



Was ist ein Datenleck?
Unter Datenlecks versteht man die unkontrollierte Exfiltration von Unternehmensdaten an Dritte. Dies geschieht auf verschiedene Weise wie falsch konfigurierte Datenbanken, schlecht geschützte Netzwerkserver, Phishing-Angriffe oder sogar unvorsichtiger Umgang mit Daten.
Datenlecks können versehentlich passieren: 82 % aller Organisationen Dritten weitreichenden Lesezugriff auf ihre Umgebungen zu gewähren, was große Sicherheitsrisiken und ernsthafte Bedenken hinsichtlich des Datenschutzes mit sich bringt. Datenlecks treten jedoch auch aufgrund böswilliger Aktivitäten wie Hacking, Phishing oder Insider-Bedrohungen auf, bei denen Mitarbeiter absichtlich Daten stehlen.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

Mögliche Auswirkungen von Datenlecks
Datenlecks können tiefgreifende und weitreichende Auswirkungen haben:
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
Die zunehmende Bedrohung durch Leckagen bei maschinellem Lernen (ML)
Beim Trainieren eines Modells mit einem Datensatz, der sich von dem eines Large Language Model (LLM) unterscheidet, kann es zu Verzerrungen beim maschinellen Lernen oder bei künstlicher Intelligenz (KI) kommen. Diese Situation entsteht in der Regel aufgrund eines Missmanagements in der Vorverarbeitungsphase der ML-Entwicklung. Ein typisches Beispiel für ML-Leckagen ist die Verwendung des Mittelwerts und der Standardabweichung eines gesamten Trainingsdatasets anstelle der gesamten Trainingsteilmenge.
Datenlecks treten in Modellen des maschinellen Lernens durch Ziellecks oder Train-Test-Kontaminationen auf. In letzterem Fall gelangen die Daten, die zum Testen des Modells bestimmt sind, in den Trainingssatz. Wenn ein Modell während des Trainings Testdaten ausgesetzt wird, sind seine Leistungsmetriken irreführend hoch.
Bei Ziellecks umfassen die für das Training verwendeten Teilmengen Informationen, die in der Vorhersagephase der ML-Entwicklung nicht verfügbar sind. Obwohl LLMs in diesem Szenario gut abschneiden, bieten sie den Stakeholdern eine falsches Gefühl der Wirksamkeit des Modells, was zu einer schlechten Leistung in realen Anwendungen führt.


Häufige Ursachen für Datenlecks
Datenlecks treten aus einer Vielzahl von Gründen auf. Im Folgenden sind einige der häufigsten aufgeführt.
Menschliches Versagen
Menschliches Versagen kann auf jeder Ebene eines Unternehmens passieren, oft ohne böswillige Absicht. So können Mitarbeiter beispielsweise versehentlich vertrauliche Informationen wie Finanzunterlagen oder persönliche Daten an die falsche E-Mail-Adresse senden.
Phishing-Angriffe
Phishing-Angriffe treten in verschiedenen Formen auf, haben aber nur eine Methode: Cyberkriminelle ködern privilegierte Konten dazu, wertvolle Details preiszugeben. So können Angreifer beispielsweise scheinbar legitime E-Mails versenden, in denen sie Mitarbeiter auffordern, auf bösartige Links zu klicken und sich bei einem bestimmten Konto anzumelden. Auf diese Weise gibt der Mitarbeiter seine Anmeldedaten freiwillig an den Angreifer weiter, die dann für einen oder mehrere böswillige Zwecke verwendet werden.
Schlechte Konfiguration
Falsch konfigurierte Datenbanken, Cloud-Dienste und Softwareeinstellungen schaffen Schwachstellen, die sensible Daten unbefugtem Zugriff aussetzen. Fehlkonfigurationen treten häufig aufgrund von Aufsicht, mangelndem Fachwissen oder Nichtbeachtung von Best Practices für die Sicherheit auf. Wenn Sie die Standardeinstellungen, wie z. B. Standardbenutzernamen und -kennwörter, unverändert lassen, können Sie Cyberkriminellen einfachen Zugriff gewähren.
Falsche App-Einstellungen, das Nichtanwenden von Sicherheitspatches und -updates sowie unzureichende Zugriffskontrollen/Berechtigungseinstellungen können ebenfalls zu Sicherheitslücken führen.
