



¿Qué es la fuga de datos?
La fuga de datos es la exfiltración incontrolada de datos de la organización a un tercero. Se produce a través de varios medios, como bases de datos mal configuradas, servidores de red mal protegidos, ataques de phishing o incluso un manejo de datos descuidado.
La fuga de datos puede ocurrir accidentalmente: El 82% de todas las organizaciones Dar a terceros un amplio acceso de lectura a sus entornos, lo que plantea importantes riesgos de seguridad y graves problemas de privacidad. Sin embargo, la fuga de datos también se produce debido a actividades maliciosas, como la piratería, el phishing o las amenazas internas en las que los empleados roban datos intencionadamente.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

Posibles impactos de la fuga de datos
La fuga de datos puede tener impactos profundos y de gran alcance:
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
La creciente amenaza de fugas de aprendizaje automático (ML)
Al entrenar un modelo con un conjunto de datos diferente al de un modelo de lenguaje grande (LLM), puede producirse un sesgo de aprendizaje automático o inteligencia artificial (IA). Esta situación suele surgir debido a una mala gestión de la fase de preprocesamiento del desarrollo de ML. Un ejemplo típico de fuga de ML es el uso de la media y la desviación estándar de un conjunto de datos de entrenamiento completo en lugar de todo el subconjunto de entrenamiento.
La fuga de datos se produce en los modelos de aprendizaje automático a través de la fuga de objetivos o la contaminación de las pruebas de entrenamiento. En este último, los datos destinados a probar el modelo se filtran en el conjunto de entrenamiento. Si un modelo se expone a datos de prueba durante el entrenamiento, sus métricas de rendimiento serán engañosamente altas.
En la fuga de objetivos, los subconjuntos utilizados para el entrenamiento incluyen información que no está disponible en la fase de predicción del desarrollo de ML. Aunque los LLM funcionan bien en este escenario, brindan a las partes interesadas una Falsa sensación de eficacia del modelo, lo que lleva a un rendimiento deficiente en aplicaciones del mundo real.


Causas comunes de la fuga de datos
La fuga de datos ocurre por una variedad de razones; Los siguientes son algunos de los más comunes.
Fallo humano
El error humano puede ocurrir en cualquier nivel dentro de una organización, a menudo sin intención maliciosa. Por ejemplo, los empleados pueden enviar accidentalmente información confidencial, como registros financieros o datos personales, a la dirección de correo electrónico incorrecta.
Ataques de phishing
Los ataques de phishing se manifiestan de varias formas, pero tienen un método: los ciberdelincuentes engañan a las cuentas privilegiadas para que proporcionen detalles valiosos. Por ejemplo, los atacantes pueden enviar correos electrónicos aparentemente legítimos pidiendo a los empleados que hagan clic en enlaces maliciosos e inicien sesión en una cuenta determinada. Al hacerlo, el empleado ofrece voluntariamente sus credenciales de inicio de sesión al atacante, que luego se utilizan para uno o varios fines maliciosos.
Mala configuración
Las bases de datos, los servicios en la nube y la configuración de software mal configurados crean vulnerabilidades que exponen los datos confidenciales al acceso no autorizado. Errores de configuración A menudo ocurren debido a negligencia, falta de experiencia o incumplimiento de las mejores prácticas de seguridad. Dejar la configuración predeterminada sin cambios, como los nombres de usuario y las contraseñas predeterminadas, puede facilitar el acceso a los ciberdelincuentes.
La configuración incorrecta de las aplicaciones, la falta de aplicación de parches y actualizaciones de seguridad y la configuración inadecuada de controles/permisos de acceso también pueden crear agujeros de seguridad.
Medidas de seguridad débiles
Las medidas de seguridad débiles disminuyen una organización'de la postura de seguridad. Usar contraseñas simples y fáciles de adivinar; no implementar políticas de contraseñas seguras; otorgar permisos excesivos y no seguir el principio de mínimo privilegio (PoLP); O bien, la reutilización de contraseñas en varias cuentas aumenta el riesgo de fuga de datos.
