Was ist LLM Jacking?
LLM-Jacking ist eine Angriffstechnik, mit der Cyberkriminelle die Cloud-basierten LLMs (Large Language Models) eines Unternehmens manipulieren und ausnutzen. LLM-Jacking beinhaltet den Diebstahl und Verkauf von Anmeldeinformationen für Cloud-Konten, um böswilligen Zugriff auf die LLMs eines Unternehmens zu ermöglichen, während das Opfer unwissentlich die Verbrauchskosten trägt.
Unser Forschung zeigt, dass 7 von 10 Unternehmen Dienste der künstlichen Intelligenz (KI) nutzen, einschließlich generativer KI (GenAI)-Angebote von Cloud-Anbietern wie Amazon Bedrock und SageMaker, Google Vertex AI und Azure OpenAI Service. Diese Dienste bieten Entwicklern Zugriff auf LLM-Modelle wie Claude, Jurassic-2, die GPT-Serie, DALL-E, OpenAI Codex, Amazon Titan und Stable Diffusion. Durch den Verkauf des Zugangs zu LLM-Modellen können Cyberkriminelle einen schädlichen Dominoeffekt auslösen, der sich über mehrere Unternehmenssäulen erstreckt.
Während Bedrohungsakteure LLM-Jacking-Angriffe durchführen können, um selbst Daten zu stehlen, verkaufen sie LLM-Zugang oft an ein größeres Netz von Cyberkriminellen. Dies ist sogar noch gefährlicher, da es den Umfang und das Ausmaß potenzieller Angriffe erweitert. Durch die Entführung der LLMs eines Unternehmens kann jeder Cyberkriminelle, der Cloud-basierte LLM-Anmeldeinformationen erwirbt, einzigartige Angriffe orchestrieren.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

Was sind die möglichen Folgen eines LLM-Jacking-Angriffs?
Erhöhte Verbrauchskosten
Wenn Cyberkriminelle LLM-Jacking-Angriffe durchführen, sind übermäßige Verbrauchskosten die erste Auswirkung. Dies liegt daran, dass Cloud-basierte GenAI- und LLM-Dienste, so vorteilhaft sie auch sind, für Unternehmen recht teuer zu hosten sein können. Wenn Angreifer den Zugang zu diesen Diensten verkaufen und eine verdeckte und böswillige Nutzung ermöglichen, können sich die Kosten daher summieren. Laut Forscherkönnen LLM-Jacking-Angriffe zu Verbrauchskosten von bis zu 46.000 US-Dollar pro Tag führen. Dieser Betrag kann je nach LLM-Preismodell schwanken.
Instrumentalisierung von LLMs in Unternehmen
Wenn die LLM-Modelle eines Unternehmens nicht integer sind oder keine robusten Leitplanken aufweisen, können sie schädliche Ergebnisse erzeugen. Durch das Hijacking unternehmensspezifischer LLM-Modelle oder das Reverse-Engineering von LLM-Architekturen können Angreifer das GenAI-Ökosystem eines Unternehmens als Waffe für böswillige Angriffe und Aktivitäten nutzen. Durch die Manipulation von Unternehmens-LLMs können Bedrohungsakteure sie beispielsweise dazu bringen, falsche oder bösartige Ausgaben sowohl für Backend- als auch für kundenorientierte Anwendungsfälle zu generieren. Es kann eine Weile dauern, bis Unternehmen diese Art von Hijacking erkennen, und dann ist der Schaden oft schon angerichtet.
Verschärfung bestehender LLM-Schwachstellen
Die Einführung von LLM weist inhärente Sicherheitsherausforderungen auf. Laut OWASPZu den Top 10 LLM-Schwachstellen gehören Prompt Injection, Training Data Poisoning, Model Denial of Service, Disclosure sensibles Information, Excessive Agency, Overliance und Model Theft. Wenn Cyberkriminelle LLM-Jacking-Angriffe einsetzen, verschärfen sie die inhärenten Risiken und Schwachstellen, die mit LLMs verbunden sind, erheblich.
Schneefalleffekt auf hohem Niveau
Wenn man bedenkt, wie schnell Unternehmen GenAI und LLMs in geschäftskritische Kontexte integrieren, können LLM-Jacking-Angriffe schwerwiegende und langfristige Auswirkungen auf hoher Ebene haben. Zum Beispiel kann LLM-Jacking die Angriffsfläche eines Unternehmens erweitern, was zu Datenschutzverletzungen und anderen großen Exploits führt.
Da KI-Kompetenz eine wichtige Reputationsmetrik für die heutigen Unternehmen ist, können LLM-Jacking-Angriffe zu einem Verlust des Vertrauens und des Respekts von Kollegen und der Öffentlichkeit führen. Vergessen Sie nicht die verheerenden finanziellen Folgen von LLM-Jacking, zu denen niedrigere Gewinnspannen, Datenverlust, Ausfallkosten und Anwaltskosten gehören.
Wie funktionieren LLM-Jacking-Angriffe?
Im Prinzip ähnelt LLM Jacking Angriffen wie Kryptojacking, bei dem Bedrohungsakteure heimlich Kryptowährungen mit der Rechenleistung eines Unternehmens schürfen. In beiden Fällen nutzen Bedrohungsakteure die Ressourcen und die Infrastruktur eines Unternehmens gegen sie. Bei LLM-Jacking-Angriffen liegt das Fadenkreuz der Hacker jedoch fest auf den in der Cloud gehosteten LLM-Diensten und den Inhabern von Cloud-Konten.
Um zu verstehen, wie LLM Jacking funktioniert, betrachten wir es aus zwei Perspektiven. Zuerst untersuchen wir, wie Unternehmen LLMs nutzen, und dann gehen wir dazu über, wie Bedrohungsakteure sie ausnutzen.
Wie interagieren Unternehmen mit Cloud-gehosteten LLM-Diensten?
Die meisten Cloud-Anbieter bieten Unternehmen eine benutzerfreundliche Oberfläche und einfache Funktionen, die für die agile Einführung von LLM konzipiert sind. Diese Modelle von Drittanbietern sind jedoch nicht automatisch einsatzbereit. Erstens müssen sie aktiviert werden.
Um LLMs zu aktivieren, müssen Entwickler eine Anfrage an ihre Cloud-Anbieter stellen. Entwickler können Anfragen auf verschiedene Weise stellen, auch über einfache Anfrageformulare. Sobald Entwickler diese Antragsformulare eingereicht haben, können Cloud-Anbieter LLM-Dienste schnell aktivieren. Nach der Aktivierung können Entwickler mithilfe von CLI-Befehlen (Command Line Interface) mit ihren Cloud-basierten LLMs interagieren.
Beachten Sie, dass das Senden eines Aktivierungsantragsformulars an einen Cloud-Anbieter nicht durch eine kugelsichere Sicherheitsschicht geschützt ist. Bedrohungsakteure können das Gleiche tun, daher müssen sich Unternehmen auf zusätzliche Arten von KI- und LLM-Sicherheit konzentrieren.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Wie führen Bedrohungsakteure LLM-Jacking-Angriffe durch?
