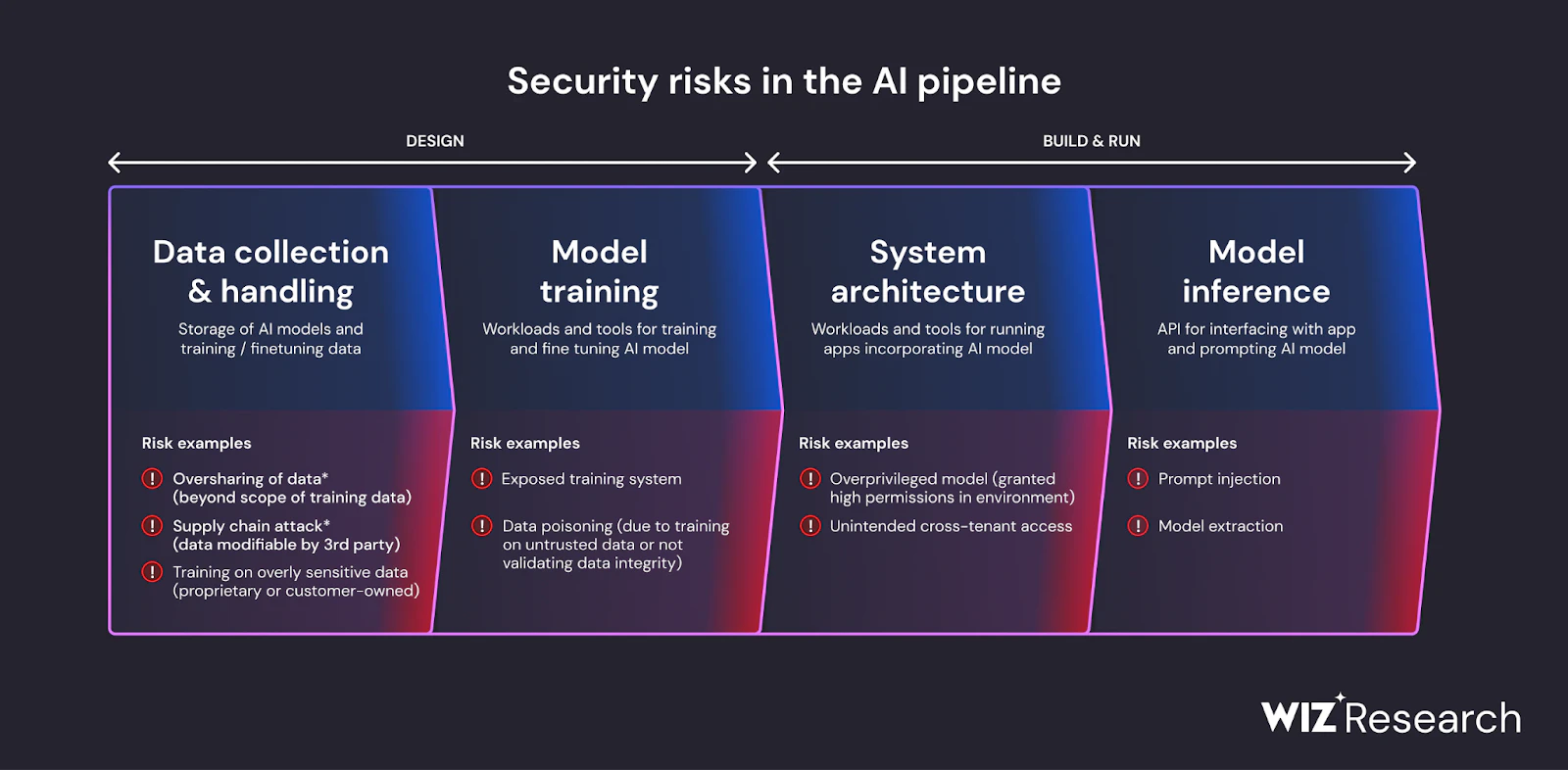
Che cos'è il LLM Jacking?
Il jacking LLM è una tecnica di attacco che i criminali informatici utilizzano per manipolare e sfruttare gli LLM (Large Language Models) basati su cloud di un'azienda. Il jacking LLM comporta il furto e la vendita delle credenziali dell'account cloud per consentire l'accesso dannoso agli LLM di un'azienda, mentre la vittima copre inconsapevolmente i costi di consumo.
Nostro ricerca mostra che 7 aziende su 10 sfruttano i servizi di intelligenza artificiale (AI), comprese le offerte di intelligenza artificiale generativa (GenAI) di fornitori di cloud tra cui Amazon Bedrock e Creatore di salvi, Google Vertex AI e Azure OpenAI Service. Questi servizi forniscono agli sviluppatori l'accesso a modelli LLM come Claude, Jurassic-2, la serie GPT, DALL-E, OpenAI Codex, Amazon Titan e Stable Diffusion. Vendendo l'accesso ai modelli LLM, i criminali informatici possono avviare un dannoso effetto domino su più pilastri organizzativi.
Sebbene gli attori delle minacce possano condurre attacchi di jacking LLM per rubare i dati da soli, spesso vendono l'accesso LLM a una rete più ampia di criminali informatici. Questo è ancora più pericoloso perché estende la portata e la portata dei potenziali attacchi. Dirottando gli LLM di un'azienda, qualsiasi criminale informatico che acquista credenziali LLM basate su cloud può orchestrare attacchi unici.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

Quali sono le potenziali conseguenze di un attacco di jacking LLM?
Aumento dei costi di consumo
Quando i criminali informatici conducono attacchi di jacking LLM, i costi di consumo eccessivi sono la prima ripercussione. Questo perché i servizi GenAI e LLM basati su cloud, per quanto vantaggiosi, possono essere piuttosto costosi da ospitare per le aziende. Pertanto, quando gli avversari vendono l'accesso a questi servizi e consentono un utilizzo nascosto e dannoso, i costi possono aumentare. Secondo Ricercatori, gli attacchi di jacking LLM possono comportare costi di consumo fino a $ 46.000 al giorno. Questo importo può variare a seconda dei modelli di prezzo LLM.
Militarizzazione degli LLM aziendali
Se i modelli LLM di un'azienda mancano di integrità o non sono dotati di robusti guardrail, possono generare output dannosi. Dirottando i modelli LLM specifici dell'organizzazione o il reverse engineering delle architetture LLM, gli avversari possono utilizzare l'ecosistema GenAI di un'azienda come arma per attacchi e attività dannose. Ad esempio, manipolando gli LLM aziendali, gli attori delle minacce possono fare in modo che generino output falsi o dannosi sia per i casi d'uso back-end che per quelli rivolti ai clienti. Le aziende possono impiegare un po' di tempo per identificare questo tipo di dirottamento, e a quel punto il danno è spesso fatto.
