

Was sind KI-Leitplanken?
KI-Leitplanken (auch LLM-Leitplanken oder GenAI-Leitplanken genannt) sind Präventive Sicherheitskontrollen die das Verhalten eines KI-Systems innerhalb definierter Richtliniengrenzen einschränken. Sie prägen, was ein Modell sehen, tun und zurückgeben kann, und verringern das Risiko schädlicher, voreingenommener oder richtlinienverstoßender Ergebnisse während der Modellausführung.
Leitplanken sind Präventive Maßnahmen Angewandt vor und während der Inferenz. Sie arbeiten Seite an Seite Detektivsteuerung wie Protokollierung, Überwachung und Warnungen, die Verstöße nach Erfolgen identifizieren, und Governance-Kontrollen wie Richtlinien, Dokumentationen und Prüfungsanforderungen.
In der Praxis werden drei Schutzplankenlagen zusammen verwendet:
Eingabe-Leitplanken: Filtere, validiere und forme Prompts um, bevor sie das Modell erreichen.
Bearbeitung von Leitplanken: Kontrollieren Sie, auf welche Kontexte, Daten und Werkzeuge das Modell Zugriff hat, und setzen Sie Geschäftsregeln während des Schlussfolgerns durch.
Ausgangsleitplanken: Bewerten Sie die Antwort des Modells und blockieren, verändern oder ablehnen Sie es, bevor Sie es an den Nutzer zurückgeben.
Diese Leitplanken unterscheiden sich von der traditionellen Anwendungssicherheit. Traditionelle Steuerungen schützen deterministischen Code und strukturierte Eingaben wie Formularfelder oder JSON. KI-Leitplanken müssen nichtdeterministische Systeme und natürliche Sprache verwalten, bei denen dieselbe Anfrage jedes Mal unterschiedliche Ausgaben liefern kann und das Modellverhalten durch Einbettung von Kontext oder Prompt-Injection beeinflusst werden kann.
Für Unternehmen – insbesondere beim Umgang mit regulierten Daten oder kundenorientierten Arbeitsabläufen – sind Leitplanken der Weg, wie man arbeitet Einen Prototyp in ein Produktionssystem umwandeln. Sie setzen Ihre Sicherheits-, Schutz- und Compliance-Anforderungen durch und ermöglichen es den Teams, auf leistungsstarken Grundlagenmodellen aufzubauen.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Warum KI-Leitplanken für Cloud-Sicherheit wichtig sind
Wenn Sie KI in der Cloud einsetzen, kombinieren Sie zwei herausfordernde Eigenschaften: unvertrauenswürdige natürliche Spracheingaben und Zugang zu sensiblen Daten und Systemen. Ein Modell kann durch beliebigen Text beeinflusst werden, läuft jedoch auf gemeinsamer Infrastruktur, hinter öffentlichen oder internen APIs und oft mit Zugang zu echten Geschäftsdaten. Das widerlegt viele der Annahmen hinter traditionellen Sicherheitsmaßnahmen.
Cloud-KI-Systeme verarbeiten sensible Daten wie persönliche Informationen, Finanzunterlagen oder proprietäre Dokumente. Traditionelle Kontrollen wie Netzwerkregeln und Firewalls Eingabeaufforderungen, Kontextfenster oder Modellverhalten kann nicht evaluiert werden, sodass sie keine Angriffe wie prompte Injektion, Rückholmanipulation oder unerwartete Werkzeugnutzung verhindern. Große Cloud-Anbieter integrieren inzwischen Sicherheitskontrollen in ihre KI-Dienste (z. B. Guardrails für Amazon Bedrock, Azure OpenAI-Inhaltsfilter und Google Vertex AI-Sicherheitsfilter), aber diese müssen mit kombiniert werden organisationsspezifische Richtlinien, IAM-Kontrollen und Laufzeitüberwachung um effektiv zu sein.
In einer Cloud-Umgebung sind Ihre KI-Angriffsfläche Enthält jetzt:
Modelle: hostete LLMs, fein abgestimmte Modelle und benutzerdefinierte Embeddings.
Trainings- und Inferenzdaten: Datenseen, Vektorspeicher und Protokolle, die vertrauliche Inhalte enthalten können.
Schlussendpunkte: öffentliche und interne APIs für Chat, Suche oder Toolaufrufe.
