



Che cos'è la perdita di dati?
La perdita di dati è l'esfiltrazione incontrollata di dati dell'organizzazione a terzi. Si verifica attraverso vari mezzi come database configurati in modo errato, server di rete scarsamente protetti, attacchi di phishing o persino una gestione negligente dei dati.
La perdita di dati può verificarsi accidentalmente: 82% di tutte le organizzazioni Offri a terze parti un ampio accesso in lettura ai loro ambienti, il che pone gravi rischi per la sicurezza e seri problemi di privacy. Tuttavia, la perdita di dati si verifica anche a causa di attività dannose, tra cui hacking, phishing o minacce interne in cui i dipendenti rubano intenzionalmente i dati.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

Potenziali impatti della perdita di dati
La fuga di dati può avere impatti profondi e di vasta portata:
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
La crescente minaccia della perdita di machine learning (ML)
Quando si addestra un modello utilizzando un set di dati diverso da quello di un modello linguistico di grandi dimensioni (LLM), possono verificarsi distorsioni nell'apprendimento automatico o nell'intelligenza artificiale (AI). Questa situazione si verifica in genere a causa di una cattiva gestione della fase di pre-elaborazione dello sviluppo del ML. Un esempio tipico di perdita di ML consiste nell'utilizzo della media e della deviazione standard di un intero set di dati di training anziché dell'intero sottoinsieme di training.
La perdita di dati si verifica nei modelli di Machine Learning a causa di una perdita di target o di una contaminazione da train-test. In quest'ultimo, i dati destinati al test del modello fuoriescono nel set di addestramento. Se un modello viene esposto ai dati di test durante l'addestramento, le metriche delle prestazioni saranno ingannevolmente elevate.
Nella perdita di target, i sottoinsiemi utilizzati per l'addestramento includono informazioni non disponibili nella fase di previsione dello sviluppo del ML. Sebbene gli LLM funzionino bene in questo scenario, offrono agli stakeholder un falso senso di efficacia del modello, con conseguente scarsità di prestazioni nelle applicazioni reali.


Cause comuni di perdita di dati
La perdita di dati si verifica per una serie di motivi; Di seguito sono riportati alcuni dei più comuni.
Errore umano
L'errore umano può verificarsi a qualsiasi livello all'interno di un'organizzazione, spesso senza intenti malevoli. Ad esempio, i dipendenti possono inviare accidentalmente informazioni sensibili, come documenti finanziari o dati personali, all'indirizzo e-mail sbagliato.
Attacchi di phishing
Gli attacchi di phishing si manifestano in varie forme, ma hanno un solo metodo: i criminali informatici attirano gli account privilegiati per fornire dettagli preziosi. Ad esempio, gli aggressori possono inviare e-mail apparentemente legittime chiedendo ai dipendenti di fare clic su collegamenti dannosi e di accedere a un determinato account. In questo modo, il dipendente offre volontariamente le proprie credenziali di accesso all'aggressore, che vengono poi utilizzate per uno o più scopi dannosi.
Configurazione scadente
I database, i servizi cloud e le impostazioni software configurati in modo errato creano vulnerabilità che espongono i dati sensibili ad accessi non autorizzati. Configurazioni errate Spesso si verificano a causa di svista, mancanza di esperienza o mancata osservanza delle best practice di sicurezza. Lasciare invariate le impostazioni predefinite, come i nomi utente e le password predefiniti, può garantire un facile accesso ai criminali informatici.
Anche le impostazioni errate dell'app, la mancata applicazione di patch e aggiornamenti di sicurezza e le impostazioni inadeguate di controlli/autorizzazioni di accesso possono creare falle di sicurezza.
Misure di sicurezza deboli
Misure di sicurezza deboli sminuiscono un'organizzazione'. Utilizzo di password semplici e facili da indovinare; mancata implementazione di politiche di password complesse; concedere autorizzazioni eccessive e non seguire il principio del privilegio minimo (PoLP); o il riutilizzo delle password su più account aumenta il rischio di perdita di dati.
