



What is an incident response plan template?
An incident response plan template is a pre-structured document that gives organizations a standardized framework for how to detect, investigate, contain, and recover from cybersecurity incidents. Without one, teams improvise during a breach, and that improvisation is exactly what leads to missed evidence, slower containment, and a larger blast radius.
Think of it this way: a template is the skeleton. It gives you the phases, roles, escalation paths, and communication procedures you need. A finished incident response plan (IRP) is what you get after you customize that skeleton with your specific environment, tech stack, risk profile, and regulatory obligations. The template gives you structure; you fill in the specifics.
NIST SP 800-61 Revision 2 defined a four-phase incident response lifecycle: Preparation, Detection and Analysis, Containment/Eradication/Recovery, and Post-Incident Activity. That framework remains the most widely referenced foundation for IRP templates, though multiple alternatives exist, including SANS, CIS, and ISO 27035, each with a different focus.
An Actionable Incident Response Plan Template
A quickstart guide to creating a powerful incident response plan - designed specifically for organizations with cloud-based deployments.

Incident Response Plan Template [By Section]
To help you get started (or pressure-test what you already have), we've put together a Cloud Incident Response Plan Template that walks through the full lifecycle, from preparation and detection through containment, eradication, and post-incident review. It also includes response and prevention tactics for common attack scenarios like DoS attacks, man-in-the-middle exploits, and data breaches, along with a compliance matrix covering GDPR, HIPAA, SOX, and other key regulations.
Whether you're drafting your first plan or updating an existing one to better account for your cloud footprint, this template gives you a practical foundation to build on.
Table of Contents
1 Introduction
The introduction should run through the aims and objectives of the plan, explaining what it's for and the role it plays in relation to your incident response policy and playbooks.
As with your policy, it should state the roles of those who should read the document.
For example, your:
Incident response management team
Legal team
Communications team
Security operations team
BCDR team
At the same time, the introduction should also serve as a brief reminder about the responsibilities of key incident response personnel, as detailed in your incident response policy—in particular, those of the incident response manager.
1.1 Incident response playbooks
The introduction should lay down the foundations for creating your incident response playbooks. At the very least, it should state who'll be responsible for writing and maintaining them.
In a small organization, this may be just the one person. But in a large-scale enterprise, you'll likely need a team of professional technical writers.
In addition, you should set priorities for creating playbooks based on the risks associated with each type of event.
1.2 Shared responsibility model
If you host workloads in the public cloud, responsibility for compliance and security is shared between you, as the customer, and your cloud service provider (CSP). Each of the big three leading CSPs, Amazon Web Services (AWS), Microsoft Azure, and Google Cloud, has adopted a shared responsibility model to help customers understand the obligations of each party.
It's important your introduction draw attention to the model for a number of reasons. This is because, in potential cases where the fault lies with your CSP, your:
IT teams will still likely need to play a role in the response
Legal teams will need to understand the contractual implications of such an incident and how it would affect reporting requirements under data protection regulations and standards
Communications teams will still need to coordinate a response to ensure all affected parties are in the loop
2 Technical Response
2.1 Preparation
Preparation is integral to the success of your response to an attack and plays a key role in the incident response lifecycle. Your plan should therefore outline preparatory measures that will help reduce the impact of any breach.
For example:
Mechanisms that provide threat detection coverage based on workload (sensor-based) and control plane (log-based) data sources
Processes for rapid containment and quarantine of compromised entities, including virtual machines, identities, and cloud-native services such as object stores and managed databases
Implementation of an issue-tracking system for escalating cases and keeping track of progress
Contingency measures to minimize disruption to business operations
Incident response training
Incident response testing exercises
Security-aware architecture such as microsegmentation and secure access service edge (SASE)
Adoption of contemporary approaches to security, such as zero trust and the principle of least privilege (PoLP)
Cyber insurance cover
Furthermore, subsequent phases of the response lifecycle often require deep-root cause analysis using forensic data to understand how the assailant gained initial access and conducted the attack. Your plan should therefore include provisions to ensure that you capture this data to support timeline analysis after an incident.
This is particularly important in cloud environments, where forensic data is often stored in ephemeral resources. As a result, without careful planning, your organization could easily lose critical information. Tooling such as cloud detection and response (CDR) and cloud investigation and response automation (CIRA) can help meet such challenges.