Agenten und Orchestrierung: Code, der es Modellen ermöglicht, interne Werkzeuge oder externe Dienste aufzurufen.
Modellartefakte: Gewichte, Kontrollpunkte und Containerabbilder, die in der Lieferkette manipuliert werden können.
Ohne Schutzmechanismen kann normales KI-Verhalten zu einem Sicherheitsvorfall werden: Ein Prompt-Injection-Angriff zieht sensible Daten aus einem Vektorspeicher, ein Agent führt eine unbeabsichtigte Aktion gegen interne APIs aus oder ein falsch konfigurierter Endpunkt stellt Kundeninformationen frei. Diese Fehler schaffen sowohl Sicherheits- als auch Markenrisiken, da das Ergebnis des Modells für Nutzer direkt sichtbar ist.
Unternehmen in regulierten Branchen nutzen bereits mehrschichtige Leitplanken, um Implementierungen sicher zu halten. Zum Beispiel betreiben Automobilhersteller cloudbasierte Assistenten mit strenger Eingabefilterung, kontrolliertem Zugriff auf Fahrzeugdaten und Laufzeitprüfungen, welche Antworten an die Fahrer zurückgegeben werden können. So können sie fortschrittliche Modelle übernehmen und gleichzeitig strenge Sicherheits- und Compliance-Grenzen durchsetzen.
Arten von KI-Leitplanken
Praktische Leitplanken funktionieren als Pipeline. Eingaben werden überprüft, bevor sie das Modell erreichen, das Modell läuft in einem kontrollierten Ausführungskontext, und die Ausgaben werden validiert, bevor sie Nutzer oder nachgelagerte Systeme erreichen.
1. Eingangsleitplanken
Eingabe-Leitplanken bewerten und formen eingehende Anfragen neu vor der Schlussfolgerung. Dies ist die erste Präventionsschicht gegen unsicheres Verhalten.
Häufige Eingangsleitplanken sind:
Sofortige Injektion und Jailbreak-Erkennung: Identifizieren Sie Versuche, Systeminstruktionen zu überschreiben oder auf eingeschränkte Daten zuzugreifen.
Scannen sensibler Daten: Erkennen und schwärzen Sie PII, PHI, Zugangsdaten oder Schlüssel innerhalb von Prompts.
Illegale oder verbotene Inhalte: Blockieren Sie Anfragen, die schädliche Anweisungen oder verbotenes Material suchen.
Missbrauchs- und Missbrauchskontrollen: Durchsetzen Sie Ratenbegrenzungen, identifizieren Sie anomale Nutzung und blockieren Sie Brute-Force-Versuche gegen Sicherheitsfilter.
In der Praxis können Eingabe-Leitplanken eine Aufforderung ablehnen, eine Klarstellung anfordern oder Reinigen Sie die Eingabe (z. B. durch das Maskieren von Identifikatoren), bevor es an das Modell gesendet wird.
2. Bearbeitung von Leitplanken
Verarbeitungsleitplanken prägen den Ausführungskontext, in dem das Modell arbeitet. Sie bestimmen, worauf das Modell Zugriff hat und wie es sich verhalten darf, abgesehen vom Text der Eingabeaufforderung.
Zu den Verarbeitungs-Leitplanken gehören typischerweise:
Kontextkontrollen: Beschränken Sie, welche Dokumente, Felder oder Protokolle für jede Anfrage dem Modell zur Verfügung gestellt werden können.
RAG-Sicherheit: Begrenze, welche Sammlungen eine Abrufpipeline abfragen kann, wie viele Ergebnisse sie verwenden kann, und wende Filterung auf abgerufene Inhalte an.
Durchsetzung von Richtlinien: Kodieren Sie Geschäftsregeln wie "Dieses Modell kann keinen Zugriff auf Produktions-Zahlungs-APIs" oder "Nur Daten aus derselben Region zurückgeben."
Kontrollmechanismen für Identität und geringste Privilegien: Verwenden Sie IAM-Richtlinien, um das Servicekonto des Modells daran zu hindern, auf unautorisierte Datenquellen oder -dienste zuzugreifen.
Werkzeug- und Agenten-Leitplanken: Definieren Sie, welche Tools ein KI-Agent aufrufen darf, welche Aktionen menschliche Zustimmung erfordern und wie Parameter vor der Ausführung validiert werden.
