

悪意のあるAIモデルは 意図的に兵器化されたモデル遺物 これらは読み込みや実行時に有害な動作を実行します。 偶発的な欠陥を含む脆弱なモデルとは異なり、悪意のあるモデルは展開環境を侵害するように設計されています。
悪意のあるAIモデルの特徴は、脅威が埋め込まれていることです モデルファイル自体の内部. 多くの場合、攻撃者はモデルの重みやロードロジック内に実行可能なコードを隠すために、安全でないシリアライゼーション形式を悪用します。 モデルがインポートまたはデシリアライズされると、そのコードは自動的に実行されます—多くの場合、推論が行われる前にです。
これにより、悪意のあるAIモデルは独自のサプライチェーン脅威となっています。 彼らは、公開リポジトリからダウンロードされたものやチーム間で共有された事前学習済みモデルに対する組織の信頼を利用します。 モデルアーティファクトは従来のソースコードのように扱われないため、コードレビュー、静的解析、依存性スキャンなどのセキュリティ制御をしばしば回避します。
AIの普及が加速する中で、事前学習モデルは現代開発の基盤となっています。 その利便性がモデルのアーティファクトを高価値の攻撃ベクトルへと変えてしまい、従来のアプリケーションセキュリティツールでは検査されるように設計されていなかったものとなっています。
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

悪意のあるAIモデルがサプライチェーンの現実的なリスクである理由
悪意のあるAIモデルは、現代のソフトウェア開発を一変させた同じ力、すなわち再利用、自動化、外部コンポーネントへの信頼から生まれます。 事前学習済みモデルは、開発を加速しコストを削減し、ゼロからの再学習を避けるために、公開リポジトリから定期的に削除されています。 多くの組織では、モデルのダウンロードと展開はライブラリをインストールするのと同じくらい日常的なものになっています。