Given the dynamic and complex nature of the cloud, under the requirements of your plan, you should maintain an up-to-date asset inventory. This will give you the visibility you need to manage an incident as quickly and efficiently as possible and with the minimum impact on your business.
It will help you determine:
Your most sensitive assets
Shared dependencies that may be infected
Potential avenues for the spread of an attack
The defense mechanisms you have in place
Priorities for recovery of systems
And don't forget that the cloud is distributed architecture, where your data may be located across different availability zones and regions. Your asset mapping exercise will therefore help you establish the geographical location of your assets and the territorial privacy laws that apply to your data accordingly. It will also give you a full picture of all your IT assets, helping to ensure none of them are overlooked when drawing up your list of preparatory requirements.
2.2 Detection
Your plan should cover the detection phase of the incident response lifecycle even if your security operations teams already have well-established detection procedures in place. This is because it presents the opportunity to determine whether the methods and tools they use are still up to the job and keeping pace with the latest threats.
There are a number of ways in which you can document the detection phase. For example, you could start by running through the different sources of information you use to identify potential security incidents. For example:
Workload telemetry
CSP telemetry
Third-party threat intelligence
Feedback from end users
Other parties in your software supply chain
Using these sources of information, you should document deeper layers of detection across:
Compute: Workload-level monitoring, leveraging endpoint detection and response (EDR) or lighter-weight workload sensors
Identity: Monitoring of behavioral patterns of specific identities, potentially leveraging identity threat detection and response (ITDR) tooling or monitoring of IdPs
Network: Monitoring for lateral movement at the network level, using intrusion prevention systems (IPS), intrusion detection systems (IDS), or VPC Flow Log analysis
Data: Monitoring for data exfiltration or suspicious data access, using data security posture management (DSPM), data detection and response (DDR), or data loss prevention (DLP)
Control: Monitoring for suspicious activity within the control plane, using cloud-native tooling like, for example, GuardDuty or Security Hub in AWS
And it also makes sense to map out the different signs associated with an attack, such as:
A high number of failed login attempts
Unusual service access requests
Privilege escalations
Blocked access to accounts or resources
Missing data assets
Slow running systems
A system crash
A sudden spike in cloud resource consumption
Furthermore, you should provide an outline as to how security teams piece together information to decide whether an event represents a real security incident or just legitimate network activity. Security information and event management (SIEM) tooling can provide this functionality in general, although it often requires considerable configuration and development work on the part of the security operations team to manage effectively. For organizations with substantial cloud footprints, specialized tooling such as CDR provides much of this functionality out-of-the-box.
2.3 Investigation
Once you've confirmed an attack is taking place, you'll then need to perform detailed analysis to determine the full nature of the incident.
Again, you should set out a structured approach by systematically running through the different types of analysis you'll need to perform. For example:
On a file: Such as examining changes to a tf.state file used for managing Terraform infrastructure as code (IaC)
On a specific storage location: Such as examining S3 data events to identify anomalous access to a bucket
On an individual cloud identity: Such as analyzing behavioral patterns of a specific AWS IAM user
As with the detection phase, you'll need to adopt a system for correlating event data from different log sources.
And, to help you further build up a profile of each incident, your plan should incorporate a two-tier incident classification framework. The role of each tier should be as follows:
First tier: Information recorded during the analysis phase for use in setting priorities for incident management.
Second tier: Information recorded throughout the incident response lifecycle for use in your post-incident review and making improvements in the future.
Incident Classification Framework (First Tier)
| Category | Attack Vector | Severity of Impact |
|---|---|---|
| Denial of Service | Compromised Credentials | Low |
| Unauthorized access | Code Exploit | High |
| Malware | Malicious code | High |
| Human error | Supply-chain compromise | Critical |
Category of IncidentAttack VectorSeverity of ImpactDenial of serviceCompromised credentialsLowUnauthorized accessCode exploitModerateMalwareMalicious codeHighHuman errorSupply-chain compromiseCritical
To determine the severity of impact, you'll need to consider a range of factors, such as:
The threat to safety
The threat to sensitive data
The amount of data affected
Whether you can implement any temporary workarounds or fallback measures
The number of services affected
Whether those services are mission critical
Regulatory compliance implications
During the analysis phase, you should also build up information about the attacker. For example, by establishing the IP address, email address, and domain names associated with the attack and researching incident databases. Such details may be needed as evidence in any legal proceedings that might follow. So it makes sense to provide for a hashing mechanism as a way to substantiate the integrity of your information.
