



데이터 유출이란 무엇입니까?
데이터 유출은 조직 데이터를 제3자에게 무단으로 반출하는 것입니다. 잘못 구성된 데이터베이스, 제대로 보호되지 않은 네트워크 서버, 피싱 공격 또는 부주의한 데이터 처리와 같은 다양한 수단을 통해 발생합니다.
데이터 유출은 우발적으로 발생할 수 있습니다. 전체 조직의 82% 제3자에게 해당 환경에 대한 광범위한 읽기 액세스 권한을 부여하면 주요 보안 위험과 심각한 개인 정보 보호 문제가 발생합니다. 그러나 데이터 유출은 해킹, 피싱 또는 직원이 의도적으로 데이터를 훔치는 내부자 위협을 포함한 악의적인 활동으로 인해 발생하기도 합니다.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

데이터 유출의 잠재적 영향
데이터 유출은 다음과 같은 심오하고 광범위한 영향을 미칠 수 있습니다.
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
기계 학습(ML) 유출의 증가하는 위협
대규모 언어 모델(LLM)과 다른 데이터 세트를 사용하여 모델을 훈련할 때 머신 러닝 또는 인공 지능(AI) 편향이 발생할 수 있습니다. 이러한 상황은 일반적으로 ML 개발의 전처리 단계를 잘못 관리하여 발생합니다. ML 유출의 일반적인 예는 전체 훈련 하위 집합 대신 전체 훈련 데이터 세트의 평균 및 표준 편차를 사용하는 것입니다.
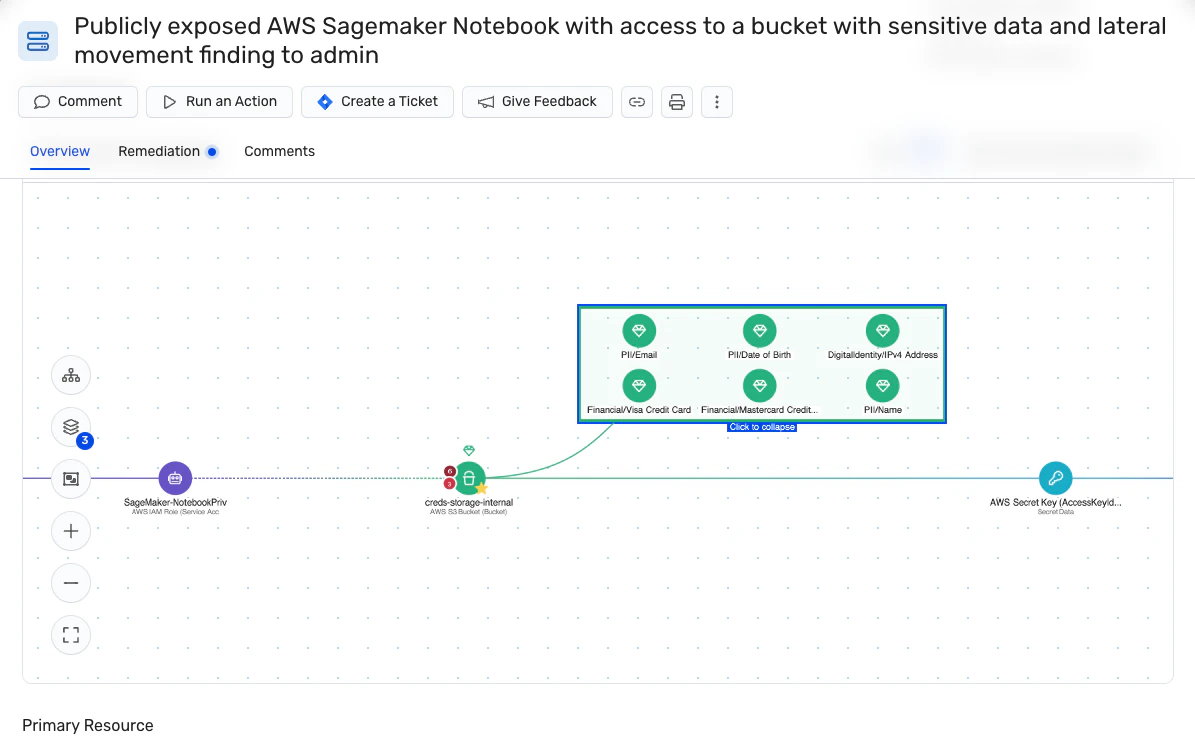
데이터 유출은 대상 유출 또는 학습 테스트 오염을 통해 기계 학습 모델에서 발생합니다. 후자의 경우 모델을 테스트하기 위한 데이터가 학습 세트로 누출됩니다. 모델이 학습 중에 테스트 데이터에 노출되면 성능 메트릭이 오해의 소지가 있을 정도로 높습니다.