Nachdem Sie nun verstanden haben, wie Unternehmen in der Regel mit in der Cloud gehosteten LLM-Diensten interagieren, sehen wir uns an, wie Bedrohungsakteure LLM-Jacking-Angriffe ermöglichen.
Hier sind die Schritte, die Bedrohungsakteure unternehmen, um einen LLM-Jacking-Angriff zu orchestrieren:
Um Cloud-Anmeldeinformationen zu verkaufen, müssen Bedrohungsakteure diese zuerst stehlen. Als Forscher zum ersten Mal LLM-Jacking-Angriffstechniken aufdeckten, verfolgten sie die gestohlenen Anmeldedaten zu einem System, das eine anfällige Version von Laravel (CVE-2021-3129).
Sobald ein Bedrohungsakteur Anmeldedaten von einem anfälligen System stiehlt, kann er sie auf illegalen Marktplätzen an andere Cyberkriminelle verkaufen, die sie kaufen und für fortschrittlichere Angriffe nutzen können.
Mit gestohlenen Cloud-Anmeldeinformationen in der Hand müssen Bedrohungsakteure ihren Zugriff und ihre Administratorrechte bewerten. Um die Grenzen ihrer Cloud-Zugriffsrechte heimlich auszuwerten, können Cyberangreifer die
InvokeModel-APIrufen.Auch wenn die
InvokeModel-APIAufruf eine gültige Anforderung ist, können Bedrohungsakteure einen "ValidationException"-Fehler auslösen, indem sie diemax_tokens_to_samplebis -1. In diesem Schritt geht es lediglich darum, festzustellen, ob die gestohlenen Anmeldeinformationen auf LLM-Dienste zugreifen können. Tritt hingegen der Fehler "AccessDenied" auf, wissen die Bedrohungsakteure, dass die gestohlenen Anmeldeinformationen nicht angezeigt werden.'Sie verfügen nicht über ausnutzbare Zugriffsrechte.
Angreifer können sich auch auf GetModelInvocationLoggingConfiguration um die Konfigurationseinstellungen für die in der Cloud gehosteten KI-Dienste eines Unternehmens herauszufinden. Denken Sie daran, dass dieser Schritt von den Leitplanken und Fähigkeiten der einzelnen Cloud-Anbieter und -Dienste abhängt. Aus diesem Grund haben Bedrohungsakteure in einigen Fällen möglicherweise keinen vollständigen Einblick in die LLM-Ein- und -Ausgaben eines Unternehmens.
Die Durchführung eines LLM-Jacking-Angriffs garantiert keine Monetarisierung für Bedrohungsakteure. Es gibt jedoch einige Möglichkeiten, wie Bedrohungsakteure sicherstellen können, dass LLM-Jacking profitabel ist. Bei der Autopsie eines LLM-Jacking-Angriffs entdeckten die Forscher, dass Angreifer den Open-Source-OAI-Reverse-Proxy-Server möglicherweise als zentrales Panel nutzen können, um gestohlene Cloud-Anmeldeinformationen mit LLM-Zugriffsrechten zu verwalten.
Sobald Bedrohungsakteure ihre LLM-Jacking-Angriffe monetarisieren und den Zugang zu den LLM-Modellen eines Unternehmens verkaufen, gibt es keine Möglichkeit, die Art des Schadens vorherzusagen, der daraus resultieren kann. Andere Angreifer mit unterschiedlichem Hintergrund und mit unterschiedlichen Motiven können ohne ihr Wissen LLM-Zugang erwerben und die GenAI-Infrastruktur eines Unternehmens nutzen. Während die Folgen von LLM-Jacking-Angriffen zunächst im Verborgenen bleiben mögen, können die Auswirkungen katastrophal sein.


LLM-Taktiken zur Verhinderung und Erkennung von Wagenhebern
Hier sind einige leistungsstarke Möglichkeiten, wie sich Unternehmen vor LLM-Jacking-Angriffen schützen können:
Präventions-Taktiken
Robustes Modelltraining:
Vielfältige und qualitativ hochwertige Datensätze: Stellen Sie sicher, dass das Modell mit einer Vielzahl von Daten trainiert wird, um Verzerrungen und Schwachstellen zu vermeiden.
Adversarial Training: Machen Sie das Modell böswilligen Eingaben ausgesetzt, um seine Resilienz zu verbessern.
Reinforcement Learning from Human Feedback (RLHF): Ausrichten des Modells's Outputs mit menschlichen Werten und Erwartungen.
Strenge Eingabevalidierung:
Filterung: Implementieren Sie Filter, um schädliche oder böswillige Eingabeaufforderungen zu blockieren.
Desinfektion: Bereinigen Sie Eingaben, um potenziell schädliche Elemente zu entfernen.
Ratenbegrenzung: Begrenzen Sie die Anzahl der Anfragen, um Missbrauch zu verhindern.
Regelmäßige Modellprüfungen:
Schwachstellenbewertungen: Identifizieren Sie potenzielle Schwachstellen im Modell.
Bias-Erkennung: Überwachen Sie das Modell auf unbeabsichtigte Verzerrungen's Ausgänge.
Leistungsüberwachung: Verfolgen Sie die Modellleistung im Laufe der Zeit, um Anomalien zu erkennen.
Transparente Modelldokumentation:
Klare Richtlinien: Geben Sie klare Anweisungen zum verantwortungsvollen Umgang mit dem Modell.
Einschränkungen: Kommunizieren des Modells'Grenzen und potenziellen Verzerrungen.
Kontinuierliches Lernen und Anpassung:
Bleiben Sie auf dem Laufenden: Bleiben Sie auf dem Laufenden über die neuesten LLM-Bedrohungen und Gegenmaßnahmen.
Modellupdates: Aktualisieren Sie das Modell regelmäßig, um neue Sicherheitsrisiken zu beheben.
Erkennungs-Taktiken
Erkennung von Anomalien:
Identifizierung von Ausreißern: Identifizieren Sie ungewöhnliche oder unerwartete Modellverhaltensweisen.
Statistische Analyse: Verwenden Sie statistische Methoden, um Abweichungen von normalen Mustern zu erkennen.
Überwachung von Inhalten:
Keyword-Filterung: Überwachen Sie die Ausgaben auf bestimmte Keywords oder Phrasen, die mit schädlichen Inhalten verknüpft sind.
Stimmungsanalyse: Analysieren Sie die Stimmung der generierten Inhalte, um potenzielle Probleme zu identifizieren.
Stilanalyse: Erkennen Sie Anomalien im Schreibstil der generierten Inhalte.
Analyse des Nutzerverhaltens:
Ungewöhnliche Muster: Identifizieren Sie abnormales Benutzerverhalten, z. B. schnelle Anfragen oder wiederholte Aufforderungen.
Kontoüberwachung: Überwachen Sie Benutzerkonten auf verdächtige Aktivitäten.
Human-in-the-Loop-Verifizierung:
Qualitätssicherung: Stellen Sie menschliche Prüfer ein, um die Qualität und Sicherheit der generierten Inhalte zu bewerten.