このワークフローは、内部レビューされたコードから外部の成果物への信頼を移し、ほとんど検査されないものに移します。 モデルファイルはしばしば不透明なバイナリとして扱われ、アプリケーションコードやコンテナ画像に対する精査なしに保存、共有、ロードされます。 その結果、コードレビュー、静的解析、依存性スキャンなどの確立されたセキュリティ制御をしばしば回避しています。
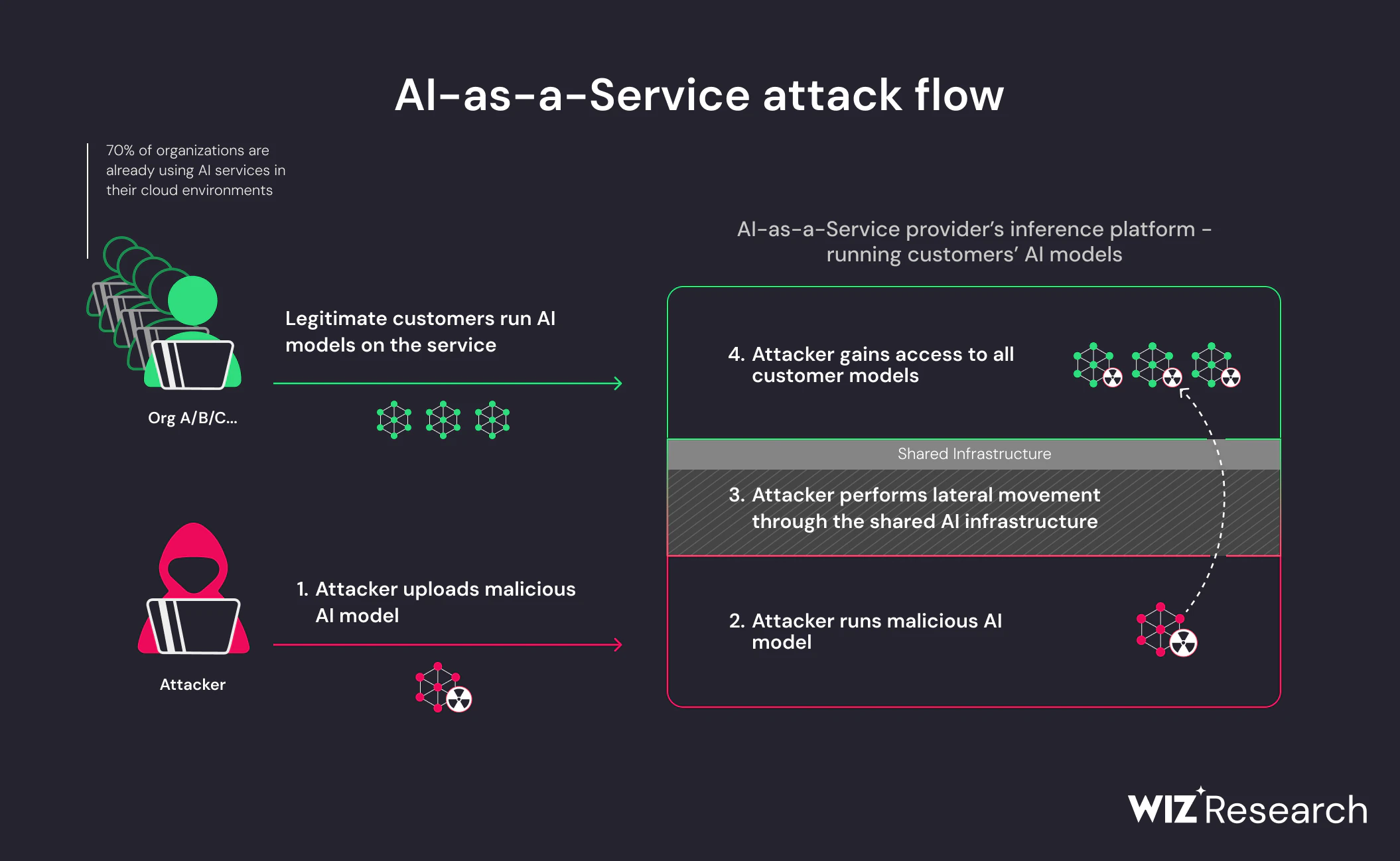
このリスクが特に深刻なのは、悪意のあるモデルが悪用を行っている点です 期待される行動. モデルの読み込みはAIパイプラインにおいて通常で信頼できる作業です。 攻撃者がモデルの成果物に実行可能な論理を埋め込むと、その信頼が配信の手段となります。 エクスプロイトチェーンは必要ありません。システムが設計された通りに動作しているために侵害が起こるのです。
これが悪意のあるAIモデルが サプライチェーン脅威 アプリケーションのバグではなく、 リスクはモデルの使い方から生じるのではなく、 どこから来て、どのように装填されるか. モデルの再利用がチームや環境全体で拡大し続ける中で、モデルの出所や挙動を検証する能力は基本的なセキュリティ要件となります。
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
もっと読む

悪意のあるAIモデルの高レベルな動作
悪意のあるAIモデルは、現代のAIワークフローにおけるモデルのパッケージ化、配布、読み込みの仕組みを悪用します。 核心的なリスクはモデルの予測ではなく、 モデルファイルがデシリアライズまたは初期化されたときにトリガーされる実行パス.
