LLM Jacking이란 무엇입니까?
LLM 재킹은 사이버 범죄자가 기업의 클라우드 기반 LLM(대규모 언어 모델)을 조작하고 악용하는 데 사용하는 공격 기술입니다. LLM 재킹은 클라우드 계정 자격 증명을 훔쳐 판매하여 기업의 LLM에 악의적으로 액세스할 수 있도록 하는 동시에 피해자가 자신도 모르게 소비 비용을 부담하는 것을 포함합니다.
우리의 연구 10개 기업 중 7개 기업이 Amazon Bedrock 및 Amazon Bedrock을 포함한 클라우드 제공업체의 생성형 AI(GenAI) 제품을 포함한 인공 지능(AI) 서비스를 활용하고 있습니다. 세이지메이커, Google Vertex AI 및 Azure OpenAI 서비스. 이러한 서비스를 통해 개발자는 Claude, Jurassic-2, GPT 시리즈, DALL-E, OpenAI Codex, Amazon Titan 및 Stable Diffusion과 같은 LLM 모델에 액세스할 수 있습니다. LLM 모델에 대한 액세스를 판매함으로써 사이버 범죄자는 여러 조직 기둥에 걸쳐 해로운 도미노 효과를 일으킬 수 있습니다.
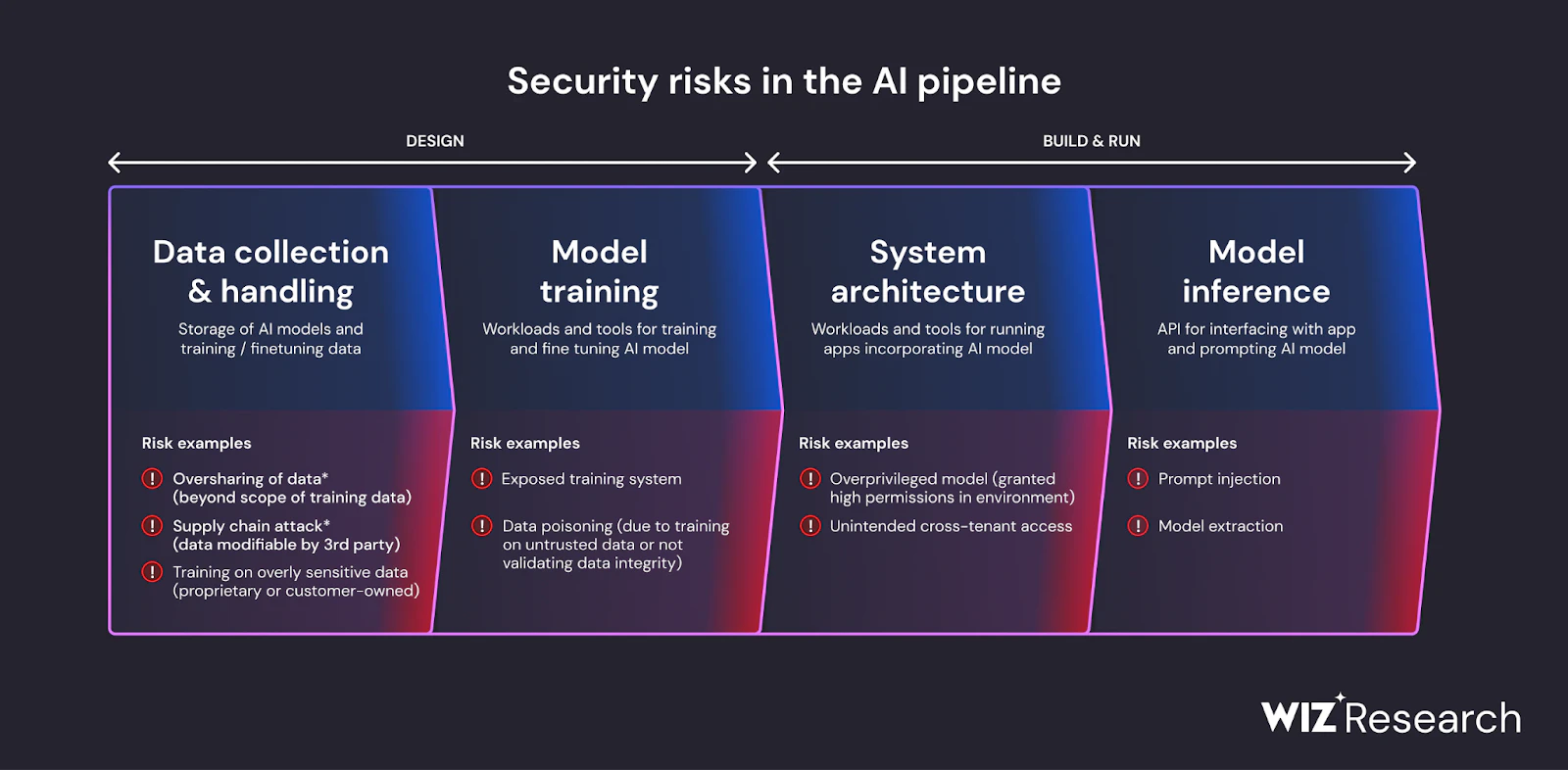
위협 행위자는 데이터를 훔치기 위해 LLM 재킹 공격을 수행할 수 있지만 더 큰 사이버 범죄자 웹에 LLM 액세스 권한을 판매하는 경우가 많습니다. 이는 잠재적인 공격의 범위와 규모를 확장하기 때문에 훨씬 더 위험합니다. 클라우드 기반 LLM 자격 증명을 구매하는 모든 사이버 범죄자는 기업의 LLM을 하이재킹하여 고유한 공격을 오케스트레이션할 수 있습니다.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

LLM 재킹 공격의 잠재적 결과는 무엇입니까?
소비 비용 증가
사이버 범죄자가 LLM 재킹 공격을 수행할 때 가장 먼저 발생하는 것은 과도한 소비 비용입니다. 이는 클라우드 기반 GenAI 및 LLM 서비스가 유용하기는 하지만 기업이 호스팅하는 데 상당한 비용이 들 수 있기 때문입니다. 따라서 악의적 사용자가 이러한 서비스에 대한 액세스 권한을 판매하고 은밀하고 악의적인 사용을 가능하게 하면 비용이 합산될 수 있습니다. 에 따르면 연구자, LLM 재킹 공격은 하루에 최대 $46,000의 소비 비용을 초래할 수 있습니다. 이 금액은 LLM 가격 모델에 따라 변동될 수 있습니다.
엔터프라이즈 LLM의 무기화
기업의 LLM 모델에 무결성이 부족하거나 강력한 가드레일이 없는 경우 해로운 결과를 생성할 수 있습니다. 공격자는 조직별 LLM 모델을 하이재킹하거나 LLM 아키텍처를 리버스 엔지니어링함으로써 기업의 GenAI 에코시스템을 악의적인 공격 및 활동의 무기로 사용할 수 있습니다. 예를 들어, 위협 행위자는 엔터프라이즈 LLM을 조작하여 백엔드 및 고객 대면 사용 사례 모두에 대해 거짓 또는 악성 출력을 생성하도록 할 수 있습니다. 기업이 이러한 종류의 하이재킹을 식별하는 데 시간이 걸릴 수 있으며, 그 때까지 피해가 발생하는 경우가 많습니다.
