

Qu’est-ce que la sécurité des agents d’IA ?
La sécurité des agents d’IA consiste à maintenir des systèmes d’IA autonomes sûrs, prévisibles et contrôlés lorsqu’ils effectuent des actions sur des systèmes réels. Les agents peuvent appeler des outils, des API et des workflows : une seule décision peut donc modifier des données ou déclencher des opérations dans votre environnement.
Un agent d’IA s’appuie sur un modèle pour raisonner sur une tâche, puis planifie des étapes et les exécute sans intervention humaine à chaque étape. Il peut, par exemple, lire des logs, appeler une API cloud, mettre à jour un enregistrement et envoyer un message.
Dans des environnements cloud, les agents s’exécutent dans des conteneurs, des fonctions serverless ou des moteurs de workflow, et utilisent des comptes de service, des clés d’API et des rôles cloud pour accéder aux ressources. Cela fait de chaque agent une identité non humaine dotée d’autorisations réelles.
La sécurité des agents d’IA consiste à définir ce qu’un agent est autorisé à faire, à limiter les systèmes qu’il peut atteindre et à valider ses actions de bout en bout. L’objectif : qu’il reste conforme au comportement attendu.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Pourquoi les agents d’IA créent une nouvelle surface d’attaque ?
Contrairement aux modèles d’IA traditionnels, les agents d’IA ne se contentent pas de générer des réponses : ils exécutent des actions. Lorsqu’un agent peut appeler des outils, déclencher des workflows ou utiliser des API cloud, toute manipulation de son raisonnement peut se traduire par des changements réels dans votre environnement, et pas seulement par une réponse trompeuse.
Plusieurs caractéristiques élargissent la surface d’attaque :
Des actions, pas des réponses : une injection de prompt ne modifie plus seulement du texte, elle peut modifier l’état d’un système.
Accès à des systèmes en production : les agents opèrent avec des identifiants et des rôles ; leurs décisions s’exécutent donc avec de vraies autorisations.
Chaînage d’outils et d’API : une requête unique peut déclencher plusieurs étapes que l’agent choisit lui-même.
Influence externe : les agents peuvent être orientés via les données qu’ils lisent, pas uniquement via des prompts directs.
État persistant : la mémoire et le contexte peuvent stocker des instructions qui façonnent le comportement futur.
Exposition de la chaîne d’approvisionnement : les frameworks, les plugins et les systèmes de retrieval introduisent de nouvelles dépendances.
Résultat : la question de sécurité centrale passe de :
« Peut-on influencer le modèle ? »
à
« Si oui, à quoi l’agent peut-il accéder ou qu’est-ce qu’il peut modifier ? »
Ce passage de la génération de texte à l’exécution avec des accès réels est précisément ce qui distingue la sécurité des agents d’IA de celle des modèles traditionnels.
Quelles sont les catégories de menaces et les risques correspondants ?
La plupart des incidents impliquant des agents d’IA relèvent d’un petit ensemble de schémas récurrents. Ces risques sont élevés, car ils transforment une manipulation du raisonnement du modèle en actions non prévues avec des autorisations réelles.
1. Actions non autorisées via la logique de l’agent
De petites manipulations des entrées ou du contexte peuvent pousser un agent à exécuter des étapes au-delà de ses attributions. Par exemple :
déclencher un workflow prématurément ;
exécuter des appels d’API destructeurs ;
ou chaîner des outils d’une manière que le concepteur n’avait pas anticipée.
Il s’agit d’une exploitation de la logique métier, et non d’une vulnérabilité logicielle classique.
2. Détournement d’identité et élévation de privilèges
Par commodité, les agents s’exécutent souvent avec des autorisations excessives . Si un attaquant influence la prise de décision de l’agent, il prend le contrôle de ces privilèges. Une identité d’agent compromise peut :
usurper des rôles ;
modifier des ressources ;
ou créer de nouveaux chemins d’accès.
Dans des environnements cloud, cela peut aller jusqu’à une compromission totale du compte.
