

組織がますますAIを製品や業務に組み込む中で、AIシステムのセキュリティ確保は最優先事項となっています セックオプス. しかし、AIのセキュリティは従来のソフトウェアのセキュリティとは異なり、AIはモデル、データパイプライン、コード、API、サードパーティ統合からなるエコシステムであり、これらすべてが新たなセキュリティおよびコンプライアンスリスクをもたらします。
AI アプリケーションがクラウドで実行されている場合、これらのリスクはさらに困難になります。 クラウドでホストされる AI モデルは、外部データセット、API、ユーザーと動的に対話するため、データ ポイズニング、プロンプト インジェクション、敵対的攻撃の影響を受けやすくなります。
従来のセキュリティテストでは、AIに対処するのに十分ではありません'の拡張された複雑な攻撃対象領域。 だからこそ、AIレッドチーミング――現実世界で敵対的攻撃を積極的にシミュレートする実践――が、現代のAIセキュリティ戦略において重要な要素として浮上し、 AIサイバーセキュリティ市場の成長.
で AIセキュリティ規制の強化 AI の導入が急増しているため、組織は進化する脅威や新たな機会に先んじるために AI レッドチームを採用する必要があります。
AIレッドチームとは何ですか?
AI レッド チームは、AI システムへの攻撃をシミュレートして、現実世界の条件下で脆弱性を特定するサイバーセキュリティの実践です。
標準的な安全性ベンチマークや制御されたモデル テストとは異なり、AI レッドチームはモデルの精度と公平性を評価するだけではありません。 AIモデルやデータパイプラインからクラウドホスト型AIサービス、ユーザーとAIの相互作用に至るまで、AIライフサイクルとサプライチェーン全体を精査し、すべてのコンポーネントが潜在的な敵に対して強靭であることを保証します。
対立的な姿勢を取ることで、AIレッドチーミングはモデルトレーニング、推論パイプライン、リアルタイムユーザーインタラクションなどを通じて隠れたセキュリティの弱点を積極的に発見します。 これは静的なモデル評価を超えて、AI システムが動的な現実世界の状況でも回復力を維持することを保証します。
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

AIレッドチームはどのようなテストを通常行いますか?
効果的な AI レッドチームには、企業展開の拡大する攻撃対象領域をカバーするために、技術的側面と運用的側面の両方にまたがる包括的なアプローチが必要です。 主なテスト分野は次のとおりです。
バイアス & 公平性テスト: AI モデルが、ストレスや敵対的なプレッシャーにさらされている場合など、差別的または偏った出力を生成するかどうかを評価します
データプライバシー侵害: リスクの特定 データリーク または不正アクセスを防止し、機密情報がデータパイプライン全体にわたって保護されることを保証します
人間とAIの相互作用リスク: AIシステムが悪意あるまたは予期しないユーザー入力や使用にどのように反応するかをテストし、これは脆弱性の検出に不可欠です。 プロンプトインジェクション
対抗的ML防御: プロンプトインジェクションなどの標的型敵対攻撃に耐えるAIシステム能力を評価します。 データポイズニング
追加のテストエリアには、ストレス下でのパフォーマンス、インテグレーションの脆弱性分析、およびシナリオ固有の脅威モデリングが含まれます。
これらのテストは、継続的な再トレーニングとモデルのドリフトにより動的で適応性の高いセキュリティ対策を必要とする AI システムの進化し続ける性質を考慮する必要があります。 AIは常に進化しているため、組織は強健な測定や対策戦略に投資し、先んじて行動する必要があります。 AIのセキュリティリスク.
AIレッドチーミングの目的は何ですか?
AI レッドチームは、AI システムの欠陥を強調 (および修正) して AI システムの回復力と信頼性を高めることで、ユーザーと企業を AI の悪用から保護することを目的としています。 AI レッドチーム化の主な目的は次のとおりです。
リスクの特定: 攻撃者が悪用する前にAIの脆弱性を検出して対処する
レジリエンスの構築: 敵対的な脅威に対するAIモデルとインフラストラクチャの強化
規制の整合性: コンプライアンス要件の遵守、特に EU AI法 および 米国ホワイトハウスのAIに関する大統領令
公的信頼: AI が安全で信頼性が高く、倫理基準に準拠していることを確認する
AIレッドチーミングをより広範な組織に統合する AIリスク管理 戦略および AIガバナンスの枠組み 組織全体で長期的かつ積極的なセキュリティを達成するために極めて重要です。
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

AI向けのレッドチーミングは従来のレッドチーミングとどう違いますか?
