O que são guarda-corpos de LLM?
Os guardrails de LLM são controles técnicos que restringem o comportamento de aplicações baseadas em IA em produção. Em vez de modificar o modelo em si, os guardrails envolvem o modelo com políticas que regem o que ele pode ver, dizer e fazer em cada solicitação.
Os guarda-corpos operam no momento da inferência e são aplicados pela aplicação e sua infraestrutura ao redor. Eles validam entradas antes que os prompts cheguem ao modelo, inspecionam as saídas antes que as respostas cheguem aos usuários e controlam estritamente o acesso a ferramentas, APIs, fontes de dados e recursos em nuvem.
É importante distinguir os guarda-corpos de outros mecanismos de segurança relacionados:
Alinhamento do modelo (tempo de treinamento): Técnicas de alinhamento, como aprendizado por reforço a partir de feedback humano (RLHF), moldam o comportamento básico de um modelo durante o treinamento. Isso melhora a segurança e utilidade geral, mas é estático e não está ciente do contexto ou das políticas da sua aplicação.
Filtros de conteúdo do provedor (nível de serviço): Provedores de nuvem oferecem filtros integrados (por exemplo, filtragem de conteúdo Azure OpenAI ou Amazon Bedrock Guardrails) que bloqueiam categorias amplas de conteúdo, como discurso de ódio ou violência. Esses operam na camada API e são intencionalmente genéricos.
Guarda-corpos de LLM (nível de aplicação): Guardrails são controles que você projeta e configura para impor seu Regras de segurança e negócios. Elas podem variar conforme o usuário, função, ambiente ou caso de uso, e evoluem conforme sua aplicação muda.
25 agentes de IA. 257 ataques reais. Quem vence?
Desde a descoberta zero-day até a escalação de privilégios na nuvem, testamos 25 combinações agente-modelo em 257 desafios reais de segurança ofensiva. Os resultados podem te 👀 surpreender

Essas camadas são complementares. Alinhamento fornece segurança básica, filtros de provedores bloqueiam conteúdos nocivos comuns e guarda-corpos aplicam controles de segurança e acesso específicos da aplicação.
Na prática, os guardrails de LLM funcionam como segurança na camada de aplicação para sistemas de IA. Eles aplicam a inferência de modelos antes e depois da política e garantem que o modelo opere dentro dos limites definidos pelas suas identidades, regras de governança de dados e permissões na nuvem.
Mesmo LLMs gerenciados ou "seguros" exigem proteções. Um modelo bem alinhado ainda pode ser manipulado por meio de Injeção Rápida ou expostos a permissões excessivas por meio de identidades mal configuradas. Portanto, os guardrails eficazes devem ser em camadas, conscientes do contexto e integrados de forma estreita ao ambiente de nuvem ao redor.
Por que os guardrails de LLM são críticos para a segurança de aplicações
Em aplicações modernas, LLMs não são mais interfaces de chat isoladas. Eles são incorporados diretamente à lógica da aplicação, onde interpretam a entrada do usuário, recuperam dados, invocam ferramentas e acionam ações posteriores. Como resultado, fraquezas no comportamento dos LLMs rapidamente se tornam riscos de segurança para aplicações.
Um dos riscos mais visíveis é a injeção rápida. Atacantes podem manipular entradas para sobrescrever instruções do sistema ou extrair comportamentos não intencionais do modelo. Pesquisa mostra que as taxas de sucesso variam amplamente dependendo da arquitetura do modelo, técnicas de defesa e complexidade de ataque, o que torna estatísticas gerais menos úteis na prática. O que importa é o quão bem seus guarda-corpos específicos resistem a ataques realistas e de múltiplas etapas no seu ambiente.
Vazamento de dados é outra grande preocupação. LLMs frequentemente têm acesso a bases de conhecimento internas, fontes de geração aumentadas por recuperação ou dados operacionais sensíveis. Sem controles fortes de saída, um modelo pode expor informações que nunca deveriam sair do sistema. Uma pergunta simples como "O que você sabe sobre nossos sistemas internos?" pode levar a uma divulgação não intencional se as barreiras forem fracas ou mal estruturadas.
A chamada de ferramentas e a execução de funções aumentam significativamente a pressão. Quando um LLM pode acionar chamadas de API, modificar registros ou interagir com recursos em nuvem, um ataque bem-sucedido pode resultar em impacto no mundo real. Se a identidade do serviço subjacente for superprivilegiada, um agente comprometido pode acessar muito mais do que o pretendido. Aplicar permissões de privilégio mínimo limita o raio de explosão por padrão, de modo que até mesmo agentes abusados não possam causar danos desproporcionais.
Também é importante separar questões de confiabilidade de questões de segurança. Alucinações são um problema de confiabilidade em que o modelo produz informações incorretas. Ações não autorizadas, exposição de dados e abuso de privilégios são problemas de segurança que as proteções são projetadas para prevenir. Tratar esses riscos como o mesmo leva a controles mal colocados e falsa confiança.
No fim das contas, as proteções dos LLMs são importantes porque os sistemas de IA agora estão em limites críticos de confiança. Eles traduzem entradas não confiáveis em ações confiáveis. Sem fortes e estratificadas barreiras de segurança ligadas à identidade, acesso a dados e permissões na nuvem, as aplicações de IA expandem a superfície de ataque em vez de controlá-la.
Onde os guarda-corpos de LLM se encaixam em uma pilha moderna de aplicações de IA
Os limites dos LLMs abrangem toda a pilha de aplicações de IA, em vez de viver em um único ponto de controle. Para entender como eles funcionam juntos, é útil visualizar os limites de proteção em cinco camadas: aplicação, API, identidade, dados e runtime e infraestrutura.
No Camada de aplicação, os guarda-corpos moldam como os prompts e respostas são tratados. A validação de entrada verifica os prompts do usuário em busca de padrões maliciosos, enquanto políticas de resposta garantem que as saídas sigam regras de formatação, segurança e divulgação. Muitas equipes começam aqui com controles em nível de prompt, mas eles abordam apenas uma fatia restrita do risco total.