기존 LLM 취약점의 악화
LLM 채택은 내재된 보안 문제를 특징으로 합니다. 에 따르면 오와스프, 상위 10개 LLM 취약점에는 프롬프트 인젝션(prompt injection), 훈련 데이터 중독(training data poisoning), 모델 서비스 거부(model denial of service), 민감한 정보 공개(sensitive information closure), 과도한 에이전시(excessive agency), 과잉 의존(overreliance), 모델 도난(model theft) 등이 있습니다. 사이버 범죄자가 LLM 재킹 공격을 사용하면 LLM과 관련된 내재된 위험과 취약성이 크게 악화됩니다.
높은 수준의 강설 효과
기업이 미션 크리티컬 컨텍스트에서 GenAI 및 LLM을 얼마나 빠르게 통합하고 있는지 고려할 때 LLM 재킹 공격은 심각하고 높은 수준과 장기적 영향을 미칠 수 있습니다. 예를 들어, LLM 재킹은 기업의 공격 표면을 확장하여 데이터 침해 및 기타 주요 익스플로잇을 초래할 수 있습니다.
또한 AI 숙련도는 오늘날 기업의 중요한 평판 지표이기 때문에 LLM 재킹 공격은 동료와 대중의 신뢰와 존경을 잃을 수 있습니다. 낮은 이윤, 데이터 손실, 다운타임 비용 및 법률 비용을 포함한 LLM 재킹의 파괴적인 재정적 여파를 잊지 마십시오.
LLM 재킹 공격은 어떻게 작동하나요?
원칙적으로 LLM 재킹은 다음과 같은 공격과 유사합니다. 크립토재킹(Cryptojacking), 위협 행위자가 기업의 처리 능력을 사용하여 비밀리에 암호화폐를 채굴하는 곳입니다. 두 경우 모두 위협 행위자는 조직의 리소스와 인프라를 사용합니다. 그러나 LLM 재킹 공격의 경우 해커의 조준선은 클라우드 호스팅 LLM 서비스와 클라우드 계정 소유자에게 단단히 집중됩니다.
LLM 재킹이 어떻게 작동하는지 이해하기 위해 두 가지 관점에서 살펴보겠습니다. 먼저 기업이 LLM을 사용하는 방법을 살펴본 다음 위협 행위자가 LLM을 악용하는 방법에 대해 살펴보겠습니다.
기업은 클라우드 호스팅 LLM 서비스와 어떻게 상호 작용하나요?
대부분의 클라우드 제공업체는 애자일 LLM 채택을 위해 설계된 사용하기 쉬운 인터페이스와 간단한 기능을 기업에 제공합니다. 그러나 이러한 타사 모델은 자동으로 사용할 준비가 되지 않습니다. 먼저 활성화가 필요합니다.
LLM을 활성화하려면 개발자는 클라우드 제공업체에 요청해야 합니다. 개발자는 간단한 요청 양식을 포함하여 몇 가지 다른 방법으로 요청할 수 있습니다. 개발자가 이러한 요청 양식을 제출하면 클라우드 제공업체는 LLM 서비스를 빠르게 활성화할 수 있습니다. 활성화 후 개발자는 명령줄 인터페이스(CLI) 명령을 사용하여 클라우드 기반 LLM과 상호 작용할 수 있습니다.
클라우드 공급자에게 활성화 요청 양식을 보내는 프로세스는 방탄 보안 계층으로 보호되지 않는다는 점을 명심하십시오. 위협 행위자도 쉽게 동일한 작업을 수행할 수 있으므로 기업은 추가적인 종류의 AI 및 LLM 보안에 집중해야 합니다.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

위협 행위자는 LLM 재킹 공격을 어떻게 수행합니까?
기업이 일반적으로 클라우드 호스팅 LLM 서비스와 상호 작용하는 방식을 이해했으므로 이제 위협 행위자가 LLM 재킹 공격을 촉진하는 방법을 살펴보겠습니다.
위협 행위자가 LLM 재킹 공격을 조정하기 위해 수행하는 단계는 다음과 같습니다.
클라우드 자격 증명을 판매하려면 위협 행위자가 먼저 자격 증명을 훔쳐야 합니다. 연구원들이 LLM 재킹 공격 기법을 처음 발견했을 때, 그들은 도난당한 자격 증명을 추적하여 취약한 버전의 Laravel(CVE-2021-3129 (영문)).
위협 행위자가 취약한 시스템에서 자격 증명을 훔치면 불법 마켓플레이스에서 다른 사이버 범죄자에게 판매할 수 있으며, 다른 사이버 범죄자는 이를 구매하여 보다 지능적인 공격에 활용할 수 있습니다.
도난당한 클라우드 자격 증명을 손에 넣은 위협 행위자는 자신의 액세스 및 관리 권한을 평가해야 합니다. 클라우드 액세스 권한의 제한을 은밀하게 평가하기 위해 사이버 공격자는 다음을 활용할 수 있습니다.
인소크모델 API외침.비록
인소크모델 APIcall이 유효한 요청인 경우 위협 행위자는 다음을 설정하여 "ValidationException" 오류를 유도할 수 있습니다.max_tokens_to_sample를 -1로 설정합니다. 이 단계는 도난당한 자격 증명이 LLM 서비스에 액세스할 수 있는지 여부를 확인하기 위한 것입니다. 반대로, "AccessDenied" 오류가 나타나면 위협 행위자는 도난당한 자격 증명이'악용할 수 있는 액세스 권한이 없습니다.
악의적 사용자는 다음을 호출할 수도 있습니다. GetModelInvocationLoggingConfiguration 기업의 클라우드 호스팅 AI 서비스에 대한 구성 설정을 파악합니다. 이 단계는 개별 클라우드 공급자 및 서비스의 가드레일과 기능에 따라 달라진다는 점을 기억하십시오. 그렇기 때문에 경우에 따라 위협 행위자가 기업의 LLM 입력 및 출력에 대한 완전한 가시성을 확보하지 못할 수 있습니다.
LLM 재킹 공격을 수행한다고 해서 위협 행위자의 수익 창출이 보장되는 것은 아닙니다. 그러나 위협 행위자가 LLM 재킹이 수익성이 있는지 확인할 수 있는 몇 가지 방법이 있습니다. LLM 재킹 공격을 부검하는 동안 연구원들은 공격자가 오픈 소스 OAI 리버스 프록시 서버를 중앙 집중식 패널로 사용하여 LLM 액세스 권한으로 도난당한 클라우드 자격 증명을 관리할 수 있음을 발견했습니다.