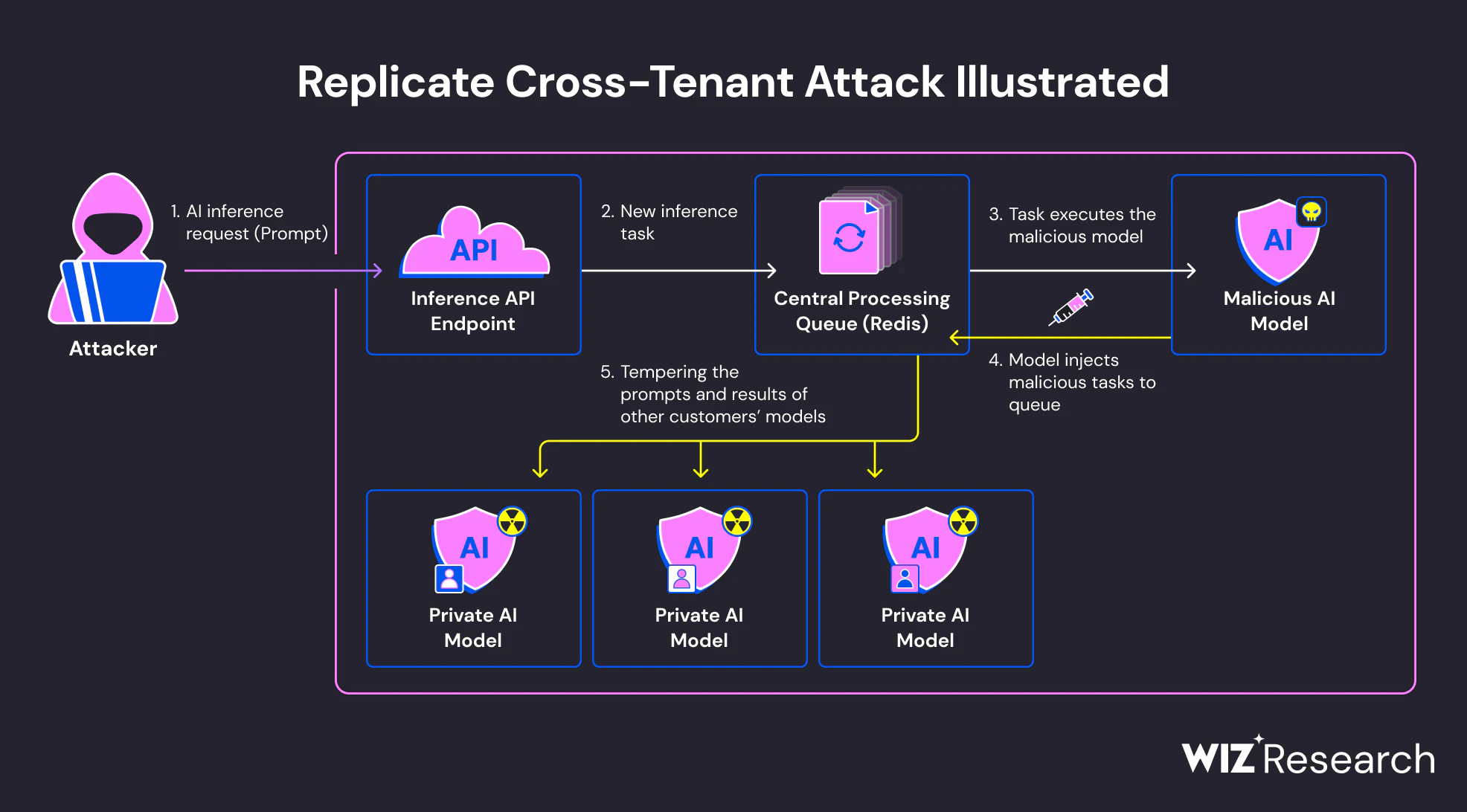
モデルロード時の実行
多くのAIフレームワークは、モデルの読み込みプロセスの一部として実行可能なロジックを実行できるシリアライズ形式をサポートしています。 特に、Pythonの ピクルスPyTorchや関連ツールでよく使われる-ベースのフォーマットは、モデルがデシリアライズされた際に任意のコードを実行することがあります。 この行動は記録されていますが、実際には見過ごされがちです。
悪意のあるモデルが読み込まれると、組み込みコードは推論や評価が行われる前に即座に実行できます。 システムの視点から見ると、これは通常のモデルインポートのように見えます。 攻撃者の視点から見ると、これは信頼できる環境内での実行ポイントです。
なぜ推論の前にこれが起こるのか
アプリケーションコードとは異なり、モデルはデータとして扱われます。 セキュリティコントロールはモデルの読み込み方法よりも、どのように使われるかに焦点を当てる傾向があります。 その結果、最も危険な活動はライフサイクルの初期、つまりロード時に発生し、ランタイムの監視、アクセス制御、動作チェックが適用される前に発生します。
これが、従来のツールでは悪意のあるモデルを検出しにくい理由です。 疑わしいAPI呼び出しがないこと、入力の不形がないこと、異常な出力がないこともあります。 この妥協は、単にモデルが正当なものとして受け入れられたために起こります。
一般的な攻撃者の目的
実行が完了すると、攻撃者は通常、馴染みのある目標を追求します。
環境内で利用可能な認証情報やトークンの盗難
トレーニングデータや下流データストアへのアクセス
バックドアやスケジュールされたタスクを通じた永続性の確立
暗号マイニングやさらなる侵害のために計算資源を消費すること
これらの動作はAI環境に特有のものではなく、モデルは権限を上げ、機密データに近い環境で動作することが多いため、その影響が増しています。
より安全なフォーマット、より安全なデフォルト
すべてのモデルフォーマットが同じリスクを抱えるわけではありません。 実行可能なロジックから重みを分離するために設計されたフォーマット — 例えば SafeTensorとONNX –モデル読み込み中のコード実行の可能性を低減します。 これらのフォーマットは、埋め込み実行パスを持たずにモデルデータを保存するため、設計上安全性を高めています。
一方、デシリアライゼーション中に実行可能な論理を許可するシリアライズ機構は、厳密に管理されない限りリスクが高まります。 実際には、互換性や利便性のために、明確なセキュリティ基準が適用されない限り、チームは安全でないフォーマットをデフォルトで選ぶことが多いです。
