

What is a site reliability engineer?
A site reliability engineer (SRE) is a professional who applies software engineering principles to infrastructure and operations problems. Google created this discipline in the early 2000s to solve a fundamental challenge: how do you keep systems running reliably when they grow beyond what manual processes can handle?
Organizations hire SREs to maintain uptime, reduce repetitive manual work called toil, and scale operations as systems grow more complex. This is particularly important given that industry research consistently shows many serious outages are preventable through stronger processes and management practices.
When your application serves millions of users across distributed infrastructure, you cannot rely on someone manually checking servers or restarting services. SREs automate these tasks and build systems that heal themselves.
SREs bridge the gap between development teams who build features and operations teams who keep systems running. They understand both code and infrastructure deeply enough to identify why a deployment caused latency spikes or why a database query suddenly started timing out. The role has evolved significantly from managing physical servers to orchestrating containers, serverless functions, and multi-cloud deployments where resources exist for seconds before disappearing.
Secure Coding Best Practices [Cheat Sheet]
With curated insights and easy-to-follow code snippets, this 11-page cheat sheet simplifies complex security concepts, empowering every developer to build secure, reliable applications.
Download

Why site reliability engineering matters in cloud environments
Cloud-native architectures have made reliability harder to achieve than in the days of monolithic applications running on dedicated servers. When your system consists of hundreds of microservices running across Kubernetes clusters, each with its own dependencies and failure modes, traditional operations approaches fall apart. Manual processes cannot keep pace with hundreds of deployments per day and thousands of interdependent services.
The shift from static infrastructure to dynamic environments fundamentally changes how teams maintain reliability. Resources spin up and down constantly based on demand, containers get rescheduled across nodes, and serverless functions exist only during execution. This ephemeral nature requires automated monitoring and response that can detect problems and remediate them faster than any human could.
Reliability connects directly to business outcomes. Downtime impacts revenue when customers cannot complete purchases, with recent data showing 54% of outages cost over $100,000. It erodes trust when users experience errors during critical workflows. For regulated industries, availability failures can create compliance risk and contractual exposure. Examples include missed SLAs triggering financial penalties, audit findings tied to availability controls under SOC 2 or ISO 27001, or regulatory scrutiny in sectors like healthcare (HIPAA) and finance (PCI DSS). SREs exist because reliability is no longer optional in environments where everything depends on distributed systems working together.
SRE vs. DevOps: What's the difference?
Both SRE and DevOps aim to improve software delivery and operations, but they differ in focus and methodology.
| Aspect | SRE | DevOps |
|---|---|---|
| Primary focus | Measurable reliability targets | Faster delivery via culture + automation |
| Key metrics | SLOs, SLIs, error budgets | DORA metrics (lead time, change fail rate) |
| Approach | Engineering solutions to operations problems | Breaking down silos between dev and ops |
| Origins | Google (early 2000s) | Broader industry movement |
DevOps is a cultural movement that emphasizes collaboration and shared responsibility. SRE is a specific implementation that treats operations as a software engineering problem. Many organizations use both, with DevOps principles guiding how teams work together and SRE practices providing concrete methods for achieving reliability.
Core responsibilities of a site reliability engineer
SRE responsibilities span the entire lifecycle of production systems, from initial design through incident response and continuous improvement.
Ensuring system reliability and availability
SREs design systems to stay running even when components fail. This means building redundancy so that losing a server or even an entire availability zone does not take down the service. Failover mechanisms automatically redirect traffic away from unhealthy instances, while graceful degradation ensures that partial failures reduce functionality rather than causing complete outages.
Capacity planning requires SREs to forecast resource needs before demand spikes cause problems. They analyze growth trends, model peak traffic scenarios, and provision infrastructure accordingly. SREs also participate in architecture reviews to catch reliability risks before code reaches production, flagging designs that create single points of failure or lack proper retry logic.
Monitoring, observability, and incident response
Monitoring tracks known metrics like CPU usage and error rates. Observability goes further by helping teams understand unknown system states through logs, traces, and metrics that reveal why something failed, not just that it failed. SREs build observability systems that answer questions nobody thought to ask in advance.
Effective alerting strategies reduce noise so on-call engineers respond to real problems rather than false alarms. SREs manage on-call rotations that distribute the burden fairly and prevent burnout. When incidents occur, they follow structured workflows: detect the problem, triage severity, mitigate impact, resolve the root cause, and communicate status to stakeholders. Blameless postmortems identify what went wrong and how to prevent recurrence without assigning personal fault. This is especially important since industry data consistently shows that outages attributed to human error typically trace back to process gaps, inadequate runbooks, or insufficient training rather than individual mistakes.
Automating toil and building internal tooling
Toil is repetitive manual work that scales linearly with system growth and provides no lasting value. Restarting a service manually every time it crashes is toil. Writing a script that automatically restarts it and alerts the team is engineering.