Feedback-Mechanismen: Sammeln Sie Benutzerfeedback, um potenzielle Probleme zu identifizieren.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

Wie Wiz LLM-Jacking-Angriffe verhindern kann
Die bahnbrechende KI-SPM-Tool-Lösung von Wiz kann dazu beitragen, zu verhindern und abzuschwächen, dass LLM-Jacking-Angriffe zu großen Katastrophen eskalieren. Wiz AI-SPM kann auf verschiedene Weise zur Abwehr von LLM-Jacking beitragen:
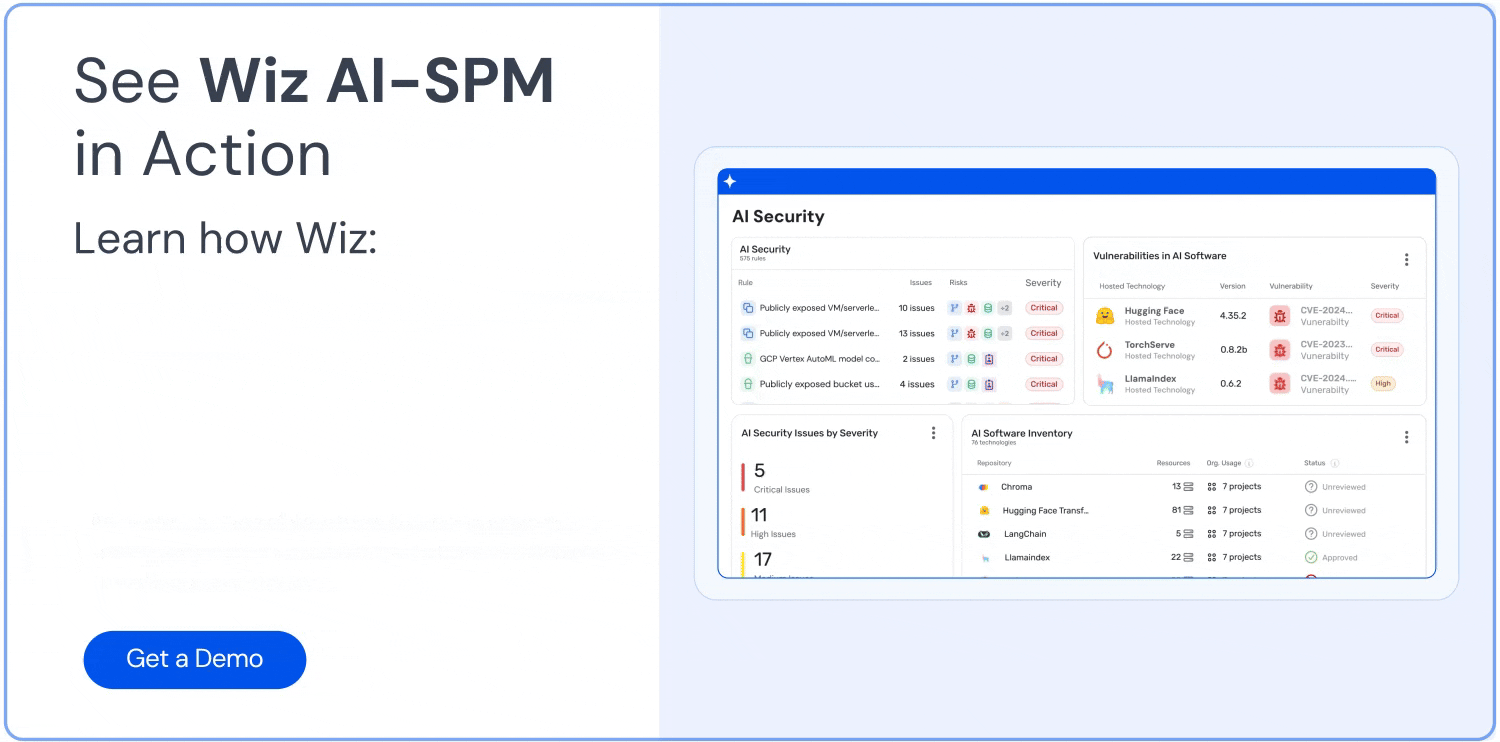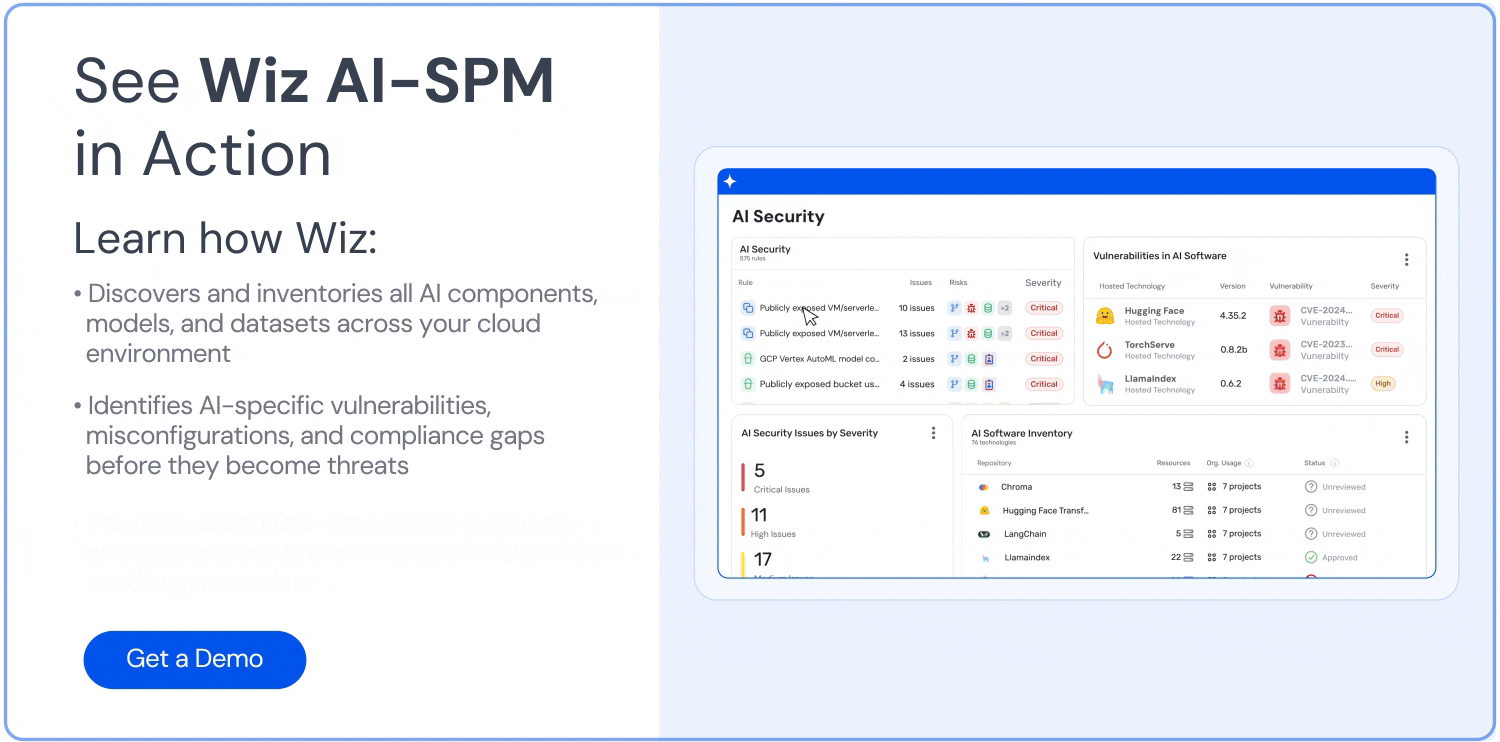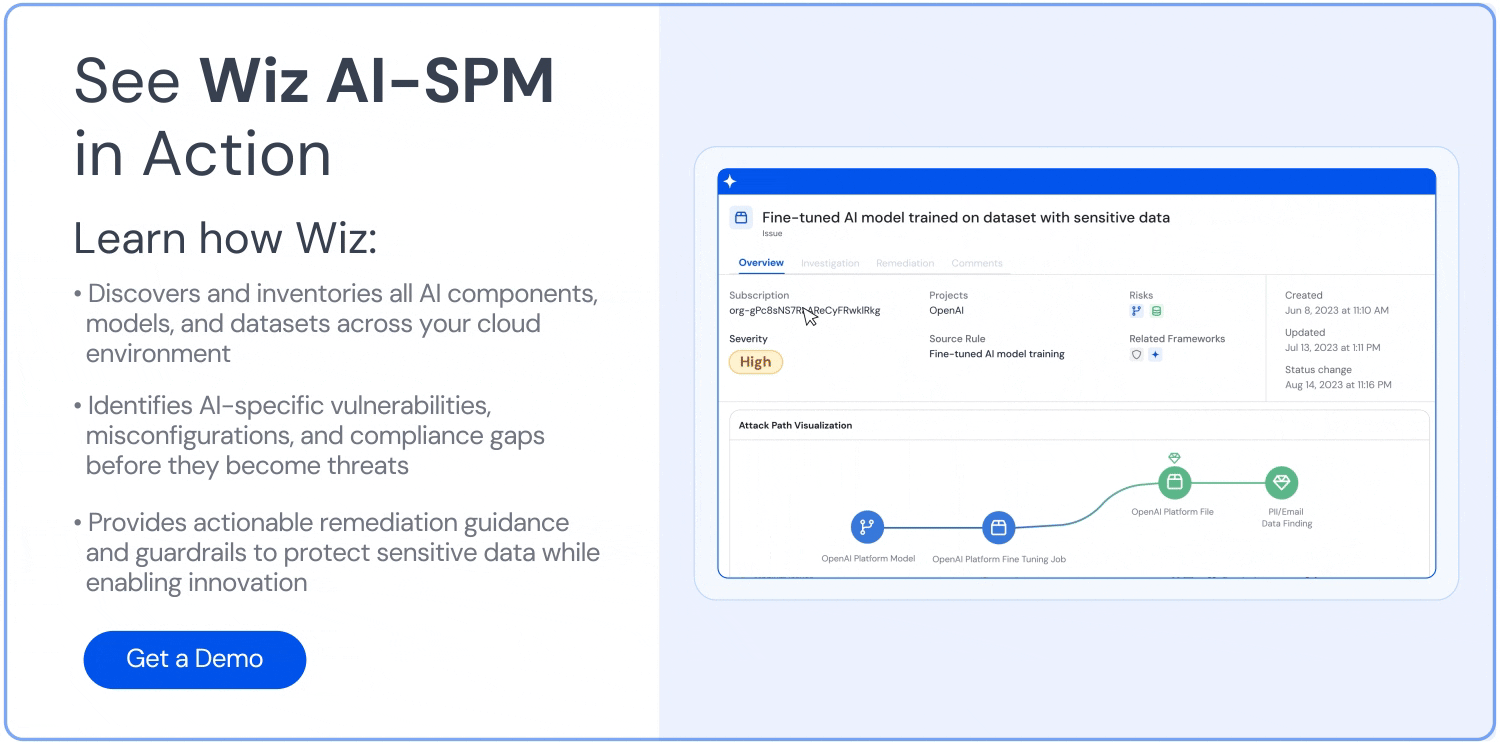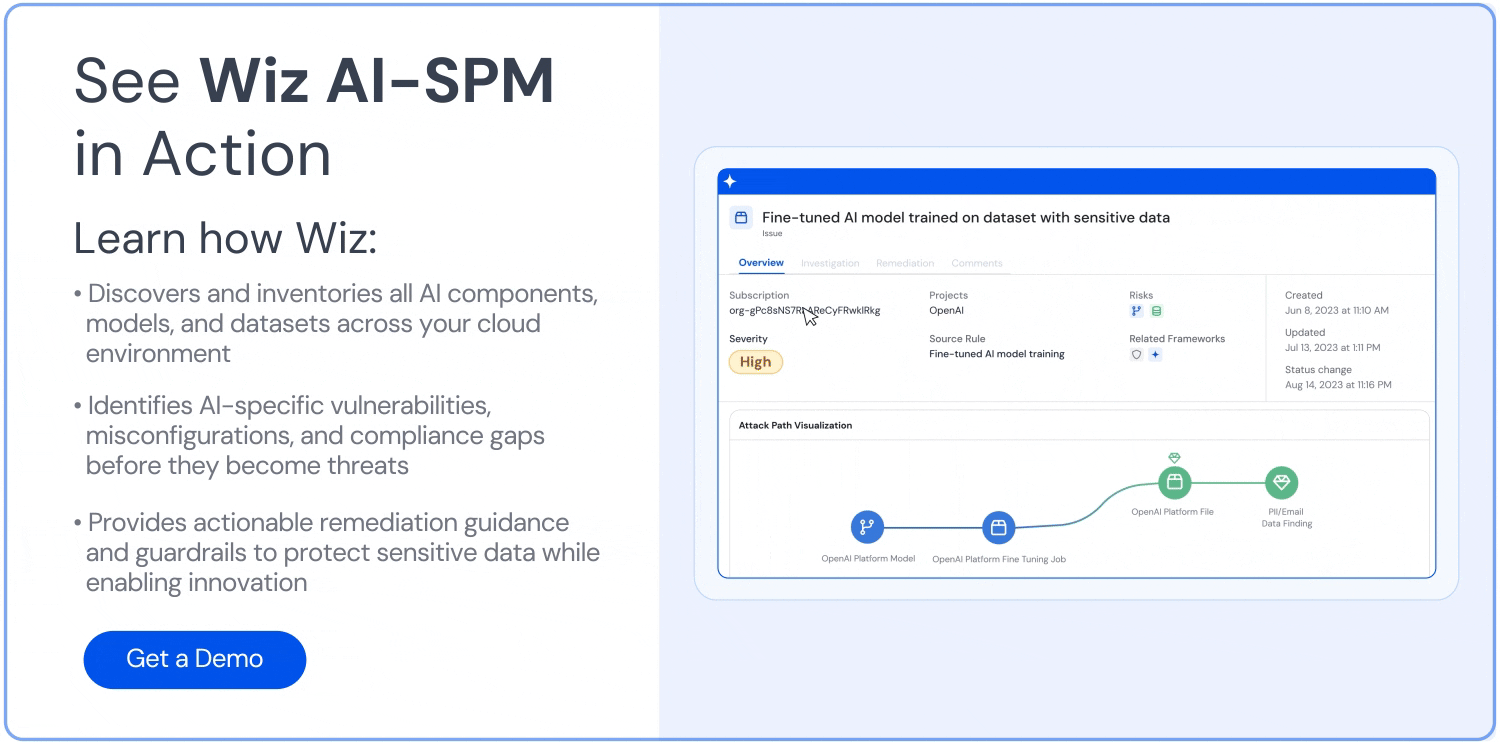
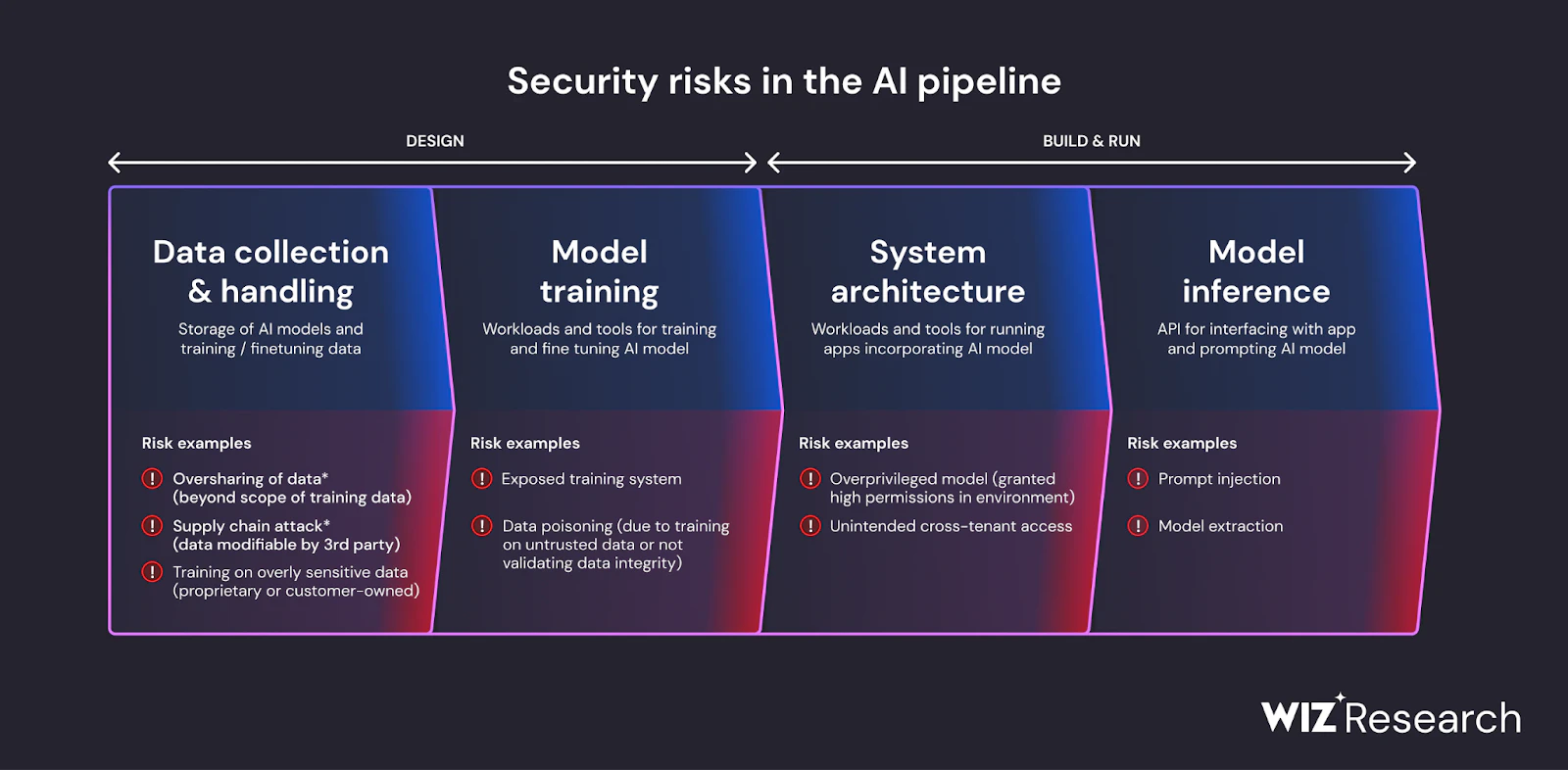
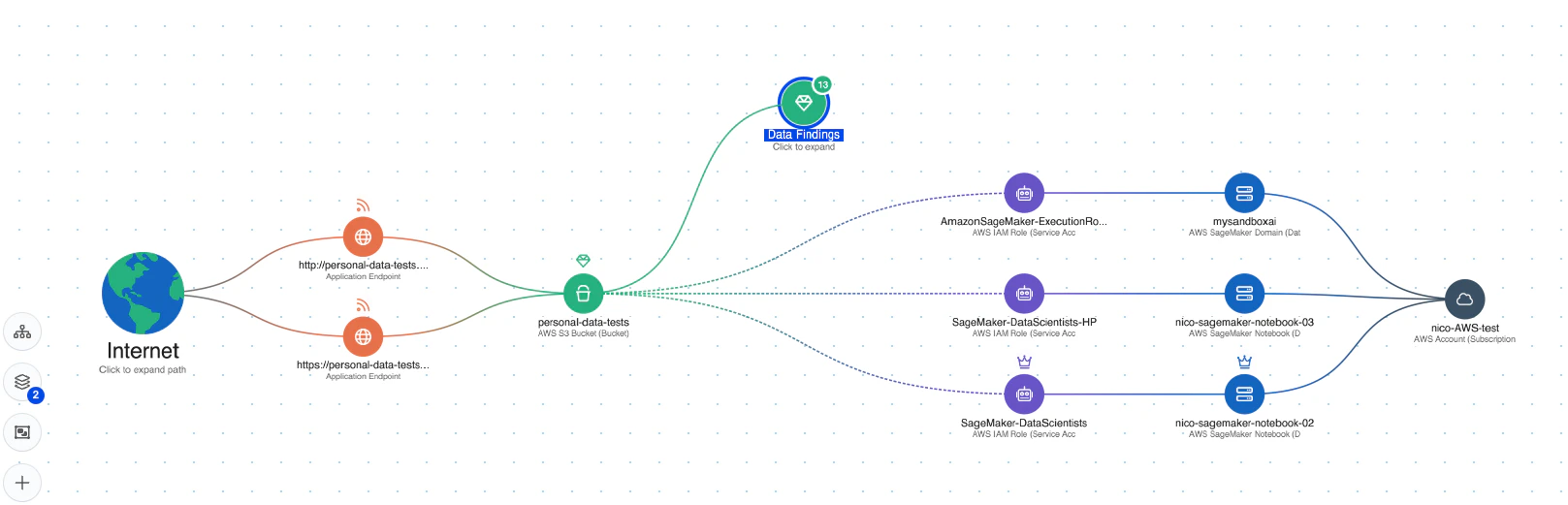
Umfassende Transparenz: Wiz AI-SPM bietet Full-Stack-Transparenz in KI-Pipelines, einschließlich KI-Services, Technologien und SDKs, ohne dass Agenten erforderlich sind. Diese Transparenz hilft Unternehmen, alle KI-Komponenten in ihrer Umgebung, einschließlich LLMs, zu erkennen und zu überwachen, wodurch es für Angreifer schwieriger wird, unbekannte oder Schatten-KI Betriebsmittel.
