

O que são guarda-corpos de IA?
Guarda-rails de IA (também chamados de guardrails LLM ou guardrails GenAI) são Controles de segurança preventiva que restringem o comportamento de um sistema de IA dentro dos limites definidos das políticas. Eles moldam o que um modelo pode ver, fazer e devolver, reduzindo o risco de resultados prejudiciais, tendenciosos ou que violam políticas durante a execução do modelo.
Os guarda-corpos são Controles preventivos aplicado antes e durante a inferência. Eles trabalham juntos Controles de detetive como registro, monitoramento e alerta, que identificam violações após ocorrerem, e Controles de governança como políticas, documentação e requisitos de auditoria.
Na prática, três camadas de guarda-corpos são usadas juntas:
Guarda-corpos de entrada: Filtre, valide e remodele os prompts antes que cheguem ao modelo.
Limites de processamento de proteção: Controle quais contextos, dados e ferramentas o modelo pode acessar e faça cumprir regras de negócio durante o raciocínio.
Guarda-corpos de saída: Avalie a resposta do modelo e bloqueie-o, modifique ou rejeite antes de devolvê-lo ao usuário.
Esses guarda-corpos diferem da segurança tradicional de aplicações. Controles tradicionais protegem código determinístico e entradas estruturadas como campos de formulário ou JSON. Os protetores de IA devem gerenciar sistemas não determinísticos e linguagem natural, onde a mesma solicitação pode produzir resultados diferentes a cada vez e onde o comportamento do modelo pode ser influenciado por meio de embedding de contexto ou injeção de prompts.
Para empresas – especialmente ao lidar com dados regulados ou fluxos de trabalho voltados para o cliente – as proteções são a forma de agir transformar um protótipo em um sistema de produção. Eles aplicam seus requisitos de segurança, proteção e conformidade, ao mesmo tempo em que permitem que as equipes construam sobre modelos de fundação poderosos.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Por que as proteções de IA são importantes para a segurança na nuvem
Ao implantar IA na nuvem, você combina duas propriedades desafiadoras: entradas de linguagem natural não confiáveis e Acesso a dados e sistemas sensíveis. Um modelo pode ser influenciado por texto arbitrário, mas ele roda em infraestrutura compartilhada, por trás de APIs públicas ou internas, e frequentemente com acesso a dados reais de negócios. Isso quebra muitas das suposições por trás dos controles tradicionais de segurança.