Inoltre, lasciando i dati Unencrypted, inattivi e in transito, predispone i dati alla perdita. Non attuare il principio del privilegio minimo (PoLP) E affidarsi a protocolli/tecnologie di sicurezza obsoleti può creare lacune nel framework di sicurezza.
Strategie per prevenire le perdite
1. Pre-elaborazione e sanificazione dei dati
Anonimizzazione e redazione
L'anonimizzazione comporta l'alterazione o la rimozione di informazioni di identificazione personale (PII) e dati sensibili per evitare che vengano ricollegati agli individui. L'oscuramento è un processo più specifico che comporta la rimozione o l'oscuramento di parti sensibili dei dati, come numeri di carte di credito, numeri di previdenza sociale o indirizzi.
Senza un'adeguata anonimizzazione e redazione, i modelli di intelligenza artificiale possono "Memorizza" Dati sensibili del set di addestramento, che potrebbero essere riprodotti inavvertitamente negli output del modello. Ciò è particolarmente pericoloso se il modello viene utilizzato in applicazioni pubbliche o rivolte ai client.
Migliori pratiche:
Utilizza tecniche di tokenizzazione, hashing o crittografia per rendere anonimi i dati.
Assicurarsi che tutti i dati oscurati vengano rimossi in modo permanente sia dai set di dati strutturati (ad esempio, database) che non strutturati (ad esempio, file di testo) prima dell'addestramento.
Implementare la privacy differenziale (discussa più avanti) per ridurre ulteriormente il rischio di esposizione dei dati individuali.
Minimizzazione dei dati
La minimizzazione dei dati comporta solo la raccolta e l'utilizzo del più piccolo set di dati necessario per raggiungere l'obiettivo del modello di intelligenza artificiale. Meno dati vengono raccolti, minore è il rischio che le informazioni sensibili vengano divulgate.
La raccolta di dati eccessivi aumenta la superficie di rischio di violazioni e le possibilità di fuga di informazioni sensibili. Utilizzando solo ciò che'è necessario, si garantisce anche la conformità alle normative sulla privacy come il GDPR o il CCPA.
Migliori pratiche:
Condurre un audit dei dati per valutare quali punti dati sono essenziali per la formazione.
Implementa le policy per eliminare i dati non essenziali nelle prime fasi della pipeline di pre-elaborazione.
Rivedere regolarmente il processo di raccolta dei dati per assicurarsi che non vengano conservati dati non necessari.
2. Misure di salvaguardia per la formazione dei modelli
Suddivisione corretta dei dati
La suddivisione dei dati separa il set di dati in set di training, convalida e test. Il set di addestramento insegna il modello, mentre i set di convalida e test garantiscono l'accuratezza del modello senza overfitting.
Se i dati vengono suddivisi in modo errato (ad esempio, gli stessi dati sono presenti sia nel set di addestramento che in quello di test), il modello può "memorizzare" efficacemente il set di test, portando a una sovrastima delle sue prestazioni e alla potenziale esposizione di informazioni sensibili sia nella fase di addestramento che in quella di previsione.
Migliori pratiche:
Randomizza i set di dati durante la suddivisione per garantire che non ci siano sovrapposizioni tra i set di training, convalida e test.
Utilizza tecniche come la convalida incrociata k-fold per valutare in modo affidabile le prestazioni del modello senza perdita di dati.
Tecniche di regolarizzazione
Le tecniche di regolarizzazione vengono impiegate durante l'addestramento per evitare l'overfitting, in cui il modello diventa troppo specifico per i dati di addestramento e impara a "memorizzare" piuttosto che generalizzare. L'overfitting aumenta la probabilità di perdita di dati poiché il modello può memorizzare informazioni sensibili dai dati di addestramento e riprodurle durante l'inferenza.
Migliori pratiche:
Abbandono degli studi: Rilascia casualmente alcune unità (neuroni) dalla rete neurale durante l'addestramento, costringendo il modello a generalizzare piuttosto che memorizzare gli schemi.
