

Bösartige KI-Modelle sind absichtlich als Waffen eingesetzte Modellartefakte die schädliche Aktionen ausführen, wenn sie geladen oder ausgeführt werden. Im Gegensatz zu verwundbaren Modellen – die versehentliche Fehler enthalten – sind bösartige Modelle darauf ausgelegt, die Umgebung, in der sie eingesetzt werden, zu kompromittieren.
Das definierende Merkmal bösartiger KI-Modelle ist, dass die Bedrohung eingebettet ist Innerhalb der Modelldatei selbst. In vielen Fällen missbrauchen Angreifer unsichere Serialisierungsformate, um ausführbaren Code in Modellgewichten oder Ladelogik zu verstecken. Wenn das Modell importiert oder deserialisiert wird, wird dieser Code automatisch ausgeführt – oft bevor irgendeine Schlussfolgerung erfolgt.
Das macht bösartige KI-Modelle zu einer eigenständigen Bedrohung in der Lieferkette. Sie nutzen das Vertrauen aus, das Organisationen in vortrainierte Modelle setzen, die aus öffentlichen Repositorien heruntergeladen oder intern in Teams geteilt werden. Da Modellartefakte nicht wie traditioneller Quellcode behandelt werden, umgehen sie häufig Sicherheitskontrollen wie Code-Review, statische Analyse und Abhängigkeitsscanning.
Mit der beschleunigten Einführung von KI sind vortrainierte Modelle zu einem grundlegenden Baustein für moderne Entwicklung geworden. Diese gleiche Bequemlichkeit hat Modellartefakte zu einem hochwertigen Angriffsvektor gemacht – einem, für den traditionelle Anwendungssicherheitstools nie ausgelegt waren.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Warum bösartige KI-Modelle ein echtes Risiko in der Lieferkette darstellen
Bösartige KI-Modelle entstehen aus denselben Kräften, die die moderne Softwareentwicklung verändert haben: Wiederverwendung, Automatisierung und Vertrauen in externe Komponenten. Vortrainierte Modelle werden routinemäßig aus öffentlichen Repositories entnommen, um die Entwicklung zu beschleunigen, Kosten zu senken und ein Neutraining von Grund auf zu vermeiden. In vielen Organisationen ist das Herunterladen und Bereitstellen von Modellen so routinemäßig geworden wie die Installation einer Bibliothek.
Dieser Workflow verlagert das Vertrauen weg von intern überprüftem Code hin zu externen Artefakten, die selten inspiziert werden. Modelldateien werden oft als undurchsichtige Binärdateien behandelt – gespeichert, geteilt und geladen, ohne die genaue Prüfung von Anwendungscode oder Container-Images. Dadurch umgehen sie häufig etablierte Sicherheitskontrollen wie Code-Review, statische Analyse und Abhängigkeitsscans.