Sistemas de IA em nuvem lidam com dados sensíveis, como informações pessoais, registros financeiros ou documentos proprietários. Controles tradicionais como regras de rede e firewalls Não é possível avaliar prompts, janelas de contexto ou comportamento do modelo, para que não previnam ataques como injeção rápida, manipulação de recuperação ou uso inesperado de ferramentas. Os principais provedores de nuvem agora incluem controles de segurança em seus serviços de IA (por exemplo, Guardrails para Amazon Bedrock, filtros de conteúdo Azure OpenAI e filtros de segurança de IA Google Vertex), mas esses precisam ser combinados com políticas específicas da organização, controles de IAM e monitoramento em tempo de execução para ser eficaz.
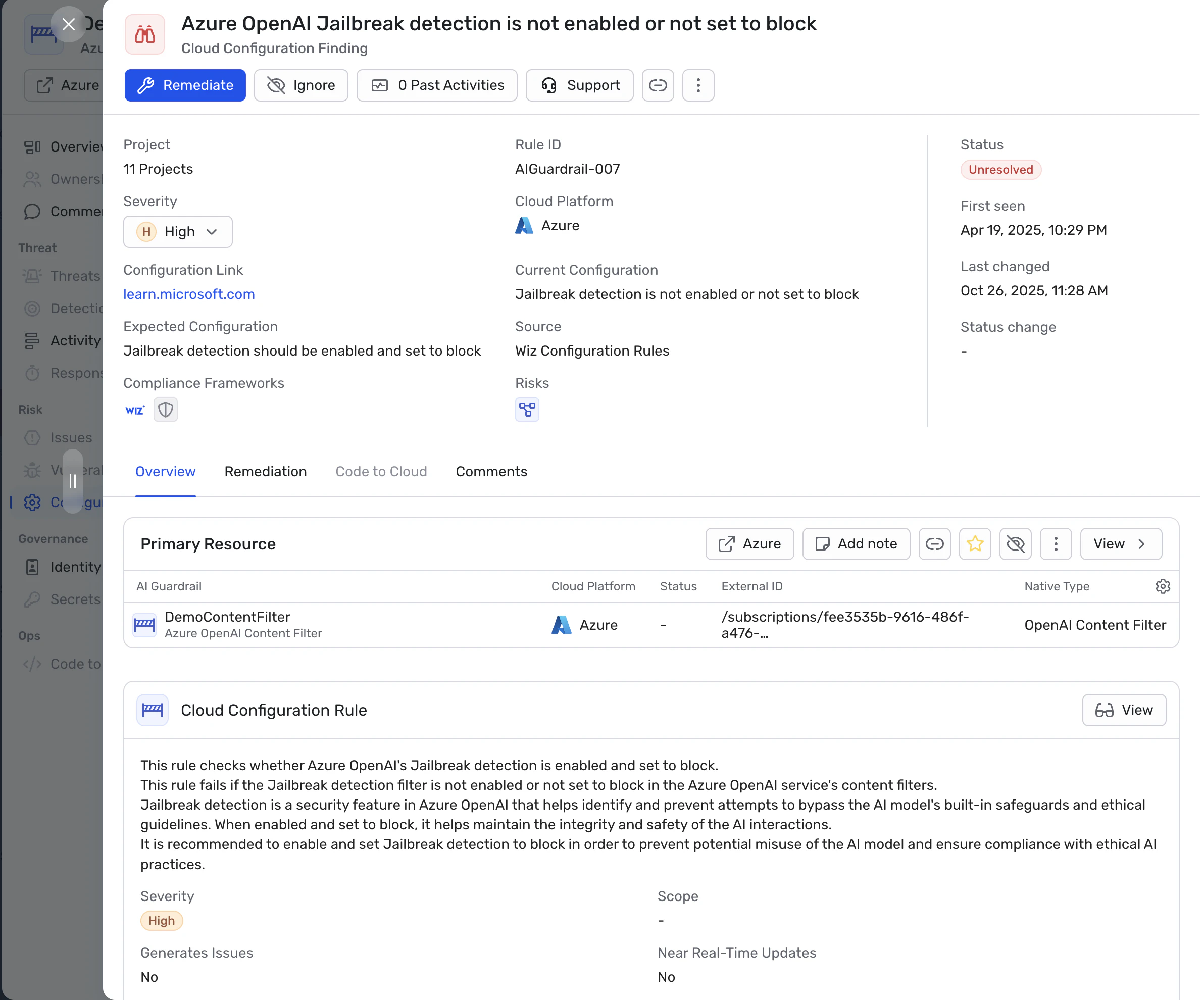
Em um ambiente de nuvem, você Superfície de ataque por IA Agora inclui:
Modelos: LLMs hospedados, modelos finamente ajustados e embeddings personalizados.
Dados de treinamento e inferência: data lakes, porta-vetores e logs que podem conter conteúdo confidencial.
Endpoints de inferência: APIs públicas e internas para chat, busca ou chamadas de ferramentas.
Agentes e orquestração: código que permite que modelos chamem ferramentas internas ou serviços externos.
Artefatos do modelo: pesos, pontos de controle e imagens de contêineres que podem ser manipulados na cadeia de suprimentos.
Sem proteções, o comportamento normal da IA pode se tornar um incidente de segurança: um ataque de injeção rápida puxa dados sensíveis de um armazenamento vetorial, um agente executa uma ação não intencional contra APIs internas, ou um endpoint mal configurado expõe informações do cliente. Essas falhas criam tanto risco de segurança quanto risco de marca, porque a saída do modelo é diretamente visível para os usuários.
Empresas em setores regulados já utilizam guarda-corpos de múltiplas camadas para manter as implantações seguras. Por exemplo, fabricantes automotivos usam assistentes baseados em nuvem com filtragem rigorosa de entrada, acesso controlado aos dados do veículo e verificações em tempo de execução sobre quais respostas podem ser retornadas aos motoristas. Isso permite que adotem modelos avançados, ao mesmo tempo em que mantém limites rigorosos de segurança e conformidade.
Tipos de guarda-rails de IA
Guarda-corpos práticos funcionam como um Oleoduto. As entradas são verificadas antes de chegarem ao modelo, o modelo roda dentro de um contexto de execução controlada, e as saídas são validadas antes de chegarem aos usuários ou aos sistemas a jusante.
1. Guarda-corpos de entrada
Os guarda-corpos de entrada avaliam e reconfiguram as solicitações recebidas Antes da inferência. Esta é a primeira camada de prevenção contra comportamentos inseguros.