AI レッド チームと従来のレッド チームはどちらも、 攻撃者が脆弱性を悪用する前に脆弱性を特定する、それらは異なります 基本的には、範囲、方法論、目的.
従来の赤チーム活動:インフラストラクチャ、ネットワーク、アプリケーションに焦点を当てています
従来のレッドチームは、組織のITインフラストラクチャ、アプリケーション、および従業員に対する現実世界のサイバー攻撃をシミュレートします。 主な目標は、以下をターゲットにして、セキュリティ防御が敵対者に対してどの程度耐えられるかを評価することです。
ネットワークセキュリティ: 構成ミス、権限昇格、ラテラルムーブメントの悪用
アプリケーションのセキュリティ: SQLインジェクション(SQLi)などのWebアプリの脆弱性の特定、 リモート・コード実行 (RCE)、および XSS (クロスサイト スクリプティング)
ソーシャルエンジニアリング: 従業員を操作して認証情報を公開したり、フィッシングリンクをクリックさせたりする
従来のレッドチームは、MITRE ATTなどの業界標準に従って明確に定義されています&CK、NIST 800-53、および OSSTMM。 発見された脆弱性には、多くの場合、明確な修正 (ソフトウェアのパッチ適用、構成の更新、ユーザーの認識の向上) があります。
AIレッドチーミング:従来のセキュリティを超えて攻撃対象面を拡大
AI レッドチームは、従来のセキュリティ上の懸念を超えて、AI システムによってもたらされる固有のリスクを考慮して拡張されます。 AIが実行されるインフラストラクチャを保護するだけでなく、AIモデル自体、そのデータパイプライン、API、およびリアルタイムの対話に対する敵対的攻撃をシミュレートします。
主な違い
データドリブンな脅威: 従来のソフトウェアの脆弱性とは異なり、AI の脅威はデータ操作、モデル ポイズニング、プロンプト インジェクションに由来します。
進化する攻撃対象領域: AI モデルは再トレーニング中に動的に変化するため、継続的なセキュリティ評価が必要です。
安全 & 倫理の重複: AI の脆弱性には、偏見、誤った情報、幻覚、信頼性の問題などが含まれます。'従来のサイバーセキュリティにおける典型的な懸念事項。
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
標準の AI モデルテストとはどのように異なるか
ほとんどの AI テストは、精度、バイアス検出、責任ある AI の原則に焦点を当てています。 ただし、AI レッド チームは実際の攻撃シナリオをシミュレートして、パフォーマンス ベンチマークを超えたセキュリティ ギャップを明らかにします。
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
AI レッドチーミングを AI リスク管理およびセキュリティガバナンスに統合することによって、企業は新たに浮上する脅威に先んじることができ、進化している規制(EU AI 法など)に遵守し、AI 駆動のアプリケーションにおける公衆の信頼を維持できます。
AI レッドチームの一般的な脆弱性と実際の使用例
AI は複雑ですが、現実世界の攻撃は、設定ミス、見落とされた弱点、または AI のセキュリティ衛生状態の悪用など、驚くほど単純であることがよくあります。 最も一般的な AI 攻撃には次のようなものがあります。
バックドア攻撃: AI システムに挿入された隠れたトリガーにより、攻撃者は出力を密かに操作し、不正な制御の手段を生み出す可能性があります。
プロンプトインジェクション: 悪意のある入力を作成することで、攻撃者は AI の応答を微妙に変更したり、トロイの木馬を信頼できるシステムに滑り込ませるのと同じように、意図しないデータ漏洩を引き起こしたりする可能性があります。
