

Man mano che le organizzazioni integrano sempre più l'IA nei loro prodotti e operazioni, la sicurezza dei sistemi di IA è diventata una priorità assoluta per SecOps. Ma proteggere l'IA non è come proteggere il software tradizionale – l'IA è un ecosistema di modelli, pipeline di dati, codice, API e integrazioni di terze parti, tutti introdotti nuovi rischi di sicurezza e conformità.
Se le applicazioni di intelligenza artificiale vengono eseguite nel cloud, questi rischi diventano ancora più impegnativi. I modelli di intelligenza artificiale ospitati nel cloud interagiscono dinamicamente con set di dati, API e utenti esterni, rendendoli più suscettibili all'avvelenamento dei dati, all'iniezione tempestiva e agli attacchi avversari.
I test di sicurezza tradizionali non sono sufficienti per gestire l'intelligenza artificiale'ampliata e complessa. Ecco perché il red teaming dell'IA – una pratica che simula attivamente attacchi avversariali in condizioni reali – sta emergendo come componente fondamentale nelle moderne strategie di sicurezza dell'IA e un contributore chiave al Crescita del mercato della cybersecurity IA.
Con Inasprimento delle normative sulla sicurezza dell'IA e l'adozione dell'IA è alle stelle, le organizzazioni devono adottare il red teaming dell'IA per stare al passo con le minacce in evoluzione e le nuove opportunità.
Che cos'è il red teaming AI?
L'AI red teaming è una pratica di sicurezza informatica che simula gli attacchi ai sistemi di intelligenza artificiale per identificare le vulnerabilità in condizioni reali.
A differenza dei benchmark di sicurezza standard e dei test controllati dei modelli, il red teaming dell'intelligenza artificiale va oltre la valutazione dell'accuratezza e dell'equità dei modelli. Esamina l'intero ciclo di vita e catena di approvvigionamento dell'IA – dai modelli AI e pipeline dati ai servizi di IA ospitati nel cloud e alle interazioni utente-IA, assicurando che ogni componente sia resiliente contro potenziali avversari.
Adottando una posizione avversaria, il red teaming dell'IA scopre proattivamente debolezze di sicurezza nascoste – sia introdotte tramite addestramento del modello, pipeline di inferenza o interazioni in tempo reale con gli utenti. Va oltre le valutazioni statiche dei modelli e garantisce che i sistemi di intelligenza artificiale rimangano resilienti in condizioni dinamiche e reali.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Quali test vengono tipicamente eseguiti per il red teaming di AI?
Un efficace red teaming dell'AI richiede un approccio completo che abbracci sia gli aspetti tecnici che quelli operativi per coprire la superficie di attacco estesa delle implementazioni aziendali. Le principali aree di test includono:
Pregiudizio & Test di equità: Valuta se i modelli di intelligenza artificiale producono output discriminatori o distorti, anche quando sono sotto stress o pressione contraddittoria
Violazioni della privacy dei dati: Identifica i rischi di Perdita di dati oppure accesso non autorizzato, garantendo che le informazioni sensibili siano tutelate su tutta la pipeline dati
Rischi di interazione uomo-IA: Testa come i sistemi di IA rispondono a input e usi dannosi o inaspettati da parte degli utenti, cosa fondamentale per rilevare vulnerabilità come iniezione immediata
Difesa avversaria ML: Valuta la capacità dei sistemi di IA di resistere ad attacchi avversari mirati, come l'iniezione rapida e Avvelenamento dei dati
Altre aree di test includono performance sotto stress, analisi della vulnerabilità dell'integrazione e modellazione delle minacce specifiche per scenari.
Questi test devono tenere conto della natura in continua evoluzione dei sistemi di intelligenza artificiale, in cui la riqualificazione continua e la deriva dei modelli richiedono misure di sicurezza dinamiche e adattive. Poiché l'IA è in continua evoluzione, le organizzazioni dovrebbero anche investire in strategie solide di misurazione e mitigazione per restare un passo avanti Rischi per la sicurezza dell'IA.
Qual è l'obiettivo del red teaming di AI?