Guarda-corpos de entrada comuns incluem:
Injeção rápida e detecção de fuga de jails: Identificar tentativas de sobrescrever instruções do sistema ou acessar dados restritos.
Varredura de dados sensíveis: Detecte e rediga PII, PHI, credenciais ou chaves dentro dos prompts.
Conteúdo ilegal ou proibido: Bloqueie pedidos que busquem instruções prejudiciais ou material proibido.
Controle de abuso e uso indevido: Aplicar limites de taxa, identificar usos anômalos e bloquear tentativas de força bruta contra filtros de segurança.
Na prática, os limites de entrada podem rejeitar um prompt, solicitar esclarecimento, ou higienize a entrada (por exemplo, identificadores de mascaramento) antes de enviá-lo para o modelo.
2. Guarda-corpos de processamento
Guarda-corpos de processamento moldam o contexto de execução em que o modelo opera. Eles determinam o que o modelo pode acessar e como ele pode agir, além do texto do prompt.
Os limites de proteção para processamento normalmente incluem:
Controles de contexto: Restringa quais documentos, campos ou logs podem ser fornecidos ao modelo para cada requisição.
Segurança RAG: Limite quais coleções um pipeline de recuperação pode consultar, quantos resultados pode usar e aplique filtragem ao conteúdo recuperado.
Aplicação da Política: Codificar regras de negócios como "este modelo não pode acessar APIs de pagamento em produção" ou "apenas retorne dados da mesma região."
Controles de identidade e de menor privilégio: Use políticas do IAM para restringir o acesso da conta de serviço do modelo a fontes ou serviços de dados não autorizados.
Guarda-corpos de ferramentas e agentes: Defina quais ferramentas um agente de IA pode chamar, quais ações exigem aprovação humana e como os parâmetros são validados antes da execução.
Recursos de segurança do provedor de nuvem (por exemplo, filtros de conteúdo ou filtros de tópicos no Azure OpenAI, Bedrock ou Vertex AI) podem suportar essa camada, mas devem ser combinados com
3. Guarda-corpos de saída
Guarda-corpos de saída avaliam a resposta do modelo
Guarda-corpos de saída comuns incluem:
Toxicidade e segurança de conteúdo: Detectar ódio, assédio, conteúdo de automutilação ou outras categorias proibidas.
Detecção de alucinações: Compare afirmações com fontes confiáveis ou contexto recuperado para identificar afirmações não fundamentadas.
Vazamento de dados sensíveis: Escaneie por PII, PHI, credenciais ou segredos nas saídas e remova ou bloqueie conforme necessário.
Alinhamento de marca e política: Ajustar o tom, incluir as divulgações obrigatórias e aplicar regras de conformidade em domínios regulados.
Guarda-corpos de saída podem bloquear a resposta, solicitar esclarecimento, ou
Muitas equipes combinam verificações baseadas em regras (padrões de permitir/negar, regras de redação, políticas de prompt) com classificadores baseados em ML (detecção de toxicidade, detecção de jailbreak, detecção de PII). Outros envolvem modelos de fornecedores com uma camada de segurança consistente entre provedores, usando APIs de moderação ou frameworks de proteção open-source.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Riscos de IA que as proteções são projetadas para abordar
Existem guarda-corpos de IA para evitar classes específicas de falhas. Compreender essas ameaças ajuda a projetar controles que protejam tanto seus dados quanto sua infraestrutura.
A maioria dos riscos de IA se enquadra em Quatro categorias:
1. Manipulação do comportamento do modelo
Atacantes tentam influenciar ou sobrescrever instruções do modelo para produzir ações ou saídas inseguras.
Injeção rápida: Criando entradas que sobrescrivem instruções do sistema e extraem dados ou acionam ações não permitidas.
Injeção indireta por prompt: Incorporar instruções maliciosas em documentos ou dados que o modelo posteriormente ingere por meio de recuperação ou contexto.
Fugas de Jail: Forçando o modelo a ignorar restrições de segurança embutidas usando role-playing, tradução ou outros padrões de solicitação indireta.
Prompts adversariais: Padrões sutis de prompts projetados para causar saídas incorretas sem parecer maliciosos.
Esses riscos são abordados principalmente por meio de
2. Manipulação de dados e contexto
Em vez de atacar o modelo diretamente, os adversários miram no Pipelines de dados que moldam o comportamento do modelo.
