

What is AI agent security?
AI agent security is the practice of keeping autonomous AI systems safe, predictable, and controlled when they take actions on real systems. Agents can call tools, APIs, and workflows, so a single decision can change data or trigger operations in your environment.
An AI agent uses a model to reason about a task, then plans steps and executes them: for example, reading logs, calling a cloud API, updating a record, and sending a message – all without a human running each command.
In cloud environments, agents run inside containers, serverless functions, or workflow engines, and they use service accounts, API keys, and cloud roles to access resources. That makes each agent a non-human identity with real permissions.
AI agent security is about defining what an agent is allowed to do, limiting the systems it can reach, and validating its actions end-to-end so it stays within intended behavior.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Why AI agents create a new attack surface
AI agents introduce a different kind of risk than traditional AI models because they take actions. When an agent can call tools, trigger workflows, or use cloud APIs, any manipulation of its reasoning can turn into real changes in your environment, not just a misleading response.
Several properties make the attack surface larger:
Actions, not answers: a prompt injection no longer changes text – it can change state.
Live system access: agents operate with credentials and roles, so their decisions run with real permissions.
Tool and API chaining: a single request may trigger multiple steps the agent chooses on its own.
External influence: agents can be steered through data they read, not just direct prompts.
Persistent state: memory and context can store instructions that shape future behavior.
Supply chain exposure: frameworks, plugins, and retrieval systems introduce new dependencies.
The result is that the key security question shifts from:
“Can someone influence the model?” to “If they do, what can the agent reach or change?”
That shift – from text generation to execution with access –is what makes AI agent security a distinct discipline from traditional model security.
Threat categories mapped to risk
Most AI agent incidents fall into a small set of repeatable patterns. These risks matter because they turn influence of the model’s reasoning into unintended actions with real permissions.
1. Unauthorized actions through agent logic
Small manipulations in input or context can push an agent into taking steps outside its intended scope. This may look like:
triggering a workflow early,
running destructive API calls,
or chaining tools in ways the designer didn’t anticipate.
This is business logic exploitation, not a traditional code vulnerability.
2. Identity misuse and privilege escalation
Agents often run with broad permissions for convenience. If an attacker influences the agent’s decision-making, they gain control over those privileges. A compromised agent identity can:
assume roles,
modify resources,
or provision new access paths.
In cloud environments, this can escalate into a full account compromise.
3. Data exposure through unbounded retrieval
Agents abstract access to data behind tools. With the right input, an agent can be convinced to:
reveal sensitive data from a store,
aggregate private records,
or export information to an external location.
This is data exfiltration through automation, not a direct database exploit.
4. Business logic bypass and silent failures
Agents embed business logic in prompts, policies, and tool definitions. If guardrails are incomplete, attackers can:
bypass approval gates,
trigger actions without validation,
or hide unsafe steps inside long tool chains.
These failures often don’t produce logs that look “malicious”, making them harder to detect.
5. Supply chain risk through agent tools and plugins
Agents depend on frameworks, plugins, retrievers, and embedding models. If any component is compromised, the agent will:
trust the output,
act on tampered context,
or fetch malicious data.
This creates supply chain risk at the tool layer, not just the code layer.
6. Model-level abuse that leads to unsafe actions
Prompt or indirect prompt injection isn’t just about getting a strange answer – it can cause unintended state changes. An attack might:
plant hidden instructions in retrieved content,
reframe the task the agent thinks it’s solving,
or create logic loops that trigger tool usage.
This turns manipulation of the model into manipulation of systems.
These categories all share a pattern:
the model can be influenced,
the agent has access,
and tools execute the result.
That’s what creates an attack path. Understanding these patterns helps you design controls that limit what an agent can reach and validate what it does, rather than trying to prevent every possible instruction.