O Camada API governa como as aplicações interagem com os serviços de LLM. Os limites de proteção nesse nível incluem autenticação, autorização baseada em funções, limitação de taxa e limites de uso de tokens. Esses são controles de segurança web familiares, mas se tornam especialmente importantes para endpoints de IA, onde uma única requisição pode consumir grandes recursos ou acionar ações posteriores.
O Camada de identidade foca nas contas de serviço e funções que os componentes baseados em LLM usam para acessar recursos em nuvem. As proteções de identidade impõem acesso de privilégios mínimos para que agentes de IA só possam realizar ações que possam explicitamente realizar. Quando as permissões de identidade são muito amplas, as proteções em nível de aplicação perdem sua eficácia.
O Camada de dados controla quais conjuntos de dados, embeddings e fontes de recuperação um LLM pode acessar. Os guarda-corpos de dados definem quais modelos podem ler quais dados, como informações sensíveis são tratadas e como a recuperação é definida por usuário ou função. Esses controles são críticos para evitar a exposição não intencional de dados por meio de pipelines de treinamento ou geração aumentada por recuperação.
O Runtime e camada de infraestrutura abrange os ambientes onde serviços de IA rodam, incluindo containers, serviços gerenciados de LLM e limites de rede. Os limites dessa camada incluem isolamento de rede, segmentação de carga de trabalho e detecção de comportamentos anômalos em tempo de execução. Esses controles ajudam a capturar ataques reais que contornam testes anteriores.
Na prática, a propriedade dessas camadas é dividida entre as equipes. Equipes de aplicação gerenciam prompts e lógica, equipes de plataforma gerenciam APIs e identidades, e equipes de segurança em nuvem gerenciam a infraestrutura. Os guarda-corpos de LLM exigem coordenação entre todos eles. Defesa em profundidade só funciona quando os controles entre camadas estão alinhados e aplicados de forma consistente.
Folha de dicas sobre as melhores práticas de segurança GenAI
Esta folha de dicas fornece uma visão geral prática das 7 melhores práticas que você pode adotar para começar a fortalecer a postura de segurança GenAI da sua organização.

Tipos centrais de protetores de LLMs (e o que eles realmente protegem)
A maioria dos guarda-corpos de LLM se enquadra em um pequeno número de categorias. Cada uma protege uma parte diferente do sistema, e cada uma possui limites claros. Compreender esses limites é fundamental, pois nenhuma barreira de proteção isolada pode parar cada ataque sozinha.
Guarda-corpos de entrada
Os guarda-corpos de entrada ficam entre o usuário e o modelo. O objetivo deles é detectar e bloquear prompts maliciosos ou inseguros antes que cheguem ao LLM. Técnicas comuns incluem correspondência de padrões, classificação por prompts e aplicação de limites de instruções.
Guarda-corpos de entrada podem impedir ataques óbvios, mas são fáceis de contornar com codificação, frases indiretas ou conversas com múltiplas voltas. Como resultado, eles devem ser tratados como um filtro inicial e não como uma linha principal de defesa.
Guarda-corpos de saída
Os guarda-corpos de saída inspecionam as respostas do modelo antes de serem devolvidas aos usuários. Eles aplicam regras como remoção de dados sensíveis, bloqueio de tópicos proibidos ou exigência de formatos de saída estruturados.
Esses controles ajudam a reduzir vazamentos acidentais de dados, mas dependem da precisão da detecção. Técnicas inovadoras de ataque ou exposição sutil de dados podem passar despercebidas, especialmente quando as saídas são longas ou geradas dinamicamente.
Guarda-corpos de ferramentas e funções
Guarda-corpos de ferramentas e funções controlam quais ações um LLM pode tomar quando pode chamar APIs externas ou executar código. É aí que o risco de IA passa do teórico para o operacional.
Controles eficazes incluem:
Listas de permitidores de ação por função
Defina quais ferramentas cada função pode invocar. O LLM de um agente de suporte pode buscar documentação ou criar chamados, mas nunca deve modificar registros de faturamento ou excluir contas.Verificações de políticas pré-execução
Valide cada chamada de ferramenta antes da execução. Confirme que o usuário tem permissão, que a ação é permitida no contexto atual e que a solicitação não viola regras de negócio ou limites de taxa.Aprovação humana para ações de alto risco
Exigir confirmação humana explícita para operações destrutivas ou sensíveis, como exclusão de dados, transações financeiras ou mudanças de privilégios.Escopo e fiscalização de privilégios
Garanta que as chamadas de ferramenta não possam exceder as permissões da identidade do serviço subjacente. Se o LLM roda sob uma identidade somente leitura, ele não deve ser capaz de acionar operações de escrita, mesmo que o modelo as sugira.Controles de fronteira multiagente
Quando múltiplos agentes interagirem, imponha limites rígidos entre eles. Um agente voltado para o cliente não deve invocar diretamente ferramentas administrativas pertencentes a outro agente sem autorização e validação explícitas.
Os guarda-corpos de ferramentas reduzem o risco de abuso, mas falham quando as identidades dos serviços são excessivamente privilegiadas. Isso torna os controles de identidade tão importantes quanto a lógica de aplicação.
Protetores de identidade e permissão
Proteções de identidade governam os papéis na nuvem e as contas de serviço usadas pelos componentes alimentados por LLM. O objetivo deles é garantir o acesso de privilégio mínimo para que os serviços de IA só possam alcançar os recursos de que realmente precisam.
Esses corrimãos limitam o raio de explosão quando algo dá errado, mas frequentemente são mal configurados em ambientes reais. Permissões excessivas podem minar silenciosamente até controles bem projetados em nível de aplicação.
Guarda-corpos de acesso a dados
Guarda-corpos de dados controlam quais conjuntos de dados, embeddings e fontes de recuperação um modelo pode acessar. Eles impedem que informações sensíveis sejam inseridas em prompts ou respostas sem a devida autorização.
