



O que é vazamento de dados?
O vazamento de dados é a exfiltração descontrolada de dados organizacionais para terceiros. Isso ocorre por vários meios, como bancos de dados mal configurados, servidores de rede mal protegidos, ataques de phishing ou até mesmo manuseio descuidado de dados.
O vazamento de dados pode acontecer acidentalmente: 82% de todas as organizações dar a terceiros amplo acesso de leitura a seus ambientes, o que representa grandes riscos de segurança e sérias preocupações com a privacidade. No entanto, o vazamento de dados também ocorre devido a atividades maliciosas, incluindo hackers, phishing ou ameaças internas em que os funcionários roubam dados intencionalmente.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

Possíveis impactos do vazamento de dados
O vazamento de dados pode ter impactos profundos e de longo alcance:
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
A crescente ameaça de vazamento de aprendizado de máquina (ML)
Ao treinar um modelo usando um conjunto de dados diferente daquele de um modelo de linguagem grande (LLM), pode ocorrer viés de aprendizado de máquina ou inteligência artificial (IA). Essa situação geralmente surge devido a uma má gestão da fase de pré-processamento do desenvolvimento de ML. Um exemplo típico de vazamento de ML é usar a média e o desvio padrão de um conjunto de dados de treinamento inteiro em vez de todo o subconjunto de treinamento.
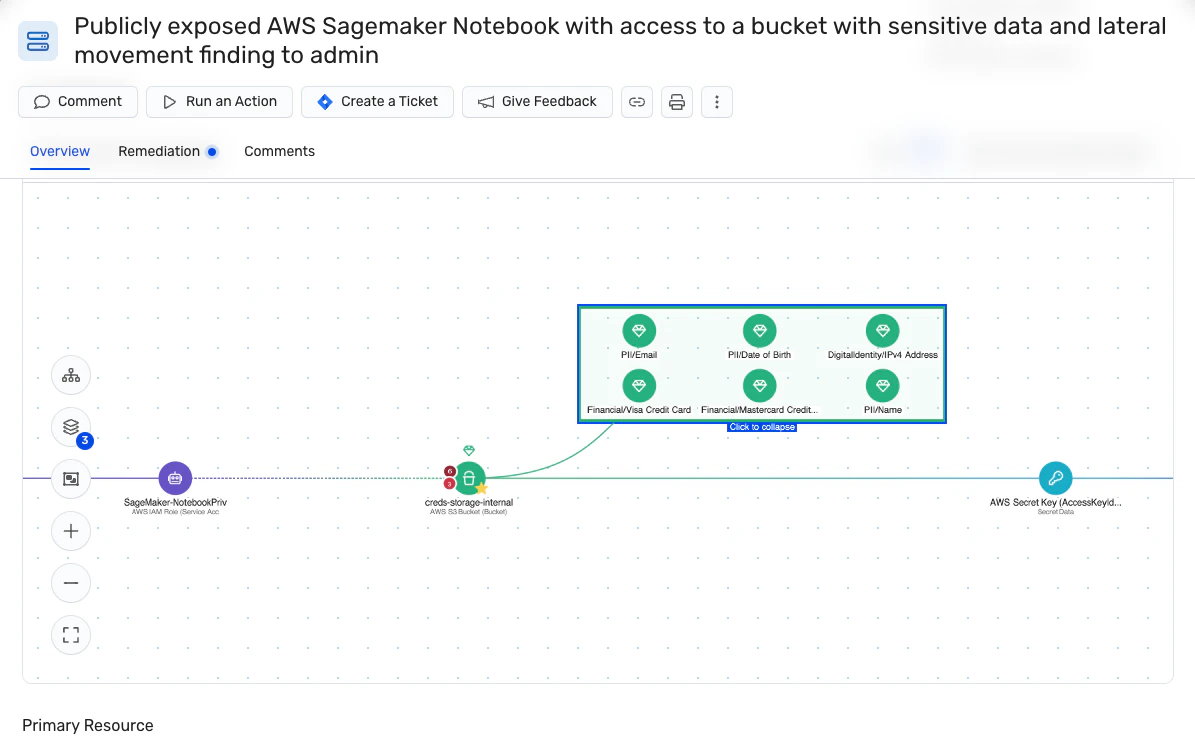
O vazamento de dados ocorre em modelos de aprendizado de máquina por meio de vazamento de destino ou contaminação de teste de trem. Neste último, os dados destinados a testar o modelo vazam para o conjunto de treinamento. Se um modelo for exposto a dados de teste durante o treinamento, suas métricas de desempenho serão enganosamente altas.