타겟 유출에서 훈련에 사용되는 하위 집합에는 ML 개발의 예측 단계에서 사용할 수 없는 정보가 포함됩니다. LLM은 이 시나리오에서 좋은 성과를 거두지만, 이해관계자에게 모델 효능에 대한 잘못된 인식이로 인해 실제 응용 프로그램에서 성능이 저하됩니다.


데이터 유출의 일반적인 원인
데이터 유출은 다양한 이유로 발생합니다. 다음은 가장 일반적인 것 중 일부입니다.
인적 오류
인적 오류는 조직 내의 모든 수준에서 발생할 수 있으며, 악의적인 의도 없이 발생하는 경우가 많습니다. 예를 들어 직원이 실수로 재무 기록이나 개인 데이터와 같은 민감한 정보를 잘못된 이메일 주소로 보낼 수 있습니다.
피싱(Phishing) 공격
피싱 공격은 다양한 형태로 나타나지만 사이버 범죄자가 권한 있는 계정을 미끼로 중요한 세부 정보를 제공하도록 하는 한 가지 방법이 있습니다. 예를 들어, 공격자는 겉보기에 합법적으로 보이는 이메일을 보내 직원에게 악성 링크를 클릭하고 지정된 계정에 로그인하도록 요청할 수 있습니다. 이렇게 하면 직원은 로그인 자격 증명을 공격자에게 자발적으로 제공하게 되며, 이 자격 증명은 하나 또는 여러 악의적인 목적으로 사용됩니다.
구성 불량
잘못 구성된 데이터베이스, 클라우드 서비스 및 소프트웨어 설정은 민감한 데이터를 무단 액세스에 노출시키는 취약성을 생성합니다. 잘못된 구성 감독, 전문 지식 부족 또는 보안 모범 사례를 따르지 않아 발생하는 경우가 많습니다. 기본 사용자 이름 및 암호와 같은 기본 설정을 변경하지 않으면 사이버 범죄자가 쉽게 액세스할 수 있습니다.
잘못된 앱 설정, 보안 패치 및 업데이트 적용 실패, 부적절한 액세스 제어/권한 설정도 보안 허점을 만들 수 있습니다.
취약한 보안 조치
취약한 보안 조치는 조직을 약화시킵니다.'s 보안 태세. 간단하고 추측하기 쉬운 암호를 사용합니다. 강력한 암호 정책을 구현하지 못함; 과도한 권한을 부여하고 최소 권한(PoLP) 원칙을 따르지 않는 행위 또는 여러 계정에서 비밀번호를 재사용하면 데이터 유출 위험이 높아집니다.
또한 데이터를 남기고 암호화 되지 않은저장 중이거나 전송 중인 경우 데이터가 유출되기 쉽습니다. 구현하지 않음 최소 권한 원칙(PoLP) 또한 오래된 보안 프로토콜/기술에 의존하면 보안 프레임워크에 격차가 생길 수 있습니다.
누출을 방지하기 위한 전략
1. 데이터 전처리 및 삭제
익명화 및 편집
익명화에는 개인 식별 정보(PII) 및 민감한 데이터를 변경하거나 제거하여 개인에게 다시 연결되지 않도록 하는 것이 포함됩니다. 수정은 신용 카드 번호, 주민등록번호 또는 주소와 같은 데이터의 민감한 부분을 제거하거나 모호하게 하는 것과 관련된 보다 구체적인 프로세스입니다.