Sicherheitsfunktionen für Cloud-Anbieter (z. B. Inhaltsfilter oder Themenfilter in Azure OpenAI, Bedrock oder Vertex AI) können diese Ebene unterstützen, sollten aber mit kombiniert werden
3. Ausgangsleitplanken
Ausgabe-Leitplanken bewerten die Antwort des Modells
Gängige Ausgangsleitplanken sind:
Toxizität und Inhaltssicherheit: Erkennen Sie Hass, Belästigung, Selbstverletzungsinhalte oder andere verbotene Kategorien.
Halluzinationserkennung: Vergleichen Sie Behauptungen mit vertrauenswürdigen Quellen oder abgerufenem Kontext, um nicht gestützte Aussagen zu identifizieren.
Sensible Datenlecks: Scanne nach PII, PHI, Zugangsdaten oder Geheimnissen in den Ausgaben und entfernen oder blockieren Sie bei Bedarf.
Ausrichtung von Marke und Politik: Ton anpassen, erforderliche Offenlegungen einfügen und Compliance-Regeln in regulierten Bereichen durchsetzen.
Ausgangsleitplanken können die Antwort blockieren, um Klarstellung bitten oder
Viele Teams kombinieren regelbasierte Prüfungen (Erlaubt/Ablehnen von Mustern, Schwärzregeln, Prompt-Richtlinien) mit ML-basierten Klassifikatoren (Toxizitätserkennung, Jailbreak-Erkennung, PII-Erkennung). Andere verpacken Herstellermodelle mit einer einheitlichen Sicherheitsschicht über Anbieter, die Moderations-APIs oder Open-Source-Schutzrahmen verwenden.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

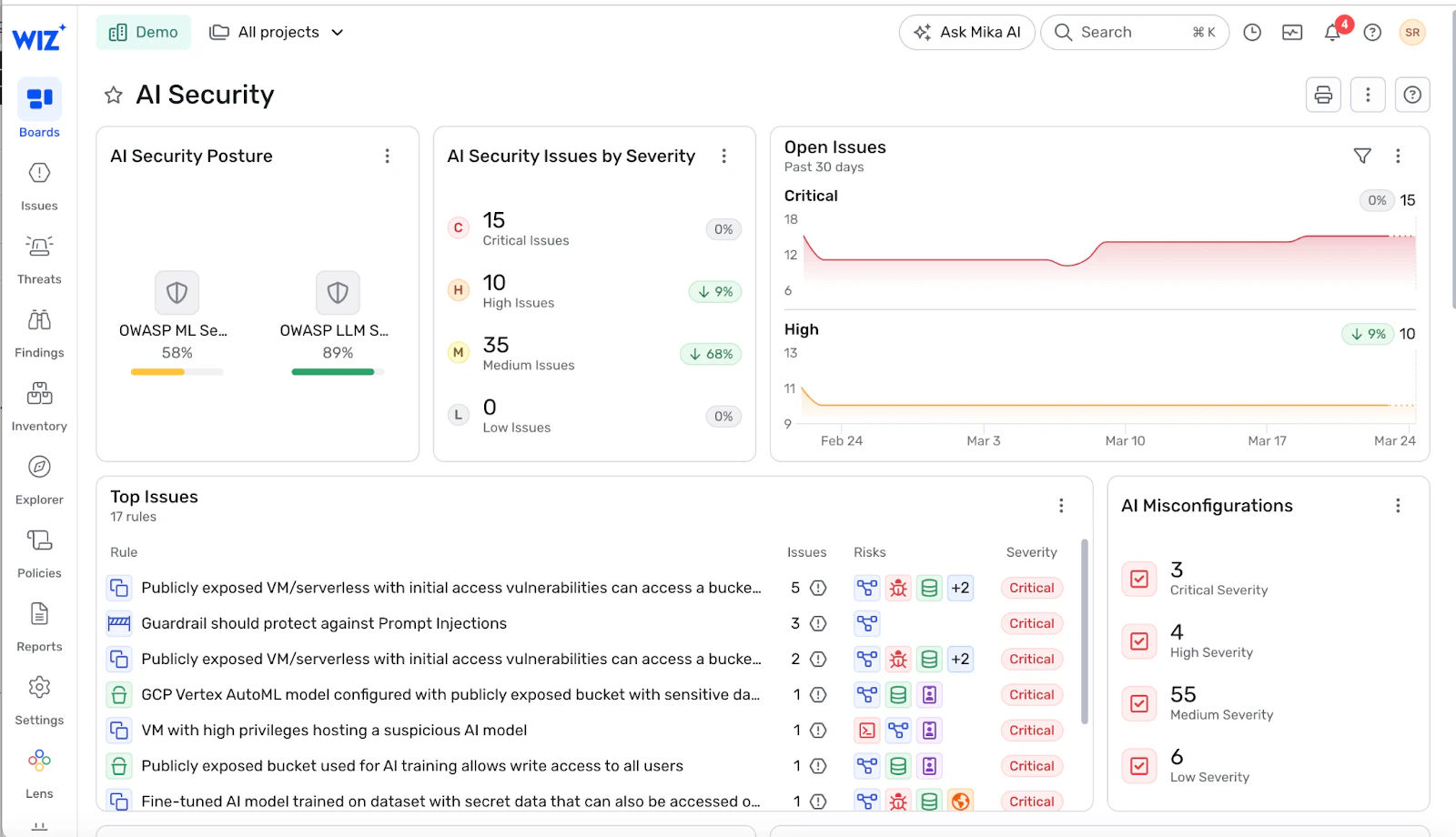
KI-Risiken, auf die Schutzmechanismen ausgelegt sind
KI-Leitplanken existieren, um bestimmte Ausfallklassen zu verhindern. Das Verständnis dieser Bedrohungen hilft Ihnen, Kontrollen zu entwerfen, die sowohl Ihre Daten als auch Ihre Infrastruktur schützen.
Die meisten KI-Risiken fallen in Vier Kategorien:
1. Modellverhalten manipulieren
Angreifer versuchen, Modellinstruktionen zu beeinflussen oder zu überschreiben, um unsichere Aktionen oder Ausgaben zu erzeugen.
Prompte Injektion: Eingaben erstellen, die Systemanweisungen überschreiben und Daten extrahieren oder verbotene Aktionen auslösen.