No vazamento de alvo, os subconjuntos usados para treinamento incluem informações indisponíveis na fase de previsão do desenvolvimento de ML. Embora os LLMs tenham um bom desempenho nesse cenário, eles oferecem às partes interessadas uma falsa sensação de eficácia do modelo, levando a um desempenho ruim em aplicativos do mundo real.


Causas comuns de vazamento de dados
O vazamento de dados ocorre por vários motivos; A seguir estão alguns dos mais comuns.
Erro humano
O erro humano pode acontecer em qualquer nível dentro de uma organização, muitas vezes sem intenção maliciosa. Por exemplo, os funcionários podem enviar acidentalmente informações confidenciais, como registros financeiros ou dados pessoais, para o endereço de e-mail errado.
Ataques de phishing
Os ataques de phishing se manifestam de várias formas, mas têm um método: os cibercriminosos atraem contas privilegiadas para fornecer detalhes valiosos. Por exemplo, os invasores podem enviar e-mails aparentemente legítimos pedindo aos funcionários que cliquem em links maliciosos e façam login em uma determinada conta. Ao fazer isso, o funcionário oferece suas credenciais de login ao invasor, que são usadas para um ou vários fins maliciosos.
Configuração ruim
Bancos de dados, serviços em nuvem e configurações de software mal configurados criam vulnerabilidades que expõem dados confidenciais a acesso não autorizado. Configurações incorretas geralmente ocorrem devido a supervisão, falta de experiência ou falha em seguir as melhores práticas de segurança. Deixar as configurações padrão inalteradas, como nomes de usuário e senhas padrão, pode conceder acesso fácil aos cibercriminosos.
Configurações incorretas do aplicativo, falha na aplicação de patches e atualizações de segurança e configurações inadequadas de controles/permissões de acesso também podem criar brechas de segurança.
Medidas de segurança fracas
Medidas de segurança fracas diminuem uma organização's postura de segurança. Usando senhas simples e fáceis de adivinhar; falha na implementação de políticas de senha forte; conceder permissões excessivas e não seguir o princípio do privilégio mínimo (PoLP); ou reutilizar senhas em várias contas aumenta o risco de vazamento de dados.
Além disso, deixando dados Criptografado— em repouso e em trânsito — predispõe os dados a vazamentos. Não implementar o princípio do privilégio mínimo (PoLP) e confiar em protocolos/tecnologias de segurança desatualizados pode criar lacunas em sua estrutura de segurança.
Estratégias para evitar vazamentos
1. Pré-processamento e higienização de dados
Anonimização e Redação
A anonimização envolve a alteração ou remoção de informações de identificação pessoal (PII) e dados confidenciais para evitar que sejam vinculados a indivíduos. A redação é um processo mais específico que envolve a remoção ou ocultação de partes confidenciais dos dados, como números de cartão de crédito, números de previdência social ou endereços.
Sem anonimização e redação adequadas, os modelos de IA podem "memorizar" dados confidenciais do conjunto de treinamento, que podem ser reproduzidos inadvertidamente nas saídas do modelo. Isso é especialmente perigoso se o modelo for usado em aplicativos públicos ou voltados para o cliente.
Melhores práticas:
Use técnicas de tokenização, hash ou criptografia para anonimizar os dados.
Certifique-se de que todos os dados editados sejam removidos permanentemente dos conjuntos de dados estruturados (por exemplo, bancos de dados) e não estruturados (por exemplo, arquivos de texto) antes do treinamento.
Implemente a privacidade diferencial (discutida posteriormente) para reduzir ainda mais o risco de exposição de dados individuais.
Minimização de dados
A minimização de dados envolve apenas coletar e usar o menor conjunto de dados necessário para atingir o objetivo do modelo de IA. Quanto menos dados coletados, menor o risco de vazamento de informações confidenciais.
A coleta excessiva de dados aumenta a superfície de risco de violações e as chances de vazamento de informações confidenciais. Usando apenas o que's necessário, você também garante a conformidade com os regulamentos de privacidade, como GDPR ou CCPA.
Melhores práticas:
Realize uma auditoria de dados para avaliar quais pontos de dados são essenciais para o treinamento.
Implemente políticas para descartar dados não essenciais no início do pipeline de pré-processamento.
Revise regularmente o processo de coleta de dados para garantir que nenhum dado desnecessário seja retido.