GenAI Security Best Practices [Cheat Sheet]
This cheat sheet provides a practical overview of the 7 best practices you can adopt to start fortifying your organization’s GenAI security posture. Inside you’ll find:

Identity and access management for AI agents
The most effective way to control an AI agent is to control its identity. If the agent doesn’t have a permission, it can’t use that permission – even if its reasoning is influenced.
Treat every agent as a first-class non-human identity with its own scoped access, rather than sharing keys or letting it inherit broad roles from a service or user account.
A secure IAM pattern for agents includes:
Separate identities: each agent uses its own role or service account, never a shared credential.
Least privilege: attach only the permissions needed for the agent’s tasks, not full access to a resource or account.
Short-lived credentials: use temporary tokens and automatic rotation so access expires quickly.
No secrets in code: credentials live in a secret manager, not in prompts, environment variables, or config files.
In cloud environments, this typically means using native identity primitives:
AWS: IAM roles with STS temporary credentials
Azure: Managed Identities
GCP: Service Accounts with Workload Identity
Kubernetes: Service Accounts with RBAC and cloud federation (e.g., IRSA)
Permissions should be reviewed regularly. Ask simple questions:
Which agent identities have admin-level rights?
Which permissions are unused and can be removed?
Can this agent reach sensitive data or powerful APIs?
By limiting what agents can access – and ensuring each has a dedicated identity – you reduce the blast radius of any mistake or manipulation. Agent security starts with what the agent can do, not just how the model behaves.
Best Practices for AI Agent Security
Security for AI agents scales when it follows cloud-native principles rather than creating a parallel “AI security stack.” The most reliable approach is phased: gain visibility, eliminate high-impact attack paths, defend continuously at runtime, and improve posture over time. Each phase builds on the last and uses context from your environment to prioritize work where it matters.
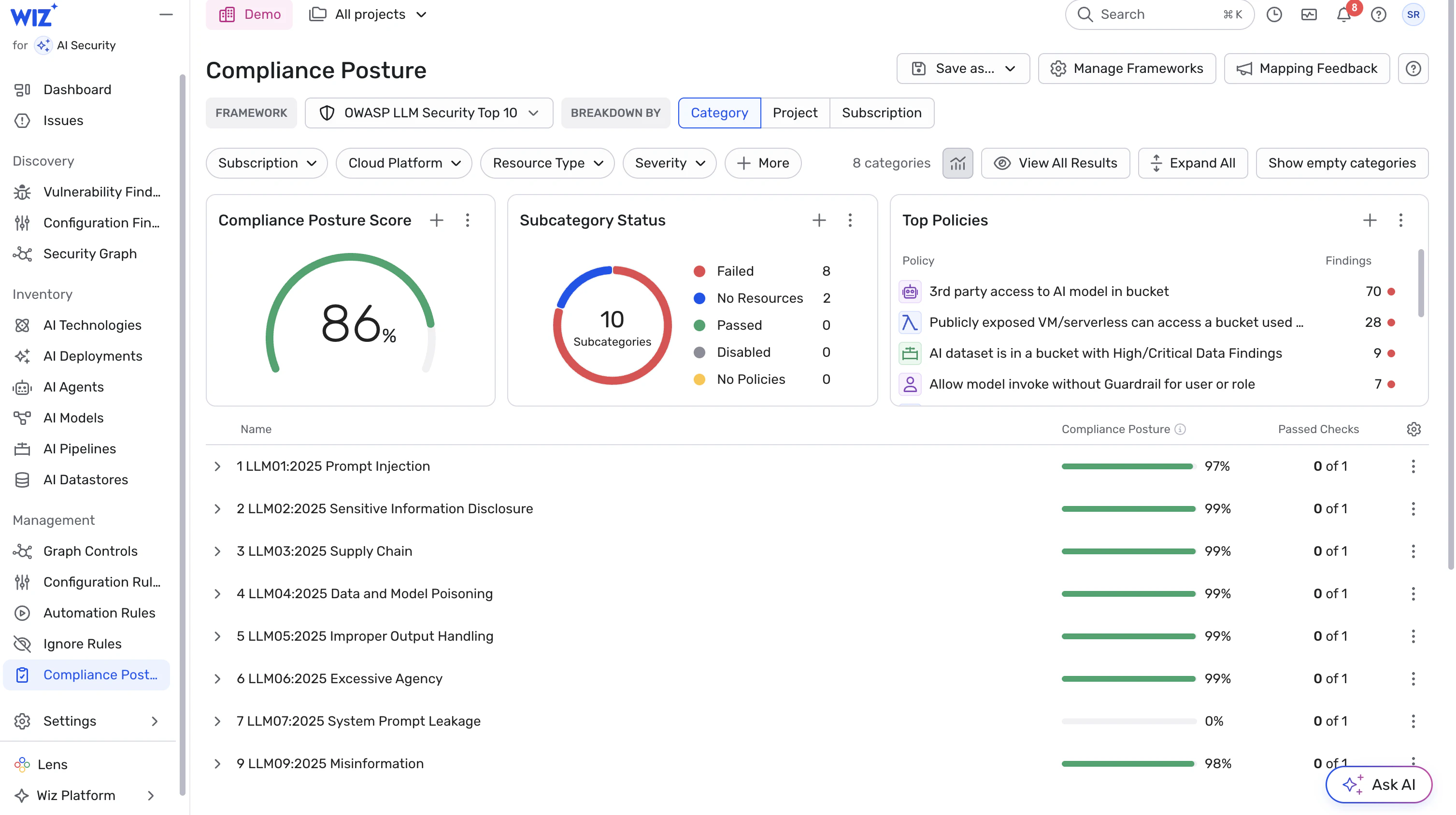
1. Start with visibility: inventory all AI agents & workloads
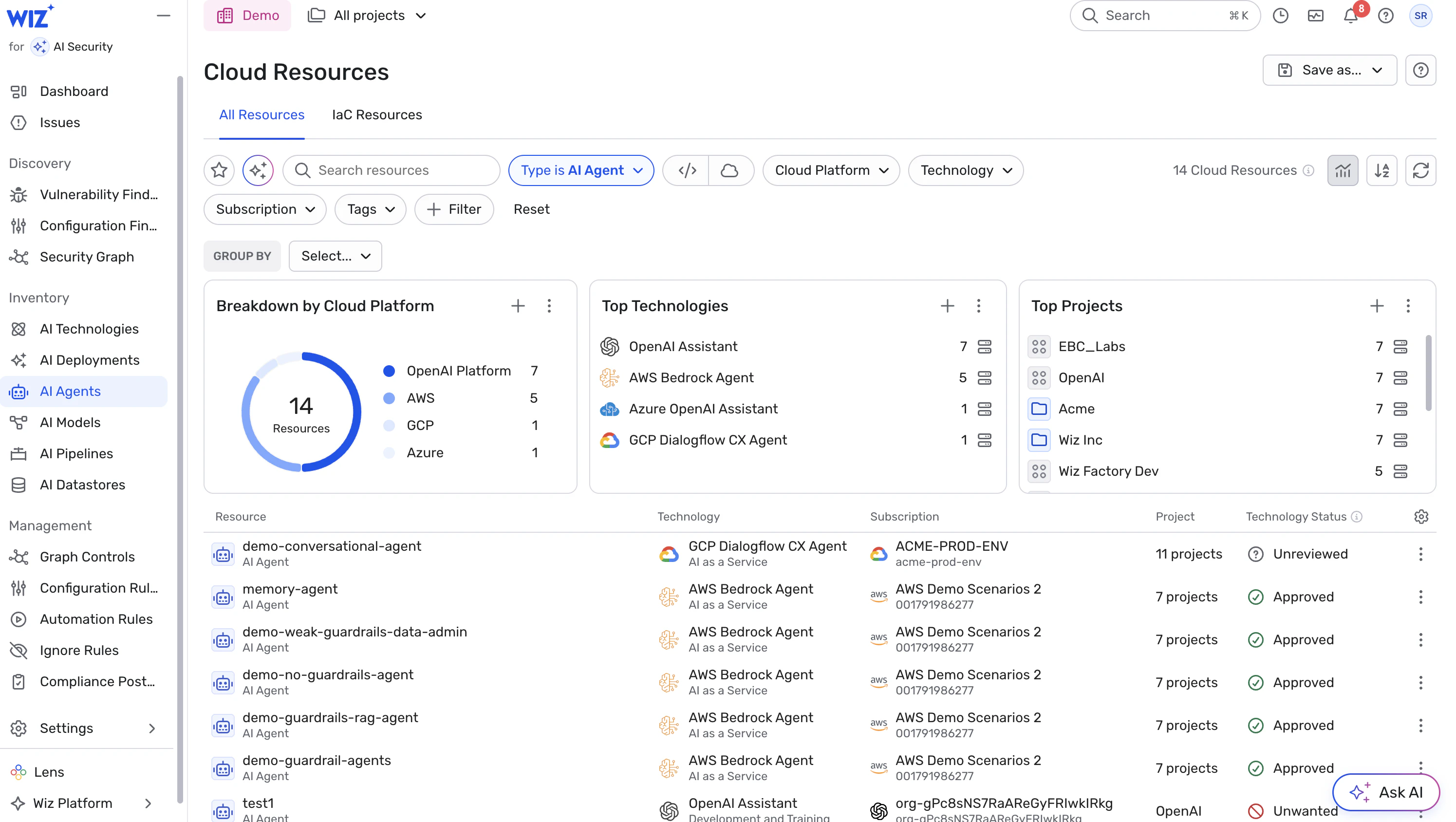
Maintain an up-to-date inventory of all AI-related workloads — agents, inference endpoints, data-processing flows, etc. — including dependencies (models, SDKs, libraries, retrievers, data stores).
Ensure every agent’s identity, permissions, and associated resources are tracked centrally.
Treat undiscovered or ad-hoc agents as high-risk: unknown identity + unknown permissions = high uncertainty.
2. Apply context-aware risk prioritization, not blanket rules
For each agent, evaluate risk based on what it can access (data stores, secrets, APIs) and how it can act (network exposure, cloud roles, external interfaces).
Prioritize remediation for agents with high access + high reach, especially those combining external exposure and sensitive data access.
Focus on attack-path elimination: fix the combination of permissions, access paths, identity scope — not just isolated misconfigurations.
3. Enforce secure configurations & guardrails by default
Use baseline configuration templates (IaC or policy-as-code) for agent deployment, with conservative defaults: minimal permissions, no unnecessary network exposure, restricted tool scopes.
Validate all AI-specific settings (e.g. model permissions, input/output sanitization, network policies) before deploying agents or inference endpoints.
Reject changes that open up explosive combinations (e.g. agent with internet exposure + write access to sensitive data stores).