SREs automate deployments, scaling decisions, and common remediation tasks. They build internal platforms that let developers self-serve infrastructure needs without waiting for operations tickets. This tooling might include deployment pipelines, feature flag systems, or dashboards that surface relevant metrics for each team.
Managing error budgets and SLOs
Service Level Objectives (SLOs) define reliability targets, like 99.9% availability. Service Level Indicators (SLIs) measure whether you are meeting those targets. Error budgets represent the acceptable amount of unreliability: if your SLO allows 0.1% downtime, that budget equals roughly 8.7 hours per year.
Common SLI types and example SLOs:
| SLI Type | What It Measures | Example SLO |
|---|---|---|
| Availability | Percentage of successful requests | 99.9% of requests return non-error responses |
| Latency | Response time distribution | 95% of requests complete in <200ms, 99% in <1s |
| Error rate | Percentage of failed requests | <0.1% of requests return 5xx errors |
| Throughput | Requests processed per time unit | System handles 10,000 requests/second at peak |
| Freshness | Data staleness | Dashboard data refreshes within 5 minutes of source update |
Teams use error budgets to balance reliability investments with feature velocity. When the budget is healthy, developers can ship faster and take more risks. When it is exhausted, reliability work takes priority over new features. This framework turns reliability from a vague goal into a measurable constraint that drives engineering decisions.
Collaborating with development and security teams
SREs work with developers on reliability requirements during design and code review. They help teams understand how their code behaves under load, where bottlenecks exist, and what happens when dependencies fail.
The intersection of reliability and security grows more important each year as security operations become inseparable from maintaining system availability. Runtime threats, vulnerability remediation, and misconfigurations can all cause outages. A compromised container might consume resources until the service degrades. An unpatched vulnerability might get exploited in ways that crash the application. For SREs, the fastest path to restoring reliability is having shared context (what changed, what's exposed, what identities are involved, and what data or services are in the blast radius) so security and engineering teams can act on the same facts rather than reconciling conflicting tool outputs.
Essential skills for site reliability engineers
SRE roles require both deep technical expertise and strong collaboration abilities.
Technical skills
Programming proficiency: Python, Go, or Bash for automation scripts and tooling
Systems administration: Linux/Unix fundamentals, networking basics, and troubleshooting methodology
Containerization and orchestration: Docker, Kubernetes, and understanding of container security implications
Cloud platforms: AWS, Azure, or GCP experience including managed services and IAM
Infrastructure as Code: Terraform or similar tools for provisioning and configuration management
CI/CD pipelines: Design and integration for automated testing and deployment
Soft skills
Clear communication during incidents keeps stakeholders informed without creating panic. SREs provide status updates, manage expectations, and document what happened for future reference. Cross-team collaboration requires working effectively with developers, security engineers, and product managers who have different priorities and technical backgrounds.
Prioritization under pressure determines success during major incidents. When multiple systems are degraded, SREs decide what to fix first based on business impact. Strong documentation skills matter for writing runbooks, postmortems, and knowledge bases that help the entire team learn from experience.
Common tools SREs use
SRE toolchains typically include monitoring and observability platforms for collecting and analyzing system data, incident management systems for coordinating response, Infrastructure as Code frameworks for provisioning, container orchestration platforms for running workloads, and CI/CD systems for automating deployments.
Modern SRE toolchains increasingly include security visibility to catch misconfigurations and vulnerabilities that could affect reliability. A misconfigured security group that exposes a database to the internet is both a security risk and a reliability risk. Agentless approaches are often preferred in production environments to reduce performance overhead and operational maintenance from additional software running on every host, though many organizations still deploy agents for specific use cases like APM, EDR, and deep runtime telemetry. In ephemeral environments (Kubernetes pods, autoscaling groups, serverless functions), coverage gaps often emerge from inventory drift and ownership ambiguity, so visibility that stays current without added friction becomes essential for both reliability and security teams.
Site reliability engineer interview questions
SRE interviews uniquely blend software engineering depth with operational rigor, testing candidates on reliability principles like SLOs, error budgets, and toil reduction rather than just coding ability
Leia maisSite reliability engineer salary and career outlook
SRE remains one of the highest-compensated roles in infrastructure and operations due to the specialized skill set required.
| Experience Level | Salary Range (USD) |
|---|---|
| Entry-level/Junior SRE | $90,000 - $120,000 |
| Mid-level SRE | $120,000 - $160,000 |
| Senior SRE | $160,000 - $200,000 |
| Staff/Principal SRE | $200,000 - $280,000+ |
Ranges vary significantly by geography, company size, and on-call expectations. Roles with heavy paging loads often include on-call stipends or higher base compensation to offset the operational burden. Career progression follows either an individual contributor track (senior to staff to principal) or a management track (team lead to engineering manager to director).
Site reliability engineer job description template
Role Summary
We are seeking a Site Reliability Engineer to maintain and improve the reliability of our cloud-native infrastructure. You will work closely with development teams to ensure our services meet availability targets while building automation that reduces manual operational work.
