



データ漏洩とは?
データ漏洩とは、組織データが第三者に対して野放しに持ち出されることです。 これは、データベースの設定ミス、ネットワークサーバーの保護が不十分な、フィッシング攻撃、さらには不注意なデータ処理など、さまざまな手段で発生します。
データ漏洩は、次のような場合に誤って発生する可能性があります。 全組織の82% サードパーティに環境への広範な読み取りアクセスを許可すると、大きなセキュリティリスクと深刻なプライバシー上の懸念が生じます。 ただし、データ漏洩は、ハッキング、フィッシング、または従業員が意図的にデータを盗むインサイダー脅威などの悪意のある活動によっても発生します。
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

データ漏洩の潜在的な影響
データ漏洩は、次のような広範囲にわたる深刻な影響を与える可能性があります。
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
機械学習(ML)漏洩の脅威の高まり
大規模言語モデル (LLM) とは異なるデータセットを使用してモデルをトレーニングすると、機械学習や人工知能 (AI) のバイアスが発生する可能性があります。 この状況は通常、ML 開発の前処理フェーズの管理ミスが原因で発生します。 ML リーケージの典型的な例は、トレーニングサブセット全体ではなく、トレーニングデータセット全体の平均と標準偏差を使用することです。
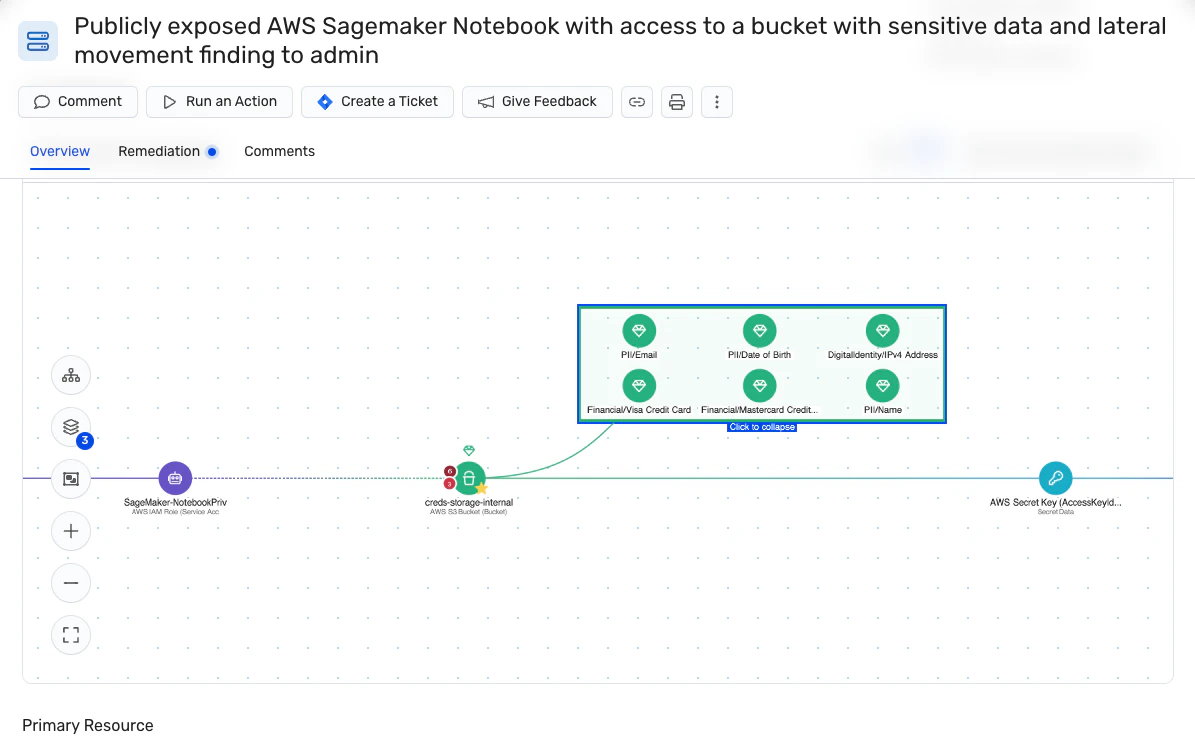
機械学習モデルでは、データ漏洩は、ターゲット漏洩や学習試験の汚染を通じて発生します。 後者では、モデルのテストを目的としたデータがトレーニングセットに漏れます。 トレーニング中にモデルがテスト データにさらされると、そのパフォーマンス メトリックは誤解を招くほど高くなります。
ターゲット漏洩では、トレーニングに使用されるサブセットには、ML 開発の予測フェーズでは利用できない情報が含まれます。 このシナリオでは LLM は優れたパフォーマンスを発揮しますが、利害関係者に モデルの有効性の誤った感覚これは、実際のアプリケーションのパフォーマンスの低下につながります。


データ漏えいの一般的な原因
データ漏洩はさまざまな理由で発生します。以下は最も一般的なものの一部です。
ヒューマンエラー
ヒューマンエラーは、組織内のどのレベルでも発生する可能性があり、多くの場合、悪意はありません。 たとえば、従業員が誤って財務記録や個人データなどの機密情報を間違ったメールアドレスに送信してしまう可能性があります。
フィッシング攻撃
フィッシング攻撃にはさまざまな形で現れますが、サイバー犯罪者が特権アカウントをおびき寄せて貴重な詳細情報を提供させるという1つの方法があります。 たとえば、攻撃者は、従業員に悪意のあるリンクをクリックして特定のアカウントにログインするように求める、一見正当なメールを送信できます。 これにより、従業員は自分のログイン資格情報を攻撃者に自発的に提供し、その資格情報が 1 つまたは複数の悪意のある目的に使用されます。
設定が不十分
