






In the previous post in this series, we explored how organizations can gain visibility into modern AI applications — identifying where AI systems exist and how those systems are assembled across code, cloud services, and runtime environments.
But once those systems are discovered, security teams face a new set of questions:
What risk does this AI application introduce?
What data or systems can it access?
What actions could it take if misused or manipulated?
Understanding where AI exists is only the first step. The next challenge is determining where real risk lies within those systems.
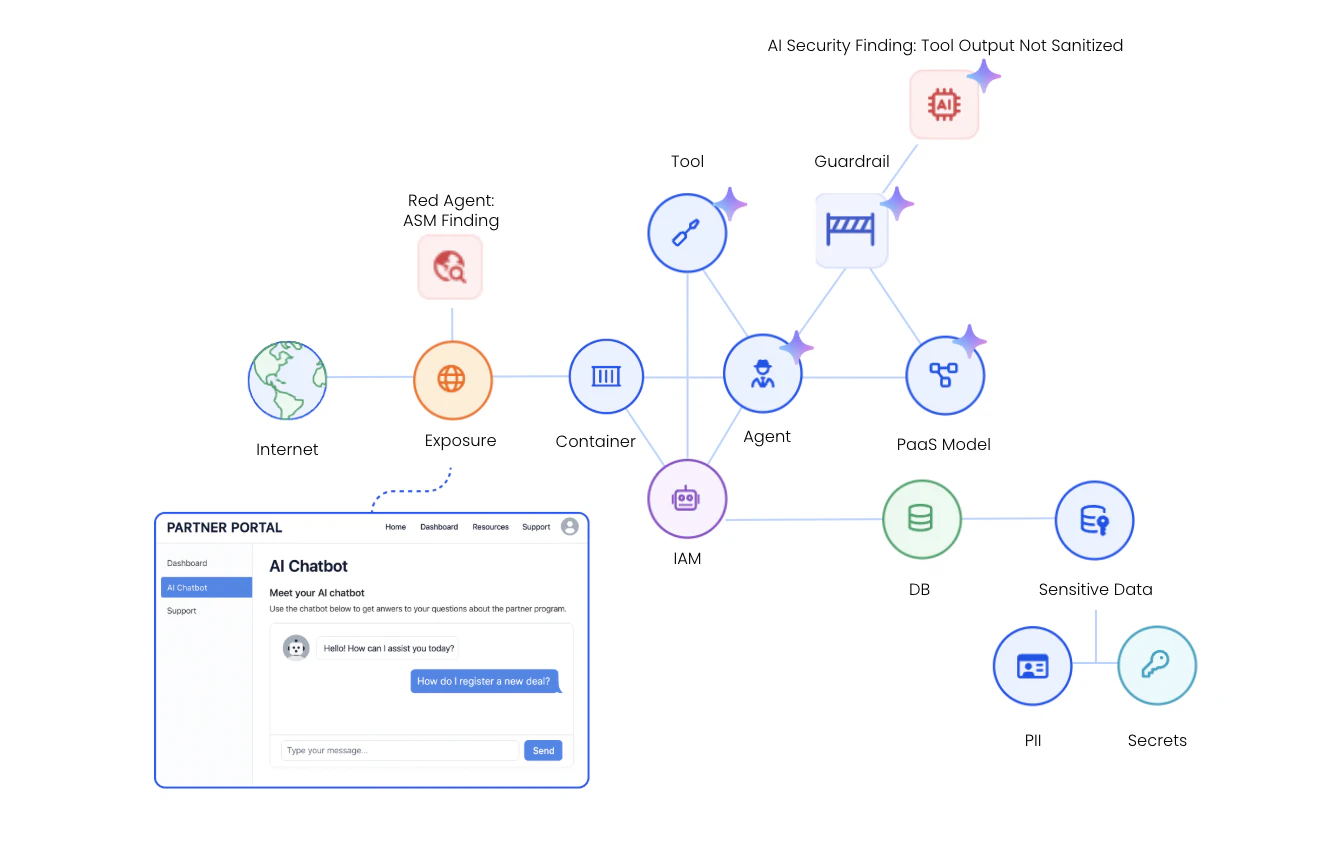
Consider a simple example: an externally accessible AI chatbot designed to answer customer questions.
At first glance, the application appears harmless. But underneath, multiple components are interacting:
The AI agent runs on a workload with permissions to sensitive customer data
The agent can use connected tools to access or update internal datasets
The user-facing chat interface exposes the system to prompt injection attempts
None of these elements alone necessarily represents a breach.
But when these components connect and interact, they can create real exploitable attack paths across the environment.
Real AI risk doesn’t come from a single weakness — it emerges from how AI systems behave across their components.
