

조직들이 점점 더 AI를 제품과 운영에 내장함에 따라, AI 시스템의 보안을 강화하는 것이 최우선 과제가 되었습니다 SecOps. 하지만 AI 보안은 전통적인 소프트웨어 보안과는 다릅니다 – AI는 모델, 데이터 파이프라인, 코드, API, 제3자 통합으로 이루어진 생태계로, 모두 새로운 보안 및 준수 위험을 도입합니다.
AI 애플리케이션이 클라우드에서 실행되는 경우 이러한 위험은 훨씬 더 어려워집니다. 클라우드 호스팅 AI 모델은 외부 데이터 세트, API 및 사용자와 동적으로 상호 작용하므로 데이터 중독, 프롬프트 주입 및 적대적 공격에 더 취약합니다.
기존의 보안 테스트로는 AI를 다루기에 충분하지 않습니다'의 확장되고 복잡한 공격 표면. 그래서 AI 레드팀 — 실제 상황에서 적대적 공격을 적극적으로 시뮬레이션하는 실천 — 이 현대 AI 보안 전략의 핵심 요소이자 주요 기여자로 부상하고 있습니다 AI 사이버보안 시장 성장.
와 AI 보안 규제 강화 AI 채택이 급증함에 따라 조직은 진화하는 위협과 새로운 기회에 앞서 나가기 위해 AI 레드팀을 채택해야 합니다.
AI 레드 팀이란?
AI 레드팀은 AI 시스템에 대한 공격을 시뮬레이션하여 실제 조건에서 취약점을 식별하는 사이버 보안 관행입니다.
표준 안전 벤치마크 및 통제된 모델 테스트와 달리 AI 레드팀은 모델 정확성과 공정성을 평가하는 것 이상입니다. AI 모델과 데이터 파이프라인부터 클라우드 호스팅 AI 서비스, 사용자-AI 상호작용에 이르기까지 AI 전체 수명 주기와 공급망을 면밀히 검토하여 모든 구성 요소가 잠재적 적대자에 대해 회복력을 갖추도록 보장합니다.
대립적 태도를 취함으로써 AI 레드팀은 모델 학습, 추론 파이프라인, 실시간 사용자 상호작용 등 숨겨진 보안 취약점을 선제적으로 발견합니다. 이는 정적 모델 평가를 넘어 AI 시스템이 역동적이고 실제 조건에서 탄력성을 유지하도록 보장합니다.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

AI 레드 팀 테스트는 일반적으로 어떤 테스트가 수행됩니까?
효과적인 AI 레드팀을 위해서는 엔터프라이즈 배포의 확장된 공격 표면을 다루기 위해 기술 및 운영 측면을 모두 포괄하는 포괄적인 접근 방식이 필요합니다. 주요 테스트 영역은 다음과 같습니다.
바이어스 & 공정성 테스트: AI 모델이 스트레스나 적대적 압력을 받을 때를 포함하여 차별적이거나 편향된 출력을 생성하는지 여부를 평가합니다.
데이터 프라이버시 침해: 위험 식별 데이터 유출 또는 무단 접근을 방지하여 민감한 정보가 전체 데이터 파이프라인에 걸쳐 보호되도록 보장합니다
인간-AI 상호작용 위험: AI 시스템이 악의적이거나 예상치 못한 사용자 입력과 사용에 어떻게 반응하는지를 테스트하며, 이는 다음과 같은 취약점을 탐지하는 데 매우 중요합니다 즉각적인 인젝션
적대적 머신러닝 방어: 즉각적인 주입과 같은 표적 적대적 공격을 AI 시스템이 견딜 수 있는 능력을 평가합니다. 데이터 오염
추가 테스트 영역에는 스트레스하의 성능, 통합 취약성 분석 및 시나리오별 위협 모델링이 포함됩니다.
이러한 테스트는 지속적인 재훈련과 모델 드리프트로 인해 역동적이고 적응력이 뛰어난 보안 조치가 필요한 AI 시스템의 끊임없이 진화하는 특성을 고려해야 합니다. AI는 끊임없이 진화하고 있기 때문에, 조직은 앞서 나가기 위해 견고한 측정 및 완화 전략에 투자해야 합니다 AI 보안 위험.