위협 행위자가 LLM 재킹 공격으로 수익을 창출하고 기업의 LLM 모델에 대한 액세스 권한을 판매하면 어떤 종류의 피해가 뒤따를 수 있는지 예측할 수 있는 방법이 없습니다. 서로 다른 배경과 동기를 가진 다른 공격자들은 자신도 모르게 LLM 액세스 권한을 구매하고 기업의 GenAI 인프라를 사용할 수 있습니다. LLM 재킹 공격의 결과는 처음에는 숨겨져 있을 수 있지만 그 여파는 치명적일 수 있습니다.


LLM 재킹 방지 및 탐지 전술
기업이 LLM 재킹 공격으로부터 스스로를 보호할 수 있는 몇 가지 강력한 방법은 다음과 같습니다.
예방 전술
강력한 모델 학습:
다양한 고품질 데이터 세트: 편향과 취약성을 방지하기 위해 광범위한 데이터에 대해 모델을 훈련해야 합니다.
적대적 학습: 모델을 악의적인 입력에 노출하여 복원력을 향상시킵니다.
인간 피드백을 통한 강화 학습(RLHF): 모델 정렬'인간의 가치와 기대를 가진 결과물.
엄격한 입력 유효성 검사:
필터링: 필터를 구현하여 유해하거나 악의적인 프롬프트를 차단합니다.
살균: 입력을 정리하여 잠재적으로 유해한 요소를 제거합니다.
속도 제한: 남용을 방지하기 위해 요청 수를 제한합니다.
정기 모델 감사:
취약성 평가: 모델의 잠재적 약점을 식별합니다.