Understanding AI Risk Across Layers
Siloed security approaches can’t capture the interconnected risks created by modern AI systems.
Infrastructure scanners identify cloud resources but cannot see how models, agents, and tools behave together. Code analysis reveals developer intent but not how systems operate once deployed. Runtime monitoring captures activity after the fact but lacks the architectural context needed to understand how risk emerges.
Each signal provides useful insight, but none can fully uncover the potential risk of an AI application .
AI applications operate across four interconnected layers:
Infrastructure & Access — AI workloads and their identities
Model & Guardrails — the models powering inference and the guardrails governing and monitoring their input and output.
Data — training data, knowledge bases, and customer data
Application — agents, tools, APIs, and integrations that allow AI systems to take action
These layers form the architecture of most modern AI applications.
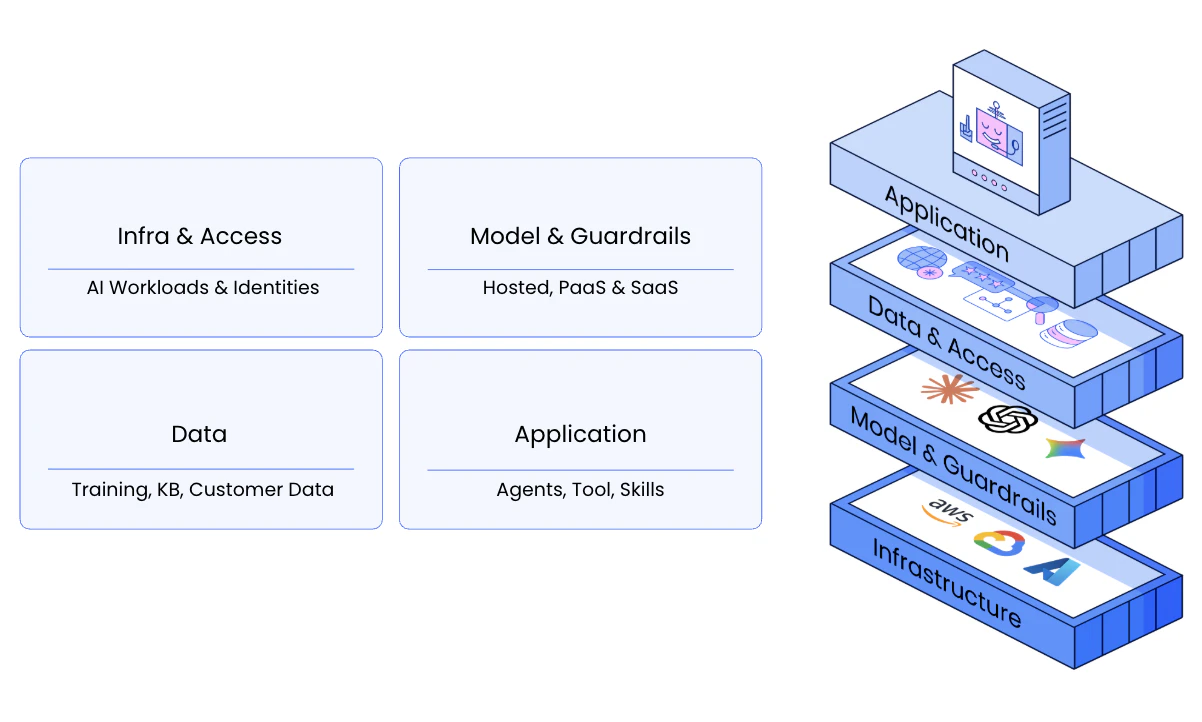
Risk rarely appears within a single layer. Instead, it emerges when components across layers interact.
Returning to the chatbot example, breaking down the signals across layers reveals where the risk actually comes from:
Infra & Access — the AI agent is exposed through a public endpoint with an authentication bypass.
Model & Guardrails — the agent runs on an AI Model hosted in a PaaS with misconfigured guardrails
Data — the model and agent can reach internal datasets containing sensitive information.
Application — the agent has tools that allow it to read and expose the sensitive data.
Individually, these signals may appear benign. But together they form a toxic combination — making this a high-risk AI agent within your cloud environment with a considerable blast radius.
Understanding AI risk therefore requires a deep understanding of how signals interact across the layers of the application.
However, legacy security tools are not equipped to provide the level of protection required to safely deploy AI applications within the enterprise. An increasing number of agents are now defined directly in code and embedded within workloads. Traditional code analysis methods cannot accurately reconstruct the architecture of modern AI applications — including their toolchains, MCP servers, capability boundaries, model integrations, and the guardrails designed to constrain them.