AI 레드 팀의 목표는 무엇입니까?
AI 레드 팀은 AI 시스템의 결함을 강조(및 수정)하여 AI 시스템이 탄력적이고 신뢰할 수 있도록 함으로써 AI의 오용으로부터 사용자와 기업을 보호하는 것을 목표로 합니다. AI 레드팀의 주요 목표는 다음과 같습니다.
위험 식별: 공격자가 AI 취약점을 악용하기 전에 탐지 및 해결
탄력성 구축: 적대적 위협에 대한 AI 모델 및 인프라 강화
규제 정렬: 준수 요건을 충족하는 것, 여기에는 EU AI법 그리고 미국 백악관 AI 행정명령
공공 신뢰: AI가 안전하고 신뢰할 수 있으며 윤리적 기준에 부합하는지 확인
AI 레드팀 통합을 더 넓은 범위에 포함시키기 AI 리스크 관리 전략 및 AI 거버넌스 프레임워크 조직 전반에 걸쳐 장기적이고 선제적인 보안을 달성하는 데 매우 중요합니다.
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

AI용 레드 팀은 전통적인 레드 팀과 어떻게 다릅니까?
AI 레드팀과 기존 레드팀 모두 공격자가 취약점을 악용하기 전에 취약점 식별, 그들은 다릅니다 기본적으로 범위, 방법론 및 목표.
기존 레드 팀 활동: 인프라, 네트워크, 애플리케이션에 중점
기존의 레드 팀은 조직의 IT 인프라, 애플리케이션 및 직원에 대한 실제 사이버 공격을 시뮬레이션합니다. 주요 목표는 다음을 대상으로 보안 방어가 공격자로부터 얼마나 잘 버틸 수 있는지 평가하는 것입니다.
네트워크 보안: 잘못된 구성, 권한 상승, 측면 이동 악용
애플리케이션 보안: SQLi(SQL 인젝션)와 같은 웹 앱 취약점 식별, 원격 코드 실행(RCE)및 XSS(교차 사이트 스크립팅)
사회 공학: 직원을 조작하여 자격 증명을 공개하거나 피싱 링크를 클릭하도록 하는 행위
전통적인 레드 팀은 MITRE ATT와 같은 업계 표준에 따라 잘 정의되어 있습니다&CK, NIST 800-53 및 OSSTMM. 발견된 취약점에는 명확한 수정 사항(소프트웨어 패치, 구성 업데이트, 사용자 인식 향상)이 있는 경우가 많습니다.
AI 레드 팀 활동: 전통적 보안을 넘어 공격 표면 확장
AI 레드팀은 AI 시스템이 제기하는 고유한 위험을 설명하기 위해 기존의 보안 문제를 넘어 확장됩니다. AI가 실행되는 인프라를 보호하는 대신 AI 모델 자체, 데이터 파이프라인, API 및 실시간 상호 작용에 대한 적대적 공격을 시뮬레이션합니다.
주요 차이점
데이터 기반 위협: 기존 소프트웨어 취약점과 달리 AI 위협은 데이터 조작, 모델 중독 및 프롬프트 주입에서 비롯됩니다.
진화하는 공격 표면: AI 모델은 재훈련하면서 동적으로 변경되므로 지속적인 보안 평가가 필요합니다.
안전 & 윤리 중복: AI 취약점에는 편견, 잘못된 정보, 환각, 신뢰성 문제가 포함됩니다.'전통적인 사이버 보안의 일반적인 우려 사항입니다.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
AI 레드 팀 활동이 표준 AI 모델 테스트와 다른 점
대부분의 AI 테스트는 정확성, 편향 감지 및 책임 있는 AI 원칙에 중점을 둡니다. 그러나 AI 레드 팀은 실제 공격 시나리오를 시뮬레이션하여 성능 벤치마크 이상의 보안 격차를 발견합니다.
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
AI 레드 팀 활동을 AI 위험 관리 및 보안 거버넌스에 통합함으로써, 조직은 신흥 위협을 앞서 나가고, 진화하는 규정(예: EU AI 법)을 준수하며, AI 기반 애플리케이션에서 대중의 신뢰를 유지할 수 있습니다.