Indirekte prompte Injektion: Bösartige Anweisungen in Dokumente oder Daten einzubetten, die das Modell später durch Abruf oder Kontext aufnimmt.
Jailbreaks: Das Modell wird gezwungen, eingebaute Sicherheitsbeschränkungen durch Rollenspiel, Übersetzung oder andere indirekte Anfragemuster zu ignorieren.
Gegnerische Eingabeaufforderungen: Subtile Prompt-Muster, die dazu dienen, falsche Ausgaben zu verursachen, ohne böswillig zu wirken.
Diese Risiken werden in erster Linie über
2. Daten- und Kontextmanipulation
Anstatt das Modell direkt anzugreifen, zielen die Gegner auf das Datenpipelines die das Verhalten des Modells prägen.
Datenvergiftung: Schädliche oder verzerrte Daten in Trainings- oder Feinabstimmungssets einzuschleusen, damit das Modell unsichere Muster lernt.
Kontextvergiftung: Manipulation der Dokumente oder des Abrufindexes, die von RAG-Systemen verwendet werden, um Antworten zu beeinflussen.
RAG-Vergiftung: Kontrollieren, welche Dokumente abgerufen werden, damit das Modell irreführende Informationen wiederholt.
Feinabstimmung-Entführung: Kompromittieren von Feinabstimmungen, um Hintertüren einzubauen.
Diese Bedrohungen erfordern
3. Extraktion sensibler Informationen und geistiger Eigentumsrechte
Angreifer versuchen, Daten aus dem Modell oder seinen unterstützenden Komponenten wiederherzustellen.
Modellextraktion: Das Verhalten eines proprietären Modells durch wiederholte Abfragen reproduzieren.
Mitgliedschaftsschlussfolgerung: Feststellung, ob bestimmte Datensätze Teil der Trainingsdaten waren, indem Modellantworten untersucht wurden.
Sensible Datenlecks: Das Modell reproduziert auswendig gelernte Inhalte aus Logs, Trainingsdaten oder Vektorspeichern.
Diese Risiken werden durch die Minderung gemindert
4. Ausnutzung des Zugangs durch Agenten und Werkzeuge
Die am schnellsten wachsende Risikokategorie umfasst Modelle, die
Überberechtigte Agenten: Agenten, die einen breiten Zugang zu internen APIs, Datenbanken oder Cloud-Diensten haben.
