

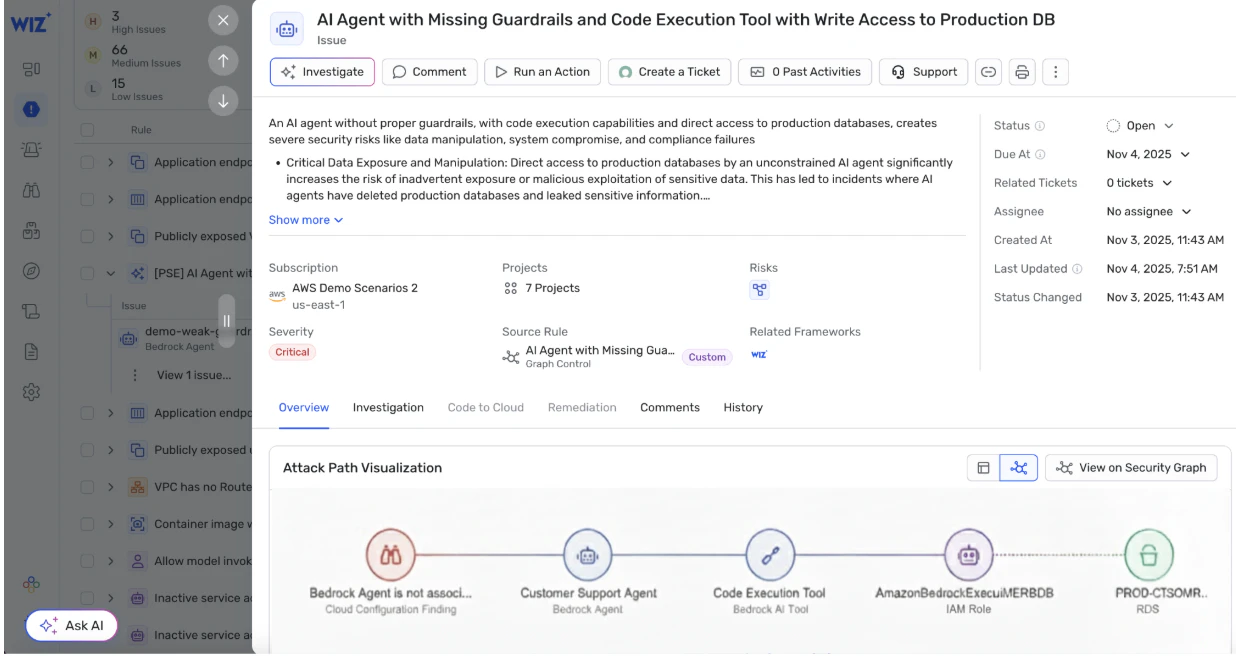
KI-Agent-Sicherheit im Überblick
KI-Agent-Sicherheit bezeichnet, wie autonome KI-Systeme sicher, vorhersehbar und kontrolliert bleiben, wenn sie Aktionen auf echten Systemen ausführen.
Ein KI-Agent nutzt ein Modell, um eine Aufgabe zu analysieren, plant dann konkrete Schritte und führt sie aus: Logs lesen, eine Cloud-API aufrufen, ein Dataset aktualisieren und eine Nachricht senden – ohne dass ein Mensch jeden Befehl einzeln bestätigen müsste.
In Cloud-Umgebungen laufen Agents in Containern, Serverless-Funktionen oder Workflow-Engines. Sie verwenden Service-Accounts, API-Schlüssel und Cloud-Rollen für den Ressourcenzugriff. Das macht jeden Agenten zu einer Non-Human-Identity, also einer maschinellen Identität mit eigenen Berechtigungen.
Konkret heißt das: definieren, was ein Agent tun darf, begrenzen, welche Systeme er erreichen kann, und seine Aktionen End-to-End validieren – damit er innerhalb des beabsichtigten Verhaltens bleibt.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

KI-Agents als neue Angriffsfläche
KI-Agents bringen ein anderes Risikoprofil mit als traditionelle KI-Modelle, weil sie echte Aktionen ausführen. KI-Agent-Sicherheit rückt damit in den Mittelpunkt moderner digitaler Sicherheitskonzepte.