And, finally, you should mandate the creation of snapshots of any storage volumes affected to allow for subsequent analysis by forensic tooling.
2.4 Escalation
Escalation procedures should provide incident handlers with the information they need to route cases to the right people. This will help reduce disruption by avoiding delays caused by assignments bouncing at random between teams until someone finally takes ownership.
When defining escalation paths, you should consider:
The type and severity of the incident
The systems affected
The specific technical knowledge of assignees
Experience level and roles and responsibilities
Lines of command and overall responsibility for incident management
Availability of on-call personnel
Who else needs to be kept in the loop
During the course of the response, new information may come to light, such as a change in scope of the incident, which necessitates further escalation. You should therefore cater for these circumstances by providing similar such guidance. However, this may be better suited for inclusion in individual incident response playbooks.
2.5 Containment
The next part of your plan should offer direction on how to contain an attack and limit the impact on your IT systems and business operations. These steps can help buy time in circumstances where you're not yet in a position to take appropriate remediation action.
Different types of attack necessitate different types of containment approaches. For example, in the case of a denial-of-service (DoS) attack, the containment phase would focus on network measures, such as IP address filtering. By contrast, in many other cases, you'll need to isolate resources to prevent lateral movement of the attack.
The method you use will also vary based on the resources involved in the attack. For example, in traditional environments, EDR can quickly isolate a compromised machine from the network. By contrast, in cloud environments, often the most efficient way to isolate it is by changing the security group settings through the control plane.
Your plan will therefore serve mainly as a reference point to different playbooks, each with their own containment strategy accordingly.
Bear in mind that security operations teams will be under intense pressure to remove the threat from your systems as quickly as possible, and that tools such as security orchestration, automation, and response (SOAR) can help to manage the containment process.
By contrast with SIEM, which is geared towards data aggregation and event alerting, SOAR focuses more on orchestrating the incident response process. Most importantly, it allows you to create playbooks that automate the complex series of tasks that are often involved in a remediation exercise.
Any containment strategy should give due attention to wider operational factors, such as the:
Time and resources needed for containment vs those for full remediation
Effectiveness of the containment method
Impact on service availability
In addition, you should adapt your containment strategy to the distributed nature of the cloud. For example, your applications may be replicated across availability zones or cloud regions. You may then be able to failover to a secondary standby deployment while you deal with the breach within the primary environment. However, you also need to be aware of the potential for the attack to spread to the failover environment.
And, finally, your plan should advise against simply containing or remediating the threat by blind deletion, as this would leave you without the footprint left behind by the attack for post-incident analysis.
2.6 Eradication
Once the threat has been contained, the work of eradication can begin. Eradication is the complete removal of the threat so that it's no longer present anywhere within your organization's network. This may also necessitate disruption to services. So you should include provision for notifying any users that may be affected.
In some cases, it may be necessary to manually remove the threat. Whatever the case, you'll need to cover the various options for eradication, such as:
Restoring files to their pre-infection state
Changing passwords
Reinstalling applications
Blocking points of entry
Updating IaC templates
Patching vulnerabilities
3 Communications
You should drill your PR and social media teams, company bloggers and trained spokespeople about preparations for a communications response in the event of an incident. A cybersecurity breach is a highly technical affair. So it's important communications teams have sufficient technical understanding to get the right messages to the right people. This can go a long way towards maintaining the trust and loyalty of staff, customers, and the wider public.
You should remind them to maintain:
An up-to-date list of all those that will need to be informed
Contact details for the appropriate press
Template statements for different types of incident
Information for use by customer support teams when dealing with the public
Any messages should be checked beforehand by legal and technical teams to prevent misinformation. And you should also call for a periodic review of communications procedures just as with other parts of the incident response process.
Furthermore, you should inform your CSP about the incident, providing detailed information about the attack. This can benefit both parties in your mutual efforts to combat the same threats. It can also help other customers using the CSP's services, as adversaries are likely to target other deployments on the platform using the same attack vector. You'll therefore need to document agreed points of contact and methods of communication. And bear in mind that communications teams should expect to liaise with your CSP even where a security breach lies within the provider's remit under the shared responsibility model.
