

Cosa sono i guardrail dell'IA?
I guardrail dell'IA (chiamati anche guardrails LLM o guardrail GenAI) sono Controlli di sicurezza preventiva che limitano il comportamento di un sistema di IA entro limiti politici definiti. Essi modellano ciò che un modello può vedere, fare e restituire, riducendo il rischio di output dannosi, distorti o che violano le politiche durante l'esecuzione del modello.
Le ringhiere di protezione sono Controlli preventivi applicato prima e durante l'inferenza. Lavorano insieme Controlli da detective come la registrazione, il monitoraggio e l'allerta, che identificano le violazioni dopo che si verificano, e Controlli di governance come politiche, documentazione e requisiti di audit.
In pratica, vengono utilizzati insieme tre strati di guardrail:
Guardrail di input: Filtra, valida e rimodella i prompt prima che arrivino al modello.
Guardrail di elaborazione: Controlla il contesto, i dati e gli strumenti a cui il modello può accedere e applica le regole di business durante il ragionamento.
Guardrail di uscita: Valuta la risposta del modello e blocca, modifica o rifiuta prima di restituirlo all'utente.
Questi guardrail differiscono dalla tradizionale sicurezza delle applicazioni. I controlli tradizionali proteggono il codice deterministico e gli input strutturati come i campi form o JSON. I guardrail dell'IA devono gestire sistemi non deterministici e linguaggio naturale, dove la stessa richiesta può produrre output diversi ogni volta e dove il comportamento del modello può essere influenzato tramite l'embedding contest o l'iniezione di prompt.
Per le aziende – specialmente quando si gestiscono dati regolamentati o flussi di lavoro rivolti al cliente – le barriere di sicurezza sono il modo migliore trasformare un prototipo in un sistema di produzione. Essi fanno rispettare i tuoi requisiti di sicurezza, protezione e conformità, consentendo comunque ai team di costruire su potenti modelli di base.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Perché le barriere dell'IA sono importanti per la sicurezza del cloud
Quando implementi l'IA nel cloud, combini due proprietà impegnative: Input in linguaggio naturale non affidabili e Accesso a dati e sistemi sensibili. Un modello può essere influenzato da testo arbitrario, eppure funziona su infrastrutture condividete, dietro API pubbliche o interne, e spesso con accesso a dati aziendali reali. Questo rompe molte delle assunzioni alla base dei controlli di sicurezza tradizionali.
I sistemi di IA cloud gestiscono dati sensibili come informazioni personali, registri finanziari o documenti proprietari. Controlli tradizionali come le regole di rete e i firewall Non può valutare prompt, finestre di contesto o comportamento del modello, quindi non impediscono attacchi come iniezioni pronte, manipolazioni di recupero o usi inaspettati di strumenti. I principali fornitori cloud ora includono controlli di sicurezza nei loro servizi di IA (ad esempio, Guardrails for Amazon Bedrock, filtri di contenuto Azure OpenAI e filtri di sicurezza AI Google Vertex), ma questi devono essere combinati con politiche specifiche per organizzazione, controlli IAM e monitoraggio a runtime per essere efficace.
In un ambiente cloud, il tuo Superficie d'attacco AI ora include:
Modelli: ospitava LLM, modelli fine-tuned e embedding personalizzati.
Dati di addestramento e inferenza: data lake, vettoriali store e log che possono contenere contenuti riservati.
Endpoint di inferenza: API pubbliche e interne per chat, ricerca o chiamate agli strumenti.
Agenti e orchestrazione: codice che permette ai modelli di chiamare strumenti interni o servizi esterni.
Artefatti del modello: pesi, checkpoint e immagini dei container che possono essere manomessi nella catena di approvvigionamento.
Senza barriere, il comportamento normale dell'IA può diventare un incidente di sicurezza: un attacco di iniezione prompt estrae dati sensibili da uno store vettoriale, un agente esegue un'azione indesiderata contro API interne o un endpoint configurato male espone informazioni dei clienti. Questi guasti creano sia rischi per la sicurezza che per il marchio, perché l'output del modello è direttamente visibile agli utenti.
Le imprese nei settori regolamentati già utilizzano guardrail multilivello per garantire la sicurezza delle implementazioni. Ad esempio, i produttori automobilistici utilizzano assistenti cloud con filtraggio rigoroso degli input, accesso controllato ai dati del veicolo e controlli in tempo reale su quali risposte possono essere restituite ai conducenti. Questo permette loro di adottare modelli avanzati rispettando comunque rigorosi limiti di sicurezza e conformità.