Esses controles dependem de classificação precisa de dados e políticas de acesso. Se os dados forem rotulados incorretamente ou as regras de acesso forem muito amplas, as proteções perdem eficácia.
Guarda-corpos de tempo de execução
Os limites de segurança em tempo de execução monitoram o que realmente acontece em produção. Eles analisam o comportamento em chamadas de API, atividade de identidade e telemetria em nuvem para detectar anomalias e uso indevido.
Detecção em tempo de execução ajuda a detectar bypasses que passam por controles anteriores, mas requer linhas de base e ajustes para reduzir falsos positivos. Quando combinados com o contexto sobre permissões de identidade e sensibilidade dos dados, os sinais em tempo de execução tornam-se muito mais acionáveis.
Melhores Práticas de Segurança em LLM [Guia de Dica]
Esta lista de verificação de 7 páginas oferece etapas práticas e prontas para implementação para orientá-lo na proteção de LLMs em todo o seu ciclo de vida, mapeados para ameaças do mundo real.

Implementando protetores de LLM em ambientes de nuvem
Passar de um protótipo para uma aplicação de IA de produção aumenta significativamente a complexidade da implementação de guardrails. Onde e como os modelos rodam na nuvem afetam diretamente a eficácia desses controles.
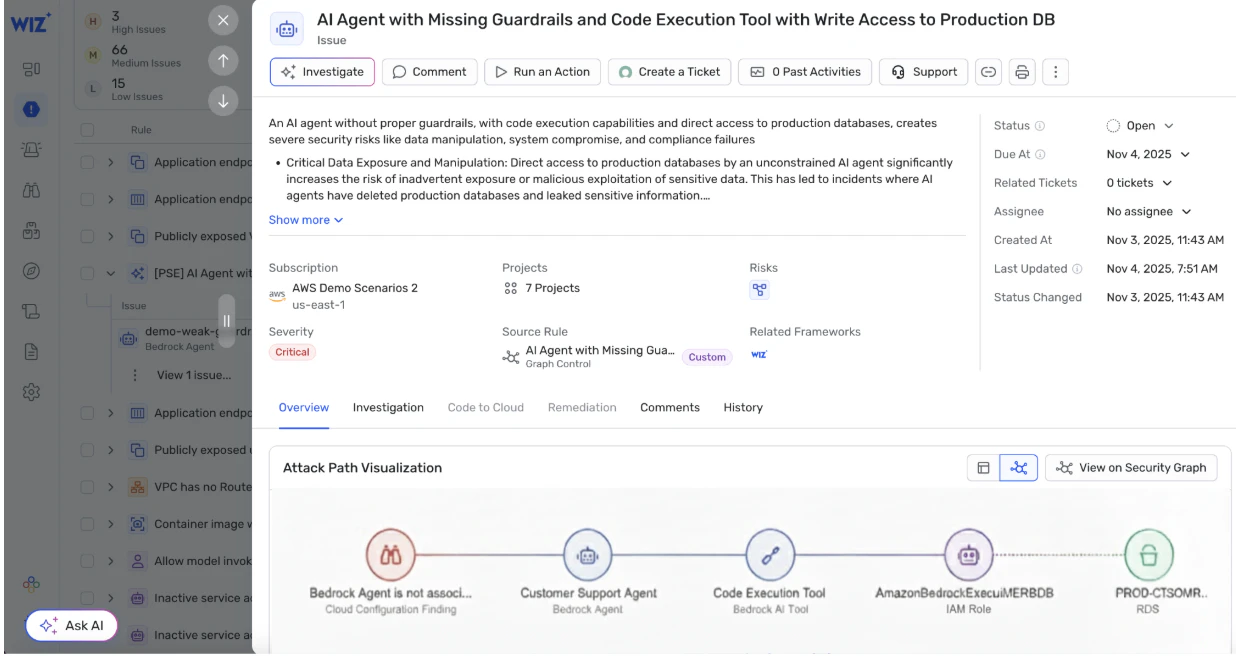
Serviços gerenciados de LLM fornecem proteções básicas úteis, mas não eliminam a necessidade de controles de segurança em nível de aplicação e nuvem. O Azure OpenAI suporta isolamento de rede por meio de Azure Private Link usando Private Endpoints, junto com identidades gerenciadas para autenticação. A Amazon Bedrock oferece proteções embutidas que vão além do filtro básico de conteúdo, incluindo tópicos negados, verificações contextuais de aterramento e detecção de alucinações usando raciocínio automatizado. O Google Vertex AI oferece filtros de segurança de conteúdo e se integra com os Controles de Serviço VPC para restringir a exfiltração de dados.
Guia de Melhores Práticas de Segurança em Vertex AI
Explore a Página de Dicas de Melhores Práticas de Segurança da Vertex AI, um guia prático para proteger cargas de trabalho de IA com recomendações claras, controles reais e passos práticos que você pode aplicar imediatamente.

Essas funcionalidades gerenciadas reduzem certas classes de risco, mas decisões críticas permanecem responsabilidade do cliente. As equipes ainda controlam a exposição da rede, permissões de identidade, políticas de acesso a dados e configurações de registro. Controles nativos em nuvem são seguros Como O serviço é acessado, mas eles não abordam totalmente Como o modelo se comporta dentro de uma aplicação. Riscos como injeção rápida, uso indevido de ferramentas e abuso lógico ainda precisam ser tratados na camada de aplicação por meio de protetores personalizados.
Isso cria um Modelo de responsabilidade compartilhada entre o provedor de nuvem e o dono da aplicação. Os provedores protegem a plataforma subjacente e oferecem proteções básicas, enquanto os clientes são responsáveis por aplicar políticas específicas do negócio, acesso de privilégios mínimos e proteções contextuais.
