



What are AI security risks?
AI security risks are threats specific to AI systems, pipelines, models, and training data that traditional security tools were not designed to address. Unlike conventional software vulnerabilities, AI risks stem from non-deterministic behavior, training data dependencies, and emerging attack vectors such as prompt injection, model poisoning, and adversarial manipulation.
Why AI security risks matter for businesses

As organizations adopt AI agents and GenAI applications, the attack surface expands across prompts, APIs, datasets, plugins, and connected systems. According to Wiz's 2026 State of AI in the Cloud report, 81% of organizations now use managed AI services, 90% run self-hosted models, and 68% of those that do ingest data through third-party software. This means many security teams are inheriting AI risk they didn't deploy or sanction.
A single misconfigured AI service or compromised third-party model can expose sensitive data, trigger regulatory violations, or open lateral attack paths into the broader cloud environment, often without ever appearing on a sanctioned asset inventory.
The 4-Step Framework for AI Threat Readiness
Wiz has designed a 4-step framework to help organizations defend against rapid, automated exploitation in a post-Mythos world.

The top 7 AI security risks and how to mitigate them
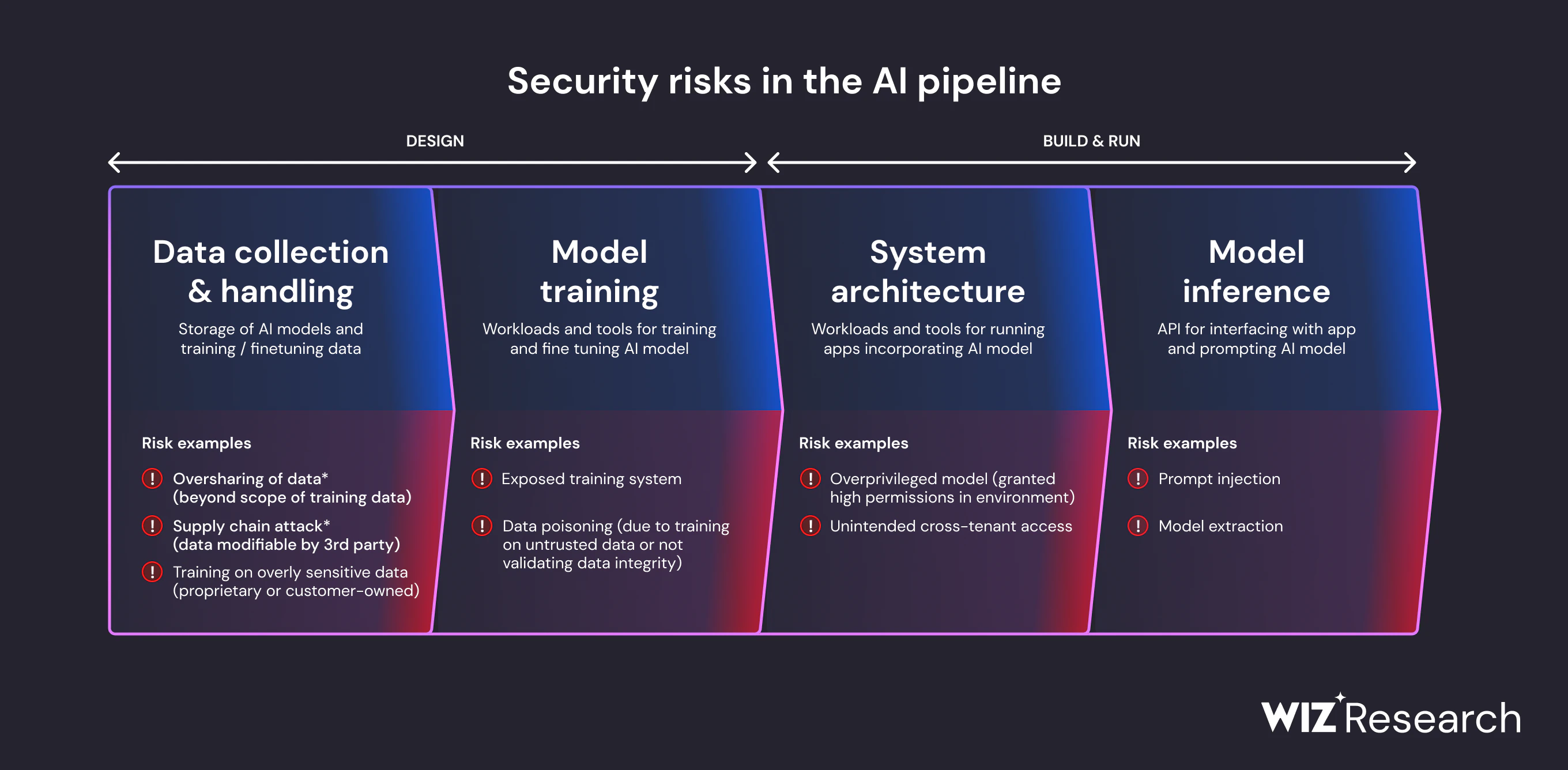
The AI development pipeline introduces different risks across every stage, from training data ingestion to runtime inference and agent activity. The diagram below highlights where these exposures emerge and how different attack paths can affect AI systems in production.