Schwache Sicherheitsmaßnahmen
Schwache Sicherheitsmaßnahmen schwächen eine Organisation'Sicherheitslage. Verwendung einfacher, leicht zu erratender Passwörter; Versäumnis, sichere Passwortrichtlinien zu implementieren; Vergabe übermäßiger Berechtigungen und Nichtbefolgung des Prinzips der geringsten Privilegien (PoLP); Oder die Wiederverwendung von Passwörtern für mehrere Konten erhöht das Risiko von Datenlecks.
Außerdem wird das Hinterlassen von Daten unverschlüsselt– im Ruhezustand und während der Übertragung – prädisponiert die Daten für Lecks. Die Prinzip der geringsten Privilegien (PoLP) Und wenn Sie sich auf veraltete Sicherheitsprotokolle/-technologien verlassen, können Lücken in Ihrem Sicherheitsrahmen entstehen.
Strategien zur Vermeidung von Leckagen
1. Datenvorverarbeitung und -bereinigung
Anonymisierung und Schwärzung
Bei der Anonymisierung werden personenbezogene Daten und sensible Daten geändert oder entfernt, um zu verhindern, dass sie mit Einzelpersonen in Verbindung gebracht werden können. Die Schwärzung ist ein spezifischerer Prozess, bei dem sensible Teile der Daten wie Kreditkartennummern, Sozialversicherungsnummern oder Adressen entfernt oder unkenntlich gemacht werden.
Ohne angemessene Anonymisierung und Schwärzung können KI-Modelle "auswendig lernen" Vertrauliche Daten aus dem Trainingssatz, die versehentlich in Modellausgaben reproduziert werden könnten. Dies ist besonders gefährlich, wenn das Modell in öffentlichen oder clientorientierten Anwendungen verwendet wird.
Bewährte Methoden:
Verwenden Sie Tokenisierungs-, Hashing- oder Verschlüsselungstechniken, um Daten zu anonymisieren.
Stellen Sie sicher, dass alle geschwärzten Daten vor dem Training dauerhaft sowohl aus strukturierten (z. B. Datenbanken) als auch aus unstrukturierten (z. B. Textdateien) Datensätzen entfernt werden.
Implementieren Sie Differential Privacy (siehe unten), um das Risiko einer individuellen Datenoffenlegung weiter zu verringern.
Datenminimierung
Bei der Datenminimierung wird nur der kleinste Datensatz gesammelt und verwendet, der erforderlich ist, um das Ziel des KI-Modells zu erreichen. Je weniger Daten gesammelt werden, desto geringer ist das Risiko, dass vertrauliche Informationen durchgesickert sind.
Das Sammeln übermäßiger Daten erhöht die Risikofläche für Sicherheitsverletzungen und die Wahrscheinlichkeit, dass vertrauliche Informationen durchsickern. Indem man nur das verwendet, was'Wenn dies erforderlich ist, stellen Sie auch die Einhaltung von Datenschutzbestimmungen wie DSGVO oder CCPA sicher.
Bewährte Methoden:
Führen Sie ein Datenaudit durch, um zu beurteilen, welche Datenpunkte für das Training unerlässlich sind.
Implementieren Sie Richtlinien, um nicht benötigte Daten zu Beginn der Vorverarbeitungspipeline zu verwerfen.
Überprüfen Sie regelmäßig den Datenerfassungsprozess, um sicherzustellen, dass keine unnötigen Daten aufbewahrt werden.
2. Schutzmaßnahmen für das Modelltraining
Richtiges Datensplitting
Durch die Datenaufteilung wird das Dataset in Trainings-, Validierungs- und Testsätze unterteilt. Der Trainingssatz lehrt das Modell, während die Validierungs- und Testsätze die Genauigkeit des Modells sicherstellen, ohne dass es zu einer Überanpassung kommt.
Wenn Daten falsch aufgeteilt werden (z. B. wenn dieselben Daten sowohl im Trainings- als auch im Testsatz vorhanden sind), kann das Modell den Testsatz effektiv "auswendig lernen", was zu einer Überschätzung seiner Leistung und einer potenziellen Offenlegung sensibler Informationen sowohl in der Trainings- als auch in der Vorhersagephase führt.
Bewährte Methoden:
Randomisieren Sie Datasets während der Aufteilung, um sicherzustellen, dass sich die Trainings-, Validierungs- und Testsätze nicht überschneiden.
Verwenden Sie Techniken wie die k-fache Kreuzvalidierung, um die Modellleistung ohne Datenlecks robust zu bewerten.
