

I modelli di IA dannosi sono Artefatti del modello intenzionalmente armati che compiono azioni dannose quando sono caricate o in movimento. A differenza dei modelli vulnerabili – che contengono difetti accidentali – i modelli dannosi sono progettati per compromettere l'ambiente in cui vengono impiegati.
La caratteristica distintiva dei modelli di IA dannose è che la minaccia è incorporata all'interno del file modello stesso. In molti casi, gli attaccanti abusano di formati di serializzazione non sicuri per nascondere codice eseguibile all'interno dei pesi dei modelli o nella logica di caricamento. Quando il modello viene importato o deserializzato, quel codice viene eseguito automaticamente – spesso prima che avvenga qualsiasi inferenza.
Questo rende i modelli di IA dannosi una minaccia distinta alla catena di approvvigionamento. Sfruttano il trust che le organizzazioni pongono in modelli pre-addestrati scaricati da repository pubblici o condivisi internamente tra i team. Poiché gli artefatti del modello non vengono trattati come il codice sorgente tradizionale, spesso bypassano i controlli di sicurezza come la revisione del codice, l'analisi statica e la scansione delle dipendenze.
Con l'accelerazione dell'adozione dell'IA, i modelli pre-addestrati sono diventati un elemento fondamentale per lo sviluppo moderno. Questa stessa comodità ha trasformato artefatti del modello in un vettore di attacco di alto valore – uno che gli strumenti di sicurezza applicativa tradizionali non sono mai stati progettati per esaminare.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Perché i modelli di IA dannosi rappresentano un reale rischio nella supply chain
I modelli di IA dannosi emergono dalle stesse forze che hanno rimodellato lo sviluppo software moderno: riutilizzo, automazione e fiducia nei componenti esterni. I modelli pre-addestrati vengono regolarmente prelevati da archivi pubblici per accelerare lo sviluppo, ridurre i costi ed evitare la rieducazione da zero. In molte organizzazioni, scaricare e distribuire modelli è diventato tanto di routine quanto installare una libreria.