1. Data breaches
Sensitive data exposure through AI systems can trigger regulatory violations, customer harm, and significant business disruption.
Real-life attack scenario:
Attackers can exploit membership inference vulnerabilities to determine whether specific customer records were included in a training dataset. They may also craft targeted queries to extract sensitive information from model outputs, such as email addresses or phone numbers memorized during training through attribute inference attacks.
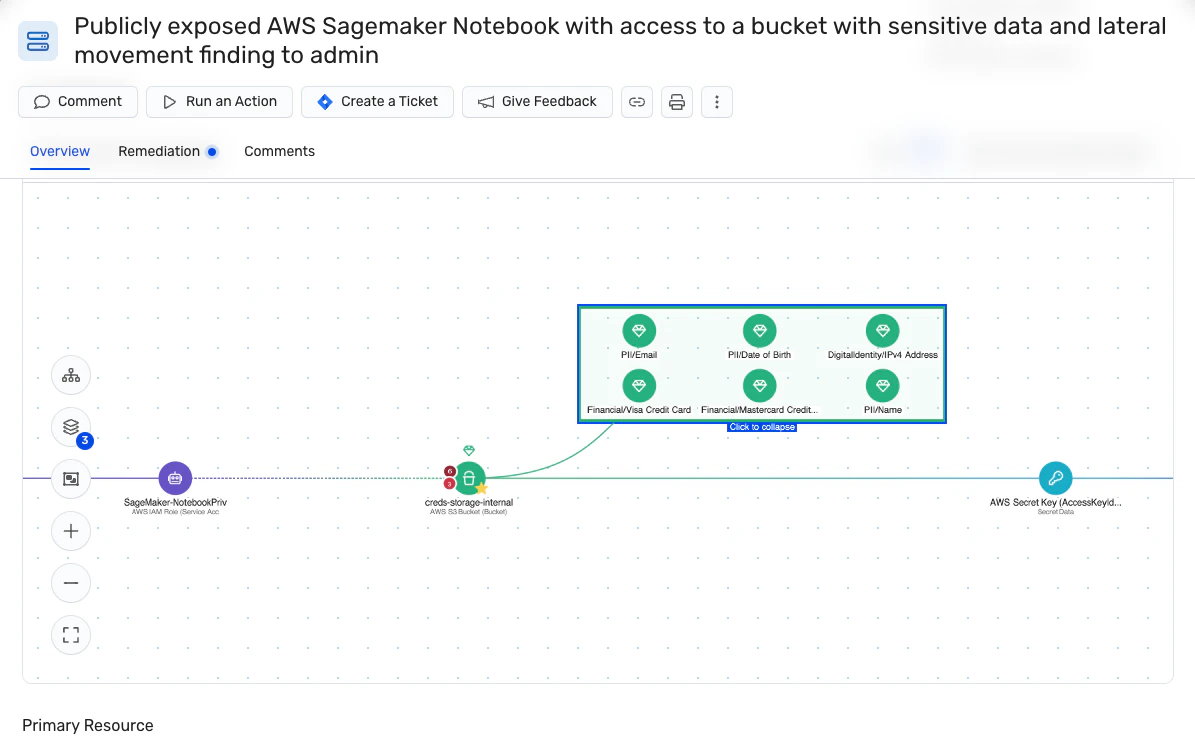
GenAI applications built on LLMs face heightened risk because training datasets often contain PII scraped from public sources without consent. When models memorize and reproduce this data, organizations can still face legal and regulatory exposure even if they did not intentionally collect the data.
Mitigation:
Implement robust encryption for data at rest and in transit.
Use differential privacy techniques during model development.
Regularly audit and monitor access to sensitive data following the principle of least privilege.
Adhere to data protection regulations like GDPR.
Align AI governance practices with frameworks like NIST AI RMF and the EU AI Act to strengthen transparency, accountability, and AI risk management.
2. Adversarial attacks
Adversarial attacks compromise AI model integrity, resulting in incorrect or manipulated outputs that undermine system reliability and security posture.
Real-life attack scenario:
Attackers can exploit a model’s sensitivity to input changes through gradient-based attacks or manipulate inputs to reduce model resistance and evade detection.