Key Responsibilities
Define and maintain SLOs for critical services, tracking SLIs and managing error budgets
Build monitoring and alerting systems that surface actionable signals without excessive noise
Automate incident response and remediation for common failure scenarios
Participate in on-call rotations and lead incident response during outages
Conduct blameless postmortems and implement preventive measures
Develop internal tooling that improves developer productivity and system reliability
Collaborate with security teams to remediate vulnerabilities affecting production systems
Required Skills
3+ years of experience in SRE, DevOps, or systems engineering roles
Proficiency in at least one programming language (Python, Go, or similar)
Experience with Kubernetes and container orchestration
Strong understanding of distributed systems and cloud infrastructure
Experience with monitoring and observability tools
Preferred Skills
Cloud provider certifications (AWS, GCP, or Azure)
Experience with Infrastructure as Code (Terraform, Pulumi)
Kubernetes certifications (CKA, CKAD)
Qualifications
Bachelor's degree in Computer Science or equivalent practical experience. Demonstrated ability to debug complex distributed systems issues.
Improve site reliability with Wiz
Wiz provides agentless visibility across cloud environments, Kubernetes clusters, and workloads to give SREs fast context during incident response with minimal operational overhead. When an incident occurs, you need to understand the blast radius immediately, not after stitching together data from multiple consoles or waiting for different tools to sync their findings.
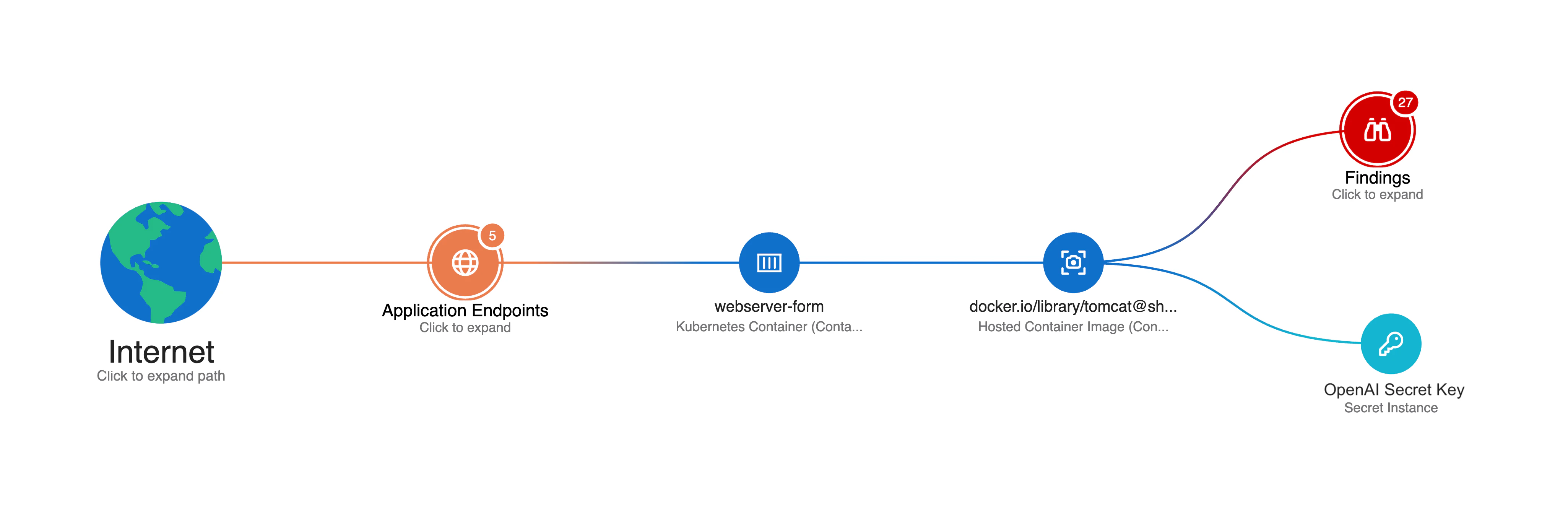
The Security Graph connects vulnerabilities, misconfigurations, identities, and exposure paths so teams can quickly see how a problem in one component affects others. Runtime threat detection can surface active behavior affecting availability, such as cryptomining consuming compute resources or lateral movement indicating compromise, helping teams spot issues that static scanning alone won't catch in time. At PROS, SOC analysts reduced the time to determine real threats from hours to minutes, and MITRE ATT&CK framework coverage helped identify detection gaps before they caused incidents.
IaC scanning in pipelines catches misconfigurations before they reach production, reducing incidents that SREs need to respond to. Prioritized risk findings filter noise and surface only issues that matter based on actual exploitability and business impact. This means less toil triaging alerts and more time building reliable systems.
Site reliability depends on fast context and low noise. See how cloud visibility helps teams respond faster. Schedule a demo to get started!
Catch code risks before you deploy
Learn how Wiz Code scans IaC, containers, and pipelines to stop misconfigurations and vulnerabilities before they hit your cloud