Questo flusso di lavoro sposta la fiducia dal codice revisionato internamente verso artefatti esterni che vengono raramente ispezionati. I file modello sono spesso trattati come binari opachi – memorizzati, condivisi e caricati senza la supervisione applicata al codice applicativo o alle immagini dei contenitori. Di conseguenza, spesso bypassano i controlli di sicurezza consolidati come la revisione del codice, l'analisi statica e la scansione delle dipendenze.
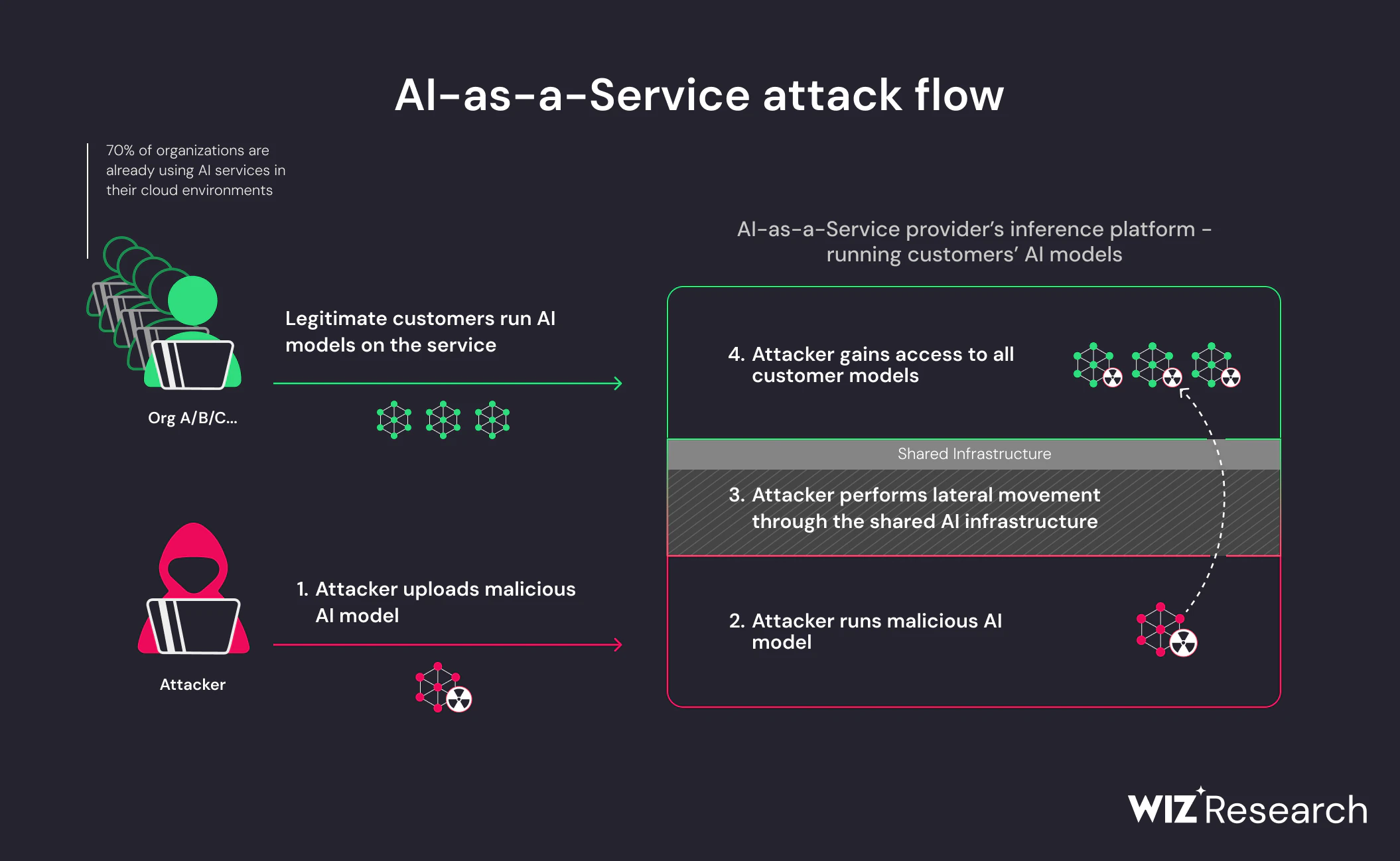
Ciò che rende questo rischio particolarmente acuto è che i modelli dannosi sfruttano Comportamento atteso. Caricare un modello è un'azione normale e affidabile nelle pipeline di IA. Quando gli attaccanti incorporano la logica eseguibile negli artefatti del modello, quella fiducia diventa il meccanismo di consegna. Non è richiesta alcuna catena di exploit; il compromesso avviene perché il sistema sta facendo esattamente ciò per cui è stato progettato.
Ecco perché i modelli di IA dannosi rappresentano un Minaccia alla catena di approvvigionamento piuttosto che un bug dell'applicazione. Il rischio non deriva da come viene utilizzato un modello, ma da come viene utilizzato da dove proviene e come viene caricata. Man mano che il riutilizzo dei modelli continua a crescere tra team e ambienti, la capacità di validare la provenienza e il comportamento del modello diventa un requisito fondamentale di sicurezza.
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
Leggi di più

Come funzionano i modelli di IA dannosi ad alto livello
I modelli di IA dannosi sfruttano il modo in cui i modelli vengono confezionati, distribuiti e caricati nei flussi di lavoro moderni dell'IA. Il rischio centrale non sono le previsioni del modello, ma il percorso di esecuzione attivato quando un file modello viene deerializzato o inizializzato.
