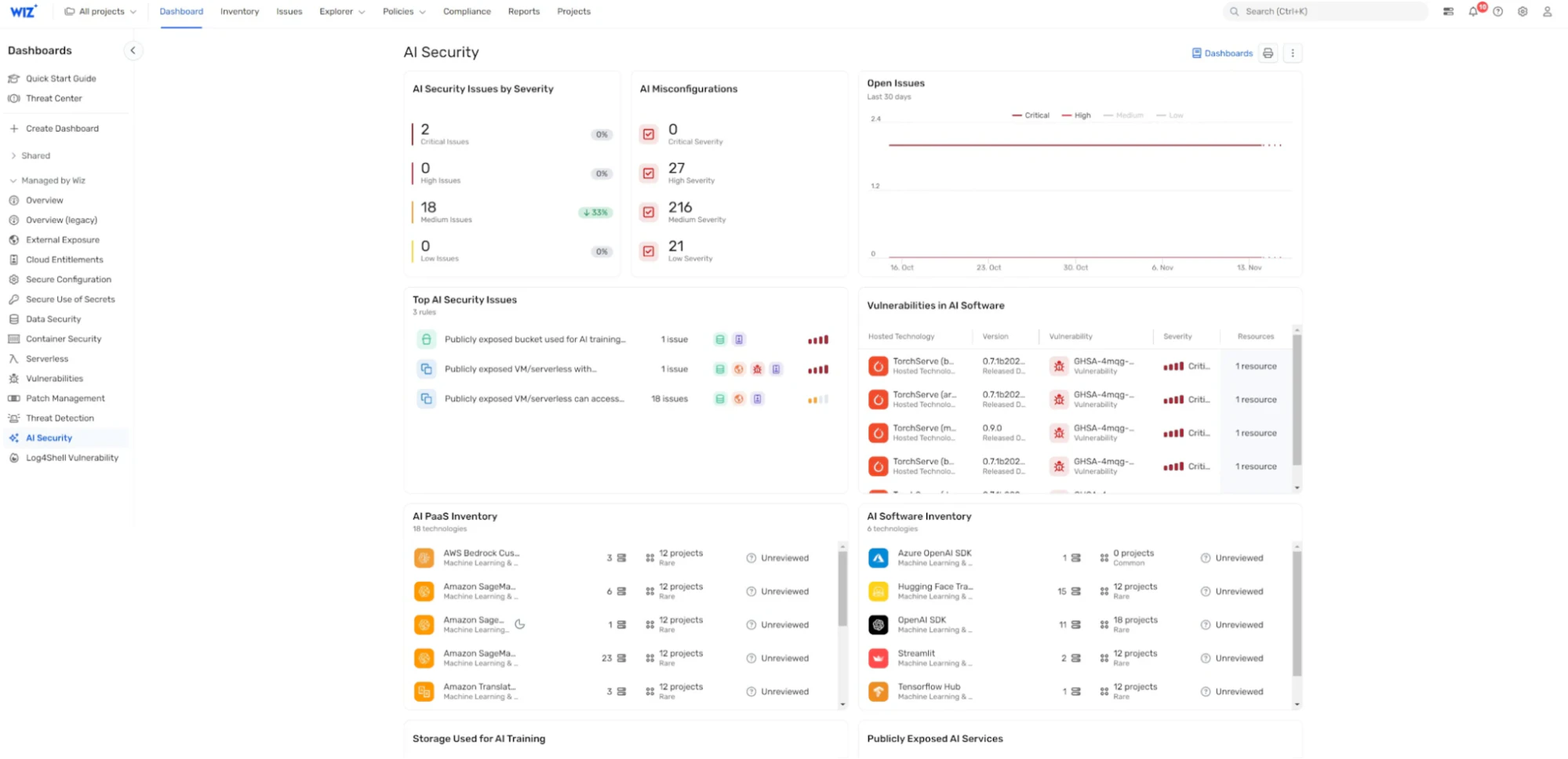
AIセキュリティダッシュボード: Wiz AI-SPMは、AIセキュリティ体制の概要とリスクの優先順位付けされたキューを提供するAIセキュリティダッシュボードを提供します。 これにより、AI開発者とセキュリティチームは、LLMジャッキングにつながる可能性のある脆弱性を含む最も重要な問題にすばやく集中できます。
Wiz AI-SPMは、これらの機能を実装することで、組織がAIシステムの強力なセキュリティ体制を維持し、攻撃者がLLMジャッキング攻撃やその他のAI関連の脅威を成功させることをより困難にします。