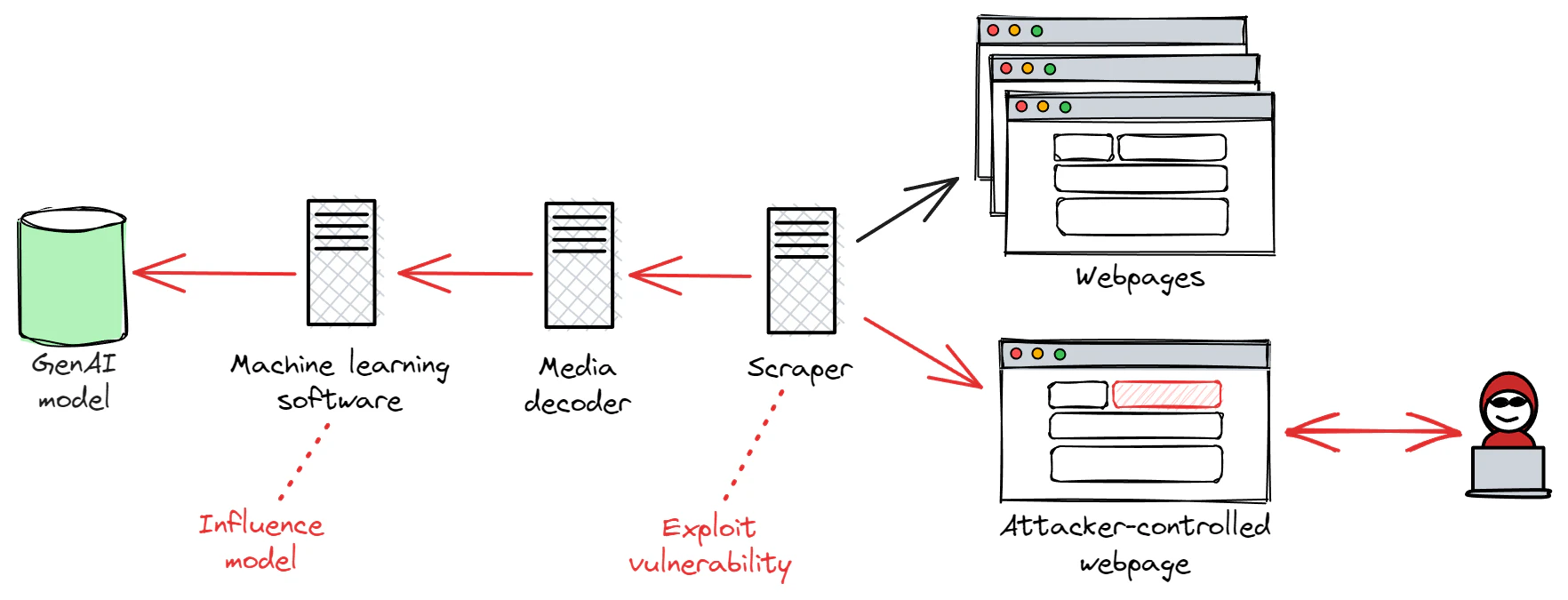
Indirect prompt injection attacks also create serious risks for LLMs. By embedding malicious prompts inside requested content, attackers can manipulate an AI system into exposing sensitive data, executing harmful actions, or redirecting users to malicious destinations. Researchers demonstrated this risk in 2024 when prompt injection attacks against Slack AI exposed sensitive information from private channels.
Mitigation:
Regularly update model parameters to strengthen resistance against attacks.
Employ ensemble methods that combine predictions from multiple models.
Conduct ethical hacking and penetration testing to identify vulnerabilities proactively.
Establish continuous monitoring to detect unusual patterns or deviations in model behavior.
Incorporate adversarial training techniques during model development.
Validate and sanitize model inputs before processing prompts or external content.
3. Shadow AI
Shadow AI refers to unauthorized or unmonitored AI tools used without security team approval. These systems create unmanaged exposure outside normal security and governance controls. According to a 2025 Gartner survey, 69% of organizations suspect employees are using unauthorized public GenAI tools.
Real-life attack scenario:
When employees paste proprietary code or internal documents into ChatGPT without adjusting privacy settings, that data may be retained or used for model training. Employees may also adopt AI tools that lack basic security controls, introducing risks that bypass governance entirely.
This is why maintaining a complete AI asset inventory is critical for AI governance.
Mitigation:
Create standardized processes for AI support and AI risk management.
Establish protocols for detecting and responding to unauthorized AI deployments.
Conduct training programs to ensure employees understand safe and approved AI usage practices.
Continuously monitor for unsanctioned AI tools and integrations across the environment.
4. Partial control over outputs
Even with extensive testing, AI models can return outputs that are biased, unfair, or factually wrong. Developers have only partial control over what models produce, and users can influence responses through irregular prompts.
AI hallucinations create a distinct security risk when models confidently generate false information. In software development, hallucinated package names have led to dependency confusion attacks where developers install malicious packages that don't actually exist in legitimate repositories.
Real-life attack scenario:
An attacker could aim to create hyper-realistic fake content using your AI model to spread misinformation (deepfakes), or a malicious actor may try to inject bias into your model via input manipulation (content-bias injection).
Mitigation:
Conduct bias audits on training data and model outputs using tools like Fairness Indicators.
Advocate for implementing bias-correction techniques, such as reweighting or resampling, during model training.
Define and implement ethical internal guidelines for data collection and model development.
Promote transparency by sharing ethical guidelines for AI usage with users.
Attackers also leverage LLMs to scale their operations, a trend highlighted by "AI" and "GPT" appearing in over 800,000 dark web posts in a single year, according to a 2024 IBM report. AI-generated phishing lures are more convincing, polymorphic malware evades detection longer, and autonomous attack chains require less human oversight. The most concerning development: attackers using AI to discover entirely new vulnerability classes.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

5. Supply chain risks
AI systems rely heavily on open-source datasets, models, libraries, and pipeline tooling that may lack strong security controls. When attackers compromise these dependencies, the impact can extend across the broader production environment.