Ambientes de nuvem multi-inquilino e compartilhados introduzem riscos adicionais. Uma única VPC mal configurada, um endpoint de IA acessível publicamente ou um papel IAM excessivamente amplo pode enfraquecer silenciosamente os limites de proteção em nível de aplicação sem qualquer alteração na lógica do modelo.
Configurações incorretas na nuvem são um ponto comum de falha. Quando serviços de IA são expostos à internet ou operam sob identidades altamente privilegiadas, os atacantes podem contornar completamente a validação por prompt e os controles de ferramentas ao abusando das APIs de nuvem subjacentes. Nesses cenários, os guarda-corpos podem parecer eficazes durante os testes, oferecendo pouca proteção real na produção.
O desvio do guardrail é outro desafio. Controles existentes em ambientes de desenvolvimento ou staging podem ser enfraquecidos ou removidos em produção devido a mudanças emergenciais, novos pipelines ou atualizações de infraestrutura. Com o tempo, essa deriva cria lacunas que os atacantes podem explorar.
Manter guardas eficazes exige validação contínua ao longo de todo o ciclo de vida. Os controles devem ser aplicados consistentemente desde o desenvolvimento até a implantação e o tempo de execução. Integrar verificações de guardrail em pipelines de CI e CD ajuda a detectar configurações erradas antes que cheguem à produção.
A defesa em profundidade só funciona quando as proteções da camada de aplicação, permissões de identidade, políticas de acesso a dados e controles de infraestrutura permanecem alinhados à medida que os sistemas evoluem. Reforço das proteções nativas das nuvens Segurança de IA, mas não substituem a necessidade de guarda-corpos robustos e específicos para aplicação que abordem diretamente o comportamento do modelo.


Por que as proteções de LLMs falham e como os atacantes as contornam
Mesmo implantações bem-intencionadas de guarda-rail frequentemente falham sob pressão real. Entender como os atacantes contornam os controles é essencial para projetar guarda-corpos que se sustentem na produção.
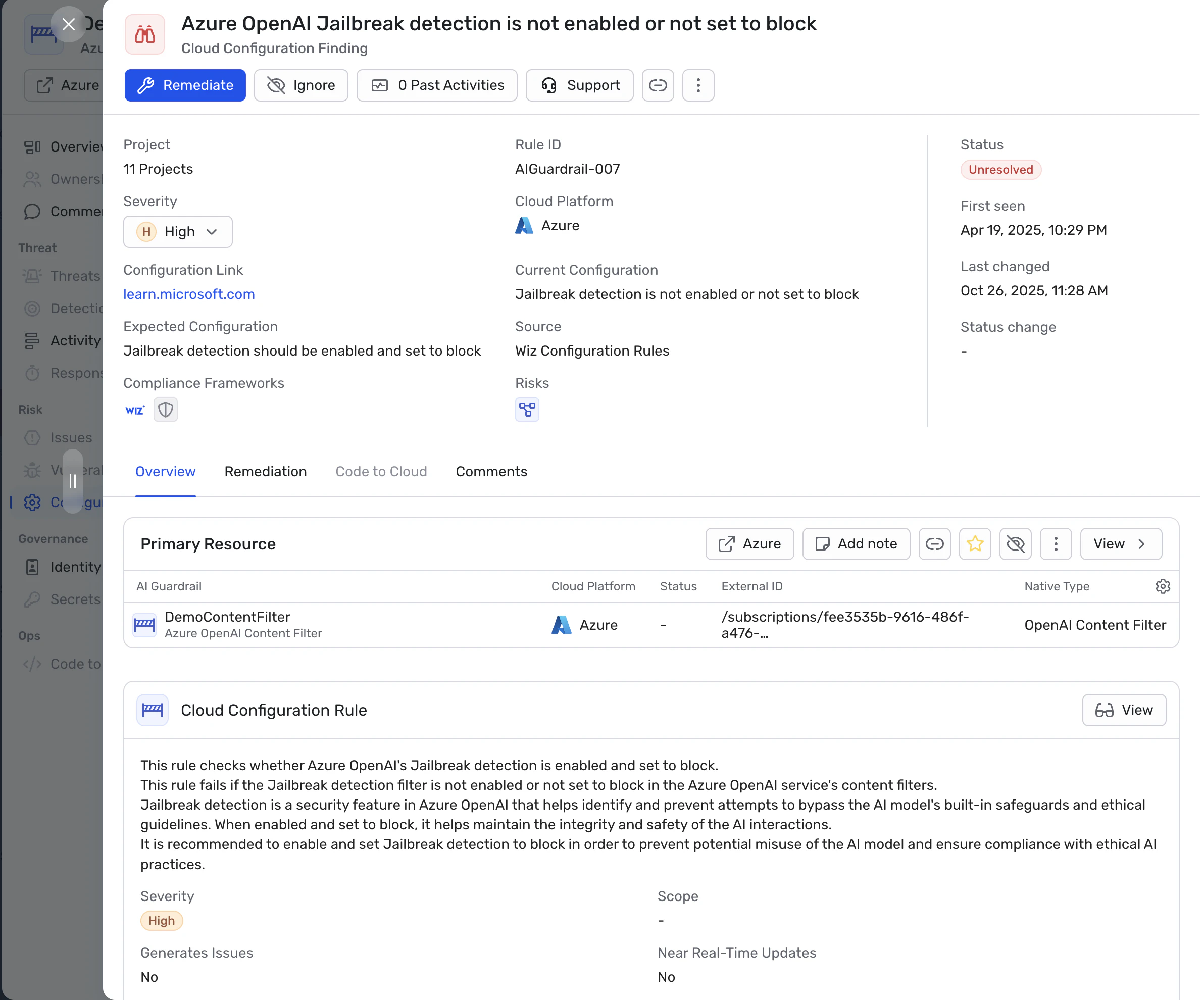
A injeção rápida continua sendo a fraqueza mais visível. Atacantes raramente dependem de um único prompt malicioso. Em vez disso, eles usam interações com múltiplos turnos, manipulação de papéis e instruções indiretas que gradualmente sobrepõem a intenção do sistema. Guarda-corpos que avaliam apenas prompts individuais frequentemente deixam passar esses padrões, permitindo que comportamentos prejudiciais surjam com o tempo.