Además, dejar datos Sin cifrar—en reposo y en tránsito— predispone los datos a la fuga. Al no implementar el Principio de mínimo privilegio (PoLP) Y confiar en protocolos/tecnologías de seguridad obsoletos puede crear brechas en su marco de seguridad.
Estrategias para prevenir fugas
1. Preprocesamiento y saneamiento de datos
Anonimización y redacción
La anonimización implica alterar o eliminar la información de identificación personal (PII) y los datos confidenciales para evitar que se vinculen a las personas. La redacción es un proceso más específico que consiste en eliminar u ocultar partes confidenciales de los datos, como números de tarjetas de crédito, números de Seguro Social o direcciones.
Sin la anonimización y la redacción adecuadas, los modelos de IA pueden "memorizar" Datos confidenciales del conjunto de entrenamiento, que podrían reproducirse inadvertidamente en las salidas del modelo. Esto es especialmente peligroso si el modelo se utiliza en aplicaciones públicas o orientadas al cliente.
Prácticas recomendadas:
Utilice técnicas de tokenización, hashing o cifrado para anonimizar los datos.
Asegúrese de que los datos redactados se eliminen permanentemente de los conjuntos de datos estructurados (por ejemplo, bases de datos) y no estructurados (por ejemplo, archivos de texto) antes del entrenamiento.
Implemente la privacidad diferencial (que se analiza más adelante) para reducir aún más el riesgo de exposición de datos individuales.
Minimización de datos
La minimización de datos implica recopilar y utilizar solo el conjunto de datos más pequeño necesario para lograr el objetivo del modelo de IA. Cuantos menos datos se recopilen, menor será el riesgo de que se filtre información confidencial.
La recopilación excesiva de datos aumenta la superficie de riesgo de infracciones y las posibilidades de filtrar información confidencial. Al usar solo lo que'si es necesario, también garantiza el cumplimiento de las regulaciones de privacidad como GDPR o CCPA.
Prácticas recomendadas:
Realice una auditoría de datos para evaluar qué puntos de datos son esenciales para la formación.
Implemente políticas para descartar datos no esenciales en las primeras etapas de la canalización de preprocesamiento.
Revise periódicamente el proceso de recopilación de datos para asegurarse de que no se conservan datos innecesarios.
2. Medidas de seguridad de la formación de modelos
División adecuada de datos
La división de datos separa el conjunto de datos en conjuntos de entrenamiento, validación y prueba. El conjunto de entrenamiento enseña el modelo, mientras que los conjuntos de validación y prueba garantizan la precisión del modelo sin sobreajuste.
Si los datos se dividen incorrectamente (por ejemplo, los mismos datos están presentes tanto en el conjunto de entrenamiento como en el de prueba), el modelo puede "memorizar" eficazmente el conjunto de prueba, lo que lleva a una sobreestimación de su rendimiento y a una posible exposición de información confidencial tanto en la fase de entrenamiento como en la de predicción.
Prácticas recomendadas:
Aleatorice los conjuntos de datos durante la división para garantizar que no haya superposición entre los conjuntos de entrenamiento, validación y prueba.
Utilice técnicas como la validación cruzada de k-fold para evaluar de forma sólida el rendimiento del modelo sin fugas de datos.
Técnicas de regularización
Las técnicas de regularización se emplean durante el entrenamiento para evitar el sobreajuste, donde el modelo se vuelve demasiado específico para los datos de entrenamiento y aprende a "memorizar" en lugar de generalizar a partir de ellos. El sobreajuste aumenta la probabilidad de fuga de datos, ya que el modelo puede memorizar información confidencial de los datos de entrenamiento y reproducirla durante la inferencia.