3. Exposition de données via une récupération non bornée
Les agents abstraient l’accès aux données derrière des outils. Avec la bonne entrée, un agent peut être amené à :
révéler des données sensibles depuis un datastore ;
agréger des enregistrements privés ;
ou exporter des informations vers un emplacement externe.
C’est de la data exfiltration via l’automatisation, et non une exploitation directe d’une base de données.
4. Contournement de la logique métier et échecs silencieux
Les agents intègrent de la logique métier dans des prompts, des politiques et des définitions d’outils. Si les garde-fous sont incomplets, des attaquants peuvent :
contourner des étapes d’approbation ;
déclencher des actions sans validation ;
ou dissimuler des étapes dangereuses dans de longues chaînes d’outils.
De manière générale, les logs générés par ces défaillances ne ressemblent pas à une activité malveillante, ce qui complique la détection.
5. Risques de chaîne d’approvisionnement via les outils et plugins des agents
Les agents dépendent de frameworks, de plugins, de retrievers et de modèles d’embedding. Si un composant est compromis, l’agent va :
faire confiance à l’output ;
agir à partir d’un contexte altéré ;
ou récupérer des données malveillantes.
Cela crée un risque de chaîne d’approvisionnement au niveau des outils, et pas uniquement au niveau du code.
6. Abus au niveau du modèle conduisant à des actions dangereuses
L’injection de prompt (directe ou indirecte) ne sert pas seulement à obtenir une réponse étrange : elle peut provoquer des changements d’état non prévus. Une attaque peut :
injecter des instructions cachées dans du contenu récupéré ;
reformuler la tâche que l’agent pense résoudre ;
ou créer des boucles de logique qui déclenchent l’utilisation d’outils.
On passe ainsi de la manipulation du modèle à la manipulation des systèmes.
Toutes ces catégories partagent le même schéma :
le modèle peut être influencé ;
l’agent a des accès ;
et les outils exécutent le résultat.
Cette combinaison crée un chemin d’attaque. Comprendre ces schémas vous aide à concevoir des contrôles qui limitent les accès d’un agent et valident ces actions, plutôt que d’essayer d’empêcher toute instruction possible.
GenAI Security Best Practices [Cheat Sheet]
This cheat sheet provides a practical overview of the 7 best practices you can adopt to start fortifying your organization’s GenAI security posture. Inside you’ll find:

Comment gérer les identités et les accès (IAM) des agents d’IA ?
La manière la plus efficace de contrôler un agent d’IA est de contrôler son identité. Si l’agent n’a pas d’autorisation, il ne peut pas l’utiliser, même si son raisonnement est influencé.
Considérez chaque agent comme une identité non humaine à part entière avec un périmètre d’accès strictement défini, plutôt que de partager des clés ou de le laisser hériter de rôles trop larges depuis un compte de service ou un compte utilisateur.
Un modèle IAM robuste pour les agents inclut :
Des identités séparées : chaque agent utilise son propre rôle ou son propre compte de service, mais jamais un identifiant partagé.
Principe du moindre privilège (PoLP) : n’attachez que les autorisations nécessaires aux tâches de l’agent, et pas un accès complet à une ressource ou à un compte.
Identifiants de courte durée : utilisez des tokens temporaires et une rotation automatique afin que les accès expirent rapidement.
Aucun secret dans le code : les identifiants résident dans un gestionnaire de secrets, pas dans des prompts, des variables d’environnement ou des fichiers de configuration.
Dans des environnements cloud, cela signifie généralement utiliser des primitives d’identité natives :
AWS : des rôles IAM avec des identifiants temporaires STS ;
Azure : Managed Identities ;
GCP : Service Accounts avec Workload Identity ;
Kubernetes : Service Accounts avec RBAC et fédération cloud (p. ex. IRSA).
Les autorisations doivent être revues régulièrement. Posez-vous des questions simples :
Quelles identités d’agents disposent de droits de niveau admin ?
Quelles autorisations ne sont pas utilisées et peuvent être supprimées ?
Cet agent peut-il accéder à des données sensibles ou à des API puissantes ?
