

Modelos de IA maliciosos são artefatos de modelos intencionalmente armados que executam ações prejudiciais quando estão carregadas ou em execução. Diferente dos modelos vulneráveis – que contêm falhas acidentais – modelos maliciosos são projetados para comprometer o ambiente em que são implantados.
A característica definidora dos modelos de IA maliciosa é que a ameaça está embutida dentro do próprio arquivo do modelo. Em muitos casos, atacantes abusam de formatos de serialização inseguros para ocultar código executável dentro dos pesos dos modelos ou lógica de carregamento. Quando o modelo é importado ou desserializado, esse código é executado automaticamente – muitas vezes antes de qualquer inferência ocorrer.
Isso torna modelos de IA maliciosos uma ameaça distinta à cadeia de suprimentos. Eles exploram a confiança que as organizações depositam em modelos pré-treinados baixados de repositórios públicos ou compartilhados internamente entre equipes. Como artefatos de modelo não são tratados como o código-fonte tradicional, eles frequentemente contornam controles de segurança como revisão de código, análise estática e varredura de dependências.
À medida que a adoção da IA acelera, modelos pré-treinados se tornaram um bloco fundamental para o desenvolvimento moderno. Essa mesma conveniência transformou artefatos de modelos em um vetor de ataque de alto valor – algo para o qual as ferramentas tradicionais de segurança de aplicações nunca foram projetadas para inspecionar.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Por que modelos de IA maliciosos são um risco real na cadeia de suprimentos
Modelos de IA maliciosos surgem das mesmas forças que transformaram o desenvolvimento moderno de software: reutilização, automação e confiança em componentes externos. Modelos pré-treinados são rotineiramente retirados de repositórios públicos para acelerar o desenvolvimento, reduzir custos e evitar retreinamento do zero. Em muitas organizações, baixar e implantar modelos tornou-se tão rotineiro quanto instalar uma biblioteca.
