¿Qué es el LLM Jacking?
El LLM jacking es una técnica de ataque que los ciberdelincuentes utilizan para manipular y explotar los LLM (grandes modelos de lenguaje) basados en la nube de una empresa. El secuestro de LLM implica robar y vender credenciales de cuentas en la nube para permitir el acceso malicioso a los LLM de una empresa, mientras que la víctima, sin saberlo, cubre los costos de consumo.
Nuestro investigación muestra que 7 de cada 10 empresas aprovechan los servicios de inteligencia artificial (IA), incluidas las ofertas de IA generativa (GenAI) de proveedores de la nube, como Amazon Bedrock y Creador de Sage., Google Vertex AI y Azure OpenAI Service. Estos servicios proporcionan a los desarrolladores acceso a modelos LLM como Claude, Jurassic-2, la serie GPT, DALL-E, OpenAI Codex, Amazon Titan y Stable Diffusion. Al vender el acceso a los modelos de LLM, los ciberdelincuentes pueden iniciar un efecto dominó dañino en múltiples pilares de la organización.
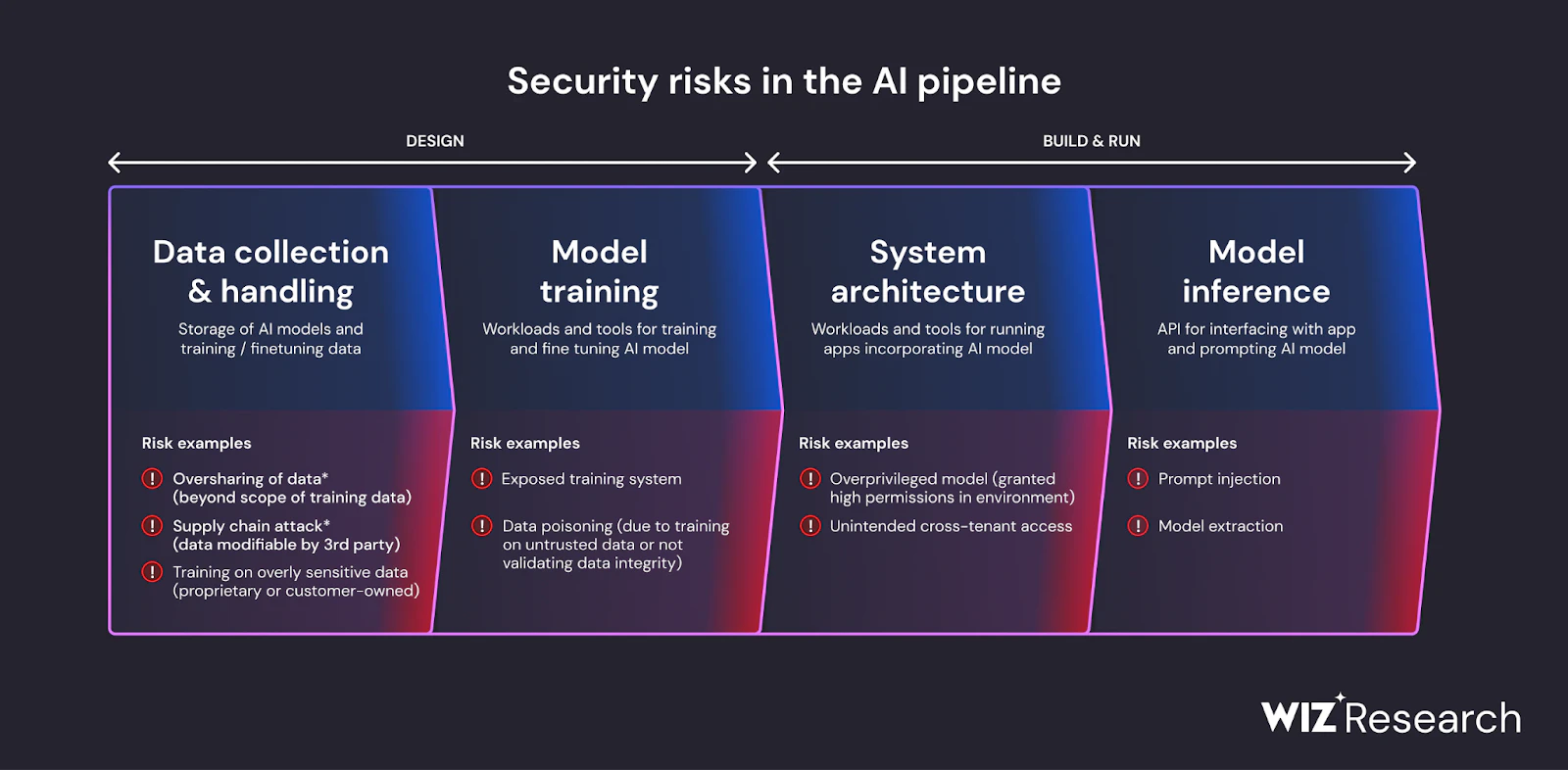
Si bien los actores de amenazas pueden llevar a cabo ataques de secuestro de LLM para robar datos ellos mismos, a menudo venden acceso de LLM a una red más grande de ciberdelincuentes. Esto es aún más peligroso porque amplía el alcance y la escala de los posibles ataques. Al secuestrar los LLM de una empresa, cualquier ciberdelincuente que compre credenciales de LLM basadas en la nube puede orquestar ataques únicos.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

¿Cuáles son las posibles consecuencias de un ataque de jacking LLM?
Aumento de los costes de consumo
Cuando los ciberdelincuentes llevan a cabo ataques de LLM jacking, los costes de consumo excesivos son la primera repercusión. Esto se debe a que los servicios GenAI y LLM basados en la nube, por muy beneficiosos que sean, pueden ser bastante costosos para las empresas. Por lo tanto, cuando los adversarios venden el acceso a estos servicios y permiten el uso encubierto y malicioso, los costos pueden acumularse. Según Investigadores, los ataques de jacking de LLM pueden resultar en costos de consumo de hasta $46,000 por día. Esta cantidad puede fluctuar en función de los modelos de precios de LLM.
Militarización de los LLM empresariales
Si los modelos de LLM de una empresa carecen de integridad o no cuentan con barreras de seguridad sólidas, pueden generar resultados perjudiciales. Al secuestrar modelos de LLM específicos de la organización o arquitecturas de LLM de ingeniería inversa, los adversarios pueden utilizar el ecosistema GenAI de una empresa como arma para ataques y actividades maliciosas. Por ejemplo, mediante la manipulación de los LLM empresariales, los actores de amenazas pueden hacer que generen salidas falsas o maliciosas para casos de uso de backend y de cara al cliente. Las empresas pueden tardar un tiempo en identificar este tipo de secuestro, momento en el que el daño suele estar hecho.