データポイズニング: 破損したトレーニング データを挿入すると、AI の動作が徐々に歪められ、攻撃者の目的に有利な方法で行動するように効果的に AI に教えることができます。
統合の弱点: API とクラウド接続の脆弱性により、システムが悪用にさらされ、攻撃者がセキュリティ対策を回避して重要なデータにアクセスできる可能性があります。
これらの脆弱性は単なる理論的なものではありません。 によって明らかになった実際のケースを探ってみましょう。 ウィズリサーチチーム、これらのリスクが鮮明に焦点を合わせています。
DeepSeekデータベースリーク: 最新の DeepSeek モデルの統合上の欠陥により、機密性の高い AI トレーニング データが漏洩しました。
🔍この実際の例は、その方法を示しています。… 新しい AI の脅威は、見落とされた API とモデル アクセスの設定ミスから発生する可能性があります。
SAP AI の脆弱性: SAP の AI システムの構成ミスにより、隠れたバックドア リスクが生じ、攻撃者が AI 出力を操作できる可能性があります。
🔍この実際の例は、その方法を示しています。…確立されたエンタープライズAIプラットフォームでさえ、セキュリティの盲点が存在します。
NVIDIA AI の脆弱性: NVIDIA の AI コンテナ ツールキットの弱点により、迅速なインジェクション攻撃が可能になり、インフラストラクチャ レベルでの AI セキュリティのギャップが露呈しました。
🔍この実際の例は、その方法を示しています。…入力ベースの攻撃を通じて攻撃者はAIの挙動を操作し、AI駆動の決定と出力に影響を与えることができます。
Hugging Face モデルのリスク: Hugging Face の人気のある AI-as-a-service プラットフォームのデータ ポイズニングの脆弱性により、攻撃者はトレーニング データに微妙で悪意のある変更を導入することができました。
🔍この実際の例は、その方法を示しています。…広く信頼されているAIサービスでさえ、敵対的データ操作に対して脆弱であることが強調されており、継続的なセキュリティテストが必要です。
その点に関しては AIセキュリティ、最も単純な失敗でさえ深刻な結果を生むことがあります。 組織には、本格的なセキュリティ侵害にエスカレートする前に、これらの問題をキャッチして修正するために、継続的かつプロアクティブな AI レッド チームが必要です。
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

AI レッドチーミングのベストプラクティス: 5ステップのフレームワーク
AIシステムを効果的にレッドチーム化するには、組織はスケーラブルで反復可能で、継続的に進化するセキュリティフレームワークを必要としています。 AI モデルは動的に再トレーニングと更新を行うため、静的なセキュリティ対策は効果がなくなります。 適切に構造化された AI レッド チーム プロセスにより、AI は敵対的攻撃、バイアスの悪用、設定ミスに対する回復力を維持できます。
ステップ1: AI レッドチーミングの範囲を定義する
AIセキュリティのテストを行う前に、組織は次のように定義する必要があります:
どのAIコンポーネントをテストする必要がありますか?
モデルの堅牢性、APIインテグレーション、クラウドベースのAIセキュリティ、トレーニングデータの整合性
どのような攻撃シナリオがありますか?
対敵ML攻撃(回避、毒物注入)、APIの不正利用、プロンプトインジェクション、サプライチェーンリスク
何のセキュリティ & コンプライアンス要件が適用されますか?