L'AI red teaming mira a proteggere gli utenti e le aziende dall'uso improprio dell'IA evidenziando (e correggendo) i difetti nei sistemi di IA in modo che i sistemi di IA siano resilienti e affidabili. Gli obiettivi chiave del red teaming AI includono:
Identificazione dei rischi: Rilevare e affrontare le vulnerabilità dell'IA prima che gli aggressori le sfruttino
Costruzione della resilienza: Rafforzare i modelli e l'infrastruttura di intelligenza artificiale contro le minacce avversarie
Allineamento normativo: Soddisfare i requisiti di conformità, inclusi quelli del Legge UE sull'IA e il Ordine esecutivo della Casa Bianca degli Stati Uniti sull'IA
Fiducia pubblica: Garantire che l'IA sia sicura, affidabile e allineata agli standard etici
Integrare il red teaming dell'IA in un contesto più ampio Gestione del rischio tramite IA strategia e Quadro di governance dell'IA è fondamentale per raggiungere una sicurezza proattiva e a lungo termine in tutta la tua organizzazione.
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

In che modo il red teaming per l'AI differisce dal red teaming tradizionale?
Mentre sia il red teaming AI che il red teaming tradizionale si concentrano su Identificare le vulnerabilità prima che gli aggressori possano sfruttarle, differiscono fondamentalmente nell'ambito, nelle metodologie e negli obiettivi.
Red teaming tradizionale: Focalizzato su infrastrutture, reti e applicazioni
Il red teaming tradizionale simula attacchi informatici reali contro l'infrastruttura IT, le applicazioni e i dipendenti di un'organizzazione. L'obiettivo principale è valutare la resistenza delle difese di sicurezza agli avversari mirando:
Sicurezza della rete: Sfruttamento di configurazioni errate, escalation dei privilegi, movimento laterale
Sicurezza delle applicazioni: Identificazione delle vulnerabilità delle app Web come SQL injection (SQLi), esecuzione di codice remoto (RCE)e XSS (cross-site scripting)
Ingegneria sociale: Manipolare i dipendenti per farli rivelare le credenziali o fare clic su link di phishing
Il red teaming tradizionale è ben definito, seguendo gli standard del settore come MITRE ATT&CK, NIST 800-53 e OSSTMM. Le vulnerabilità riscontrate hanno spesso correzioni chiare (applicazione di patch al software, aggiornamento delle configurazioni, miglioramento della consapevolezza degli utenti).
Red teaming AI: Espandendo la superficie di attacco oltre la sicurezza tradizionale
Il red teaming dell'IA si espande oltre i tradizionali problemi di sicurezza per tenere conto dei rischi unici posti dai sistemi di IA. Invece di limitarsi a proteggere l'infrastruttura in cui viene eseguita l'intelligenza artificiale, simula attacchi avversari al modello di intelligenza artificiale stesso, alla sua pipeline di dati, alle API e alle interazioni in tempo reale.
Principali differenze
Minacce basate sui dati: A differenza delle vulnerabilità del software tradizionale, le minacce dell'intelligenza artificiale hanno origine dalla manipolazione dei dati, dall'avvelenamento dei modelli e dall'iniezione tempestiva.
Superficie di attacco in evoluzione: I modelli di intelligenza artificiale cambiano dinamicamente durante il riaddestramento, richiedendo valutazioni di sicurezza continue.