Tipi di guardrail per l'IA
I corrimano pratici funzionano come Gasdotto. Gli input vengono controllati prima di raggiungere il modello, il modello gira in un contesto di esecuzione controllata e gli output vengono validati prima di raggiungere gli utenti o i sistemi a valle.
1. Guardrail di ingresso
I guardrail di input valutano e rimodellano le richieste in arrivo Prima dell'inferenza. Questo è il primo livello di prevenzione contro comportamenti pericolosi.
Le guardrail di ingresso comuni includono:
Iniezione rapida e rilevamento della fuga da prigione: Identificare tentativi di sovrascrivere le istruzioni di sistema o di accedere a dati limitati.
Scansione dei dati sensibili: Rileva e oscura PII, PHI, credenziali o chiavi all'interno dei prompt.
Contenuti illegali o vietati: Bloccare richieste che cercano istruzioni dannose o materiale vietato.
Controlli su abuso e uso improprio: Applicare i limiti di velocità, identificare l'uso anomalo e bloccare i tentativi di forza bruta contro i filtri di sicurezza.
In pratica, i guardrail di input possono rifiutare un prompt, richiedere chiarimenti o Sanitizza l'input (ad esempio, identificatori di mascheramento) prima di inviarlo al modello.
2. Guardrail di elaborazione
I guardrail di elaborazione modellano il contesto di esecuzione in cui opera il modello. Determinano a cosa il modello può accedere e come può agire, oltre al testo del prompt.
I guardrail per l'elaborazione includono tipicamente:
Controlli contestuali: Limitare quali documenti, campi o log possono essere forniti al modello per ogni richiesta.
Sicurezza RAG: Limita quali collezioni una pipeline di recupero può interrogare, quanti risultati può utilizzare e applica il filtraggio ai contenuti recuperati.
Applicazione delle politiche: Codifica regole di business come "questo modello non può accedere alle API di pagamento di produzione" o "restituisci solo dati dalla stessa regione."
Controlli di identità e minori privilegi: Usa le politiche IAM per limitare l'accesso all'account di servizio del modello a fonti o servizi dati non autorizzati.
Guardrail per strumenti e agenti: Definisci quali strumenti un agente AI può chiamare, quali azioni richiedono l'approvazione umana e come i parametri vengono validati prima dell'esecuzione.
Le funzionalità di sicurezza dei provider cloud (ad esempio, filtri di contenuto o filtri di argomento in Azure OpenAI, Bedrock o Vertex AI) possono supportare questo livello, ma dovrebbero essere combinate con
3. Guardrail di uscita
I guardrail di uscita valutano la risposta del modello
Le guardrail di uscita comuni includono:
Tossicità e sicurezza dei contenuti: Rilevare odio, molestie, contenuti di autolesionismo o altre categorie non ammesse.
Rilevamento delle allucinazioni: Confronta le affermazioni con fonti affidabili o contesto recuperato per identificare affermazioni non supportate.
Fuga di dati sensibili: Scansiona per identificazioni personali, PHI, credenziali o segreti negli output e rimuovi o blocca secondo necessità.
Allineamento di brand e politiche: Regolare il tono, includere le dichiarazioni obbligatorie e applicare le regole di conformità nei domini regolamentati.
I guardrail di uscita possono bloccare la risposta, richiedere chiarimenti o
Molti team combinano controlli basati su regole (schemi di permesso/negazione, regole di redazione, policy di prompt) con classificatori basati su ML (rilevamento tossicità, rilevamento jailbreak, rilevamento PII). Altri avvolgono i modelli dei fornitori con un livello di sicurezza coerente tra i fornitori utilizzando API di moderazione o framework open-source guardrail.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Rischi dell'IA che le guardrail sono progettate per affrontare
Esistono barriere di sicurezza per l'IA per prevenire specifiche classi di guasti. Comprendere queste minacce ti aiuta a progettare controlli che proteggano sia i tuoi dati che la tua infrastruttura.
La maggior parte dei rischi dell'IA rientra in quattro categorie:
1. Manipolazione del comportamento del modello
Gli attaccanti cercano di influenzare o sovrascrivere le istruzioni del modello per produrre azioni o output non sicuri.
Iniezione rapida: Creare input che sovrascrivono le istruzioni di sistema ed estraggono dati o attivano azioni non consentite.