OWASP AIセキュリティ, NIST AI RMF, EU AI法, SOC 2, GDPR
ステップ2: AI敵対的テスト方法を選択して実装する
AIレッドチーミングは、ペネトレーションテストを超えるものであり、現実のAI脅威をシミュレートするために敵対的なML技術が必要です。
モデル中心のテスト (AIの堅牢性評価)
敵対的摂動テスト: AIをだまして誤分類させるための入力を生成
モデル反転 & 抽出: AI応答からプライベートな学習データを再構築する試み
データパイプラインのセキュリティテスト
データポイズニングシミュレーション: 悪意のあるトレーニングデータを注入すると AI の動作が歪むかどうかをテスト
バイアス & 公平性テスト: 攻撃者がAIモデルのバイアスを操作に悪用できるかどうかを評価します
人間と AI の相互作用 & API セキュリティ
プロンプトインジェクション攻撃: AI が操作された入力によって保護手段を無視するかどうかをテストします
API 悪用テスト: AIモデルのAPIの脆弱性(例:無制限のデータ取得)を調査します。
ステップ 3: スケーラビリティのためのAIレッドチーミングの自動化
クラウド規模のデプロイ全体で AI の脆弱性を手動でテストするのは非効率的です。 自動化は、大規模な敵対的攻撃のシミュレーションに役立ちます。
AI セキュリティを使用する & 敵対的テストツール
ガラク: LLMセキュリティのためのオープンソースの敵対的テストツール
PyRIT (生成 AI のための Python リスク識別): 回避攻撃とモデル抽出攻撃をシミュレート
マイクロソフトカウンターフィット: 機械学習モデルの AI セキュリティ テスト
敵対的ロバストネスツールボックス(ART): 敵対的なAIの攻撃と防御をシミュレートします
ステップ 4: 継続的な AI リスク監視を実装する & 応答
AIレッドチーミングは一度きりのテストではありません。AIモデルが更新され再トレーニングされるにつれて、継続的に進化する必要があります。
継続的なAIレッドチーミング戦略
AI 脅威インテリジェンスの共有を確立します。 MITRE ATLASとOWASP AI Top 10から進化する脅威を追跡します。
継続的な AI セキュリティ テストを採用する: CI/CD パイプラインに敵対的テストを統合します。
AIの自動リスクスコアリングを開発します。 リスクの高い AI の脆弱性に優先順位を付けて修復します。
ステップ5: AIレッドチーミングをガバナンスとコンプライアンスに合わせる
セキュリティだけでなく、AIレッドチーミングは規制的および倫理的AIガイドラインをサポートする必要があり、コンプライアンスを確保します。
主要な AI セキュリティ & コンプライアンス基準
NIST AI リスク管理フレームワーク (AI RMF): AI セキュリティのベスト プラクティス
EU AI 法: リスクの高い AI アプリケーションのコンプライアンス要件