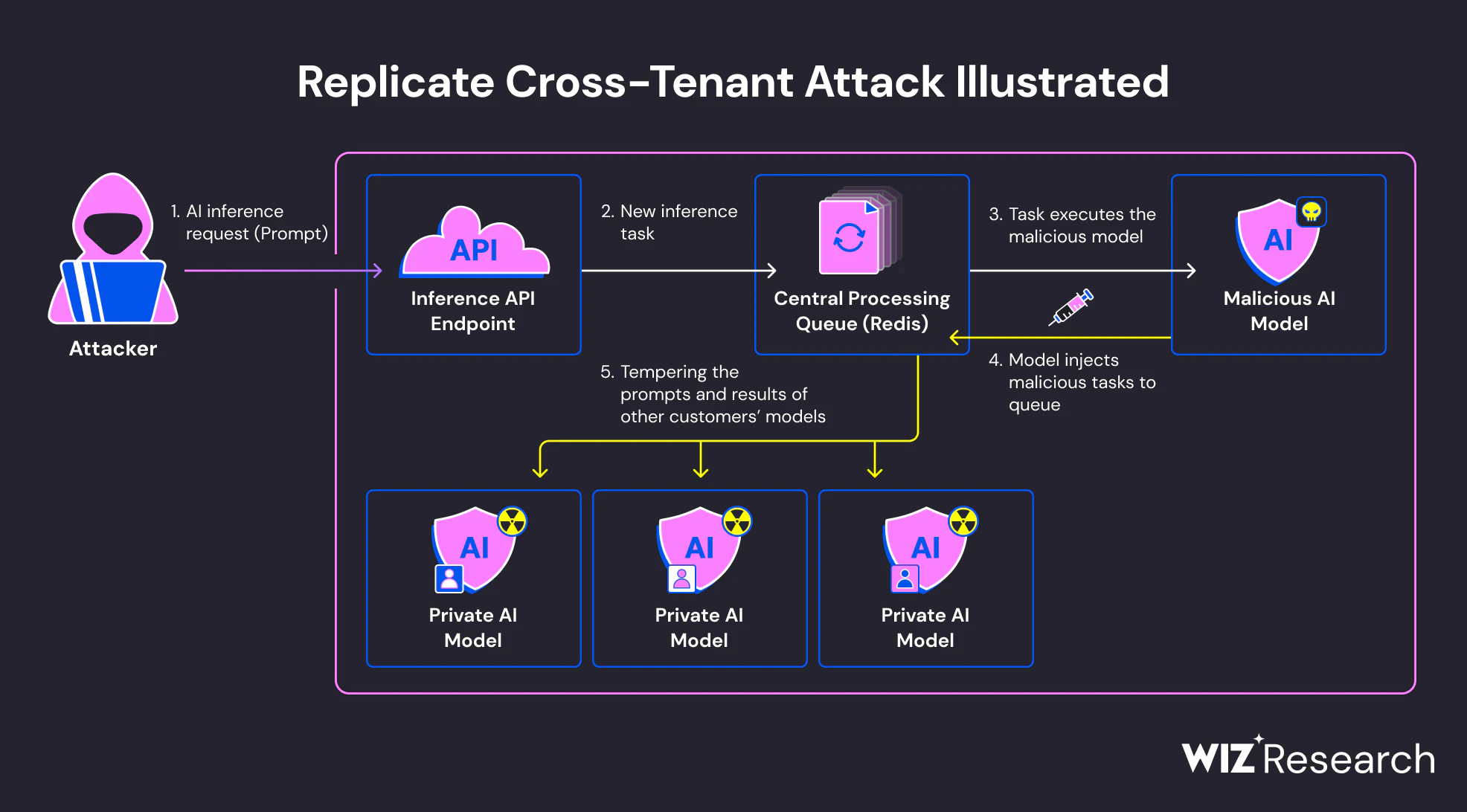
Esecuzione durante il caricamento del modello
Molti framework di IA supportano formati di serializzazione che permettono di eseguire la logica eseguibile come parte del processo di caricamento del modello. In particolare, Python Cetriolo-basati su -– comunemente utilizzati in PyTorch e strumenti correlati—possono eseguire codice arbitrario quando un modello viene deserializzato. Questo comportamento è documentato, ma spesso trascurato nella pratica.
Quando un modello malevolo viene caricato, il codice incorporato può essere eseguito immediatamente, prima che avvenga inferenza o valutazione. Dal punto di vista del sistema, sembra una normale importazione di modello. Dal punto di vista dell'attaccante, è un punto di esecuzione affidabile all'interno di un ambiente affidabile.
