

What is AI data classification?
AI data classification is the automated process of using machine learning algorithms to sort and label your data based on what it contains and how sensitive it is. This means instead of writing rules manually to find credit card numbers or social security numbers, you train a model to recognize these patterns and apply labels automatically.
Traditional classification relies on exact pattern matching—like looking for 16-digit numbers that might be credit cards. AI classification goes further by understanding context, learning from examples, and adapting to new data types without you having to update rules constantly.
In cloud environments, this matters because you're dealing with massive amounts of data spread across storage buckets, databases, serverless functions, and containers. Manual classification simply can't keep up with that scale or the speed at which data moves and changes.
AI Security Posture Assessment Sample Report
See real examples of AI security vulnerabilities and classification challenges in cloud environments.

How AI data classification works in cloud environments
AI data classification starts by scanning your cloud environment to find all your data assets. The system connects to your cloud storage services, databases, and data lakes through APIs to build a complete inventory of what you have and where it lives.
Once it knows what data exists, the classification engine analyzes each piece of data to extract features—file type, content patterns, metadata, and data relationships. These features help the AI model determine sensitivity. The system then applies classification labels using cloud-native mechanisms: S3 object tags in AWS, Azure Blob index tags in Azure, and GCS object labels in Google Cloud. These tags persist with the data and can trigger automated policies.
The model then applies what it learned during training to categorize your data. If you're using supervised learning, the model learned from labeled examples you provided. With unsupervised learning, it finds patterns and groups similar data together without needing those examples upfront.
This process runs continuously as new data enters your environment. Classification systems use event-driven triggers (S3 Event Notifications, Azure Event Grid, GCS Pub/Sub) to detect new objects immediately, or scheduled batch scans for databases and file systems. When you upload a file to S3, an event notification triggers a Lambda function that invokes the classification API and applies labels within seconds to minutes. The same happens when data moves between services or gets replicated across regions.
Cloud-specific challenges include handling data that spans multiple regions and availability zones (creating data residency and sovereignty concerns), maintaining consistent classification across AWS, Azure, and GCP with their different storage services and APIs, and dealing with ephemeral resources like Lambda functions and containers that spin up and down in seconds. Your classification system needs to work with containers that might only exist for minutes and serverless functions that process data on the fly.
Types of AI data classification methods
You have four main approaches to AI data classification, and each works differently depending on your needs and the data you're working with.
Supervised classification requires you to provide labeled training data. You show the model examples of each category—like "this is PII" or "this is public data"—and it learns to recognize similar patterns in new data. Common algorithms include decision trees, support vector machines, and neural networks. This method works well when you have clear categories and enough labeled examples to train on.
Unsupervised classification finds patterns without you telling it what to look for. The model uses clustering algorithms to group similar data together based on characteristics it discovers. This approach helps you find sensitive data types you didn't know existed or spot emerging patterns in large datasets where manual labeling would take forever.
Semi-supervised classification sits in the middle. You provide a small set of labeled examples, and the model uses those plus a large amount of unlabeled data to learn. This reduces the manual work while still maintaining good accuracy, which makes it practical for cloud environments where you have way more data than you could ever label by hand.
Human-in-the-loop and active learning approaches improve classification over time through feedback. When security analysts correct a misclassification or validate edge cases, the system incorporates these corrections into retraining cycles, progressively improving accuracy on your specific data patterns and organizational definitions of sensitivity. This means your classification gets more accurate as it runs, adapting to how your organization's data and needs change.
AI Data Security: Key Principles and Best Practices
AI data security is a specialized practice at the intersection of data protection and AI security that’s aimed at safeguarding data used in AI and machine learning (ML) systems.
もっと読む
Security benefits of AI-powered data classification
AI-powered data classification gives you continuous, automated protection for sensitive data across your entire cloud environment. You maintain visibility into where data lives, who accesses it, and what risks exist without having to manually track everything.
The system automatically discovers sensitive information across all your cloud services. It finds personally identifiable information, protected health information, payment card data, intellectual property, and any custom sensitive data types you define. This happens whether the data sits in S3 buckets, RDS databases, or gets processed by Lambda functions.
Once data is classified, you can automatically apply the right security policies. Only authorized users and services get access to sensitive information based on the classification labels. This enforcement happens in near real time (typically within seconds to minutes) as data moves through your environment. Unified policy engines help standardize enforcement across AWS, Azure, and GCP, reducing drift between development and production environments where inconsistent policies often create security gaps.
Compliance becomes much easier because the system helps map your data to frameworks like GDPR, HIPAA, PCI DSS, SOC 2, and ISO 27001, then generates evidence reports—important as 70% of organizations plan to focus on AI/ML data usage governance according to recent industry research. You get compliance reports without manual data collection, and the system flags gaps before they become violations.
For data loss prevention, classification labels trigger protective actions. If someone tries to move or expose classified data inappropriately, your DLP solution can block it based on the label. This works across email, file sharing, and cloud storage.
During security incidents, classification provides immediate context. You instantly know what types of data were affected and how sensitive they are, which helps you respond faster and meet notification requirements.
AI models can reduce false positives compared to simple pattern matching by incorporating contextual signals—file type, surrounding text, metadata, and data relationships. For example, they distinguish an actual credit card number from a random 16-digit sequence in a test file. This matters because high false alarm rates degrade analyst precision and slow response times, as documented in security operations research.
Implementation challenges and security considerations
Implementing AI data classification in the cloud comes with specific challenges you need to address for it to work securely and effectively.
Model security is your first concern. The classification models themselves become targets because attackers want to understand your data protection patterns or manipulate how data gets classified. Context-aware platforms that correlate identity permissions, network exposure, and misconfigurations to data stores help prioritize model and data risks with real attack paths—for example, flagging when a classification service account has excessive permissions to production data stores or when model files are stored in internet-accessible S3 buckets. You need to protect model files, control who can access them, and monitor for unauthorized changes.
Model poisoning happens when attackers corrupt training data or manipulate inputs to cause misclassification. A poisoned model might label sensitive data as public or fail to identify protected information. You combat this by validating training data sources, implementing cryptographic integrity checks on model files, monitoring classification accuracy metrics for sudden drops, and watching for unusual classification patterns that signal compromise.
Performance and scalability create practical problems. Processing massive amounts of cloud data requires significant compute resources and robust data integration pipelines. Organizations commonly cite data integration complexity, API rate limits, and compute costs as top technical barriers for AI-driven classification workloads. You need to balance how accurate you want classification to be against how fast it needs to run and how much it costs. Real-time data streams and large object stores make this balance even harder.
Maintaining consistent classification across multiple cloud providers takes work. Each provider has different storage types (S3 vs. Azure Blob vs. GCS), access patterns (IAM vs. RBAC vs. IAM), and native classification services (Amazon Macie vs. Microsoft Purview vs. Google Cloud DLP). You need unified policies and metadata schemas that work across all three platforms. Your models and policies need to account for these differences while still applying uniform classification standards.
Privacy and compliance add another layer of complexity. The classification process itself must comply with data protection regulations. You can't expose sensitive data during analysis, and classification metadata can't reveal protected information. Some regulations require you to explain why data was classified a certain way, which means you need models that can show their reasoning.
State of AI in the Cloud 2025
The State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