4 Legal
Where the incident involves the exposure of personal data, the most immediate concern for your legal team is to report the breach under the requirements of data protection laws that apply to your organization.
However, unlike the traditional model of IT, where you host your data in a centralized data center, your public cloud workloads may be distributed across a number of geographical locations, each of which may come within the scope of different territorial regulations.
Your plan should therefore include a compliance matrix to help legal teams quickly and efficiently determine which laws apply to the data affected. This is particularly important given that they'll need to report the breach as quickly as possible—usually within strict regulatory timescales.
Your matrix should include the:
Territorial scope of each regulation
Types of data each law covers
Company deployments that process and store such data
Contact details for reporting a breach
Information you'll need to provide in your report
On similar lines, you should implement plans for potential violations of any contractual obligations as a result of an incident. For example, where a contract enforces compliance with the Payment Card Industry Data Security Standard (PCI DSS).
Finally, you may need to cooperate with other external parties, such as companies involved in any software supply chain. You'll therefore need to document similar arrangements and, in conjunction with the legal team, formalize non-disclosure agreements as necessary.
5 Business Continuity and Disaster Recovery (BCDR)
Data is the life force of any modern business. So your IT systems need to resume normal operation as quickly as possible following a security incident—with the minimum loss of data and impact to your business.
That's why BCDR plays such an important role in an incident response strategy. The two should work in harmony with one another to ensure you have a well-organized, efficient and synchronized response. This should be reflected in your plan by:
Outlining procedures for coordinating incident response and BCDR teams
Integrating common elements of incident response and BCDR, such as processes, roles, and responsibilities
Including detailed guidance about when to trigger BCDR responses depending on the stage you're at in the incident response process
The BCDR section of the plan should give due consideration to:
The security of any failover system
Backup hygiene practices to prevent infection
Recovery priorities
System dependencies
Business expectations about recovery based on the recovery time objectives (RTOs) and recovery point objectives (RPOs)
6 Attack Scenarios