바이어스 감지: 모델에서 의도하지 않은 바이어스 모니터링's 출력.
성능 모니터링: 시간 경과에 따른 모델 성능을 추적하여 이상을 감지합니다.
투명한 모델 문서화:
명확한 지침: 모델을 책임감 있게 사용하는 방법에 대한 명확한 지침을 제공합니다.
제한 사항: 모델 전달'의 한계와 잠재적 편향.
지속적인 학습 및 적응:
최신 정보 확인: 최신 LLM 위협 및 대책에 대한 최신 정보를 제공합니다.
모델 업데이트: 새로운 취약성을 해결하기 위해 모델을 정기적으로 업데이트합니다.
탐지 전술
변칙 검색:
이상치 식별: 비정상적이거나 예상치 못한 모델 동작을 식별합니다.
통계 분석: 통계적 방법을 사용하여 정규 패턴에서 벗어난 부분을 감지합니다.
콘텐츠 모니터링:
키워드 필터링: 유해한 콘텐츠와 관련된 특정 키워드 또는 구문에 대한 출력을 모니터링합니다.
감정 분석: 생성된 콘텐츠의 감정을 분석하여 잠재적인 문제를 식별합니다.
스타일 분석: 생성된 콘텐츠의 쓰기 스타일에서 변칙을 감지합니다.
사용자 행동 분석:
비정상적인 패턴: 빠른 요청 또는 반복적인 프롬프트와 같은 비정상적인 사용자 동작을 식별합니다.
계정 모니터링: 의심스러운 활동에 대한 사용자 계정을 모니터링합니다.
Human-in-the-Loop 검증:
품질 보증: 생성된 콘텐츠의 품질과 안전성을 평가하기 위해 인간 검토자를 고용합니다.
