

What are AI guardrails?
AI guardrails (also called LLM guardrails or GenAI guardrails) are preventive safety controls that constrain an AI system’s behavior within defined policy boundaries. They shape what a model can see, do, and return, reducing the risk of harmful, biased, or policy-violating outputs during model execution.
Guardrails are preventive controls applied before and during inference. They work alongside detective controls such as logging, monitoring, and alerting, which identify violations after they occur, and governance controls such as policies, documentation, and audit requirements.
In practice, three layers of guardrails are used together:
Input guardrails: Filter, validate, and reshape prompts before they reach the model.
Processing guardrails: Control which context, data, and tools the model can access, and enforce business rules during reasoning.
Output guardrails: Evaluate the model’s response and block, modify, or reject it before returning it to the user.
These guardrails differ from traditional application security. Traditional controls protect deterministic code and structured inputs like form fields or JSON. AI guardrails must manage non-deterministic systems and natural language, where the same request can produce different outputs every time and where model behavior can be influenced through embedding context or prompt injection.
For enterprises – especially when handling regulated data or customer-facing workflows – guardrails are how you turn a prototype into a production system. They enforce your safety, security, and compliance requirements while still enabling teams to build on top of powerful foundation models.
AI Security Starter Pack
Get the essential templates and checklists to secure AI workloads from code to runtime.

Why AI guardrails matter for cloud security
When you deploy AI in the cloud, you combine two challenging properties: untrusted natural language inputs and access to sensitive data and systems. A model can be influenced by arbitrary text, yet it runs on shared infrastructure, behind public or internal APIs, and often with access to real business data. That breaks many of the assumptions behind traditional security controls.
Cloud AI systems handle sensitive data such as personal information, financial records, or proprietary documents. Traditional controls like network rules and firewalls cannot evaluate prompts, context windows, or model behavior, so they don’t prevent attacks like prompt injection, retrieval manipulation, or unexpected tool use. Major cloud providers now include safety controls in their AI services (e.g., Guardrails for Amazon Bedrock, Azure OpenAI content filters, and Google Vertex AI safety filters), but these need to be combined with organization-specific policies, IAM controls, and runtime monitoring to be effective.
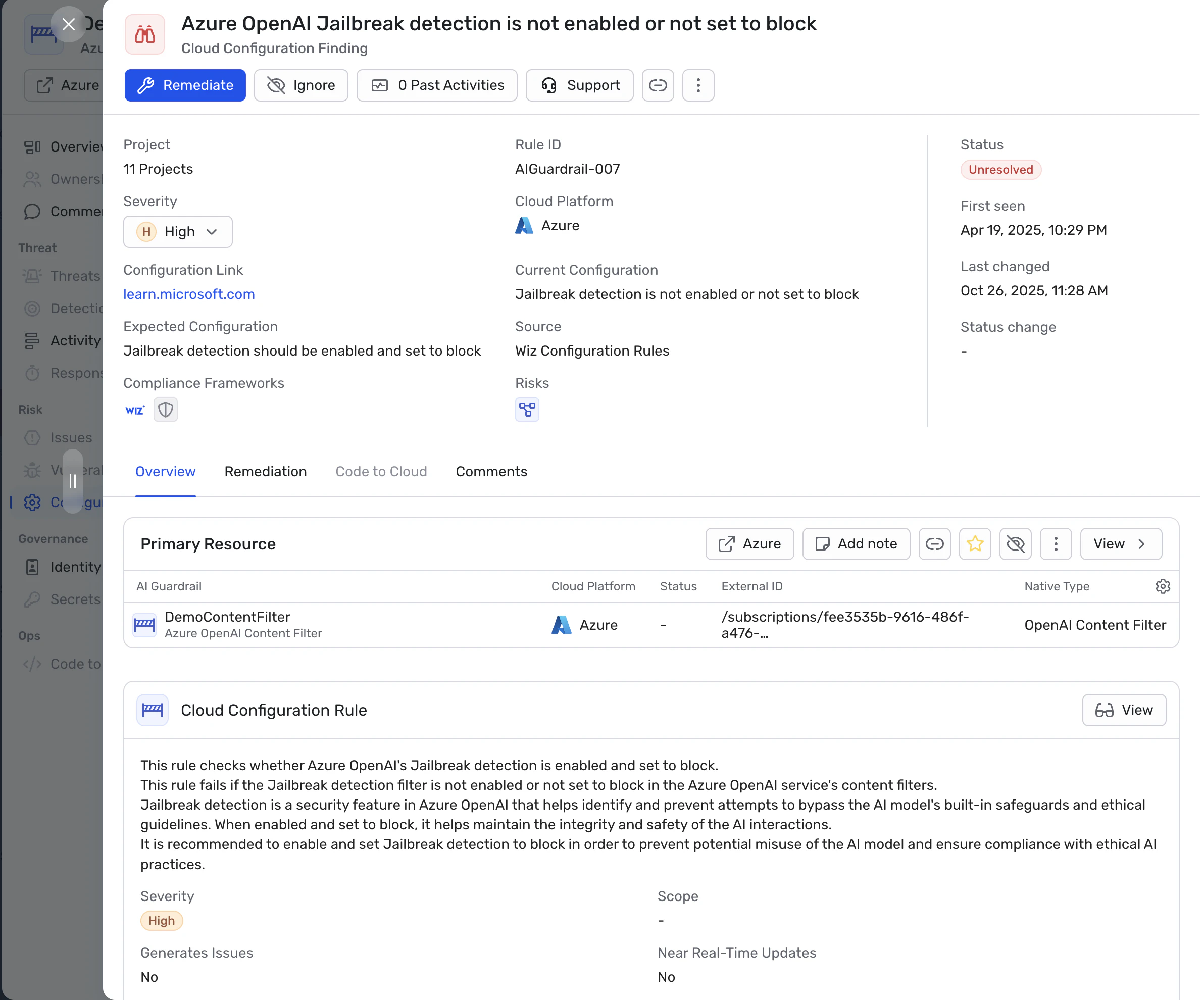
In a cloud environment, your AI attack surface now includes:
Models: hosted LLMs, fine-tuned models, and custom embeddings.
Training and inference data: data lakes, vector stores, and logs that may contain confidential content.
Inference endpoints: public and internal APIs for chat, search, or tool calls.