Perché questo accade prima dell'inferenza
A differenza del codice applicativo, i modelli sono trattati come dati. I controlli di sicurezza tendono a concentrarsi su come vengono utilizzati i modelli, non su come vengono caricati. Di conseguenza, l'attività più pericolosa avviene all'inizio del ciclo di vita – al momento del caricamento – prima che vengano applicati il monitoraggio in tempo reale, i controlli di accesso o i controlli comportamentali.
Questo è ciò che rende difficili rilevare modelli dannosi con gli strumenti tradizionali. Non potrebbero esserci chiamate API sospette, né input malformati né output anomali. Il compromesso avviene semplicemente perché il modello è stato accettato come legittimo.
Obiettivi comuni degli attaccanti
Una volta raggiunta l'esecuzione, gli attaccanti tipicamente inseguono obiettivi familiari:
Rubare credenziali o token disponibili nell'ambiente
Accesso ai dati di addestramento o ai dati a valle
Stabilire la persistenza attraverso backdoor o compiti programmati
Consumo di risorse di calcolo per cryptomining o ulteriori compromesse
Queste azioni non sono uniche degli ambienti di IA, ma i modelli spesso funzionano con permessi elevati e la vicinanza a dati sensibili, aumentando così il loro impatto.
Formati più sicuri, predefiniti più sicuri
Non tutti i formati dei modelli comportano lo stesso rischio. Formati progettati per separare pesi dalla logica eseguibile – come SafeTensors e ONNX –riducono la probabilità di esecuzione del codice durante il caricamento del modello. Questi formati memorizzano i dati dei modelli senza percorsi di esecuzione incorporati, rendendoli più sicuri per progettazione.
Al contrario, i meccanismi di serializzazione che permettono la logica eseguibile durante la deserializzazione aumentano il rischio a meno che non siano strettamente controllati. In pratica, compatibilità e comodità spesso portano i team a optare per formati non sicuri a meno che non vengano applicati standard di sicurezza espliciti.
Comprensione come i modelli sono quindi caricati è fondamentale per difendersi dai modelli AI dannosi. La minaccia non si basa su input avversali o su comportamenti innovativi dell'IA – si basa su percorsi di esecuzione prevedibili e affidabili negli strumenti ML comuni.


Vettori di attacco principali per modelli di IA dannosi
I modelli di IA dannosi tipicamente raggiungono la produzione attraverso un piccolo numero di vettori di attacco ripetibili. Questi vettori sfruttano la fiducia negli artefatti del modello e nell'automazione nei flussi di lavoro dell'IA piuttosto che nel comportamento innovativo dell'IA.
Repository pubblici di modelli
I repository pubblici sono il canale di distribuzione più comune per modelli dannosi. Gli attaccanti caricano modelli armati su piattaforme popolari o usano il typosquatting per imitare progetti noti. Col tempo, possono costruirsi una reputazione attraverso release innocui prima di introdurne una versione malevola.
Poiché i modelli pre-addestrati vengono spesso scaricati direttamente in ambienti di sviluppo o addestramento, questi artefatti possono bypassare i processi di revisione applicati al codice applicativo o alle immagini dei container.
Esecuzione remota del codice tramite caricatori di modelli
Alcuni flussi di lavoro di IA consentono esplicitamente l'esecuzione remota o personalizzata di codice durante il caricamento del modello. Impostazioni come flag di loader permissive o classi di modelli personalizzate espandono la superficie di attacco permettendo di recuperare e eseguire dinamicamente la logica eseguibile.
In questi casi, il rischio non deriva dai pesi del modello stessi, ma dal meccanismo di caricamento che implicitamente si fida del codice esterno. Questo rende la configurazione dei loader una parte importante del modello di minaccia.
Modelli di Trojan e backdoor appresi
Non tutti i modelli dannosi si basano sull'esecuzione durante il caricamento. Alcuni sono progettati per comportarsi normalmente nella maggior parte delle condizioni durante la produzione Output dannosi quando sono presenti trigger specifici. Questi modelli "Trojan" incorporano comportamenti dannosi direttamente nei pesi appresi piuttosto che nel codice eseguibile.