Werkzeugmissbrauch: Erlaubte Werkzeuge auf unerwartete Weise zu verwenden, was zu unbefugten Operationen führte.
Identitätseskalation: Ein Modell, das unter einem privilegierten Dienstkonto ohne angemessene Isolation handelt.
Diese Risiken erfordern
Sample AI Security Assessment
Get a glimpse into how Wiz surfaces AI risks with AI-BOM visibility, real-world findings from the Wiz Security Graph, and a first look at AI-specific Issues and threat detection rules.
Get Sample Report

Wie KI-Leitplanken in der Praxis funktionieren
In einem echten System sind Leitplanken kein einzelner Filter, den man am Ende hinzufügt. Sie sind mehrere Steuerungen, die über den Anforderungspfad angewendet werden, vom API-Einstiegspunkt bis zur Ausgabevalidierung. Jede Schicht beseitigt eine andere Risikoklasse.
Ein gewöhnlicher Inferenzfluss mit Leitplanken Sieht so aus:
Benutzeranforderung: Ein Nutzer sendet einen Prompt oder API-Aufruf.
Eingabe-Leitplanken: Die Anfrage wird validiert, bereinigt oder abgelehnt, bevor sie das Modell erreicht.
Kontextkonstruktion (RAG): Wenn ein Abruf verwendet wird, werden nur genehmigte Datenquellen und Dokumente abgerufen und gefiltert.
Durchsetzung von Richtlinien: Geschäftsregeln und Sicherheitsprüfungen prägen, worauf das Modell Zugriff hat und welche Tools es aufrufen kann.
Modellinferenz: Das Modell erzeugt innerhalb dieser Einschränkungen eine Antwort.
Werkzeugausführung (Agenten): Wenn das Modell Aktionen anfordert, werden Parameter validiert und unter minimalem Privileg-Prinzip ausgeführt oder erfordern menschliche Genehmigung.
Ausgangsleitplanken: Die Antwort wird auf Sicherheit, unterstützte Ansprüche, sensible Daten und Einhaltung überprüft, bevor sie an den Nutzer zurückgegeben wird.
Logging und Überwachung: Die vollständige Interaktion wird protokolliert, um Analyse, Warnungen zu erhalten und zu verbessern.
Dieses Muster ermöglicht es Ihnen, unsicheres Verhalten zu verhindern, bevor es auftritt, und Probleme zu erkennen, die durchdringen.
Wo Leitplanken durchgesetzt werden
Leitplanken können an mehreren Stellen in Ihrer Architektur integriert werden:
API-Gateway: Authentifizierung, Ratenbegrenzung, grobe Inhaltsprüfungen.
Orchestrierungsschicht: Chains, Middleware und Validatoren, die Prompt-Filter, Kontextkontrollen und Policy-Logik implementieren.
Cloud-Dienste: Anbieter-Sicherheitsfilter (z. B. Toxizitäts- oder Themenfilter), die während der Inferenz laufen.
Identitätsschicht: IAM-Richtlinien, die definieren, auf welche Datenquellen, APIs und Tools das Modell-Dienstkonto zugreifen kann.
Werkzeuggrenzen: Validierungs- und Genehmigungsflüsse für Agentenaktionen.
Vektorspeicher: Zugriffskontrollen und Dokumenten-Filterung, um Kontextvergiftungen oder Datenlecks zu verhindern.
Ausgangsfilter: Klassifikationsmodelle oder Regeln, die unsichere Antworten blockieren oder umschreiben.
Jede Schicht ist darauf ausgelegt, eine andere Risikoklasse zu beseitigen, sodass Fehler in einer Schicht von einer anderen erkannt werden.