4. Monitor runtime behavior and detect drift or misuse
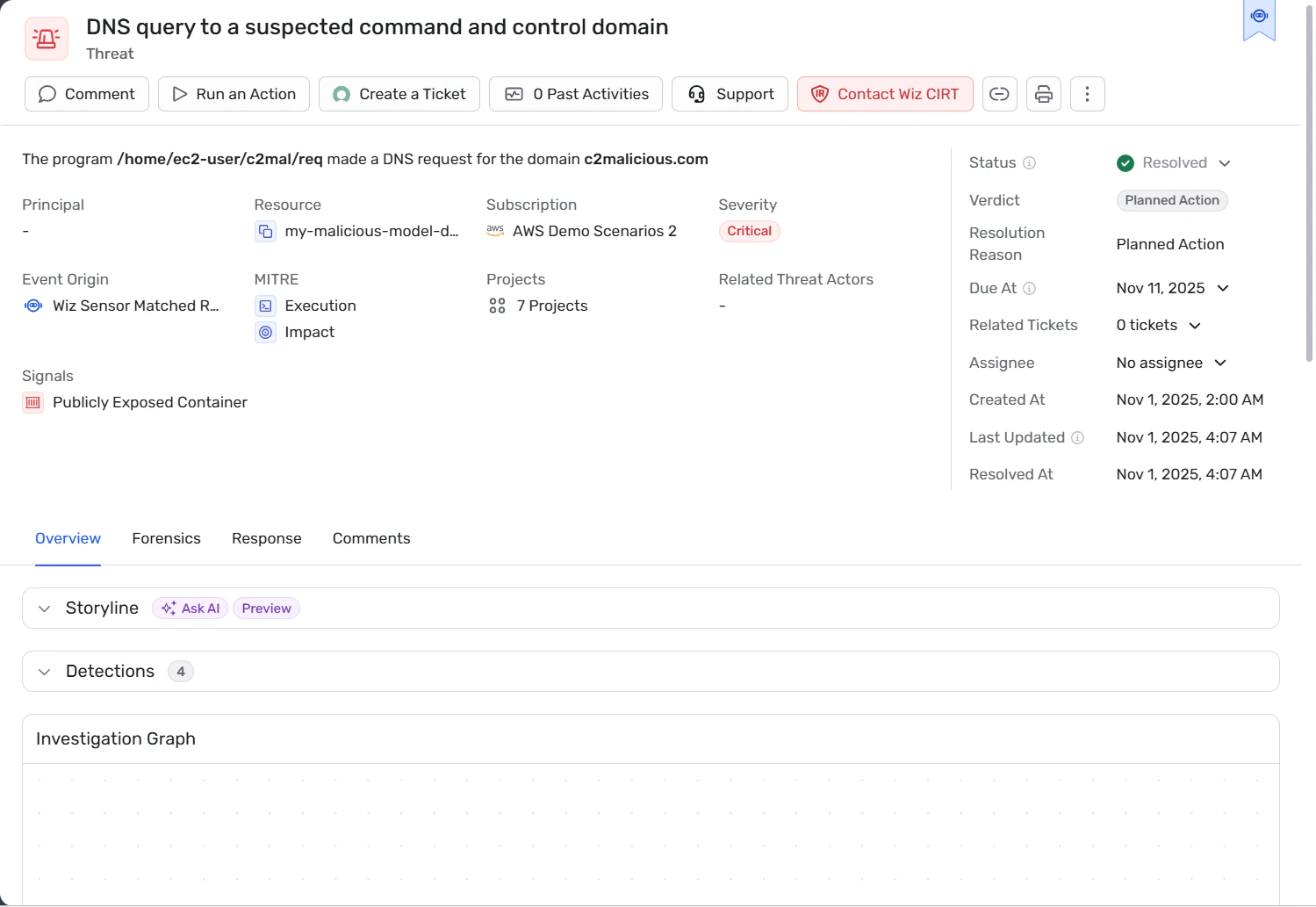
Log agent activity: tool calls, API interactions, data accesses, network outbound calls — capturing enough context (identity, resource, data sensitivity) to reconstruct what happened.
Establish a behavioral baseline per agent or agent category. Alert on deviations such as unusual API calls, unexpected data access patterns, or network egress to external destinations.