Envenenamento de dados: Injetar dados maliciosos ou tendenciosos em conjuntos de treinamento ou ajuste fino para que o modelo aprenda padrões inseguros.
Envenenamento por contexto: Manipular os documentos ou o índice de recuperação usados pelos sistemas RAG para influenciar respostas.
Intoxicação por TRAPOS: Controlar quais documentos são recuperados para que o modelo repita informações enganosas.
Sequestro de ajuste fino: Comprometer trabalhos de ajuste fino para inserir backdoors.
Essas ameaças exigem
3. Extração de informações sensíveis e propriedade intelectual
Os atacantes tentam recuperar dados do modelo ou de seus componentes de suporte.
Extração de modelos: Reproduzir o comportamento de um modelo proprietário por meio de consultas repetidas.
Inferência de membros: Determinar se registros específicos faziam parte dos dados de treinamento por meio de sondagens das respostas do modelo.
Vazamento de dados sensíveis: O modelo reproduz conteúdo memorizado de logs, dados de treinamento ou armazenamentos vetoriais.
Esses riscos são mitigados por meio de
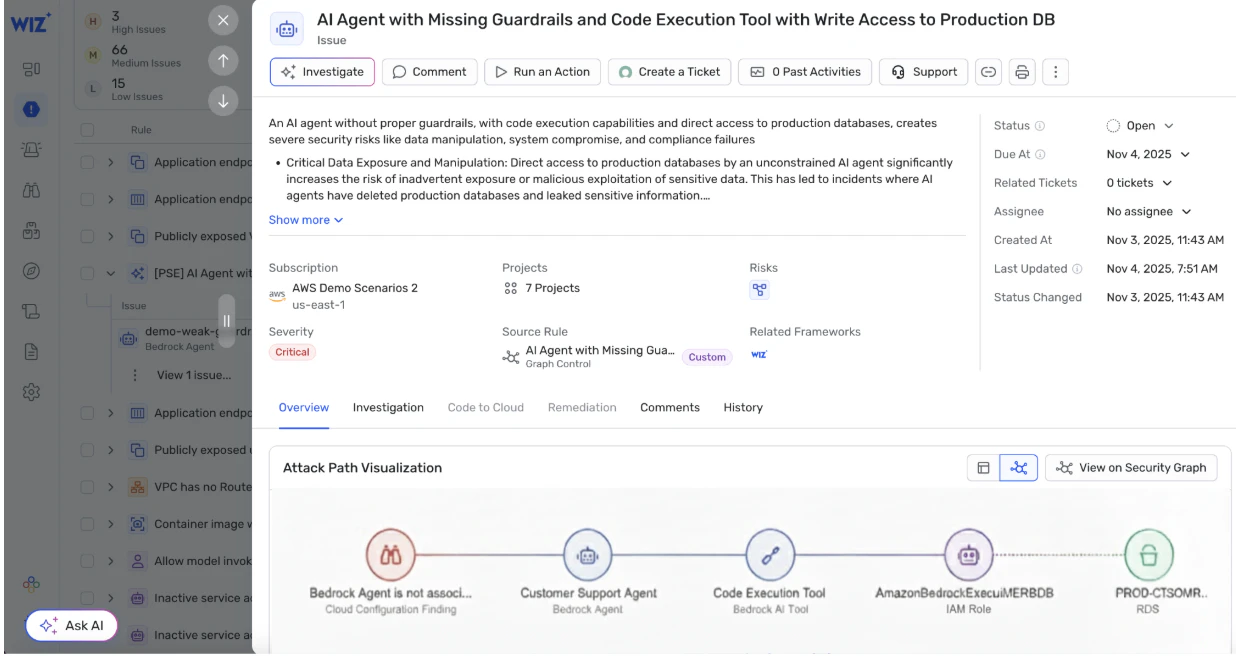
4. Explorando o acesso por meio de agentes e ferramentas
A categoria de risco que mais cresce envolve modelos que podem
Agentes com excesso de permissão: Agentes que têm amplo acesso a APIs internas, bancos de dados ou serviços em nuvem.
Abuso de ferramentas: Usar ferramentas permitidas de maneiras inesperadas, levando a operações não autorizadas.
Escalonamento de identidade: Um modelo atuando sob uma conta de serviço privilegiada sem o isolamento adequado.
Esses riscos exigem o processamento de guarda-limites (IAM de privilégio mínimo, listas de permissões de ferramentas, fluxos de trabalho de aprovação) e monitoramento em tempo de execução para detectar comportamentos inesperados.