Esse fluxo de trabalho transfere a confiança do código revisado internamente para artefatos externos que raramente são inspecionados. Arquivos modelo são frequentemente tratados como binários opacos – armazenados, compartilhados e carregados sem a análise aplicada ao código da aplicação ou às imagens de contêineres. Como resultado, eles frequentemente ignoram controles de segurança estabelecidos, como revisão de código, análise estática e varredura de dependências.
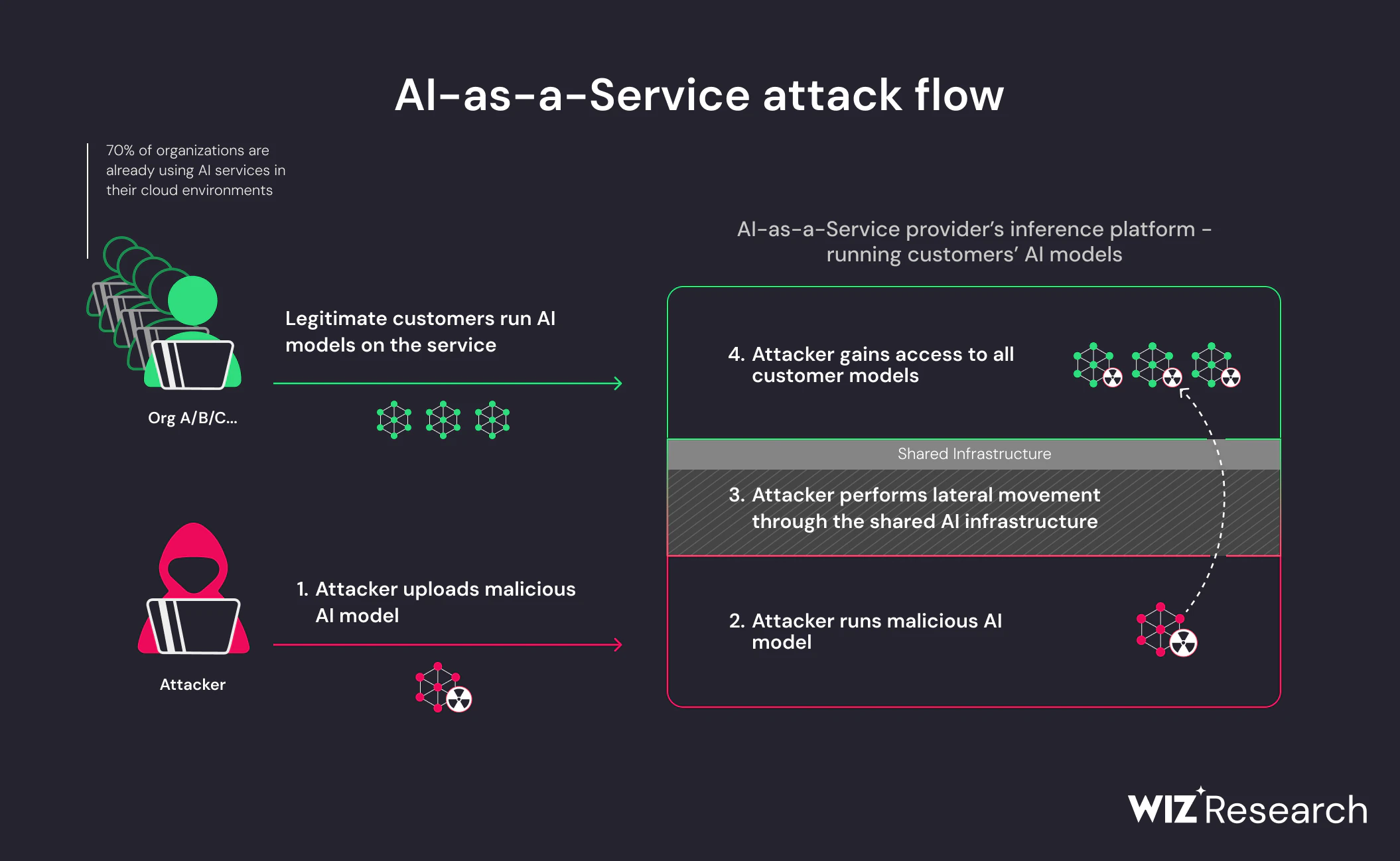
O que torna esse risco particularmente agudo é que modelos maliciosos exploram Comportamento esperado. Carregar um modelo é uma ação normal e confiável em pipelines de IA. Quando os atacantes incorporam lógica executável em artefatos do modelo, essa confiança se torna o mecanismo de entrega. Não é necessária uma cadeia de exploits; o compromisso ocorre porque o sistema está fazendo exatamente o que foi projetado para fazer.
É por isso que modelos de IA maliciosos representam um Ameaça à cadeia de suprimentos em vez de um bug de aplicação. O risco não se origina de como um modelo é usado, mas sim de de onde vem e como é carregado. À medida que o reuso de modelos continua a crescer entre equipes e ambientes, a capacidade de validar a proveniência e o comportamento do modelo torna-se uma necessidade fundamental de segurança.
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
Leia mais

Como os modelos de IA maliciosos funcionam em um nível geral
Modelos de IA maliciosos exploram a forma como os modelos são embalados, distribuídos e carregados nos fluxos de trabalho modernos de IA. O risco central não são as previsões do modelo, mas o Caminho de execução é acionado quando um arquivo modelo é desserializado ou inicializado.