En limitant l’accès des agents et en veillant à ce que chacun dispose d’une identité dédiée, vous réduisez le rayon d’impact de toute erreur ou manipulation. La sécurité des agents commence par ce que l’agent peut faire, pas uniquement par la manière dont le modèle se comporte.
Quelles sont les bonnes pratiques de sécurité pour les agents d’IA ?
La sécurité des agents d’IA monte en puissance lorsqu’elle suit des principes cloud-native, plutôt que de créer une « pile de sécurité IA » parallèle. L’approche la plus fiable est progressive :
gagner en visibilité ;
éliminer les chemins d’attaque à fort impact ;
se défendre en continu au runtime ;
améliorer sa sécurité dans la durée.
Chaque phase s’appuie sur la précédente et utilise le contexte de votre environnement pour prioriser ce qui compte réellement.
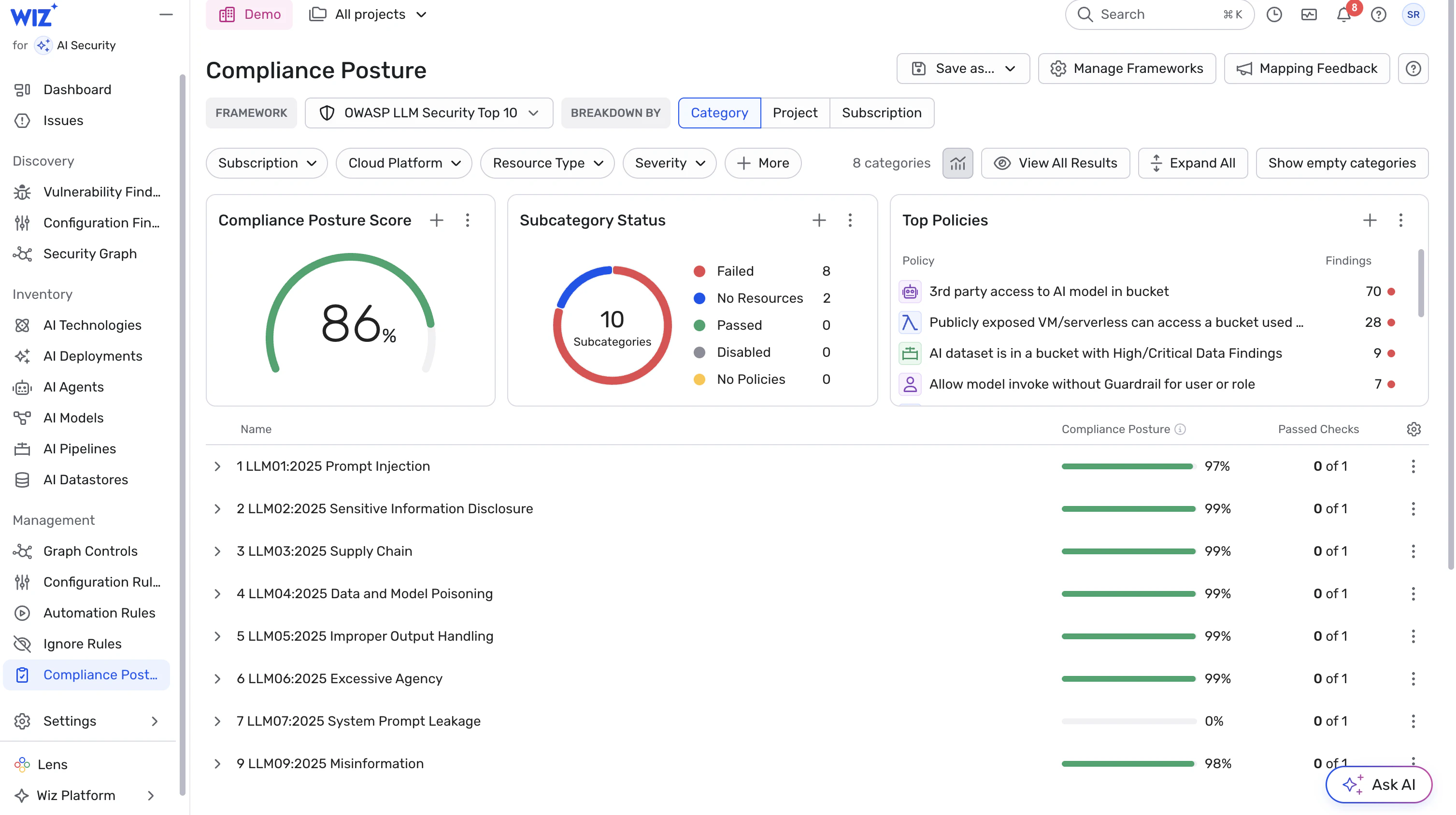
1. Commencez par la visibilité : inventoriez tous les agents d’IA et les workloads
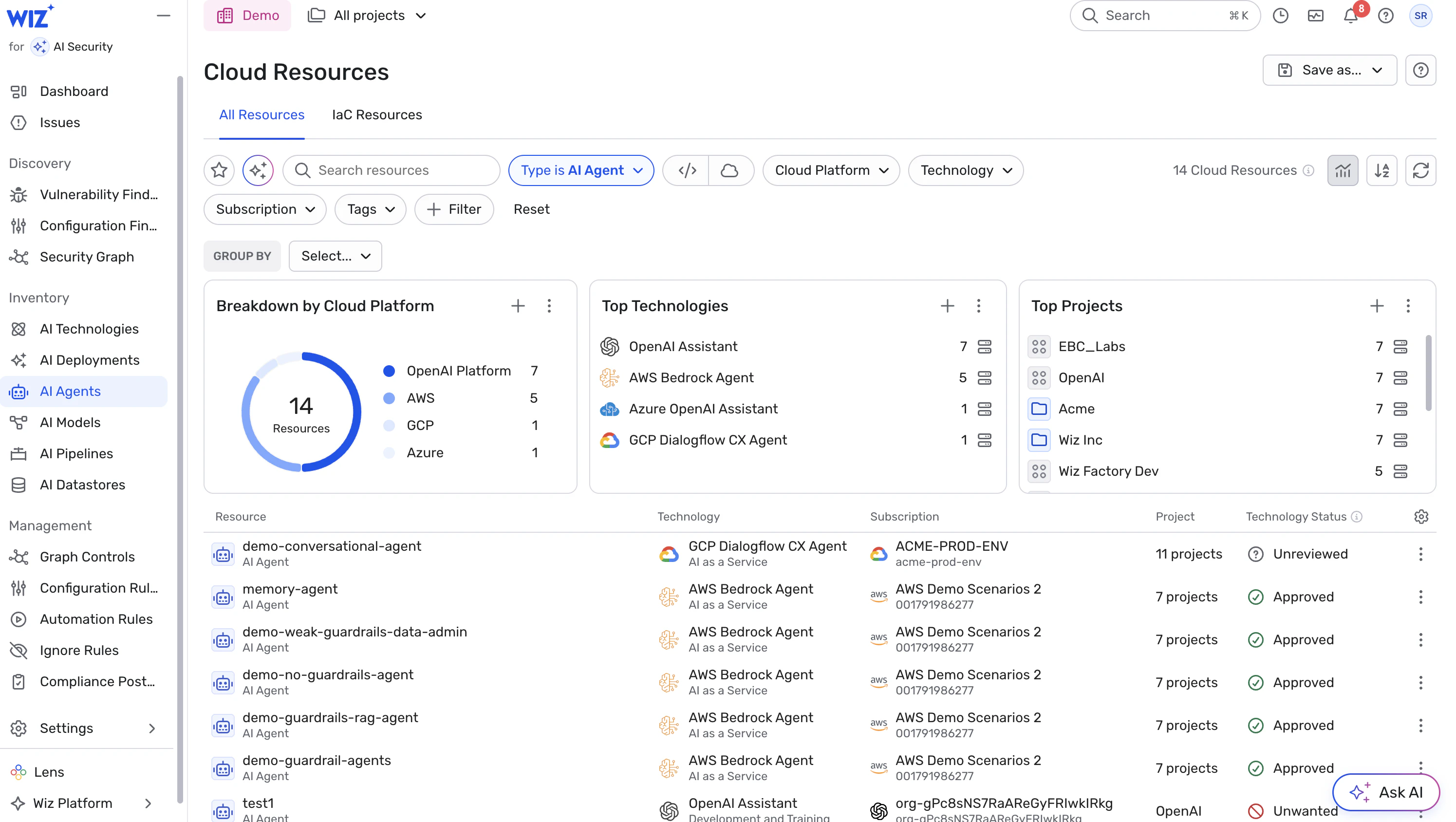
Maintenez un inventaire à jour de tous les workloads liés à l’IA (agents, endpoints d’inférence, flux de traitement des données, etc.) y compris les dépendances (modèles, SDK, bibliothèques, retrievers, datastores).