Regularisierungstechniken
Regularisierungstechniken werden während des Trainings eingesetzt, um eine Überanpassung zu verhindern, bei der das Modell zu spezifisch für die Trainingsdaten wird und lernt, sich diese zu "merken", anstatt sie zu verallgemeinern. Eine Überanpassung erhöht die Wahrscheinlichkeit von Datenlecks, da das Modell vertrauliche Informationen aus den Trainingsdaten speichern und während der Inferenz reproduzieren kann.
Bewährte Methoden:
Dropout: Bestimmte Einheiten (Neuronen) werden während des Trainings nach dem Zufallsprinzip aus dem neuronalen Netzwerk entfernt, wodurch das Modell gezwungen wird, Muster zu verallgemeinern, anstatt sie sich zu merken.
Gewichtsabfall (L2-Regularisierung): Bestrafen Sie große Gewichte während des Trainings, um zu verhindern, dass das Modell zu eng an die Trainingsdaten angepasst wird.
Frühes Stoppen: Überwachen Sie die Modellleistung für einen Validierungssatz und beenden Sie das Training, wenn das Modell'Die Leistung beginnt sich durch Überanpassung zu verschlechtern.
Differenzieller Datenschutz
Differential Privacy fügt den Daten- oder Modellausgaben ein kontrolliertes Rauschen hinzu und stellt sicher, dass es für Angreifer schwierig wird, Informationen über einen einzelnen Datenpunkt im Datensatz zu extrahieren.
Durch die Anwendung von Differential Privacy ist es weniger wahrscheinlich, dass KI-Modelle während des Trainings oder der Vorhersage Details bestimmter Personen preisgeben, was einen Schutz vor gegnerischen Angriffen oder unbeabsichtigten Datenlecks bietet.
Bewährte Methoden:
Fügen Sie Gaußsches oder Laplace-Rauschen zu Trainingsdaten, Modellgradienten oder endgültigen Vorhersagen hinzu, um einzelne Datenbeiträge zu verschleiern.
Verwenden Sie Frameworks wie TensorFlow Privacy oder PySyft, um Differential Privacy in der Praxis anzuwenden.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Sichere Modellbereitstellung
Mandanten-Isolierung
In einer Umgebung mit mehreren Mandanten wird durch die Mandantenisolation eine logische oder physische Grenze zwischen den einzelnen Mandanten geschaffen's Daten, die es einem Mieter unmöglich machen, auf einen anderen zuzugreifen oder ihn zu manipulieren'sensiblen Informationen zu übermitteln. Durch Isolierung jedes Mieters'können Unternehmen unbefugten Zugriff verhindern, das Risiko von Datenschutzverletzungen verringern und die Einhaltung von Datenschutzbestimmungen sicherstellen.
Die Mandantenisolation bietet eine zusätzliche Sicherheitsebene, die Unternehmen die Gewissheit gibt, dass ihre sensible KI-Trainingsdaten ist vor möglichen Lecks oder unbefugtem Zugriff geschützt.
Bewährte Methoden:
Logische Trennung: Verwenden Sie Virtualisierungstechniken wie Container oder virtuelle Computer (VMs), um sicherzustellen, dass die Daten und die Verarbeitung der einzelnen Mandanten voneinander isoliert sind.
Zugriffskontrollen: Implementieren Sie strenge Zugriffskontrollrichtlinien, um sicherzustellen, dass jeder Mandant nur auf seine eigenen Daten und Ressourcen zugreifen kann.
Verschlüsselung und Schlüsselverwaltung: Verwenden Sie mandantenspezifische Verschlüsselungsschlüssel, um Daten weiter zu trennen und sicherzustellen, dass auch im Falle eines Verstoßes die Daten anderer Mandanten sicher bleiben.
Ressourcendrosselung und -überwachung: Verhindern Sie, dass Mandanten freigegebene Ressourcen erschöpfen, indem Sie Ressourcenlimits erzwingen und auf anomales Verhalten überwachen, das die Isolation des Systems beeinträchtigen könnte.
Bereinigung der Ausgabe
Die Ausgabebereinigung umfasst die Implementierung von Überprüfungen und Filtern für Modellausgaben, um die versehentliche Offenlegung sensibler Daten zu verhindern, insbesondere bei der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) und generativen Modellen.
In einigen Fällen kann das Modell vertrauliche Informationen reproduzieren, auf die es während des Trainings gestoßen ist (z. B. Namen oder Kreditkartennummern). Durch die Bereinigung der Ausgänge wird sichergestellt, dass keine sensiblen Daten offengelegt werden.