Esacerbazione delle vulnerabilità LLM esistenti
L'adozione di LLM presenta sfide intrinseche alla sicurezza. Secondo OWASP, le prime 10 vulnerabilità LLM includono l'iniezione tempestiva, l'avvelenamento dei dati di addestramento, il denial of service del modello, la divulgazione di informazioni sensibili, l'eccessiva agenzia, l'eccessivo affidamento e il furto di modelli. Quando i criminali informatici utilizzano attacchi di jacking LLM, esacerbano in modo significativo i rischi e le vulnerabilità intrinseche associati agli LLM.
Effetto nevicate di alto livello
Considerando la rapidità con cui le aziende stanno incorporando GenAI e LLM in contesti mission-critical, gli attacchi di jacking LLM possono avere gravi implicazioni di alto livello e a lungo termine. Ad esempio, il jacking LLM può espandere la superficie di attacco di un'azienda, con conseguenti violazioni dei dati e altri importanti exploit.
Inoltre, poiché la competenza nell'intelligenza artificiale è una metrica reputazionale fondamentale per le aziende di oggi, gli attacchi di jacking LLM possono causare una perdita di fiducia e rispetto da parte dei colleghi e del pubblico. Non dimenticate le devastanti ricadute finanziarie del jacking LLM, che includono margini di profitto inferiori, perdita di dati, costi di inattività e spese legali.
Come funzionano gli attacchi di jacking LLM?
In linea di principio, il jacking LLM è simile ad attacchi come Cryptojacking, in cui gli attori delle minacce estraggono segretamente criptovalute utilizzando la potenza di elaborazione di un'azienda. In entrambi i casi, gli attori delle minacce utilizzano le risorse e l'infrastruttura di un'organizzazione contro di loro. Tuttavia, con gli attacchi di jacking LLM, il mirino dell'hacker è saldamente sui servizi LLM ospitati nel cloud e sui proprietari di account cloud.
Per capire come funziona il jacking LLM, diamo un'occhiata da due prospettive. Innanzitutto, esploreremo il modo in cui le aziende utilizzano gli LLM, quindi passeremo a come gli attori delle minacce li sfruttano.
In che modo le aziende interagiscono con i servizi LLM ospitati nel cloud?
La maggior parte dei fornitori di cloud fornisce alle aziende un'interfaccia facile da usare e funzioni semplici progettate per un'adozione agile dell'LLM. Tuttavia, questi modelli di terze parti non sono automaticamente pronti per l'uso. Innanzitutto, richiedono l'attivazione.
Per attivare gli LLM, gli sviluppatori devono fare una richiesta ai loro fornitori di servizi cloud. Gli sviluppatori possono effettuare richieste in diversi modi, anche tramite semplici moduli di richiesta. Una volta che gli sviluppatori hanno inviato questi moduli di richiesta, i fornitori di servizi cloud possono attivare rapidamente i servizi LLM. Dopo l'attivazione, gli sviluppatori possono interagire con i loro LLM basati su cloud utilizzando i comandi dell'interfaccia a riga di comando (CLI).
Tieni presente che il processo di invio di un modulo di richiesta di attivazione a un provider cloud non è protetto da un livello di sicurezza a prova di proiettile. Gli attori delle minacce possono facilmente fare lo stesso, quindi le aziende devono concentrarsi su ulteriori tipi di sicurezza AI e LLM.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

In che modo gli attori delle minacce conducono gli attacchi di jacking LLM?
Ora che hai capito come le aziende interagiscono tipicamente con i servizi LLM ospitati nel cloud, diamo un'occhiata a come gli attori delle minacce facilitano gli attacchi di jacking LLM.
Ecco i passaggi che gli attori delle minacce adottano per orchestrare un attacco di jacking LLM:
Per vendere le credenziali cloud, gli attori delle minacce devono prima rubarle. Quando i ricercatori hanno scoperto per la prima volta le tecniche di attacco LLM jacking, hanno rintracciato le credenziali rubate in un sistema che utilizzava una versione vulnerabile di Laravel (CVE-2021-3129).
Una volta che un autore di minacce ruba le credenziali da un sistema vulnerabile, può venderle su marketplace illeciti ad altri criminali informatici che possono acquistarle e sfruttarle per attacchi più avanzati.
Con le credenziali cloud rubate in mano, gli attori delle minacce devono valutare i propri privilegi di accesso e amministrativi. Per valutare furtivamente i limiti dei loro privilegi di accesso al cloud, gli aggressori informatici possono sfruttare il
InvokeModel APIchiamare.Anche se il
InvokeModel APIè una richiesta valida, gli attori delle minacce possono generare un errore "ValidationException" impostando ilmax_tokens_to_samplea -1. Questo passaggio serve semplicemente ad accertare se le credenziali rubate possono accedere ai servizi LLM. Al contrario, se viene visualizzato un errore "AccessDenied", gli attori delle minacce sanno che le credenziali rubate non'Non disporre di privilegi di accesso sfruttabili.
Gli avversari possono anche invocare GetModelInvocationLoggingConfiguration per capire le impostazioni di configurazione dei servizi di intelligenza artificiale ospitati nel cloud di un'azienda. Ricorda che questo passaggio dipende dalle barriere e dalle capacità dei singoli fornitori e servizi cloud. Ecco perché, in alcuni casi, gli attori delle minacce potrebbero non avere una visibilità completa degli input e degli output LLM di un'azienda.
Condurre un attacco di jacking LLM non garantisce la monetizzazione per gli attori delle minacce. Tuttavia, ci sono alcuni modi in cui gli attori delle minacce possono assicurarsi che il jacking LLM sia redditizio. Durante l'autopsia di un attacco di jacking LLM, i ricercatori hanno scoperto che gli avversari possono potenzialmente utilizzare il server open source OAI Reverse Proxy come pannello centralizzato per gestire le credenziali cloud rubate con privilegi di accesso LLM.
Una volta che gli attori delle minacce monetizzano i loro attacchi di jacking LLM e vendono l'accesso ai modelli LLM di un'azienda, non c'è modo di prevedere il tipo di danno che può derivarne. Altri avversari di diversa provenienza e con motivazioni diverse possono acquistare l'accesso LLM e utilizzare l'infrastruttura GenAI di un'azienda a loro insaputa. Mentre le conseguenze degli attacchi di jacking LLM possono inizialmente rimanere nascoste, le ricadute possono essere catastrofiche.


Tattiche di prevenzione e rilevamento del jacking LLM
Ecco alcuni modi efficaci in cui le aziende possono proteggersi dagli attacchi di jacking LLM:
Tattiche di prevenzione
Addestramento robusto del modello:
Set di dati diversificati e di alta qualità: assicurati che il modello sia addestrato su un'ampia gamma di dati per prevenire distorsioni e vulnerabilità.
Addestramento avversario: esporre il modello a input dannosi per migliorarne la resilienza.