Assurez-vous que l’identité de chaque agent, ses autorisations et les ressources associées sont suivies de manière centralisée.
Considérez les agents non découverts ou ad hoc comme à haut risque : identité inconnue + autorisations inconnues = forte incertitude.
2. Priorisez les risques avec le contexte, pas avec des règles uniformes
Pour chaque agent, évaluez le risque en fonction de ses accès (datastores, secrets, API) et de sa capacité d’action (exposition réseau, rôles cloud, interfaces externes).
Priorisez la remédiation pour les agents avec un accès élevé + une portée élevée, en particulier ceux qui combinent une exposition externe et un accès à des données sensibles.
Concentrez-vous sur l’élimination des chemins d’attaque : corrigez la combinaison d’autorisations, des chemins d’accès et du périmètre d’identité, pas seulement des erreurs de configuration isolées.
3. Appliquez des configurations sécurisées et des garde-fous par défaut
Utilisez des modèles de configuration de référence (IaC ou policy-as-code) pour le déploiement des agents, avec des valeurs par défaut conservatrices : autorisations minimales, pas d’exposition réseau inutile, périmètres d’outils restreints.
Validez tous les paramètres spécifiques à l’IA (p. ex. autorisations du modèle, assainissement des entrées et des outputs, politiques réseau) avant de déployer des agents ou des endpoints d’inférence.
Rejetez les changements qui ouvrent des configurations à risque élevé, comme un agent exposé sur Internet, couplé à un accès en écriture à des datastores sensibles.
4. Surveillez le comportement au runtime et détectez les dérives ou les abus