Wie Wiz umfassende KI-Schutzmechanismen im gesamten Sicherheitslebenszyklus ermöglicht
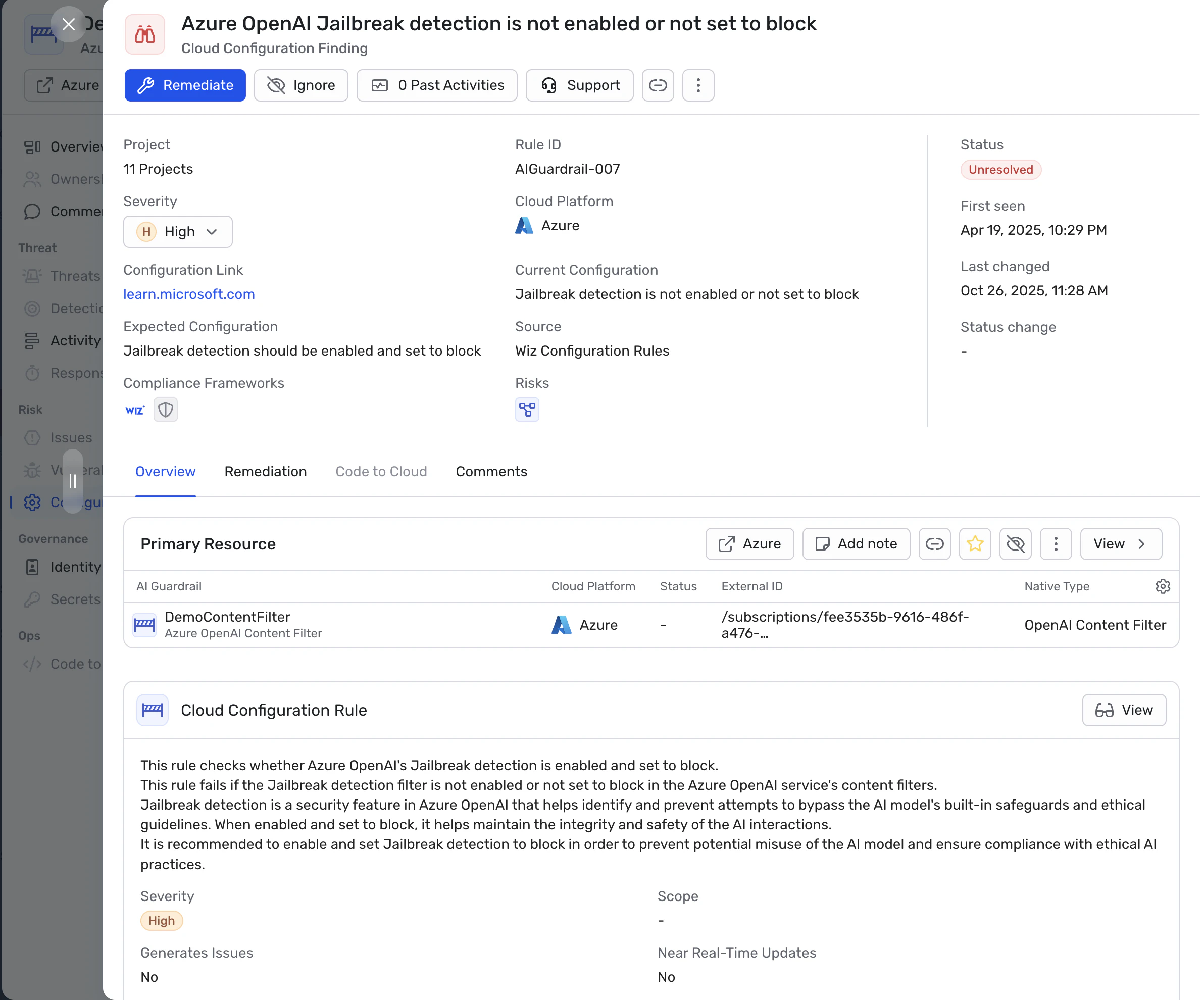
Wiz AI-SPM Sie erhalten eine vollständige Transparenz Ihres KI-Bestands über AWS, Azure und GCP – von verwalteten KI-Diensten und Inferenz-Endpunkten bis hin zu Retrieval-Pipelines und deren Identitäten. Wiz erkennt Fehlkonfigurationen auf Plattformen wie Amazon SageMaker, Azure OpenAI und Google Vertex AI, die Ihre Leitplanken umgehen können, wie öffentliche Endpunkte mit Zugang zu sensiblen Daten oder Agenten unter überprivilegierten Rollen.