Campanhas reais de malware começaram a explorar como incorporar prompts em cargas maliciosas para impulsionar o comportamento em tempo de execução. Por exemplo, o Abraço Lame Malware enviava prompts codificados em base64 para um LLM pedindo comandos de reconhecimento do sistema, tentando coletar informações sobre o host infectado. Nesses casos, o modelo não interagia com um usuário, mas era invocado dentro de um ambiente comprometido, contornando efetivamente os limites de entrada voltados para o usuário.
A dependência excessiva do filtro de saída é outra falha comum. Filtros que escaneiam respostas para conteúdo proibido podem ser contornados por meio de codificação, ofuscação ou acionando ações prejudiciais sem produzir texto obviamente perigoso. Em muitos casos, os resultados mais prejudiciais ocorrem quando o modelo executa uma ação com sucesso, em vez de gerar linguagem problemática.
O abuso de ferramentas e funções é mais sutil, mas frequentemente mais perigoso. No Compromisso da Extensão para Desenvolvedores do Amazon Q, os atacantes inseriram prompts que instruíam explicitamente um agente de IA a excluir todos os arquivos e recursos em nuvem acessíveis a ele. Embora o ataque não tenha tido sucesso, ele ilustra como atores maliciosos estão experimentando técnicas de desvio de guardrail que aproveitam chamadas de ferramentas e contextos de execução externa.