Bewährte Methoden:
Verwenden Sie Mustervergleichsalgorithmen, um personenbezogene Daten (z. B. E-Mail-Adressen, Telefonnummern) in Modellausgaben zu identifizieren und zu schwärzen.
Legen Sie Schwellenwerte für probabilistische Ausgaben fest, um zu verhindern, dass das Modell übermäßig zuverlässige Vorhersagen trifft, die vertrauliche Details offenlegen könnten.
4. Organisatorische Praktiken
Schulung der Mitarbeiter
Mitarbeiterschulungen stellen sicher, dass alle Personen, die an der Entwicklung, Bereitstellung und Wartung von KI-Modellen beteiligt sind, die Risiken von Datenlecks und die Best Practices zu deren Minderung verstehen. Viele Datenschutzverletzungen treten aufgrund von menschlichem Versagen oder Versehen auf. Durch ein ordnungsgemäßes Training kann die versehentliche Offenlegung vertraulicher Informationen verhindert oder Schwachstellen modelliert werden.
Bewährte Methoden:
Bieten Sie regelmäßige Schulungen zu Cybersicherheit und Datenschutz für alle Mitarbeiter an, die mit KI-Modellen und sensiblen Daten umgehen.
Informieren Sie Ihre Mitarbeiter über aufkommende KI-Sicherheitsrisiken und neue Präventionsmaßnahmen.
Data-Governance-Richtlinien
Data-Governance-Richtlinien legen klare Richtlinien für die Erfassung, Verarbeitung, Speicherung und den Zugriff auf Daten im gesamten Unternehmen fest und stellen sicher, dass Sicherheitspraktiken konsistent angewendet werden.
Eine klar definierte Governance-Richtlinie stellt sicher, dass die Datenverarbeitung standardisiert und konform mit Datenschutzgesetzen wie DSGVO oder HIPAA ist, wodurch die Wahrscheinlichkeit von Lecks verringert wird.