Combine runtime signals with identity and environment context to detect real exploitation attempts, not just anomalous events.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

How Wiz helps secure AI agents
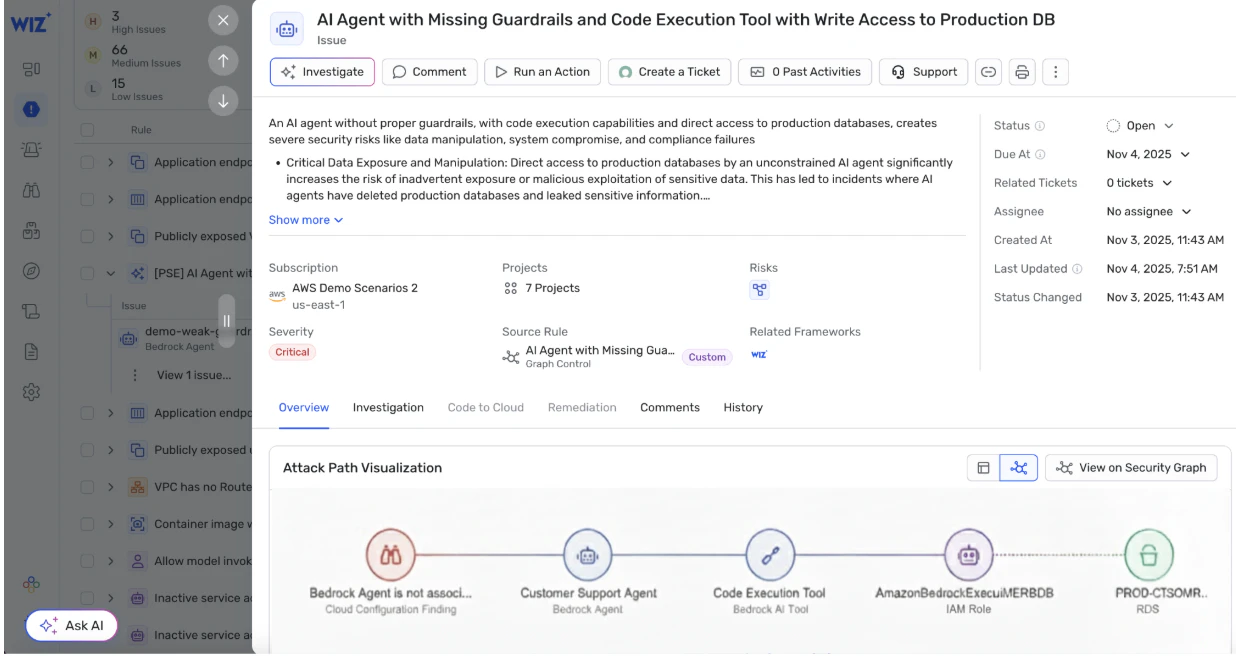
Wiz approaches AI agent security as an extension of your cloud attack surface, not a separate technology stack. As part of the Wiz AI-Application Protection Platform (AI-APP), agents, the identities they use, the data they can reach, and the workloads they run on are mapped into the Wiz Security Graph alongside code and cloud context, so you can see where an agent’s access could turn a prompt manipulation into a real attack path.
This unified view highlights toxic combinations that matter in practice – for example, an internet-reachable agent runtime with broad access to a sensitive datastore, or an operations agent that can modify CI/CD pipelines and read production secrets. Instead of chasing isolated findings, Wiz helps teams break the whole path, with direct ownership context so the right team can remediate the risk at the source.
To stop misconfigurations from returning, Wiz maps agent identities and permissions back to the code and IaC that defined them so you fix the template, not just the running instance.
As part of this model, Wiz applies AI Security Posture Management (AI-SPM) across the AI resources in your cloud. Wiz detects AI misconfigurations in inference endpoints, agent runtimes, and agent orchestration flows, including deployments without guardrails, unsafe tool scopes, or excessive access to sensitive data. These findings are surfaced in graph context, so you can see how misconfigurations combine with identity and network reach to create real exploitation paths – not just configuration drift.
For teams that want to move from visibility to action, AI-Powered Wiz extends this model with purpose-built agents grounded in the same graph context. Red Agent helps validate exploitable risk in AI applications and APIs, Blue Agent investigates suspicious runtime activity, and Green Agent helps drive remediation back to the right code, identity, or configuration, while workflows let teams keep human approval where it matters.
Discover where AI agents create real risk in your environment – and how to break the attack paths behind them. Request a demo
Develop AI Applications Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