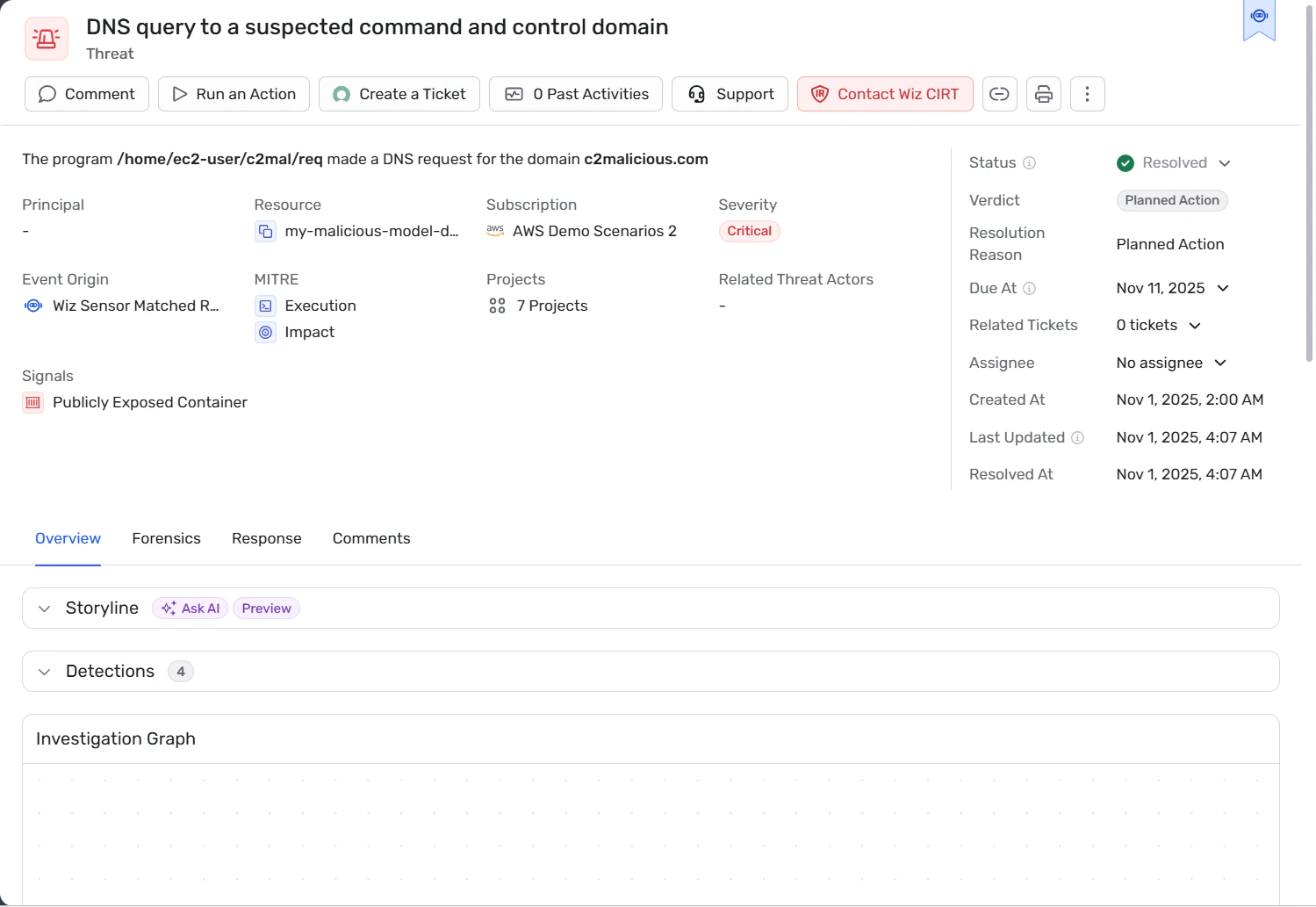
Journalisez l’activité des agents : appels d’outils, interactions avec des API, accès aux données, appels réseau sortants, en capturant suffisamment de contexte (identité, ressource, sensibilité des données) pour reconstituer ce qui s’est passé.
Établissez une baseline comportementale par agent ou par catégorie d’agents. Déclenchez des alertes en cas d’écarts, comme des appels d’API inhabituels, des schémas d’accès aux données inattendus ou un egress réseau vers des destinations externes.
Combinez les signaux au runtime avec le contexte des identités et de l’environnement afin de détecter de vraies tentatives d’exploitation, et pas seulement des événements atypiques.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

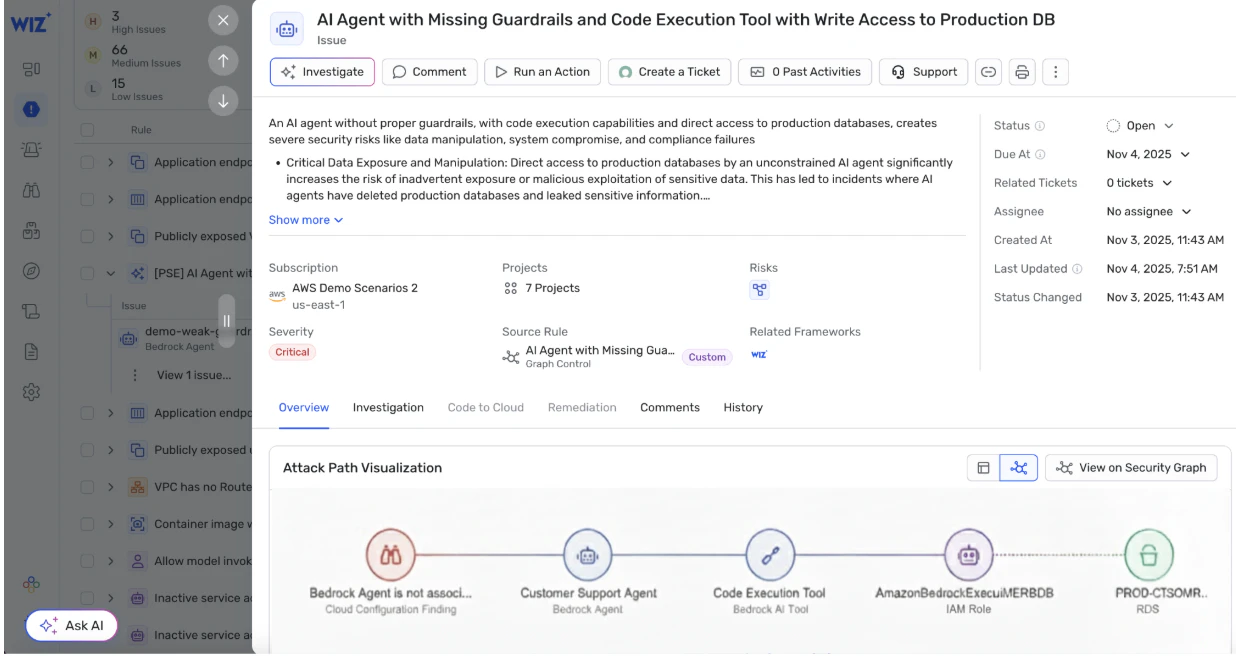
Comment Wiz aide à sécuriser les agents d’IA ?
Wiz aborde la sécurité des agents d’IA comme une composante de votre surface d’attaque cloud, et non comme une pile technologique séparée. Les agents, les identités qu’ils utilisent, les données qu’ils peuvent atteindre et les workloads sur lesquels ils s’exécutent sont cartographiés dans le Wiz Security Graph. Vous visualisez ainsi où l’accès d’un agent pourrait transformer une manipulation de prompt en véritable chemin d’attaque.
Cette vue unifiée met en évidence les combinaisons toxiques qui comptent en pratique. On peut citer comme exemple un runtime d’agent accessible depuis Internet avec un accès étendu à un datastore sensible, ou un agent d’exploitation capable de modifier des pipelines CI/CD et de lire des secrets de production. Plutôt que de poursuivre des constats isolés, Wiz aide les équipes à neutraliser l’ensemble du chemin d’attaque, en apportant un contexte d’attribution direct pour que la bonne équipe corrige le risque à la source.
