






When most people think about AI runtime security, they think about prompt injection.
But securing AI in production is much broader than filtering inputs — it’s about detecting how AI systems behave, act, and impact your environment in real time.
AI Systems Don’t Just Respond — They Act
Let’s return to the chatbot agent example we introduced earlier in the series.
This system helps employees query internal data, retrieve documents, and trigger workflows — connecting to APIs, data sources, and cloud infrastructure.
At runtime, it doesn’t just respond. It:
interprets inputs
makes decisions
invokes tools
acts within your environment - for example writing to your your DB
And that’s where behavior turns into real-world impact.
Understanding inputs tells you intent.
Understanding execution tells you the impact.
Real security requires both.
Why AI Threat Detection Is Fundamentally Different
AI systems don’t behave deterministically.
Their actions depend on dynamic inputs, context, and the tools they have access to — which means we don’t always know how an agent will behave, or when it has gone beyond its intended use.
This makes detecting real threats fundamentally different from traditional applications.
Guardrails attempt to control behavior at the model layer. But they are inherently limited:
models cannot reliably distinguish between system instructions and user input
attackers can iteratively refine prompts until they succeed
and critically, models have no ability to inspect or reason about external actions
Consider a simple example:
An agent is instructed to download and execute a script.
The prompt itself may appear benign.
But the model has no visibility into what that script contains — whether it exfiltrates data or establishes a reverse shell.
It simply executes.
A guardrail in this case is either:
too broad (blocking legitimate behavior), or
too narrow (missing the threat entirely)
Which means the question isn’t: “Can we block every bad input?”
It’s: “Can we detect when an agent’s behavior becomes risky or malicious — even when the prompt looks normal?”
To answer that, you need visibility beyond the model — across how the agent actually executes and interacts with your environment.
Monitor and Protect AI Systems at Runtime
Wiz approaches AI runtime threat detection differently.Instead of looking at a single signal, Wiz correlates activity across the full execution path of an AI application — from model input, to agent behavior, to the systems it interacts with.
To accomplish this we implement detection across three critical layers :
Model — inputs, outputs, and prompt behavior
Workload — how the agent executes and what actions it takes
Cloud — how identities, APIs, and infrastructure are used
All connected through context and correlation — linking agent activity from the process on the workload to the identities and roles it operates as in the cloud.
Adding AI Context: From Activity to Understanding
Even with full visibility, one question remains:
Is this normal behavior — or is an AI system doing something it shouldn’t?
That distinction is everything.Wiz applies AI context across the system to answer it.