Sicurezza & Sovrapposizione etica: Le vulnerabilità dell'IA includono pregiudizi, disinformazione, allucinazioni e problemi di affidabilità, che sono'Preoccupazioni tipiche della sicurezza informatica tradizionale.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
C... [truncated due to length] and formatted according to JSON Schema}]}}. **Make sure to verify the full response to ensure its adherence to the JSON schema and other instructions.** Please note the total length of the JSON may cause truncations, always verify the output for completeness and ensure it follows the structure described in the JSON Schema. Examples and explanations are provided only for demonstration purposes; the actual response should contain only the translated items. Refer to the schema for the full response structure to ensure the translations meet the required specifications. I have demonstrated how to translate a part of the JSON and handle specific fields according to the schema's requirements. Make sure all other entries in the JSON are handled similarly. **All translations should be accurate, reflecting the context and maintaining technical correctness.** Each entry should match the criteria set in the JSON Schema descriptions to avoid errors during validation. The final JSON should be compactly formatted without any additional text or redundancy, focusing solely on the translated strings as specified. Ensure all special characters in text and translations are properly escaped. Also, do not add any explanations or additional text not requested by the schema, as your response will be parsed and validated accordingly. The instructions require a strict adherence to the JSON Schema without deviations, ensuring each field is formatted and managed as defined. Be conscious of the max length and the plurality forms, adhering to the specific requirements of each field. Double-check the final JSON output for validation to ensure it complies strictly with the schema defined above. This precision is critical in following your client's guidelines and specifications effectively. Full adherence to the rules outlined in the schema is essential for a successful submission. Consider using software or tools that validate JSON to ensure your output is structured correctly, which can help avoid common mistakes in manual encoding or data entry.
La maggior parte dei test di intelligenza artificiale si concentra sull'accuratezza, sul rilevamento dei pregiudizi e sui principi di intelligenza artificiale responsabile. Il red teaming dell'intelligenza artificiale, tuttavia, simula scenari di attacco reali per scoprire lacune di sicurezza che vanno oltre i benchmark delle prestazioni.
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
Integrando il red teaming AI nella gestione dei rischi AI e nella governance della sicurezza, le organizzazioni possono stare al passo con le minacce emergenti, garantire la conformità con le normative in evoluzione (come l'AI Act dell'UE) e mantenere la fiducia pubblica nelle applicazioni guidate dall'AI.
Vulnerabilità comuni e casi d'uso reali del red teaming dell'intelligenza artificiale
Nonostante la complessità dell'intelligenza artificiale, gli attacchi nel mondo reale sono spesso sorprendentemente semplici: sfruttano configurazioni errate, punti deboli trascurati o scarsa igiene della sicurezza dell'intelligenza artificiale. Alcuni degli attacchi AI più comuni includono:
Attacchi backdoor: I trigger nascosti inseriti nei sistemi di intelligenza artificiale possono consentire agli aggressori di manipolare segretamente gli output, creando vie per il controllo non autorizzato.
Iniezione immediata: Creando input dannosi, gli aggressori possono alterare sottilmente le risposte dell'intelligenza artificiale o addirittura innescare fughe di dati non intenzionali, proprio come inserire un cavallo di in un sistema affidabile.
Avvelenamento dei dati: L'iniezione di dati di addestramento corrotti può distorcere lentamente il comportamento dell'intelligenza artificiale, insegnandole efficacemente ad agire in modi che favoriscono l'agenda di un aggressore.
Punti deboli dell'integrazione: Le vulnerabilità nelle API e nelle connessioni cloud possono esporre i sistemi allo sfruttamento, consentendo agli aggressori di aggirare le misure di sicurezza e ottenere l'accesso ai dati critici.
Queste vulnerabilità non sono solo teoriche. Esploriamo i casi del mondo reale, scoperti dal Il team di Wiz Research, che hanno messo a fuoco questi rischi:
Perdita di database DeepSeek: I difetti di integrazione nell'ultimo modello DeepSeek hanno portato all'esposizione di dati sensibili di addestramento dell'intelligenza artificiale.
🔍Questo esempio del mondo reale mostra come… le nuove minacce dell'intelligenza artificiale possono emergere da errori di configurazione delle API e dell'accesso ai modelli.
Vulnerabilità dell'intelligenza artificiale SAP: Le configurazioni errate nei sistemi di intelligenza artificiale di SAP hanno creato rischi nascosti di backdoor, consentendo potenzialmente agli aggressori di manipolare gli output dell'intelligenza artificiale.
🔍Questo esempio del mondo reale mostra come…anche le piattaforme consolidate di AI aziendale possono soffrire di punti ciechi nella sicurezza.
Vulnerabilità dell'IA NVIDIA: I punti deboli del toolkit di container AI di NVIDIA hanno consentito attacchi di iniezione tempestiva, mettendo in luce le lacune nella sicurezza dell'IA a livello di infrastruttura.