Mehrere Eigenschaften vergrößern die Angriffsfläche:
Aktionen statt Informationen: Eine Prompt-Injection ändert nicht mehr nur Text – sie kann den Systemzustand ändern.
Live-Systemzugriff: Agents arbeiten mit Credentials und Rollen. Ihre Entscheidungen werden mit echten Berechtigungen ausgeführt.
Tool- und API-Verkettung: Eine einzige Anfrage kann mehrere Schritte auslösen, die der Agent selbst wählt.
Externe Einflussnahme: Agents lassen sich durch Daten steuern, die sie lesen – nicht nur durch direkte Prompts.
Gespeicherter Kontext: Memory und Kontext können Anweisungen speichern, die zukünftiges Verhalten prägen.
Supply-Chain-Risiken: Frameworks, Plugins und Retrieval-Systeme führen zu neuen Abhängigkeiten.
Das Ergebnis: Die zentrale Sicherheitsfrage verschiebt sich von:
„Kann jemand das Modell beeinflussen?" zu „Was kann der Agent erreichen oder ändern, wenn das passiert?"
Diese Verschiebung – von Textgenerierung zu Ausführung mit Zugriff – macht KI-Agent-Sicherheit zu einer eigenständigen Disziplin, die sich klar von traditioneller Modellsicherheit unterscheidet.
Risiken von KI-Agents
Bei den meisten KI-Agent-Vorfällen zeichnen sich erkennbare Muster ab. Dadurch lassen sich mögliche Risiken eingrenzen.
1. Unautorisierte Aktionen durch Agent-Logik
Kleine Manipulationen in der Eingabe oder im Kontext können einen Agenten dazu bringen, Schritte außerhalb seines beabsichtigten Umfangs auszuführen. Das kann bedeuten:
Der Agent löst einen Workflow vorzeitig aus.
Der Agent führt destruktive API-Aufrufe aus.
Der Agent verkettet Tools auf Arten, die niemand vorgesehen hat.
Das ist Business-Logic-Exploitation – keine traditionelle Code-Schwachstelle.
2. Missbrauch von Identität und Berechtigungen durch KI-Agents
Agents werden oft aus Bequemlichkeit mit weitreichenden Berechtigungen ausgestattet. Wenn ein Angreifer die Entscheidungsfindung des Agents beeinflusst, gewinnt er Kontrolle über diese Berechtigungen. Eine kompromittierte Agent-Identität kann:
Rollen übernehmen.
Ressourcen modifizieren.
Neue Zugriffspfade einrichten.
In Cloud-Umgebungen können so ganze Accounts kompromittiert werden.
3. Datenoffenlegung durch unbegrenzte Abfragen
Agents abstrahieren den Datenzugriff hinter Tools. Mit der richtigen Eingabe lässt sich ein Agent dazu bringen:
Sensible Daten aus einem Datastore offenzulegen.
Private Datasets zu aggregieren.
Informationen an einen externen Standort zu exportieren.
Das ist Data Exfiltration durch Automatisierung – kein direkter Datenbank-Exploit.
4. Business-Logic und unvollständige Sicherheitskonzepte
Agents betten Geschäftslogik in Prompts, Richtlinien und Tool-Definitionen ein. Wenn Sicherheitskonzepte unvollständig sind, können Angreifer:
Genehmigungsschritte umgehen.
Aktionen ohne Validierung auslösen.
Unsichere Schritte in langen Tool-Ketten verstecken sich.
Diese Fehler erzeugen oft keine Logs, die „bösartig" aussehen. Das erschwert die Erkennung erheblich.
5. Supply-Chain-Risiko durch Agent-Tools und Plugins
Agents hängen von Frameworks, Plugins, Retrievern und Embedding-Modellen ab. Wenn eine Komponente kompromittiert ist, wird der Agent:
Der Ausgabe vertrauen.
Auf manipulierten Kontext reagieren.
Bösartige Daten abrufen.
Das erzeugt Supply-Chain-Risiko auf der Tool-Ebene – nicht nur auf der Code-Ebene.
6. Modell-Missbrauch mit unsicheren Aktionen als Folge
Prompt-Injection oder indirekte Prompt-Injection kann unbeabsichtigt konkrete Wirkungen entfalten. Ein Angriff könnte:
Versteckte Anweisungen in abgerufenen Inhalten platzieren.