Apprendimento per rinforzo dal feedback umano (RLHF): allineare il modello'con i valori e le aspettative umane.
Convalida rigorosa dell'input:
Filtraggio: implementa filtri per bloccare i prompt dannosi o dannosi.
Sanificazione: Pulire gli input per rimuovere gli elementi potenzialmente dannosi.
Limitazione della velocità: limita il numero di richieste per evitare abusi.
Verifica regolare del modello:
Valutazioni della vulnerabilità: identificare i potenziali punti deboli del modello.
Rilevamento delle distorsioni: monitorare le distorsioni non intenzionali nel modello'.
Monitoraggio delle prestazioni: monitora le prestazioni del modello nel tempo per rilevare anomalie.
Documentazione del modello trasparente:
Linee guida chiare: fornisci istruzioni chiare su come utilizzare il modello in modo responsabile.
Limitazioni: Comunicare il modello'e potenziali distorsioni.
Apprendimento continuo e adattamento:
Tieniti informato: tieniti aggiornato sulle ultime minacce e contromisure LLM.
Aggiornamenti del modello: aggiornare regolarmente il modello per risolvere le nuove vulnerabilità.
Tattiche di rilevamento
Rilevamento anomalie:
Identificazione dei valori anomali: identifica comportamenti insoliti o imprevisti del modello.
Analisi statistica: utilizza metodi statistici per rilevare le deviazioni dai modelli normali.
Monitoraggio dei contenuti:
Filtro per parole chiave: monitora gli output per parole chiave o frasi specifiche associate a contenuti dannosi.
Analisi del sentiment: analizza il sentiment dei contenuti generati per identificare potenziali problemi.
Analisi dello stile: rileva anomalie nello stile di scrittura del contenuto generato.
Analisi del comportamento degli utenti:
Modelli insoliti: identifica il comportamento anomalo degli utenti, come richieste rapide o richieste ripetitive.
Monitoraggio dell'account: monitora gli account utente per rilevare attività sospette.
Verifica human-in-the-loop:
Garanzia di qualità: Impiega revisori umani per valutare la qualità e la sicurezza dei contenuti generati.