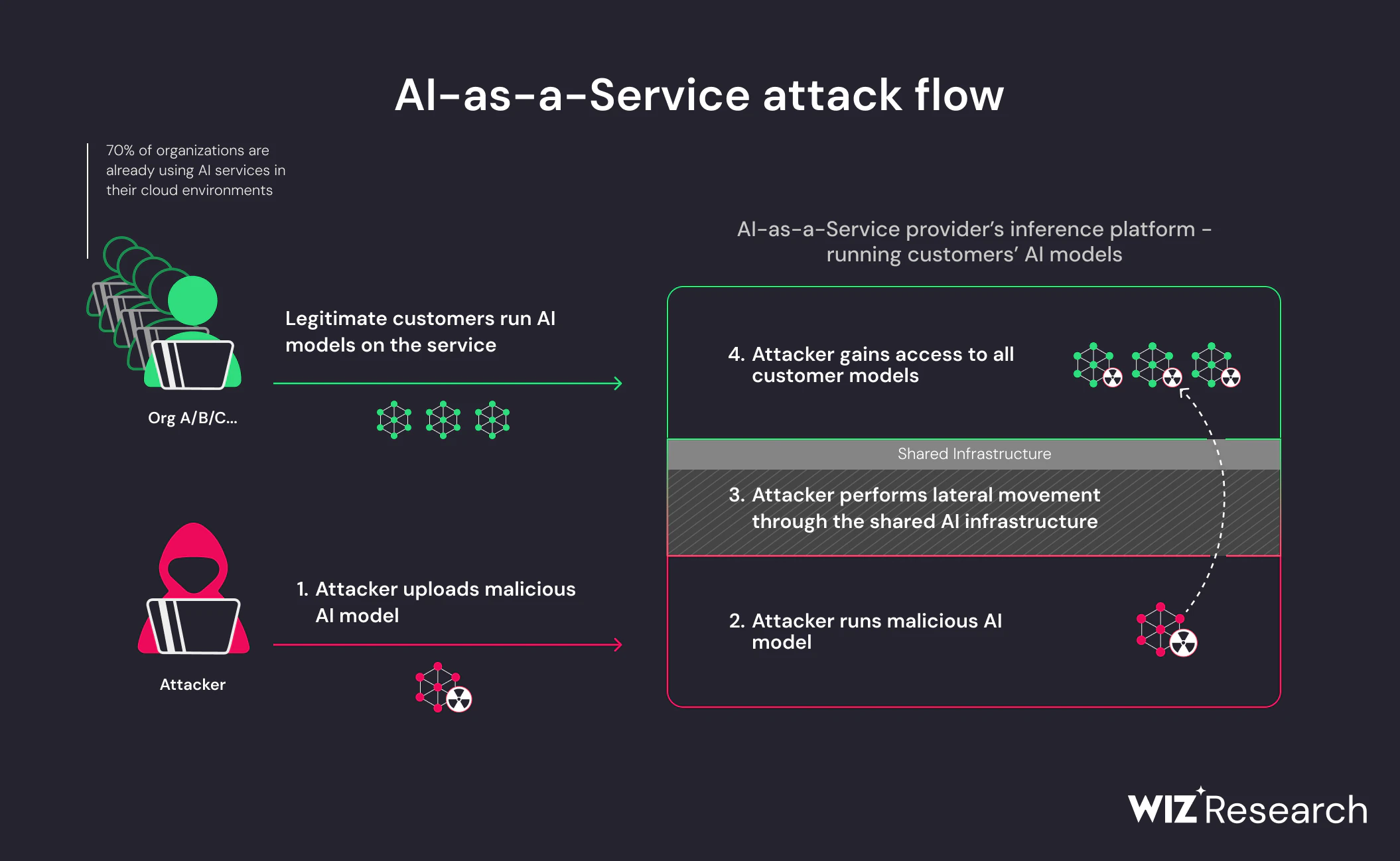
Was dieses Risiko besonders akut macht, ist, dass bösartige Modelle ausnutzen Erwartetes Verhalten. Das Laden eines Modells ist eine normale, vertrauenswürdige Aktion in KI-Pipelines. Wenn Angreifer ausführbare Logik in Modellartefakte einbetten, wird dieses Vertrauen zum Liefermechanismus. Es ist keine Exploit-Kette erforderlich; der Kompromiss erfolgt, weil das System genau das tut, wofür es entwickelt wurde.
Deshalb stellen bösartige KI-Modelle eine Bedrohung durch die Lieferkette statt eines Anwendungsfehlers. Das Risiko entspringt nicht der Verwendung eines Modells, sondern von der Verwendung eines Modells. woher es kommt und wie es geladen wird. Da die Wiederverwendung von Modellen weiterhin über Teams und Umgebungen hinweg skaliert, wird die Fähigkeit, Modellherkunft und -verhalten zu validieren, zu einer grundlegenden Sicherheitsanforderung.