Die Aufgabe neu formulieren, die der Agent lösen muss.
Logikschleifen erzeugen, die die Tool-Nutzung auslösen.
Das verwandelt die Manipulation des Modells in Manipulation von Systemen.
Diese Kategorien teilen alle ein Muster:
Das Modell lässt sich beeinflussen.
Der Agent hat Zugriff.
Tools führen das Ergebnis aus.
Das erzeugt einen Angriffspfad. Wer diese Muster versteht, kann begrenzen, was ein Agent erreichen kann, und validieren, was er tut – anstatt zu versuchen, jede mögliche Anweisung zu verhindern.
GenAI Security Best Practices [Cheat Sheet]
This cheat sheet provides a practical overview of the 7 best practices you can adopt to start fortifying your organization’s GenAI security posture. Inside you’ll find:

Identity and Access Management für KI-Agents
Der effektivste Weg, einen KI-Agenten zu kontrollieren, ist die Kontrolle seiner Identität. Wenn der Agent keine Berechtigung hat, kann er sie nicht nutzen – selbst wenn seine Schlussfolgerung beeinflusst wird.
Behandelt jeden Agenten als vollwertige Non-Human-Identity mit eigenem, begrenztem Zugriff. Lasst ihn keine Schlüssel teilen oder breite Rollen von einem Service- oder Benutzerkonto erben.
Ein sicheres IAM-Muster für Agents umfasst:
Separate Identitäten: Jeder Agent nutzt seine eigene Rolle oder seinen eigenen Service-Account – niemals gemeinsame Credentials.
Prinzip der geringsten Berechtigung: Vergebt nur die Berechtigungen, die für die Aufgaben des Agents nötig sind – keinen Vollzugriff auf eine Ressource oder ein Konto.
Kurzlebige Credentials: Nutzt temporäre Tokens und automatische Rotation, damit der Zugriff schnell abläuft.
Keine Secrets im Code: Credentials gehören in einen Secret-Manager – nicht in Prompts, Umgebungsvariablen oder Konfigurationsdateien.
In Cloud-Umgebungen bedeutet das typischerweise die Nutzung nativer Identitätsprimitive:
AWS: IAM-Rollen mit temporären STS-Credentials.
Azure: Managed Identities.
GCP: Service-Accounts mit Workload-Identity.
Kubernetes: Service-Accounts mit RBAC und Cloud-Föderation (z. B. IRSA).
Berechtigungen solltet ihr regelmäßig überprüfen. Stellt einfache Fragen:
Welche Agent-Identitäten haben Admin-Rechte?
Welche Berechtigungen werden nicht genutzt und lassen sich entfernen?
Kann dieser Agent sensible Daten oder mächtige APIs erreichen?
Indem ihr begrenzt, worauf Agents zugreifen können – und sicherstellt, dass jeder eine dedizierte Identität hat –, reduziert ihr den Schadensradius bei jedem Fehler oder jeder Manipulation. Agent-Sicherheit beginnt mit dem, was der Agent tun kann – nicht nur damit, wie sich das Modell verhält.