Real-life attack scenario:
Attackers may attempt model subversion by tampering with model behavior or introducing adversarial data through tainted dataset injection attacks. Open-source model ecosystems can also introduce supply chain risk when organizations deploy unverified models or dependencies from public repositories.
This risk has grown alongside open-source AI ecosystems like Hugging Face, where organizations may deploy models without fully validating their provenance or security posture.
Mitigation:
Vet and validate AI datasets, models, and third-party integrations before deployment.
Implement secure communication channels and encryption for data exchange across the supply chain.
Establish contractual security requirements and validation standards for vendors and suppliers.
Continuously monitor AI dependencies for suspicious behavior or unauthorized changes.
6. Lack of explainability
AI models can behave in ways that are difficult to interpret or justify. When teams cannot clearly understand model behavior, testing, governance, and incident response become significantly harder.
Real-life attack scenario:
Attackers may attempt model inversion attacks to reverse-engineer sensitive training data or manipulate inputs directly to influence outputs and compromise system integrity.
Mitigation:
Use interpretable models and explainability techniques during development where possible.
Implement post hoc explainability methods to analyze model decisions after deployment.
Maintain clear documentation and governance standards for AI development and deployment processes.
7. Limited testing
AI models can behave unpredictably in production environments, creating security gaps that traditional testing approaches may miss. According to Wiz's 2026 State of AI in the Cloud report, 80% of organizations now have developers using AI IDE extensions, and roughly 1 in 5 of those using AI-powered "vibe coding" platforms have been found to have systemic security weaknesses rooted in shared generation patterns.
Testing AI is uniquely difficult. For example, non-deterministic models can pass identical test cases on Tuesday and fail them on Wednesday, meaning traditional pass/fail frameworks miss the behavioral drift that matters most. AI is shipping code faster than testing frameworks can keep up.
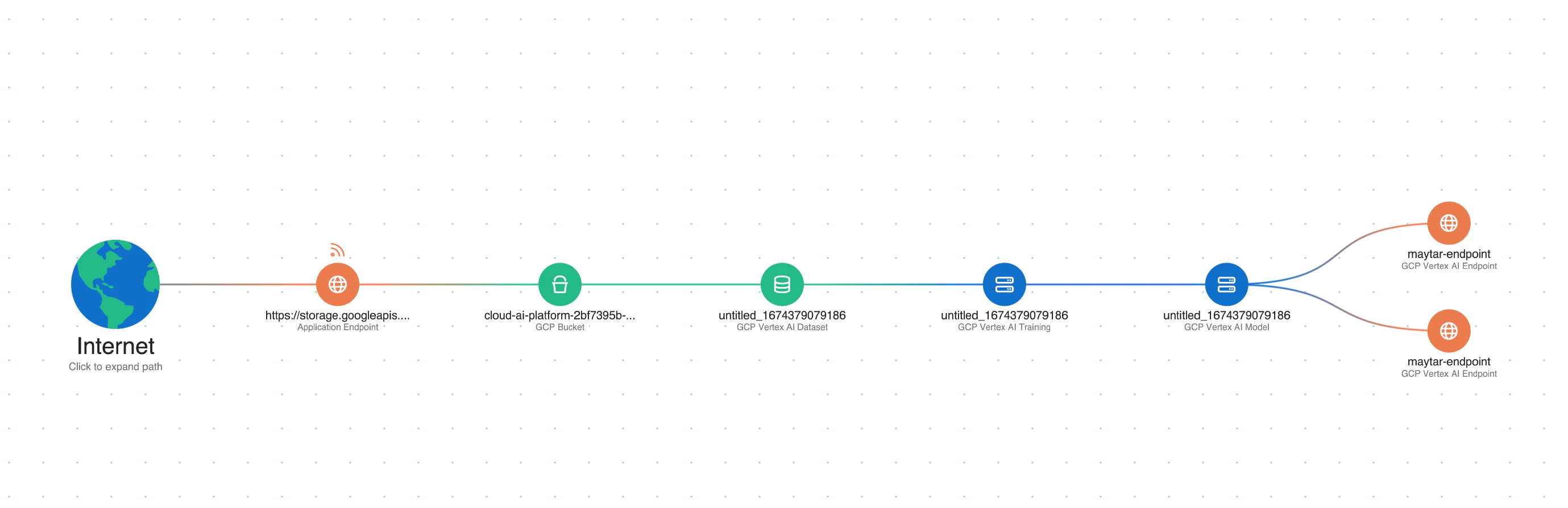
Real-life attack scenario:
Attackers may manipulate model behavior through evasion attacks that subtly alter inputs or poison training datasets with malicious data designed to influence future outputs.
Mitigation:
Include diverse real-world and adversarial examples in test datasets.
Establish testing frameworks that include unit, integration, penetration, and adversarial testing.
Use adversarial training techniques to improve resilience against manipulated inputs.
Continuously test models after deployment to identify unexpected behavioral drift and emerging attack paths.