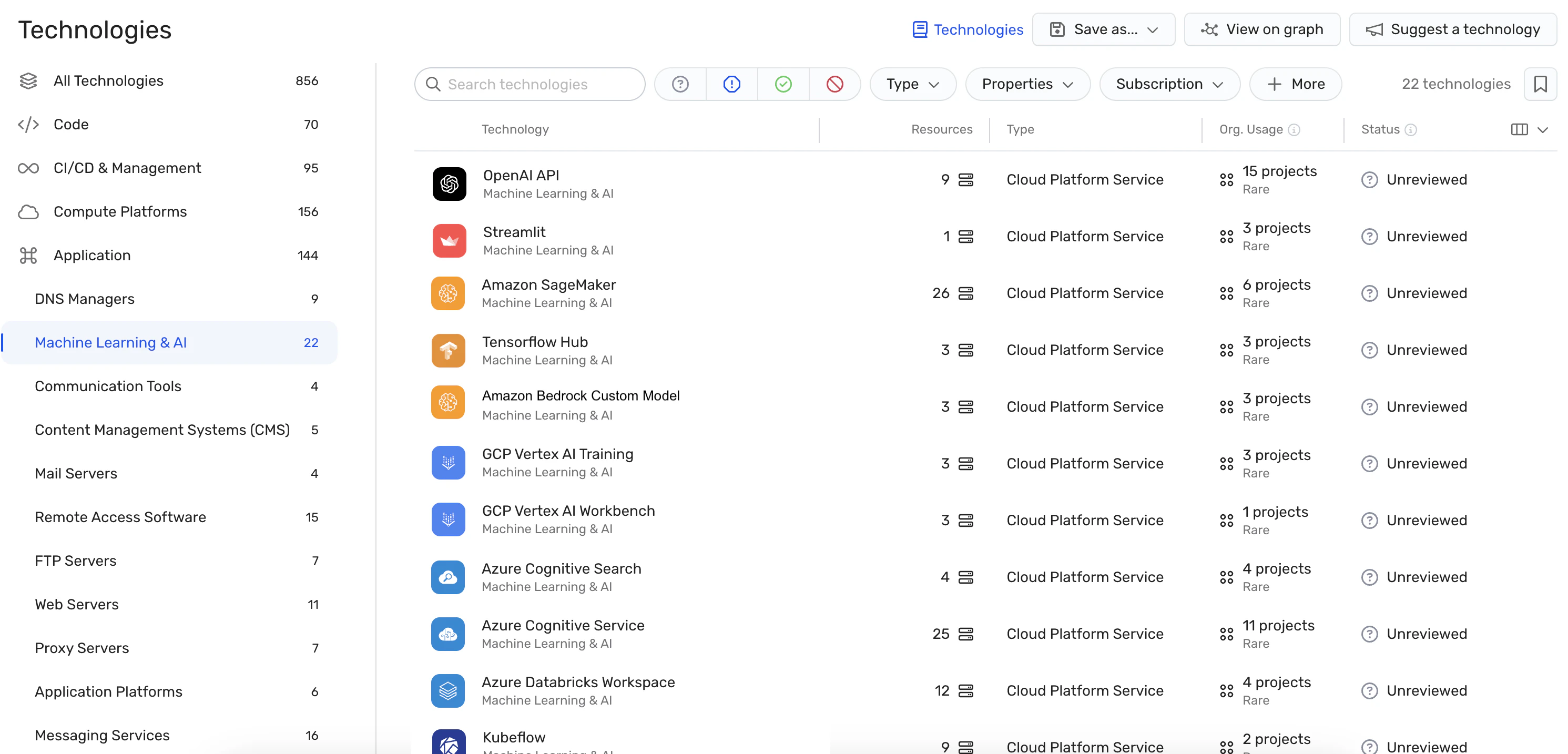
Erkennung von Fehlkonfigurationen: Die Plattform erzwingt Best Practices für die KI-Sicherheit durch die Erkennung von Fehlkonfigurationen in KI-Diensten mit eingebauten Regeln. Dies kann dazu beitragen, Schwachstellen zu verhindern, die bei LLM-Jacking-Angriffen ausgenutzt werden könnten.
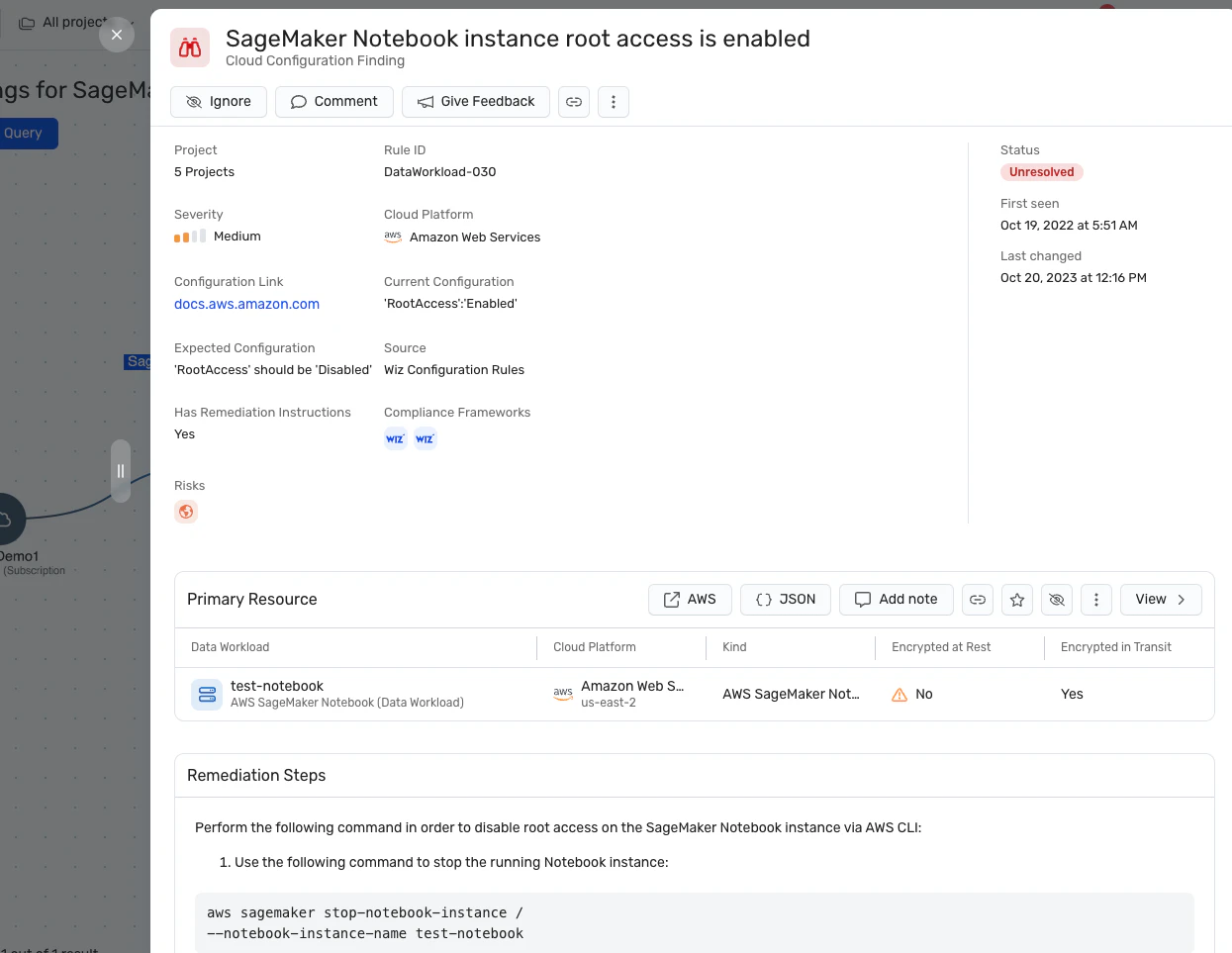
Analyse des Angriffspfads: Wiz AI-SPM identifiziert und beseitigt proaktiv Angriffspfade für KI-Modelle, indem es Schwachstellen, Identitäten, Internetrisiken, Daten, Fehlkonfigurationen und Geheimnisse bewertet. Diese umfassende Analyse kann dazu beitragen, potenzielle Eintrittspunkte für LLM-Hubversuche zu verhindern.