Prácticas recomendadas:
Abandono escolar: Eliminar aleatoriamente ciertas unidades (neuronas) de la red neuronal durante el entrenamiento, lo que obliga al modelo a generalizar en lugar de memorizar patrones.
Decaimiento de peso (regularización L2): Penalizar los pesos grandes durante el entrenamiento para evitar que el modelo se ajuste demasiado a los datos de entrenamiento.
Parada temprana: Supervise el rendimiento del modelo en un conjunto de validación y detenga el entrenamiento cuando el modelo'El rendimiento comienza a degradarse debido al sobreajuste.
Privacidad diferencial
La privacidad diferencial agrega ruido controlado a los datos o a las salidas del modelo, lo que dificulta que los atacantes extraigan información sobre cualquier punto de datos individual en el conjunto de datos.
Al aplicar la privacidad diferencial, es menos probable que los modelos de IA filtren detalles de individuos específicos durante el entrenamiento o la predicción, lo que proporciona una capa de protección contra ataques adversarios o fugas de datos no intencionadas.
Prácticas recomendadas:
Agregue ruido gaussiano o de Laplace a los datos de entrenamiento, modele gradientes o predicciones finales para ocultar las contribuciones de datos individuales.
Utilice marcos como TensorFlow Privacy o PySyft para aplicar la privacidad diferencial en la práctica.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Implementación segura de modelos
Aislamiento de inquilinos
En un entorno de varios inquilinos, el aislamiento de inquilinos crea un límite lógico o físico entre cada inquilino's, lo que hace imposible que un inquilino acceda o manipule a otro's información confidencial. Aislando a cada inquilino's, las empresas pueden evitar el acceso no autorizado, reducir el riesgo de violaciones de datos y garantizar el cumplimiento de las regulaciones de protección de datos.
El aislamiento de inquilinos proporciona una capa adicional de seguridad, lo que brinda a las organizaciones la tranquilidad de saber que su datos confidenciales de entrenamiento de IA está protegido contra posibles fugas o accesos no autorizados.
Prácticas recomendadas:
Separación lógica: use técnicas de virtualización como contenedores o máquinas virtuales (VM) para asegurarse de que los datos y el procesamiento de cada inquilino estén aislados entre sí.
Controles de acceso: Implemente políticas estrictas de control de acceso para garantizar que cada inquilino solo pueda acceder a sus propios datos y recursos.
Cifrado y gestión de claves: use claves de cifrado específicas del inquilino para segregar aún más los datos, lo que garantiza que, incluso si se produce una infracción, los datos de otros inquilinos permanezcan seguros.
Supervisión y limitación de recursos: Evite que los inquilinos agoten los recursos compartidos mediante la aplicación de límites de recursos y la supervisión de comportamientos anómalos que puedan poner en peligro el aislamiento del sistema.
Desinfección de salida
La desinfección de resultados implica la implementación de comprobaciones y filtros en las salidas del modelo para evitar la exposición accidental de datos confidenciales, especialmente en el procesamiento del lenguaje natural (NLP) y los modelos generativos.
En algunos casos, el modelo puede reproducir información confidencial que encontró durante el entrenamiento (por ejemplo, nombres o números de tarjetas de crédito). La desinfección de las salidas garantiza que no se expongan datos confidenciales.
Prácticas recomendadas:
Utilice algoritmos de coincidencia de patrones para identificar y redactar PII (por ejemplo, direcciones de correo electrónico, números de teléfono) en las salidas del modelo.
Establezca umbrales en las salidas probabilísticas para evitar que el modelo haga predicciones demasiado seguras que podrían exponer detalles confidenciales.
4. Prácticas Organizacionales
Capacitación de empleados
La formación de los empleados garantiza que todas las personas implicadas en el desarrollo, la implementación y el mantenimiento de los modelos de IA comprendan los riesgos de fuga de datos y las mejores prácticas para mitigarlos. Muchas filtraciones de datos se producen debido a errores humanos o descuidos. Una formación adecuada puede evitar la exposición accidental de información confidencial o vulnerabilidades de modelos.