적절한 익명화 및 편집이 없으면 AI 모델은 다음을 수행할 수 있습니다. "암기하다" 모델 출력에서 실수로 재현될 수 있는 학습 세트의 민감한 데이터입니다. 이는 모델이 공용 또는 클라이언트 지향 응용 프로그램에서 사용되는 경우 특히 위험합니다.
권장사항:
토큰화, 해시 또는 암호화 기술을 사용하여 데이터를 익명화합니다.
훈련하기 전에 수정된 데이터가 정형(예: 데이터베이스) 및 비정형(예: 텍스트 파일) 데이터 세트 모두에서 영구적으로 제거되었는지 확인합니다.
차등 개인 정보 보호(나중에 설명)를 구현하여 개별 데이터 노출 위험을 더욱 줄입니다.
데이터 최소화
데이터 최소화에는 AI 모델의 목표를 달성하는 데 필요한 가장 작은 데이터 세트만 수집하고 사용하는 것이 포함됩니다. 수집되는 데이터가 적을수록 민감한 정보가 유출될 위험이 낮아집니다.
과도한 데이터를 수집하면 위반에 대한 위험 표면과 민감한 정보가 유출될 가능성이 높아집니다. 무엇만 사용함으로써'필요한 경우 GDPR 또는 CCPA와 같은 개인 정보 보호 규정을 준수해야 합니다.
권장사항:
데이터 감사를 수행하여 교육에 필수적인 데이터 포인트를 평가합니다.
전처리 파이프라인 초기에 필수적이지 않은 데이터를 삭제하는 정책을 구현합니다.
데이터 수집 프로세스를 정기적으로 검토하여 불필요한 데이터가 보존되지 않도록 합니다.
2. 모델 학습 보호 장치
적절한 데이터 분할
데이터 분할은 데이터 세트를 훈련, 검증 및 테스트 세트로 분리합니다. 훈련 세트는 모델을 학습시키는 반면, 검증 및 테스트 세트는 과적합 없이 모델의 정확성을 보장합니다.
데이터가 부적절하게 분할된 경우(예: 학습 및 테스트 세트 모두에 동일한 데이터가 있는 경우) 모델은 테스트 세트를 효과적으로 "기억"할 수 있으므로 성능이 과대 평가되고 학습 및 예측 단계 모두에서 민감한 정보가 노출될 수 있습니다.
권장사항:
분할하는 동안 데이터 세트를 무작위화하여 훈련, 검증 및 테스트 세트 간에 중복이 없도록 합니다.
k-fold 교차 검증과 같은 기법을 사용하여 데이터 유출 없이 모델 성능을 강력하게 평가할 수 있습니다.
정규화 기법
정규화 기법은 모델이 훈련 데이터에 너무 특이적이 되어 일반화하는 것이 아니라 "암기"하는 방법을 학습하는 과적합을 방지하기 위해 훈련 중에 사용됩니다. 과적합은 모델이 학습 데이터에서 민감한 정보를 기억하고 추론 중에 재현할 수 있기 때문에 데이터 유출 가능성을 높입니다.
권장사항:
드롭아웃: 훈련 중에 신경망에서 특정 단위(뉴런)를 무작위로 드롭하여 모델이 패턴을 기억하는 대신 일반화하도록 합니다.
가중치 감소(L2 정규화): 모델이 훈련 데이터에 너무 가깝게 맞지 않도록 훈련 중에 큰 가중치에 페널티를 부여합니다.
조기 정지: 검증 세트에서 모델 성능을 모니터링하고 모델이 다음과 같을 때 학습을 중지합니다.'의 성능은 과적합으로 인해 저하되기 시작합니다.
차등 개인 정보 보호
차등 개인 정보 보호는 데이터 또는 모델 출력에 제어된 노이즈를 추가하여 공격자가 데이터 세트의 개별 데이터 포인트에 대한 정보를 추출하기 어렵게 만듭니다.
AI 모델은 차등 개인 정보 보호를 적용하여 훈련 또는 예측 중에 특정 개인의 세부 정보를 유출할 가능성을 줄여 적대적 공격이나 의도하지 않은 데이터 유출에 대한 보호 계층을 제공합니다.