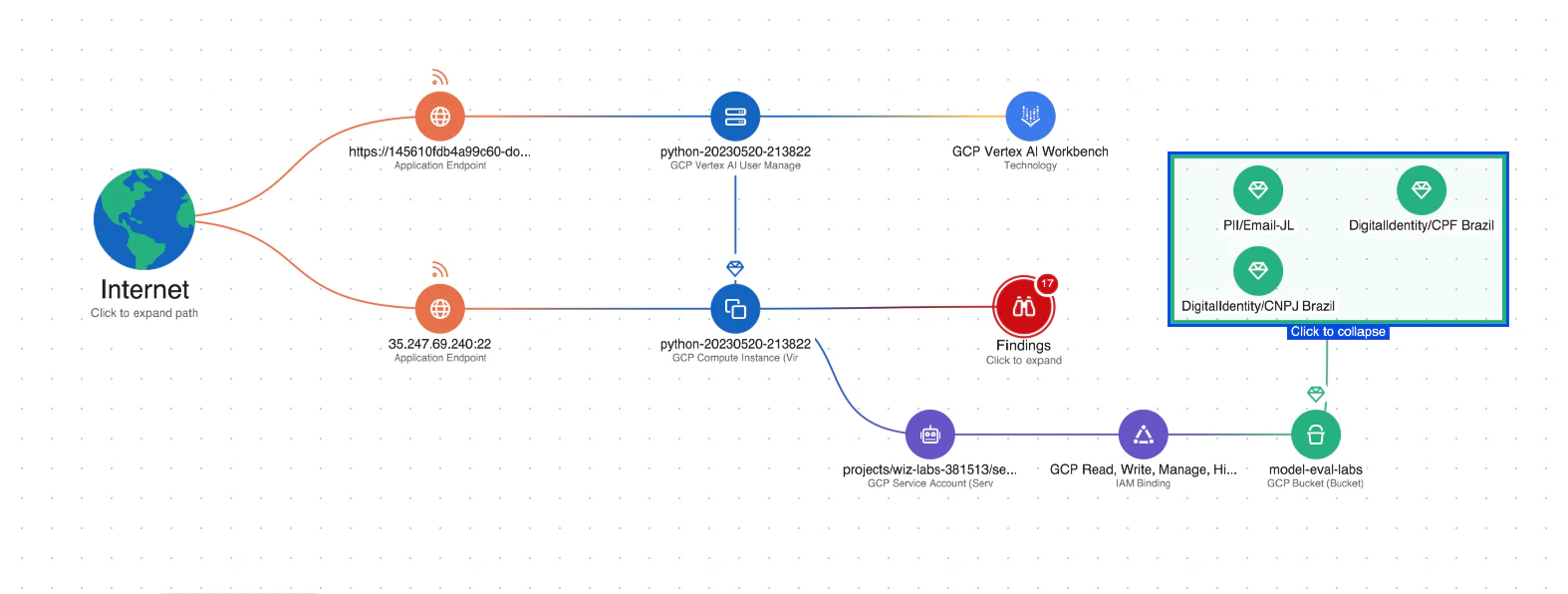
Datensicherheit für KI: Die Plattform umfasst Data Security Posture Management (DSPM) speziell für KI konzipierte Funktionen, die sensible Trainingsdaten automatisch erkennen und Angriffspfade zu ihnen entfernen können. Dies trägt zum Schutz vor Datenlecks die bei LLM-Jacking-Angriffen verwendet werden könnten.
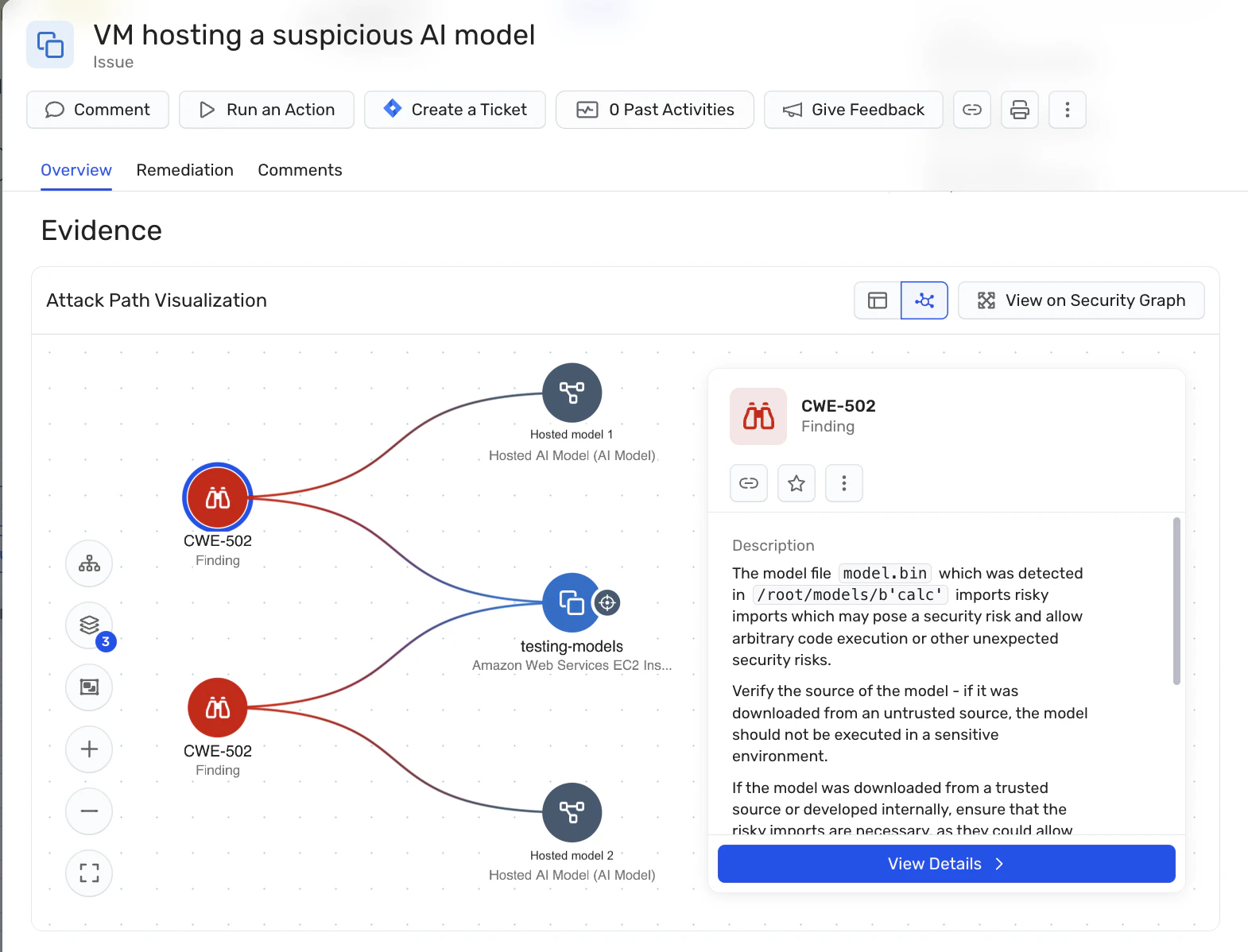
Bedrohungserkennung in Echtzeit: Wiz AI-SPM bietet Laufzeitschutz vor verdächtigem Verhalten, das von KI-Modellen ausgeht. Diese Funktion kann dazu beitragen, LLM-Hubversuche in Echtzeit zu erkennen und darauf zu reagieren, wodurch die potenziellen Auswirkungen minimiert werden.