피드백 메커니즘: 사용자 피드백을 수집하여 잠재적인 문제를 식별합니다.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

Wiz가 LLM 재킹 공격을 방지하는 방법
Wiz의 획기적인 AI-SPM 툴 솔루션 LLM 재킹 공격이 대규모 재해로 확대되는 것을 방지하고 완화하는 데 도움이 될 수 있습니다. Wiz AI-SPM은 다음과 같은 여러 가지 방법으로 LLM 재킹을 방어할 수 있습니다.
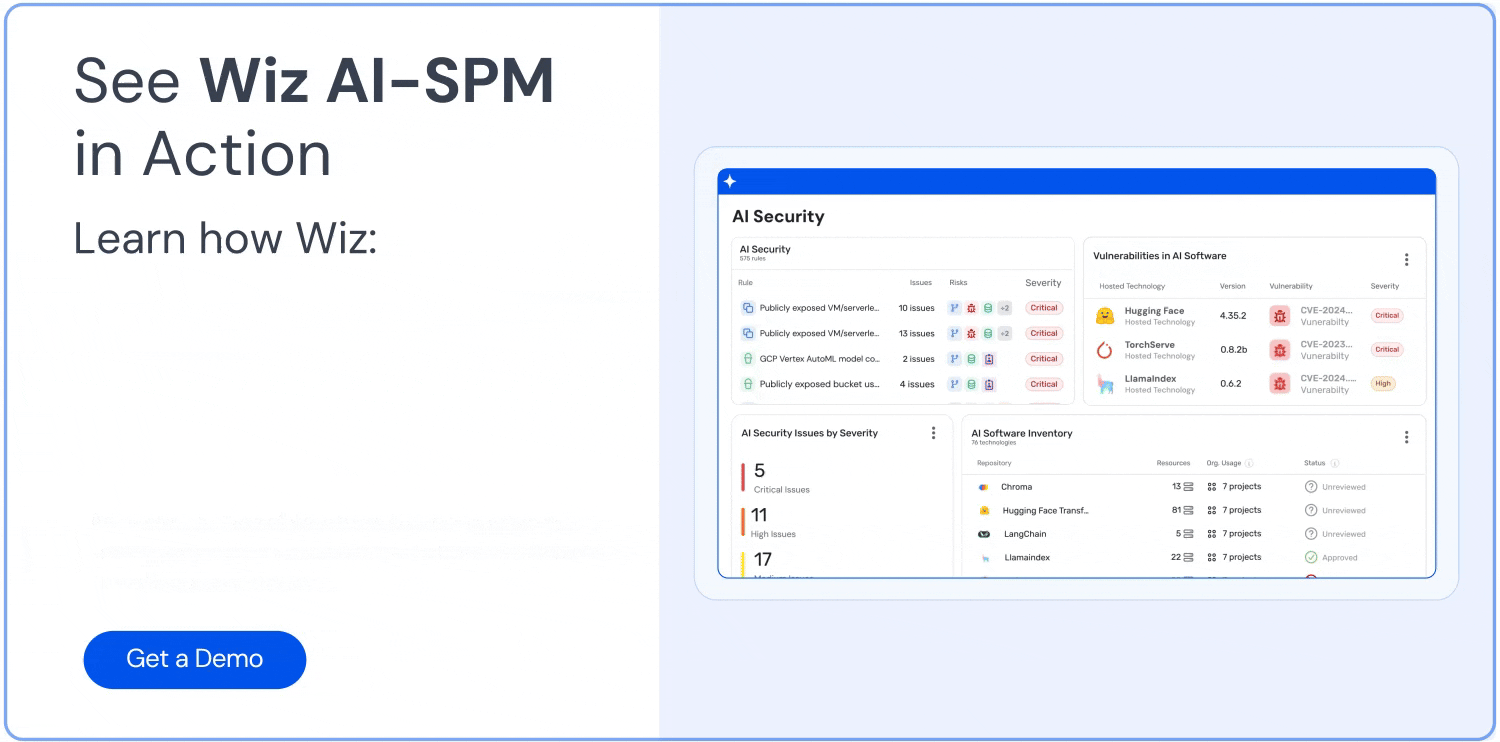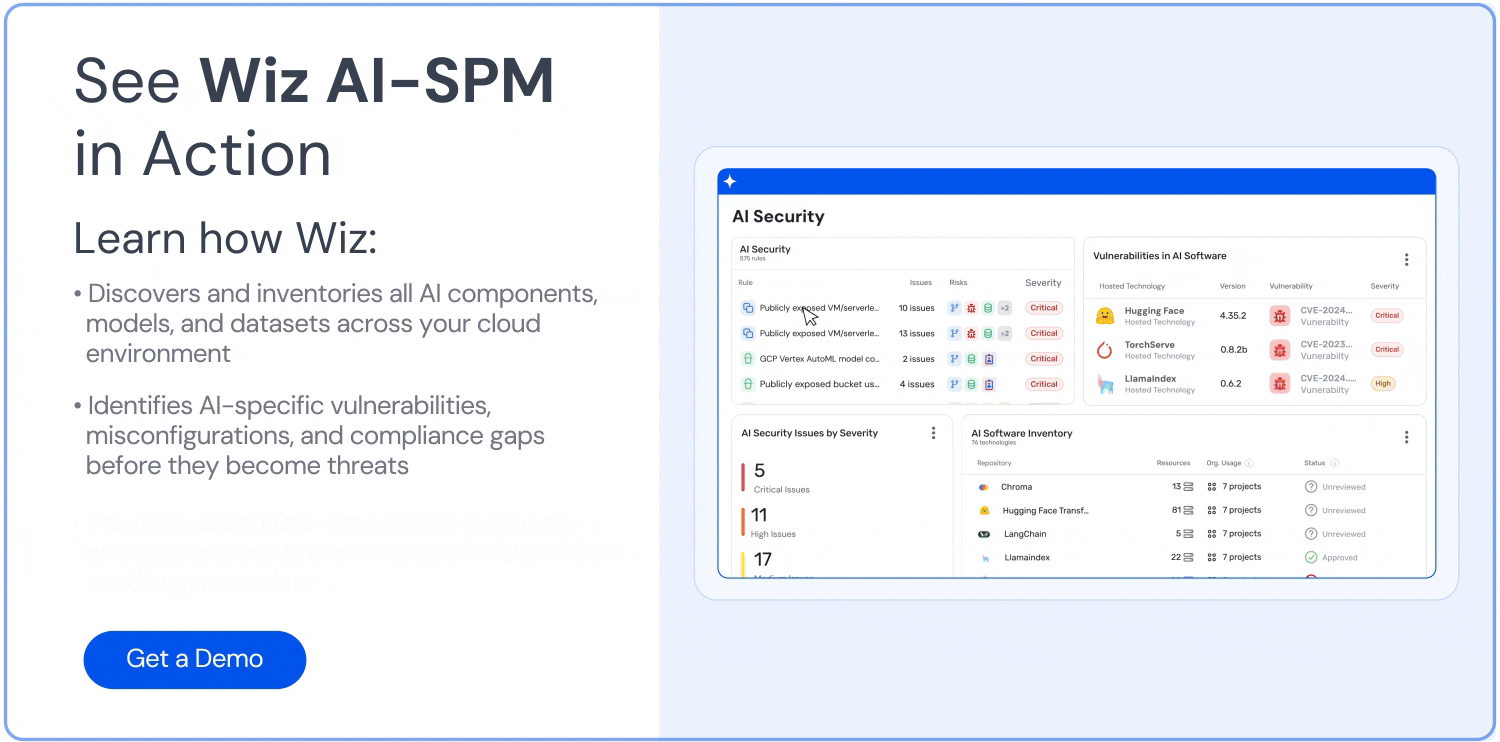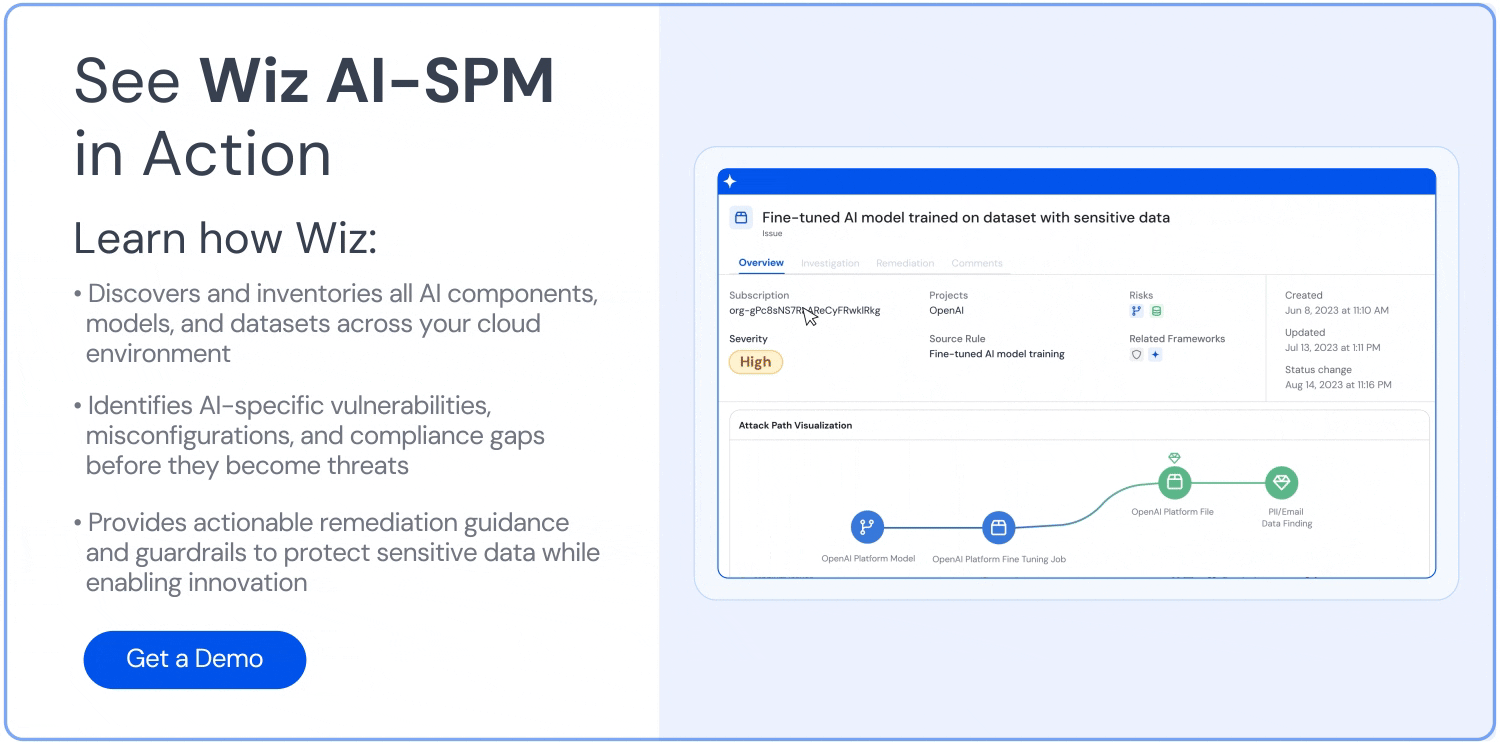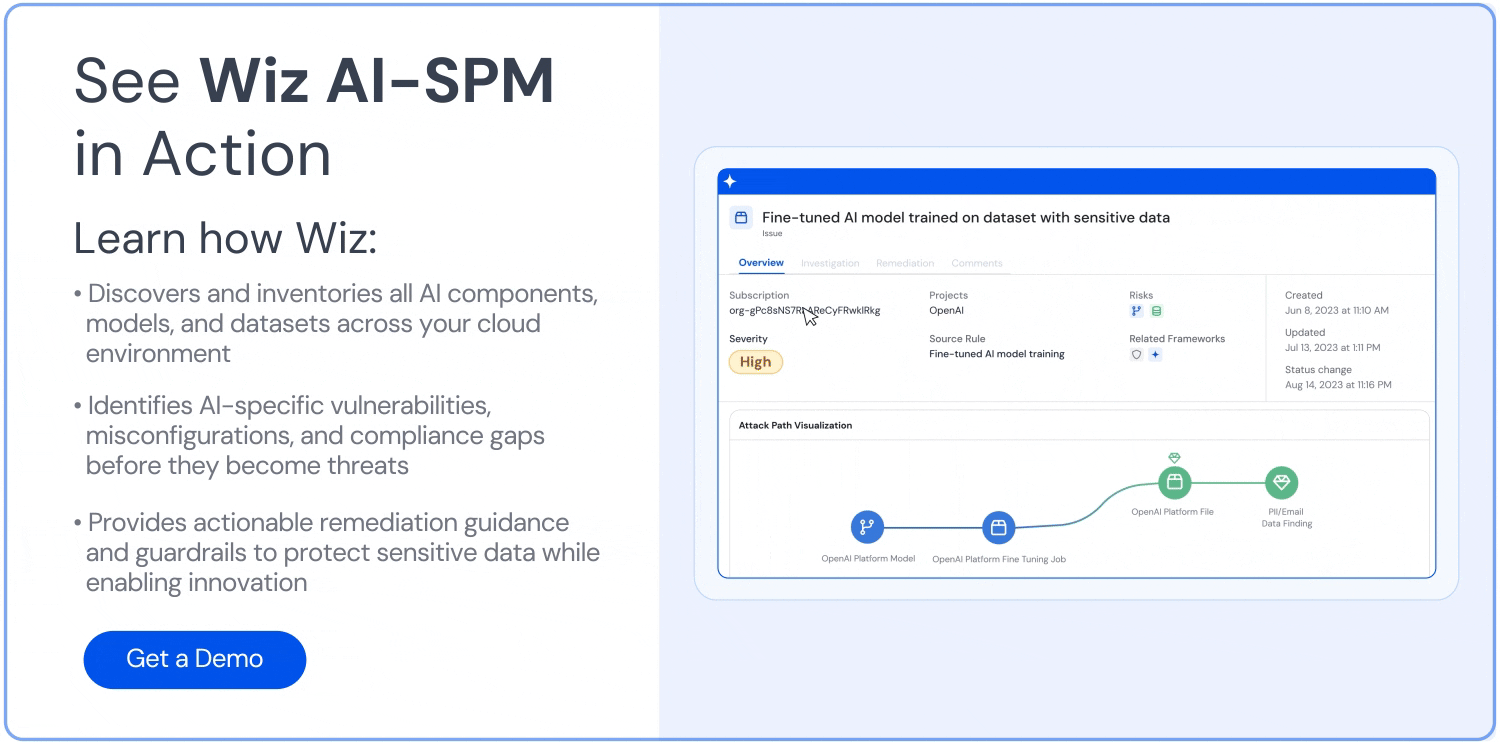
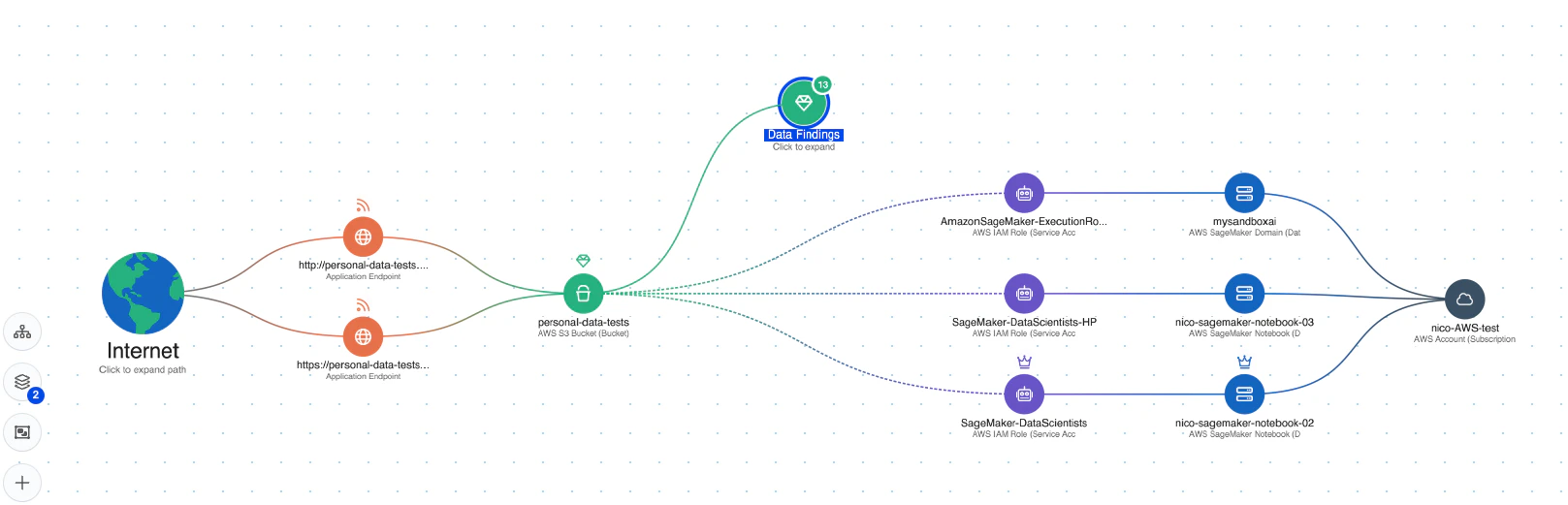
포괄적인 가시성: Wiz AI-SPM은 에이전트 없이 AI 서비스, 기술 및 SDK를 포함한 AI 파이프라인에 대한 풀 스택 가시성을 제공합니다. 이러한 가시성은 조직이 LLM을 포함하여 환경의 모든 AI 구성 요소를 탐지하고 모니터링하는 데 도움이 되므로 공격자가 알려지지 않았거나 그림자 AI 리소스.