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
Mehr lesen

Wie bösartige KI-Modelle auf hoher Ebene funktionieren
Bösartige KI-Modelle nutzen aus, wie Modelle in modernen KI-Workflows verpackt, verteilt und geladen werden. Das Kernrisiko sind nicht die Vorhersagen des Modells, sondern die Ausführungspfad wird ausgelöst, wenn eine Modelldatei deserialisiert oder initialisiert wird.
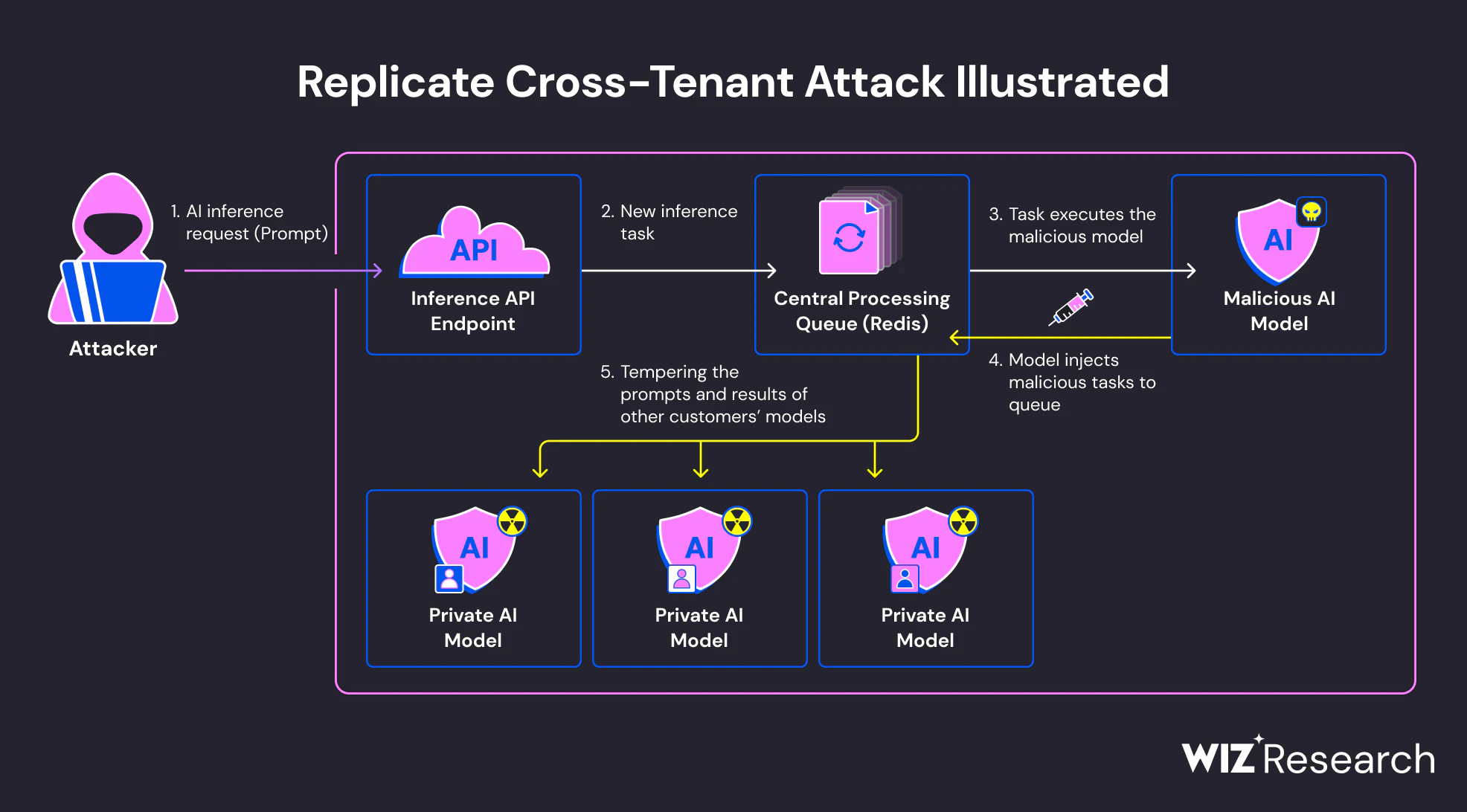
Ausführung während des Modellladens
Viele KI-Frameworks unterstützen Serialisierungsformate, die es ermöglichen, ausführbare Logik als Teil des Modellladeprozesses auszuführen. Insbesondere Pythons Pickle-basierte Formate – häufig in PyTorch und verwandten Tools verwendet – können beliebigen Code ausführen, wenn ein Modell deserialisiert wird. Dieses Verhalten ist dokumentiert, wird aber in der Praxis oft übersehen.