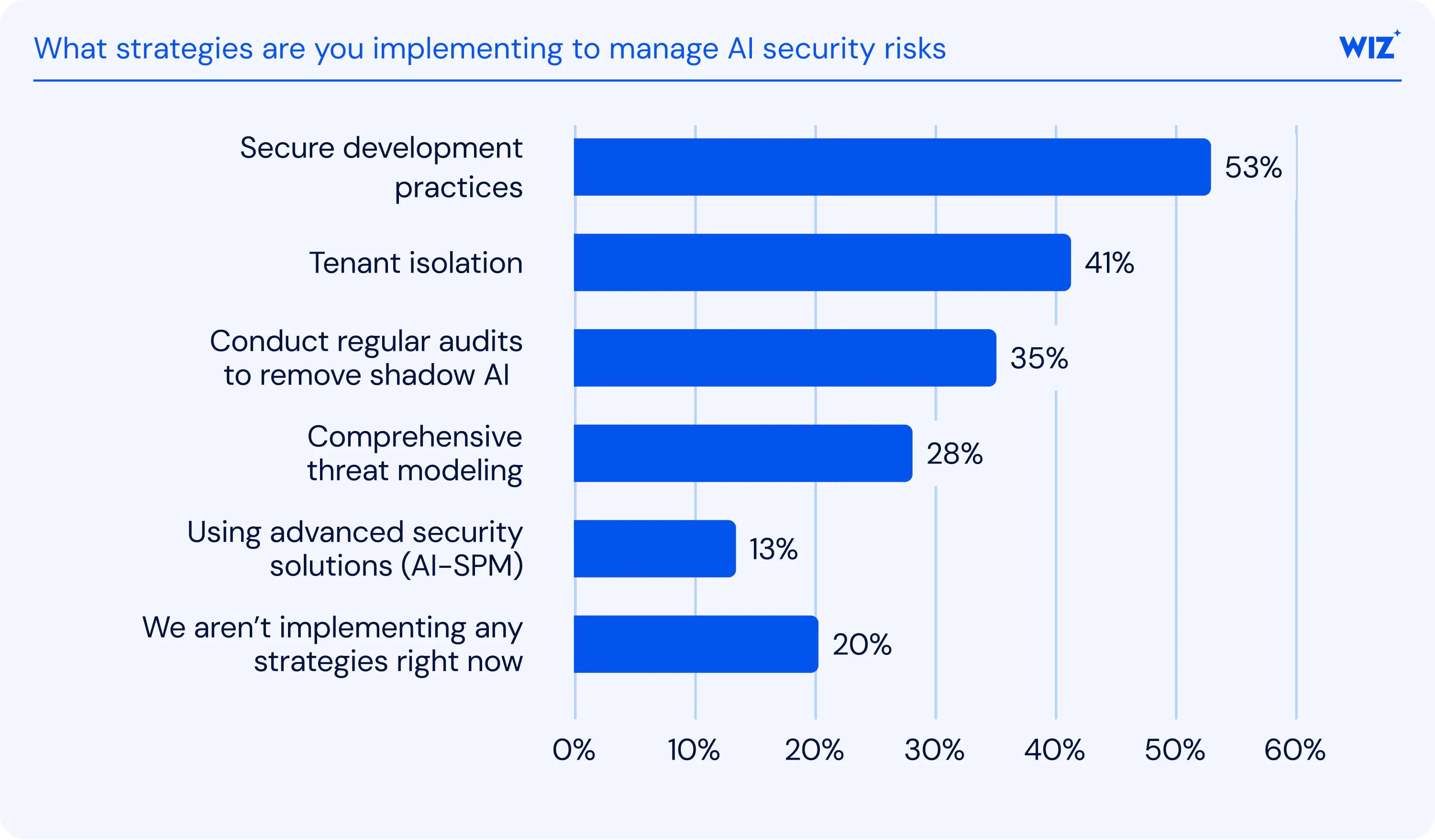
3 ways to manage AI security risks
Managing AI security risks requires more than reacting to individual threats. Organizations also need governance, visibility, and security controls tailored to AI systems and their unique attack surfaces.
Build a solid data governance framework
Without clear governance, AI risks are harder to detect, investigate, and contain. A strong framework defines how data is used, protected, and owned across the AI lifecycle.
Your framework should include:
Data classification: Identify sensitive data based on business value, regulatory requirements, and exposure risk.
Risk assessment: Continuously evaluate risks across models, datasets, integrations, and workflows.
Security controls: Enforce encryption, access controls, monitoring, and least privilege.
Ethical guardrails: Define acceptable use, fairness standards, and escalation paths.
Bias monitoring: Detect and reduce algorithmic bias through ongoing analysis.
Ownership and accountability: Assign clear responsibility for AI systems, decisions, and incident response.
Regulatory alignment is also critical. Frameworks like GDPR, NIST AI RMF, the EU AI Act, and OECD AI Principles provide guidance on data protection, risk management, transparency, and accountability. Used effectively, they act as operational guardrails—informing governance, testing, documentation, and incident response.
Maintain an up-to-date AI asset inventory
AI is often more deeply embedded across the environment than organizations realize. Without complete visibility into AI assets, security teams cannot properly govern access, monitor risk, or respond to incidents.