Sample AI Security Assessment
Get a glimpse into how Wiz surfaces AI risks with AI-BOM visibility, real-world findings from the Wiz Security Graph, and a first look at AI-specific Issues and threat detection rules.
Get Sample Report

Como funcionam as proteções de IA na prática
Em um sistema real, guardrails não são um filtro único que você adiciona no final. São múltiplos controles aplicados ao longo do caminho da requisição, desde o ponto de entrada da API até a validação da saída. Cada camada remove uma classe diferente de risco.
Um comum Fluxo de inferência com guarda-corpos Parece assim:
Pedido do usuário: Um usuário envia um prompt ou chamada de API.
Guarda-corpos de entrada: A solicitação é validada, sanitizada ou rejeitada antes de chegar ao modelo.
Construção do contexto (RAG): Se for usada a recuperação, apenas fontes de dados aprovadas e documentos são buscados e filtrados.
Aplicação da Política: Regras de negócio e verificações de segurança moldam o que o modelo pode acessar e quais ferramentas ele pode usar.
Inferência de modelo: O modelo gera uma resposta dentro dessas restrições.
Execução da ferramenta (agentes): Se o modelo solicitar ações, os parâmetros são validados e executados sob privilégio mínimo, ou requerem aprovação humana.
Guarda-corpos de saída: A resposta é verificada quanto à segurança, reivindicações comprovadas, dados sensíveis e conformidade antes de ser retornada ao usuário.
Registro e monitoramento: A interação completa é registrada para análise, alerta e melhoria.
Esse padrão permite prevenir comportamentos inseguros antes que ocorram e detectar problemas que passam despercebidos.
Onde as guarda-vidas são aplicadas
Guardrails podem ser integrados em vários pontos da sua arquitetura:
API gateway: Autenticação, limitação de taxa, verificações de conteúdo grosseiro.
Camada de orquestração: Chains, middleware e validadores que implementam filtros de prompt, controles de contexto e lógica de políticas.
Serviços em nuvem: Filtros de segurança do provedor (por exemplo, filtros de toxicidade ou tópicos) que funcionam durante a inferência.
Camada de identidade: Políticas IAM que definem quais fontes de dados, APIs e ferramentas a conta de serviço do modelo pode acessar.
Limites das ferramentas: Fluxos de validação e aprovação para ações do agente.
Armazenamento vetorial: Controles de acesso e filtragem em nível de documento para evitar envenenamento do contexto ou vazamento de dados.
Filtros de saída: Modelos de classificação ou regras que bloqueiam ou reescrevem respostas inseguras.