データベース、クラウドサービス、ソフトウェア設定の設定に誤りがあると、機密データが不正アクセスにさらされる脆弱性が生まれます。 設定ミス 多くの場合、見落とし、専門知識の欠如、またはセキュリティのベストプラクティスに従わなかったことが原因です。 デフォルトのユーザー名やパスワードなどのデフォルト設定を変更しないままにしておくと、サイバー犯罪者に簡単にアクセスが許可される可能性があります。
アプリの設定が正しくない、セキュリティパッチやアップデートを適用しない、アクセス制御や権限の設定が不十分であるなども、セキュリティホールを引き起こす可能性があります。
セキュリティ対策が弱い
セキュリティ対策が弱いと、組織は衰退します'のセキュリティ体制。 シンプルで推測しやすいパスワードを使用する。強力なパスワードポリシーを実装しない。過剰な権限を付与し、最小特権の原則(PoLP)に従わない。また、複数のアカウントでパスワードを再利用すると、データ漏洩のリスクが高まります。
また、データを残す 暗号化(保存時および転送中) は、データを漏洩の素因となります。 実装していない 最小特権の原則 (PoLP) また、古いセキュリティプロトコル/テクノロジーに依存すると、セキュリティフレームワークにギャップが生じる可能性があります。
漏れを防ぐための戦略
1. データの前処理とサニタイズ
匿名化と編集
匿名化には、個人を特定できる情報(PII)や機密データが個人に再びリンクされるのを防ぐために、変更または削除することが含まれます。 墨消しは、クレジットカード番号、社会保障番号、住所など、データの機密部分を削除または隠すことを含む、より具体的なプロセスです。
適切な匿名化と編集がなければ、AIモデルは次のことができます "覚える" トレーニング セットからの機密データで、モデル出力で誤って再現される可能性があります。 これは、モデルがパブリックまたはクライアント向けアプリケーションで使用される場合に特に危険です。
ベストプラクティス:
トークン化、ハッシュ化、または暗号化技術を使用して、データを匿名化します。
トレーニングの前に、編集されたデータが構造化データセット (データベースなど) と非構造化データセット (テキスト ファイルなど) の両方から完全に削除されていることを確認してください。
差分プライバシー (後述) を実装して、個々のデータ漏洩のリスクをさらに軽減します。
データの最小化
データの最小化には、AIモデルの目的を達成するために必要な最小のデータセットのみを収集して使用することが含まれます。 収集されるデータが少ないほど、機密情報が漏洩するリスクは低くなります。
過剰なデータを収集すると、侵害のリスク領域が増え、機密情報が漏洩する可能性が高くなります。 何を使うだけで'必要に応じて、GDPRやCCPAなどのプライバシー規制への準拠も確認します。
ベストプラクティス:
データ監査を実施して、トレーニングに不可欠なデータポイントを評価します。
前処理パイプラインの早い段階で重要でないデータを破棄するポリシーを実装します。
データ収集プロセスを定期的に見直して、不要なデータが保持されていないことを確認します。
2. モデルトレーニングのセーフガード