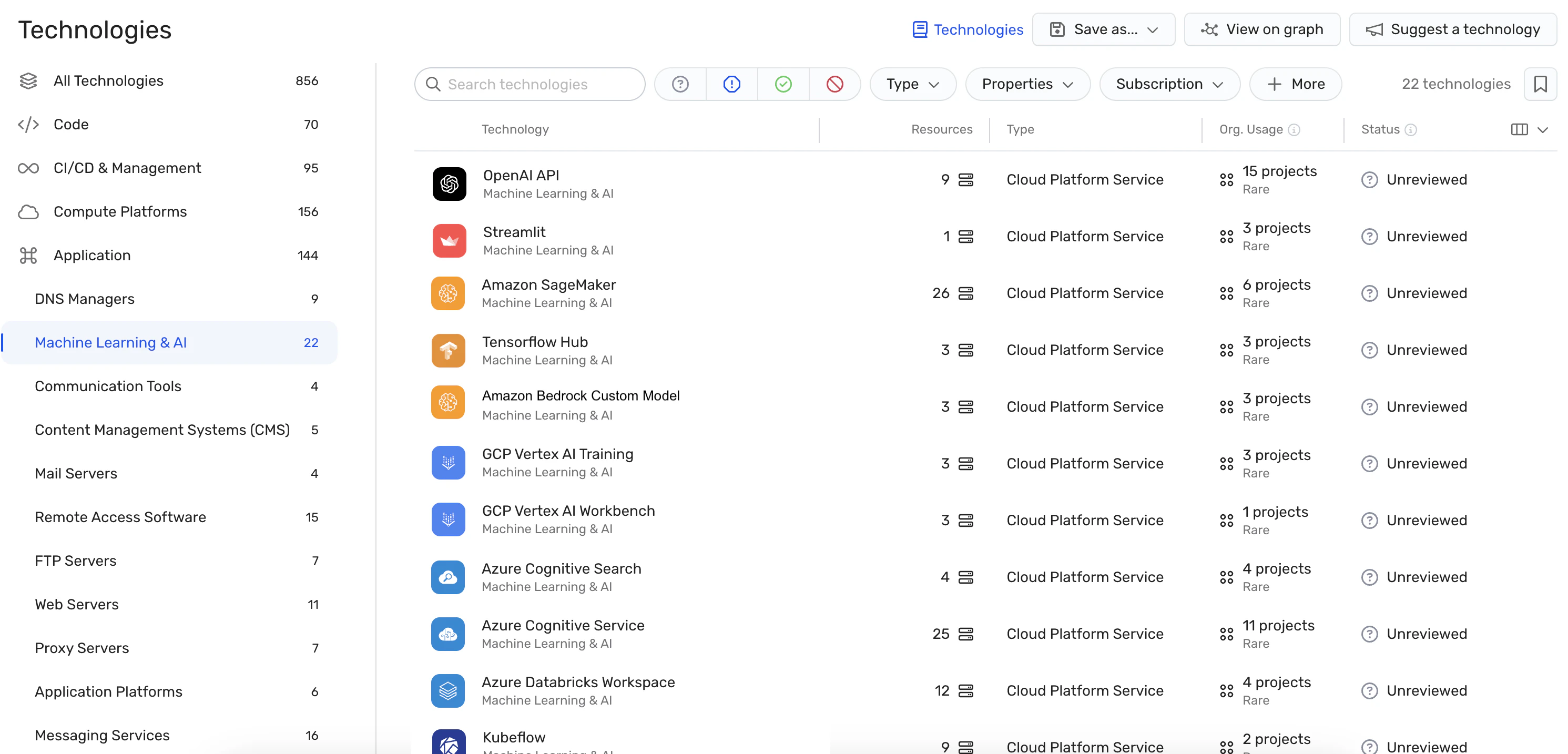
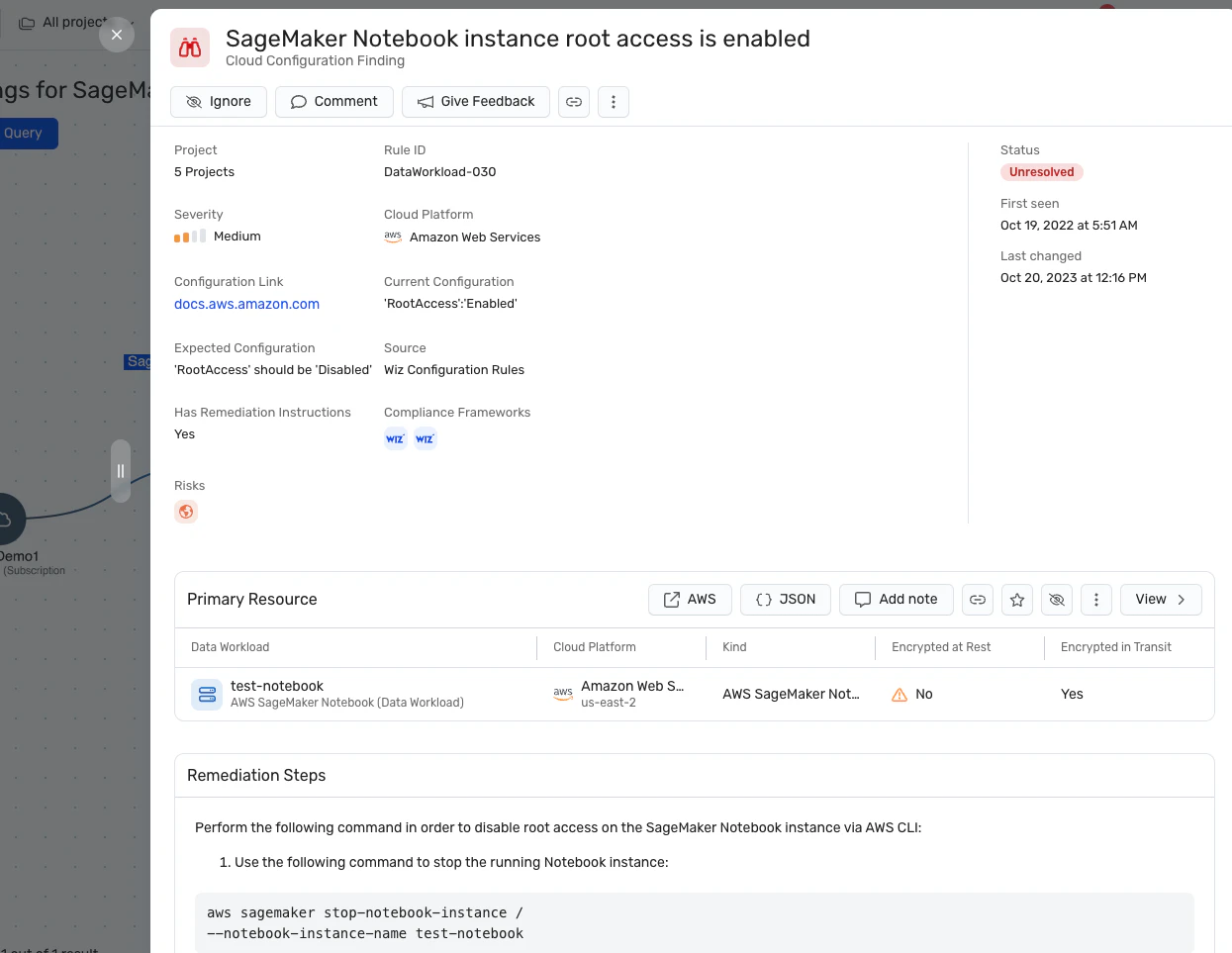
구성 오류 감지: 플랫폼은 다음을 시행합니다. AI 보안 모범 사례 기본 제공 규칙이 있는 AI 서비스의 잘못된 구성을 감지합니다. 이는 LLM 재킹 공격에서 악용될 수 있는 취약점을 방지하는 데 도움이 될 수 있습니다.