To address this gap, Wiz has developed proprietary detection and classification capabilities that identify and analyze AI applications irrespective of architecture or cloud platform. This enables comprehensive visibility into how AI systems are constructed, connected, and governed across the environment.
Wiz brings these capabilities together by analyzing AI systems across layers while continuously expanding detection for AI-native risks and components, allowing security teams to identify real AI risk rather than isolated findings.
Detecting AI Risk Signals
Understanding AI risk across layers provides the necessary context. But identifying real risk also requires analyzing the signals that reveal how AI systems are implemented, configured, and exposed.
AI applications introduce entirely new security signals — from model configurations and tool capabilities to exposed endpoints and agent permissions. Each signal reveals part of the system’s behavior.
To uncover real AI risk, security teams must analyze these signals across the full lifecycle of an AI application — from how systems are implemented in code, to how they are deployed in the cloud, and how users or attackers interact with them.
The following sections highlight the key signals that reveal AI-native risk in modern environments.
Development Risks
AI risk often begins during development, when models, tools, APIs, and data sources are integrated into applications and agents.
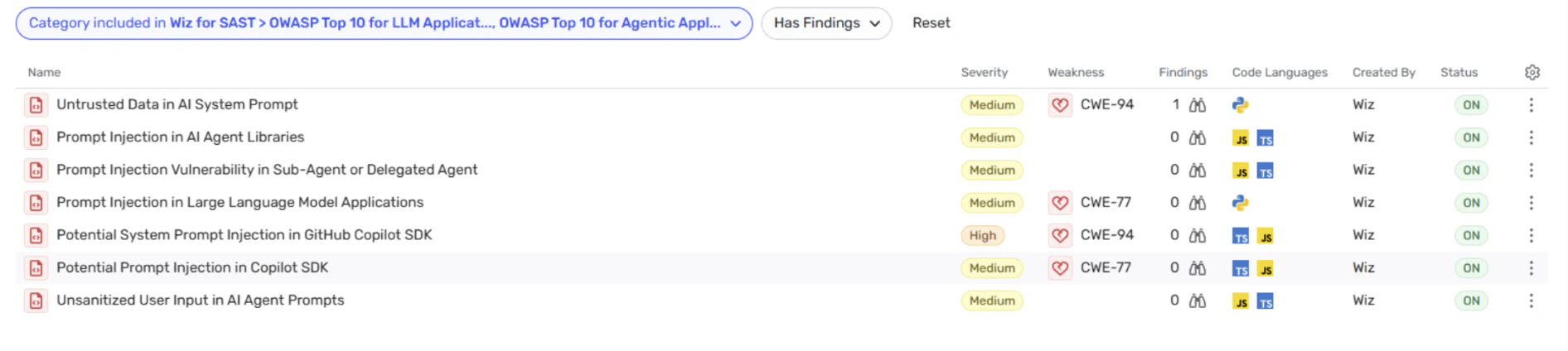
Many AI systems are defined directly in application code, where developers integrate models, tools, APIs, and data sources into agents and workflows. Small mistakes in these integrations can introduce security weaknesses long before the system is deployed.
Code analysis is uniquely valuable because it reveals how AI systems are constructed — including which models they call, which tools they can invoke, what permissions they operate with, and what data sources they can access. Once compiled applications are deployed into cloud workloads, much of this architectural context becomes significantly harder to reconstruct.
Wiz analyzes AI logic and integrations in code to detect unsafe patterns such as insecure tool usage, embedded credentials, and risky combinations across application logic and infrastructure access. Detecting these issues early helps prevent vulnerable AI systems from reaching production.