Your inventory should include four categories:
Visible AI: Customer-facing AI systems like chatbots and recommendation engines
Embedded AI: AI capabilities operating inside existing software platforms
AI add-ons: Traditional tools with optional AI functionality enabled
Custom AI: Proprietary models, agents, and internally developed AI systems
For each asset, document its purpose, deployment location, data access, and compliance status. Regular updates help eliminate blind spots as AI adoption expands across the organization.
Use AI-specific security solutions
Traditional cybersecurity and cloud security tools play an important role, but many were not designed to address AI-specific threats like prompt injection, model poisoning, or adversarial manipulation.
Purpose-built AI security solutions should provide capabilities such as:
Dynamic threat adaptation: AI-powered systems can analyze global threat intelligence and rapidly adapt to new attack patterns and evolving adversarial techniques. This adaptability can make all the difference when countering sophisticated, evolving threats like polymorphic malware or advanced persistent threats.
Automated threat hunting and forensics: AI-driven tooling can correlate events across large environments, identify hidden attack paths, and accelerate investigations.
Explainable AI compliance and auditing: Explainability features help organizations understand model behavior, support regulatory audits, and improve transparency during incident response.
Behavioral anomaly detection: AI-specific monitoring can identify unusual model behavior, unexpected outputs, or suspicious interactions that traditional tools may miss.
Organizations can use these capabilities to evaluate whether AI security tooling provides the visibility, adaptability, governance support, and response speed their environments require.
Watch 10-min AI Guided Tour
Interactive walkthrough of how Wiz helps security teams secure AI workloads across the cloud with full visibility.

The modern leader's role in securing AI applications
Security leaders shape how their organizations adopt, govern, and secure AI. That responsibility extends beyond approving tools or managing compliance requirements. It includes building the operational structures, security practices, and culture needed to support AI safely at scale.
This starts with investment. Organizations need dedicated resources for AI risk management, including specialized talent, monitoring capabilities, governance processes, and ongoing security assessments. As AI adoption grows, security teams also need visibility into how models, datasets, agents, and third-party integrations interact across the environment.
The bigger challenge is cultural. Security cannot operate as a blocker that slows innovation after deployment decisions are already made. Leaders who integrate security into AI development conversations early, encourage proactive risk identification, and reinforce the value of secure deployment practices build teams that treat AI security as a shared responsibility rather than a compliance exercise.
Protecting your AI applications with Wiz
Wiz introduced a fully integrated AI security offering within its cloud-native application protection platform. Wiz AI Security helps organizations discover AI assets, assess pipeline risk, detect shadow AI, and prioritize remediation across cloud environments.
AI bill of materials (AI-BOM) management
The AI-BOM provides visibility into every AI service, model, library, SDK, and pipeline operating across your environment. This helps security teams detect shadow AI, uncover unmanaged integrations, and maintain visibility across AI environments.
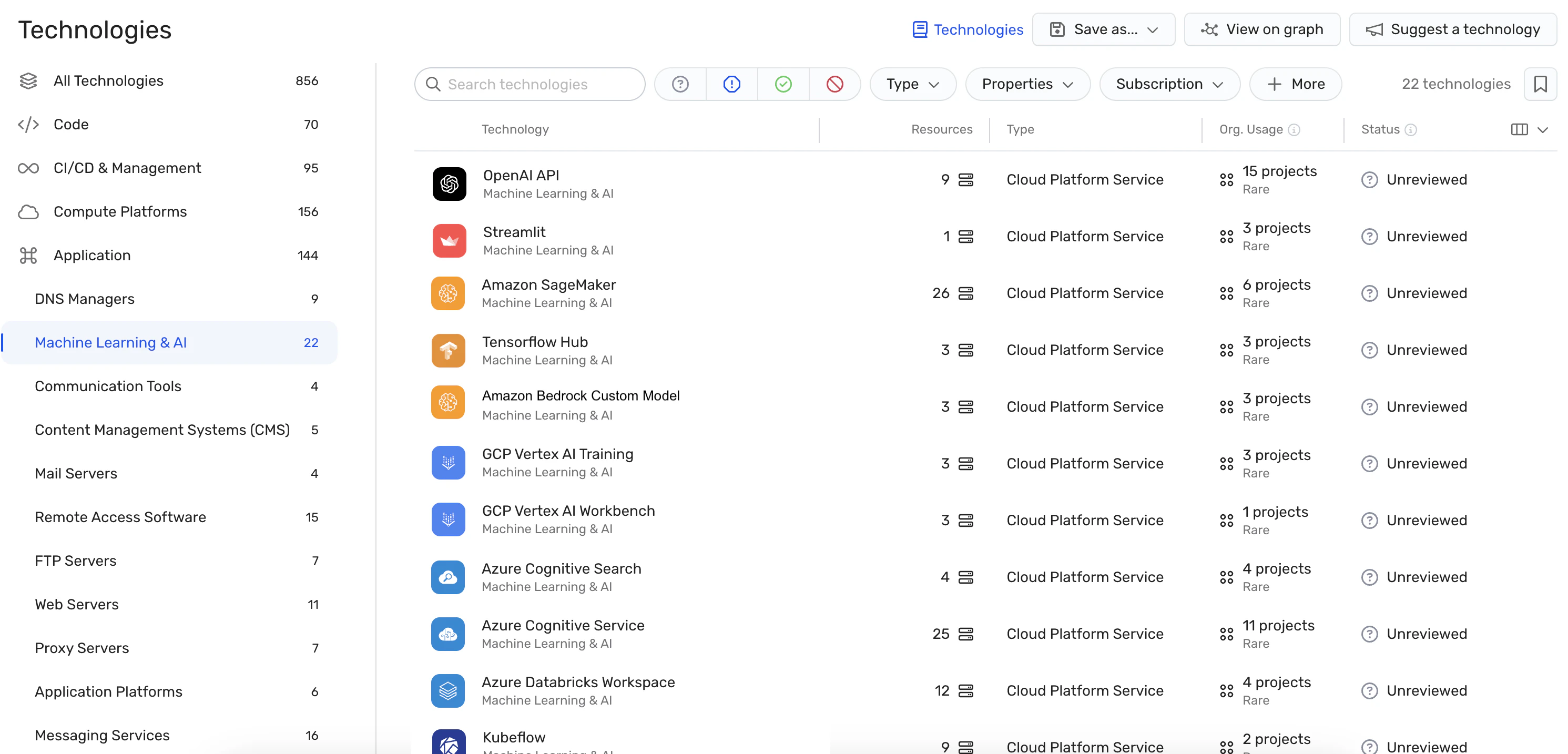
Mika AI enriches this inventory with contextual insights that show how AI assets are connected, what data they can access, and which risks they introduce. This gives teams a clearer understanding of AI exposure across both sanctioned and unsanctioned systems.