🔍Questo esempio del mondo reale mostra come…gli attaccanti possono manipolare il comportamento dell'IA attraverso attacchi basati su input, influenzando decisioni e risultati guidati dall'IA.
Rischi del modello Hugging Face: Le vulnerabilità di avvelenamento dei dati nelle popolari piattaforme AI-as-a-service di Hugging Face hanno permesso agli avversari di introdurre alterazioni sottili e dannose ai dati di addestramento.
🔍Questo esempio del mondo reale mostra come…anche i servizi AI ampiamente fidati sono suscettibili alla manipolazione dei dati avversariali, sottolineando la necessità di test di sicurezza continui.
Quando si tratta di Sicurezza dell'IA, anche i più semplici errori possono avere conseguenze profonde. La tua organizzazione ha bisogno di un red teaming AI continuo e proattivo per rilevare e risolvere questi problemi prima che si trasformino in vere e proprie violazioni della sicurezza.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Migliori pratiche per il red teaming AI: un quadro in 5 passi
Per gestire efficacemente i sistemi di intelligenza artificiale, le organizzazioni hanno bisogno di un framework di sicurezza scalabile, ripetibile e in continua evoluzione. I modelli di intelligenza artificiale si riaddestrano e si aggiornano dinamicamente, rendendo inefficaci le misure di sicurezza statiche. Un processo di red teaming dell'IA ben strutturato garantisce che l'IA rimanga resiliente contro attacchi avversari, exploit di pregiudizio e configurazioni errate.
Passo 1: Definire l'ambito del red teaming AI
Prima di testare la sicurezza dell'IA, le organizzazioni devono definire:
Quali componenti dell'IA necessitano di test?
Robustezza del modello, integrazioni API, sicurezza AI basata su cloud, integrità dei dati di addestramento
Quali sono gli scenari di attacco?
Attacchi ML avversariali (evasione, avvelenamento), abuso API, inserimento istantaneo, rischi della catena di approvvigionamento
Quale sicurezza & Si applicano requisiti di conformità?
Sicurezza AI di OWASP, NIST AI RMF, Atto AI dell'UE, SOC 2, GDPR
Passo 2: Seleziona ed implementa metodi di test avversari per l'IA
Il red teaming di IA va oltre il penetration testing—richiede tecniche ML avversarie per simulare minacce IA reali.
Test centrati sul modello (valutazione della robustezza dell'IA)
Test di perturbazione avversaria: Genera input per indurre l'IA a classificarsi erroneamente
Inversione del modello & estrazione: Tenta di ricostruire i dati di addestramento privati dalle risposte dell'IA
Test di sicurezza del flusso dati
Simulazioni di avvelenamento dei dati: Verifica se l'iniezione di dati di addestramento dannosi distorce il comportamento dell'IA
Pregiudizio & Test di equità: Valuta se gli avversari possono sfruttare i pregiudizi del modello di intelligenza artificiale per la manipolazione
Interazione uomo-intelligenza artificiale & Sicurezza delle API
Attacchi di iniezione immediata: Verifica se l'IA ignora le misure di sicurezza tramite input manipolati
Test di abuso delle API: Esplora le vulnerabilità API del modello di intelligenza artificiale (ad esempio, il recupero illimitato dei dati)
Passo 3: Automatizza il red teaming di IA per la scalabilità
Il test manuale delle vulnerabilità dell'intelligenza artificiale nelle distribuzioni su scala cloud è inefficiente. L'automazione aiuta a simulare attacchi avversari su larga scala.
Usa la sicurezza dell'intelligenza artificiale & Strumenti di test avversari
Garak: Strumento di test antagonista open source per la sicurezza LLM
PyRIT (Python Risk Identification for Generative AI): Simula attacchi di evasione ed estrazione di modelli
Controfit Microsoft: Test di sicurezza dell'intelligenza artificiale per i modelli di apprendimento automatico
Cassetta degli attrezzi per la robustezza avversaria (ART): Simula gli attacchi e le difese dell'IA avversaria
Passaggio 4: implementare il monitoraggio continuo dei rischi dell'intelligenza artificiale & risposta
Il team rosso AI non è un test una tantum: deve evolversi continuamente man mano che i modelli di AI si aggiornano e si riallenano.