理解 どうやって したがって、モデルが読み込まれていることは、悪意あるAIモデルから防御する上で中心的な役割を果たします。 この脅威は敵対的な入力や新しいAIの挙動に依存せず、一般的なMLツールにおける予測可能で信頼できる実行経路に依存しています。


悪意のあるAIモデルに対する主な攻撃経路
悪意のあるAIモデルは通常、少数の繰り返し可能な攻撃ベクトルを通じて本番環境に到達します。 これらのベクトルは、新しいAI行動ではなく、モデルの成果物への信頼やAIワークフローの自動化を利用しています。
公開モデルリポジトリ
パブリックリポジトリは悪意のあるモデルの最も一般的な配布チャネルです。 攻撃者は、武器化されたモデルを人気プラットフォームにアップロードしたり、よく知られたプロジェクトを模倣するためにタイプスクワッティングを使ったりします。 時間が経つにつれて、悪意のあるバージョンを導入する前に無害なリリースを通じて評判を築くことがあります。
事前学習モデルはしばしば開発や訓練環境に直接ダウンロードされるため、これらのアーティファクトはアプリケーションコードやコンテナイメージに適用されるレビュープロセスを回避できます。
モデルローダーによるリモートコード実行
一部のAIワークフローでは、モデル読み込み時にリモートまたはカスタムコード実行を明示的に許可しています。 許容ローダーフラグやカスタムモデルクラスなどの設定は、実行可能なロジックを取得・動的に実行できるため、攻撃対象範囲を拡大します。
この場合、リスクはモデルの重みそのものではなく、外部コードを暗に信頼する読み込みメカニズムにあります。 これにより、ローダーの設定は脅威モデルの重要な一部となります。
トロイの木馬モデルと学習済みバックドア
すべての悪意のあるモデルが読み込み中の実行に依存しているわけではありません。 生産中のほとんどの条件下で正常に振る舞うよう設計されたものもあります 特定のトリガーが存在する場合の悪意のある出力. これらの「トロイの木馬」モデルは、実行可能なコードではなく、学習した重みに直接有害な行動を埋め込んでいます。
シリアライズベースの攻撃とは異なり、トロイの木馬モデルは通常、 トレーニングやファインチューニングのプロセス例えば、訓練データを毒化したり、微調整ワークフローを操作したりするなどです。 悪意のある行動はモデルのパラメータに符号化されているため、モデルのアーティファクトを静的スキャンしても脅威の可視性は限定的です。