Exacerbación de las vulnerabilidades de LLM existentes
La adopción de LLM presenta desafíos de seguridad inherentes. Según OWASP, las 10 principales vulnerabilidades de LLM incluyen inyección rápida, envenenamiento de datos de entrenamiento, denegación de servicio de modelos, divulgación de información confidencial, agencia excesiva, dependencia excesiva y robo de modelos. Cuando los ciberdelincuentes utilizan ataques de jacking de LLM, exacerban significativamente los riesgos y vulnerabilidades inherentes asociados con los LLM.
Efecto de nevada de alto nivel
Teniendo en cuenta la rapidez con la que las empresas están incorporando GenAI y LLM en contextos de misión crítica, los ataques de jacking de LLM pueden tener graves implicaciones a alto nivel y a largo plazo. Por ejemplo, el secuestro de LLM puede expandir la superficie de ataque de una empresa, lo que resulta en violaciones de datos y otras vulnerabilidades importantes.
Además, dado que el dominio de la IA es una métrica de reputación crítica para las empresas de hoy en día, los ataques de LLM jacking pueden causar una pérdida de confianza y respeto por parte de los compañeros y del público. No olvide las devastadoras consecuencias financieras del secuestro de LLM, que incluyen márgenes de beneficio más bajos, pérdida de datos, costos de tiempo de inactividad y honorarios legales.
¿Cómo funcionan los ataques de jacking de LLM?
En principio, el jacking de LLM es similar a ataques como Cryptojacking (Secuestro de criptomonedas), donde los actores de amenazas minan criptomonedas en secreto utilizando la potencia de procesamiento de una empresa. En ambos casos, los actores de amenazas utilizan los recursos y la infraestructura de una organización en su contra. Sin embargo, con los ataques de LLM jacking, el punto de mira de los hackers está firmemente en los servicios de LLM alojados en la nube y los propietarios de cuentas en la nube.
Para entender cómo funciona el jacking LLM, veámoslo desde dos perspectivas. En primer lugar, exploraremos cómo las empresas utilizan los LLM y, a continuación, pasaremos a ver cómo los explotan los actores de amenazas.
¿Cómo interactúan las empresas con los servicios de LLM alojados en la nube?
La mayoría de los proveedores de nube proporcionan a las empresas una interfaz fácil de usar y funciones sencillas diseñadas para la adopción ágil de LLM. Sin embargo, estos modelos de terceros no están listos para su uso automáticamente. En primer lugar, requieren activación.
Para activar los LLM, los desarrolladores deben realizar una solicitud a sus proveedores de nube. Los desarrolladores pueden realizar solicitudes de diferentes maneras, incluso a través de formularios de solicitud simples. Una vez que los desarrolladores envían estos formularios de solicitud, los proveedores de la nube pueden activar rápidamente los servicios de LLM. Después de la activación, los desarrolladores pueden interactuar con sus LLM basados en la nube mediante comandos de la interfaz de línea de comandos (CLI).
Tenga en cuenta que el proceso de envío de un formulario de solicitud de activación a un proveedor de nube no está protegido por una capa de seguridad a prueba de balas. Los actores de amenazas pueden hacer lo mismo fácilmente, por lo que las empresas deben centrarse en tipos adicionales de seguridad de IA y LLM.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

¿Cómo llevan a cabo los actores de amenazas los ataques de jacking LLM?
Ahora que comprende cómo las empresas suelen interactuar con los servicios de LLM alojados en la nube, veamos cómo los actores de amenazas facilitan los ataques de LLM jacking.
Estos son los pasos que siguen los actores de amenazas para orquestar un ataque de jacking de LLM:
Para vender credenciales en la nube, los actores de amenazas deben robarlas primero. Cuando los investigadores descubrieron por primera vez las técnicas de ataque de jacking de LLM, rastrearon las credenciales robadas hasta un sistema que utilizaba una versión vulnerable de Laravel.CVE-2021-3129).
Una vez que un actor de amenazas roba credenciales de un sistema vulnerable, puede venderlas en mercados ilícitos a otros ciberdelincuentes que pueden comprarlas y aprovecharlas para ataques más avanzados.
Con credenciales robadas en la nube, los actores de amenazas deben evaluar su acceso y privilegios administrativos. Para evaluar sigilosamente los límites de sus privilegios de acceso a la nube, los ciberatacantes pueden aprovechar la
InvokeModel APIllamar.A pesar de que el
InvokeModel APIes una solicitud válida, los actores de amenazas pueden provocar un error "ValidationException" configurando el parámetromax_tokens_to_samplea -1. Este paso es simplemente para determinar si las credenciales robadas pueden acceder a los servicios de LLM. Por el contrario, si aparece un error "AccessDenied", los actores de amenazas saben que las credenciales robadas no'Tienen privilegios de acceso aprovechables.
Los adversarios también pueden invocar GetModelInvocationLoggingConfiguration para determinar los ajustes de configuración de los servicios de IA alojados en la nube de una empresa. Recuerde que este paso depende de las barreras de protección y las capacidades de los proveedores y servicios de nube individuales. Es por eso que, en algunos casos, los actores de amenazas pueden no tener una visibilidad completa de las entradas y salidas de LLM de una empresa.
Llevar a cabo un ataque de jacking de LLM no garantiza la monetización de los actores de amenazas. Sin embargo, hay algunas formas en que los actores de amenazas pueden asegurarse de que el secuestro de LLM sea rentable. Durante una autopsia de un ataque de jacking de LLM, los investigadores descubrieron que los adversarios pueden utilizar potencialmente el servidor de proxy inverso OAI de código abierto como un panel centralizado para gestionar las credenciales robadas en la nube con privilegios de acceso a LLM.
Una vez que los actores de amenazas monetizan sus ataques de LLM jacking y venden el acceso a los modelos de LLM de una empresa, no hay forma de predecir el tipo de daño que puede producirse. Otros adversarios de diferentes orígenes y con diversos motivos pueden comprar acceso a LLM y utilizar la infraestructura GenAI de una empresa sin su conocimiento. Si bien las consecuencias de los ataques de LLM jacking pueden permanecer inicialmente ocultas, las consecuencias pueden ser catastróficas.


Tácticas de prevención y detección de hincas LLM
Estas son algunas formas poderosas en que las empresas pueden protegerse de los ataques de LLM jacking:
Tácticas de prevención
Entrenamiento de modelos robustos:
Conjuntos de datos diversos y de alta calidad: asegúrese de que el modelo se entrene con una amplia gama de datos para evitar sesgos y vulnerabilidades.
Entrenamiento de adversarios: exponga el modelo a entradas maliciosas para mejorar su resistencia.
Aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF): Alinear el modelo's con los valores y expectativas humanas.
Validación estricta de entradas:
Filtrado: implemente filtros para bloquear avisos dañinos o malintencionados.