Cada camada é projetada para eliminar uma classe diferente de risco, de modo que falhas em uma camada sejam captadas por outra.
Como o Wiz permite barreiras de proteção abrangentes em IA ao longo do ciclo de vida da segurança
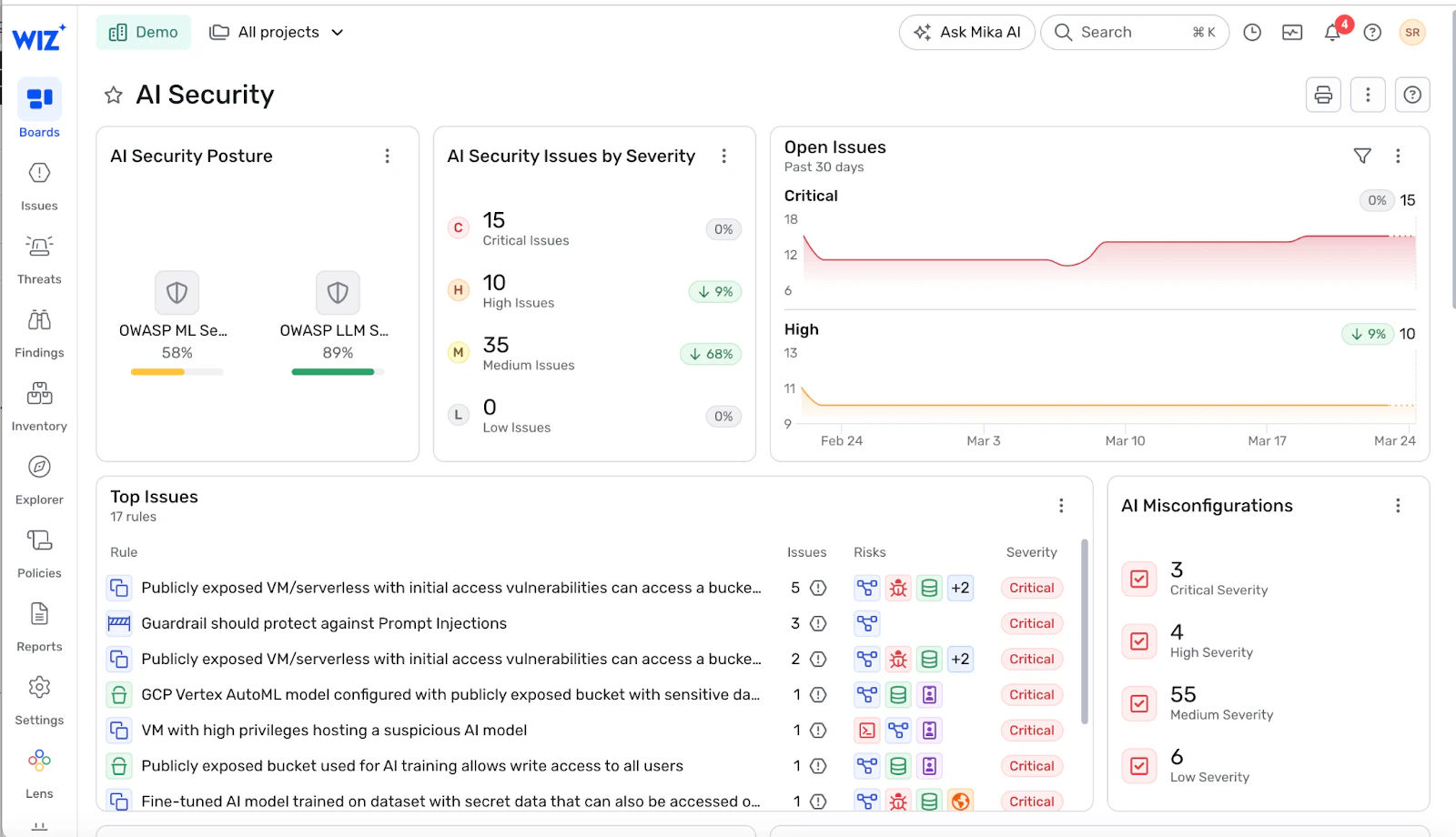
Wiz AI-SPM oferece visibilidade completa do seu patrimônio de IA na AWS, Azure e GCP – desde serviços gerenciados de IA e endpoints de inferência até pipelines de recuperação e as identidades por trás deles. O Wiz detecta configurações incorretas em plataformas como Amazon SageMaker, Azure OpenAI e Google Vertex AI que podem contornar seus limites, como endpoints públicos com acesso a dados sensíveis ou agentes rodando sob funções excessivamente autorizadas.
O Grafo de Segurança Wiz mapeia como infraestrutura, identidades, dados e cargas de trabalho de IA interagem. Isso permite identificar combinações tóxicas escondidas no ambiente – por exemplo, um endpoint exposto comunicando com um armazenamento vetorial cheio de dados sensíveis de treinamento, acessíveis por meio de uma conta de serviço ampla vinculada a um agente. Wiz destaca esses riscos para que você possa remover os caminhos de desvio que ficam sob seus guarda-corpos.
A Wiz estende esses controles ao longo do ciclo de vida do desenvolvimento e da execução. Código Wiz escaneia o IaC e o código da aplicação que define sua infraestrutura de IA para detectar problemas como chaves de modelo codificadas fixamente, regras de rede arriscadas ou serviços de IA mal configurados antes da implantação. Wiz Defend monitora cargas de trabalho relacionadas à IA em tempo de execução para padrões incomuns de API, acesso não autorizado a dados ou possíveis tentativas de exfiltração ligadas ao comportamento do modelo. Embutido DSPM As capacidades classificam dados sensíveis usados em treinamento ou inferência e mostram como eles fluem para modelos e endpoints, para que você possa construir guardas focadas em dados fundamentadas na realidade.
Como todo esse contexto está em uma única plataforma, as organizações podem aplicar políticas unificadas de segurança de IA em repositórios de código, pipelines CI/CD, recursos em nuvem e ambientes de execução. Em outras palavras, a Wiz fornece guarda-corpos para seus guarda-corpos – Garantindo que a infraestrutura, os caminhos dos dados e as identidades ao redor dos seus modelos estejam devidamente configurados, monitorados e protegidos.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