Scannen von Modellen: Die Plattform unterstützt die Identifizierung und das Scannen von gehosteten KI-Modellen und ermöglicht es Unternehmen, bösartige Modelle zu erkennen, die bei LLM-Jacking-Angriffen verwendet werden könnten. Dies ist besonders wichtig für Unternehmen, die KI-Modelle selbst hosten, da es dazu beiträgt, die mit Open-Source-Modellen verbundenen Risiken in der Lieferkette zu bewältigen.
KI-Sicherheits-Dashboard: Wiz AI-SPM bietet ein KI-Sicherheits-Dashboard, das einen Überblick über die KI-Sicherheitslage mit einer priorisierten Warteschlange von Risiken bietet. Dies hilft KI-Entwicklern und Sicherheitsteams, sich schnell auf die kritischsten Probleme zu konzentrieren, einschließlich Schwachstellen, die zu LLM-Jacking führen könnten.
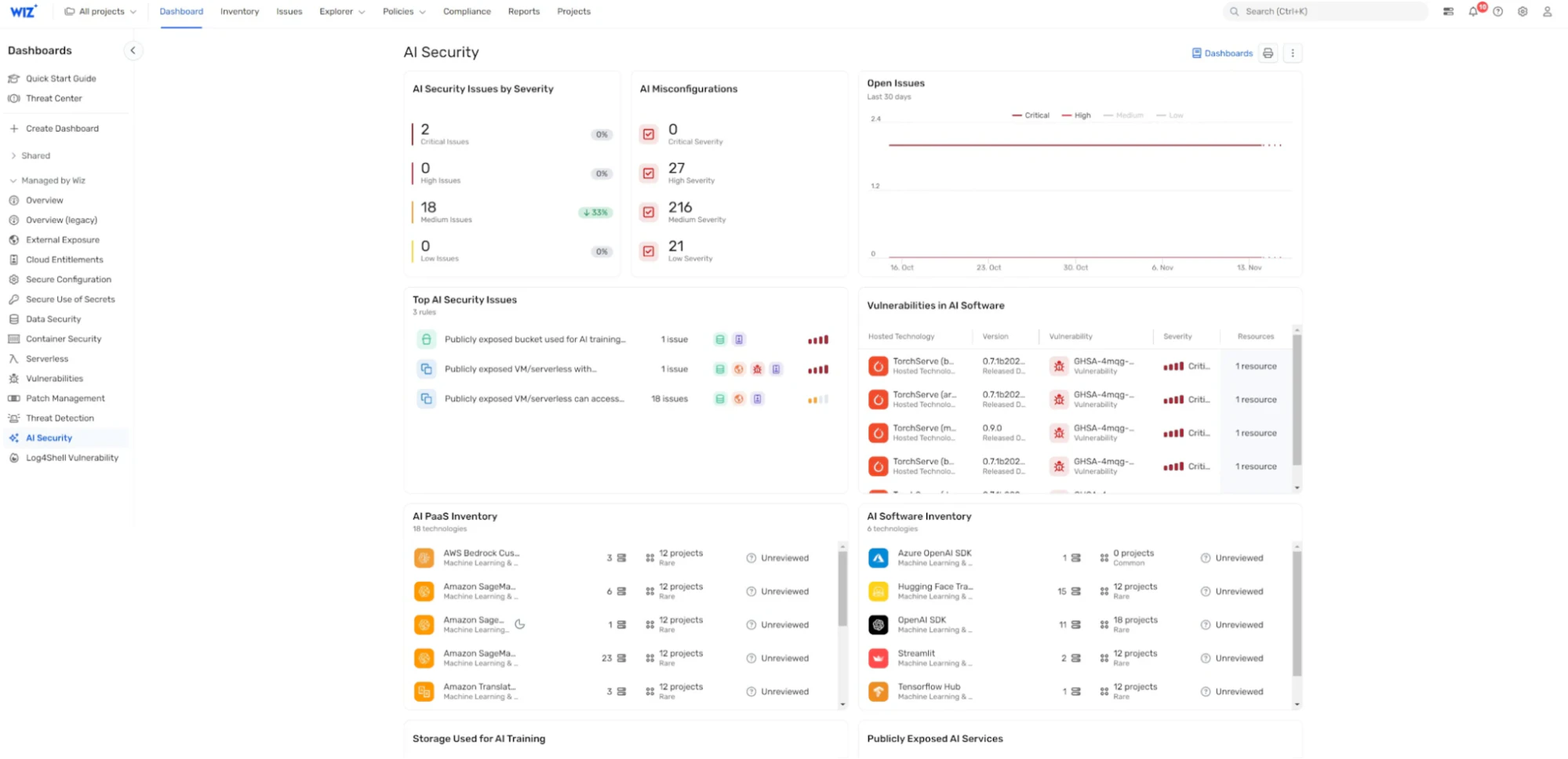
Durch die Implementierung dieser Funktionen hilft Wiz AI-SPM Unternehmen, eine starke Sicherheitslage für ihre KI-Systeme aufrechtzuerhalten, wodurch es für Angreifer schwieriger wird, LLM-Jacking-Angriffe und andere KI-bezogene Bedrohungen erfolgreich auszuführen.