Desinfección: Limpie las entradas para eliminar elementos potencialmente dañinos.
Limitación de velocidad: limite el número de solicitudes para evitar abusos.
Auditoría periódica de modelos:
Evaluaciones de vulnerabilidad: Identificar posibles debilidades en el modelo.
Detección de sesgos: supervise los sesgos no deseados en el modelo's salidas.
Supervisión del rendimiento: realice un seguimiento del rendimiento del modelo a lo largo del tiempo para detectar anomalías.
Documentación transparente del modelo:
Pautas claras: Proporcione instrucciones claras sobre cómo usar el modelo de manera responsable.
Limitaciones: Comunicar el modelo'limitaciones y posibles sesgos.
Aprendizaje continuo y adaptación:
Manténgase informado: Manténgase actualizado sobre las últimas amenazas y contramedidas de LLM.
Actualizaciones del modelo: actualice periódicamente el modelo para abordar nuevas vulnerabilidades.
Tácticas de detección
Detección de anomalías:
Identificación de valores atípicos: identifique comportamientos inusuales o inesperados del modelo.
Análisis estadístico: Utilice métodos estadísticos para detectar desviaciones de los patrones normales.
Monitoreo de contenido:
Filtrado de palabras clave: supervise las salidas de palabras clave o frases específicas asociadas con contenido dañino.
Análisis de sentimientos: Analice el sentimiento del contenido generado para identificar posibles problemas.
Análisis de estilo: Detectar anomalías en el estilo de escritura del contenido generado.
Análisis del comportamiento del usuario:
Patrones inusuales: identifique el comportamiento anormal del usuario, como solicitudes rápidas o avisos repetitivos.
Supervisión de cuentas: supervise las cuentas de usuario en busca de actividades sospechosas.
Verificación human-in-the-loop:
Aseguramiento de la calidad: Emplee revisores humanos para evaluar la calidad y la seguridad del contenido generado.
Mecanismos de retroalimentación: recopile comentarios de los usuarios para identificar posibles problemas.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

Cómo Wiz puede prevenir los ataques de jacking de LLM