공격 경로 분석: Wiz AI-SPM은 취약성, ID, 인터넷 노출, 데이터, 잘못된 구성 및 비밀을 평가하여 AI 모델에 대한 공격 경로를 사전에 식별하고 제거합니다. 이 포괄적인 분석은 LLM 재킹 시도의 잠재적인 진입점을 방지하는 데 도움이 될 수 있습니다.
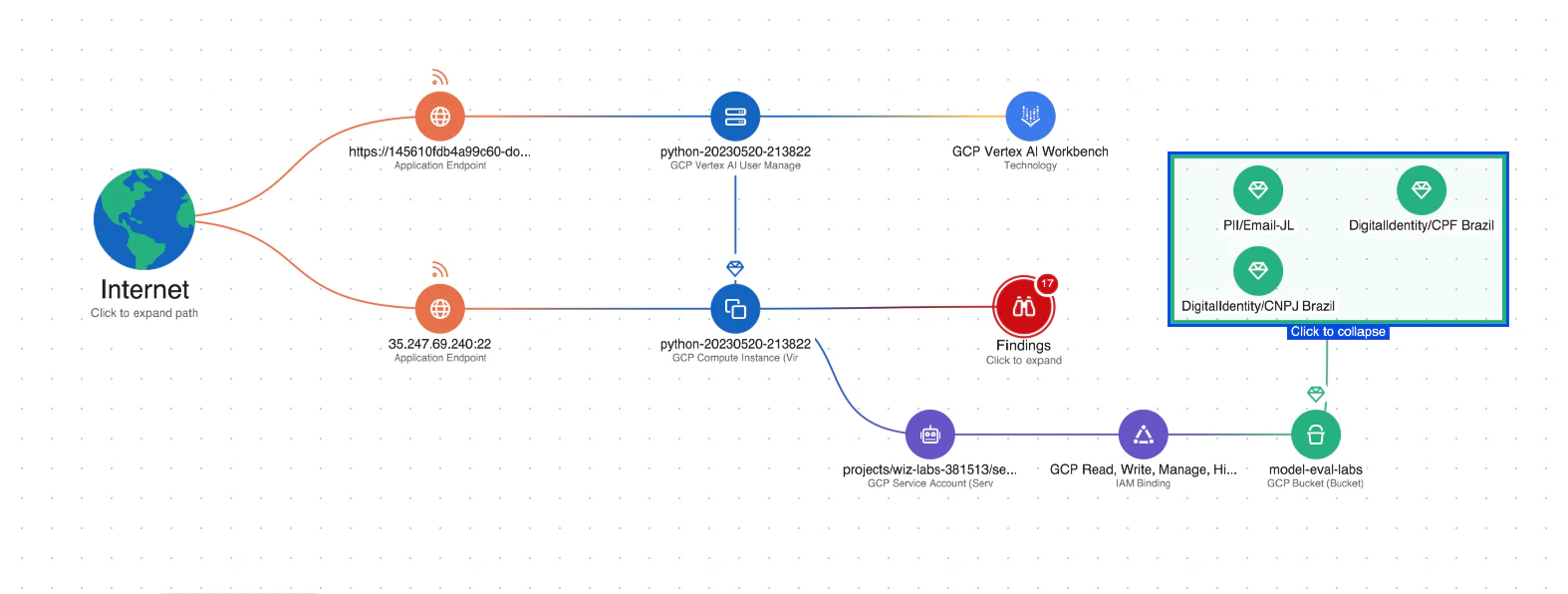
AI를 위한 데이터 보안: 이 플랫폼에는 데이터 보안 태세 관리((주)디에스엠) 특히 AI 전용 기능을 통해 민감한 교육 데이터를 자동으로 감지하고 이에 대한 공격 경로를 제거할 수 있습니다. 이렇게 하면 다음으로부터 보호할 수 있습니다. 데이터 유출 LLM 재킹 공격에 사용될 수 있습니다.
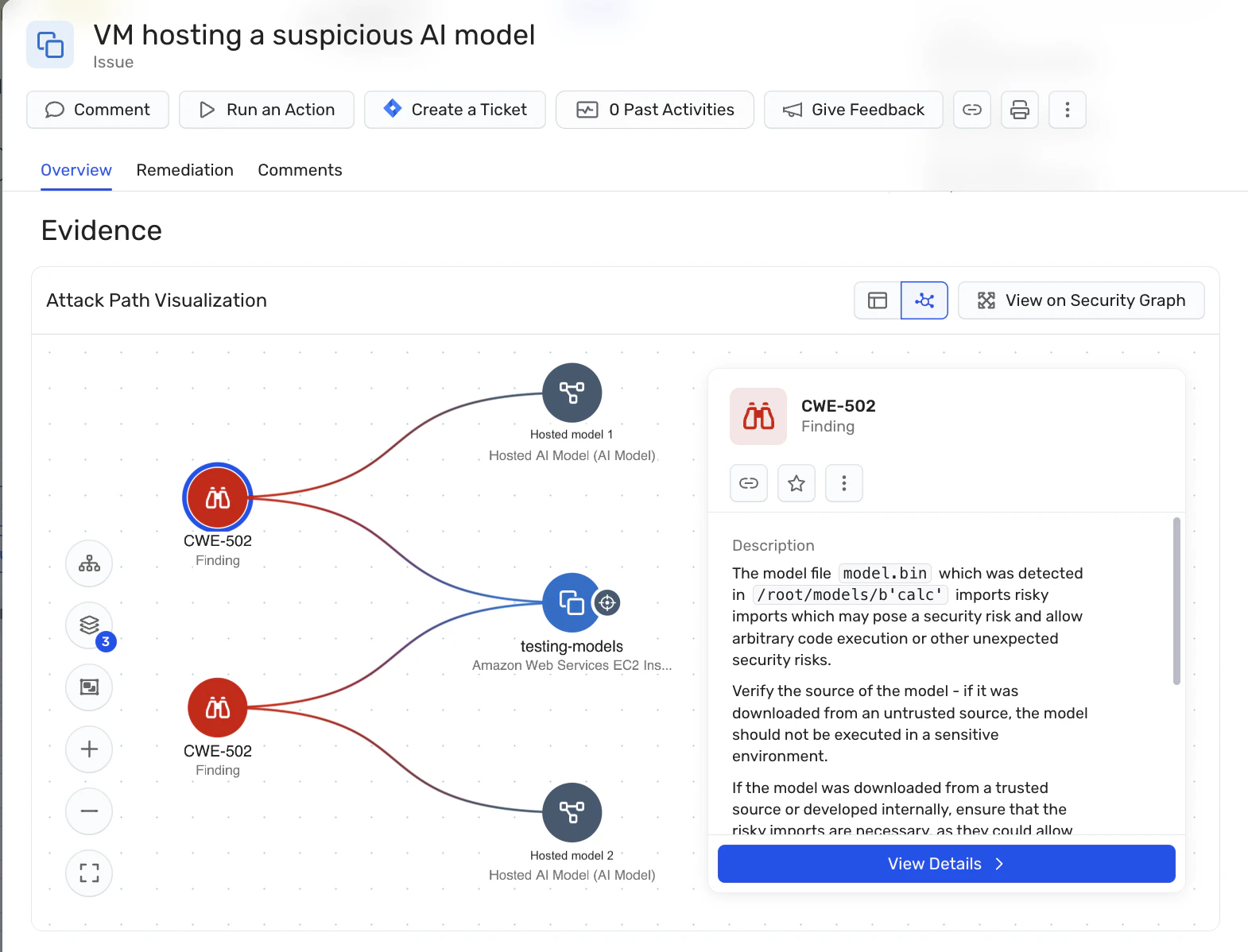
실시간 위협 탐지: Wiz AI-SPM은 AI 모델에서 발생하는 의심스러운 동작에 대한 런타임 보호 기능을 제공합니다. 이 기능은 LLM 재킹 시도를 실시간으로 감지하고 대응하여 잠재적인 영향을 최소화하는 데 도움이 될 수 있습니다.