2. Proteções de treinamento modelo
Divisão de dados adequada
A divisão de dados separa o conjunto de dados em conjuntos de treinamento, validação e teste. O conjunto de treinamento ensina o modelo, enquanto os conjuntos de validação e teste garantem a precisão do modelo sem sobreajuste.
Se os dados forem divididos incorretamente (por exemplo, os mesmos dados estão presentes nos conjuntos de treinamento e teste), o modelo pode efetivamente "memorizar" o conjunto de testes, levando à superestimação de seu desempenho e à exposição potencial de informações confidenciais nas fases de treinamento e previsão.
Melhores práticas:
Randomize conjuntos de dados durante a divisão para garantir que não haja sobreposição entre os conjuntos de treinamento, validação e teste.
Use técnicas como validação cruzada de k dobras para avaliar de forma robusta o desempenho do modelo sem vazamento de dados.
Técnicas de Regularização
Técnicas de regularização são empregadas durante o treinamento para evitar o sobreajuste, em que o modelo se torna muito específico para os dados de treinamento e aprende a "memorizar" em vez de generalizar a partir deles. O sobreajuste aumenta a probabilidade de vazamento de dados, pois o modelo pode memorizar informações confidenciais dos dados de treinamento e reproduzi-las durante a inferência.
Melhores práticas:
Abandono escolar: Descarte aleatoriamente certas unidades (neurônios) da rede neural durante o treinamento, forçando o modelo a generalizar em vez de memorizar padrões.
Queda de peso (regularização L2): Penalize pesos grandes durante o treinamento para evitar que o modelo se ajuste muito aos dados de treinamento.
Parada antecipada: Monitore o desempenho do modelo em um conjunto de validação e interrompa o treinamento quando o modelo'O desempenho começa a degradar devido ao sobreajuste.
Privacidade diferencial
A privacidade diferencial adiciona ruído controlado aos dados ou saídas do modelo, garantindo que se torne difícil para os invasores extrair informações sobre qualquer ponto de dados individual no conjunto de dados.
Ao aplicar a privacidade diferencial, os modelos de IA têm menos probabilidade de vazar detalhes de indivíduos específicos durante o treinamento ou a previsão, fornecendo uma camada de proteção contra ataques adversários ou vazamento de dados não intencional.
Melhores práticas:
Adicione ruído gaussiano ou de Laplace a dados de treinamento, gradientes de modelo ou previsões finais para obscurecer contribuições de dados individuais.
Use estruturas como TensorFlow Privacy ou PySyft para aplicar a privacidade diferencial na prática.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Implantação segura de modelos
Isolamento de locatário
Em um ambiente multilocatário, o isolamento de locatário cria um limite lógico ou físico entre cada locatário', impossibilitando que um locatário acesse ou manipule outro's informações confidenciais. Isolando cada inquilino', as empresas podem impedir o acesso não autorizado, reduzir o risco de violações de dados e garantir a conformidade com os regulamentos de proteção de dados.
O isolamento do locatário fornece uma camada adicional de segurança, dando às organizações tranquilidade sabendo que seus dados confidenciais de treinamento de IA está protegido contra possíveis vazamentos ou acesso não autorizado.
Melhores práticas:
Separação lógica: use técnicas de virtualização como contêineres ou VMs (máquinas virtuais) para garantir que os dados e o processamento de cada locatário sejam isolados uns dos outros.
Controles de acesso: Implemente políticas rígidas de controle de acesso para garantir que cada locatário possa acessar apenas seus próprios dados e recursos.
Criptografia e gerenciamento de chaves: Use chaves de criptografia específicas do locatário para segregar ainda mais os dados, garantindo que, mesmo que ocorra uma violação, os dados de outros locatários permaneçam seguros.
Limitação e monitoramento de recursos: Impedir que os locatários esgotem recursos compartilhados impondo limites de recursos e monitorando comportamentos anômalos que possam comprometer o isolamento do sistema.
Sanitização de saída
A limpeza de saída envolve a implementação de verificações e filtros nas saídas do modelo para evitar a exposição acidental de dados confidenciais, especialmente em processamento de linguagem natural (NLP) e modelos generativos.
Em alguns casos, o modelo pode reproduzir informações confidenciais encontradas durante o treinamento (por exemplo, nomes ou números de cartão de crédito). A higienização das saídas garante que nenhum dado confidencial seja exposto.
Melhores práticas:
Use algoritmos de correspondência de padrões para identificar e redigir PII (por exemplo, endereços de e-mail, números de telefone) nas saídas do modelo.