AI Resources & Security Misconfigurations
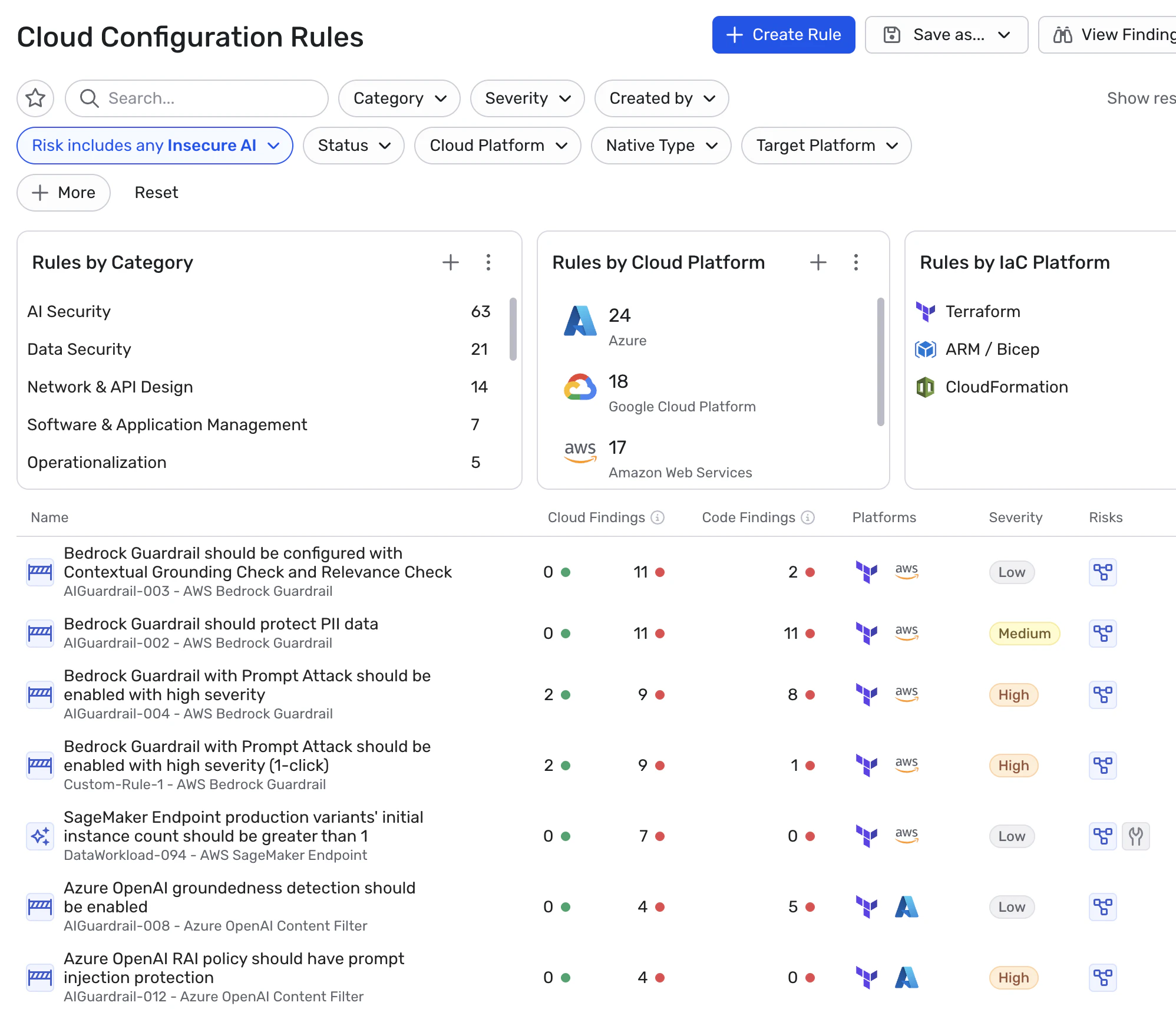
Once deployed, AI systems introduce new risks through how AI resources are deployed and configured across workloads and hosted AI platforms.
Using the Disk Analyzer and Workload Explainer, Wiz identifies hosted AI resources such as agents, models, and MCP servers running within workloads and AI services. It then scans the underlying files and system artifacts to detect malicious payloads and other hidden risks within the environment.
In addition to discovering these resources, Wiz analyzes how they are configured. Model deployments and AI platforms may introduce risks such as missing guardrails, unsafe settings, or insecure integrations that affect how models behave and what resources they can access.
Wiz detects these issues through both AI-specific security rules and cloud configuration analysis, enabling teams to identify misconfigurations regardless of whether AI systems are defined in code, deployed in workloads, or hosted through AI platforms.
This approach helps security teams detect risky configurations across AI infrastructure and ensure models, agents, and supporting services operate with the correct protections in place.
AI Capabilities, Data Access, and Exposure
Even properly deployed AI systems can introduce risk depending on what they are capable of doing, what data they can reach, and how users or attackers can interact with them.