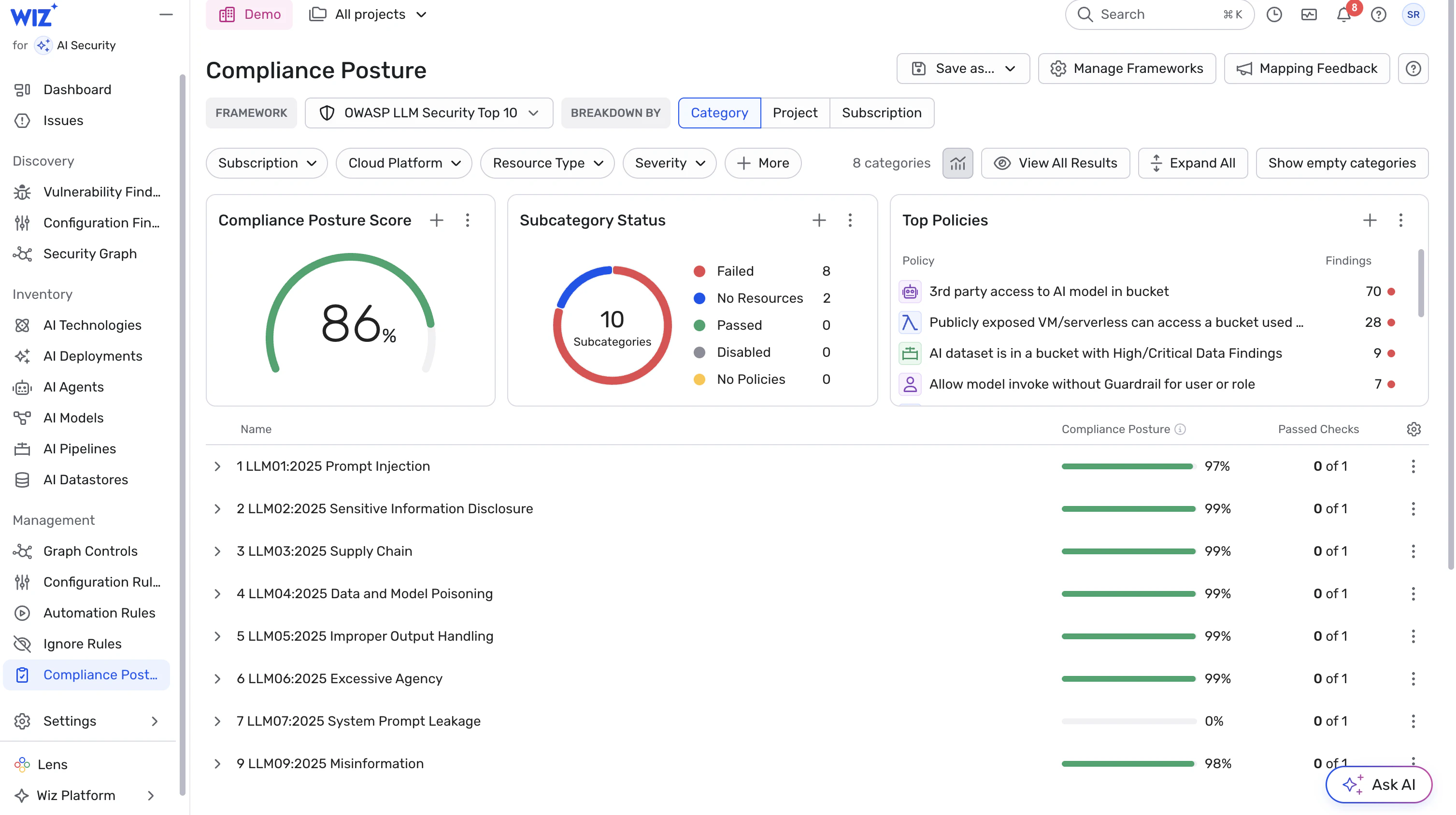
Best Practices für die Sicherheit von KI-Agents
KI-Agent-Sicherheit funktioniert am besten, wenn sie Cloud-Native-Prinzipien folgt – anstatt einen parallelen „KI-Security-Stack" zu erschaffen. Der zuverlässigste Ansatz ist phasenbasiert: Transparenz gewinnen, kritische Angriffspfade eliminieren, kontinuierlich die Runtime verteidigen und die Sicherheitseinstellungen über die Zeit verbessern. Jede Phase baut auf der vorherigen auf und nutzt Kontext aus eurer Umgebung, um Arbeit dort zu priorisieren, wo sie zählt.