Wenn ein bösartiges Modell geladen wird, kann eingebetteter Code sofort ausgeführt werden, bevor eine Schlussfolgerung oder Bewertung erfolgt. Aus Sicht des Systems sieht das wie ein normaler Modellimport aus. Aus Sicht eines Angreifers ist es ein zuverlässiger Ausführungspunkt in einer vertrauenswürdigen Umgebung.
Warum dies vor der Schlussfolgerung passiert
Im Gegensatz zu Anwendungscode werden Modelle als Daten behandelt. Sicherheitskontrollen konzentrieren sich meist darauf, wie Modelle verwendet werden, nicht darauf, wie sie geladen werden. Daher findet die gefährlichste Aktivität früh im Lebenszyklus statt – zur Ladezeit – bevor Laufzeitüberwachung, Zugriffskontrollen oder Verhaltenskontrollen durchgeführt werden.
Das macht bösartige Modelle mit herkömmlichen Tools schwer zu erkennen. Es gibt möglicherweise keine verdächtigen API-Aufrufe, keine fehlgeleiteten Eingaben und keine abnormalen Ausgaben. Der Kompromiss entsteht einfach, weil das Modell als legitim akzeptiert wurde.
Gemeinsame Ziele der Angreifer
Sobald die Ausführung erreicht ist, verfolgen Angreifer typischerweise vertraute Ziele:
Diebstahl von Zugangsdaten oder Token, die in der Umgebung verfügbar sind
Zugriff auf Trainingsdaten oder nachgelagerte Datenspeicher
Persistenz durch Hintertüren oder geplante Aufgaben etablieren
Verbrauch von Rechenressourcen für Kryptomining oder weitere Kompromittierungen
Diese Maßnahmen sind nicht einzigartig für KI-Umgebungen, aber Modelle laufen oft mit erhöhten Berechtigungen und der Nähe sensibler Daten, was ihre Wirkung erhöht.
Sicherere Formate, sicherere Standardeinstellungen
Nicht alle Modellformate bergen das gleiche Risiko. Formate, die dazu dienen, Gewichte von ausführbarer Logik zu trennen – wie zum Beispiel SafeTensors und ONNX –Verringerung der Wahrscheinlichkeit der Codeausführung während des Modellladens. Diese Formate speichern Modelldaten ohne eingebettete Ausführungspfade, was sie von Natur aus sicherer macht.
Im Gegensatz dazu erhöhen Serialisierungsmechanismen, die ausführbare Logik während der Deserialisierung ermöglichen, das Risiko, sofern sie nicht streng kontrolliert werden. In der Praxis führen Kompatibilität und Bequemlichkeit oft dazu, dass Teams auf unsichere Formate zurückgreifen, sofern keine expliziten Sicherheitsstandards durchgesetzt werden.
Verständnis Wie Modelle sind daher zentral für die Verteidigung gegen bösartige KI-Modelle. Die Bedrohung beruht nicht auf gegnerischen Eingaben oder neuartigem KI-Verhalten – sie beruht auf vorhersehbaren, vertrauenswürdigen Ausführungspfaden in gängigen ML-Tools.