La innovadora solución de herramientas AI-SPM de Wiz puede ayudar a prevenir y mitigar los ataques de LLM jacking para que no se conviertan en desastres a gran escala. Wiz AI-SPM puede ayudar a defenderse contra el jacking de LLM de varias maneras:
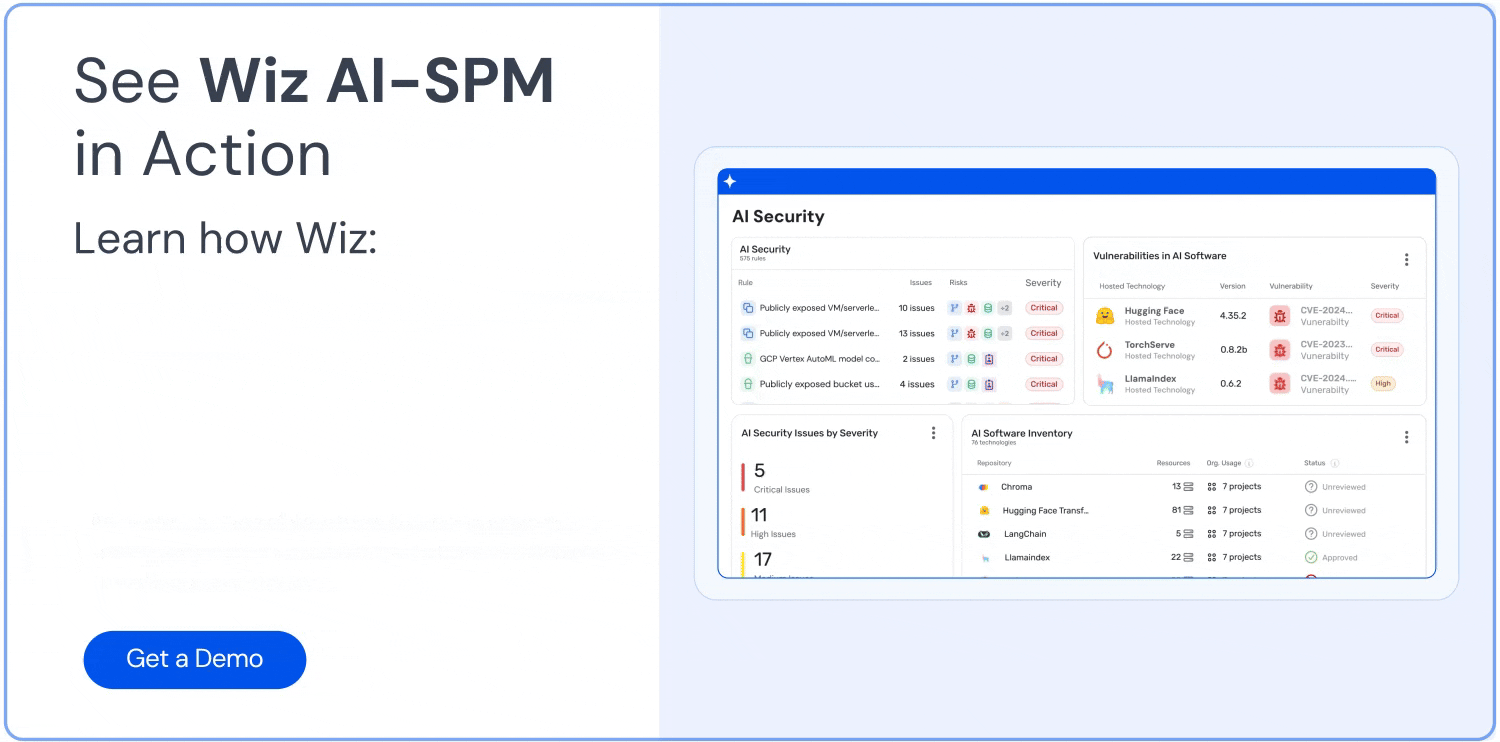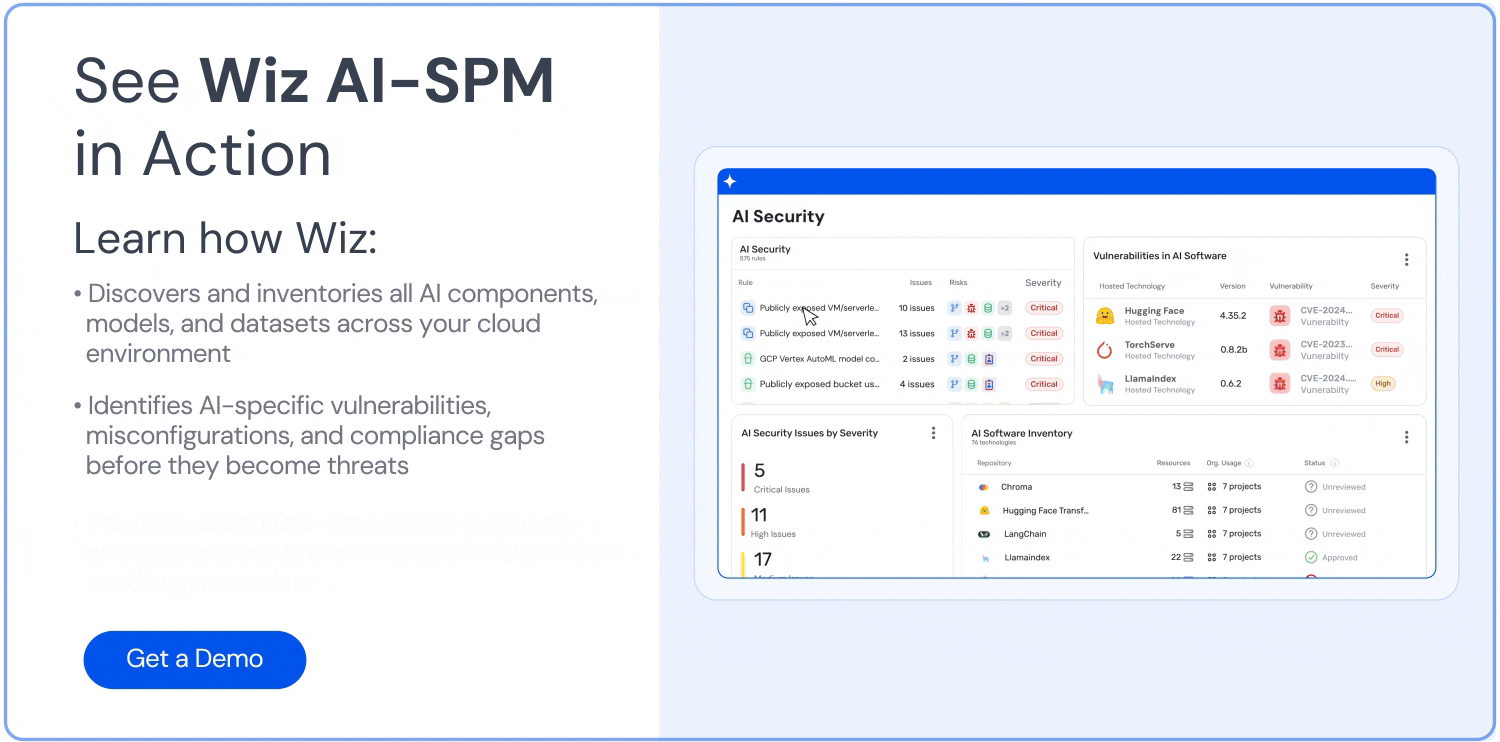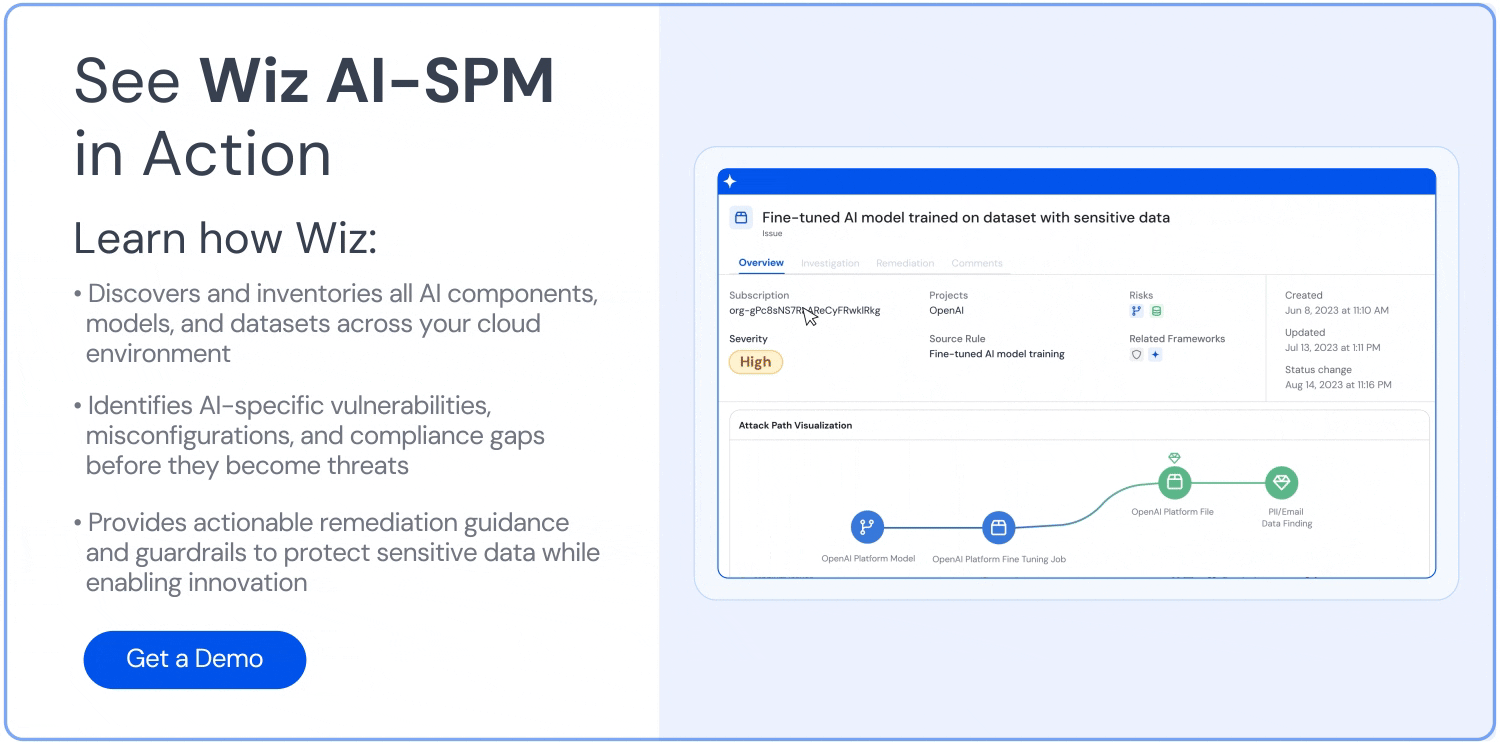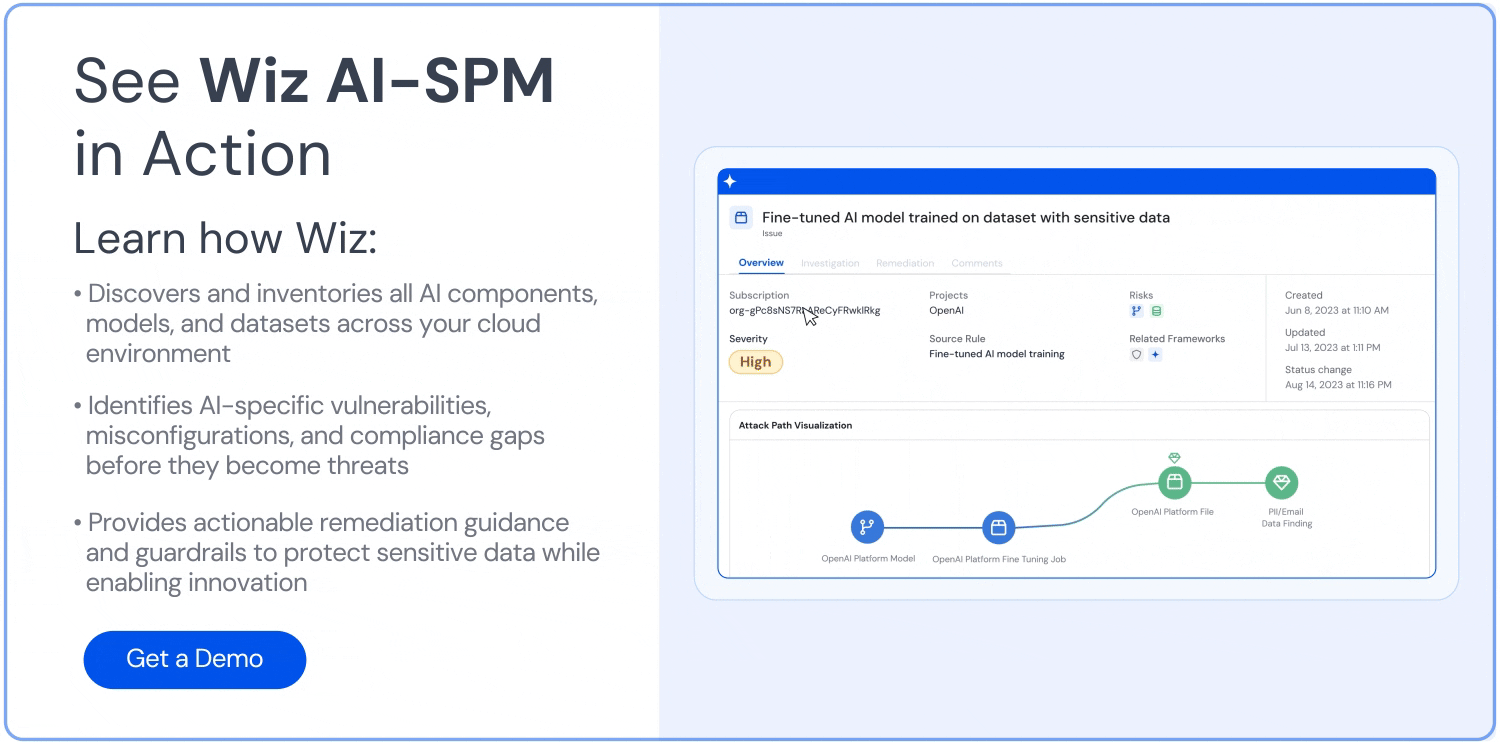
Visibilidad integral: Wiz AI-SPM proporciona visibilidad de pila completa de las canalizaciones de IA, incluidos los servicios, tecnologías y SDK de IA, sin necesidad de ningún agente. Esta visibilidad ayuda a las organizaciones a detectar y supervisar todos los componentes de IA de su entorno, incluidos los LLM, lo que dificulta que los atacantes exploten datos desconocidos o IA en la sombra Recursos.
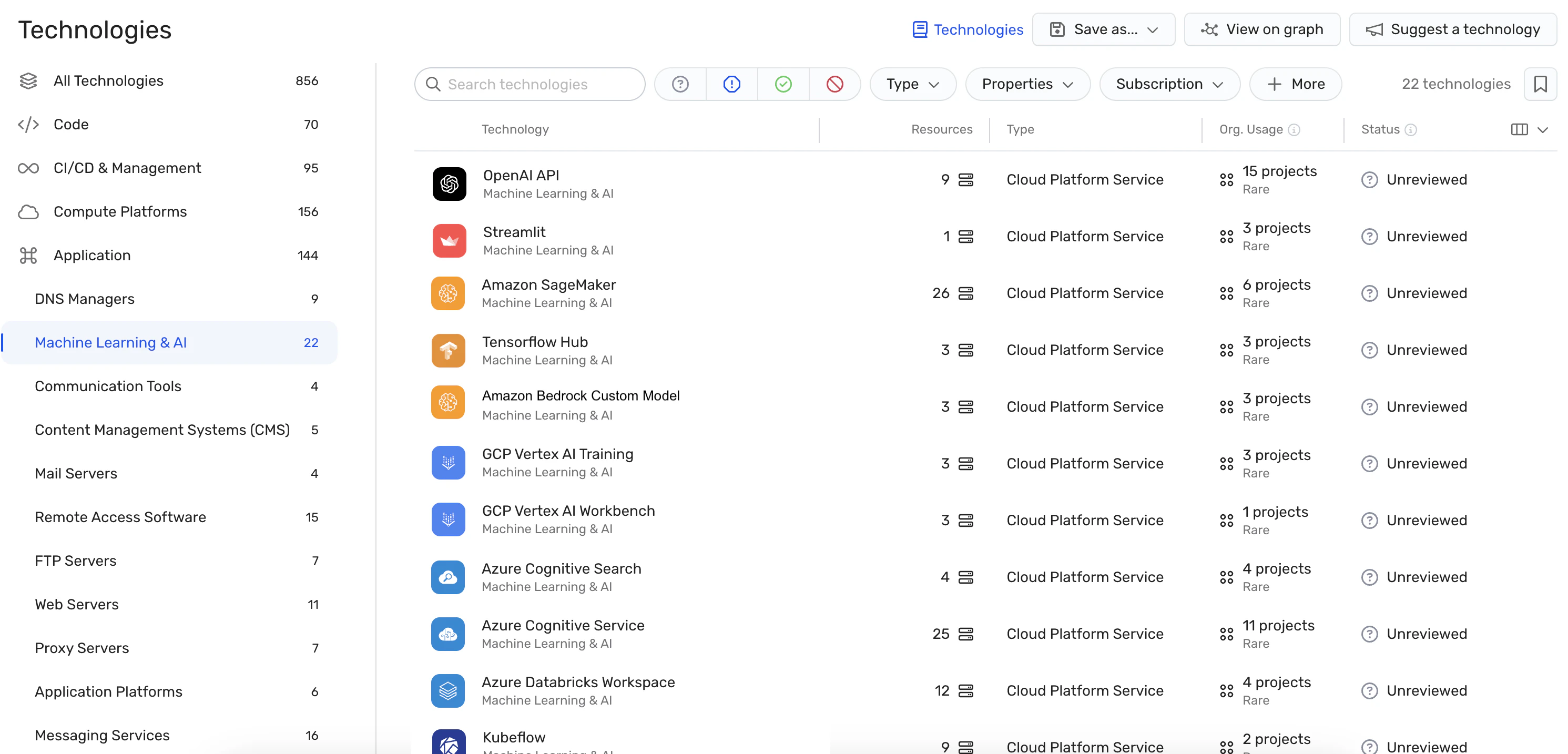
Detección de errores de configuración: La plataforma hace cumplir Mejores prácticas de seguridad de IA mediante la detección de errores de configuración en los servicios de IA con reglas integradas. Esto puede ayudar a prevenir vulnerabilidades que podrían explotarse en ataques de jacking de LLM.