Agents and orchestration: code that allows models to call internal tools or external services.
Model artifacts: weights, checkpoints, and container images that can be tampered with in the supply chain.
Without guardrails, normal AI behavior can become a security incident: a prompt injection attack pulls sensitive data from a vector store, an agent executes an unintended action against internal APIs, or a misconfigured endpoint exposes customer information. These failures create both security risk and brand risk, because the model’s output is directly visible to users.
Enterprises in regulated industries already use multi-layer guardrails to keep deployments safe. For example, automotive manufacturers run cloud-based assistants with strict input filtering, controlled access to vehicle data, and runtime checks on what responses can be returned to drivers. This lets them adopt advanced models while still enforcing strict safety and compliance boundaries.
Types of AI guardrails
Practical guardrails work as a pipeline. Inputs are checked before they reach the model, the model runs within a controlled execution context, and outputs are validated before they reach users or downstream systems.
1. Input guardrails
Input guardrails evaluate and reshape incoming requests before inference. This is the first prevention layer against unsafe behavior.
Common input guardrails include:
Prompt injection and jailbreak detection: Identify attempts to override system instructions or access restricted data.
Sensitive data scanning: Detect and redact PII, PHI, credentials, or keys within prompts.
Illegal or disallowed content: Block requests that seek harmful instructions or prohibited material.
Abuse and misuse controls: Enforce rate limits, identify anomalous usage, and block brute-force attempts against safety filters.
In practice, input guardrails may reject a prompt, request clarification, or sanitize the input (e.g., masking identifiers) before sending it to the model.
2. Processing guardrails
Processing guardrails shape the execution context in which the model operates. They determine what the model is allowed to access and how it can act, beyond the text of the prompt.
Processing guardrails typically include:
Context controls: Restrict which documents, fields, or logs can be provided to the model for each request.
RAG safety: Limit which collections a retrieval pipeline can query, how many results it can use, and apply filtering to retrieved content.
Policy enforcement: Encode business rules such as “this model cannot access production payment APIs” or “only return data from the same region.”
Identity and least-privilege controls: Use IAM policies to restrict the model’s service account from accessing unauthorized data sources or services.
Tool and agent guardrails: Define which tools an AI agent may call, which actions require human approval, and how parameters are validated before execution.
Cloud provider safety features (e.g., content filters or topic filters in Azure OpenAI, Bedrock, or Vertex AI) can support this layer, but should be combined with organization-specific rules and runtime access controls.
3. Output guardrails
Output guardrails evaluate the model’s response before it is returned to the user or used by another system.