AI 레드 팀의 일반적인 취약점 및 실제 사용 사례
AI의 복잡성에도 불구하고 실제 공격은 잘못된 구성, 간과된 약점 또는 열악한 AI 보안 위생을 악용하는 등 놀라울 정도로 간단한 경우가 많습니다. 가장 일반적인 AI 공격은 다음과 같습니다.
백도어 공격: AI 시스템에 삽입된 숨겨진 트리거를 통해 공격자는 비밀리에 출력을 조작하여 무단 제어의 길을 만들 수 있습니다.
프롬프트 주입: 공격자는 악성 입력을 제작하여 AI 응답을 미묘하게 변경하거나 트로이 목마를 신뢰할 수 있는 시스템에 밀어 넣는 것처럼 의도하지 않은 데이터 유출을 유발할 수도 있습니다.
데이터 중독: 손상된 훈련 데이터를 주입하면 AI 동작이 서서히 왜곡되어 공격자의 의제에 유리한 방식으로 행동하도록 효과적으로 학습할 수 있습니다.
통합 약점: API 및 클라우드 연결의 취약점으로 인해 시스템이 악용에 노출되어 공격자가 보안 조치를 우회하고 중요한 데이터에 액세스할 수 있습니다.
이러한 취약점은 단지 이론적인 것이 아닙니다. 에서 밝혀진 실제 사례를 살펴보겠습니다. 위즈 리서치 팀, 이러한 위험에 초점을 맞추었습니다.
DeepSeek 데이터베이스 유출: 최신 DeepSeek 모델의 통합 결함으로 인해 민감한 AI 훈련 데이터가 노출되었습니다.
🔍이 실제 사례는 어떻게… 새로운 AI 위협은 간과된 API 및 모델 액세스 구성 오류로 인해 발생할 수 있습니다.
SAP AI 취약점: SAP AI 시스템의 잘못된 구성으로 인해 숨겨진 백도어 위험이 발생하여 공격자가 AI 출력을 조작할 수 있습니다.
🔍이 실제 사례는 어떻게…오랜 기간 자리 잡은 기업 AI 플랫폼조차도 보안 상의 사각지대에서 고통받을 수 있습니다.
NVIDIA AI 취약점: NVIDIA의 AI 컨테이너 툴킷의 약점으로 인해 신속한 주입 공격이 가능해져 인프라 수준에서 AI 보안의 격차가 노출되었습니다.
🔍이 실제 사례는 어떻게…공격자는 입력 기반 공격을 통해 AI 행동을 조작하여 AI 기반 결정 및 출력에 영향을 미칠 수 있습니다.
Hugging Face 모델 위험: Hugging Face의 인기 있는 AI-as-a-Service 플랫폼의 데이터 중독 취약점으로 인해 공격자는 훈련 데이터에 미묘하고 악의적인 변경을 도입할 수 있었습니다.
🔍이 실제 사례는 어떻게…신뢰할 수 있는 AI 서비스조차 적대적 데이터 조작에 취약할 수 있으며, 지속적인 보안 테스트의 필요성을 강조합니다.
그리고 AI 보안, 심지어 가장 단순한 실수조차도 깊은 결과를 초래할 수 있습니다. 조직은 이러한 문제가 본격적인 보안 침해로 확대되기 전에 이를 포착하고 해결하기 위해 지속적이고 사전 예방적인 AI 레드 팀이 필요합니다.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

AI 레드 팀 활동을 위한 모범 사례: 5단계 프레임워크
AI 시스템을 효과적으로 레드팀으로 구성하려면 조직에는 확장 가능하고 반복 가능하며 지속적으로 진화하는 보안 프레임워크가 필요합니다. AI 모델은 동적으로 재훈련 및 업데이트되므로 정적 보안 조치가 비효율적입니다. 잘 구성된 AI 레드팀 프로세스를 통해 AI는 적대적 공격, 편견 악용 및 잘못된 구성에 대한 탄력성을 유지할 수 있습니다.
1단계: AI 레드 팀의 범위 정의
AI 보안 테스트를 시작하기 전에 조직은 다음을 정의해야 합니다:
테스트가 필요한 AI 구성 요소는 무엇입니까?