Primäre Angriffsvektoren für bösartige KI-Modelle
Bösartige KI-Modelle erreichen typischerweise durch eine kleine Anzahl wiederholbarer Angriffsvektoren die Produktion. Diese Vektoren nutzen das Vertrauen in Modellartefakte und Automatisierung in KI-Workflows aus, anstatt neuartiges KI-Verhalten.
Öffentliche Modell-Repositorien
Öffentliche Repositories sind der häufigste Vertriebskanal für bösartige Modelle. Angreifer laden bewaffnete Modelle auf beliebte Plattformen hoch oder nutzen Typosquatting, um bekannte Projekte zu imitieren. Im Laufe der Zeit können sie durch harmlose Veröffentlichungen einen Ruf aufbauen, bevor sie eine bösartige Version einführen.
Da vortrainierte Modelle oft direkt in Entwicklungs- oder Trainingsumgebungen heruntergeladen werden, können diese Artefakte die auf Anwendungscode oder Container-Images angewendeten Prüfprozesse umgehen.
Entfernte Codeausführung über Modelllader
Einige KI-Workflows erlauben explizit die Ausführung von Remote oder benutzerdefiniertem Code während des Modellladens. Einstellungen wie permissive Loader-Flags oder benutzerdefinierte Modellklassen erweitern die Angriffsfläche, indem sie es ermöglichen, ausführbare Logik dynamisch abzurufen und auszuführen.
In diesen Fällen geht das Risiko nicht von den Modellgewichten selbst aus, sondern vom Lademechanismus, der externen Code implizit vertraut. Das macht die Loader-Konfiguration zu einem wichtigen Bestandteil des Bedrohungsmodells.
Trojaner-Modelle und erlernte Hintertüren
Nicht alle bösartigen Modelle verlassen sich auf die Ausführung während des Ladens. Einige sind so konzipiert, dass sie sich unter den meisten Bedingungen während der Produktion normal verhalten bösartige Ausgaben, wenn bestimmte Auslöser vorhanden sind. Diese "Trojaner"-Modelle betten schädliches Verhalten direkt in gelernte Gewichte ein, anstatt in ausführbaren Code.
Im Gegensatz zu serialisierungsbasierten Angriffen zielen Trojaner-Modelle typischerweise auf die Trainings- oder Feinabstimmungsprozess, zum Beispiel durch vergiftete Trainingsdaten oder manipulierte Feinabstimmungs-Workflows. Da das bösartige Verhalten in den Parametern des Modells kodiert ist, bietet das statische Scannen des Modellartefakts nur begrenzte Transparenz der Bedrohung.
Dies macht Trojanermodelle zu einer eigenen Risikokategorie. Die Erkennung erfordert in der Regel adversariale Tests, Verhaltensanalysen oder Validierung von Trainingsdaten und Abstammung, anstatt nur die Modelldatei zu prüfen.
Abhängigkeit und Insiderrisiko
Bösartige Modelle können auch durch kompromittierte Abhängigkeiten oder vertrauenswürdige interne Kanäle in Umgebungen eindringen. Dazu gehören vergiftete ML-Bibliotheken, unsichere interne Register oder von Insidern mit legitimem Zugang eingeführte Modelle.
Da diese Vektoren auf bestehenden Vertrauensverhältnissen beruhen, werden sie in frühen Bedrohungsmodellen oft übersehen, obwohl sie ein Potenzial für weitreichende Auswirkungen haben.
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

Warum Cloud-Umgebungen das Risiko erhöhen
Cloud-Umgebungen erzeugen keine bösartigen KI-Modelle, aber sie sind deutlich Erhöhen Sie den Aufprall und die Geschwindigkeit von Kompromiss, wenn einer eingeführt wird. Die gleichen Eigenschaften, die Cloud-Plattformen ideal für KI machen – Automatisierung, Skalierung und Zugang zu sensiblen Daten – verstärken ebenfalls das Risiko in der Lieferkette.