Common output guardrails include:
Toxicity and content safety: Detect hate, harassment, self-harm content, or other disallowed categories.
Hallucination detection: Compare claims against trusted sources or retrieved context to identify unsupported statements.
Sensitive data leakage: Scan for PII, PHI, credentials, or secrets in outputs and remove or block as needed.
Brand and policy alignment: Adjust tone, include required disclosures, and enforce compliance rules in regulated domains.
Output guardrails can block the response, request clarification, or rewrite the response while preserving accurate content.
Many teams combine rule-based checks (allow/deny patterns, redaction rules, prompt policies) with ML-based classifiers (toxicity detection, jailbreak detection, PII detection). Others wrap vendor models with a consistent safety layer across providers using moderation APIs or open-source guardrail frameworks.
AI risks that guardrails are designed to address
AI guardrails exist to prevent specific classes of failures. Understanding these threats helps you design controls that protect both your data and your infrastructure.
Most AI risks fall into four categories:
1. Manipulating model behavior
Attackers attempt to influence or override model instructions to produce unsafe actions or outputs.
Prompt injection: Crafting inputs that override system instructions and extract data or trigger disallowed actions.
Indirect prompt injection: Embedding malicious instructions inside documents or data that the model later ingests through retrieval or context.
Jailbreaks: Forcing the model to ignore built-in safety constraints using role-playing, translation, or other indirect request patterns.
Adversarial prompts: Subtle prompt patterns designed to cause incorrect outputs without appearing malicious.
These risks are primarily addressed through input guardrails (filtering, sanitization) and processing guardrails (policy enforcement during execution).
2. Manipulating data and context
Instead of attacking the model directly, adversaries target the data pipelines that shape model behavior.
Data poisoning: Injecting malicious or biased data into training or fine-tuning sets so the model learns unsafe patterns.
Context poisoning: Manipulating the documents or retrieval index used by RAG systems to influence responses.
RAG poisoning: Controlling which documents are retrieved so the model repeats misleading information.
Fine-tune hijacking: Compromising fine-tuning jobs to insert backdoors.
These threats require processing guardrails (RAG controls, context filters) and governance controls on how training and ingestion pipelines are secured.
3. Extracting sensitive information and IP
Attackers attempt to recover data from the model or its supporting components.
Model extraction: Reproducing a proprietary model’s behavior through repeated queries.
Membership inference: Determining whether specific records were part of training data by probing model responses.
Sensitive data leakage: The model reproduces memorized content from logs, training data, or vector stores.
These risks are mitigated through input/output guardrails (PII detection, redaction), and processing guardrails that restrict access to sensitive data.
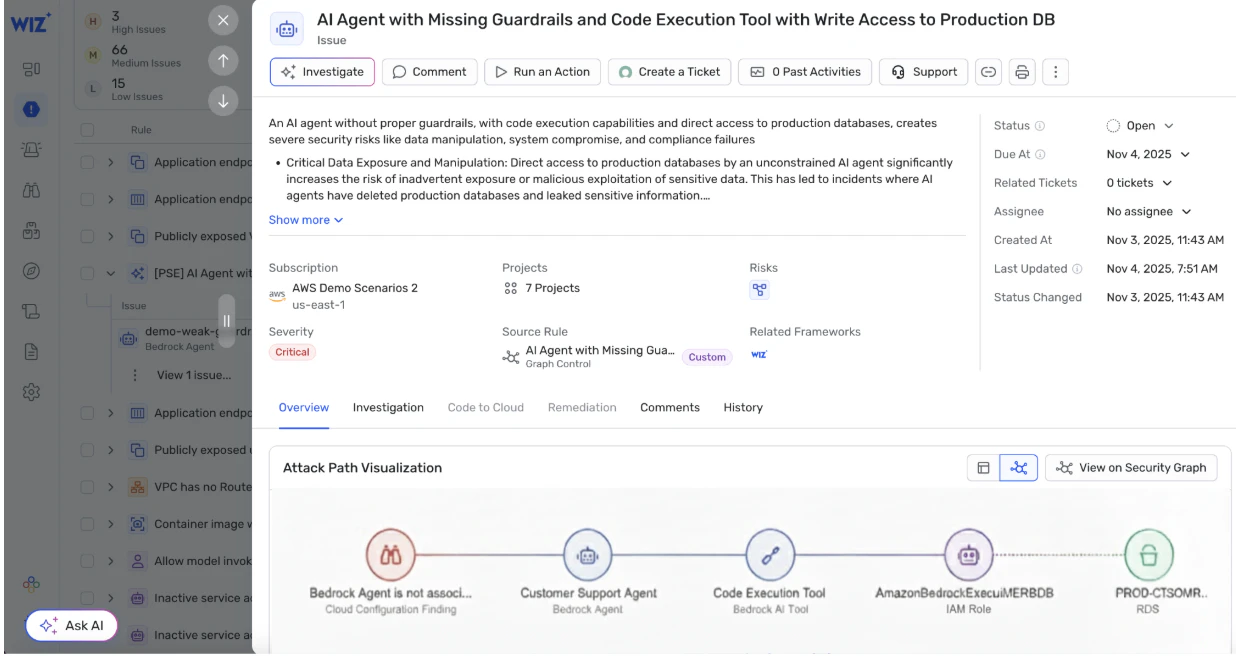
4. Exploiting access through agents and tools
The fastest-growing category of risk involves models that can perform actions, not just generate text.