Prácticas recomendadas:
Proporcione formación periódica en ciberseguridad y privacidad de datos a todos los empleados que manejen modelos de IA y datos confidenciales.
Actualizar al personal sobre los riesgos de seguridad emergentes de la IA y las nuevas medidas preventivas.
Políticas de gobernanza de datos
Las políticas de gobernanza de datos establecen directrices claras sobre cómo se deben recopilar, procesar, almacenar y acceder a los datos en toda la organización, lo que garantiza que las prácticas de seguridad se apliquen de forma coherente.
Una política de gobernanza bien definida garantiza que el tratamiento de datos esté estandarizado y cumpla con las leyes de privacidad como el RGPD o la HIPAA, lo que reduce las posibilidades de fuga.
Prácticas recomendadas:
Defina la propiedad de los datos y establezca protocolos claros para el manejo de datos confidenciales en cada etapa del desarrollo de la IA.
Revise y actualice periódicamente las políticas de gobernanza para reflejar los nuevos riesgos y requisitos normativos.
5. Aproveche las herramientas de gestión de la postura de seguridad de IA (AI-SPM)
Soluciones AI-SPM proporcionar visibilidad y control sobre los componentes críticos de la seguridad de la IA, incluidos los datos utilizados para el entrenamiento/inferencia, la integridad del modelo y el acceso a los modelos implementados. Al incorporar una herramienta AI-SPM, las organizaciones pueden gestionar de forma proactiva la postura de seguridad de sus modelos de IA, minimizando el riesgo de fuga de datos y garantizando una sólida gobernanza del sistema de IA.
Cómo AI-SPM ayuda a prevenir la fuga de modelos de ML:
Descubra e inventarie todas las aplicaciones, modelos y recursos asociados de IA
Identifique las vulnerabilidades en la cadena de suministro de IA y los errores de configuración que podrían provocar la fuga de datos
Supervise los datos confidenciales de la pila de IA, incluidos los datos de entrenamiento, las bibliotecas, las API y las canalizaciones de datos
Detecte anomalías y posibles fugas de datos en tiempo real
Implementar barreras de seguridad y controles de seguridad específicos para los sistemas de IA
Realizar auditorías y evaluaciones periódicas de las aplicaciones de IA


¿Cómo puede ayudar Wiz?
Con su integral gestión de la postura de seguridad de datos (DSPM), Wiz ayuda a prevenir y detectar la fuga de datos de las siguientes maneras.
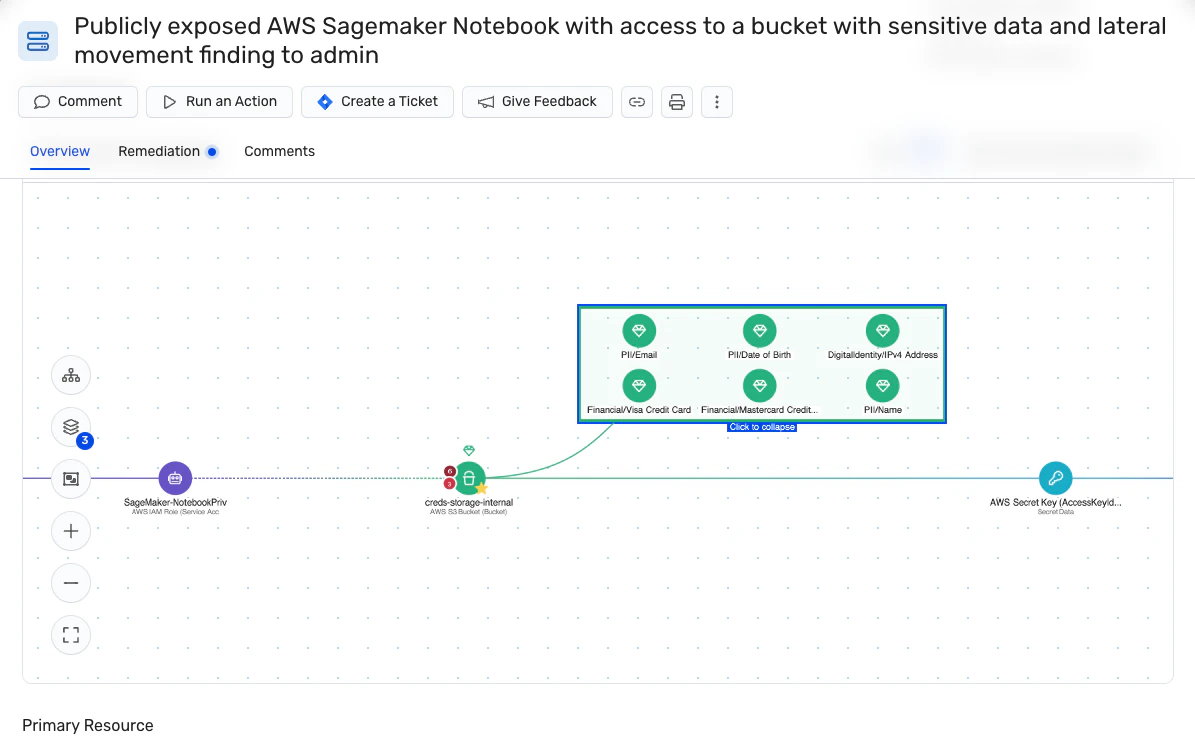
Detección y clasificación automática de datos
Wiz monitorea continuamente la exposición de datos críticos, proporcionando visibilidad en tiempo real de información confidencial como datos PII, PHI y PCI. Proporciona una vista actualizada de dónde están los datos y cómo se accede a ellos (incluso en sus sistemas de IA con nuestro Solución AI-SPM). También puede crear clasificadores personalizados para identificar datos confidenciales que son exclusivos de su empresa. Estas características facilitan aún más la respuesta rápida a los incidentes de seguridad, evitando daños por completo o minimizando significativamente el radio de explosión potencial.
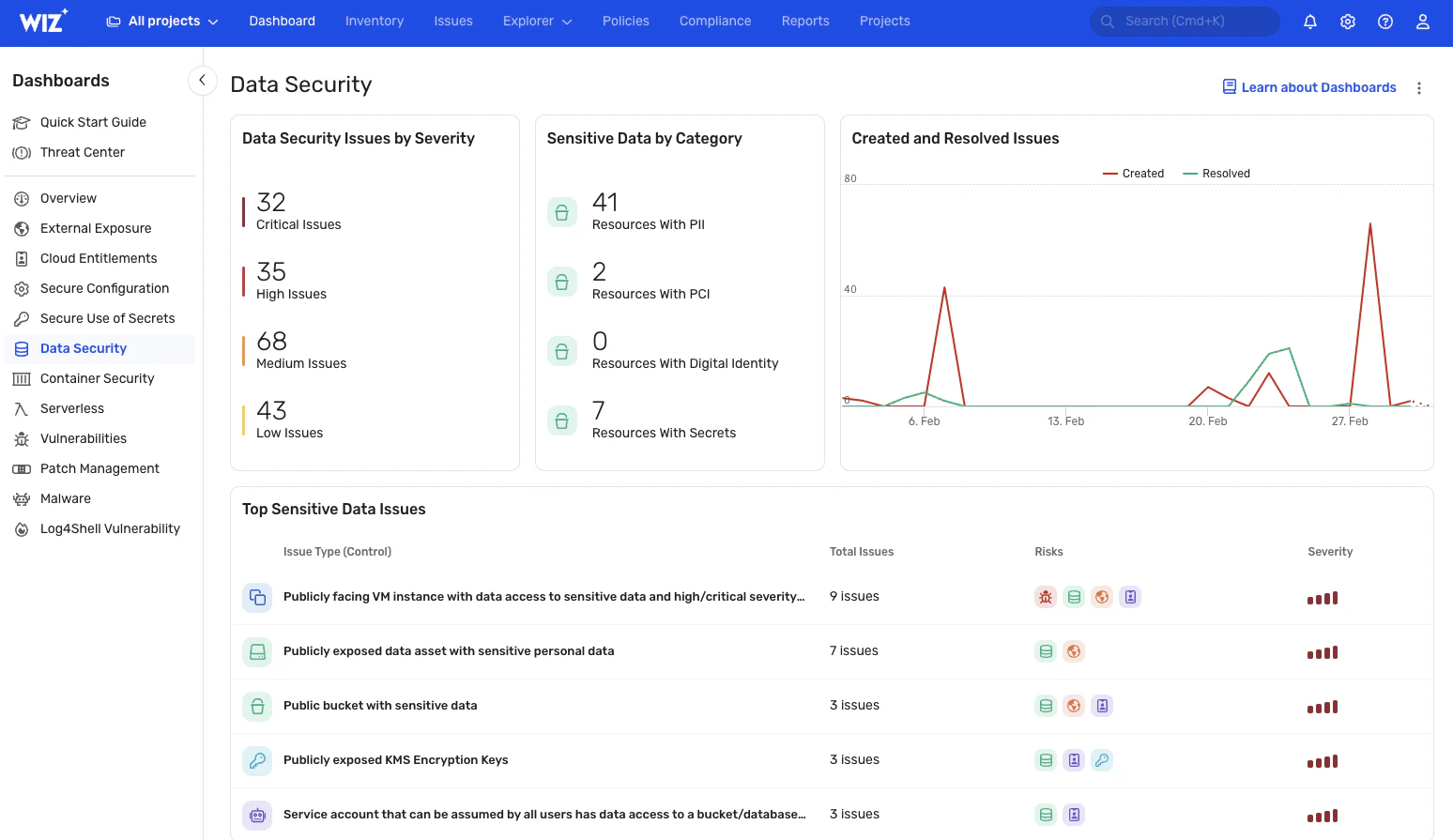
Evaluación de riesgos de datos