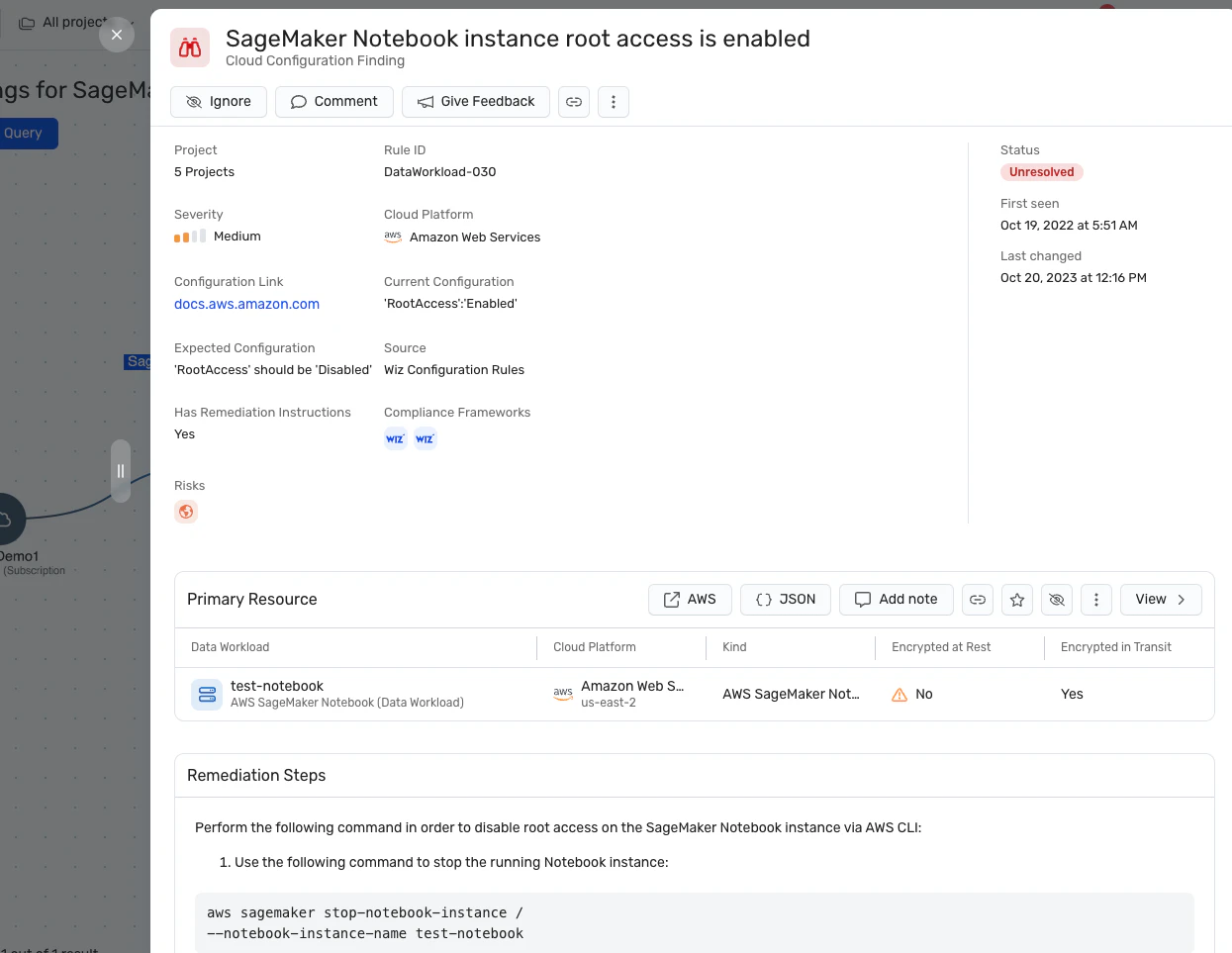
Análisis de la ruta de ataque: Wiz AI-SPM identifica y elimina de forma proactiva las rutas de ataque a los modelos de IA mediante la evaluación de vulnerabilidades, identidades, exposiciones a Internet, datos, configuraciones incorrectas y secretos. Este análisis exhaustivo puede ayudar a prevenir posibles puntos de entrada para los intentos de elevación de LLM.