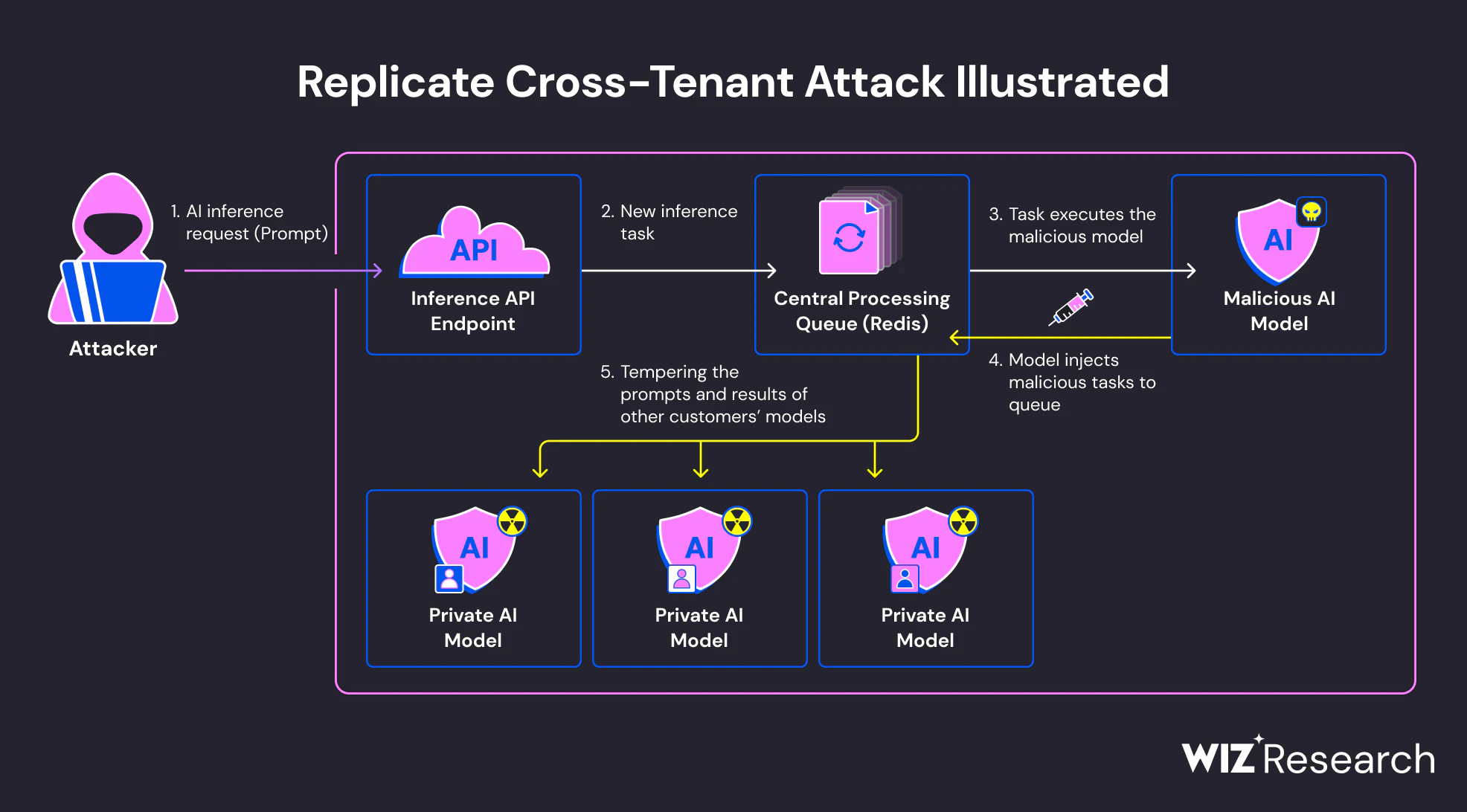
Execução durante o carregamento do modelo
Muitos frameworks de IA suportam formatos de serialização que permitem que a lógica executável seja executada como parte do processo de carregamento do modelo. Em particular, o Python piclesformatos baseados em -– comumente usados no PyTorch e ferramentas relacionadas – podem executar código arbitrário quando um modelo é desserializado. Esse comportamento é documentado, mas frequentemente negligenciado na prática.
Quando um modelo malicioso é carregado, o código embutido pode ser executado imediatamente, antes que ocorra inferência ou avaliação. Do ponto de vista do sistema, isso parece uma importação normal de modelo. Do ponto de vista do atacante, é um ponto de execução confiável dentro de um ambiente confiável.