Defina limites em saídas probabilísticas para evitar que o modelo faça previsões excessivamente confiáveis que possam expor detalhes confidenciais.
4. Práticas Organizacionais
Treinamento de funcionários
O treinamento de funcionários garante que todos os indivíduos envolvidos no desenvolvimento, implantação e manutenção de modelos de IA entendam os riscos de vazamento de dados e as melhores práticas para mitigá-los. Muitas violações de dados ocorrem devido a erro humano ou descuido. O treinamento adequado pode evitar a exposição acidental de informações confidenciais ou vulnerabilidades de modelo.
Melhores práticas:
Forneça treinamento regular de segurança cibernética e privacidade de dados para todos os funcionários que lidam com modelos de IA e dados confidenciais.
Atualize a equipe sobre os riscos emergentes de segurança da IA e novas medidas preventivas.
Políticas de governança de dados
As políticas de governança de dados estabelecem diretrizes claras sobre como os dados devem ser coletados, processados, armazenados e acessados em toda a organização, garantindo que as práticas de segurança sejam aplicadas de forma consistente.
Uma política de governança bem definida garante que o tratamento de dados seja padronizado e esteja em conformidade com as leis de privacidade, como GDPR ou HIPAA, reduzindo as chances de vazamento.
Melhores práticas:
Defina a propriedade dos dados e estabeleça protocolos claros para lidar com dados confidenciais em todas as etapas do desenvolvimento da IA.
Revise e atualize regularmente as políticas de governança para refletir novos riscos e requisitos regulatórios.
5. Aproveite as ferramentas de gerenciamento de postura de segurança de IA (AI-SPM)
Soluções AI-SPM fornecer visibilidade e controle sobre componentes críticos da segurança de IA, incluindo os dados usados para treinamento/inferência, integridade do modelo e acesso a modelos implantados. Ao incorporar uma ferramenta AI-SPM, as organizações podem gerenciar proativamente a postura de segurança de seus modelos de IA, minimizando o risco de vazamento de dados e garantindo uma governança robusta do sistema de IA.
Como o AI-SPM ajuda a evitar o vazamento do modelo de ML:
Descubra e faça um inventário de todos os aplicativos, modelos e recursos associados de IA
Identifique vulnerabilidades na cadeia de suprimentos de IA e configurações incorretas que podem levar ao vazamento de dados
Monitore dados confidenciais em toda a pilha de IA, incluindo dados de treinamento, bibliotecas, APIs e pipelines de dados
Detecte anomalias e possíveis vazamentos de dados em tempo real