Decadimento del peso (regolarizzazione L2): penalizzare pesi elevati durante l'addestramento per evitare che il modello si adatti troppo ai dati di addestramento.
Arresto anticipato: Monitorare le prestazioni del modello su un set di convalida e interrompere l'addestramento quando il modello'Le prestazioni iniziano a degradarsi a causa dell'overfitting.
Privacy differenziale
La privacy differenziale aggiunge rumore controllato ai dati o agli output del modello, garantendo che diventi difficile per gli aggressori estrarre informazioni su qualsiasi singolo punto dati nel set di dati.
Applicando la privacy differenziale, è meno probabile che i modelli di intelligenza artificiale perdano dettagli di individui specifici durante l'addestramento o la previsione, fornendo un livello di protezione contro gli attacchi avversari o la perdita involontaria di dati.
Migliori pratiche:
Aggiungi il rumore gaussiano o di Laplace ai dati di addestramento, ai gradienti del modello o alle previsioni finali per oscurare i singoli contributi di dati.
Utilizza framework come TensorFlow Privacy o PySyft per applicare la privacy differenziale nella pratica.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Distribuzione sicura del modello
Isolamento degli inquilini
In un ambiente multi-tenant, l'isolamento del tenant crea un limite logico o fisico tra ogni tenant', rendendo impossibile per un tenant accedere o manipolare un altro'informazioni riservate. Isolando ogni tenant', le aziende possono impedire l'accesso non autorizzato, ridurre il rischio di violazioni dei dati e garantire la conformità alle normative sulla protezione dei dati.
L'isolamento dei tenant fornisce un ulteriore livello di sicurezza, offrendo alle organizzazioni la tranquillità di sapere che il loro dati sensibili di addestramento dell'intelligenza artificiale è protetto da potenziali perdite o accessi non autorizzati.
Migliori pratiche:
Separazione logica: utilizza tecniche di virtualizzazione come container o macchine virtuali (VM) per garantire che i dati e l'elaborazione di ciascun tenant siano isolati l'uno dall'altro.
Controlli di accesso: Implementa criteri di controllo degli accessi rigorosi per garantire che ogni tenant possa accedere solo ai propri dati e risorse.
Crittografia e gestione delle chiavi: utilizzare le chiavi di crittografia specifiche del tenant per separare ulteriormente i dati, garantendo che, anche in caso di violazione, i dati di altri tenant rimangano al sicuro.
Limitazione e monitoraggio delle risorse: impedisce agli inquilini di esaurire le risorse condivise applicando limiti di risorse e monitorando comportamenti anomali che potrebbero compromettere l'isolamento del sistema.
Sanificazione in uscita
La sanificazione dell'output comporta l'implementazione di controlli e filtri sugli output del modello per prevenire l'esposizione accidentale di dati sensibili, in particolare nell'elaborazione del linguaggio naturale (NLP) e nei modelli generativi.
In alcuni casi, il modello potrebbe riprodurre informazioni riservate rilevate durante il training (ad esempio, nomi o numeri di carta di credito). La sanificazione degli output garantisce che non vengano esposti dati sensibili.
Migliori pratiche:
Utilizza algoritmi di corrispondenza dei modelli per identificare e oscurare le informazioni personali (ad esempio, indirizzi e-mail, numeri di telefono) negli output del modello.
Impostare soglie sugli output probabilistici per evitare che il modello esegua previsioni eccessivamente sicure che potrebbero esporre dettagli sensibili.
4. Pratiche organizzative
Formazione dei dipendenti
La formazione dei dipendenti garantisce che tutte le persone coinvolte nello sviluppo, nell'implementazione e nella manutenzione dei modelli di intelligenza artificiale comprendano i rischi di perdita di dati e le best practice per mitigarli. Molte violazioni dei dati si verificano a causa di errori umani o svista. Una formazione adeguata può prevenire l'esposizione accidentale di informazioni sensibili o le vulnerabilità dei modelli.