Por que isso acontece antes da inferência
Diferente do código de aplicação, os modelos são tratados como dados. Os controles de segurança tendem a focar em como os modelos são usados, não em como eles são carregados. Como resultado, a atividade mais perigosa ocorre no início do ciclo de vida – no momento do carregamento – antes que monitoramento em tempo de execução, controles de acesso ou verificações comportamentais sejam aplicados.
É isso que torna modelos maliciosos difíceis de detectar com ferramentas tradicionais. Pode não haver chamadas de API suspeitas, entradas malformadas e saídas anormais. O compromisso ocorre simplesmente porque o modelo foi aceito como legítimo.
Objetivos comuns dos atacantes
Uma vez alcançada a execução, os atacantes normalmente perseguem objetivos familiares:
Roubo de credenciais ou tokens disponíveis no ambiente
Acesso a dados de treinamento ou armazenamentos de dados a jusante
Estabelecer persistência por meio de backdoors ou tarefas agendadas
Consumindo recursos computacionais para mineração de criptomoedas ou comprometimento adicional
Essas ações não são exclusivas de ambientes de IA, mas modelos frequentemente rodam com permissões elevadas e proximidade a dados sensíveis, aumentando seu impacto.
Formatos mais seguros, padrões mais seguros
Nem todos os formatos de modelo apresentam o mesmo risco. Formatos projetados para separar pesos da lógica executável – como SafeTensors e ONNX –Reduzir a probabilidade de execução de código durante o carregamento do modelo. Esses formatos armazenam dados de modelo sem caminhos de execução embutidos, tornando-os mais seguros por design.
Em contraste, mecanismos de serialização que permitem lógica executável durante a desserialização aumentam o risco, a menos que sejam rigidamente controlados. Na prática, compatibilidade e conveniência frequentemente levam as equipes a adotar formatos inseguros, a menos que padrões explícitos de segurança sejam aplicados.
Compreensão Como modelos são carregados o que é, portanto, central para se defender contra modelos de IA maliciosos. A ameaça não depende de entradas adversariais ou de comportamentos inovadores de IA – ela depende de caminhos de execução previsíveis e confiáveis em ferramentas comuns de ML.


Vetores de ataque primários para modelos de IA maliciosos
Modelos de IA maliciosos normalmente chegam à produção por meio de um pequeno número de vetores de ataque repetíveis. Esses vetores exploram a confiança em artefatos do modelo e automação nos fluxos de trabalho de IA, em vez de comportamentos inovadores de IA.
Repositórios públicos de modelos
Repositórios públicos são o canal de distribuição mais comum para modelos maliciosos. Atacantes enviam modelos armados para plataformas populares ou usam typosquatting para imitar projetos conhecidos. Com o tempo, eles podem construir reputação por meio de liberações benignas antes de introduzirem uma versão maliciosa.
Como modelos pré-treinados são frequentemente baixados diretamente para ambientes de desenvolvimento ou treinamento, esses artefatos podem contornar os processos de revisão aplicados ao código da aplicação ou às imagens de contêineres.
Execução remota de código via carregadores de modelos
Alguns fluxos de trabalho de IA permitem explicitamente a execução remota ou personalizada de código durante o carregamento do modelo. Configurações como flags de carregador permissivos ou classes de modelo personalizadas expandem a superfície de ataque permitindo que a lógica executável seja buscada e executada dinamicamente.
Nesses casos, o risco não vem dos pesos do modelo em si, mas do mecanismo de carregamento que implicitamente confia no código externo. Isso torna a configuração do carregador uma parte importante do modelo de ameaça.
Modelos de Troia e backdoors aprendidos
Nem todos os modelos maliciosos dependem da execução durante o carregamento. Alguns são projetados para se comportar normalmente na maioria das condições durante a produção saídas maliciosas quando gatilhos específicos estão presentes. Esses modelos "Trojan" incorporam comportamentos prejudiciais diretamente em pesos aprendidos, em vez de código executável.