AI pipeline risk assessment
AI-SPM evaluates AI pipelines for vulnerabilities, attack paths, misconfigurations, and sensitive training data exposure. It helps organizations identify risks tied to adversarial attacks, supply chain compromises, and insecure model deployments before they impact production systems.
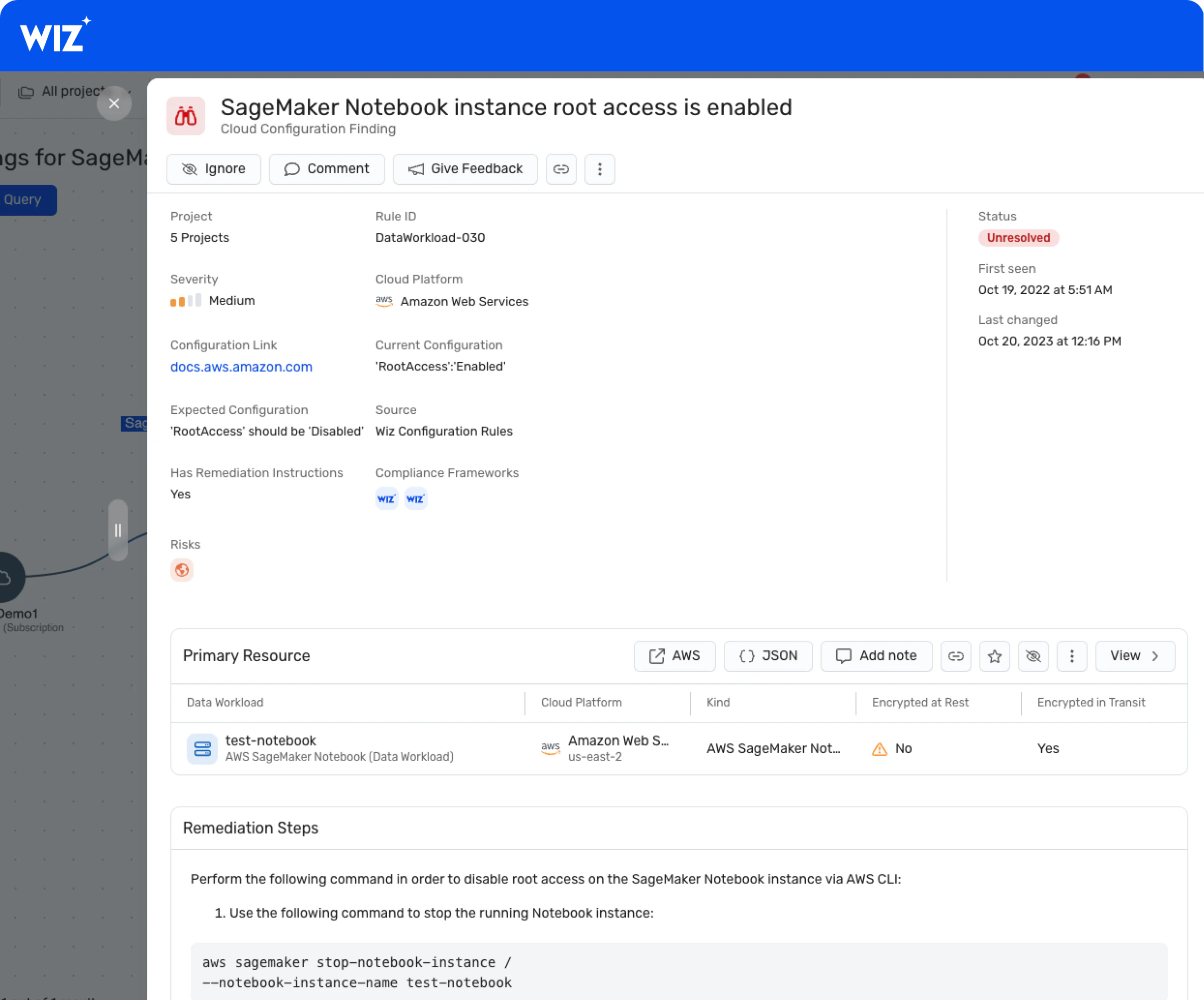
The Wiz SecOps AI Agent continuously monitors for anomalous behavior and automatically triages security events. When it detects issues like data poisoning attempts or exposed AI services, automated response workflows help contain threats quickly.