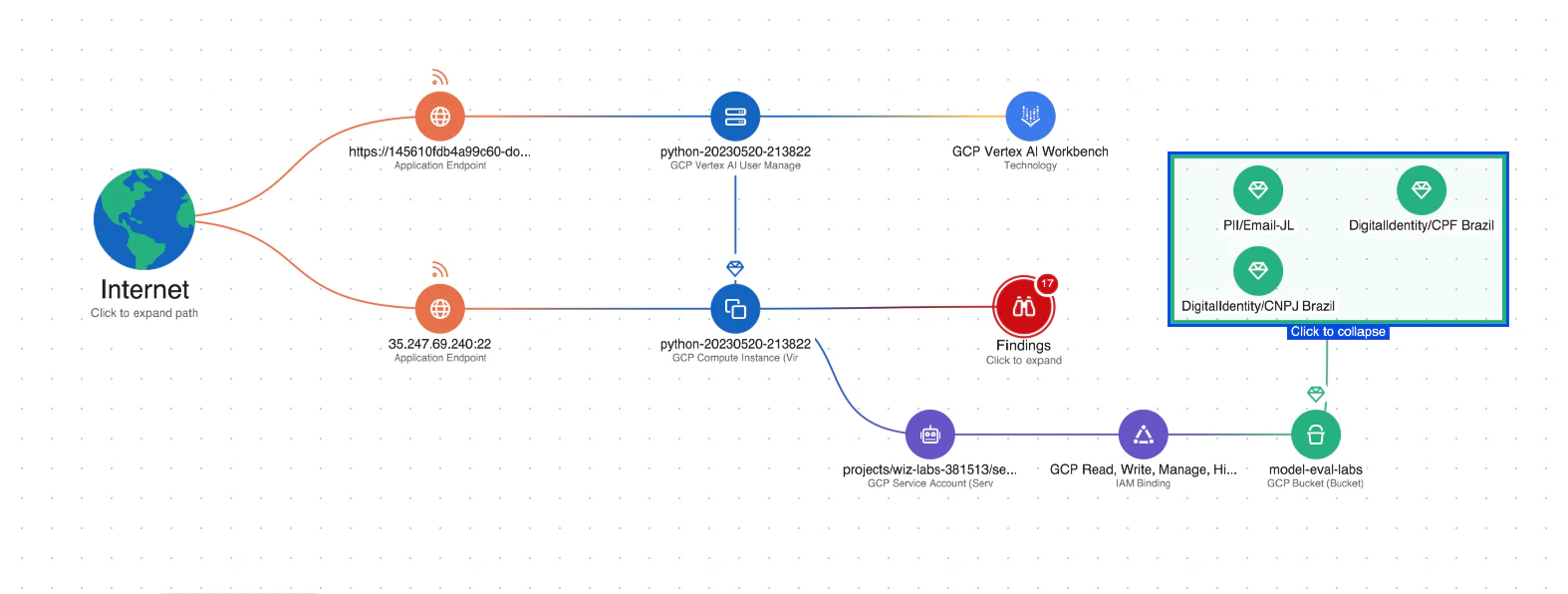
Seguridad de los datos para la IA: La plataforma incluye la gestión de la postura de seguridad de los datos (DSPM) específicamente para la IA, que puede detectar automáticamente datos de entrenamiento confidenciales y eliminar las rutas de ataque hacia ellos. Esto ayuda a protegerse contra Fuga de datos que podrían usarse en ataques de jacking LLM.
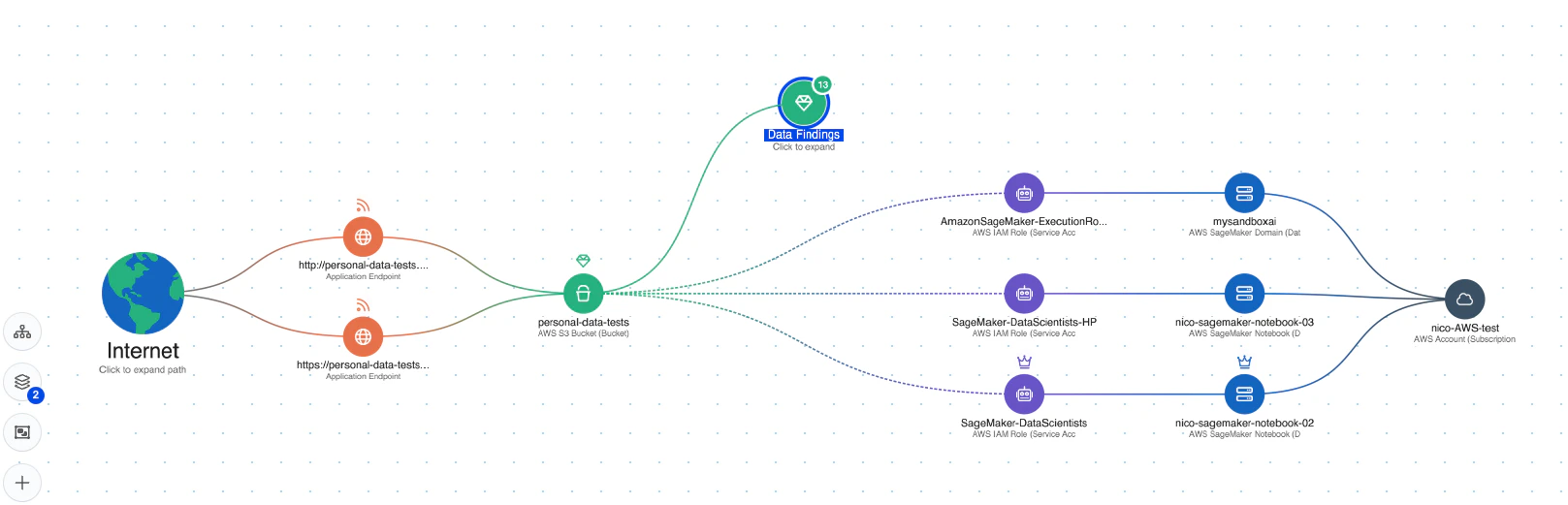
Detección de amenazas en tiempo real: Wiz AI-SPM ofrece protección en tiempo de ejecución contra comportamientos sospechosos que se originan en modelos de IA. Esta capacidad puede ayudar a detectar y responder a los intentos de elevación de LLM en tiempo real, minimizando el impacto potencial.
Escaneo de modelos: La plataforma admite la identificación y el escaneo de modelos de IA alojados, lo que permite a las organizaciones detectar modelos maliciosos que podrían usarse en ataques de LLM jacking. Esto es particularmente importante para las organizaciones que autoalojan modelos de IA, ya que ayuda a abordar los riesgos de la cadena de suministro asociados con los modelos de código abierto.
