



What is the incident response process?
The incident response process is a structured sequence of phases that security teams follow to detect, contain, and recover from security incidents. While multiple frameworks exist, including NIST, SANS, which details the six phases of the incident handling process. and ISO 27035, they share a common foundation: preparation, detection, containment, eradication, recovery, and post-incident review. This article breaks down each phase, compares how major frameworks approach them, and provides guidance on selecting the right approach for your organization.

What are the steps of incident response lifecycle?
1. Preparation
Preparation builds your organization's capacity to respond before an incident occurs, recognizing that preventive security controls cannot completely eliminate the possibility of critical data being compromised. This phase focuses on creating the policies, teams, tools, and communication channels that enable fast, coordinated action when threats emerge.
Policy and procedure development: Document incident response policies, plans, and procedures that outline roles, responsibilities, and actions to take during an incident.
Incident response team formation: Assemble a team with diverse skills, including network security, forensics, legal, and public relations. Define clear roles and responsibilities for each member.
Training and awareness: Conduct regular tabletop exercises and red team/blue team simulations to ensure team readiness. Raise awareness among all employees about their role in incident response.
Tools and resources: Equip the team with incident response tools such as forensic software, network monitoring tools, communication platforms, and documentation templates.
Communication plan: Develop a communication strategy for internal and external stakeholders to ensure accurate, timely information sharing during an incident.
The main challenges during preparation include ensuring all team members stay trained and familiar with their roles, and keeping the incident response plan up to date with evolving threats and organizational changes.
2. Detection and analysis
Detection and analysis is where your team identifies potential security incidents and determines their nature, scope, and impact. This phase transforms raw alerts into actionable intelligence that drives your response.
Monitoring and logging: Implement continuous monitoring and logging of network traffic, system activity, and user behavior to detect anomalies, suspicious activities, and behavioral cloud IOCs.
Incident identification: Use intrusion detection systems, SIEM platforms, and threat intelligence feeds to identify potential incidents, including emerging phishing campaigns.
Triage: Prioritize incidents based on severity, impact, and potential for escalation. Classify incidents and assign them to appropriate response teams.
Investigation: Conduct detailed analysis to determine the root cause, entry point, and scope of the incident. Examine logs, network traffic, and affected systems.
Documentation: Record all findings, decisions, and actions taken during the analysis phase for future reference and process improvement.
The biggest challenges here are differentiating between false positives and actual incidents, and gathering sufficient and accurate information for thorough analysis.
3. Containment
Containment stops the incident from spreading while you investigate and prepare for eradication. The goal is to limit damage without destroying evidence or disrupting business operations more than necessary.
Short-term containment: Implement immediate measures to limit impact, such as isolating affected systems, blocking malicious IP addresses, or disabling compromised accounts.
Long-term containment: Develop strategies to maintain containment while identifying and eradicating the root cause. This might involve setting up additional monitoring or deploying temporary patches.
The main challenge during containment is balancing speed with precision. Acting too quickly without analysis can cause data loss, while waiting too long allows the threat to spread.
4. Eradication
Eradication removes the root cause of the incident after containment has stopped its spread. While containment isolates the threat, eradication eliminates it entirely from your environment.
Root cause removal: Identify and remove the cause of the incident, such as malware, unauthorized access, or exploited vulnerabilities.
System hardening: Apply security patches, reconfigure systems, and strengthen security controls to prevent recurrence.
Verification is critical during eradication. Before moving to recovery, confirm that all affected systems are clean and free of any remnants of the incident.
5. Recovery
Recovery restores affected systems and services to normal operation after the threat has been eradicated. This phase requires careful validation to ensure the incident is truly resolved before returning to business as usual.
System restoration: Restore affected systems using backups or clean installs. Ensure that no traces of the incident remain.
Validation: Verify that systems are functioning correctly and securely. Conduct additional monitoring to confirm the threat has been fully eradicated.
Business continuity: Restore business operations with minimal disruption and bring all critical services back online.
The key challenges are ensuring that restored systems are fully secure and functional while minimizing downtime and disruption to business operations.