KI-Workloads laufen häufig mit erhöhten Berechtigungen. Trainingsjobs und Inferenzdienste erfordern oft Zugriff auf große Datensätze, Objektspeicherung, Geheimnisse und nachgelagerte Dienste. Wenn ein bösartiges Modell in diesem Kontext ausgeführt wird, kann es diese Rechte sofort übernehmen und so den Explosionsradius über das Modell hinaus erweitern.
Automatisierung verstärkt das Risiko zusätzlich. Modelle werden üblicherweise über CI/CD-Pipelines, Orchestrierungsrahmen oder geplante Retraining-Workflows bereitgestellt. Sobald ein bösartiges Artefakt einen dieser Pfade betritt, kann es sich ohne menschliches Eingreifen schnell über verschiedene Umgebungen ausbreiten, was eine manuelle Inspektion unpraktisch macht.
Die Cloud-Infrastruktur ändert sich auch dort, wo die Ausführung im Zusammenhang mit sensiblen Daten stattfindet. Bösartige Modelle führen typischerweise aus innerhalb derselben Datenebene wie die Daten, auf die sie zugriffen sollen, statt angrenzend daran. Im Gegensatz zu einer kompromittierten Webanwendung, die lateral pivotieren muss, um eine Datenbank zu erreichen, läuft ein Modell oft in einer Umgebung, die bereits direkten Zugriff auf Trainingsdaten, Inferenzeingaben oder nachgelagerte Systeme hat. Dadurch verringert sich der Abstand zwischen Ausführung und Aufprall.
Schließlich hängen KI-Workloads von komplexen Stacks aus verwalteten Diensten, Containern, GPUs und Laufzeitabhängigkeiten ab. Jede Schicht bringt Konfigurations- und Isolationsherausforderungen mit sich, die Angreifer ausnutzen können, wenn Steuerungen falsch angewendet werden. In der Praxis bedeutet das, dass bösartige Modelle von denselben Fehlkonfigurationen profitieren, die heute viele Cloud-Sicherheitslücken verursachen.
Zusammen verwandeln diese Faktoren bösartige KI-Modelle von einem lokalisierten Risiko in ein Sicherheitsbedenken auf Systemebene, was betont, warum Modellsicherheit im Kontext von Cloud-Identitäten, Datenzugriff und Bereitstellungspipelines bewertet werden muss – und nicht isoliert.
Verteidigung gegen bösartige KI-Modelle
Die Verteidigung gegen bösartige KI-Modelle erfordert eine Verlagerung des Fokus vom Modellverhalten auf Modellherkunft, Ladepfade und Ausführungskontext. Weil die Bedrohung im Artefakt oder Trainingsprozess selbst eingebettet ist, traditionell Anwendungssicherheitskontrollen sind notwendig, aber sind'Nicht genug allein.
Kontrollmechanismen etablieren, bevor die Modelle in die Produktion gehen
Die effektivsten Verteidigungen funktionieren bevor ein Modell geladen wird. Dazu gehört die Validierung, woher Modelle stammen, wie sie verpackt sind und welche Codepfade während des Ladens ausgeführt werden. Die Behandlung von Modellartefakten als erstklassige Komponenten der Lieferkette – unterbehaltlich Inspektion, Genehmigung und Versionskontrolle – verringert die Wahrscheinlichkeit, dass bewaffnete Modelle sensible Umgebungen erreichen.
In der Praxis bedeutet das, dieselbe Governance auf Modellregister dass Organisationen bereits Containerregister oder Artefakt-Repositorien anwenden. Wenn Container-Bilder signiert, gescannt und über kontrollierte Pipelines beworben werden, sollten Modellartefakte derselben Disziplin folgen – unabhängig davon, ob sie intern oder aus öffentlichen Quellen stammen.
Wo möglich, sollten Teams Modellformate bevorzugen, die Daten von ausführbarer Logik trennen und Loader-Konfigurationen einschränken, die externem Code implizit vertrauen. Diese Kontrollen beseitigen kein Risiko, verringern aber die Angriffsfläche erheblich.