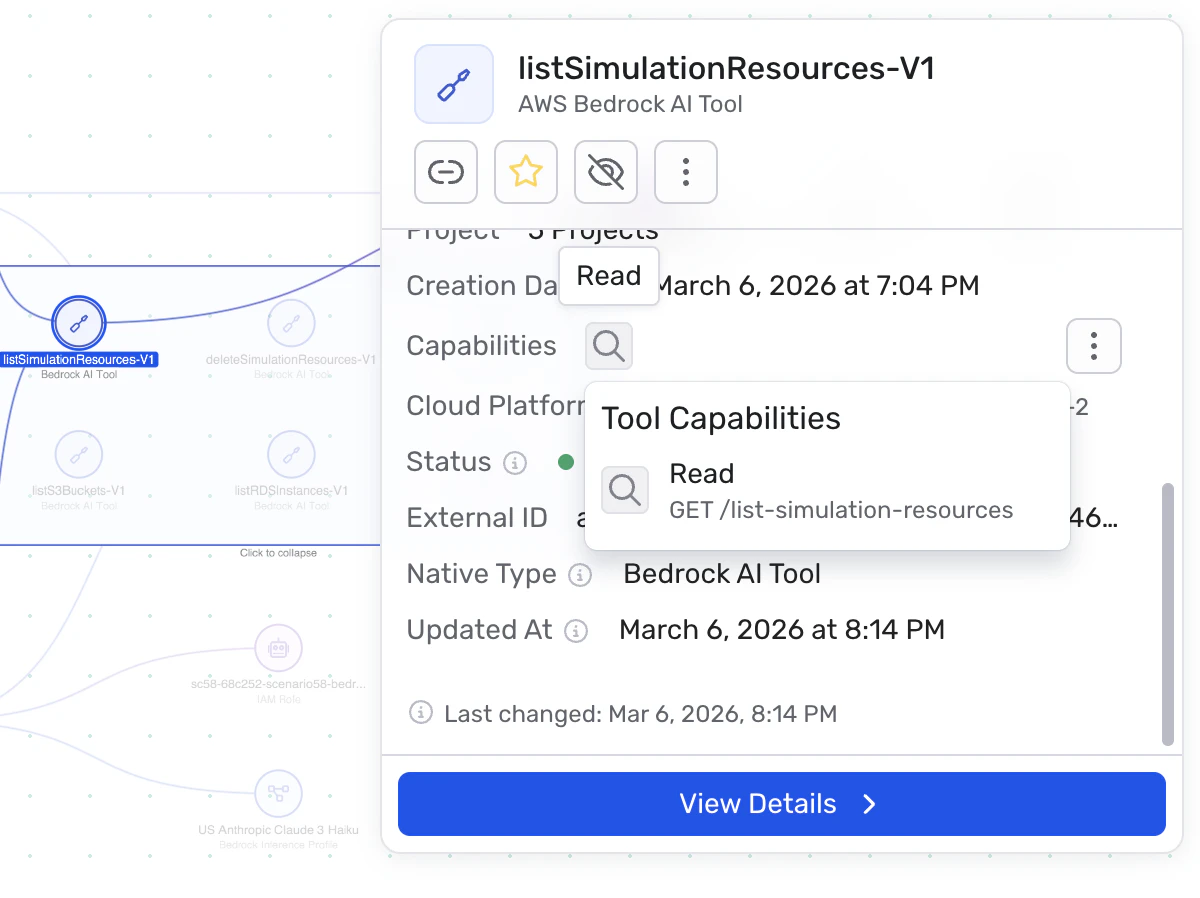
Tool & Capability Identification
AI agents derive their power from the tools they can access.
These tools may allow an agent to retrieve data, interact with APIs, trigger workflows, or modify infrastructure resources. The capabilities granted to these tools ultimately determine what the AI system can do inside the environment.
Wiz identifies the tools connected to agents and models and classifies their capabilities — such as whether a tool can read data, write or modify systems, expose sensitive data, or execute code. This allows security teams to clearly understand what an AI system can access or change and detect overly permissive or risky integrations before they can be abused.
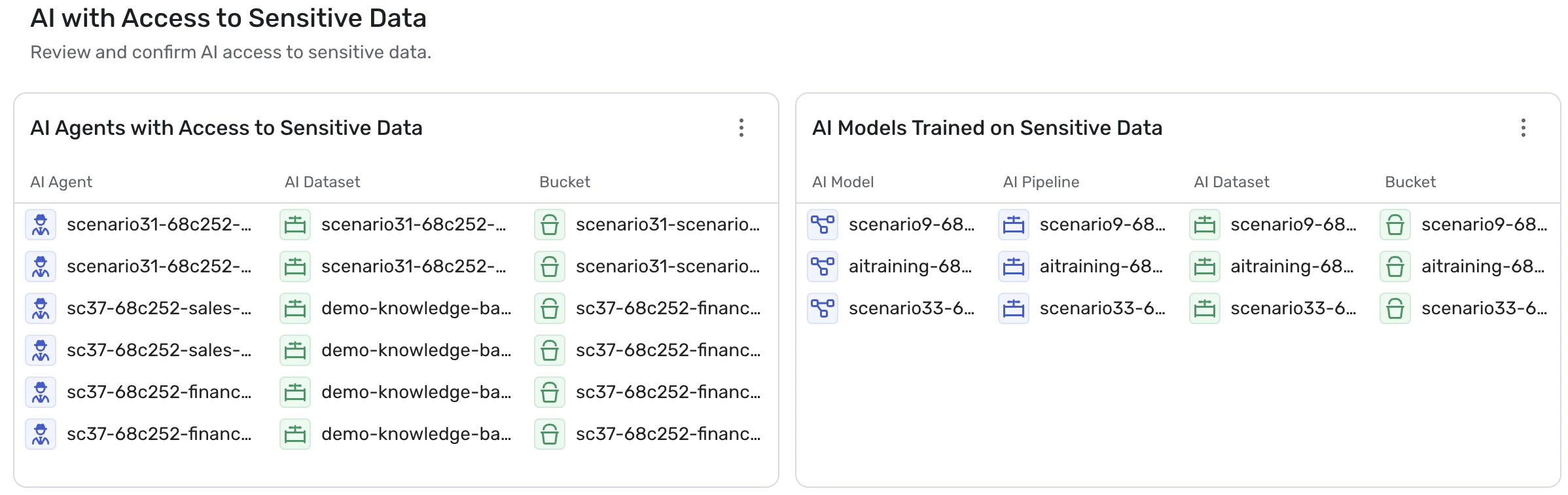
Data Exposure & Sensitive Access
AI systems often act as bridges between models and sensitive enterprise data.