Meccanismi di feedback: raccogli il feedback degli utenti per identificare potenziali problemi.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

In che modo Wiz può prevenire gli attacchi di jacking LLM
L'innovativa soluzione di strumenti AI-SPM di Wiz può aiutare a prevenire e mitigare l'escalation degli attacchi di jacking LLM in disastri su larga scala. Wiz AI-SPM può aiutare a difendersi dal jacking LLM in diversi modi:
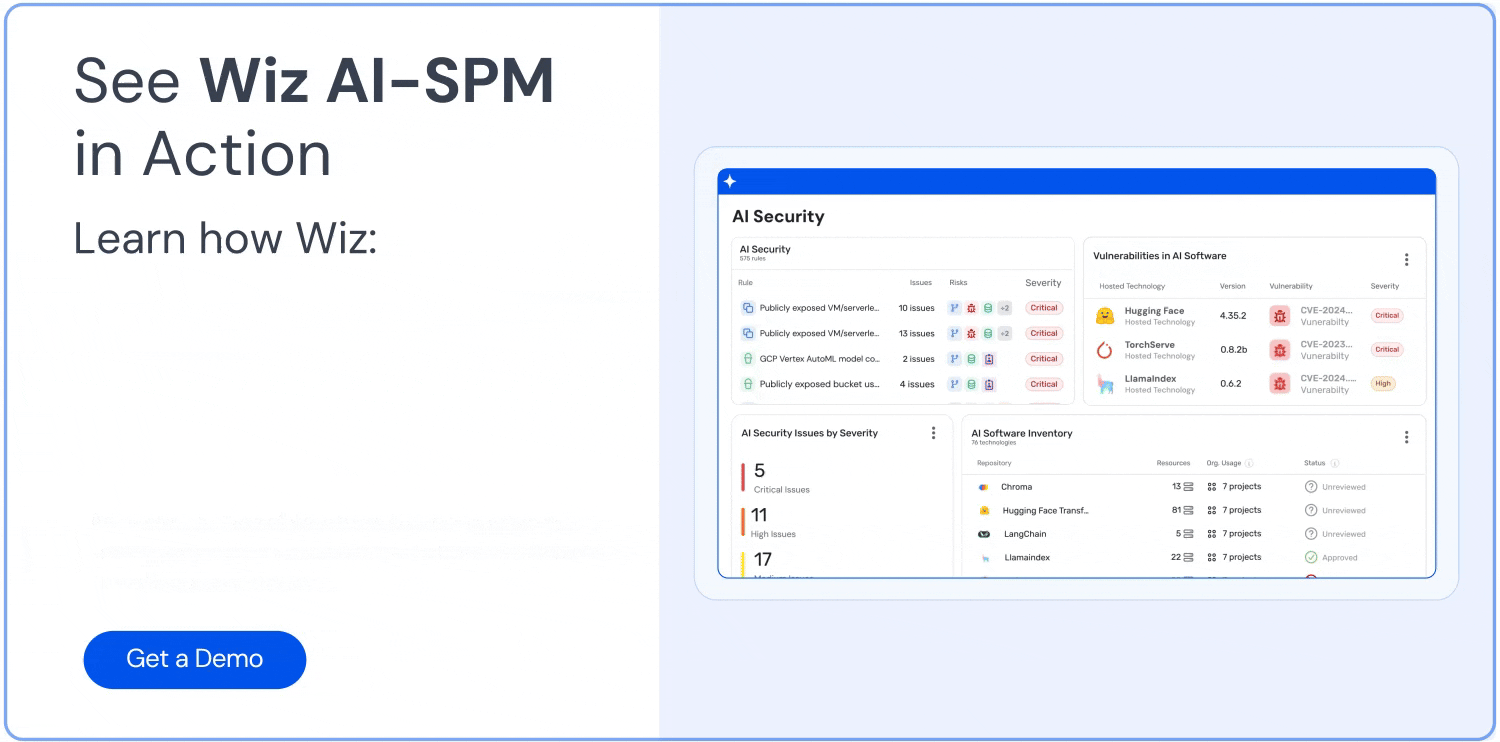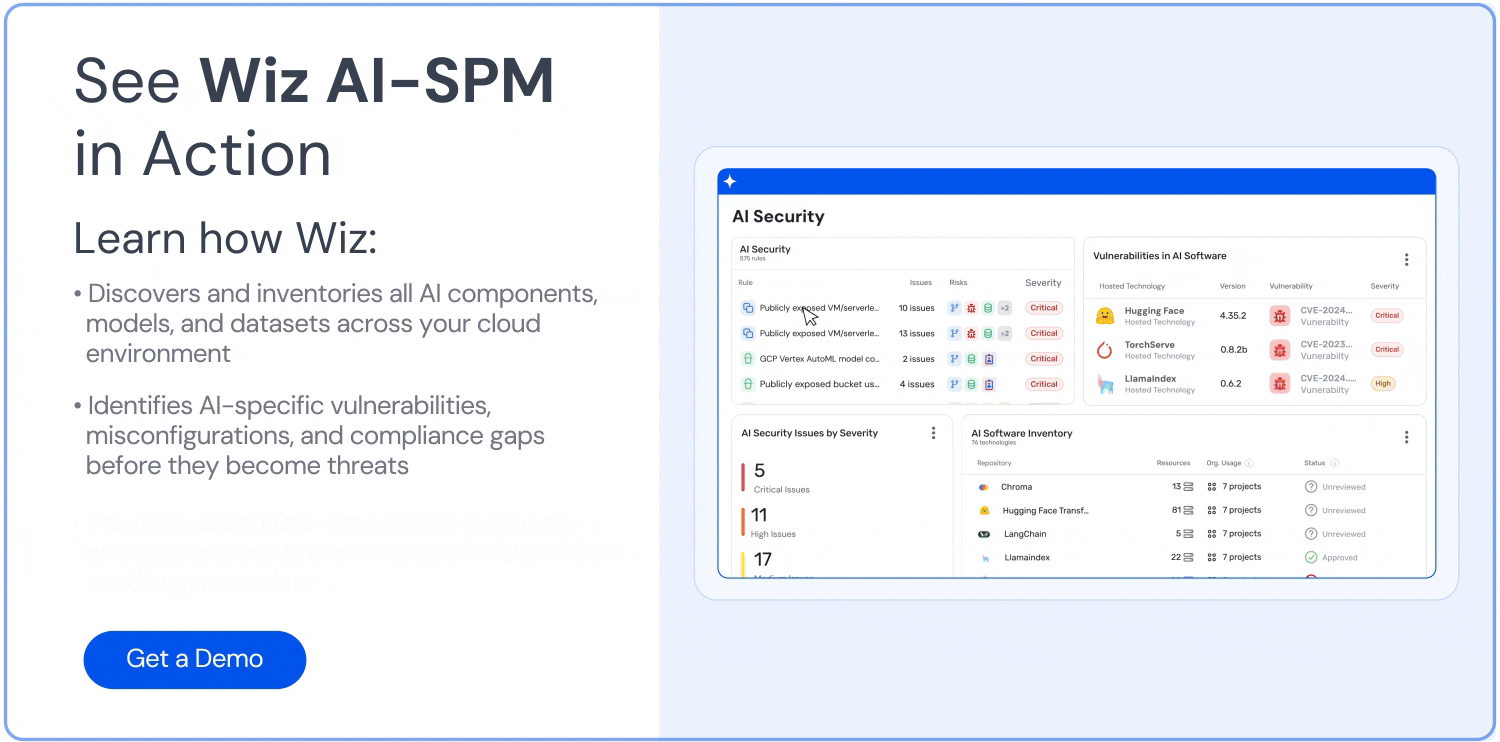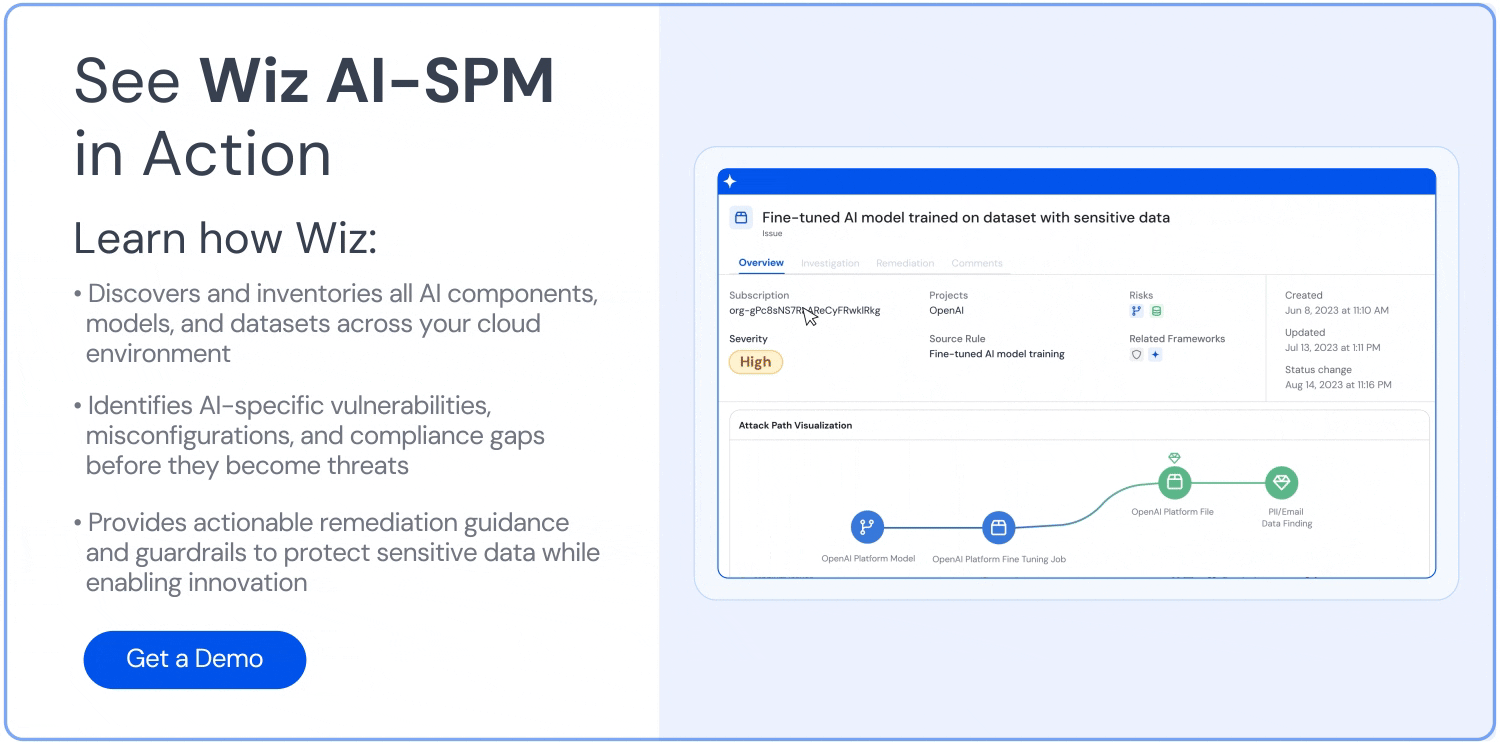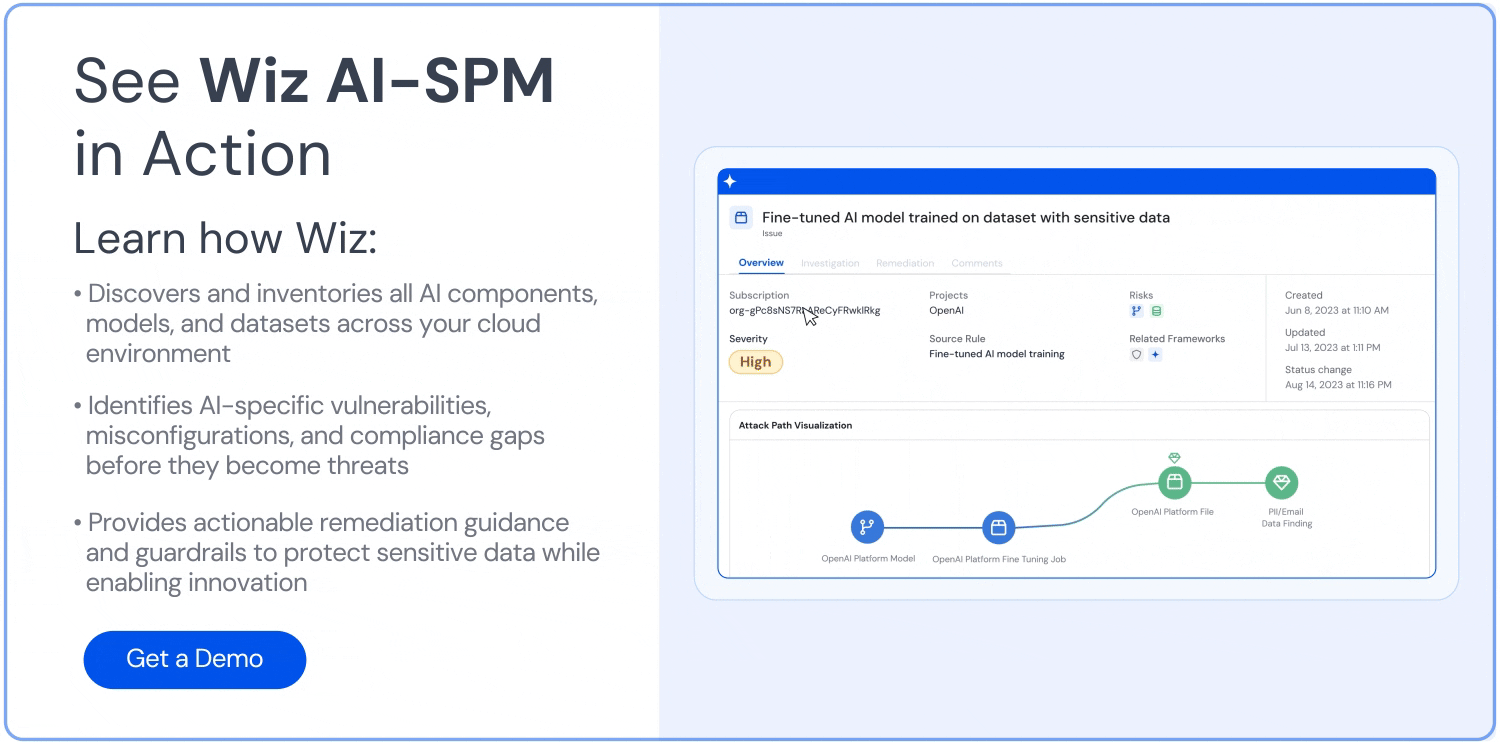
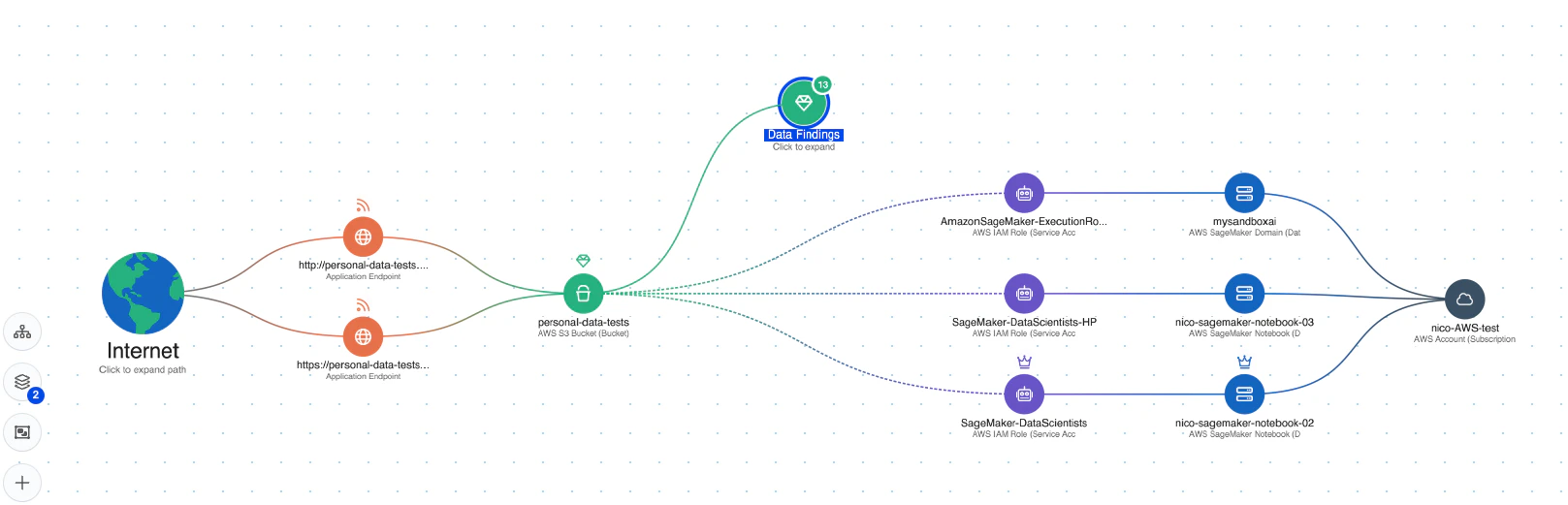
Visibilità completa: Wiz AI-SPM offre una visibilità completa delle pipeline di intelligenza artificiale, inclusi servizi, tecnologie e SDK di intelligenza artificiale, senza richiedere alcun agente. Questa visibilità aiuta le organizzazioni a rilevare e monitorare tutti i componenti di intelligenza artificiale nel loro ambiente, inclusi gli LLM, rendendo più difficile per gli aggressori sfruttare sconosciuti o ombra AI risorse.