Bewährte Methoden:
Definieren Sie das Dateneigentum und legen Sie klare Protokolle für den Umgang mit sensiblen Daten in jeder Phase der KI-Entwicklung fest.
Überprüfen und aktualisieren Sie regelmäßig Governance-Richtlinien, um neue Risiken und regulatorische Anforderungen widerzuspiegeln.
5. Nutzung von KI-Tools für das Security Posture Management (KI-SPM)
KI-SPM-Lösungen Bieten Sie Transparenz und Kontrolle über kritische Komponenten der KI-Sicherheit, einschließlich der Daten, die für das Training/die Inferenz, die Modellintegrität und den Zugriff auf bereitgestellte Modelle verwendet werden. Durch die Integration eines KI-SPM-Tools können Unternehmen die Sicherheitslage ihrer KI-Modelle proaktiv verwalten, das Risiko von Datenlecks minimieren und eine robuste KI-Systemverwaltung gewährleisten.
Wie KI-SPM hilft, ML-Modelllecks zu verhindern:
Ermitteln und inventarisieren Sie alle KI-Anwendungen, -Modelle und -zugehörigen Ressourcen
Identifizieren Sie Schwachstellen in der KI-Lieferkette und Fehlkonfigurationen, die zu Datenlecks führen könnten
Überwachung sensibler Daten im gesamten KI-Stack, einschließlich Trainingsdaten, Bibliotheken, APIs und Datenpipelines
Erkennen Sie Anomalien und potenzielle Datenlecks in Echtzeit
Implementieren Sie Leitplanken und Sicherheitskontrollen, die speziell auf KI-Systeme zugeschnitten sind
Durchführung regelmäßiger Audits und Assessments von KI-Anwendungen


Wie Wiz helfen kann
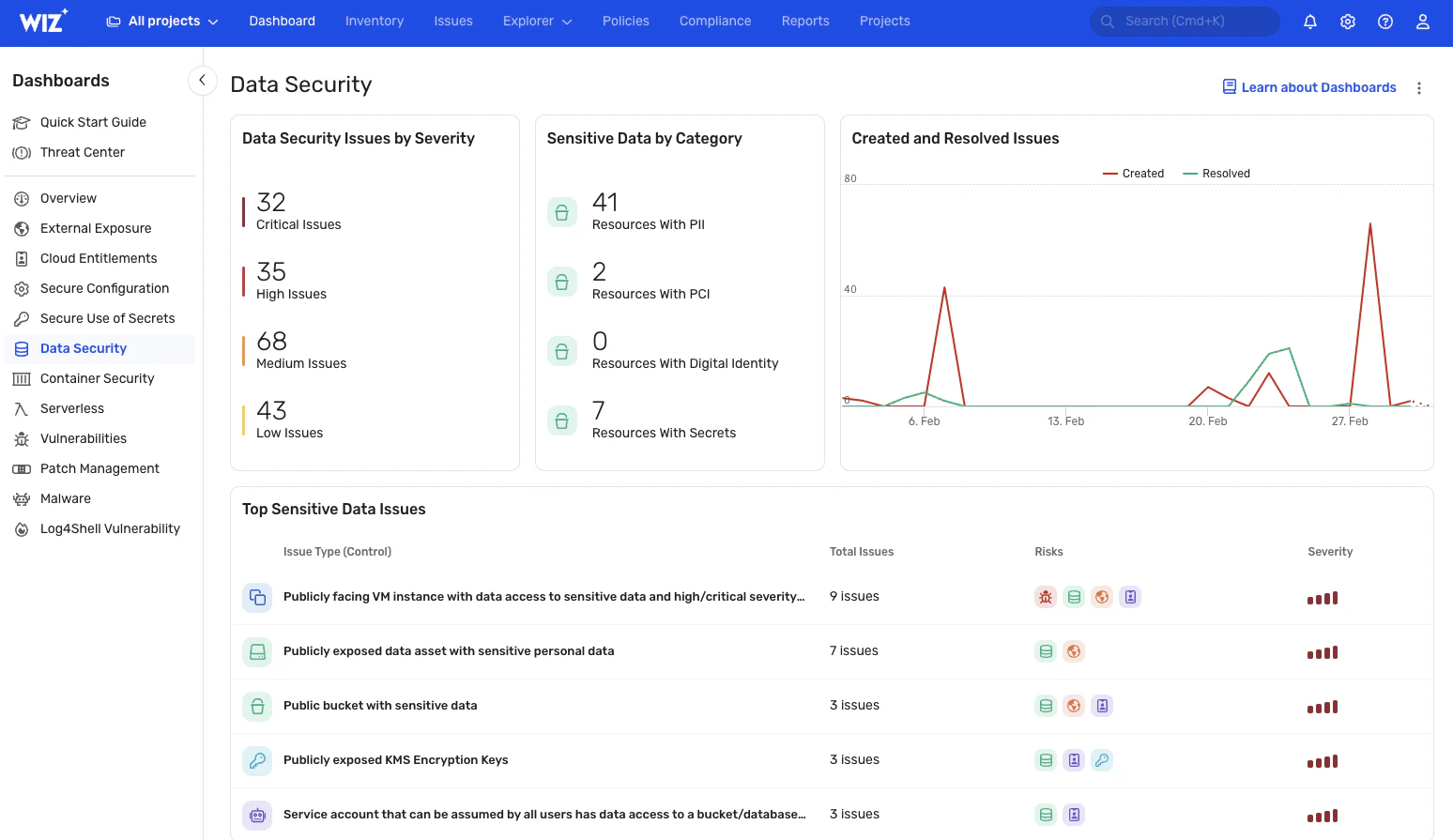
Mit seinem umfassenden Data Security Posture Management (DSPM) hilft Wiz auf folgende Weise, Datenlecks zu verhindern und zu erkennen.