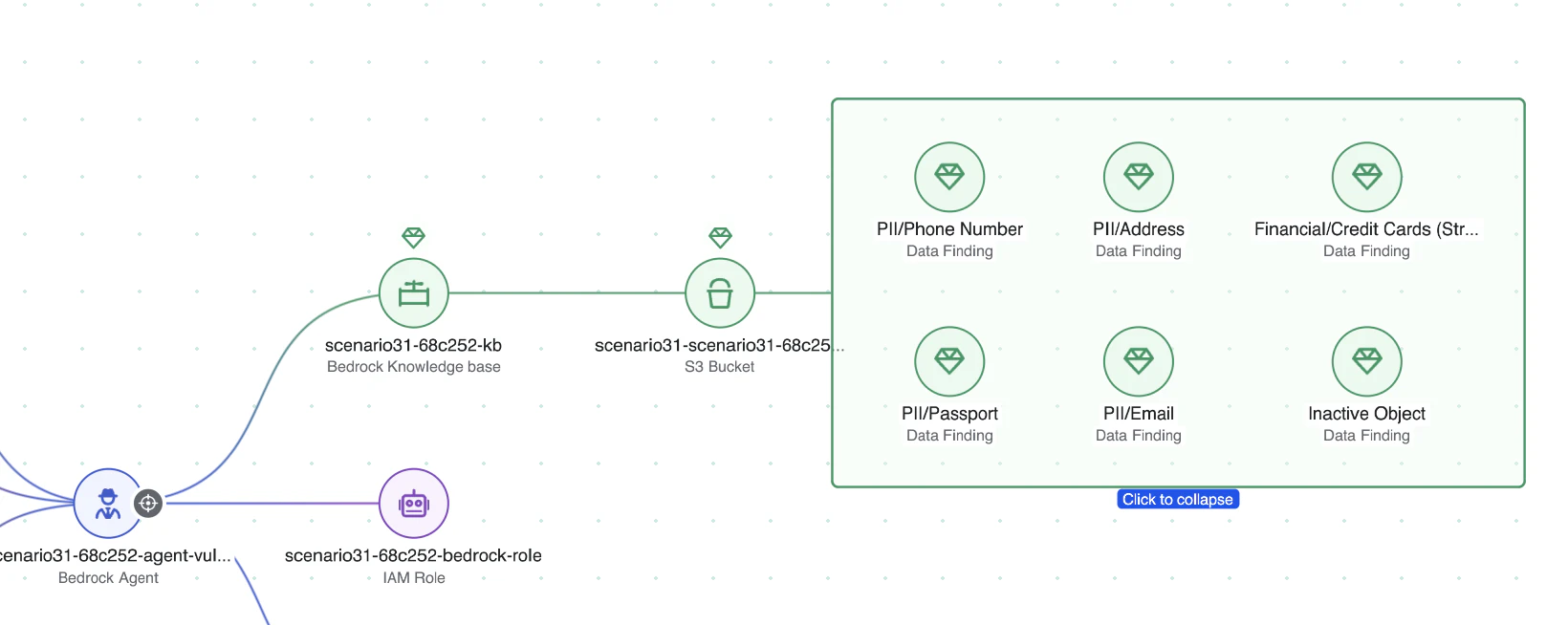
Agents may query internal knowledge bases, retrieve files from storage systems, or access customer datasets to answer prompts or perform tasks. Without proper controls, these interactions can expose confidential information or allow AI systems to retrieve data that should remain restricted.