これによりトロイの木馬モデルは独自のリスクカテゴリーとなっています。 それらを検出するには、モデルファイルだけの検査ではなく、対抗的テスト、行動分析、またはトレーニングデータや系譜の検証が必要です。
依存と内部リスク
悪意のあるモデルは、侵害された依存関係や信頼できる内部チャネルを通じて環境に侵入することもあります。 これには、毒されたMLライブラリ、安全でない内部レジストリ、正当なアクセス権を持つ内部者が導入したモデルなどが含まれます。
これらのベクトルは既存の信頼関係に依存しているため、広範な影響の可能性があるにもかかわらず、初期の脅威モデリングでは見落とされがちです。
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

なぜクラウド環境がリスクを増幅させるのか
クラウド環境は悪意のあるAIモデルを生成しませんが、かなりの頻度で作り出します インパクトと速度を上げる 誰かが紹介されたときの妥協の話です。 クラウドプラットフォームがAIに理想的な特徴である自動化、スケール、機密データへのアクセスは、サプライチェーンのリスクも拡大します。
AIワークロードはしばしば権限が上がった状態で動作します。 トレーニングジョブや推論サービスは、大規模なデータセット、オブジェクトストレージ、シークレット、下流サービスへのアクセスを必要とすることが多いです。 悪意のあるモデルがこのコンテキスト内で実行されると、即座にその権限を継承し、モデル自体を超えて攻撃範囲を拡大できます。
自動化はリスクをさらに増幅させます。 モデルは一般的にCI/CDパイプライン、オーケストレーションフレームワーク、またはスケジュールされた再学習ワークフローを通じて展開されます。 悪意のあるアーティファクトがこれらの経路に入ると、人間の介入なしに環境を高速で伝播させることができ、手動検査は非現実的になります。
クラウドインフラは、機密データに対して実行が行われる場所も変わります。 悪意のあるモデルは通常実行されます アクセスすべきデータと同じデータ平面内にあります隣接するのではなく、 データベースにアクセスするために横方向に動かなければならない侵害されたウェブアプリケーションとは異なり、モデルはしばしばすでに訓練データ、推論入力、または下流システムに直接アクセスできる環境内で動作します。 これにより、実行と衝撃の間の距離が縮まります。
最後に、AIワークロードは複雑なマネージドサービス、コンテナ、GPU、ランタイム依存関係に依存しています。 各層は、制御が誤った場合に攻撃者が利用できる構成および隔離の課題を導入します。 実際には、悪意のあるモデルは今日多くのクラウド侵害を引き起こしているのと同じミス設定から恩恵を受けています。