Wiz apporte aussi une visibilité au runtime via Defend. Si un agent effectue un appel d’API inhabituel, chaîne des outils de manière inattendue ou interagit avec des données sensibles en dehors de son comportement habituel, les signaux au runtime sont automatiquement enrichis avec le contexte cloud : quelle identité a été utilisée, quelles données ont été touchées et si l’action expose des actifs critiques.
Pour éviter le retour des erreurs de configuration, Wiz relie les identités et les autorisations des agents au code et à l’IaC qui les ont définies : vous corrigez le modèle, pas seulement l’instance en cours d’exécution.
Dans ce modèle, Wiz applique l’AI Security Posture Management (AI-SPM) à l’ensemble des ressources IA de votre cloud. Wiz détecte des erreurs de configuration IA sur des endpoints d’inférence, des runtimes d’agents et des flux d’orchestration d’agents. Cela couvre notamment des déploiements sans garde-fous, des périmètres d’outils dangereux ou un accès excessif à des données sensibles. Ces constats sont présentés dans le contexte du graphe, afin que vous voyiez comment des erreurs de configuration se combinent avec la portée des identités et la portée réseau pour créer de vrais chemins d’exploitation, et pas seulement une dérive de configuration.
Identifiez où les agents d’IA créent un risque réel dans votre environnement et comment neutraliser les chemins d’attaque. Demandez une démo.
Develop AI Applications Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