Migliori pratiche:
Fornisci una formazione regolare sulla sicurezza informatica e sulla privacy dei dati a tutti i dipendenti che gestiscono modelli di intelligenza artificiale e dati sensibili.
Aggiornare il personale sui rischi emergenti per la sicurezza dell'IA e sulle nuove misure preventive.
Politiche di governance dei dati
Le policy di governance dei dati stabiliscono linee guida chiare su come i dati devono essere raccolti, elaborati, archiviati e accessibili all'interno dell'organizzazione, garantendo che le pratiche di sicurezza siano applicate in modo coerente.
Una politica di governance ben definita garantisce che la gestione dei dati sia standardizzata e conforme alle leggi sulla privacy come GDPR o HIPAA, riducendo le possibilità di perdita.
Migliori pratiche:
Definisci la proprietà dei dati e stabilisci protocolli chiari per la gestione dei dati sensibili in ogni fase dello sviluppo dell'intelligenza artificiale.
Rivedere e aggiornare regolarmente le politiche di governance per riflettere i nuovi rischi e i requisiti normativi.
5. Sfrutta gli strumenti di gestione della postura di sicurezza (AI-SPM) dell'intelligenza artificiale
Soluzioni AI-SPM fornire visibilità e controllo sui componenti critici della sicurezza dell'intelligenza artificiale, inclusi i dati utilizzati per l'addestramento/inferenza, l'integrità dei modelli e l'accesso ai modelli distribuiti. Incorporando uno strumento AI-SPM, le organizzazioni possono gestire in modo proattivo la posizione di sicurezza dei loro modelli di intelligenza artificiale, riducendo al minimo il rischio di perdita di dati e garantendo una solida governance del sistema di intelligenza artificiale.