Einschränkung der Ausführung durch Identitäts- und Zugriffskontrollen
Bösartige Modelle sind am gefährlichsten, wenn sie weitreichende Berechtigungen erben. Die Begrenzung der Identitäten und Rollen für Trainings- und Inferenzarbeitslasten verringert den Explosionsradius, wenn ein Modell kompromittiert wird. Dazu gehört die Durchsetzung von Least Privilege für Service-Konten, die Isolierung von Umgebungen und das Vermeiden gemeinsamer Zugangsdaten über Pipelines hinweg.
Da Modelle oft innerhalb der Datenebene ausgeführt werden, wird Zugriffskontrolle zur primären Verteidigungslinie – nicht zur sekundären Schutzmaßnahme.
Beobachte das Verhalten im Kontext, nicht isoliert
Statische Inspektion allein kann nicht jedes bösartige Modell erfassen, insbesondere solche, die Verhalten in gelernte Gewichte einbetten. Die Laufzeit-Sichtbarkeit hilft, diese Lücke zu schließen, indem sie beobachtet, wie Modelle im Laufe der Zeit mit ihrer Umgebung interagieren.
Effektive Überwachung konzentriert sich auf Kontextuelle Signale: unerwarteter Netzwerkzugriff, ungewöhnliche Dateioperationen, abnormale Identitätsnutzung oder Abweichungen von etablierten Ausführungsmustern. Diese Signale sind am aussagekräftigsten, wenn sie mit dem Cloud-Kontext korreliert werden – welche Daten das Modell abrufen kann, welche Identitäten es verwendet und wie es bereitgestellt wurde.
Modellsicherheit als Teil der Cloud-Sicherheit betrachten
Letztlich ist die Verteidigung gegen bösartige KI-Modelle keine eigenständige Disziplin. Es erfordert die Integration KI-spezifischer Überlegungen in bestehende Cloud-Sicherheitspraktikeneinschließlich Supply Chain Governance, Identitätsmanagement und Workload-Monitoring.