適切なデータ分割
データ分割では、データセットがトレーニングセット、検証セット、テストセットに分割されます。 トレーニング セットはモデルを学習し、検証セットとテスト セットはオーバーフィットせずにモデルの精度を確保します。
データが不適切に分割されている場合(たとえば、トレーニングセットとテストセットの両方に同じデータが存在する場合)、モデルはテストセットを効果的に「記憶」できるため、パフォーマンスが過大評価され、トレーニングフェーズと予測フェーズの両方で機密情報が公開される可能性があります。
ベストプラクティス:
分割中にデータセットをランダム化して、トレーニング、検証、およびテストセット間で重複しないようにします。
k分割交差検証などの手法を使用して、データ漏洩のないモデルのパフォーマンスを堅牢に評価します。
正則化の手法
正則化手法は、モデルがトレーニングデータに特化しすぎて、トレーニングデータから一般化するのではなく「記憶」することを学習する過学習を防ぐために、トレーニング中に採用されます。 オーバーフィットは、モデルがトレーニング データから機密情報を記憶し、推論中にそれを再現できるため、データ漏えいの可能性を高めます。
ベストプラクティス:
落ち零れ:トレーニング中にニューラルネットワークから特定のユニット(ニューロン)をランダムにドロップし、モデルにパターンを記憶するのではなく一般化させます。
ウェイト減衰 (L2 正則化): トレーニング中に大きな重みにペナルティを課して、モデルがトレーニング データに近すぎるのを防ぎます。
早期停止: 検証セットでモデルのパフォーマンスを監視し、モデルが'のオーバーフィットによりパフォーマンスが低下し始めます。
ディファレンシャルプライバシー
ディファレンシャルプライバシーは、データまたはモデル出力に制御されたノイズを追加し、攻撃者がデータセット内の個々のデータポイントに関する情報を抽出するのを困難にします。
ディファレンシャルプライバシーを適用することで、AIモデルはトレーニングや予測中に特定の個人の詳細を漏洩する可能性が低くなり、敵対的な攻撃や意図しないデータ漏洩に対する保護層が提供されます。
ベストプラクティス:
学習データ、モデルの勾配、または最終予測にガウスノイズまたはラプラスノイズを追加して、個々のデータの寄与を不明瞭にします。
TensorFlow Privacy や PySyft などのフレームワークを使用して、実際に差分プライバシーを適用します。
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. セキュアなモデル展開
テナントの分離
マルチテナント環境では、テナントの分離により、各テナント間に論理的または物理的な境界が作成されます'のデータを使用して、あるテナントが別のテナントにアクセスしたり操作したりできなくなります'の機密情報。 各テナントを分離する'データを使用して、企業は不正アクセスを防止し、データ侵害のリスクを軽減し、データ保護規制へのコンプライアンスを確保できます。
テナントの分離により、セキュリティがさらに強化され、組織は自分の 機密性の高いAIトレーニングデータ 潜在的なリークや不正アクセスから保護されています。