AI data classification use cases for cloud security
AI data classification enables specific security capabilities that protect your cloud environment and support how your business operates.
Shadow data discovery finds sensitive information in places you didn't expect. The system scans developer environments, backup systems, and forgotten storage buckets to identify data that doesn't match expected patterns or appears outside designated storage areas. Graph-driven mapping of data stores, identities, and exposure paths accelerates removing toxic combinations—like when a dev S3 bucket containing production PII is both internet-accessible and readable by all employees—before they're exploitable.
During mergers and acquisitions, you need to quickly classify and secure data from acquired companies. AI classification rapidly identifies sensitive information that requires immediate protection or special handling during cloud migration and integration. This speeds up the process while maintaining security.
Zero-trust data access uses real-time classification to implement dynamic access controls. The system continuously reclassifies data as content changes or moves, then adjusts permissions based on current classification, user context, and data sensitivity. This ensures access policies stay current with your actual data.
Insider threat detection monitors how people access classified data. The system identifies unusual behavior like bulk downloads of sensitive information or access to data outside someone's normal job functions. These patterns help you catch threats before data leaves your environment.
Cloud workload protection follows data through its lifecycle. Classification metadata travels with data using cloud-native mechanisms like S3 object tags, Azure Blob index tags, and GCS object labels. These tags persist as data moves through containers, serverless functions, and virtual machines, ensuring appropriate security controls apply regardless of where data gets processed.
Development environment security prevents sensitive production data from appearing in dev or test environments. The system continuously scans and classifies data across all environments, flagging when production data shows up where it shouldn't.
What is Data Classification?
In this post, we’ll explore some of the challenges that can complicate cloud data classification, along with the benefits that come with this crucial step—and how a DSPM tool can help make the entire process much simpler.
もっと読む

How Wiz secures sensitive data discovery and classification
Wiz approaches data discovery and classification as proactive risk reduction rather than just a compliance checkbox. The platform secures the AI models and pipelines you use for classification, reducing the risk of model poisoning and unauthorized access to classification systems through AI-SPM capabilities that monitor model integrity, access patterns, and training data provenance.
Wiz DSPM uses agentless scanning to automatically discover and classify sensitive data across your multi-cloud environment. This minimizes performance impact on workloads by using cloud provider APIs rather than in-workload agents, though API calls do consume quotas and may incur data transfer costs for large-scale scans. You get complete visibility into data stores, databases, and file systems. The scanning happens through cloud provider APIs rather than requiring agents on every resource.
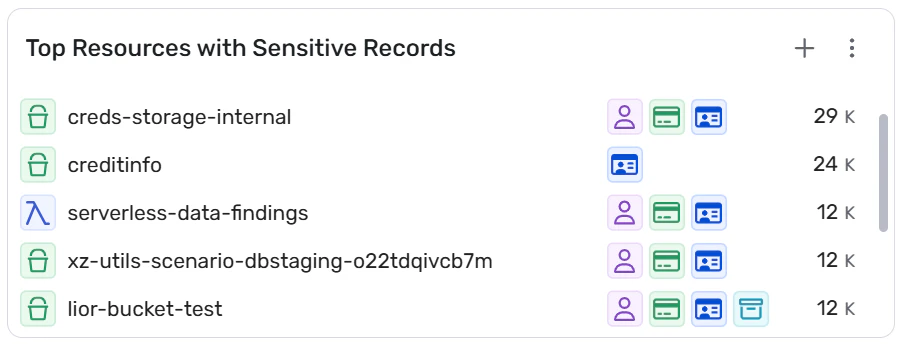
The Wiz Security Graph maps relationships between classified data, cloud resources, identities, and potential attack paths to surface toxic combinations and prioritize what to fix first. For example, it shows when a database containing customer PII is accessible by an over-privileged service account, running on an internet-exposed EC2 instance, with unpatched vulnerabilities—creating a critical attack path that requires immediate remediation. You see not just where sensitive data exists but how attackers could reach it. This attack path analysis identifies toxic combinations where classified sensitive data intersects with vulnerabilities, misconfigurations, or excessive permissions.
Get a demo to see how Wiz discovers and secures sensitive data across your cloud environment.
See Wiz in Action
Watch how Wiz discovers and classifies sensitive data across your multi-cloud environment.