A differenza degli attacchi basati su serializzazione, i modelli Trojan tipicamente mirano a Processo di addestramento o di messa a punto fine, come attraverso dati di addestramento avvelenati o flussi di lavoro di fine tuning manipolati. Poiché il comportamento malevolo è codificato nei parametri del modello, la scansione statica dell'artefatto del modello offre una visibilità limitata sulla minaccia.
Questo rende i modelli Trojan una categoria di rischio distinta. Rilevarli generalmente richiede test avversariali, analisi comportamentali o validazione dei dati di addestramento e della linea, piuttosto che l'ispezione del file del modello da solo.
Dipendenza e rischio interno
I modelli dannosi possono anche entrare negli ambienti tramite dipendenze compromesse o canali interni affidabili. Questo include librerie ML avvelenate, registri interni insicuri o modelli introdotti da insider con accesso legittimo.
Poiché questi vettori si basano su relazioni di fiducia esistenti, spesso vengono trascurati nella modellazione iniziale delle minacce, nonostante abbiano il potenziale di un impatto ampio.
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

Perché gli ambienti cloud amplificano il rischio
Gli ambienti cloud non creano modelli di IA dannosi, ma in modo significativo aumentare l'impatto e la velocità di compromesso quando ne viene introdotto. Le stesse caratteristiche che rendono le piattaforme cloud ideali per l'IA – automazione, scalabilità e accesso a dati sensibili – amplificano anche il rischio della catena di approvvigionamento.
I carichi di lavoro dell'IA spesso vengono eseguiti con permessi elevati. I lavori di addestramento e i servizi di inferenza spesso richiedono l'accesso a grandi dataset, archiviazione di oggetti, segreti e servizi a valle. Quando un modello malevolo viene eseguito all'interno di questo contesto, può immediatamente ereditare quei privilegi, espandendo il raggio di esplosione oltre il modello stesso.
L'automazione amplifica ulteriormente il rischio. I modelli sono comunemente distribuiti tramite pipeline CI/CD, framework di orchestrazione o flussi di lavoro di riaddestramento programmati. Una volta che un artefatto malevolo entra in uno di questi percorsi, può propagarsi rapidamente tra gli ambienti senza intervento umano, rendendo l'ispezione manuale poco pratica.
Anche l'infrastruttura cloud cambia dove avviene l'esecuzione rispetto ai dati sensibili. I modelli malevoli tipicamente si esegueno all'interno dello stesso piano dati in cui dovrebbero accedere, piuttosto che adiacente ad essa. A differenza di un'applicazione web compromessa che deve ruotare lateralmente per raggiungere un database, un modello spesso gira all'interno dell'ambiente che ha già accesso diretto ai dati di addestramento, agli input di inferenza o ai sistemi a valle. Questo fa collassare la distanza tra esecuzione e impatto.
Infine, i carichi di lavoro dell'IA dipendono da stack complessi di servizi gestiti, container, GPU e dipendenze runtime. Ogni livello introduce sfide di configurazione e isolamento che gli attaccanti possono sfruttare se i controlli vengono applicati in modo errato. In pratica, ciò significa che i modelli dannosi traggono beneficio dalle stesse configurazioni errate che oggi causano molte violazioni del cloud.
Insieme, questi fattori trasformano i modelli di IA dannosi da un rischio localizzato in un Preoccupazione di sicurezza a livello di sistema, rafforzando il motivo per cui la sicurezza dei modelli deve essere valutata nel contesto delle identità cloud, dell'accesso ai dati e delle pipeline di distribuzione – non in isolamento.
Difesa contro modelli di IA dannosi
Difendersi dai modelli di IA dannosi richiede uno spostamento dell'attenzione dal comportamento del modello a Provenienza del modello, percorsi di carico e contesto di esecuzione. Poiché la minaccia è incorporata nell'artefatto o nel processo di addestramento stesso, tradizionale Controlli di sicurezza delle applicazioni sono necessari ma aren'Non abbastanza da sole.