모델 스캐닝: 이 플랫폼은 호스팅된 AI 모델의 식별 및 스캔을 지원하여 조직이 LLM 재킹 공격에 사용될 수 있는 악성 모델을 탐지할 수 있도록 합니다. 이는 오픈 소스 모델과 관련된 공급망 위험을 해결하는 데 도움이 되기 때문에 AI 모델을 자체 호스팅하는 조직에 특히 중요합니다.
AI 보안 대시보드: Wiz AI-SPM은 우선 순위가 지정된 위험 대기열과 함께 AI 보안 태세에 대한 개요를 제공하는 AI 보안 대시보드를 제공합니다. 이를 통해 AI 개발자와 보안 팀은 LLM 재킹으로 이어질 수 있는 취약점을 포함하여 가장 중요한 문제에 신속하게 집중할 수 있습니다.
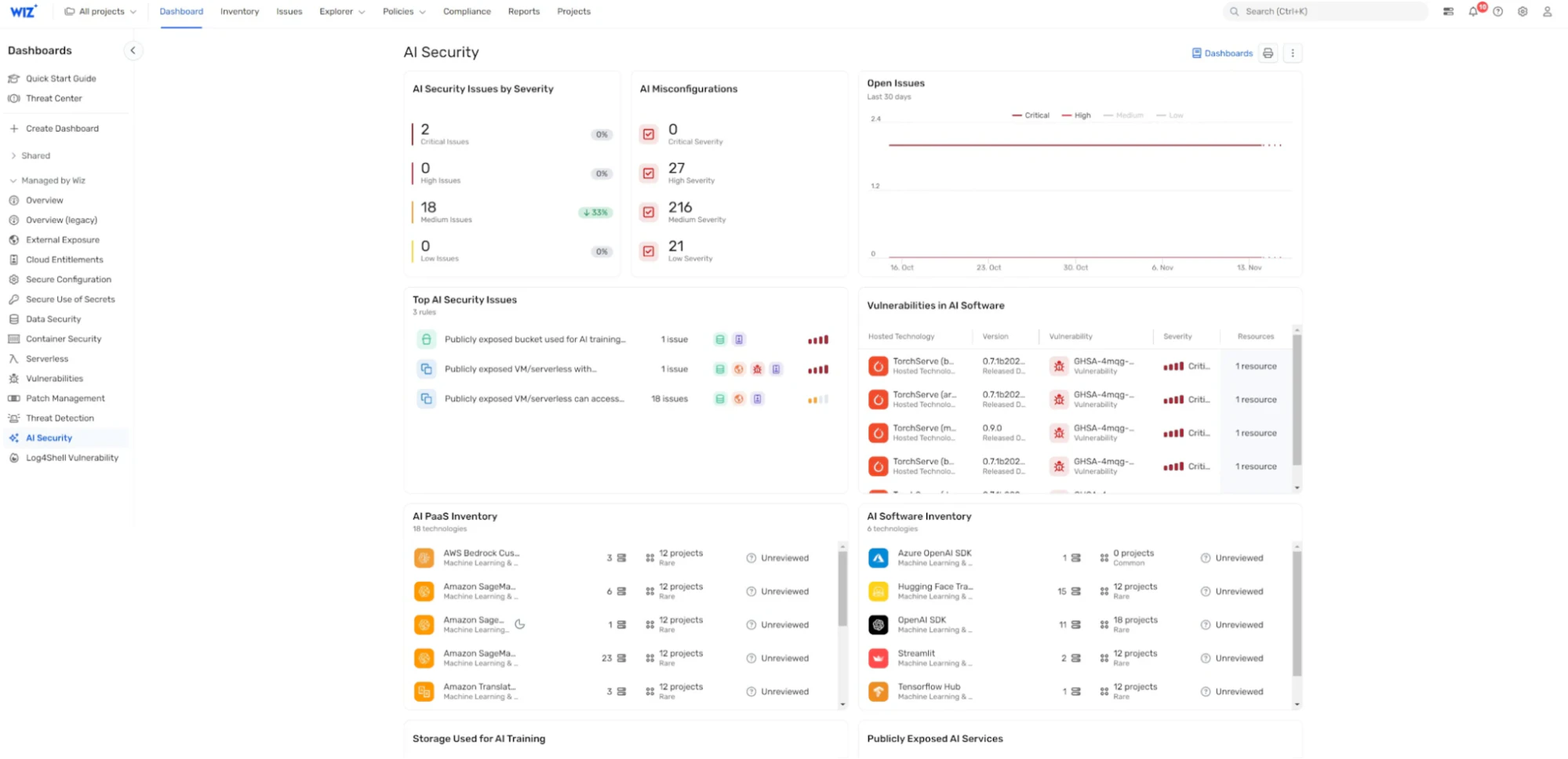
Wiz AI-SPM은 이러한 기능을 구현하여 조직이 AI 시스템에 대한 강력한 보안 태세를 유지하도록 지원하여 공격자가 LLM 재킹 공격 및 기타 AI 관련 위협을 성공적으로 실행하는 것을 더 어렵게 만듭니다.