권장사항:
가우스 또는 라플라스 노이즈를 훈련 데이터, 모델 기울기 또는 최종 예측에 추가하여 개별 데이터 기여도를 모호하게 할 수 있습니다.
TensorFlow Privacy 또는 PySyft와 같은 프레임워크를 사용하여 실제로 차등 개인정보 보호를 적용하세요.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. 보안 모델 배포
테넌트 격리
다중 테넌트 환경에서 테넌트 격리는 각 테넌트 간에 논리적 또는 물리적 경계를 만듭니다'한 테넌트가 다른 테넌트에 액세스하거나 조작할 수 없도록 하는 데이터'민감한 정보. 각 테넌트를 격리하여'데이터를 통해 기업은 무단 액세스를 방지하고 데이터 침해 위험을 줄이며 데이터 보호 규정을 준수할 수 있습니다.
테넌트 격리는 추가 보안 계층을 제공하여 조직이 다음과 같은 사실을 알고 안심할 수 있도록 합니다. 민감한 AI 교육 데이터 잠재적인 누출 또는 무단 액세스로부터 보호됩니다.
권장사항:
논리적 분리: 컨테이너 또는 VM(가상 머신)과 같은 가상화 기술을 사용하여 각 테넌트의 데이터와 처리가 서로 격리되도록 합니다.
출입 통제: 엄격한 액세스 제어 정책을 구현하여 각 테넌트가 자신의 데이터 및 리소스에만 액세스할 수 있도록 합니다.
암호화 및 키 관리: 테넌트별 암호화 키를 사용하여 데이터를 추가로 분리하여 위반이 발생하더라도 다른 테넌트의 데이터가 안전하게 유지되도록 합니다.
리소스 제한 및 모니터링: 리소스 제한을 적용하고 시스템의 격리를 손상시킬 수 있는 비정상적인 동작을 모니터링하여 테넌트가 공유 리소스를 고갈시키는 것을 방지합니다.
출력 삭제
출력 삭제에는 특히 자연어 처리(NLP) 및 생성 모델에서 민감한 데이터가 실수로 노출되는 것을 방지하기 위해 모델 출력에 대한 검사 및 필터를 구현하는 작업이 포함됩니다.
경우에 따라 모델은 학습 중에 발견한 민감한 정보(예: 이름 또는 신용 카드 번호)를 재현할 수 있습니다. 출력을 삭제하면 민감한 데이터가 노출되지 않습니다.
권장사항:
패턴 매칭 알고리즘을 사용하여 모델 출력에서 PII(예: 이메일 주소, 전화번호)를 식별하고 수정할 수 있습니다.
확률적 출력에 대한 임계값을 설정하여 모델이 민감한 세부 정보를 노출할 수 있는 예측을 과도하게 신뢰하지 않도록 합니다.
4. 조직 관행
직원 교육
직원 교육은 AI 모델의 개발, 배포 및 유지 관리에 관련된 모든 개인이 데이터 유출 위험과 이를 완화하기 위한 모범 사례를 이해하도록 합니다. 많은 데이터 침해는 인적 오류나 부주의로 인해 발생합니다. 적절한 교육을 통해 중요한 정보가 실수로 노출되거나 취약성을 모델링하는 것을 방지할 수 있습니다.
권장사항:
AI 모델 및 민감한 데이터를 다루는 모든 직원에게 정기적인 사이버 보안 및 데이터 개인 정보 보호 교육을 제공합니다.
새로운 AI 보안 위험 및 새로운 예방 조치에 대해 직원에게 업데이트합니다.
데이터 거버넌스 정책
데이터 거버넌스 정책은 조직 전체에서 데이터를 수집, 처리, 저장 및 액세스하는 방법에 대한 명확한 지침을 설정하여 보안 관행이 일관되게 적용되도록 합니다.
잘 정의된 거버넌스 정책은 데이터 처리가 표준화되고 GDPR 또는 HIPAA와 같은 개인 정보 보호법을 준수하도록 하여 유출 가능성을 줄입니다.