Inside MCP Security: A Field Guide
Explore emerging risks in agent and tool-calling architectures and how to secure them.

Over-permissioned agents: Agents that have broad access to internal APIs, databases, or cloud services.
Tool abuse: Using allowed tools in unexpected ways, leading to unauthorized operations.
Identity escalation: A model acting under a privileged service account without proper isolation.
These risks require processing guardrails (least-privilege IAM, tool allowlists, approval workflows) and runtime monitoring to detect unexpected behaviors.
How AI guardrails work in practice
In a real system, guardrails are not a single filter you add at the end. They are multiple controls applied across the request path, from the API entry point to output validation. Each layer removes a different class of risk.
A common inference flow with guardrails looks like this:
User request: A user sends a prompt or API call.
Input guardrails: The request is validated, sanitized, or rejected before it reaches the model.
Context construction (RAG): If retrieval is used, only approved data sources and documents are fetched and filtered.
Policy enforcement: Business rules and security checks shape what the model can access and which tools it may call.
Model inference: The model generates a response within these constraints.
Tool execution (agents): If the model requests actions, parameters are validated and executed under least privilege, or require human approval.
Output guardrails: The response is checked for safety, supported claims, sensitive data, and compliance before returning to the user.
Logging and monitoring: The full interaction is logged for analysis, alerting, and improvement.
This pattern lets you prevent unsafe behavior before it occurs, and detect issues that slip through.
Where guardrails are enforced
Guardrails can be integrated at several points in your architecture:
API gateway: Authentication, rate limiting, coarse content checks.
Orchestration layer: Chains, middleware, and validators that implement prompt filters, context controls, and policy logic.
Cloud services: Provider safety filters (e.g., toxicity or topic filters) that run during inference.
Identity layer: IAM policies that define which data sources, APIs, and tools the model’s service account can access.
Tool boundaries: Validation and approval flows for agent actions.
Vector stores: Access controls and document-level filtering to prevent context poisoning or data leakage.