1. Mit Transparenz starten: Alle KI-Agents und Workloads inventarisieren
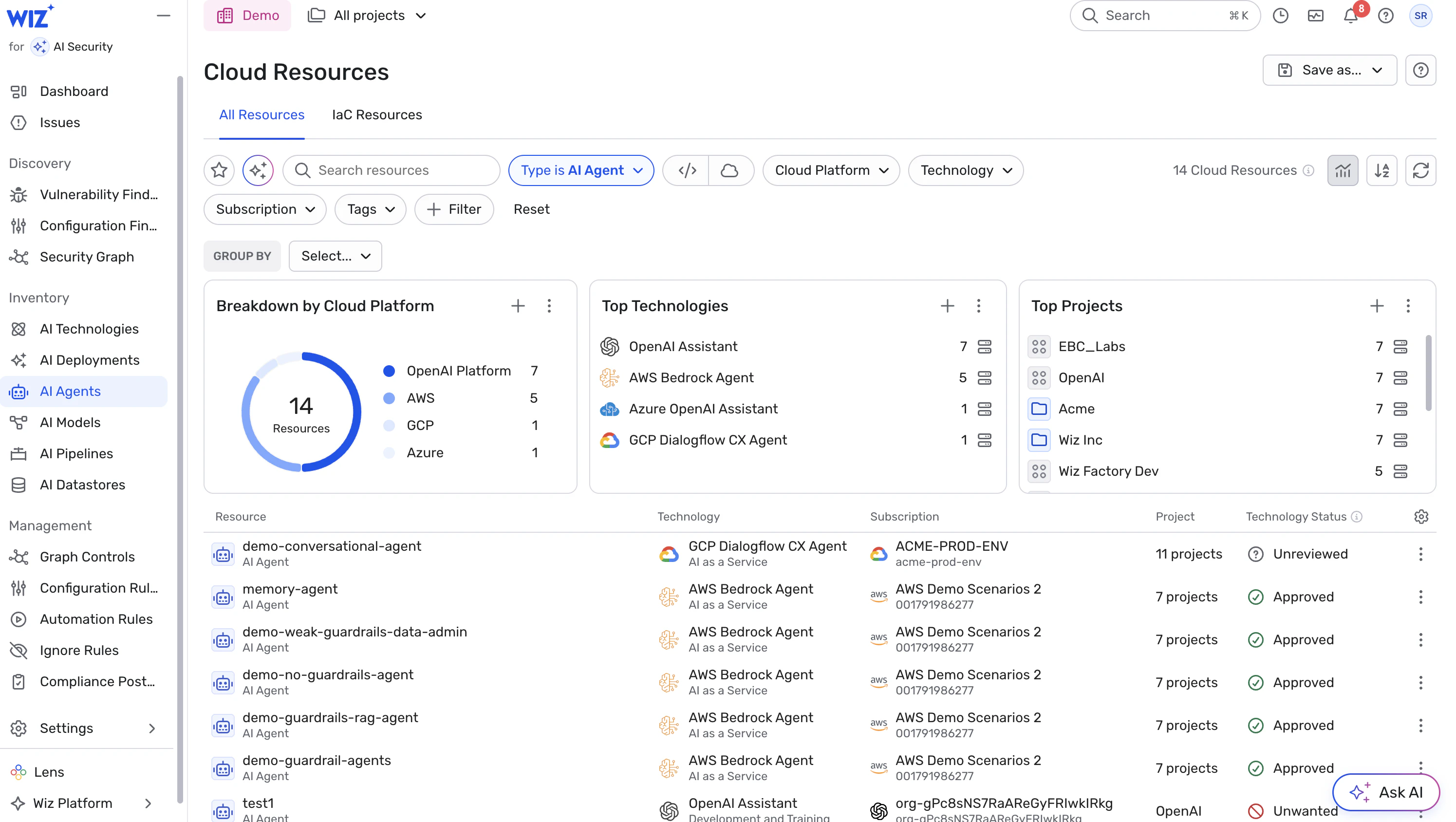
Führt ein aktuelles Inventar aller KI-bezogenen Workloads – Agents, Inferenz-Endpoints, Datenverarbeitungs-Flows usw. – einschließlich Abhängigkeiten (Modelle, SDKs, Libraries, Retriever, Datastores).
Erfasst Identität, Berechtigungen und zugehörige Ressourcen jedes Agents zentral.
Behandelt unentdeckte oder Ad-hoc-Agents als hochriskant: unbekannte Identität + unbekannte Berechtigungen = hohe Unsicherheit.
2. Kontextbezogene Risikopriorisierung statt pauschaler Regeln
Bewertet für jeden Agenten das Risiko basierend darauf, worauf er zugreifen kann (Datastores, Secrets, APIs) und wie er agieren kann (Netzwerkexposition, Cloud-Rollen, externe Schnittstellen).