Stabilire i controlli prima che i modelli arrivino in produzione
Le difese più efficaci operano prima che un modello venga caricato. Questo include la convalida da dove provengono i modelli, come sono impacchettati e quali percorsi di codice vengono eseguiti durante il caricamento. Trattare gli artefatti dei modelli come componenti di prima qualità della catena di approvvigionamento – soggetti a ispezione, approvazione e controllo delle versioni – riduce la probabilità che i modelli armati raggiungano ambienti sensibili.
In pratica, ciò significa applicare la stessa governance a Registri di modelli che le organizzazioni già fanno domanda ai registri dei contenitori o ai depositi di reperti. Se le immagini dei container sono firmate, scansionate e promosse tramite pipeline controllate, gli artefatti dei modelli dovrebbero seguire la stessa disciplina – indipendentemente dal fatto che abbiano origine interna o da fonti pubbliche.
Quando possibile, i team dovrebbero preferire formati di modello che separino i dati dalla logica eseguibile e limitino configurazioni di loader che si fidano implicitamente del codice esterno. Questi controlli non eliminano il rischio, ma restringono significativamente la superficie d'attacco.
Vincoli nell'esecuzione tramite controlli di identità e accesso
I modelli dannosi sono più pericolosi quando ereditano permessi ampi. Limitare le identità e i ruoli disponibili per i carichi di lavoro di addestramento e inferenza riduce il raggio di esplosione se un modello viene compromesso. Questo include l'applicazione del minor privilegio per gli account di servizio, l'isolamento degli ambienti e l'evitare credenziali condivise tra pipeline.
Poiché i modelli spesso si eseguono all'interno del piano dati, il controllo degli accessi diventa una linea di difesa primaria – non una salvaguarda secondaria.
Monitorare il comportamento nel contesto, non in isolamento
L'ispezione statica da sola non può individuare ogni modello malevolo, in particolare quelli che incorporano comportamenti nei pesi appresi. La visibilità in tempo reale aiuta a colmare questa lacuna osservando come i modelli interagiscono con il loro ambiente nel tempo.
Il monitoraggio efficace si concentra su Segnali contestuali: accessi di rete inattesi, operazioni di file insolite, uso anomalo dell'identità o deviazioni dai modelli di esecuzione consolidati. Questi segnali sono più significativi quando correlati al contesto cloud – quali dati il modello può accedere, quali identità utilizza e come è stato distribuito.
Considera la sicurezza dei modelli come parte della sicurezza cloud
In definitiva, difendersi dai modelli di IA dannosi non è una disciplina autonoma. Richiede di integrare considerazioni specifiche per l'IA nelle esigenze esistenti Pratiche di sicurezza cloud, inclusa la governance della supply chain, la gestione dell'identità e il monitoraggio del carico di lavoro.
Valutando i modelli come parte del sistema più ampio in cui operano – piuttosto che come scatole nere opache – i team di sicurezza possono ridurre l'esposizione a artefatti dannosi senza dover fare affidamento su rilevazioni speculative o assunzioni sul comportamento del modello.