권장사항:
데이터 소유권을 정의하고 AI 개발의 모든 단계에서 민감한 데이터를 처리하기 위한 명확한 프로토콜을 수립합니다.
거버넌스 정책을 정기적으로 검토하고 업데이트하여 새로운 위험과 규제 요구 사항을 반영합니다.
5. AI 보안 태세 관리(AI-SPM) 도구 활용
AI-SPM 솔루션 훈련/추론, 모델 무결성 및 배포된 모델에 대한 액세스에 사용되는 데이터를 포함하여 AI 보안의 중요한 구성 요소에 대한 가시성과 제어를 제공합니다. AI-SPM 도구를 통합함으로써 조직은 AI 모델의 보안 태세를 사전 예방적으로 관리하여 데이터 유출 위험을 최소화하고 강력한 AI 시스템 거버넌스를 보장할 수 있습니다.
AI-SPM이 ML 모델 유출을 방지하는 방법:
모든 AI 애플리케이션, 모델 및 관련 리소스를 검색하고 인벤토리합니다.
데이터 유출로 이어질 수 있는 AI 공급망의 취약성 및 구성 오류 식별
AI 스택 전반에서 교육 데이터, 라이브러리, API 및 데이터 파이프라인을 포함한 민감한 데이터를 모니터링합니다.
이상 징후 및 잠재적인 데이터 유출을 실시간으로 감지
AI 시스템에 특정한 가드레일 및 보안 제어를 구현합니다.
AI 애플리케이션에 대한 정기적인 감사 및 평가 수행


Wiz의 지원 방법
Wiz는 포괄적인 DSPM(Data Security Posture Management)을 통해 다음과 같은 방법으로 데이터 유출을 방지하고 감지하는 데 도움을 줍니다.
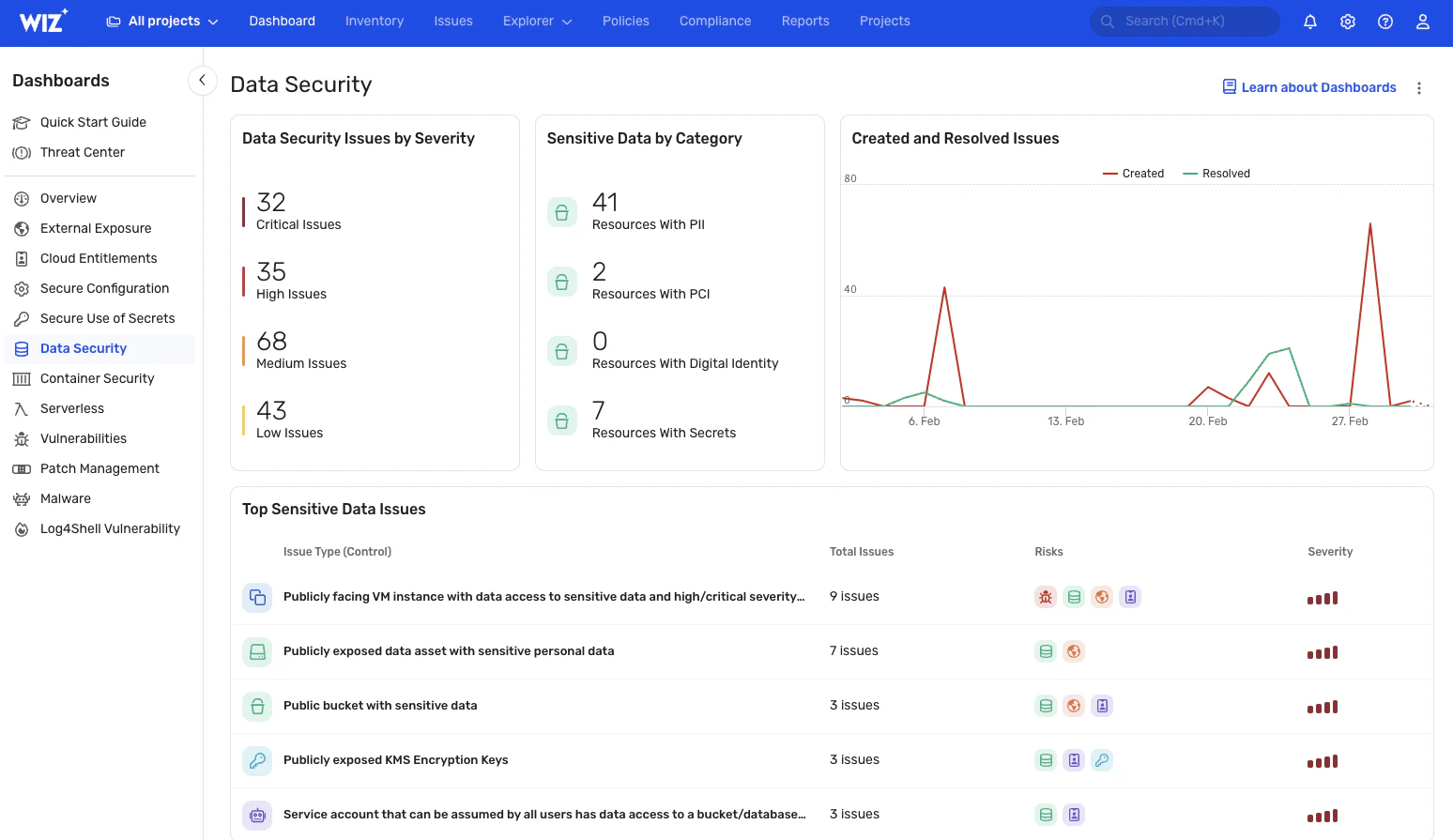
데이터 자동 검색 및 분류