ベストプラクティス:
論理的な分離: コンテナーや仮想マシン (VM) などの仮想化手法を使用して、各テナントのデータと処理が互いに分離されていることを確認します。
アクセス制御: 厳格なアクセス制御ポリシーを実装して、各テナントが自分のデータとリソースにのみアクセスできるようにします。
暗号化とキー管理: テナント固有の暗号化キーを使用してデータをさらに分離し、侵害が発生した場合でも、他のテナントからのデータが安全に保たれるようにします。
リソースの調整と監視: リソース制限を適用し、システムの分離を損なう可能性のある異常な動作を監視することで、テナントが共有リソースを使い果たすのを防ぎます。
出力サニタイズ
出力サニタイズには、特に自然言語処理 (NLP) モデルや生成モデルで機密データが誤って公開されるのを防ぐために、モデル出力にチェックとフィルターを実装することが含まれます。
場合によっては、モデルがトレーニング中に遭遇した機密情報 (名前やクレジット カード番号など) を再現することがあります。 出力をサニタイズすると、機密データが公開されることはありません。
ベストプラクティス:
パターンマッチングアルゴリズムを使用して、モデル出力のPII(メールアドレス、電話番号など)を識別し、編集します。
確率的出力にしきい値を設定して、モデルが過度に自信に満ちた予測を行い、機密性の高い詳細が公開されるのを防ぎます。
4. 組織運営の実践
従業員教育
従業員トレーニングにより、AIモデルの開発、デプロイ、保守に関与するすべての個人が、データ漏洩のリスクとそれらを軽減するためのベストプラクティスを理解できるようになります。 多くのデータ侵害は、人為的ミスや見落としによって発生します。 適切なトレーニングを行うことで、機密情報やモデルの脆弱性が誤って公開されるのを防ぐことができます。
ベストプラクティス:
AIモデルと機密データを扱うすべての従業員に、サイバーセキュリティとデータプライバシーのトレーニングを定期的に提供します。
新たなAIセキュリティリスクと新たな予防策についてスタッフに最新情報を提供します。
データガバナンスポリシー
データガバナンスポリシーは、組織全体でデータの収集、処理、保存、アクセスの方法に関する明確なガイドラインを設定し、セキュリティプラクティスが一貫して適用されるようにします。
明確に定義されたガバナンスポリシーにより、データの取り扱いが標準化され、GDPRやHIPAAなどのプライバシー法に準拠していることが保証され、漏洩の可能性が減少します。
ベストプラクティス:
データの所有権を定義し、AI開発のあらゆる段階で機密データを処理するための明確なプロトコルを確立します。
ガバナンスポリシーを定期的に見直して更新し、新しいリスクと規制要件を反映させます。
5. AI Security Posture Management(AI-SPM)ツールの活用
AI-SPMソリューション トレーニング/推論に使用されるデータ、モデルの整合性、デプロイされたモデルへのアクセスなど、AIセキュリティの重要なコンポーネントを可視化し、制御します。 AI-SPMツールを組み込むことで、組織はAIモデルのセキュリティ体制をプロアクティブに管理し、データ漏洩のリスクを最小限に抑え、堅牢なAIシステムガバナンスを確保できます。