Come Wiz aiuta a ridurre il rischio di modelli AI dannosi
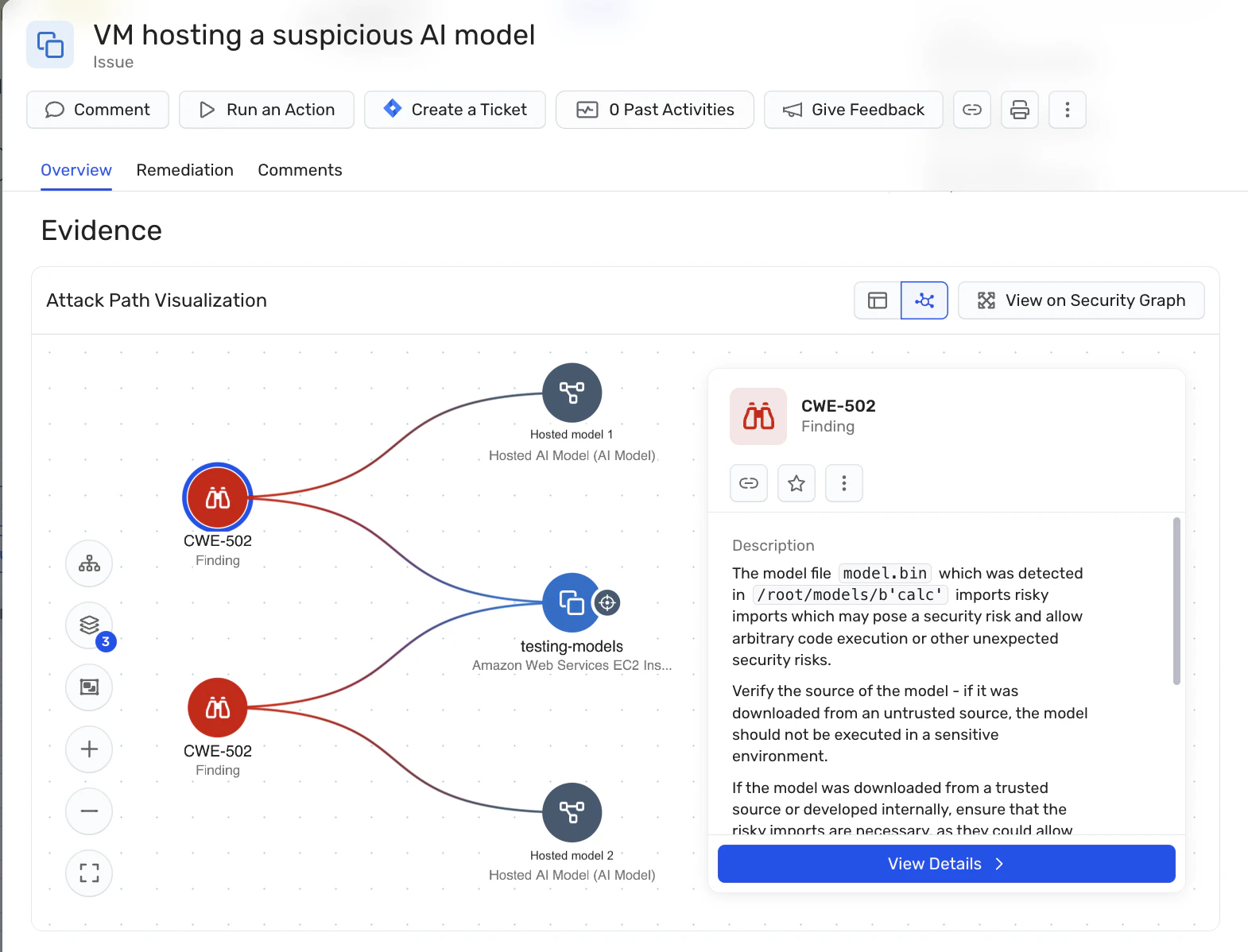
Wiz aiuta le organizzazioni a ridurre il rischio di modelli di IA dannosi basando la sicurezza dei modelli sui fondamenti della sicurezza cloud. Piuttosto che tentare di classificare l'intento o il comportamento del modello, Wiz si concentra sulla validazione dei controlli che determinano Da dove provengono i modelli, come vengono caricati e cosa possono accedere una volta installati.
Attraverso Gestione della Postura di Sicurezza AI (AI-SPM) e il Wiz Security Graph, modelli di IA, lavori di addestramento, servizi di inferenza e registri sono trattati come asset cloud di prim'ordine. Wiz fornisce visibilità sugli artefatti dei modelli ospitati ed esegue ispezioni a livello di formato per emergere metodi di serializzazione rischiosi o fonti non affidabili – estendendo la disciplina della supply chain software ai modelli AI prima che entrino in produzione.
Correlatando artefatti del modello con identità, permessi, esposizione alla rete e accesso a dati sensibili, Wiz aiuta i team a identificare quando un modello rischioso o potenzialmente dannoso diventa sfruttabile nella pratica, comprendere il suo vero raggio di esplosione e dare priorità alla bonifica basandosi su percorsi di attacco reali – senza rallentare lo sviluppo dell'IA o introdurre strumenti di sicurezza separati.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