The following is a sample selection of attack scenarios that you should plan for in your incident response strategy. It is far from a comprehensive list, but should provide sufficient guidance for devising your own roadmap for dealing with specific types of incident. You can also use it as a starting point for setting out the detailed steps you'll need to provide in your individual playbooks.
As part of the response process, you may need to implement additional preventative measures to avoid falling victim to the same or similar types of attack in the future. For that reason, we've also included a series of prevention tactics for each attack scenario.
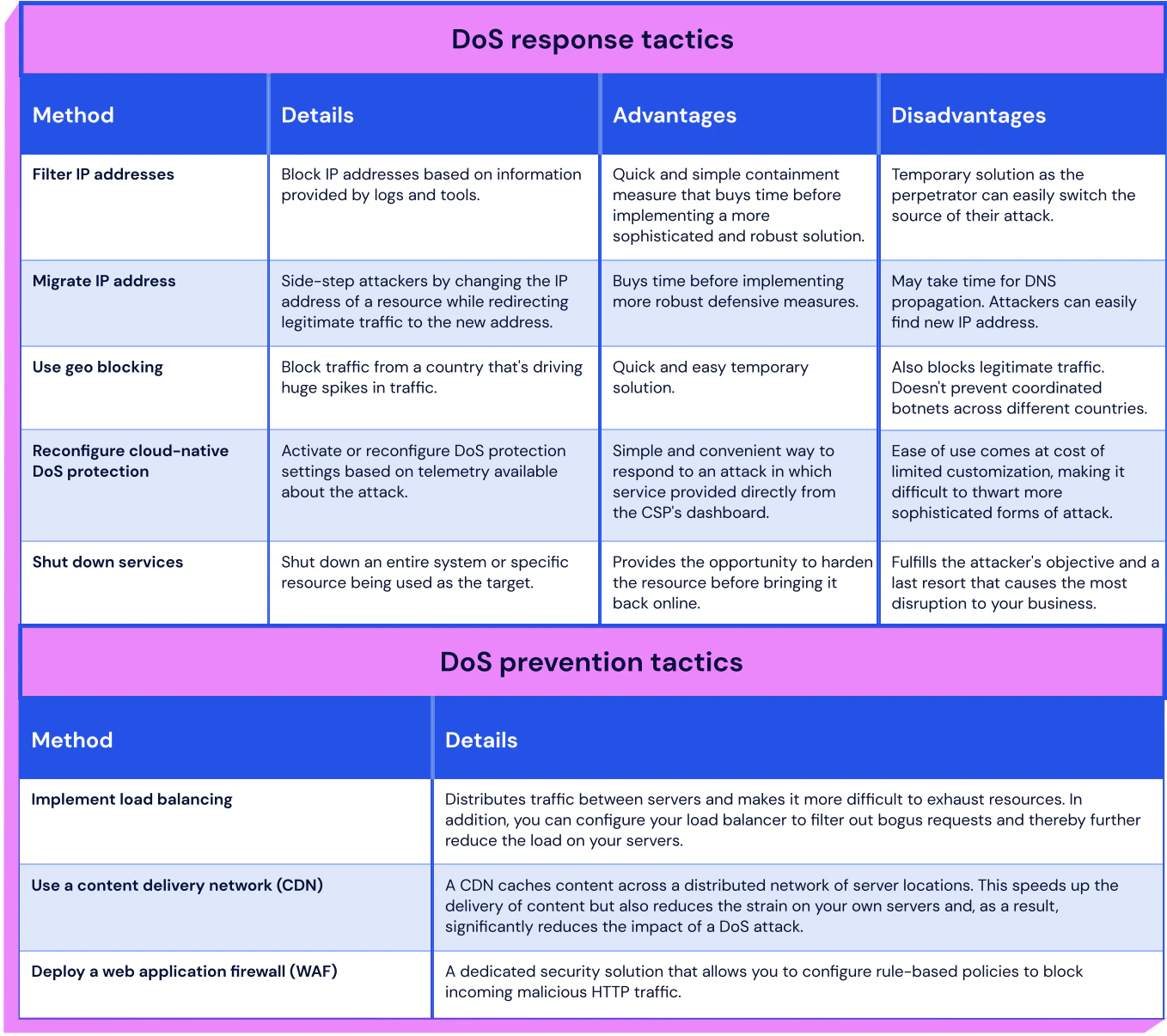
6.1 DoS Attack
Description: An attack method that overwhelms a service with bogus requests, making it unavailable to legitimate users.
Likelihood: High
Impact: High
DoS Response Tactics
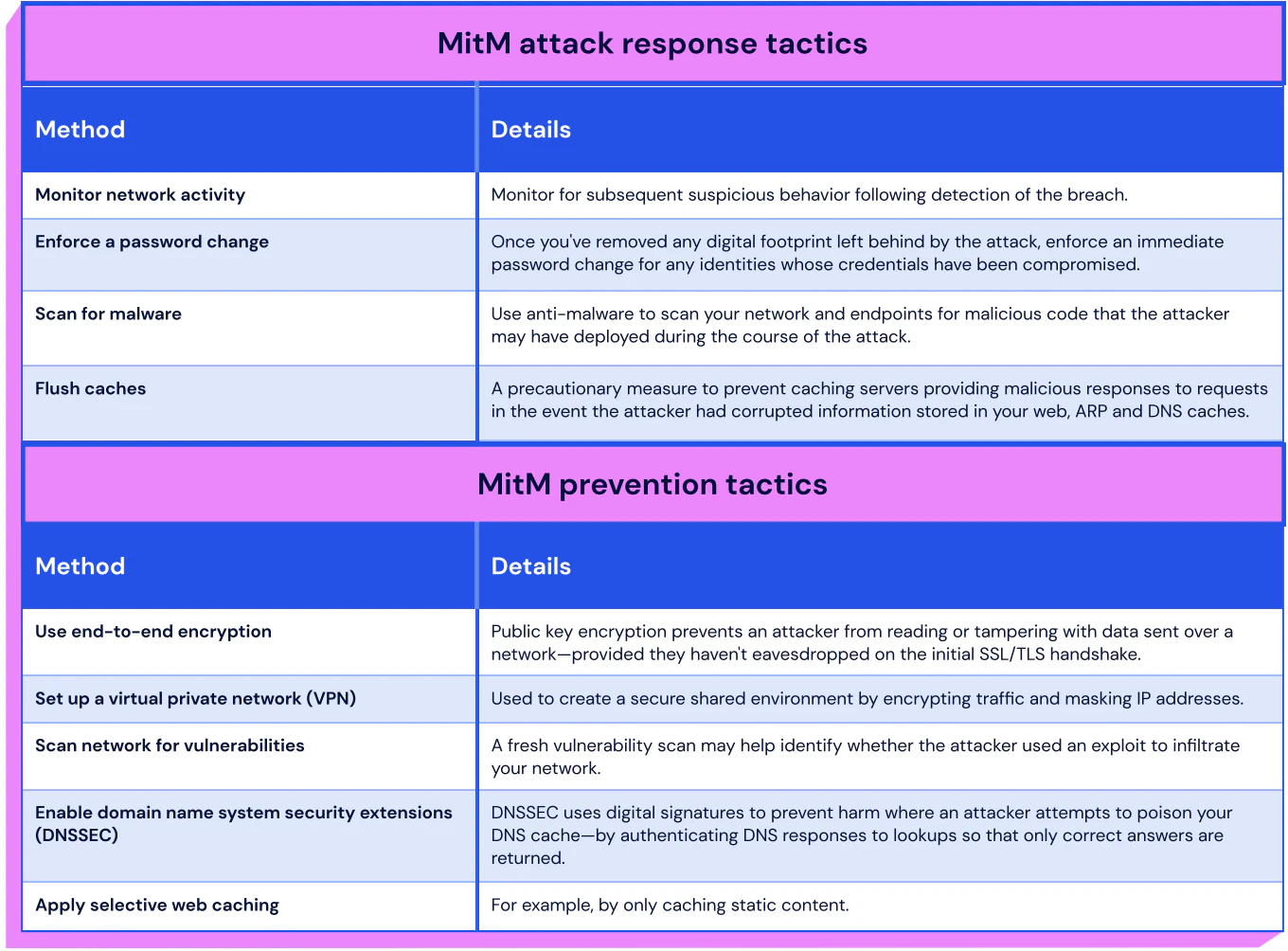
6.2 Man-in-the-Middle (MitM) Attack
Description: An attack in which a hostile actor covertly intercepts the data exchange between two parties and manipulates the communication between them.
Likelihood: Medium
Impact: High
MitM Attack Response Tactics
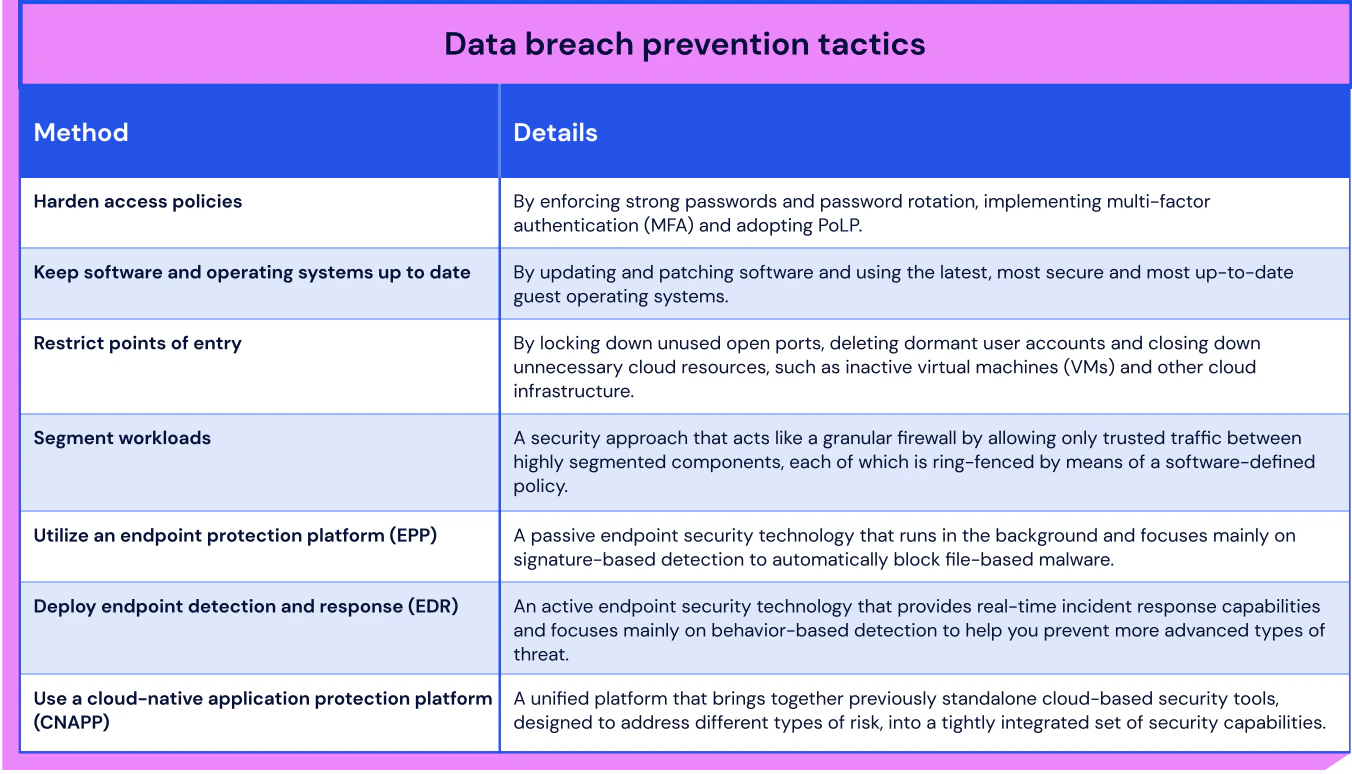
6.3 Data Breach
Description: A specific type of security breach whereby an unauthorized party has gained access to sensitive or confidential data.