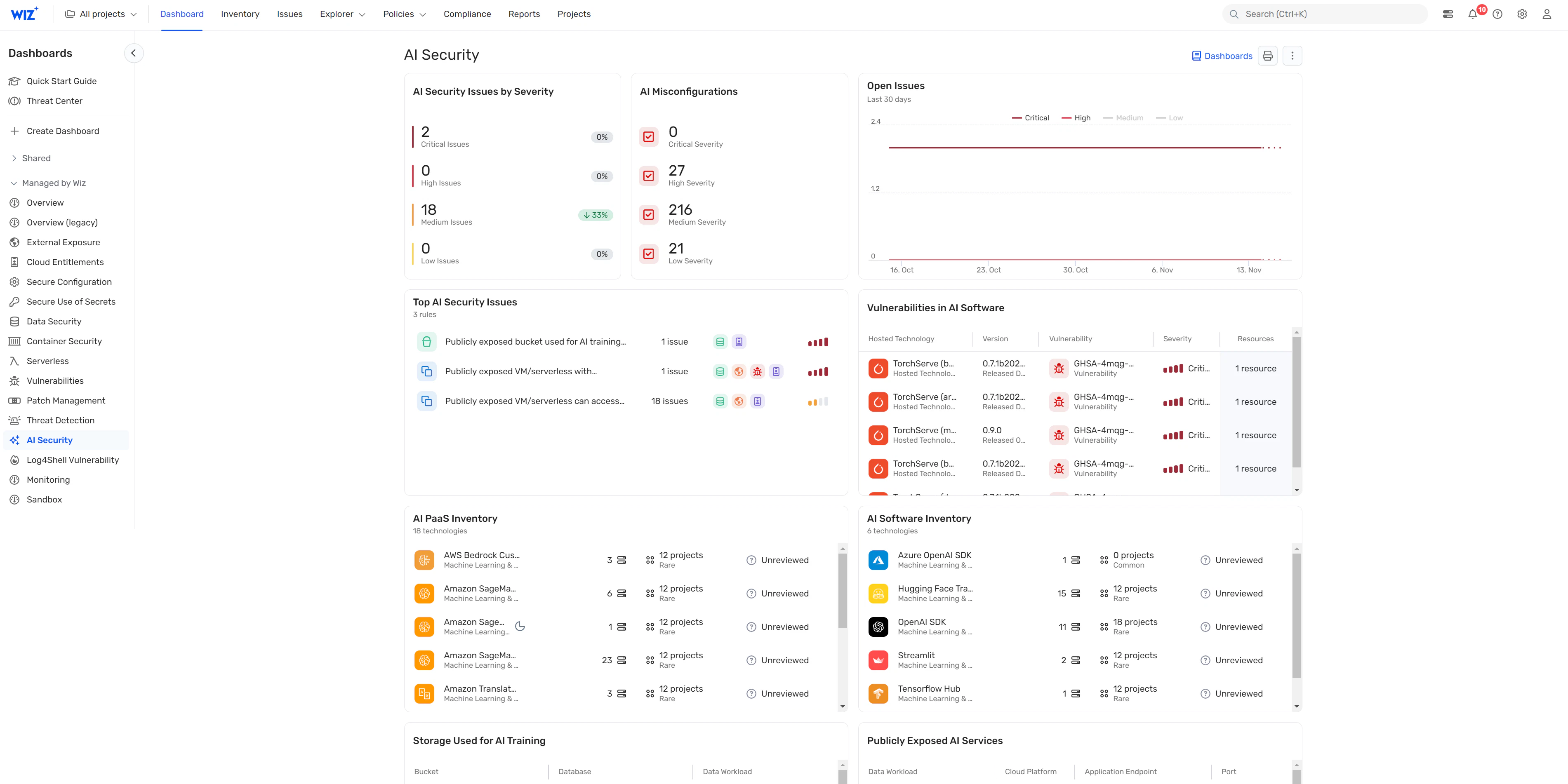
AI security dashboard access
The Wiz dashboard provides a centralized view of AI security findings, prioritized by exposure and risk context. Teams can identify vulnerabilities in AI SDKs like OpenAI and Hugging Face, investigate attack paths to AI services, and assess risks tied to model endpoints and integrations.
Request a demo to explore how Wiz can secure your cloud environment.
See Wiz AI - SPM in Action
Learn what makes Wiz the platform to enable your cloud security operation

To stay current on emerging AI risks and adoption trends, review the State of AI in the Cloud report, which analyzes findings from hundreds of thousands of public cloud accounts.