Ao contrário dos ataques baseados em serialização, modelos de Troia normalmente têm como alvo o Processo de treinamento ou ajuste fino, como por meio de dados de treinamento envenenados ou fluxos de trabalho de ajuste fino manipulados. Como o comportamento malicioso está codificado nos parâmetros do modelo, a varredura estática do artefato do modelo oferece visibilidade limitada sobre a ameaça.
Isso faz dos modelos de Trojan uma categoria de risco distinta. Detectá-los geralmente requer testes adversariais, análise comportamental ou validação dos dados de treinamento e linhagem, em vez de apenas inspeção do arquivo do modelo.
Risco de dependência e de insider
Modelos maliciosos também podem entrar em ambientes por meio de dependências comprometidas ou canais internos confiáveis. Isso inclui bibliotecas de ML envenenadas, registros internos inseguros ou modelos introduzidos por insiders com acesso legítimo.
Como esses vetores dependem de relações de confiança já existentes, eles frequentemente são negligenciados na modelagem inicial de ameaças, apesar de terem potencial para um impacto amplo.
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

Por que ambientes em nuvem amplificam esse risco
Ambientes em nuvem não criam modelos de IA maliciosos, mas fazem isso significativamente aumentar o impacto e a velocidade de compromisso quando um é apresentado. As mesmas características que tornam as plataformas em nuvem ideais para IA – automação, escala e acesso a dados sensíveis – também ampliam o risco na cadeia de suprimentos.
Cargas de trabalho de IA frequentemente rodam com permissões elevadas. Trabalhos de treinamento e serviços de inferência frequentemente exigem acesso a grandes conjuntos de dados, armazenamento de objetos, segredos e serviços a jusante. Quando um modelo malicioso é executado dentro desse contexto, ele pode herdar imediatamente esses privilégios, expandindo o raio de explosão além do próprio modelo.
A automação amplifica ainda mais o risco. Os modelos são comumente implantados por meio de pipelines CI/CD, frameworks de orquestração ou fluxos de trabalho de retraining programados. Uma vez que um artefato malicioso entra em um desses caminhos, ele pode se propagar rapidamente entre ambientes sem intervenção humana, tornando a inspeção manual impraticável.
A infraestrutura em nuvem também muda onde ocorre a execução em relação a dados sensíveis. Modelos maliciosos normalmente executam dentro do mesmo plano de dados dos dados que deveriam acessar, em vez de adjacente a ela. Diferente de uma aplicação web comprometida que precisa pivotar lateralmente para acessar um banco de dados, um modelo frequentemente roda dentro do ambiente que já tem acesso direto a dados de treinamento, entradas de inferência ou sistemas a jusante. Isso reduz a distância entre execução e impacto.
Por fim, cargas de trabalho de IA dependem de pilhas complexas de serviços gerenciados, containers, GPUs e dependências em tempo de execução. Cada camada introduz desafios de configuração e isolamento que os atacantes podem explorar se os controles forem aplicados incorretamente. Na prática, isso significa que modelos maliciosos se beneficiam das mesmas configurações erradas que causam muitas violações na nuvem hoje.
Juntos, esses fatores transformam modelos de IA maliciosos de um risco localizado em um Preocupação com segurança em nível de sistema, reforçando por que a segurança dos modelos deve ser avaliada no contexto de identidades em nuvem, acesso a dados e pipelines de implantação – não isoladamente.
Defendendo-se contra modelos de IA maliciosos
Defender-se contra modelos de IA maliciosos requer uma mudança de foco do comportamento do modelo para Proveniência do modelo, caminhos de carregamento e contexto de execução. Como a ameaça está embutida no próprio artefato ou processo de treinamento, tradicional Controles de segurança de aplicações são necessários, mas aren'não o suficiente sozinhos.