Iniezione indiretta a prompt: Incorporare istruzioni dannose all'interno di documenti o dati che il modello successivamente assimila tramite recupero o contesto.
Evasioni di prigione: Costringendo il modello a ignorare i vincoli di sicurezza integrati usando il role-playing, la traduzione o altri pattern di richiesta indiretti.
Prompt avversari: Schemi sottili di prompt progettati per causare output errati senza apparire maliziosi.
Questi rischi vengono affrontati principalmente attraverso
2. Manipolazione di dati e contesto
Invece di attaccare direttamente il modello, gli avversari prendono di mira il Pipeline dati che modellano il comportamento del modello.
Avvelenamento dei dati: Iniettare dati dannosi o di parte in set di addestramento o di fine tuning affinché il modello appra pattern non sicuri.
Avvelenamento contestuale: Manipolare i documenti o l'indice di recupero utilizzati dai sistemi RAG per influenzare le risposte.
Avvelenamento da RAG: Controlla quali documenti vengono recuperati affinché il modello ripeta informazioni fuorvianti.
Dirottamento fine: Compromessi per i lavori di messa a punto per inserire backdoor.
Queste minacce richiedono
3. Estrazione di informazioni sensibili e IP
Gli attaccanti tentano di recuperare dati dal modello o dai suoi componenti di supporto.
Estrazione del modello: Riprodurre il comportamento di un modello proprietario attraverso query ripetute.
Inferenza sull'appartenenza: Determinare se specifici record facevano parte dei dati di addestramento tramite sondaggio delle risposte del modello.
Fuga di dati sensibili: Il modello riproduce contenuti memorizzati da log, dati di addestramento o archivi vettoriali.
Questi rischi vengono mitigati attraverso
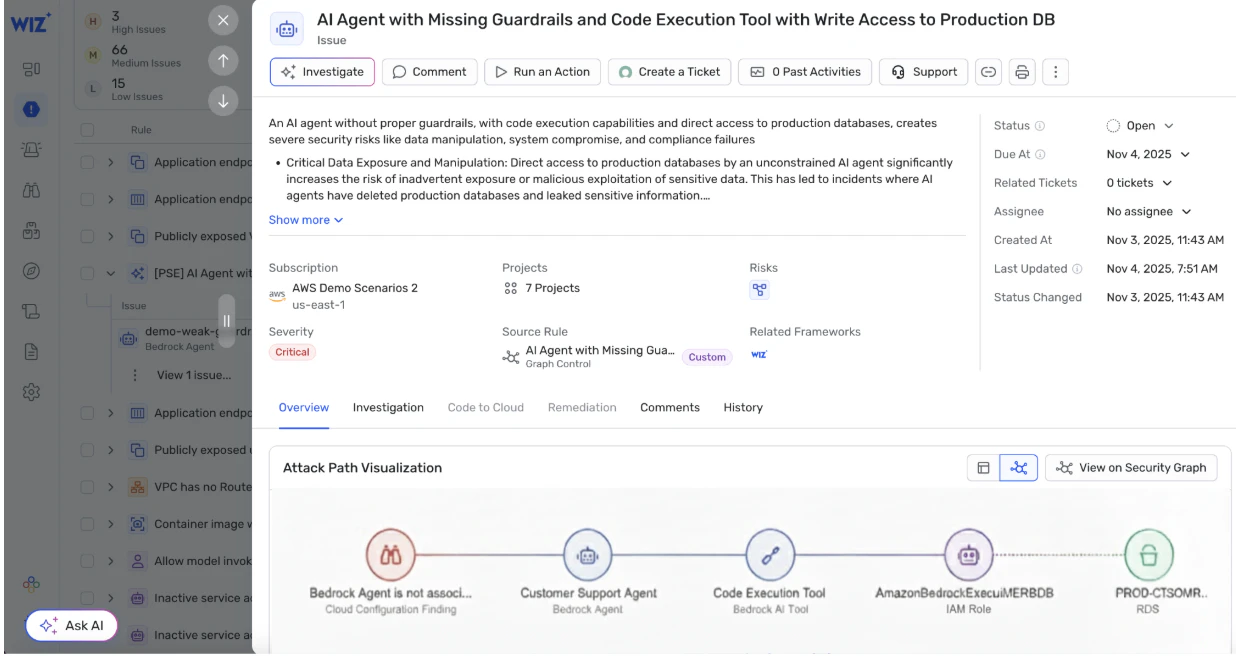
4. Sfruttamento dell'accesso tramite agenti e strumenti
La categoria di rischio in più rapida crescita riguarda modelli che possono
Agenti con autorizzazioni eccessive: Agenti che hanno ampio accesso a API interne, database o servizi cloud.