In che modo AI-SPM aiuta a prevenire la perdita del modello ML:
Individua e inventaria tutte le applicazioni, i modelli e le risorse associate all'intelligenza artificiale
Identifica le vulnerabilità nella supply chain dell'intelligenza artificiale e le configurazioni errate che potrebbero portare alla perdita di dati
Monitora i dati sensibili nello stack AI, inclusi dati di addestramento, librerie, API e pipeline di dati
Rileva anomalie e potenziali perdite di dati in tempo reale
Implementa guardrail e controlli di sicurezza specifici per i sistemi di intelligenza artificiale
Condurre audit e valutazioni regolari delle applicazioni di intelligenza artificiale


In che modo Wiz può aiutarti
Con la sua gestione completa della postura di sicurezza dei dati (DSPM), Wiz aiuta a prevenire e rilevare la perdita di dati nei seguenti modi.
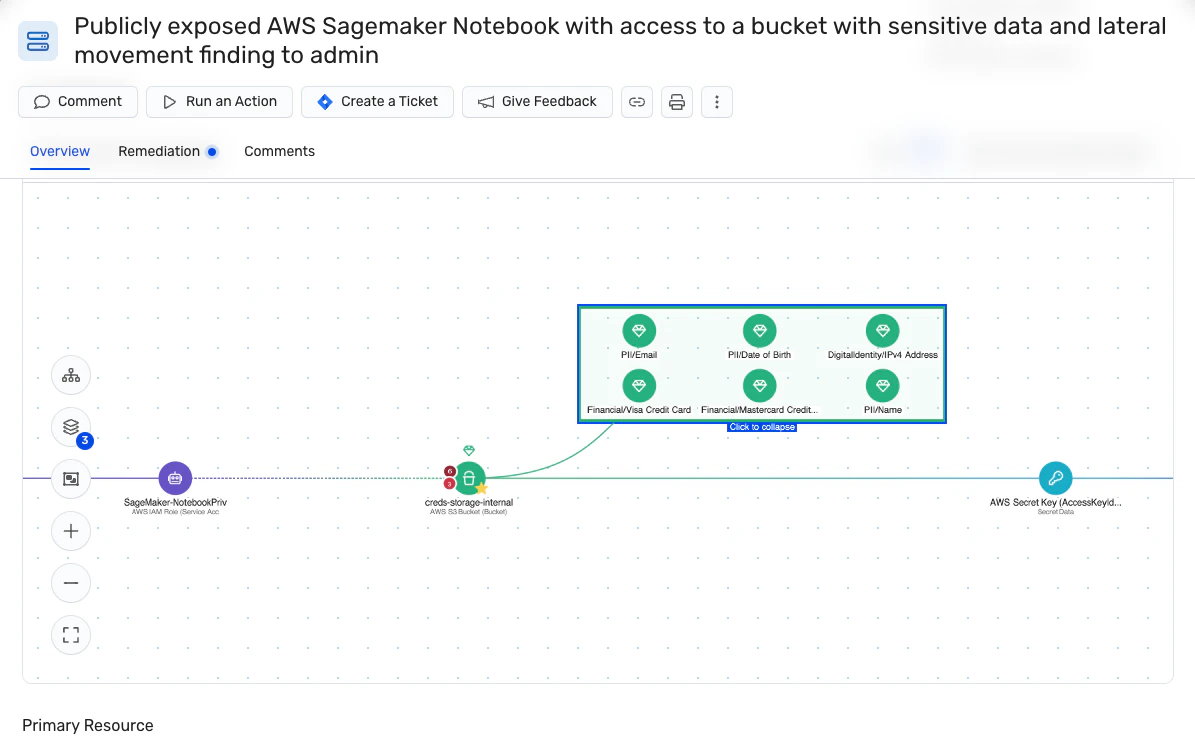
Individua e classifica automaticamente i dati
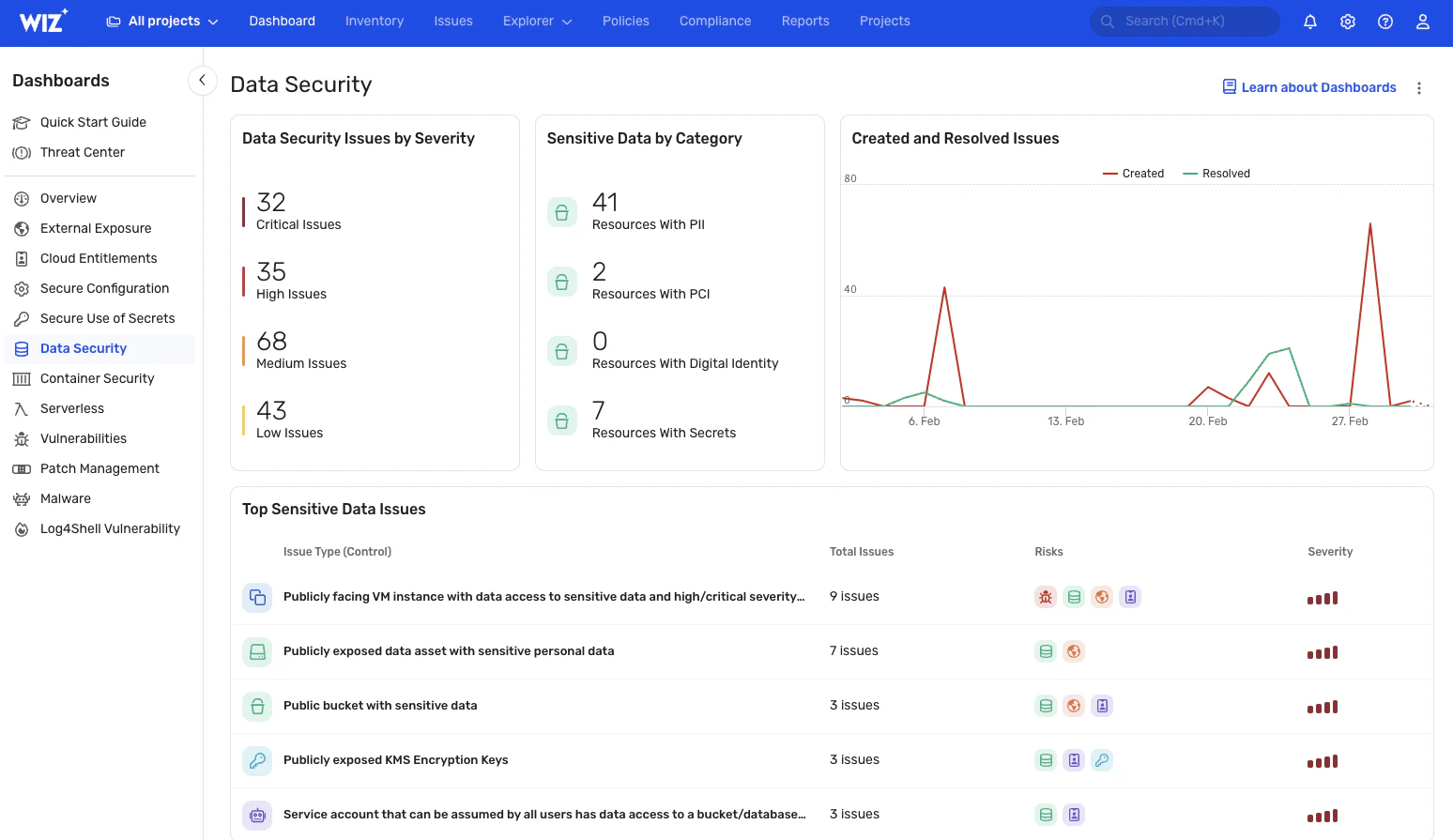
Wiz monitora continuamente l'esposizione dei dati critici, fornendo visibilità in tempo reale su informazioni sensibili come dati PII, PHI e PCI. Fornisce una visione aggiornata di dove si trovano i dati e di come vi si accede (anche nei sistemi di intelligenza artificiale con il nostro Soluzione AI-SPM). È inoltre possibile creare classificatori personalizzati per identificare i dati sensibili univoci per l'azienda. Queste caratteristiche facilitano ulteriormente la risposta rapida agli incidenti di sicurezza, evitando del tutto danni o riducendo significativamente il potenziale raggio di esplosione.
Valutazione del rischio dei dati