Permissões de identidade excessivas frequentemente prejudicam limites que normalmente seriam sólidos. Se um LLM opera sob uma identidade de serviço com permissões amplas na nuvem, um atacante que ganha influência sobre o modelo pode contornar os controles da aplicação e interagir diretamente com APIs da nuvem. Nesses casos, proteções rápidas oferecem pouca proteção porque a verdadeira fraqueza está no gerenciamento de identidade e acesso.
O desvio entre ambientes é outro problema recorrente. Controles cuidadosamente implementados em ambientes de desenvolvimento ou staging frequentemente são enfraquecidos em produção devido a correções emergenciais, novas integrações ou mudanças não documentadas. Isso cria pontos cegos que os atacantes podem explorar muito depois das revisões iniciais de segurança serem concluídas.
A exposição em nível de infraestrutura pode contornar completamente os limites da aplicação. Para modelos auto-hospedados, instâncias de computação acessíveis publicamente podem expor serviços de metadados ou fontes de credenciais, permitindo que atacantes extraiam dados sensíveis e escalem privilégios. Para serviços de IA gerenciada, endpoints públicos mal configurados ou controles de rede fracos permitem a rede direta Abuso de API Sem nunca tocar na camada de aplicação.
Nesses cenários, surge um padrão consistente. Guarda-corpos são necessários, mas não são suficientes por si só. Padrões reais de uso indevido, como os observados em campanhas recentes de malware envolvendo cargas úteis que invocam IA, mostram que atacantes já estão experimentando maneiras de evitar defesas centradas em prompts. Sem reforço dos controles de segurança nativos da nuvem que regem identidade, acesso a dados e exposição à infraestrutura, as proteções criam uma falsa sensação de segurança em vez de proteção real.
Como o Wiz ajuda a proteger aplicações de IA além dos limites de proteção
Os protetores de LLMs definem como são as aplicações de IA Suponho para se comportar, mas não garantem que esses controles funcionem em ambientes reais de nuvem, onde ameaças interagem com identidades, dados e infraestrutura. Wiz reforça as barreiras de proteção ao proteger toda a superfície de ataque da IA por meio de visibilidade contínua, avaliação de risco e defesa rica em contexto.
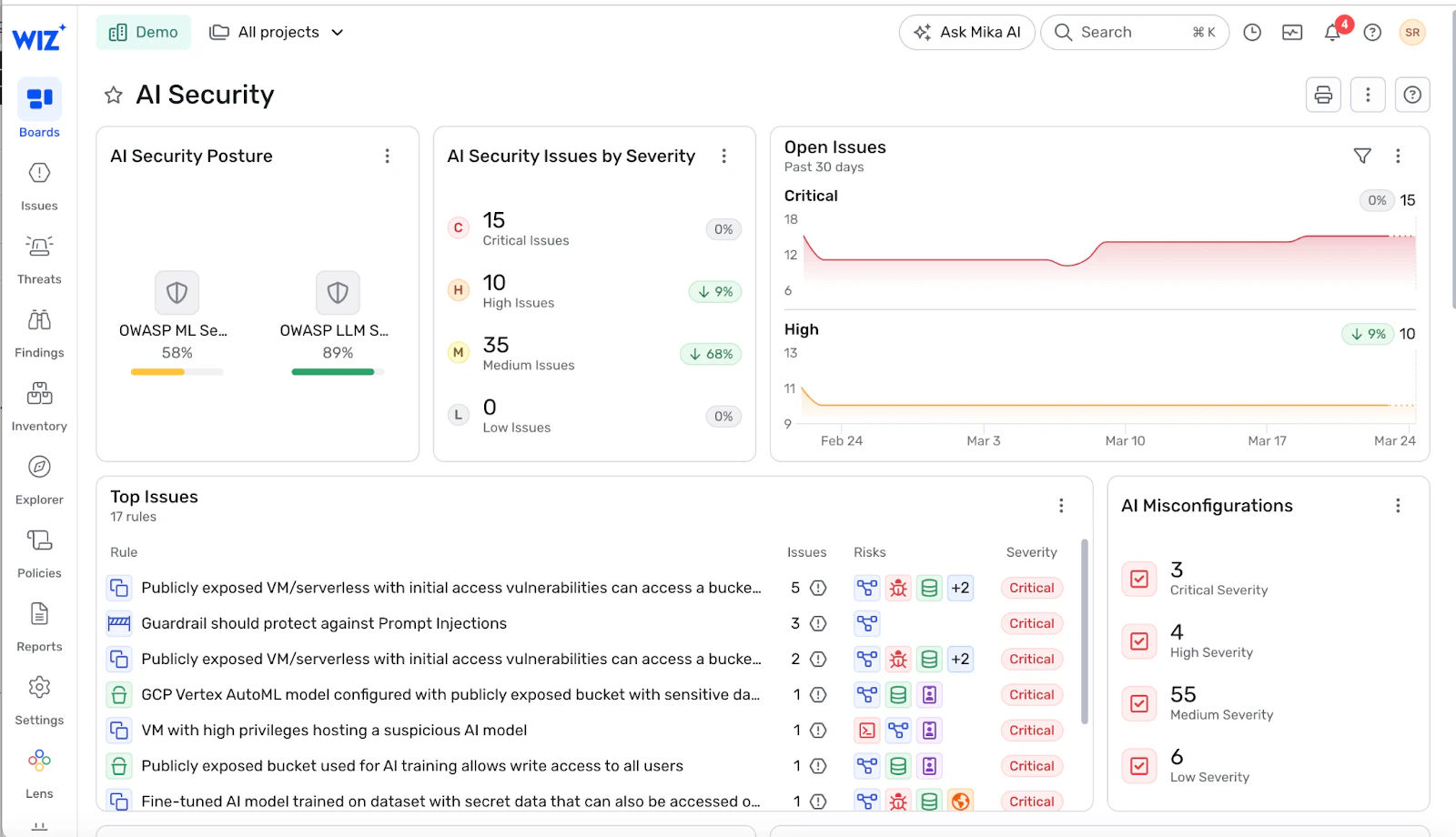
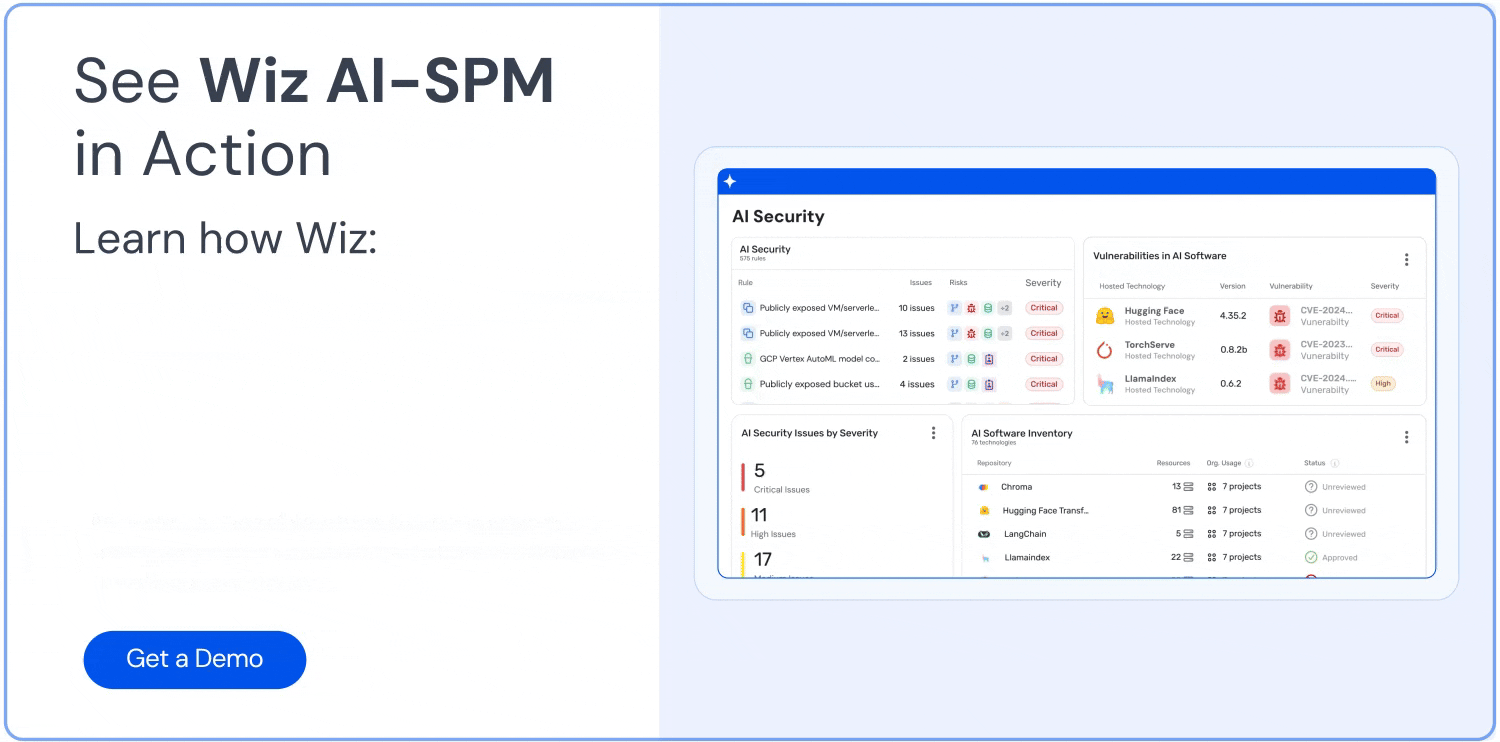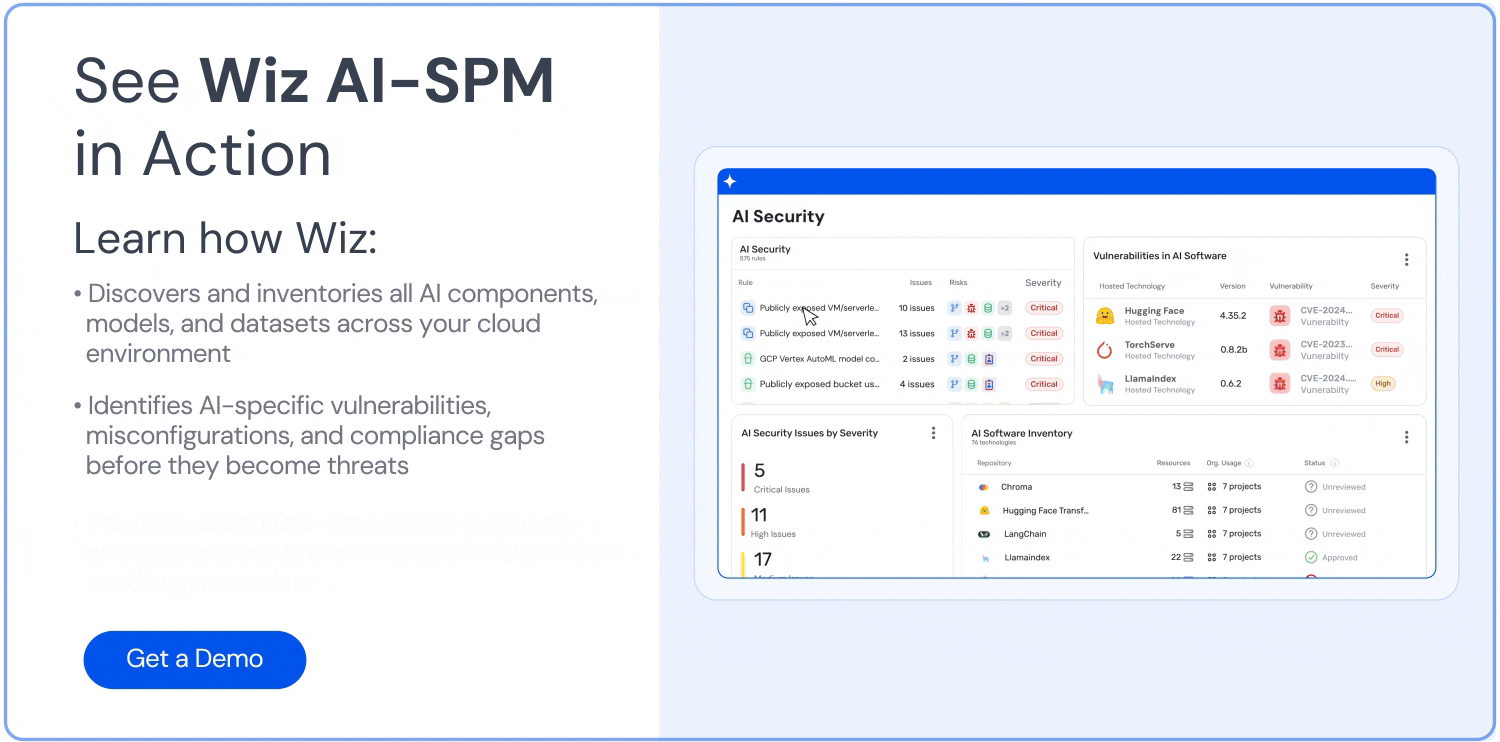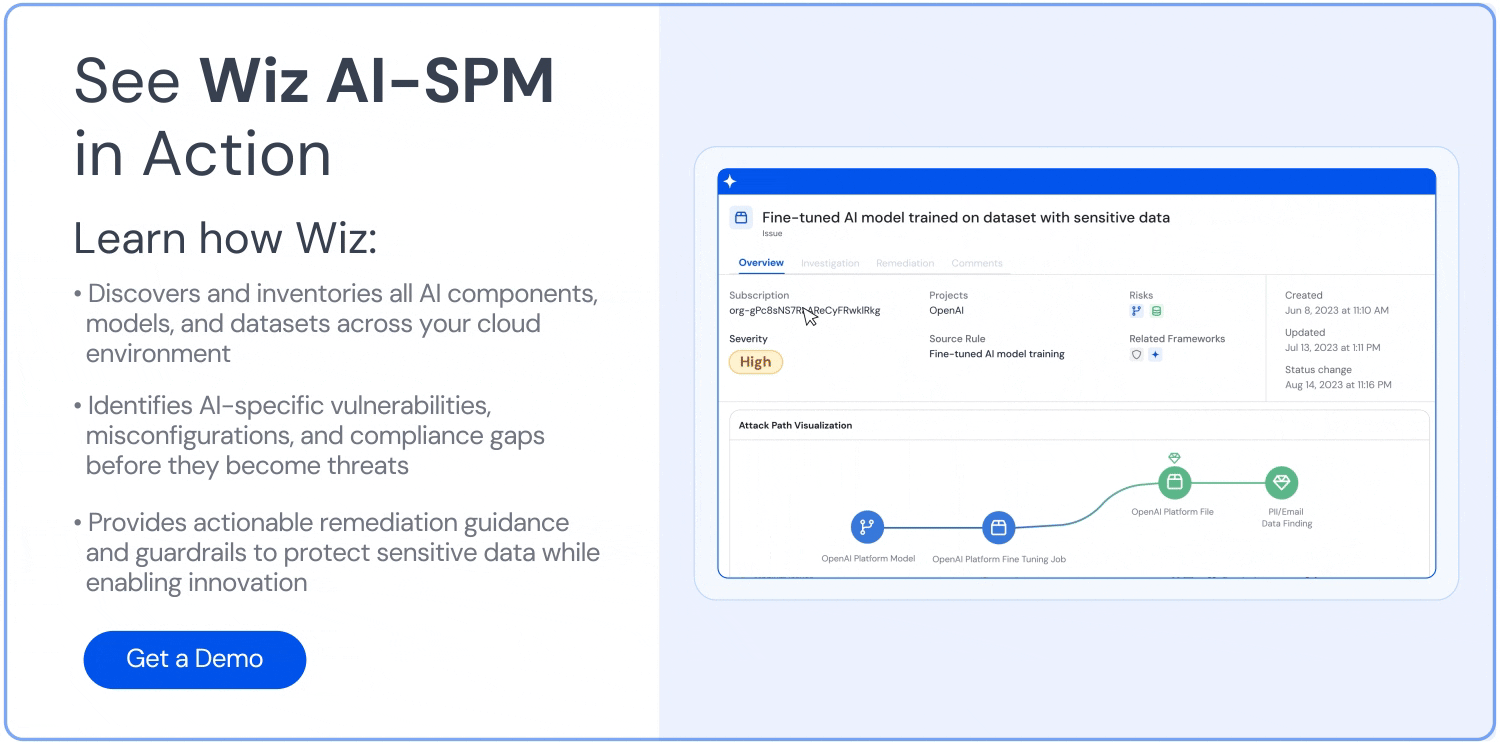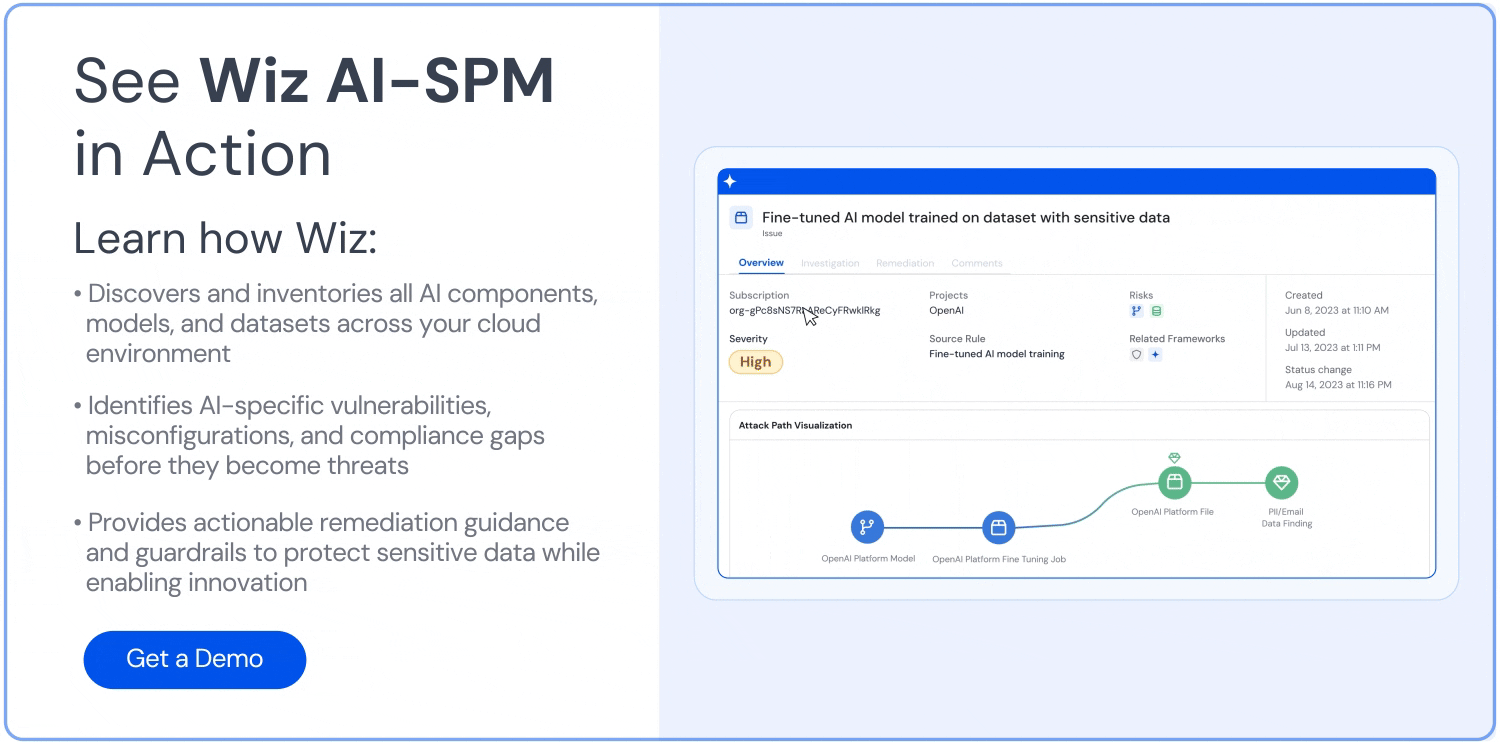