Abuso degli strumenti: Usare strumenti consentiti in modi inaspettati, portando a operazioni non autorizzate.
Escalation dell'identità: Un modello che agisce sotto un account di servizio privilegiato senza una corretta isolazione.
Questi rischi richiedono
Sample AI Security Assessment
Get a glimpse into how Wiz surfaces AI risks with AI-BOM visibility, real-world findings from the Wiz Security Graph, and a first look at AI-specific Issues and threat detection rules.
Get Sample Report

Come funzionano le barriere di sicurezza dell'IA nella pratica
In un sistema reale, le guardrail non sono un filtro singolo che aggiungi alla fine. Sono controlli multipli applicati lungo il percorso della richiesta, dal punto di ingresso dell'API alla validazione dell'output. Ogni strato elimina una diversa categoria di rischio.
Un comune Flusso di inferenza con guardrail Appare così:
Richiesta dell'utente: Un utente invia un prompt o una chiamata API.
Guardrail di input: La richiesta viene validata, sanificata o rifiutata prima di raggiungere il modello.
Costruzione contestuale (RAG): Se viene utilizzato il recupero, vengono recuperati e filtrati solo le fonti di dati e i documenti approvati.
Applicazione delle politiche: Le regole di business e i controlli di sicurezza determinano ciò a cui il modello può accedere e quali strumenti può chiamare.
Inferenza del modello: Il modello genera una risposta entro questi vincoli.
Esecuzione degli strumenti (agenti): Se il modello richiede azioni, i parametri vengono validati ed eseguiti con il privilegio minimo, oppure richiedono l'approvazione umana.
Guardrail di uscita: La risposta viene verificata per sicurezza, affermazioni supportate, dati sensibili e conformità prima di essere restituita all'utente.
Registrazione e monitoraggio: L'interazione completa viene registrata per analisi, avvisi e miglioramenti.
Questo schema ti permette di prevenire comportamenti pericolosi prima che si verifichino e di individuare problemi che si manifestano.
Dove vengono applicate le guardrail
I guardrail possono essere integrati in diversi punti della tua architettura:
API gateway: Autenticazione, limitazione di velocità, controlli di contenuti grossolani.
Strato di orchestrazione: Catene, middleware e validatori che implementano filtri di prompt, controlli contestuali e logica di policy.
Servizi cloud: Filtri di sicurezza del fornitore (ad esempio, filtri di tossicità o di tema) che si attivano durante l'inferenza.
Livello identità: Politiche IAM che definiscono quali sorgenti dati, API e strumenti può accedere l'account di servizio del modello.
Confini degli strumenti: Flussi di validazione e approvazione per le azioni dell'agente.
Archivi vettoriali: Controlli di accesso e filtraggio a livello di documento per prevenire l'avvelenamento contestuale o la fuga di dati.
Filtri di uscita: Modelli di classificazione o regole che bloccano o riscrivono risposte non sicure.
Ogni strato è progettato per eliminare una diversa classe di rischio, così che i guasti in uno strato vengano rilevati da un altro.