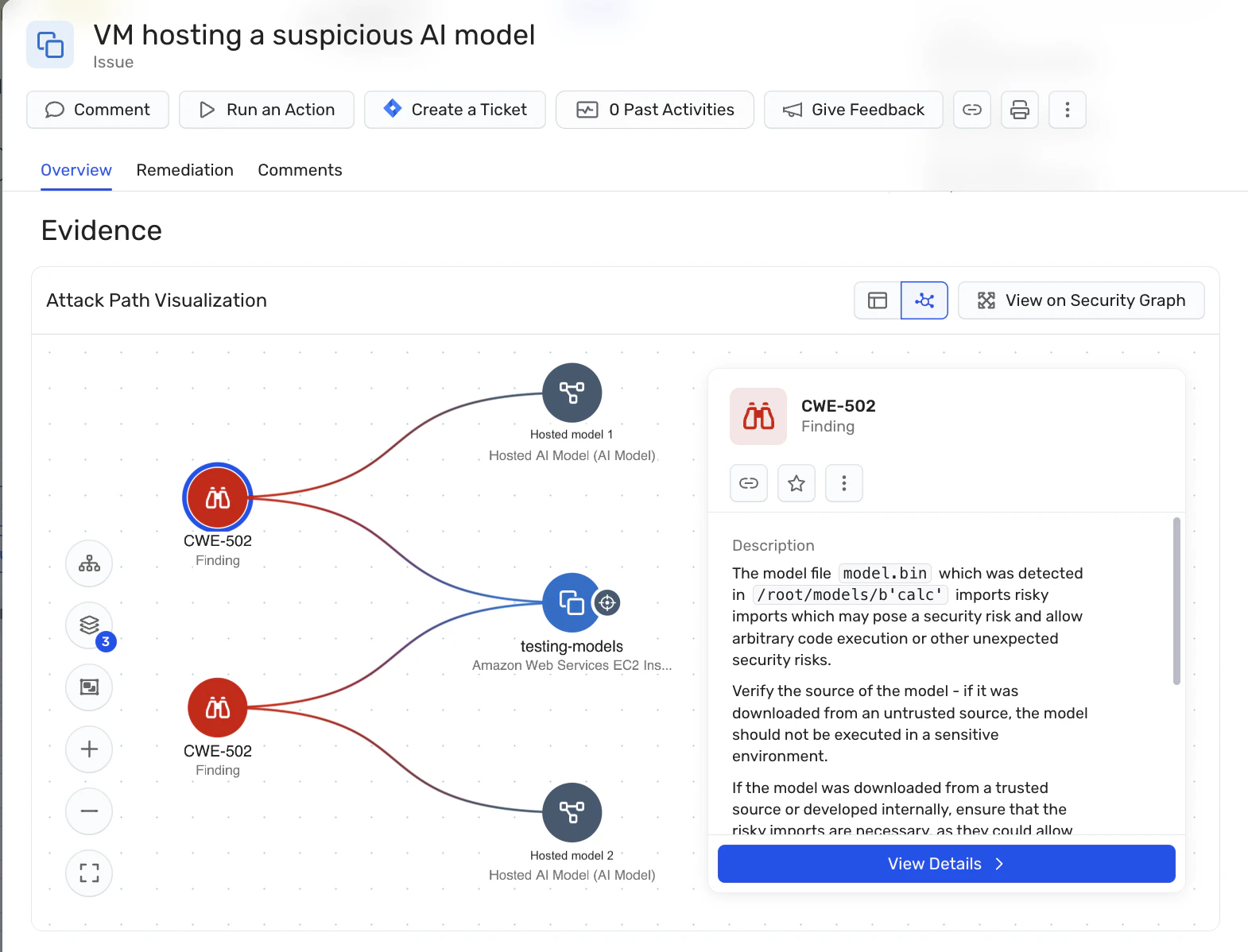
Panel de seguridad de IA: Wiz AI-SPM proporciona un panel de seguridad de IA que ofrece una visión general de la postura de seguridad de la IA con una cola de riesgos priorizada. Esto ayuda a los desarrolladores de IA y a los equipos de seguridad a centrarse rápidamente en los problemas más críticos, incluidas las vulnerabilidades que podrían conducir al secuestro de LLM.
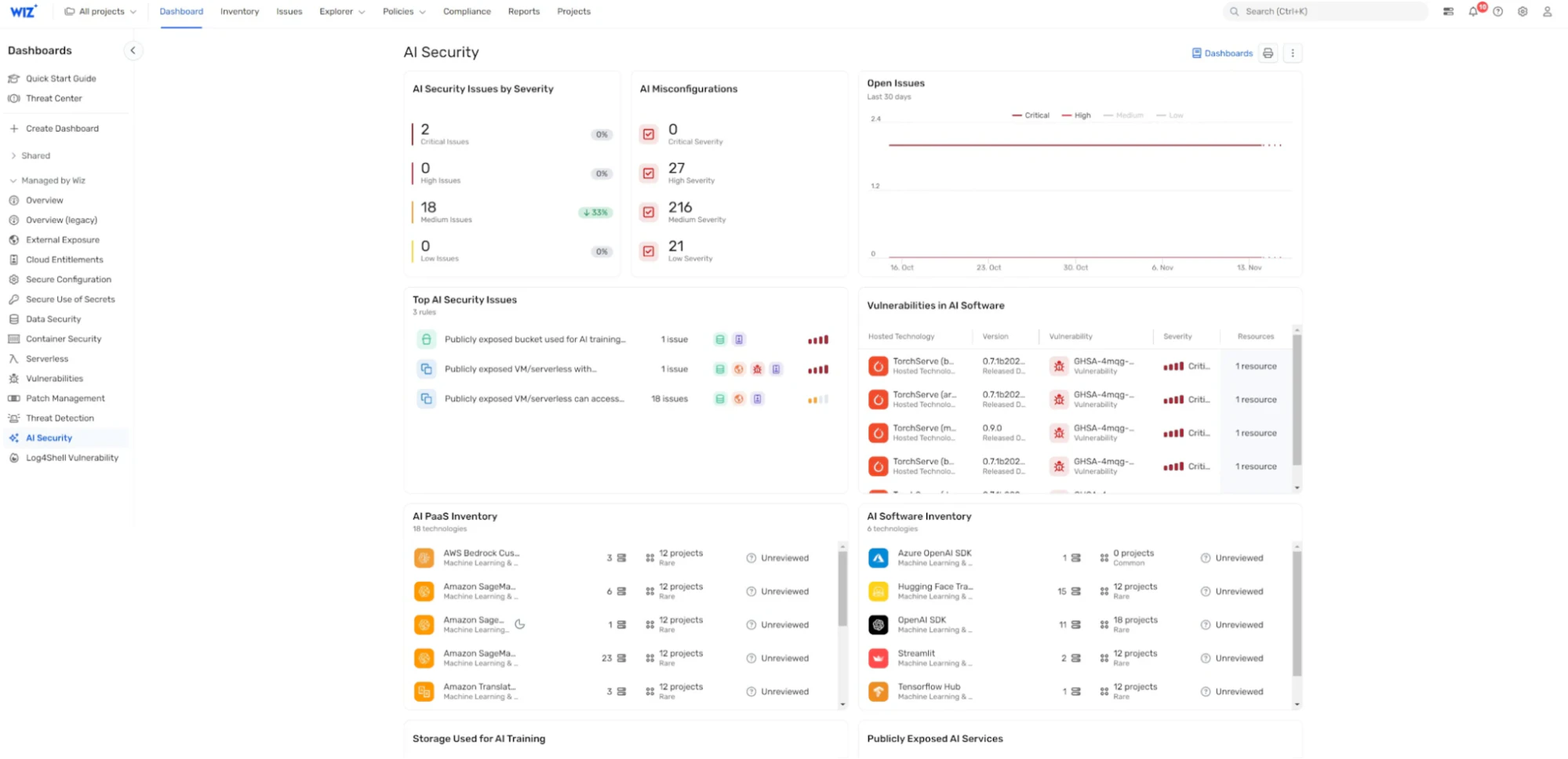
Al implementar estas características, Wiz AI-SPM ayuda a las organizaciones a mantener una sólida postura de seguridad para sus sistemas de IA, lo que dificulta que los atacantes ejecuten con éxito ataques de LLM jacking y otras amenazas relacionadas con la IA.