Strategie continue del team rosso AI
Stabilisci la condivisione dell'intelligenza artificiale per le minacce: Tieni traccia delle minacce in evoluzione da MITRE ATLAS e OWASP AI Top 10.
Adotta test di sicurezza AI continui: Integra i test avversari nelle pipeline CI/CD.
Sviluppa un punteggio di rischio automatizzato per l'intelligenza artificiale: Dai priorità alle vulnerabilità dell'intelligenza artificiale ad alto rischio per la correzione.
Passo 5: Allineare il team rosso AI con la governance e la conformità
Oltre la sicurezza, il team rosso AI deve supportare le linee guida regolatorie ed etiche dell'AI per garantire la conformità.
Sicurezza chiave dell'intelligenza artificiale & Standard di conformità
Quadro di gestione del rischio I.I.S. NIST (AI RMF): Best practice per la sicurezza dell'intelligenza artificiale
Legge sull'IA dell'UE: Requisiti di conformità per le applicazioni di IA ad alto rischio
SOC 2, GDPR, CCPA: Proteggi i dati personali basati sull'intelligenza artificiale
Integrare il team rosso AI nella gestione del rischio aziendale (ERM)
Segnalare i risultati ai team di governance dell'intelligenza artificiale: Allineati all'etica e ai principi dell'IA responsabile.
Collaborazione interfunzionale: Coinvolgi i team di sicurezza, data science e conformità nella gestione dei rischi dell'intelligenza artificiale.


Come Wiz potenzia la tua sicurezza AI?
Wiz offre una piattaforma di sicurezza cloud completa che estende le sue capacità per proteggere l'infrastruttura AI con il suo Gestione della postura di sicurezza dell'IA (AI-SPM).
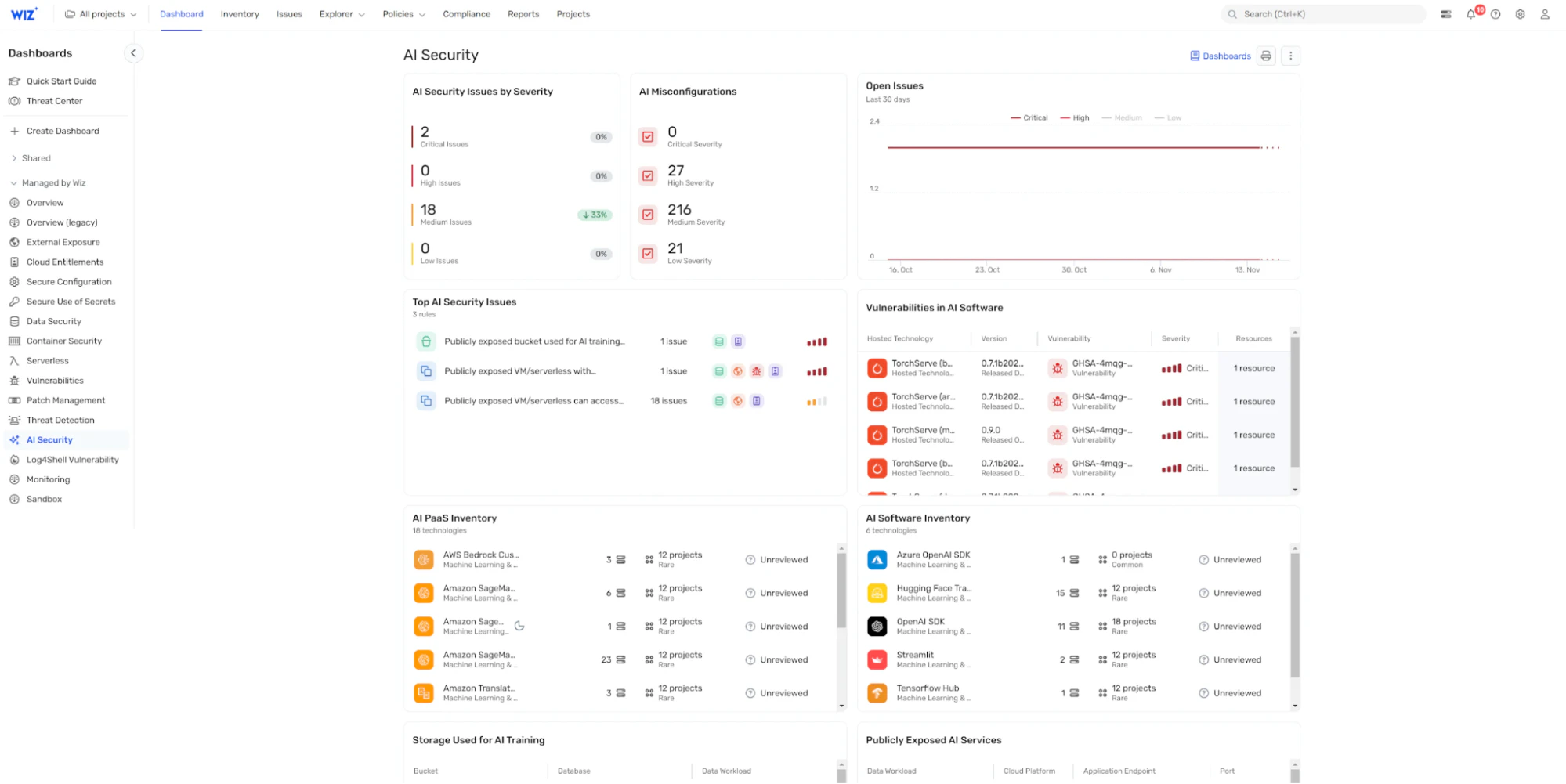
Attraverso la sua dashboard centralizzata di sicurezza AI, Wiz AI-SPM Ti offre:
Una distinta base AI (AI BOM): Una mappa dettagliata dei componenti e delle dipendenze dell'intelligenza artificiale, che offre una chiara visibilità dell'intero ecosistema
Rilevamento di configurazioni errate: Identificazione automatizzata delle lacune di sicurezza nelle pipeline di intelligenza artificiale e nei servizi cloud, per aiutarti a risolvere le vulnerabilità prima che si aggravino