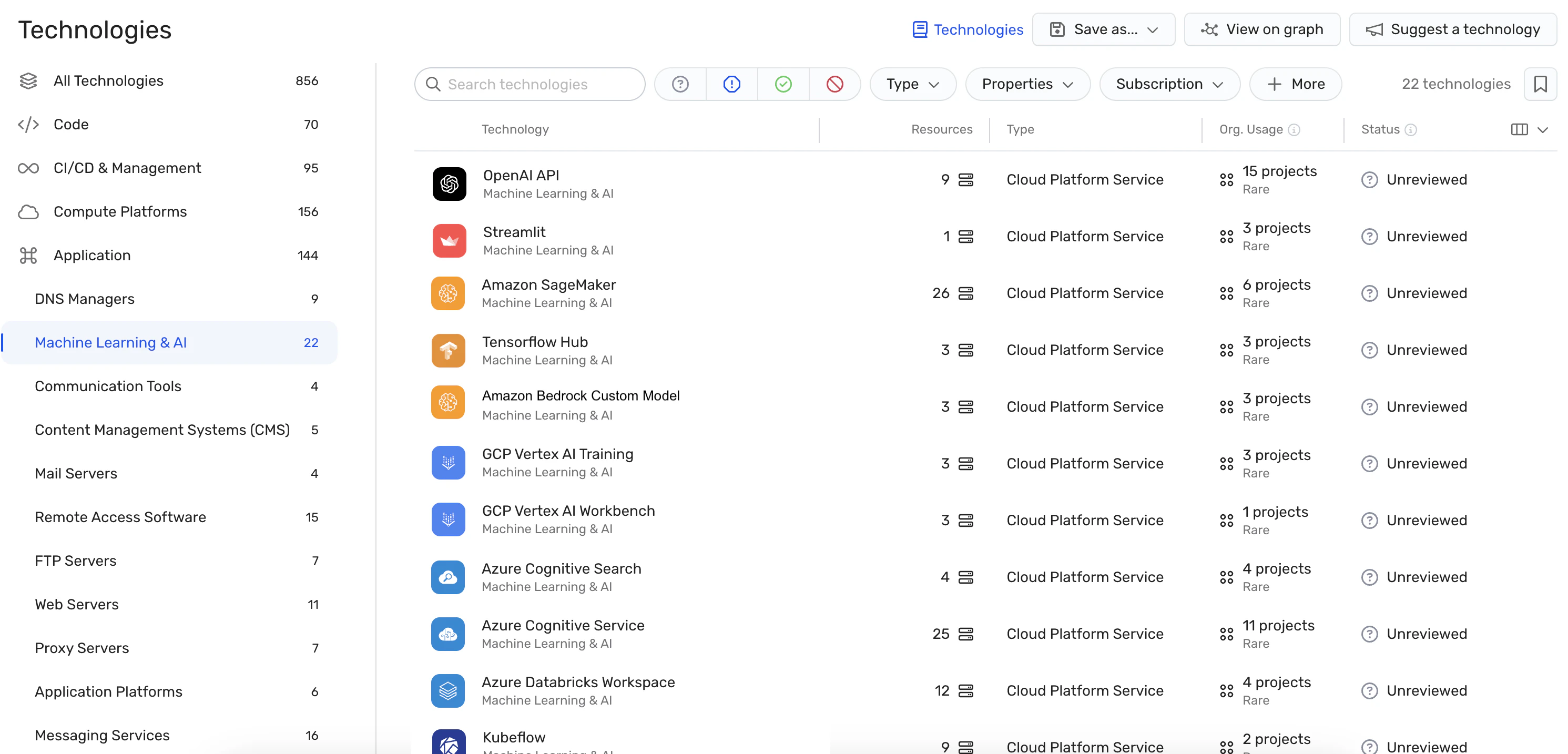
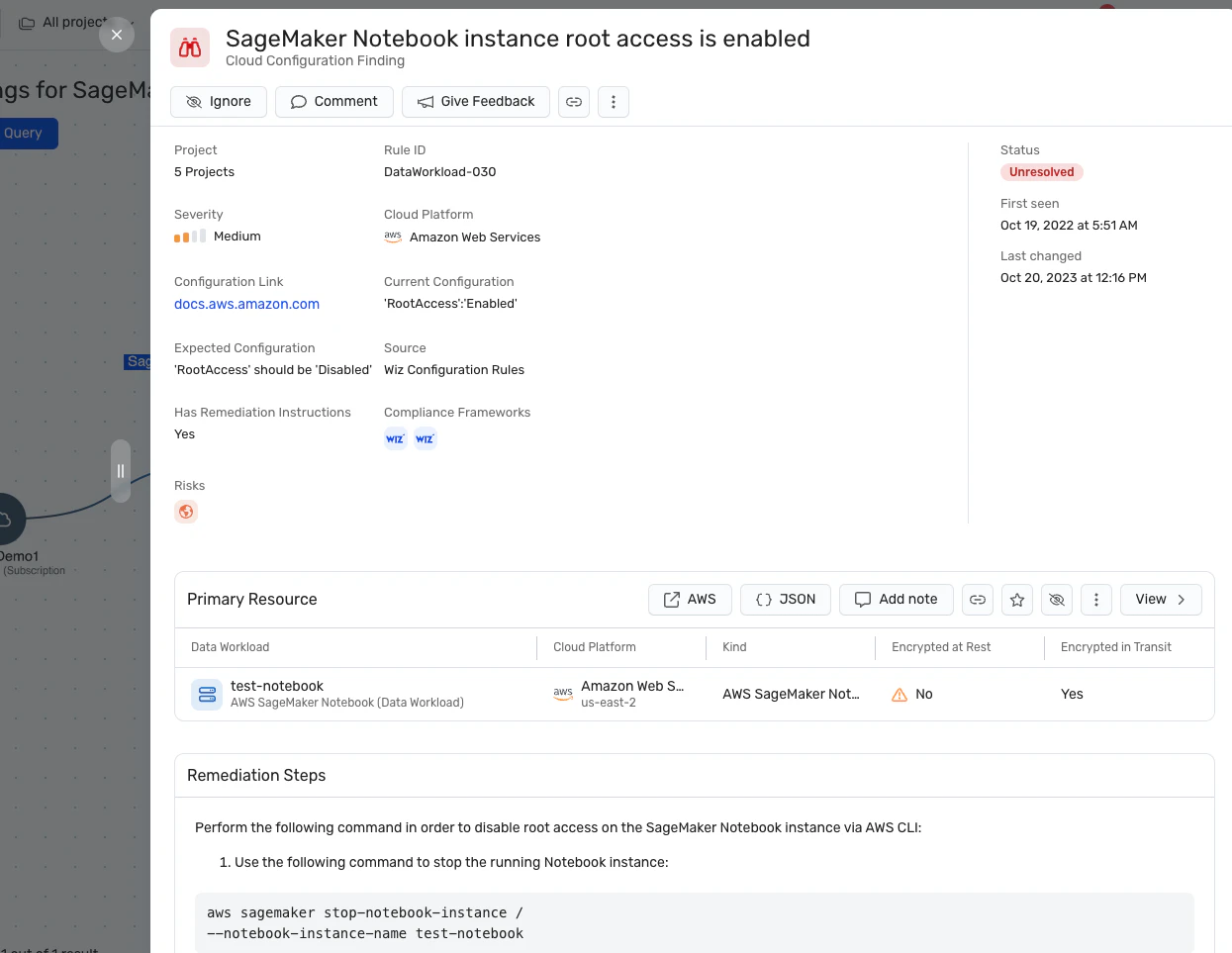
Rilevamento di configurazioni errate: La piattaforma applica Best practice per la sicurezza dell'intelligenza artificiale rilevando le configurazioni errate nei servizi di intelligenza artificiale con regole integrate. Questo può aiutare a prevenire le vulnerabilità che potrebbero essere sfruttate negli attacchi di jacking LLM.