Estabeleça os controles antes que os modelos cheguem à produção
As defesas mais eficazes operam antes de um modelo ser carregado. Isso inclui validar de onde vêm os modelos, como eles são empacotados e quais caminhos de código são executados durante o carregamento. Tratar artefatos do modelo como componentes de primeira classe da cadeia de suprimentos – sujeitos a inspeção, aprovação e controle de versões – reduz a probabilidade de que modelos armados cheguem a ambientes sensíveis.
Na prática, isso significa aplicar a mesma governança a Registros de modelos que as organizações já se aplicam a registros de contêineres ou repositórios de artefatos. Se imagens de contêineres forem assinadas, escaneadas e promovidas por meio de pipelines controlados, os artefatos dos modelos devem seguir a mesma disciplina – independentemente de se originarem internamente ou de fontes públicas.
Sempre que possível, as equipes devem preferir formatos de modelo que separem dados da lógica executável e resserram configurações de loaders que confiam implicitamente em código externo. Esses controles não eliminam o risco, mas estreitam significativamente a superfície de ataque.
Restringa a execução por meio de controles de identidade e acesso
Modelos maliciosos são mais perigosos quando herdam permissões amplas. Limitar as identidades e funções disponíveis para cargas de treinamento e inferência reduz o raio de explosão caso um modelo seja comprometido. Isso inclui a aplicação do privilégio mínimo para contas de serviço, isolar ambientes e evitar credenciais compartilhadas entre pipelines.
Como os modelos frequentemente são executados dentro do plano de dados, o controle de acesso torna-se uma linha principal de defesa – e não uma proteção secundária.
Monitore o comportamento no contexto, não isoladamente
A inspeção estática sozinha não pode detectar todos os modelos maliciosos, especialmente aqueles que incorporam comportamentos em pesos aprendidos. A visibilidade em tempo de execução ajuda a preencher essa lacuna ao observar como os modelos interagem com seu ambiente ao longo do tempo.