これらの要因が合わさることで、悪意のあるAIモデルは局所的なリスクから システムレベルのセキュリティ懸念モデルセキュリティはクラウドアイデンティティ、データアクセス、デプロイパイプラインの文脈で評価されるべきであり、単独で評価するのではなく、その理由を強調しています。
悪意あるAIモデルからの防御
悪意のあるAIモデルから防御するには、モデルの挙動から モデルの出所、読み込み経路、実行コンテキスト. 脅威はアーティファクトや訓練プロセス自体に組み込まれているため、従来の アプリケーションセキュリティ制御 必要だが、'それだけでは十分だ。
モデルが生産される前に管理体制を確立しましょう
最も効果的な防御は機能します モデルを読み込む前に. これには、モデルの出所、パッケージング方法、ロード時に実行されるコードパスの検証が含まれます。 モデルの成果物を一流のサプライチェーン部品として扱い、検査、承認、バージョン管理の対象とすることで、兵器化されたモデルが機密環境に到達する可能性を減らします。
実際には、同じガバナンスを モデルレジストリ その組織はすでにコンテナレジストリーやアーティファクトリポジトリに申請しています。 コンテナ画像が管理されたパイプラインを通じて署名され、スキャンされ、プロモーションされる場合、モデルの成果物も内部から来るものであれ公開されたものであれ、同じ規律に従うべきです。
可能な限り、データは実行可能なロジックから分離し、外部コードを暗的に信頼するローダー構成を制限するモデル形式を好むべきです。 これらのコントロールはリスクを完全に排除するものではありませんが、攻撃対象を大幅に狭めます。
アイデンティティおよびアクセス制御による実行制約
悪意のあるモデルは、広範な権限を継承するときに最も危険です。 トレーニングや推論ワークロードに割り当てられるアイデンティティや役割を制限することで、モデルが侵害された場合の攻撃範囲を減らします。 これにはサービスアカウントの最小権限の強制、環境の隔離、パイプライン間での認証情報共有の回避が含まれます。
モデルはしばしばデータプレーン内で実行されるため、アクセス制御は二次的な安全策ではなく、主要な防衛線となります。
行動は個別に観察せず、文脈の中でモニタリングしてください
静的検査だけでは、特に学習した重みに挙動を埋め込む悪意のあるモデルをすべて検出することはできません。 ランタイム可視性は、モデルが環境と時間をかけてどのように相互作用するかを観察することで、そのギャップを埋める助けとなります。