Output filters: Classification models or rules that block or rewrite unsafe responses.
Each layer is designed to remove a different class of risk, so failures in one layer are caught by another.
How Wiz enables comprehensive AI guardrails across the security lifecycle
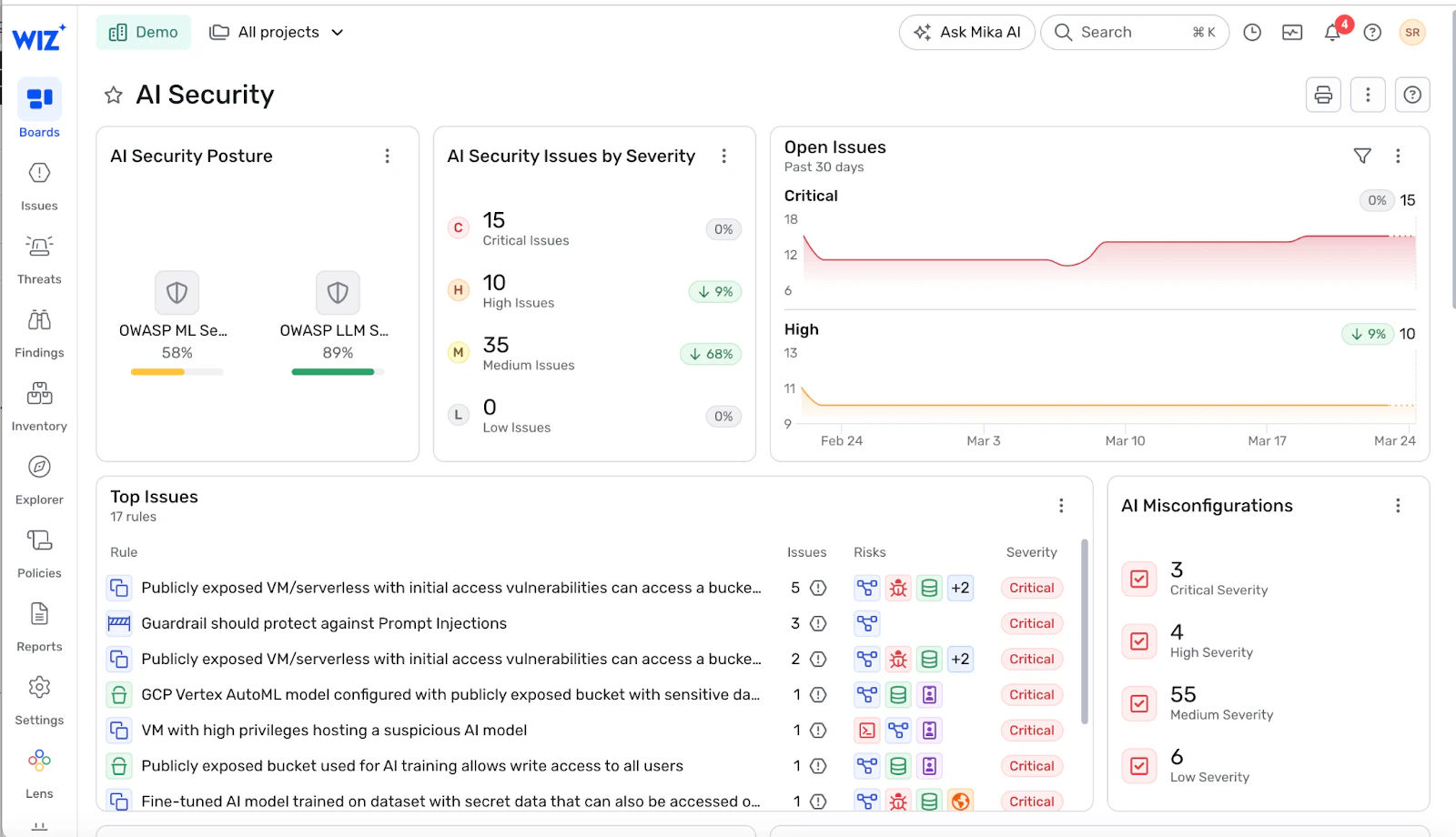
Wiz AI-SPM gives you end-to-end visibility into your AI estate across AWS, Azure, and GCP – from managed AI services and inference endpoints to retrieval pipelines and the identities behind them. Wiz detects misconfigurations in platforms like Amazon SageMaker, Azure OpenAI, and Google Vertex AI that can bypass your guardrails, such as public endpoints with access to sensitive data or agents running under over-permissioned roles.
The Wiz Security Graph maps how infrastructure, identities, data, and AI workloads interact. That lets you spot toxic combinations hidden in the environment – for example, an exposed endpoint talking to a vector store full of sensitive training data, reachable through a broad service account attached to an agent. Wiz surfaces these risks so you can remove the bypass paths that sit underneath your guardrails.
Wiz extends those controls across the development and runtime lifecycle. Wiz Code scans IaC and application code defining your AI infrastructure to catch issues like hardcoded model keys, risky network rules, or misconfigured AI services before deployment. Wiz Defend monitors AI-related workloads at runtime for unusual API patterns, unauthorized data access, or potential exfiltration attempts tied to model behavior. Built-in DSPM capabilities classify sensitive data used in training or inference and show how it flows into models and endpoints, so you can build data-focused guardrails grounded in reality.
Because all of this context sits in one platform, organizations can enforce unified AI security policies across code repositories, CI/CD pipelines, cloud resources, and runtime environments. In other words, Wiz provides guardrails for your guardrails –ensuring the infrastructure, data paths, and identities around your models are properly configured, monitored, and protected. Want to see how unified AI security works across your environment? Get a demo to explore how Wiz maps and protects your AI estate end to end. Ready to see unified AI security in action across your environment? Request a demo to explore how Wiz can secure your cloud environment.
Want to see it in action?
See how Wiz maps and protects your AI estate across code, cloud, and runtime.