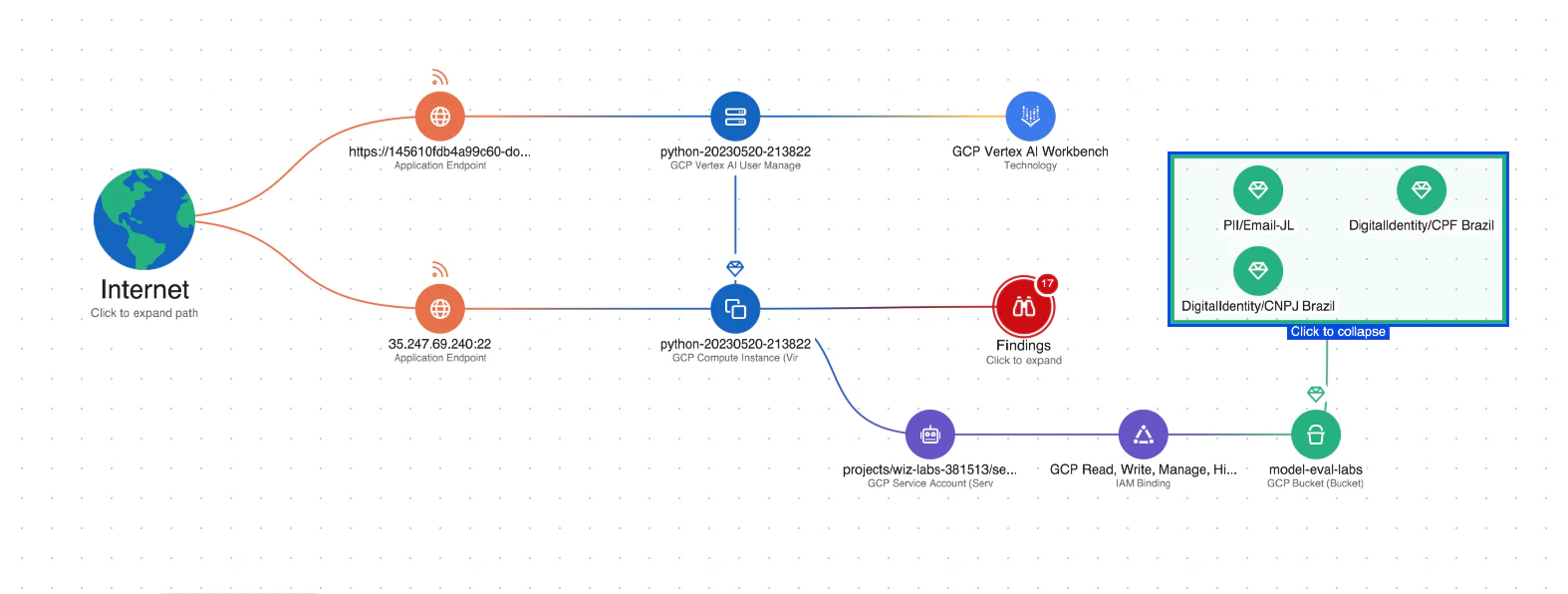
Analisi del percorso di attacco: Wiz AI-SPM identifica e rimuove in modo proattivo i percorsi di attacco ai modelli di intelligenza artificiale valutando vulnerabilità, identità, esposizioni a Internet, dati, configurazioni errate e segreti. Questa analisi completa può aiutare a prevenire potenziali punti di ingresso per i tentativi di sollevamento LLM.
Sicurezza dei dati per l'intelligenza artificiale: La piattaforma include la gestione della postura di sicurezza dei dati (Distribuzione DSPM) specifiche per l'intelligenza artificiale, in grado di rilevare automaticamente i dati di addestramento sensibili e rimuovere i percorsi di attacco ad essi. Questo aiuta a proteggere Perdita di dati che potrebbe essere utilizzato negli attacchi di jacking LLM.
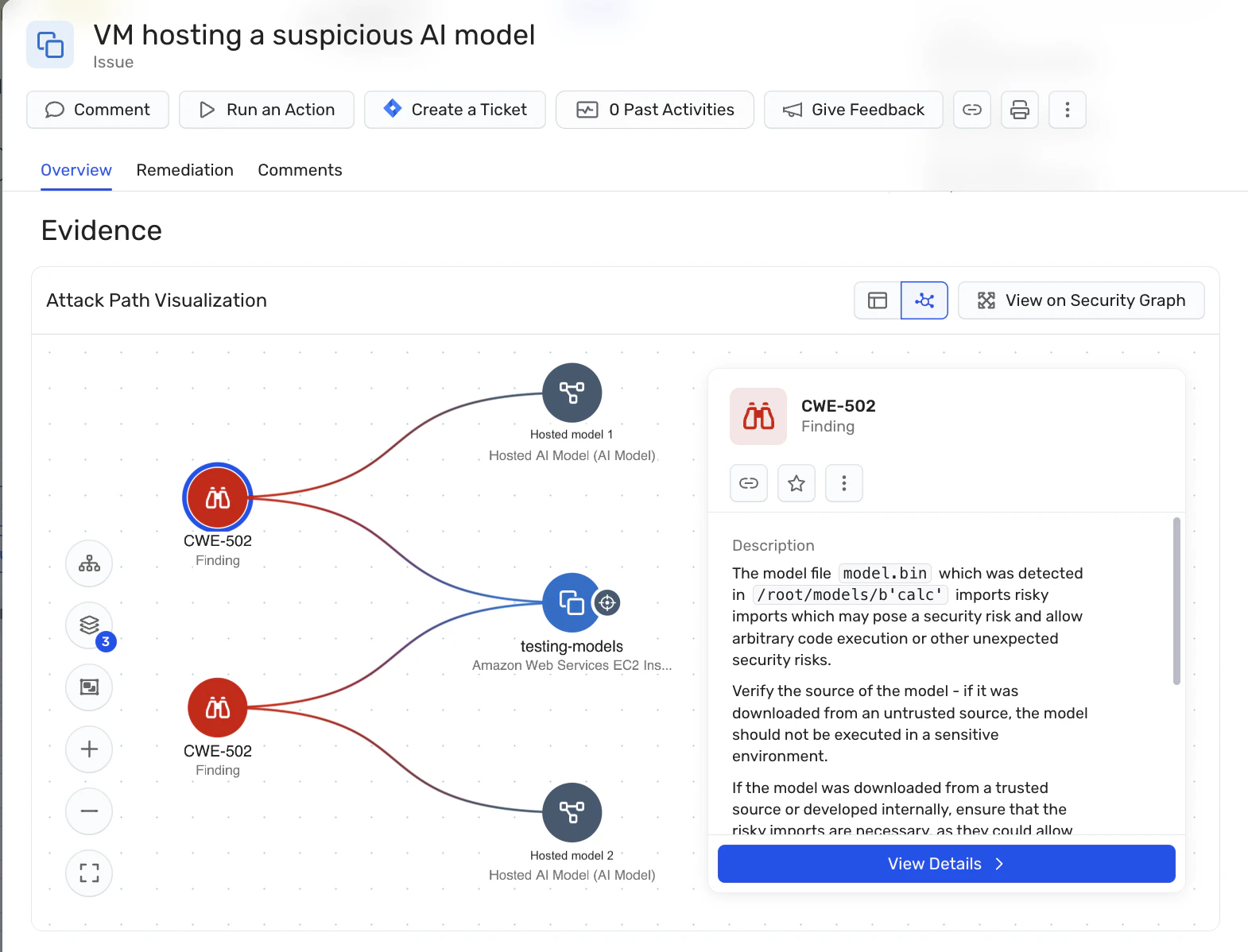
Rilevamento delle minacce in tempo reale: Wiz AI-SPM offre protezione runtime contro comportamenti sospetti provenienti da modelli di intelligenza artificiale. Questa capacità può aiutare a rilevare e rispondere ai tentativi di jacking LLM in tempo reale, riducendo al minimo il potenziale impatto.