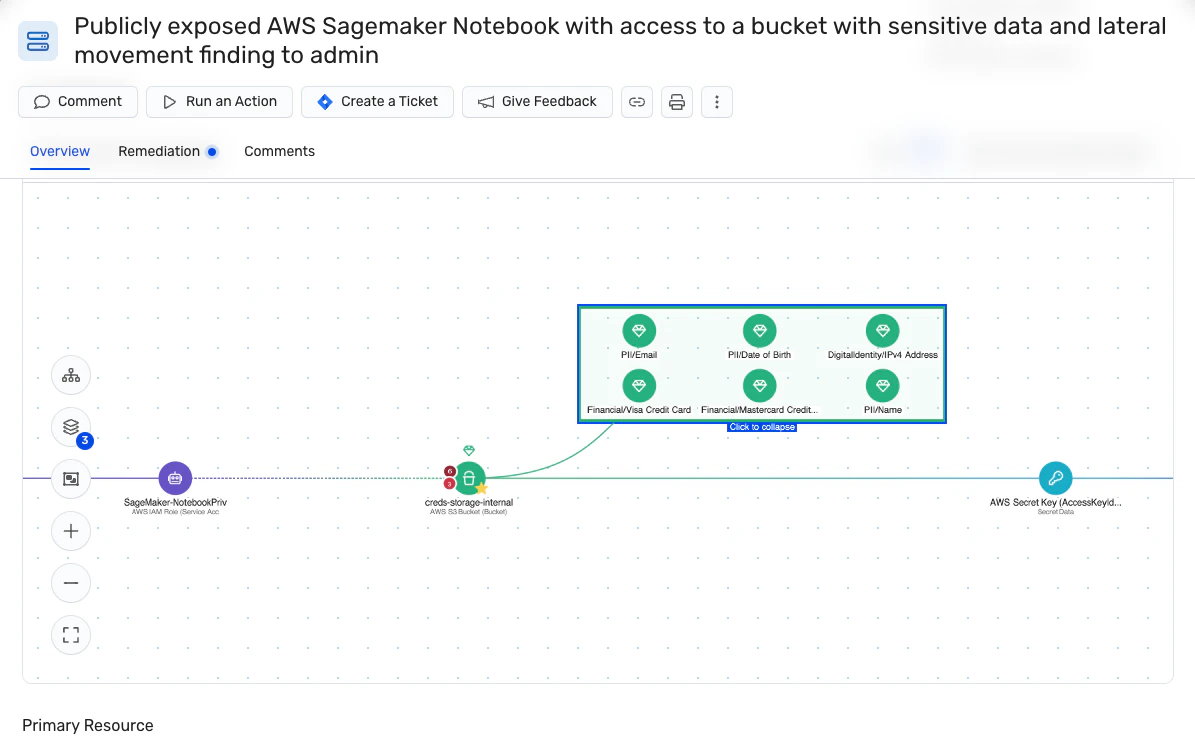
Automatisches Erkennen und Klassifizieren von Daten
Wiz überwacht kontinuierlich die Offenlegung kritischer Daten und bietet Echtzeit-Einblick in sensible Informationen wie PII-, PHI- und PCI-Daten. Es bietet einen aktuellen Überblick darüber, wo sich Daten befinden und wie auf sie zugegriffen wird (auch in Ihren KI-Systemen mit unserem KI-SPM-Lösung). Sie können auch benutzerdefinierte Klassifikatoren erstellen, um vertrauliche Daten zu identifizieren, die für Ihr Unternehmen einzigartig sind. Diese Funktionen ermöglichen eine schnelle Reaktion auf Sicherheitsvorfälle, wodurch Schäden ganz vermieden oder der potenzielle Explosionsradius erheblich minimiert wird.
Bewertung des Datenrisikos
Wiz erkennt Angriffspfade, indem es die Datenergebnisse mit Schwachstellen, Fehlkonfigurationen, Identitäten und Schwachstellen korreliert, die ausgenutzt werden können. Sie können diese Expositionspfade dann abschalten, bevor sie von Bedrohungsakteuren ausgenutzt werden können. Wiz visualisiert und priorisiert auch Expositionsrisiken basierend auf ihren Auswirkungen und ihrem Schweregrad, um sicherzustellen, dass die kritischsten Probleme zuerst behandelt werden.
Darüber hinaus unterstützt Wiz die Data Governance, indem es erkennt und anzeigt, wer auf welche Daten zugreifen kann.
Datensicherheit für KI-Trainingsdaten
Wiz bietet eine vollständige Risikobewertung Ihrer Datenbestände, einschließlich der Möglichkeit von Datenlecks, mit sofort einsatzbereiten DSPM-KI Steuerung. Unsere Tools bieten einen ganzheitlichen Überblick über die Datensicherheit Ihres Unternehmens, heben Bereiche hervor, die Aufmerksamkeit erfordern, und bieten detaillierte Anleitungen, um Ihre Sicherheitsmaßnahmen zu stärken und Probleme schnell zu beheben.
Kontinuierliche Compliance-Bewertung
Die kontinuierliche Compliance-Bewertung von Wiz stellt sicher, dass Ihr Unternehmen'Die Sicherheitslage des Unternehmens entspricht in Echtzeit den Branchenstandards und gesetzlichen Anforderungen. Unsere Plattform sucht nach Fehlkonfigurationen und Schwachstellen, gibt umsetzbare Empfehlungen zur Behebung und automatisiert die Compliance-Berichterstattung.
Mit Genie DSPM-Funktionen und -Funktionen können Sie Ihrem Unternehmen effektiv dabei helfen, die Risiken von Datenlecks zu mindern und eine robuste Datenschutz und Compliance. Buchen Sie eine Demo heute, um mehr zu erfahren.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