Wiz rileva i percorsi di attacco correlando i risultati dei dati a vulnerabilità, configurazioni errate, identità ed esposizioni che possono essere sfruttate. È quindi possibile chiudere questi percorsi di esposizione prima che gli attori delle minacce possano sfruttarli. Wiz visualizza e assegna priorità ai rischi di esposizione in base al loro impatto e al tasso di gravità, assicurando che i problemi più critici vengano affrontati per primi.
Inoltre, Wiz aiuta la governance dei dati rilevando e visualizzando chi può accedere a quali dati.
Sicurezza dei dati per l'addestramento dell'intelligenza artificiale
Wiz fornisce una valutazione completa del rischio delle tue risorse di dati, inclusa la possibilità di perdita di dati, con funzionalità pronte all'uso DSPM AI Controlli. I nostri strumenti forniscono una visione olistica del livello di sicurezza dei dati della tua organizzazione, evidenziano le aree che richiedono attenzione e offrono una guida dettagliata per rafforzare le misure di sicurezza e risolvere rapidamente i problemi.
Valutazione continua della conformità
La valutazione continua della conformità di Wiz garantisce che la tua organizzazione sia in grado di'è in linea con gli standard di settore e i requisiti normativi in tempo reale. La nostra piattaforma esegue la scansione di configurazioni errate e vulnerabilità, fornendo raccomandazioni attuabili per la correzione e automatizzando la reportistica di conformità.
Con Wiz DSPM, puoi aiutare efficacemente la tua organizzazione a mitigare i rischi di perdita di dati e garantire una solida protezione dei dati e conformità. Prenota una demo oggi per saperne di più.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