Priorisiert die Behebung für Agents mit hohem Zugriff und hoher Reichweite, besonders jene, die externe Exposition mit Zugriff auf sensible Daten kombinieren.
Fokussiert auf Angriffspfad-Eliminierung: Behebt das Zusammenspiel aus Berechtigungen, Zugriffspfaden und Identitätsumfang – nicht nur isolierte Fehlkonfigurationen.
3. Sichere Konfigurationen und Guardrails standardmäßig durchsetzen
Nutzt Baseline-Konfigurationsvorlagen (IaC oder Policy-as-Code) für Agent-Deployments mit konservativen Standardwerten: minimale Berechtigungen, keine unnötige Netzwerkexposition, eingeschränkte Tool-Scopes.
Validiert alle KI-spezifischen Einstellungen (z. B. Modellberechtigungen, Input/Output-Sanitisierung, Netzwerkrichtlinien) vor dem Deployment von Agents oder Inferenz-Endpoints.
Lehnt Änderungen ab, die explosive Kombinationen eröffnen (z. B. Agent mit Internet-Exposition + Schreibzugriff auf sensible Datastores).
4. Runtime-Verhalten überwachen und Drift oder Missbrauch erkennen
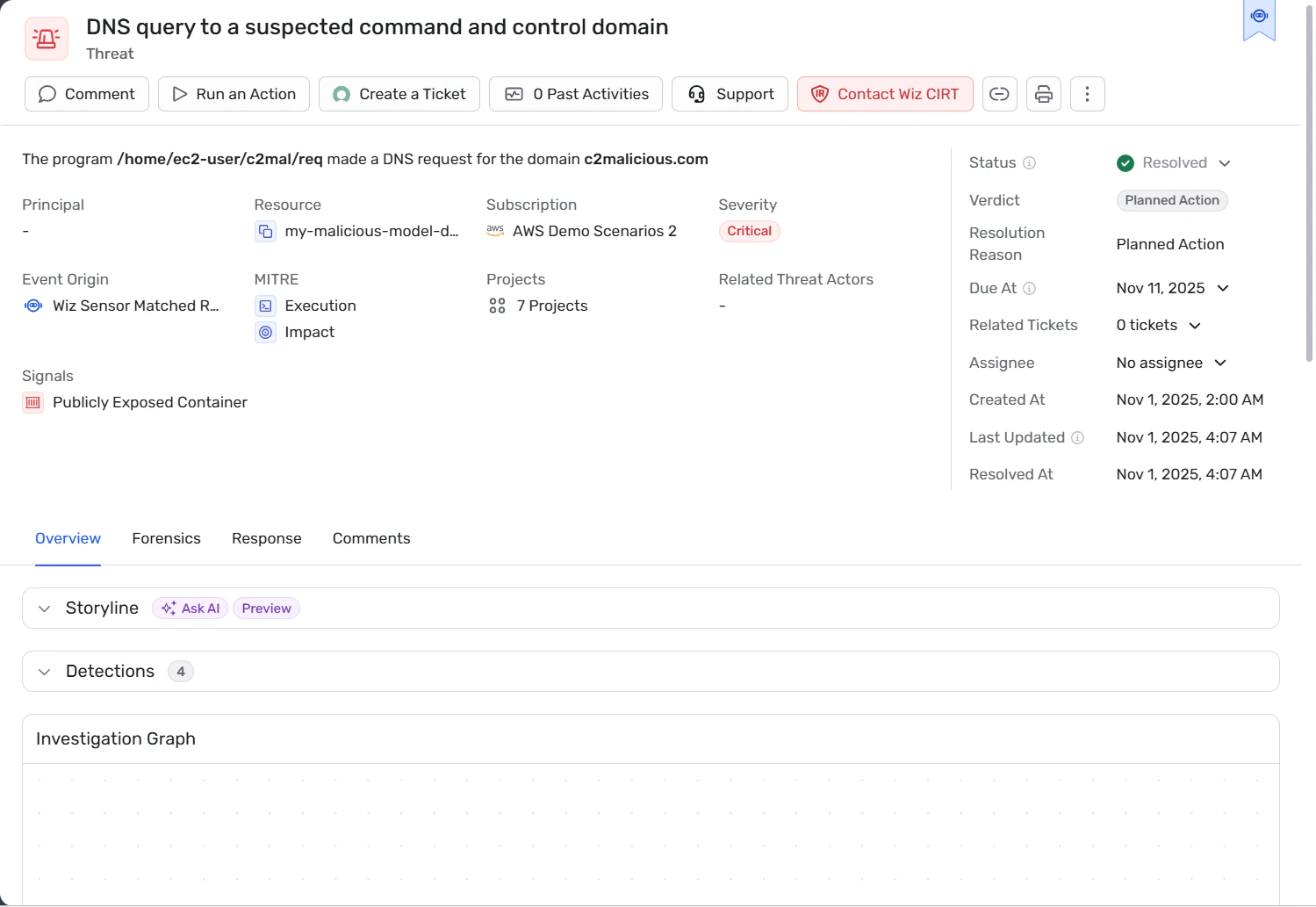
Protokolliert Agent-Aktivitäten: Tool-Aufrufe, API-Interaktionen, Datenzugriffe, ausgehende Netzwerkaufrufe – mit genug Kontext (Identität, Ressource, Datensensitivität), um zu rekonstruieren, was passiert ist.