Wiz detecta las rutas de ataque correlacionando los hallazgos de datos con vulnerabilidades, configuraciones incorrectas, identidades y exposiciones que pueden explotarse. A continuación, puede cerrar estas rutas de exposición antes de que los actores de amenazas puedan explotarlas. Wiz también visualiza y prioriza los riesgos de exposición en función de su impacto y tasa de gravedad, lo que garantiza que los problemas más críticos se aborden primero.
Además, Wiz ayuda a la gobernanza de datos al detectar y mostrar quién puede acceder a qué datos.
Seguridad de los datos para los datos de entrenamiento de IA
Wiz proporciona una evaluación de riesgos completa de sus activos de datos, incluida la posibilidad de fuga de datos, con IA DSPM mandos. Nuestras herramientas proporcionan una visión holística de la postura de seguridad de los datos de su organización, destacan las áreas que necesitan atención y ofrecen orientación detallada para reforzar sus medidas de seguridad y solucionar los problemas rápidamente.
Evaluación continua del cumplimiento
La evaluación continua del cumplimiento de Wiz garantiza que su organización'La postura de seguridad se alinea con los estándares de la industria y los requisitos regulatorios en tiempo real. Nuestra plataforma analiza en busca de errores de configuración y vulnerabilidades, proporcionando recomendaciones prácticas para la corrección y automatizando los informes de cumplimiento.
Con Wiz características y funcionalidades de DSPM, puede ayudar eficazmente a su organización a mitigar los riesgos de fuga de datos y garantizar una protección de datos y cumplimiento. Solicita una demo hoy para obtener más información.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