Indem Sicherheitsteams Modelle als Teil des umfassenderen Systems bewerten, in dem sie agieren – und nicht als undurchsichtige Blackboxen – können Sicherheitsteams die Exposition bösartiger Artefakte reduzieren, ohne sich auf spekulative Erkennung oder Annahmen über das Verhalten der Modelle zu verlassen.
Wie Wiz hilft, das Risiko bösartiger KI-Modelle zu verringern
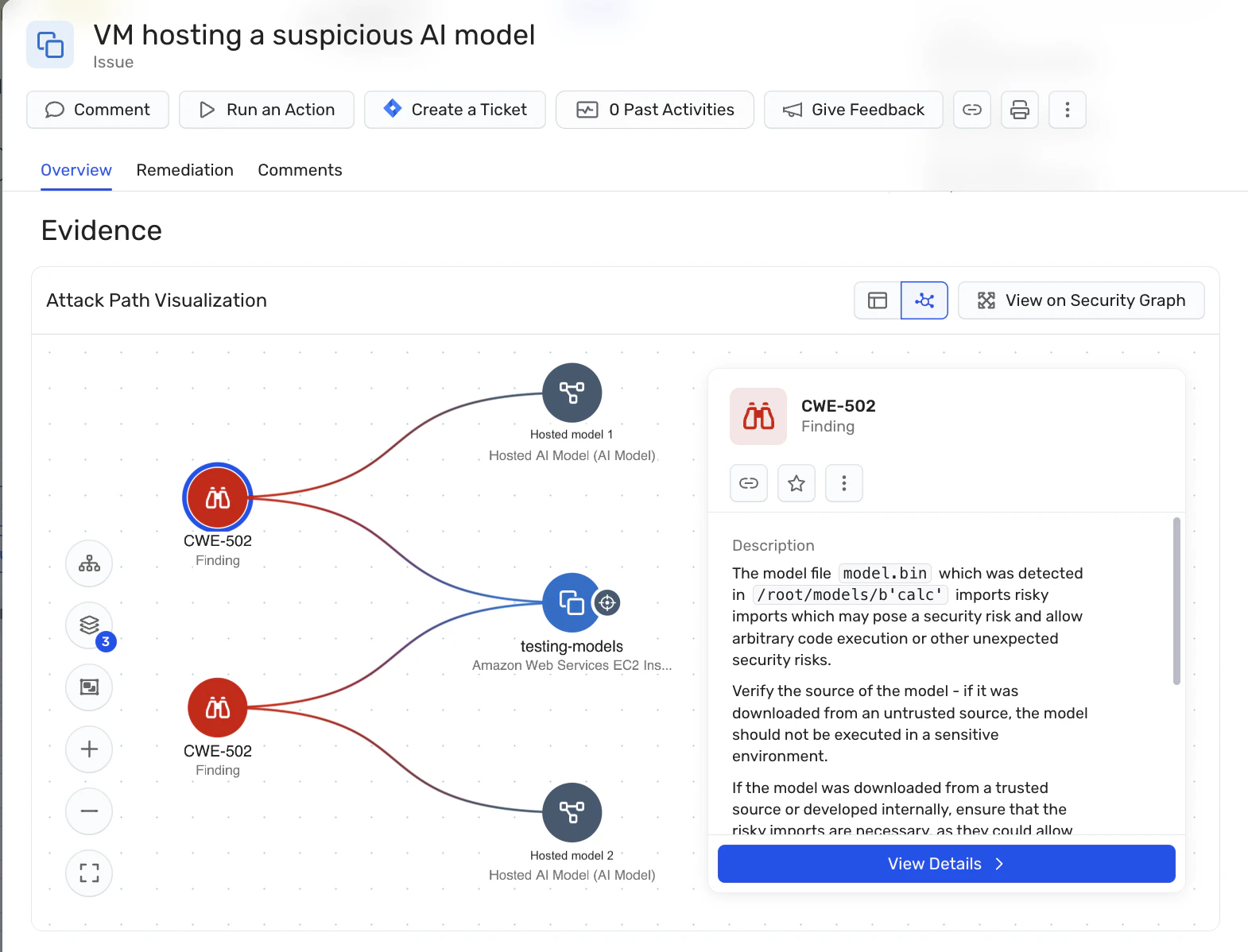
Wiz hilft Organisationen, das Risiko bösartiger KI-Modelle zu reduzieren, indem es die Modellsicherheit auf Cloud-Sicherheitsgrundlagen verankert. Anstatt zu versuchen, die Absicht oder das Verhalten des Modells zu klassifizieren, konzentriert sich Wiz darauf, die Kontrollen zu validieren, die bestimmen woher die Modelle kommen, wie sie geladen werden und worauf sie nach der Bereitstellung zugreifen können..
Durch KI-Sicherheitshaltungsmanagement (AI-SPM) und die Wiz-Sicherheitsgraph, KI-Modelle, Trainingsjobs, Inferenzdienste und Registrierungen werden als erstklassige Cloud-Assets behandelt. Wiz bietet Einblick in gehostete Modellartefakte und führt Format-Inspektionen durch, um riskante Serialisierungsmethoden oder vertrauenswürdige Quellen aufzudecken – und erweitert die Disziplin der Software-Lieferkette auf KI-Modelle, bevor sie in Produktion gelangen.
Durch die Korrelation von Modellartefakten mit Identitäten, Berechtigungen, Netzwerkexposition und Zugang zu sensiblen Daten hilft Wiz Teams dabei, zu erkennen, wann ein riskantes oder potenziell bösartiges Modell entsteht in der Praxis ausnutzbar, den tatsächlichen Explosionsradius zu verstehen und die Sanierung auf Basis realer Angriffspfade zu priorisieren – ohne die KI-Entwicklung zu verlangsamen oder separate Sicherheitstools einzuführen.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