Etabliert eine Verhaltensbaseline pro Agent oder Agent-Kategorie. Alarmiert bei Abweichungen wie ungewöhnlichen API-Aufrufen, unerwarteten Datenzugriffsmustern oder Netzwerk-Egress zu externen Zielen.
Kombiniert Runtime-Signale mit Identitäts- und Umgebungskontext, um echte Exploitation-Versuche zu erkennen – nicht nur anomale Ereignisse.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

So sichert Wiz KI-Agents ab
Wiz betrachtet KI-Agent-Sicherheit als Teil eurer Cloud-Angriffsfläche – nicht als separaten Technologie-Stack. Agents, ihre Identitäten, die Daten, die sie erreichen können, und die Workloads, auf denen sie laufen: All das bildet der Wiz Security Graph ab. So seht ihr, wo der Zugriff eines Agents eine Prompt-Manipulation in einen echten Angriffspfad verwandeln könnte.
Diese einheitliche Sicht hebt toxische Kombinationen hervor, die in der Praxis relevant sind – zum Beispiel eine aus dem Internet erreichbare Agent-Runtime mit breitem Zugriff auf einen sensiblen Datastore. Oder ein Operations-Agent, der CI/CD-Pipelines modifizieren und Produktions-Secrets lesen kann. Anstatt isolierte Findings hinterherzujagen, hilft Wiz Teams, den gesamten Pfad zu unterbrechen – mit direktem Ownership-Kontext, damit das richtige Team das Risiko an der Quelle beheben kann.
Wiz bietet auch Runtime-Transparenz durch Defend. Wenn ein Agent einen ungewöhnlichen API-Aufruf macht, Tools auf unerwartete Weise verkettet oder außerhalb seines normalen Musters mit sensiblen Daten interagiert, werden Runtime-Signale automatisch mit Cloud-Kontext angereichert: welche Identität verwendet wurde, welche Daten berührt wurden und ob die Aktion kritische Assets exponiert.
Um Fehlkonfigurationen dauerhaft zu verhindern, verknüpft Wiz Agent-Identitäten und -Berechtigungen zurück zum Code und IaC, die sie definiert haben – damit ihr das Template repariert, nicht nur die laufende Instanz.
Als Teil dieses Modells wendet Wiz AI Security Posture Management (AI-SPM) auf alle KI-Ressourcen in eurer Cloud an. Wiz erkennt KI-Fehlkonfigurationen in Inferenz-Endpoints, Agent-Runtimes und Agent-Orchestrierungs-Flows, einschließlich Deployments ohne Guardrails, unsichere Tool-Scopes oder übermäßigen Zugangs zu sensiblen Daten. Diese Findings erscheinen im Graph-Kontext. So seht ihr, wie Fehlkonfigurationen mit Identität und Netzwerkreichweite zusammenspielen, um echte Exploitation-Pfade zu erzeugen – nicht nur Konfigurationsdrift.
Entdeckt, wo KI-Agents echte Risiken in eurer Umgebung erzeugen – und wie ihr die Angriffspfade dahinter unterbrechen könnt. Demo anfordern
Develop AI Applications Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