6. Post-incident activity
Post-incident activity closes the loop by reviewing what happened and feeding lessons back into your preparation phase. This is where incident response becomes a continuous improvement cycle rather than a one-time checklist.
Post-mortem analysis: Conduct a thorough review documenting what happened, how it was detected, how it was handled, and what the outcomes were.
Lessons learned: Identify insights from the incident and incorporate them into policies, procedures, and training programs. Update detection mechanisms and security controls based on findings.
Reporting: Prepare detailed reports for senior management, legal, and regulatory bodies. Ensure reports are clear, accurate, and actionable.
Policy and procedure updates: Revise incident response policies and procedures based on post-mortem findings.
Training and awareness: Use insights gained from the incident to improve training programs and increase security awareness across the organization.
The challenges here include ensuring that all relevant information is captured and analyzed, and effectively communicating lessons learned to all stakeholders so they are actually implemented.
Need a starting point for building or refining your incident response plan? Get started with our free Incident Response Template – practical, cloud-ready example to help you move faster.
IR steps by incident response framework
Several established frameworks guide incident response processes, each with slightly different terminology and emphasis. The core activities remain consistent across frameworks, but the way they're organized and prioritized varies based on the framework's origin and intended audience.
The most prominent frameworks include NIST Special Publication 800-61, which assists organizations in incorporating cybersecurity incident response recommendations, the SANS Institute Incident Handler's Handbook, ISO/IEC 27035, and the MITRE ATT&CK framework. The table below shows how each framework structures its phases.
| NIST | SANS | ISO/IEC | Mitre |
|---|---|---|---|
|
|
|
|
Key differences between frameworks
While these frameworks share common themes, their differences matter when selecting one for your organization:
Granularity: SANS and MITRE offer more granular steps, while NIST combines some phases such as containment, eradication, and recovery into a single stage.
Focus: NIST emphasizes detection and analysis, dedicating significant guidance to these areas. SANS and MITRE place more equal emphasis across all phases.
Continuous improvement: ISO/IEC 27035 and SANS explicitly include a "Lessons Learned" phase, emphasizing the cyclical nature of incident response.
Scope: ISO/IEC 27035 takes a broader approach, incorporating incident management into the overall information security management system.
Flexibility: MITRE's framework is designed to be more adaptable to various incident types and organizational structures.
Choosing the right incident response process
Selecting an incident response lifecycle depends on your organization's context, but remember that consistent execution matters more than which framework you choose. Consider these factors when making your decision:
Regulatory requirements: Some industries require adherence to specific frameworks. Government agencies often prefer NIST due to its alignment with federal guidelines.
Organizational size and structure: Larger organizations might benefit from the more detailed SANS or MITRE frameworks, while smaller teams might prefer NIST's concise approach.
Incident types: If your organization faces a wide variety of incidents, MITRE's flexible framework might be more suitable, offering a globally accessible knowledge base of adversary tactics based on real-world observations.
Integration with existing processes: Consider how well each framework aligns with your current security operations and information security management system.
Team expertise: More experienced teams might prefer MITRE's flexibility, while teams new to formal IR processes might benefit from NIST's structured approach.
Continuous improvement focus: If your organization prioritizes ongoing refinement, frameworks with explicit "Lessons Learned" phases like SANS or ISO/IEC 27035 might be preferable.