SOC 2、GDPR、CCPA: AI 主導の個人データの保護
AIレッドチーミングを企業リスク管理 (ERM)に統合する
AI ガバナンス チームに調査結果を報告します。 倫理と責任ある AI の原則に準拠します。
部門横断的なコラボレーション: セキュリティ、データサイエンス、コンプライアンスの各チームをAIリスク管理に関与させます。


WizはどのようにしてあなたのAIセキュリティを強化しますか?
ウィズ 包括的なクラウドセキュリティプラットフォームを提供し、AIインフラのセキュリティを拡張して AIセキュリティ体制管理(AI-SPM).
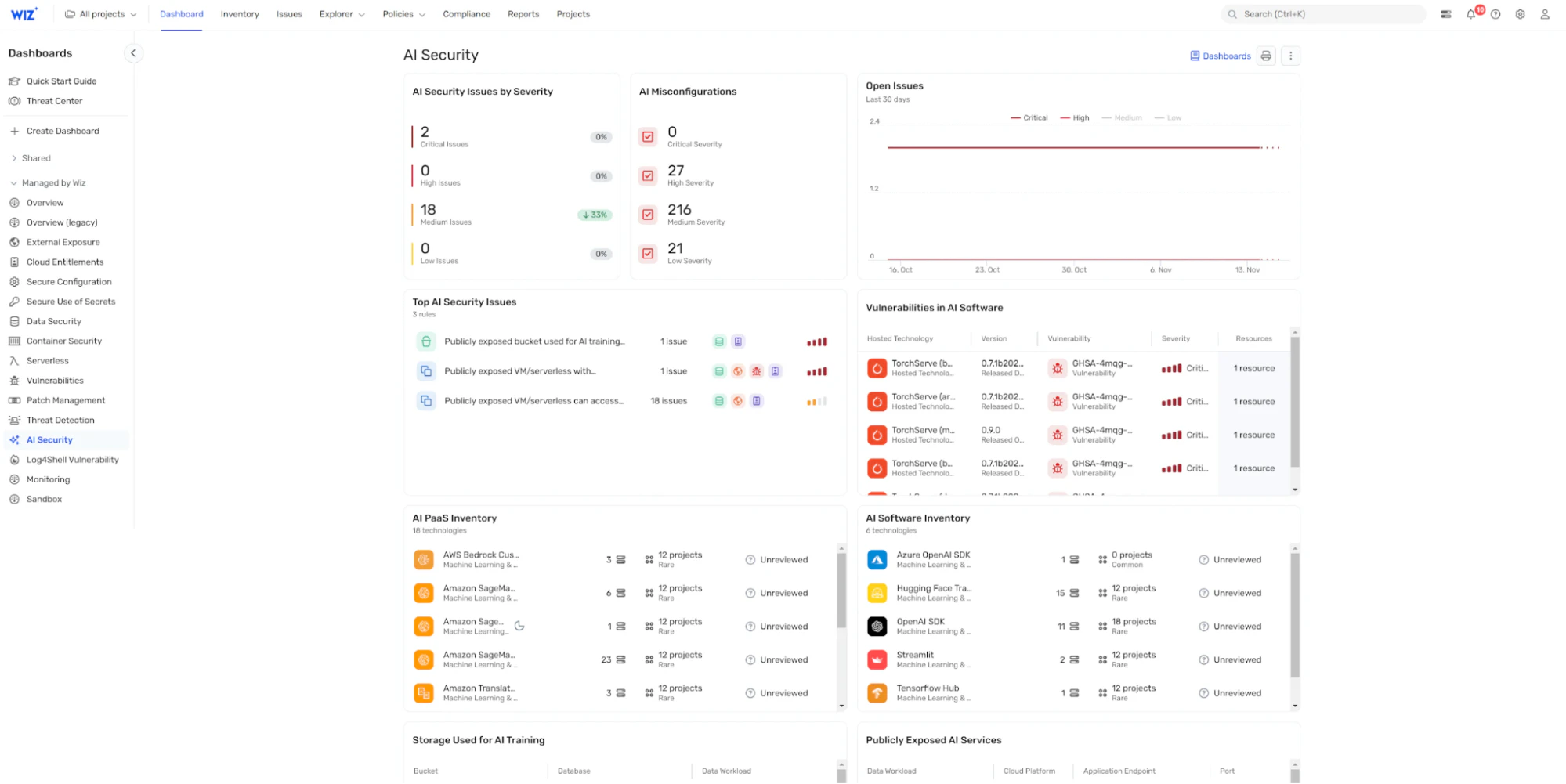
一元化された AI セキュリティ ダッシュボードを通じて、 ウィズAI-SPM 以下を提供します。
AI 部品表 (AI BOM): AI コンポーネントと依存関係の詳細なマップにより、エコシステム全体を明確に可視化できます
設定ミスの検出: AIパイプラインとクラウドサービス全体のセキュリティギャップを自動的に特定し、脆弱性がエスカレートする前に対処できるようにします
攻撃経路分析: 攻撃者がAIセキュリティリスクを悪用するために使用する可能性のあるルートを視覚化し、より多くの情報に基づいたリスク管理を可能にします
AI搭載調査: Mika AIを活用すれば、潜在的な脆弱性を迅速に調査し、複雑な攻撃シナリオを理解し、自然言語で実行可能な修復ガイダンスを得ることができます
自動応答: AIレッドチーミングが重大な脆弱性を発見すると、 Wiz SecOps AIエージェント 自動でトリアージ、調査、対応ワークフローを開始し、検出から修復までの時間を短縮できます
これらの機能を統合することで、Wiz AI-SPMはAIセキュリティのベストプラクティスを実施するだけでなく、継続的な監視と自動化されたリスク管理を効率化し、堅牢なAIガバナンスを保証します。
次のステップ
AI レッドチームは、特に規制要求が高まる中、AI 導入の保護に取り組んでいる組織にとって重要なセキュリティ機能になりつつあります。 この分野は進化し続けていますが、複雑な攻撃、コンテキストの相互運用性、標準化の欠如などの課題は依然として残っています。
Wizのようなセキュリティプラットフォームは、あなたの防御を促進し、継続的な改善を確保することで、AIセキュリティのベストプラクティスに先んじるのに役立ちます。もっと学びたいですか? を訪問してください
Wiz のようなセキュリティ プラットフォームは、防御を強化し、継続的な改善を確保することで、AI セキュリティのベスト プラクティスを先取りするのに役立ちます。 詳細を確認する準備はできましたか? 詳しくはこちらをご覧ください Wiz AI-SPM、または ライブデモぜひお会いできれば嬉しいです。
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