O monitoramento eficaz foca em Sinais contextuais: acesso inesperado à rede, operações incomuns de arquivos, uso anormal de identidade ou desvios em relação aos padrões de execução estabelecidos. Esses sinais são mais significativos quando correlacionados com o contexto da nuvem – quais dados o modelo pode acessar, quais identidades ele usa e como foi implantado.
Trate a segurança dos modelos como parte da segurança em nuvem
Em última análise, defender-se contra modelos de IA maliciosos não é uma disciplina isolada. Isso exige integrar considerações específicas de IA em situações já existentes Práticas de segurança em nuvem, incluindo governança da cadeia de suprimentos, gestão de identidade e monitoramento de carga de trabalho.
Ao avaliar modelos como parte do sistema mais amplo em que operam – em vez de como caixas-pretas opacas – as equipes de segurança podem reduzir a exposição a artefatos maliciosos sem depender de detecções especulativas ou suposições sobre o comportamento do modelo.
Como o Wiz ajuda a reduzir o risco de modelos de IA maliciosos
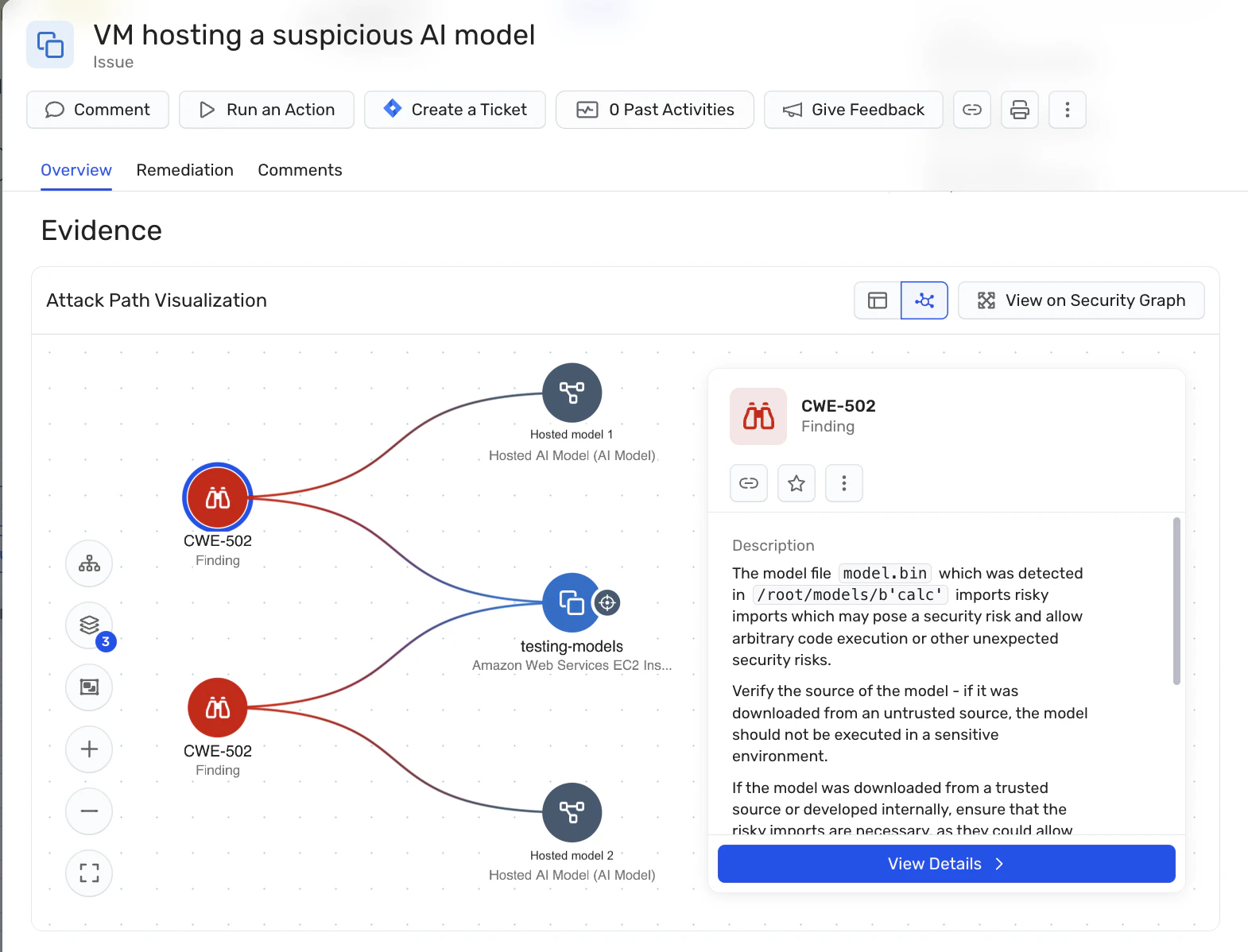
A Wiz ajuda organizações a reduzir o risco de modelos de IA maliciosos ao fundamentar a segurança dos modelos em fundamentos de segurança em nuvem. Em vez de tentar classificar a intenção ou comportamento do modelo, o Wiz foca em validar os controles que determinam de onde vêm os modelos, como são carregados e o que podem acessar após serem implantados.
Através Gestão da Postura de Segurança em IA (IA-SPM) e o Grafo de Segurança Wiz, modelos de IA, trabalhos de treinamento, serviços de inferência e registros são tratados como ativos de nuvem de primeira classe. O Wiz fornece visibilidade sobre artefatos de modelos hospedados e realiza inspeção em nível de formato para identificar métodos de serialização arriscados ou fontes não confiáveis – estendendo a disciplina da cadeia de suprimentos de software para modelos de IA antes que cheguem à produção.
Ao correlacionar artefatos do modelo com identidades, permissões, exposição à rede e acesso a dados sensíveis, o Wiz ajuda as equipes a identificar quando um modelo arriscado ou potencialmente malicioso se torna explorável na prática, compreenda seu verdadeiro raio de explosão e priorize a remediação com base em caminhos de ataque reais – sem desacelerar o desenvolvimento de IA ou introduzir ferramentas de segurança separadas.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