AI-SPM が ML モデルの漏洩を防ぐ方法:
すべての AI アプリケーション、モデル、および関連リソースの検出とインベントリ作成
AIサプライチェーンの脆弱性と、データ漏洩につながる可能性のある設定ミスを特定します
トレーニングデータ、ライブラリ、API、データパイプラインなど、AIスタック全体の機密データを監視します
異常や潜在的なデータ漏洩をリアルタイムで検出
AIシステム特有のガードレールとセキュリティ制御を実装
AIアプリケーションの定期的な監査と評価の実施


Wizがお手伝いできること
Wizは、包括的なデータセキュリティポスチャー管理(DSPM)により、次の方法でデータ漏洩を防止および検出します。
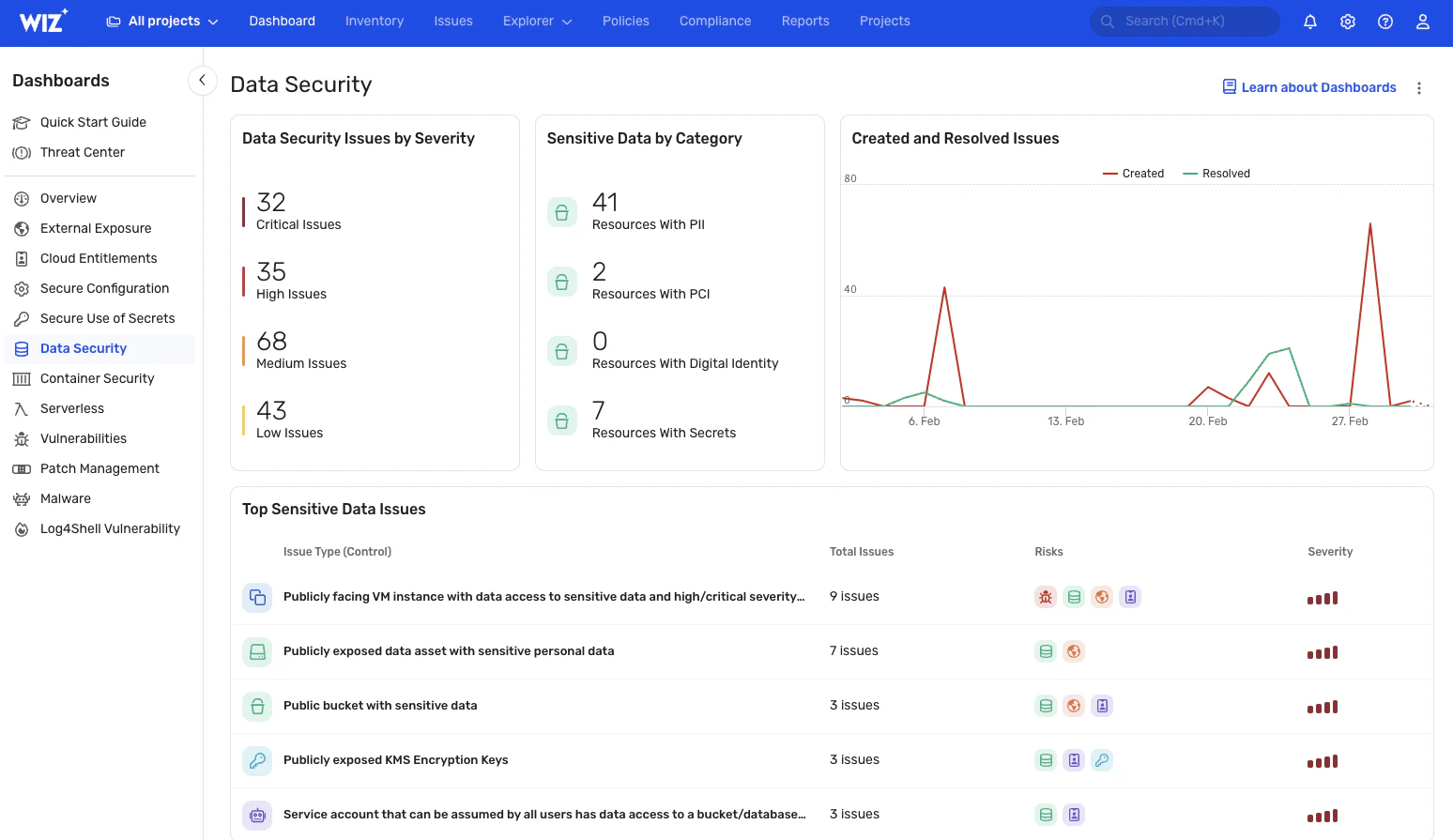
データを自動的に検出して分類
Wizは、重要なデータの露出を継続的に監視し、PII、PHI、PCIデータなどの機密情報をリアルタイムで可視化します。 これは、データがどこにあり、どのようにアクセスされているかについての最新のビューを提供します(AIシステムでも AI-SPMソリューション). また、カスタム分類子を作成して、ビジネスに固有の機密データを識別することもできます。 これらの機能により、セキュリティインシデントへの迅速な対応がさらに容易になり、損害を完全に回避したり、潜在的な爆発半径を大幅に最小化したりできます。
データリスク評価
Wizは、データ検出結果を脆弱性、設定ミス、ID、エクスポージャーと関連付けることで、攻撃経路を検出します。 その後、脅威アクターが悪用する前に、これらの露出経路をシャットダウンできます。 また、Wizは、エクスポージャーリスクの影響度と深刻度に基づいてリスクを視覚化し、優先順位を付けることで、最も重要な問題が最初に対処されるようにします。
さらに、Wizは、誰がどのデータにアクセスできるかを検出して表示することで、データガバナンスを支援します。
AIトレーニングデータのデータセキュリティ
Wizは、データ漏洩の可能性を含む、データ資産の完全なリスク評価をすぐに提供します DSPM AI コントロール。 当社のツールは、組織のデータセキュリティ体制の全体像を提供し、注意が必要な領域を強調表示し、セキュリティ対策を強化し、問題を迅速に修正するための詳細なガイダンスを提供します。
継続的なコンプライアンス評価
Wizの継続的なコンプライアンス評価により、お客様の組織を確保します'のセキュリティ体制は、業界標準や規制要件にリアルタイムで対応しています。 当社のプラットフォームは、設定ミスや脆弱性をスキャンし、修復のための実行可能な推奨事項を提供し、コンプライアンスレポートを自動化します。
で ウィズ DSPMの特徴と機能により、組織がデータ漏洩のリスクを軽減し、堅牢性を確保するのを効果的に支援できます データ保護 とコンプライアンス。 デモを予約する 今日はもっと学ぶために。
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