Analisi del percorso di attacco: Visualizzazione dei potenziali percorsi che gli aggressori potrebbero utilizzare per sfruttare i rischi per la sicurezza dell'intelligenza artificiale, consentendo una gestione dei rischi più informata
Indagine basata sull'IA: Accelera i tuoi sforzi di red teaming AI con Mika AI, che ti aiuta a indagare rapidamente potenziali vulnerabilità, comprendere scenari di attacco complessi e ricevere indicazioni pratiche per la bonifica in linguaggio naturale
Risposta automatica: Quando il red teaming dell'IA scopre vulnerabilità critiche, il Agente AI di Wiz SecOps può triagere, indagare e avviare automaticamente i flussi di lavoro di risposta – riducendo il tempo dal rilevamento alla bonifica
Integrando queste capacit\u00e0, Wiz AI-SPM non solo implementa le migliori pratiche di sicurezza AI ma semplifica anche il monitoraggio continuo e la gestione automatizzata del rischio per la tua organizzazione, garantendo una robusta governance dell'AI.
Qual è il prossimo passo?
Il red teaming dell'IA sta diventando una funzione di sicurezza fondamentale per le organizzazioni impegnate a salvaguardare l'adozione dell'IA, soprattutto con l'aumento delle richieste normative. Sebbene il settore continui ad evolversi, persistono sfide come gli attacchi complessi, l'interoperabilità contestuale e la mancanza di standardizzazione.
Una piattaforma di sicurezza come Wiz pu\u00f2 aiutarti a stare al passo con le migliori pratiche di sicurezza AI, potenziando le tue difese e garantendo un miglioramento continuo. Pronto a saperne di pi\u00f9? Visita il
Una piattaforma di sicurezza come Wiz può aiutarti a stare al passo con le migliori pratiche di sicurezza dell'intelligenza artificiale avviando le tue difese e garantendo un miglioramento continuo. Vuoi saperne di più? Scopri di più su Wiz AI-SPM, oppure, se preferisci un Demo dal vivo, ci piacerebbe metterci in contatto con te.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