Scansione del modello: La piattaforma supporta l'identificazione e la scansione di modelli di intelligenza artificiale ospitati, consentendo alle organizzazioni di rilevare modelli dannosi che potrebbero essere utilizzati negli attacchi di jacking LLM. Ciò è particolarmente importante per le organizzazioni che ospitano autonomamente modelli di intelligenza artificiale, in quanto aiuta ad affrontare i rischi della catena di approvvigionamento associati ai modelli open source.
Dashboard di sicurezza AI: Wiz AI-SPM fornisce una dashboard di sicurezza AI che offre una panoramica della posizione di sicurezza dell'IA con una coda di rischi prioritaria. Questo aiuta gli sviluppatori di intelligenza artificiale e i team di sicurezza a concentrarsi rapidamente sui problemi più critici, comprese le vulnerabilità che potrebbero portare al jacking LLM.
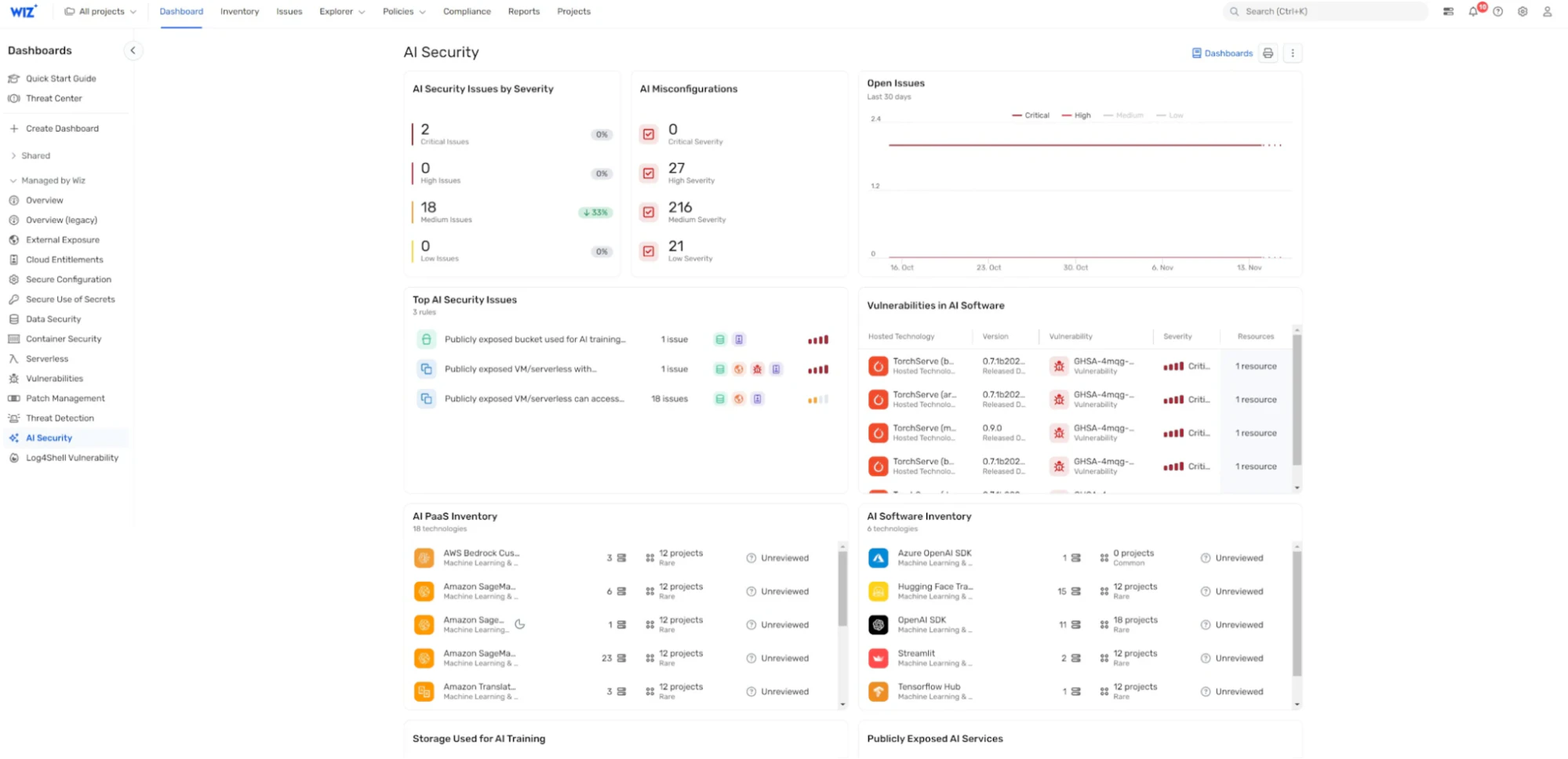
Implementando queste funzionalità, Wiz AI-SPM aiuta le organizzazioni a mantenere una solida posizione di sicurezza per i loro sistemi di intelligenza artificiale, rendendo più difficile per gli aggressori eseguire con successo attacchi di jacking LLM e altre minacce legate all'intelligenza artificiale.