Wiz integrates its DSPM platform and data classification capabilities into AI security analysis, enabling teams to understand when models or agents can access sensitive data.
Powered by a robust classification engine — including novel classifiers designed to detect a wide range of sensitive data types — Wiz continuously identifies where sensitive information resides across cloud environments.
By combining this data context with AI system analysis, Wiz can detect when models or agents may expose, retrieve, or mishandle confidential information, helping organizations enforce governance policies and maintain safe data boundaries.
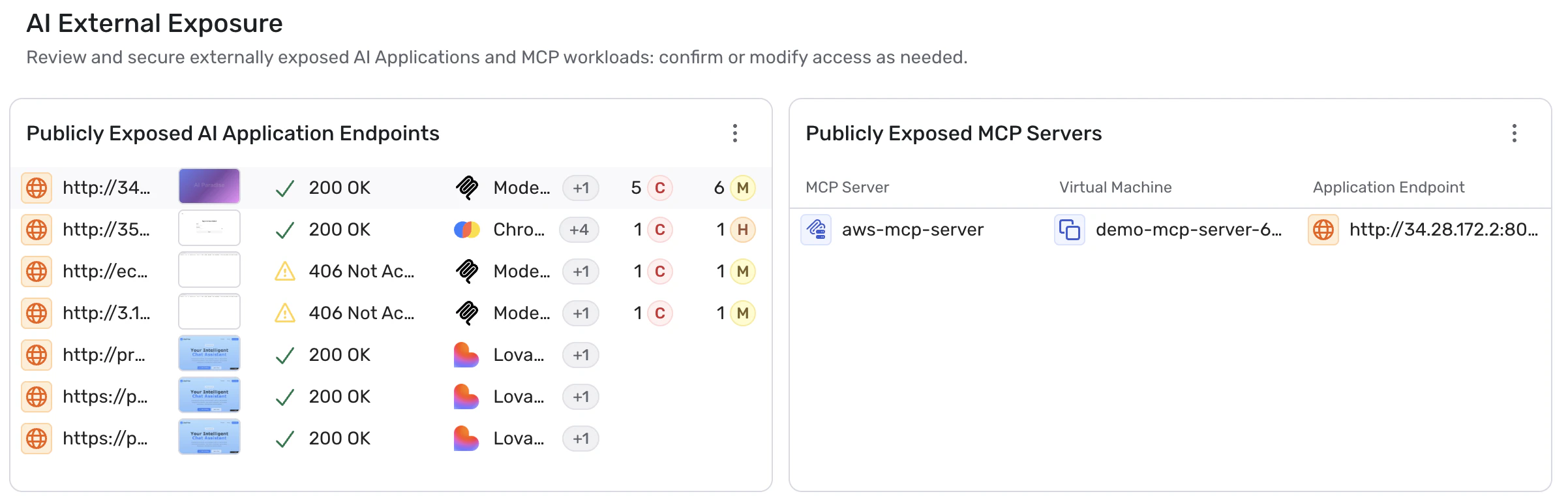
Exposed AI Endpoints
AI applications often expose APIs, agents, or chat interfaces that allow users to interact directly with the system.
These interfaces frequently become the primary entry point through which attackers interact with AI systems.
Wiz identifies publicly reachable AI endpoints and insecure exposure paths that could allow attackers to directly access AI services.
To assess the real risk of these exposures, Wiz actively probes exposed AI endpoints and simulates how an external attacker might interact with them. This analysis helps detect prompt injection risks, insecure behaviors, and other weaknesses that may only appear when systems are accessed through real-world inputs.
This visibility allows organizations to secure AI entry points before they become exploitation paths.