Wiz는 중요한 데이터 노출을 지속적으로 모니터링하여 PII, PHI 및 PCI 데이터와 같은 민감한 정보에 대한 실시간 가시성을 제공합니다. 데이터의 위치와 액세스 방법에 대한 최신 보기를 제공합니다(AI 시스템에서도). AI-SPM 솔루션). 사용자 지정 분류자를 만들어 비즈니스에 고유한 중요한 데이터를 식별할 수도 있습니다. 이러한 기능은 보안 사고에 대한 신속한 대응을 용이하게 하여 손상을 완전히 방지하거나 잠재적인 폭발 반경을 크게 최소화합니다.
데이터 위험 평가
Wiz는 데이터 결과를 악용될 수 있는 취약성, 잘못된 구성, ID 및 노출과 연관시켜 공격 경로를 탐지합니다. 그런 다음 위협 행위자가 악용하기 전에 이러한 노출 경로를 차단할 수 있습니다. Wiz는 또한 영향과 심각도에 따라 노출 위험을 시각화하고 우선 순위를 지정하여 가장 중요한 문제가 먼저 처리되도록 합니다.
또한 Wiz는 누가 어떤 데이터에 액세스할 수 있는지 감지하고 표시하여 데이터 거버넌스를 지원합니다.
AI 교육 데이터를 위한 데이터 보안
Wiz는 데이터 유출 가능성을 포함하여 데이터 자산에 대한 완전한 위험 평가를 즉시 제공합니다 (주)디에스피엠 AI 컨트롤. 당사의 도구는 조직의 데이터 보안 태세에 대한 전체적인 관점을 제공하고, 주의가 필요한 영역을 강조 표시하며, 보안 조치를 강화하고 문제를 신속하게 해결할 수 있는 자세한 지침을 제공합니다.
지속적인 규정 준수 평가
Wiz의 지속적인 규정 준수 평가를 통해 조직은 다음을 보장할 수 있습니다.'의 보안 태세는 업계 표준 및 규정 요구 사항에 실시간으로 부합합니다. 당사의 플랫폼은 잘못된 구성 및 취약성을 스캔하여 수정을 위한 실행 가능한 권장 사항을 제공하고 규정 준수 보고를 자동화합니다.
와 대단한 DSPM 기능을 사용하면 조직이 데이터 유출 위험을 완화하고 견고성을 보장할 수 있습니다. 데이터 보호 및 규정 준수. 데모 예약하기 오늘 더 알아보기 위해.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