効果的なモニタリングは以下の点に焦点を当てています。 コンテキストシグナル:予期しないネットワークアクセス、異常なファイル操作、異常なアイデンティティ使用、または確立された実行パターンからの逸脱。 これらのシグナルは、クラウドコンテキストと相関するときに最も意味を持ちます。つまり、モデルがアクセス可能なデータ、使用するアイデンティティ、そしてどのように展開されたかです。
モデルセキュリティはクラウドセキュリティの一部として扱う
最終的に、悪意あるAIモデルから防御することは独立した分野ではありません。 既存のAI特有の考慮事項を統合する必要があります クラウドセキュリティの実践、サプライチェーンガバナンス、アイデンティティ管理、ワークロード監視などが含まれます。
モデルを不透明なブラックボックスとしてではなく、動作する広範なシステムの一部として評価することで、セキュリティチームは推測的な検出やモデルの挙動に関する仮定に頼らず、悪意のあるアーティファクトへの露出を減らすことができます。
Wizが悪意のあるAIモデルのリスクを減らす手助け
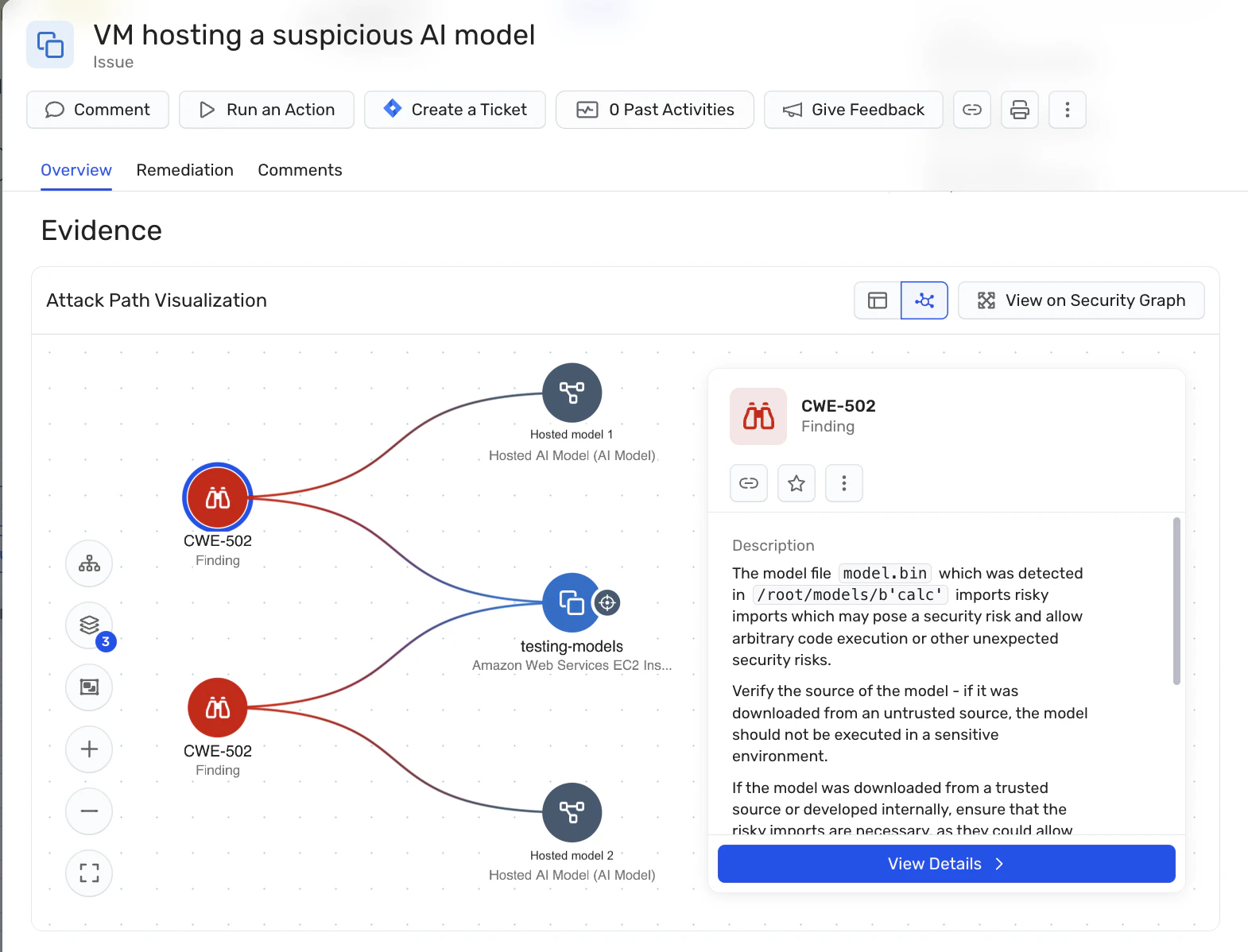
Wizは、モデルセキュリティをクラウドセキュリティの基礎に据え、悪意のあるAIモデルのリスクを減らすのを支援します。 モデルの意図や行動を分類しようとするのではなく、Wizは決定するコントロールの検証に注力しています モデルの出典、搭載方法、展開後にアクセス可能な内容.
通過 AIセキュリティ・ポスチャー・マネジメント(AI-SPM) および Wizセキュリティグラフ、AIモデル、トレーニングジョブ、推論サービス、レジストリは一流のクラウド資産として扱われます。 Wizはホストされたモデルのアーティファクトを可視化し、フォーマットレベルの検査を行い、リスクのあるシリアライズ手法や信頼できないソースを明らかにします。これにより、ソフトウェアのサプライチェーンの規律をAIモデルに拡張し、本番環境に至る前に活用できます。
モデルのアーティファクトをアイデンティティ、権限、ネットワーク露出、機密データアクセスと関連付けることで、Wizはチームがリスクの高いまたは潜在的に悪意のあるモデルがどこに現れるかを識別するのを支援します 実際には悪用可能、その真の攻撃範囲を理解し、実際の攻撃経路に基づいて修復を優先し、AI開発を遅らせたり、別のセキュリティツールを導入したりせずに。
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