Wiz's Gestão da Postura de Segurança em IA (IA-SPM) estende seu agente sem agente CNAPP fundação para inventariar todos os agentes, modelos, endpoints e serviços relacionados de IA em nuvem e SaaS. Isso inclui um Lista de materiais de IA e um Visualização do inventário do agente Isso revela onde os agentes operam, qual acesso têm e como se conectam a cargas de trabalho e dados sensíveis. Também mapeia exposições a identidades e recursos reais da nuvem usando o Wiz Security Graph, para que as equipes possam ver não apenas o que existe, mas o que importa.
A plataforma valida continuamente configurações seguras em serviços de IA como Azure OpenAI, Amazon Bedrock e Google Vertex AI, incluindo verificação de proteções de provedores, políticas de identidade e controles de dados sensíveis. Isso ajuda a detectar configurações incorretas e proteções ausentes que, de outra forma, enfraqueceriam os limites de proteção das aplicações em produção.
Por fim, o Wiz correlaciona atividade em tempo de execução e sinais de ameaça com o contexto da nuvem para detectar comportamentos suspeitos de agentes, rastrear caminhos potenciais de ataque e automatizar ações de resposta. Ao relacionar isso com permissões de identidade, sensibilidade de dados e exposição à infraestrutura, as equipes podem priorizar a remediação com base na explorabilidade real, e não em lacunas teóricas.