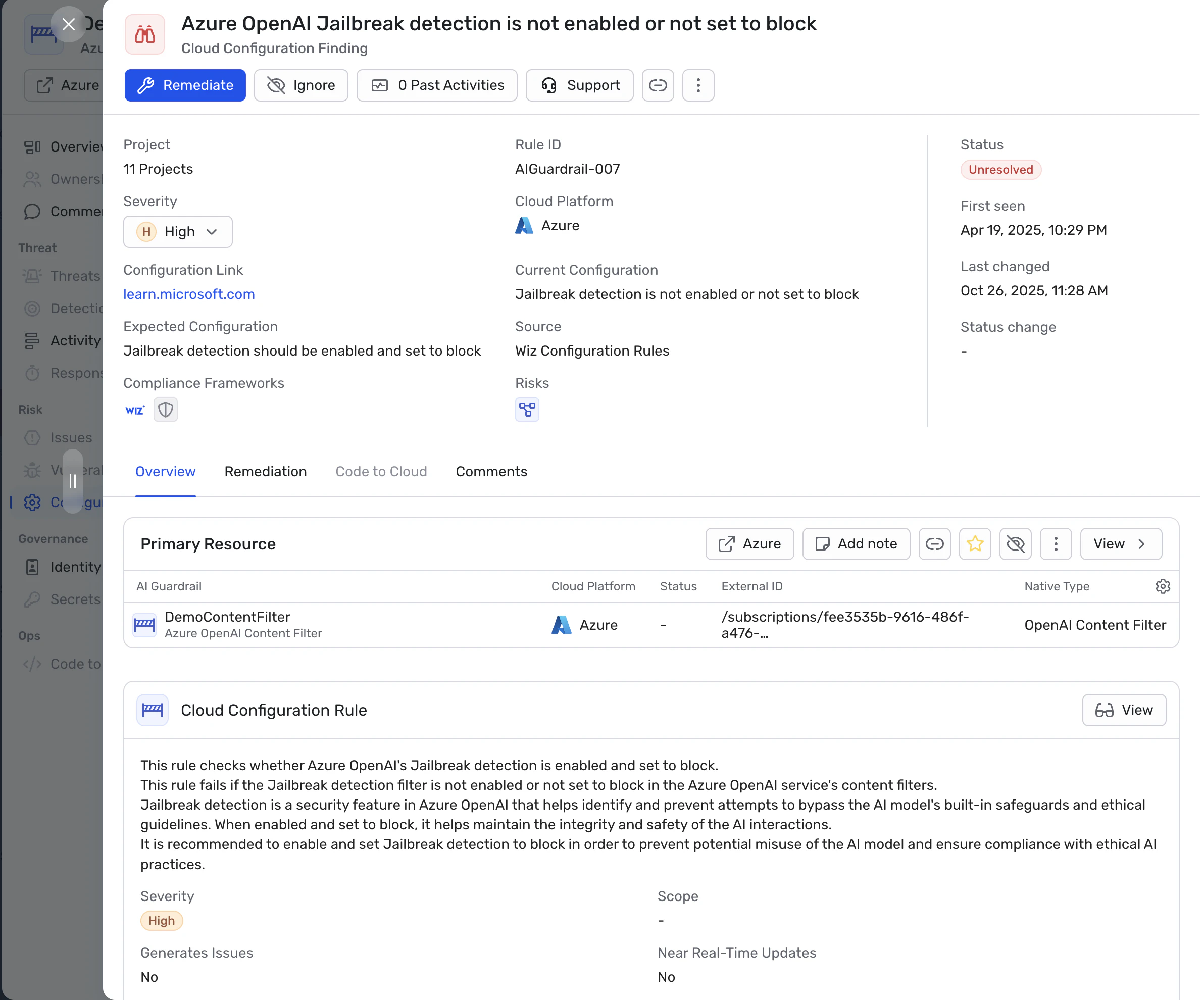
Come Wiz abilita barriere complete per l'IA lungo tutto il ciclo di vita della sicurezza
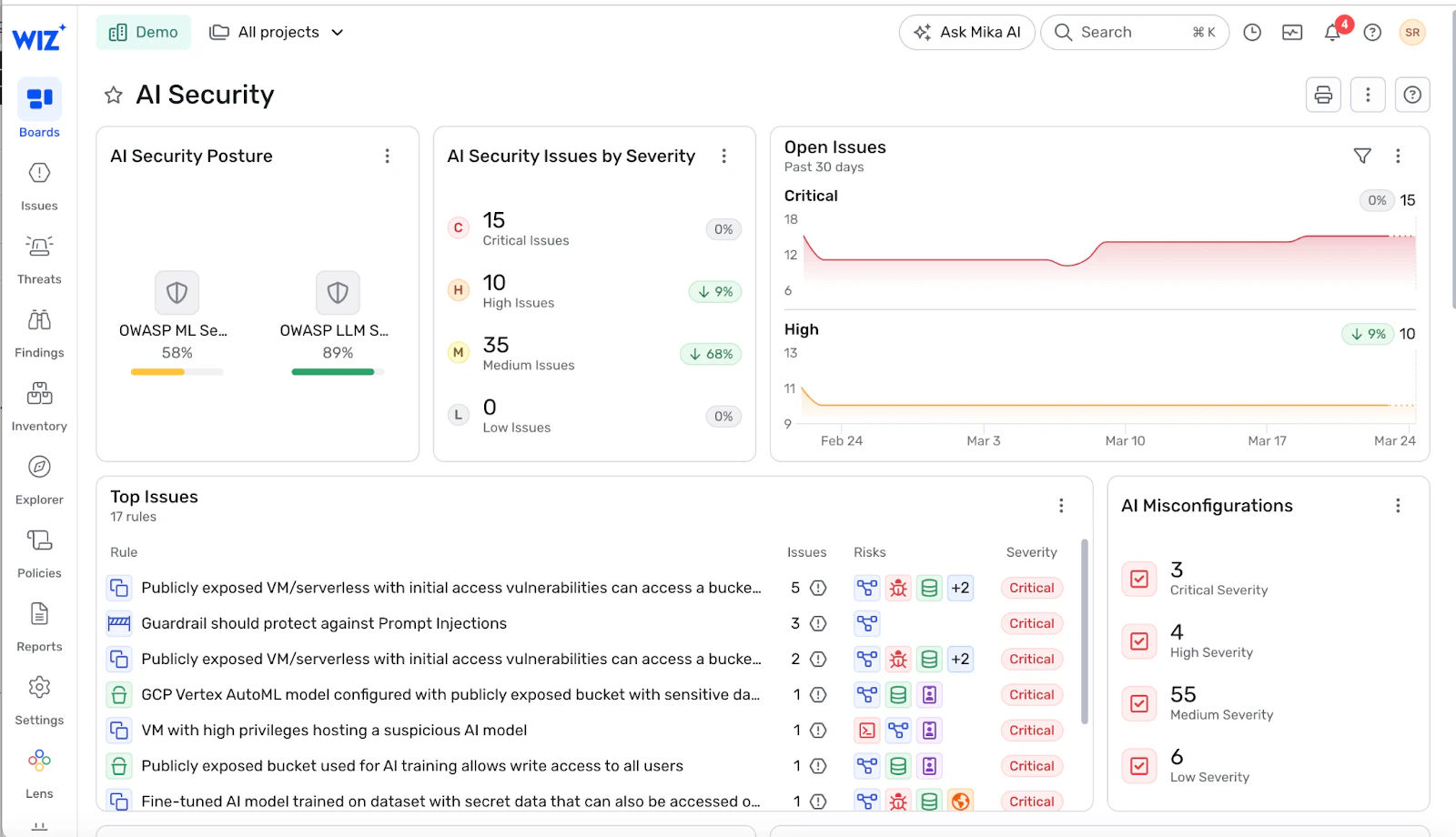
Wiz AI-SPM Ti offre una visibilità end-to-end sul tuo patrimonio di IA su AWS, Azure e GCP – dai servizi di IA gestiti e endpoint di inferenza ai pipeline di recupero e alle identità che li sostengono. Wiz rileva configurazioni errate in piattaforme come Amazon SageMaker, Azure OpenAI e Google Vertex AI che possono bypassare le tue barriere, come endpoint pubblici con accesso a dati sensibili o agenti che funzionano con ruoli sovra-autorizzati.
Le Wiz Security Graph mappa come infrastrutture, identità, dati e carichi di lavoro di IA interagiscono Questo ti permette di individuare combinazioni tossiche nascoste nell'ambiente – ad esempio, un endpoint esposto che parla con uno store vettoriale pieno di dati di addestramento sensibili, raggiungibile tramite un account di servizio ampio collegato a un agente. Wiz mette in evidenza questi rischi così da poter rimuovere i percorsi di bypass che si trovano sotto le tue barriere.
Wiz estende questi controlli lungo tutto il ciclo di sviluppo e runtime. Codice Wiz scansiona IaC e il codice applicativo che definiscono la tua infrastruttura AI per individuare problemi come chiavi di modello codificate rigidamente, regole di rete rischiose o servizi AI configurati male prima del deployment. Wiz Defend monitora i carichi di lavoro legati all'IA in tempo reale per pattern API insoliti, accessi non autorizzati ai dati o potenziali tentativi di esfiltrazione legati al comportamento del modello. Incorporato DSPM Le capacità classificano i dati sensibili usati nell'addestramento o nell'inferenza e mostrano come fluiscono nei modelli e negli endpoint, così da poter costruire guardrail focalizzati sui dati basati sulla realtà.
Poiché tutto questo contesto si trova in un'unica piattaforma, le organizzazioni possono far rispettare politiche di sicurezza unificate dell'IA su repository di codice, pipeline CI/CD, risorse cloud e ambienti di runtime. In altre parole, Wiz fornisce delle guardrail per i tuoi guardrail – Assicurandosi che l'infrastruttura, i percorsi dei dati e le identità attorno ai tuoi modelli siano correttamente configurati, monitorati e protetti.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