How Wiz supports incident response in the cloud
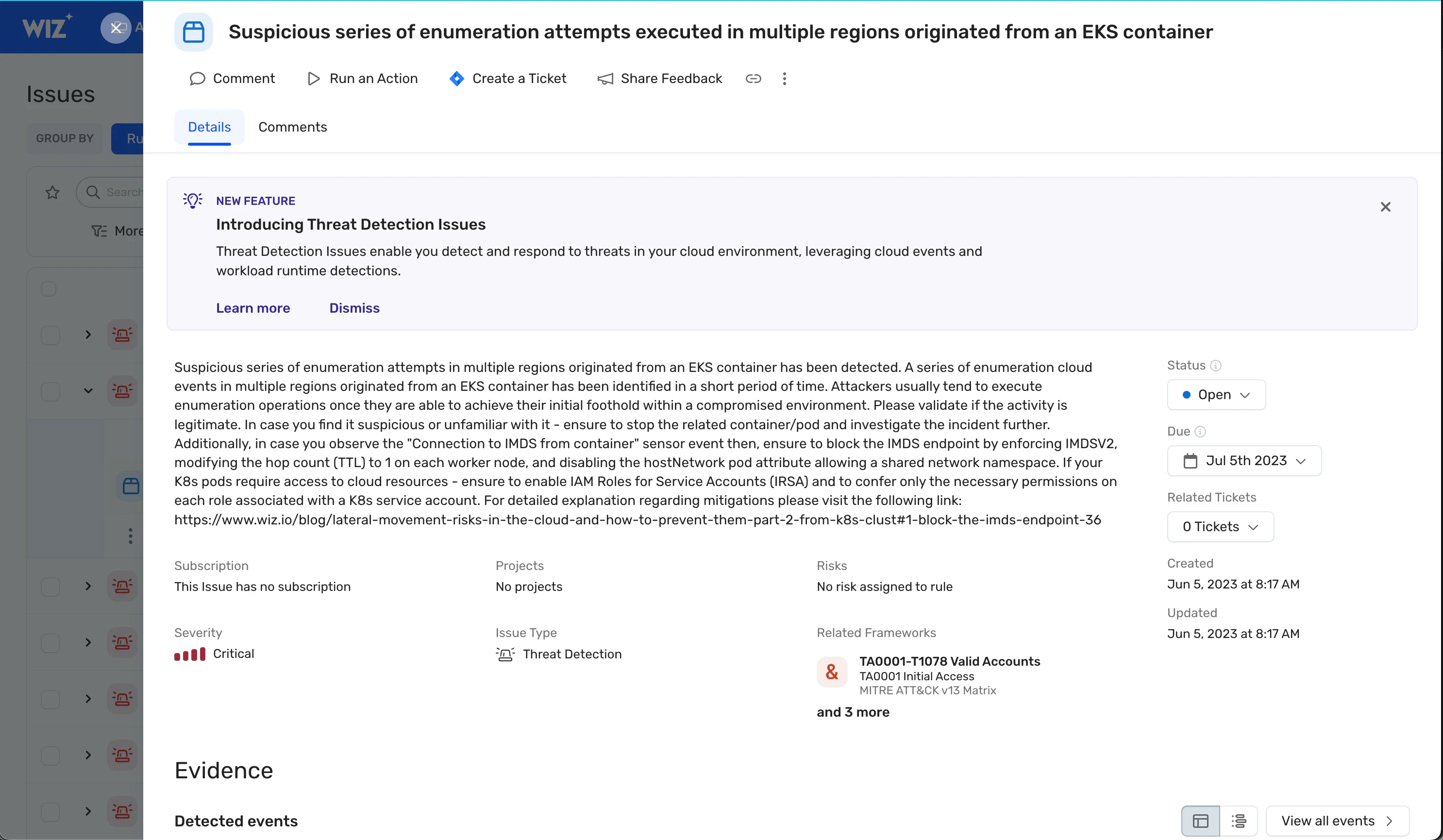
Cloud environments introduce unique IR challenges that traditional frameworks don't fully address, particularly regarding governance, shared responsibility, and visibility. Workloads are ephemeral, evidence can disappear within minutes, and investigations span multiple cloud accounts and services. Wiz Defend is built for this reality, providing features that streamline incident response in cloud environments:
Cloud Detection and Response (CDR): This is the foundation for Wiz's incident response capabilities, providing real-time threat detection, investigation, and response actions.
Security Graph: A visual representation of cloud infrastructure, helping identify relationships between resources and potential attack paths.
Automated Response Playbooks: Pre-built and customizable playbooks for automating routine incident response tasks.
Root Cause Analysis: Identifies the underlying cause of an incident to facilitate effective remediation.
Blast Radius Assessment: Evaluates the potential impact of a security breach to prioritize response actions.
Cloud-Native Incident Response
Learn why security operations team rely on Wiz to help them proactively detect and respond to unfolding cloud threats.