Likelihood: High
Impact: High
Data Breach Response Tactics
7 Post-Incident Review
Finally, you should detail arrangements for performing a post-incident review. This will help you refine your plan so you're better equipped to handle incidents in the future. It should:
Cover a technical analysis of the attack
Look at the way in which you responded to the incident
Evaluate feedback from the incident response team
Assess the impact on your business operations
You should set a deadline by which you should commence the review process, making the point that you should do this as soon as possible. You should also document your findings in a formal incident report.
7.1 Incident Classification Framework
The review is an opportunity to not only learn from the incident but also identify any patterns or trends that may be developing over time, as these could equally highlight further areas for improvement.
This is where your incident classification framework can prove invaluable, as it offers a structured way of recording information, thereby making it simpler and more convenient to analyze and spot any emerging picture.
Incident Classification Framework (Second Tier)
Root Cause of Incident: Unauthorized activity, User negligence, Third-party negligence, Policy violation, Misconfiguration, Exploit of vulnerability, Theft of hardware, Non-compliance with regulatory or industry framework, Social engineering
Early Indicators of Attack: Slow-running VMs, Deviations from normal network behavior, Announcement of new vulnerability, Announcement of new exploit
Means of Detection: Security monitoring tool, End user, Third-party service provider, Law enforcement agency
Data Exposed: Personal data, Login credentials, Intellectual property, Trade secrets, Classified information, Financial information, Unknown
Tools Used to Manage Incident: SIEM, SOAR, Cloud detection and response (CDR), XDR, Risk-based vulnerability management (RBVM) platform
Nature of Threat: Insider, Targeted, Opportunistic, Reconnaissance, Espionage
Actor's Intent: Accidental, Malicious, Financially motivated, Political, Narcissistic
Response Performance Metrics: Time taken to detect, Time taken to contain, Time taken to recover
Consequences of Attack: Loss of productivity, Loss of revenue, Financial penalty, Legal action, Harm to individuals, Reputational damage
7.2 Questionnaire
Your plan should include a questionnaire to help you get the best possible outcome from the review process. The following is a list of questions you should consider when conducting your review and updating your plan:
Was the information in our plan and playbooks sufficiently clear?
Was any of the information inaccurate?
Was any information omitted?
How long did it take to complete different tasks?
Are there any new mitigation steps or configurations we'll need to implement to prevent similar incidents in future?
Were there any gaps in our security tooling?
Did we make any mistakes that delayed recovery?
Did members of the incident response team understand their roles and responsibilities?
Did we escalate the incident to the right people and in a timely manner?
Did the attack reveal any violation of compliance requirements?
Are there any other ways in which we can improve the response process?
7.3 Periodic Reviews and Revisions
You should add new detail to your plan and playbooks whenever you:
Release new applications
Make significant changes to existing ones
Migrate deployments to new types of infrastructure
Make organizational changes that could affect the way you handle incidents
And, finally, don't forget to keep track of new threats and adapt your cybersecurity defenses and incident response documentation accordingly.
An Actionable Incident Response Plan Template
A quickstart guide to creating a powerful incident response plan - designed specifically for organizations with cloud-based deployments.