Implemente proteções e controles de segurança específicos para sistemas de IA
Realize auditorias e avaliações regulares de aplicativos de IA


Como a Wiz pode ajudar
Com seu gerenciamento abrangente de postura de segurança de dados (DSPM), o Wiz ajuda a prevenir e detectar vazamento de dados das seguintes maneiras.
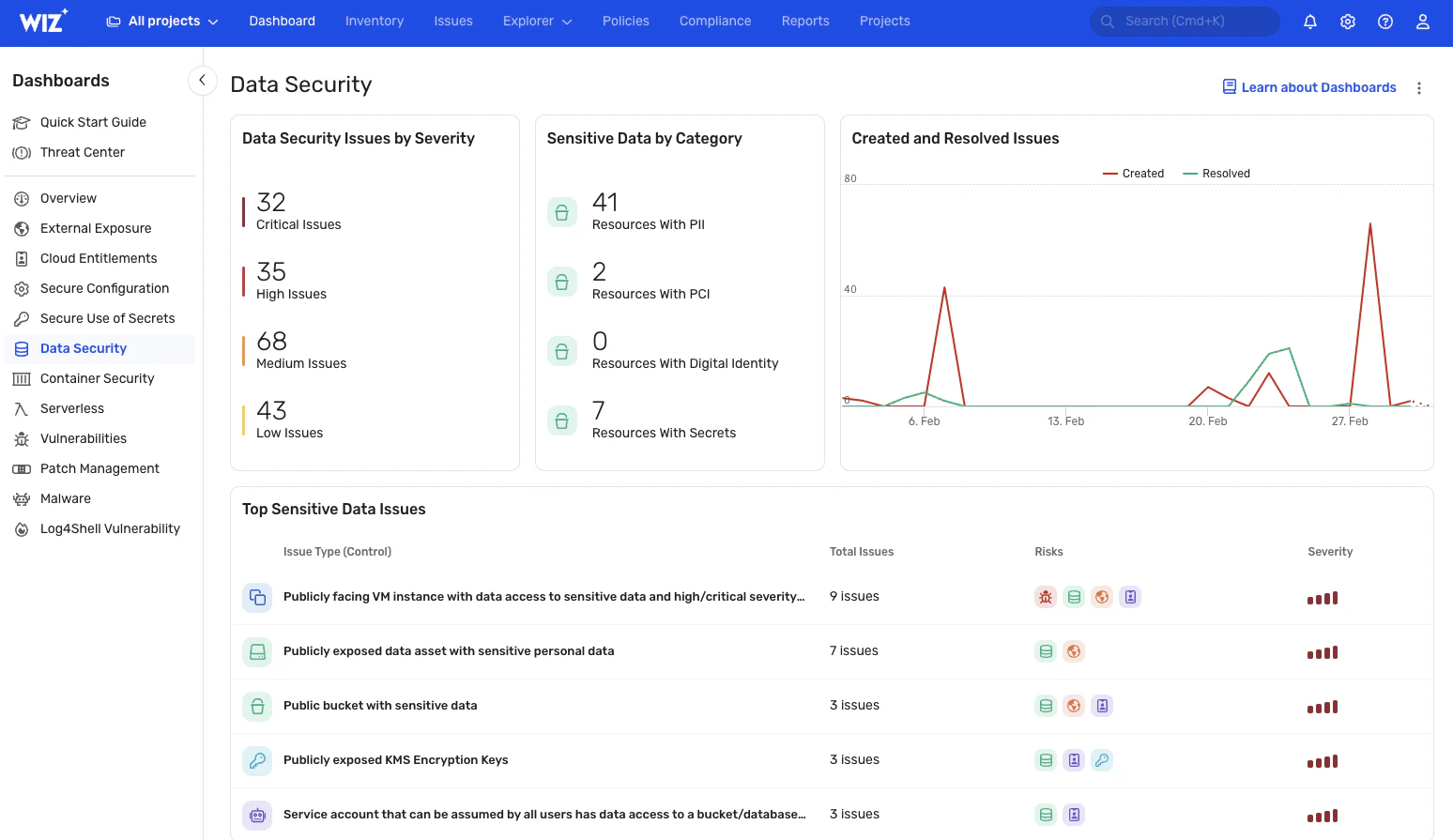
Descubra e classifique dados automaticamente
A Wiz monitora continuamente a exposição de dados críticos, fornecendo visibilidade em tempo real de informações confidenciais, como dados PII, PHI e PCI. Ele fornece uma visão atualizada de onde os dados estão e como eles estão sendo acessados (mesmo em seus sistemas de IA com nosso Solução AI-SPM). Você também pode criar classificadores personalizados para identificar dados confidenciais exclusivos da sua empresa. Esses recursos facilitam ainda mais a resposta rápida a incidentes de segurança, evitando danos ou minimizando significativamente o raio de explosão potencial.
Avaliação de risco de dados
O Wiz detecta caminhos de ataque correlacionando as descobertas de dados a vulnerabilidades, configurações incorretas, identidades e exposições que podem ser exploradas. Em seguida, você pode desativar esses caminhos de exposição antes que os agentes de ameaças possam explorá-los. A Wiz também visualiza e prioriza os riscos de exposição com base em seu impacto e taxa de gravidade, garantindo que os problemas mais críticos sejam tratados primeiro.
Além disso, o Wiz auxilia na governança de dados detectando e exibindo quem pode acessar quais dados.
Segurança de dados para dados de treinamento de IA
A Wiz fornece uma avaliação de risco completa de seus ativos de dados, incluindo a chance de vazamento de dados, com IA DSPM Controles. Nossas ferramentas fornecem uma visão holística da postura de segurança de dados da sua organização, destacam áreas que precisam de atenção e oferecem orientações detalhadas para reforçar suas medidas de segurança e corrigir problemas rapidamente.
Avaliação contínua de conformidade
A avaliação contínua de conformidade da Wiz garante que sua organização'A postura de segurança do está alinhada com os padrões do setor e os requisitos regulatórios em tempo real. Nossa plataforma verifica configurações incorretas e vulnerabilidades, fornecendo recomendações acionáveis para correção e automatizando relatórios de conformidade.
Com Wiz Recursos e funcionalidades do DSPM, você pode efetivamente ajudar sua organização a mitigar os riscos de vazamento de dados e garantir robustez Proteção de dados e conformidade. Agende uma demonstração hoje para saber mais.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