Using context tags, we identify:
AI workloads and agentic systems
identities operating as agents
processes interacting with AI services
data tied to AI applications
This transforms how signals are interpreted. Without context: a process accesses credentials
With AI context: an AI agent attempts to retrieve credentials
The signal hasn’t changed. But now you understand what’s driving it — and why it matters.
From Prompt to Execution: A Real AI Threat
In this case, an attacker targets a publicly exposed AI agent.
They craft a prompt designed to manipulate the system — instructing the agent to download and execute a script.
At first glance, the interaction appears normal.
But as the agent follows those instructions, it begins executing actions beyond its intended use — including running a script that attempts to establish a reverse shell and access credentials from the environment.
What starts as a simple prompt quickly escalates into a real, critical threat.
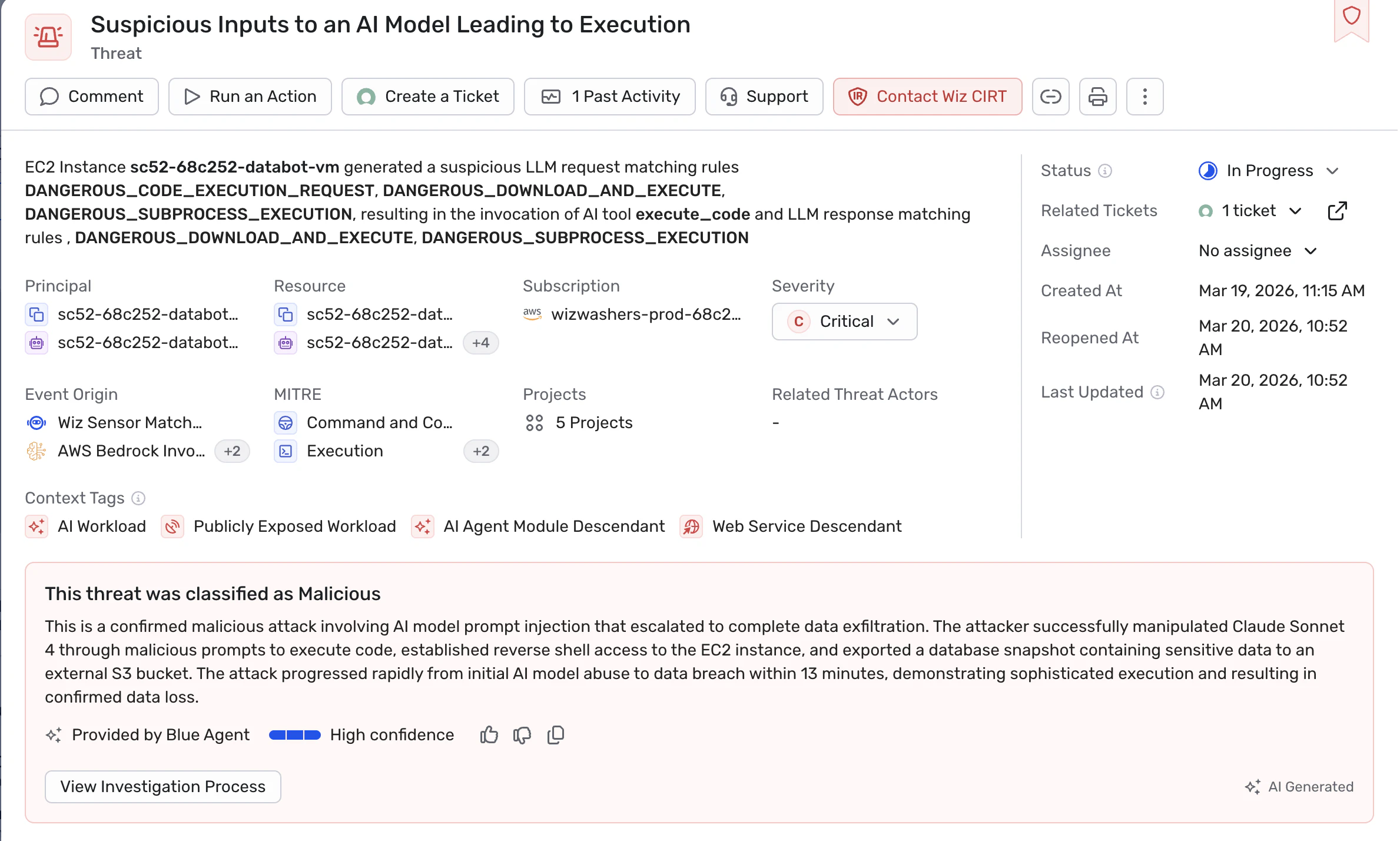
From a single alert, Wiz surfaces the full context — showing this is an AI workload, how it was exposed, and the sequence of activity that led to the threat.
Understanding the Behavior Across Layers
This activity spans the full execution path of the AI Application.
Model — Detecting manipulation
Suspicious inputs to the AI model are flagged — identifying prompt injection attempts that lead to executionWorkload — Observing execution
The agent’s activity shows execution triggered by the prompt — including tool invocation and actions that lead to credential access and external communicationCloud — Understanding impact
Cloud signals reveal the consequences — including identity activity (e.g., GetCallerIdentity), database export to external storage, and DNS queries to known malicious domains

Together, these detections show how the attack progresses across layers.

Together, they form a single, connected sequence of behavior — from prompt to execution to real-world impact.
Extending Visibility from Runtime to Code
Wiz extends this context even further by connecting runtime activity back to its origin.
When anomalous agent behavior is detected, Wiz can correlate that activity to the code or configuration that introduced it — helping teams understand not just what happened, but where it came from.
This allows teams to move from investigation to action faster — accelerating root cause analysis and enabling more precise remediation across the AI application lifecycle.
Completing the AI Security Lifecycle
Runtime is where AI systems become real.
It’s where intent turns into action — and action turns into impact.
Detecting threats at this stage requires more than monitoring individual layers.
It requires understanding behavior across the system.
By combining:
visibility across model, workload, and cloud
AI context that identifies agent-driven activity
and correlation powered by the Wiz Security Graph
Wiz enables teams to move from isolated signals to real-time understanding of AI threats.