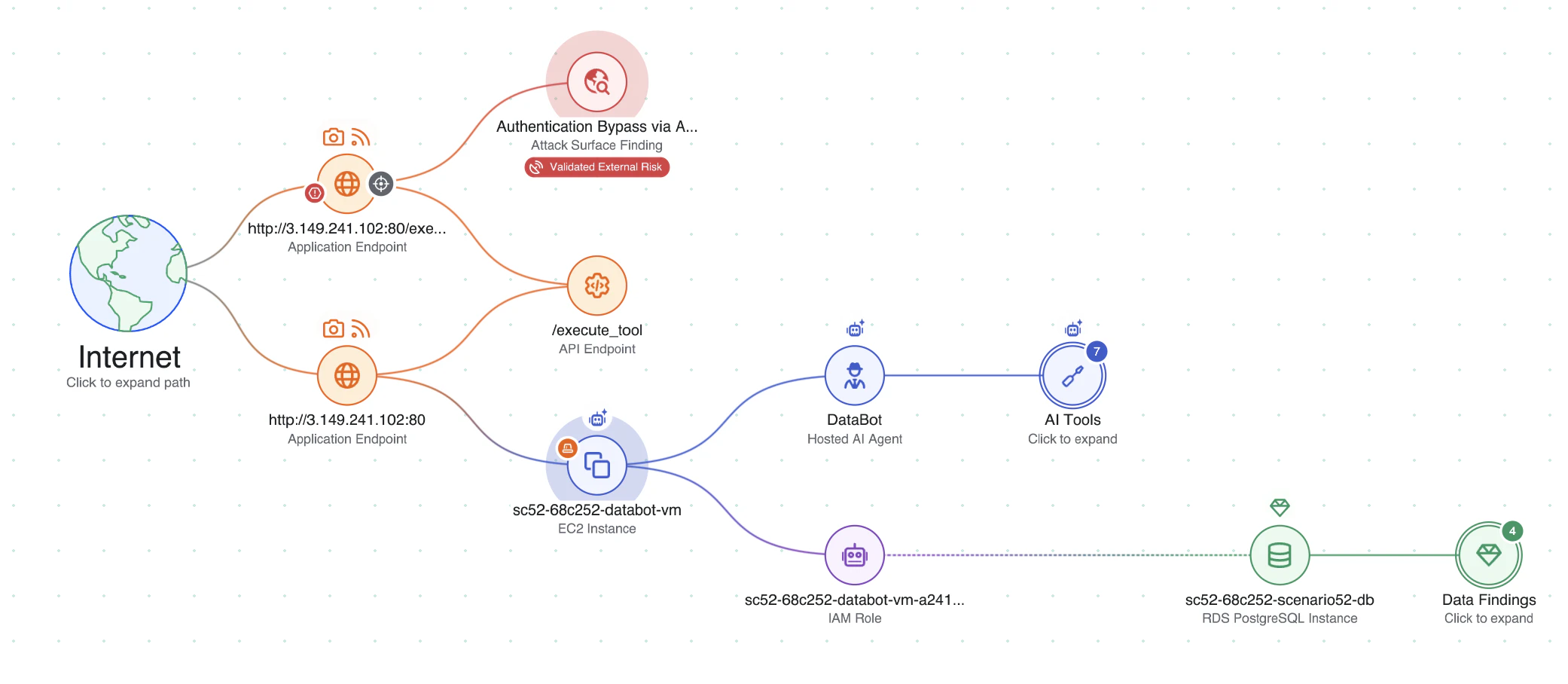
Connecting AI Signals to Real Risk
Individually, these signals provide useful insight. But real AI risk only becomes clear when they are evaluated together within the architecture of the AI application.
A model misconfiguration may exist, but the model may not have access to sensitive data. An agent may have powerful tools, but those tools may still be constrained by the permissions granted to the agent. A publicly exposed endpoint may exist, but the system behind it may not reach sensitive resources.
Understanding what truly matters requires analyzing these signals in context.
Returning to the chatbot example introduced earlier, the risk does not come from any single weakness. Instead, it emerges from the combination of signals: a publicly accessible interface, an AI agent with tool capabilities, and access to sensitive data sources.
When evaluated together, these signals reveal a clear attack path — where an external attacker could interact with the chatbot, manipulate prompts, and cause the agent to retrieve sensitive information through its connected tools.
Wiz’s Security Graph reconstructs these relationships by connecting code, cloud infrastructure, identities, data access, and runtime activity — revealing the full attack path across the environment.
Prioritizing and Hardening AI Risk
Once real AI attack paths are identified, the next step is reducing exposure across the system.
Wiz helps teams operationalize these insights by prioritizing risks based on the potential impact of the attack path and providing clear remediation guidance across AI applications, infrastructure, and code.
Security teams can quickly identify how to address issues such as tightening agent permissions, securing exposed AI endpoints, enforcing model guardrails, or limiting access to sensitive data sources.
For risks introduced in application logic, Wiz also helps teams trace issues back to the underlying implementation and fix them directly in code.
By combining deep visibility, AI-native detections, and contextual analysis across layers, Wiz enables organizations to move from isolated AI findings to prioritized, actionable AI risk — allowing teams to adopt AI safely while maintaining strong security controls.
What Comes Next
In this post, we explored how organizations can move beyond visibility to understand real AI risk — combining AI-native detections with context across infrastructure, models, identities, data, and application logic.
AI security doesn’t stop at understanding risk. As these systems interact with users and external inputs, organizations must also monitor for active threats and misuse at runtime.
In the next post in this series, we’ll explore how security teams detect and respond to AI threats as they occur — including prompt manipulation, agent misuse, and other emerging attack techniques.

