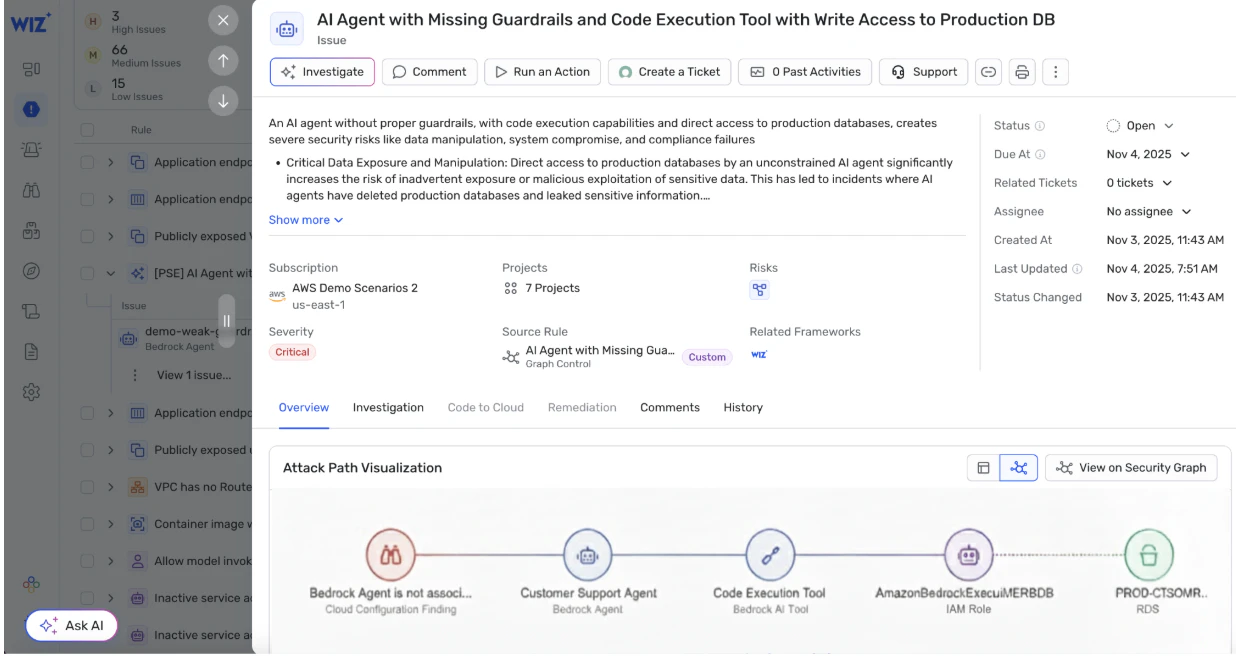
Das Wiz-Sicherheitsgraph kartiert, wie Infrastruktur, Identitäten, Daten und KI-Workloads miteinander interagieren. So kannst du toxische Kombinationen erkennen, die in der Umgebung verborgen sind – zum Beispiel ein exponierter Endpunkt, der mit einem Vektorspeicher voller sensibler Trainingsdaten spricht, der über ein breites Servicekonto erreichbar ist, das einem Agenten zugeordnet ist. Wiz deckt diese Risiken auf, sodass Sie die Umgehungswege unter Ihren Leitplanken entfernen können.
Wiz erweitert diese Steuerungen über den Entwicklungs- und Laufzeitzyklus. Wiz Code scannt IaC und Anwendungscode, der Ihre KI-Infrastruktur definiert, um Probleme wie fest kodierte Modellschlüssel, riskante Netzwerkregeln oder falsch konfigurierte KI-Dienste vor der Bereitstellung zu erkennen. Wiz Defend überwacht KI-bezogene Workloads zur Laufzeit auf ungewöhnliche API-Muster, unbefugten Datenzugriff oder mögliche Exfiltrationsversuche im Zusammenhang mit dem Modellverhalten. Eingebaut DSPM Fähigkeiten klassifizieren sensible Daten, die in Training oder Inferenz verwendet werden, und zeigen, wie sie in Modelle und Endpunkte einfließen, sodass man datenorientierte Leitplanken in der Realität aufbauen kann.
Da all dieser Kontext auf einer Plattform liegt, können Organisationen einheitliche KI-Sicherheitsrichtlinien über Code-Repositorien, CI/CD-Pipelines, Cloud-Ressourcen und Laufzeitumgebungen durchsetzen. Mit anderen Worten, Wiz bietet Leitplanken für deine Leitplanken – Stellen Sie sicher, dass die Infrastruktur, Datenpfade und Identitäten rund um Ihre Modelle korrekt konfiguriert, überwacht und geschützt sind.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