모델 강인성, API 통합, 클라우드 기반 AI 보안, 훈련 데이터 무결성
공격 시나리오는 무엇입니까?
적대적 ML 공격(회피, 독살), API 남용, 프롬프트 주입, 공급망 위험
어떤 보안 & 규정 준수 요구 사항이 적용됩니까?
OWASP AI 보안, NIST AI RMF, EU AI Act, SOC 2, GDPR
2단계: 인공지능 적대적 테스트 방법 선택 및 구현
인공지능(AI) 레드 팀은 침투 테스트를 넘어서며 실제 세계의 AI 위협을 모방하기 위해 적대적 머신러닝 기술을 요구합니다.
모델 중심 테스트(AI 강건성 평가).
적대적 섭동 테스트: AI를 속여 잘못된 분류로 유도하는 입력을 생성합니다.
모델 반전 & 추출: AI 응답에서 개인 학습 데이터를 재구성하려는 시도
데이터 파이프라인 보안 테스트
데이터 중독 시뮬레이션: 악성 학습 데이터를 삽입하면 AI 동작이 왜곡되는지 테스트
바이어스 & 공정성 테스트: 공격자가 조작을 위해 AI 모델 편향을 악용할 수 있는지 평가합니다.
인간-AI 상호 작용 & API 보안
프롬프트 삽입 공격: AI가 조작된 입력을 통해 보호 장치를 무시하는지 테스트
API 남용 테스트: AI 모델의 API 취약점(예: 무제한 데이터 검색) 탐색
3단계: AI 레드 팀링의 자동화를 위한 확대 계획
클라우드 규모 배포에서 AI 취약성을 수동으로 테스트하는 것은 비효율적입니다. 자동화는 대규모 적대적 공격을 시뮬레이션하는 데 도움이 됩니다.
AI 보안 사용 & 적대적 테스트 도구
가락: LLM 보안을 위한 오픈 소스 적대적 테스트 도구
PyRIT(생성형 AI를 위한 Python 위험 식별): 회피 및 모델 추출 공격 시뮬레이션
마이크로소프트 카운터핏: 기계 학습 모델에 대한 AI 보안 테스트
적대적 견고성 도구 상자(ART): 적대적 AI 공격 및 방어 시뮬레이션
4단계: 지속적인 AI 위험 모니터링 구현 & 응답
AI 레드 팀이란 한 번의 테스트가 아니라 AI 모델이 업데이트되고 재훈련됨에 따라 지속적으로 발전해야 합니다.
지속적인 AI 레드 팀 전략
AI 위협 인텔리전스 공유 구축: MITRE ATLAS 및 OWASP AI Top 10에서 진화하는 위협을 추적합니다.
지속적인 AI 보안 테스트 채택: CI/CD 파이프라인에 적대적 테스트를 통합합니다.
AI를 위한 자동화된 위험 점수 개발: 고위험 AI 취약점의 우선순위를 정하여 수정합니다.
5단계: AI 레드 팀을 거버넌스 및 규정 준수와 맞추기
보안을 넘어서, AI 레드 팀은 규제 및 윤리적 AI 지침을 준수하도록 지원해야 합니다.
주요 AI 보안 & 규정 준수 표준
NIST AI 위험 관리 프레임워크(AI RMF): AI 보안 모범 사례
EU AI법: 고위험 AI 애플리케이션에 대한 규정 준수 요구 사항
SOC 2, GDPR, CCPA: AI 기반 개인 데이터 보호
기업 위험 관리(ERM)에 AI 레드 팀 통합
AI 거버넌스 팀에 조사 결과를 보고합니다. 윤리 및 책임 있는 AI 원칙에 부합합니다.
부서 간 협업: AI 위험 관리에 보안, 데이터 과학 및 규정 준수 팀을 참여시키세요.


Wiz가 귀하의 AI 보안을 강화하는 방법은 무엇입니까?
위즈 AI 인프라를 안전하게 보호할 수 있는 포괄적인 클라우드 보안 플랫폼을 제공합니다 AI 보안 태세 관리(AI-SPM).
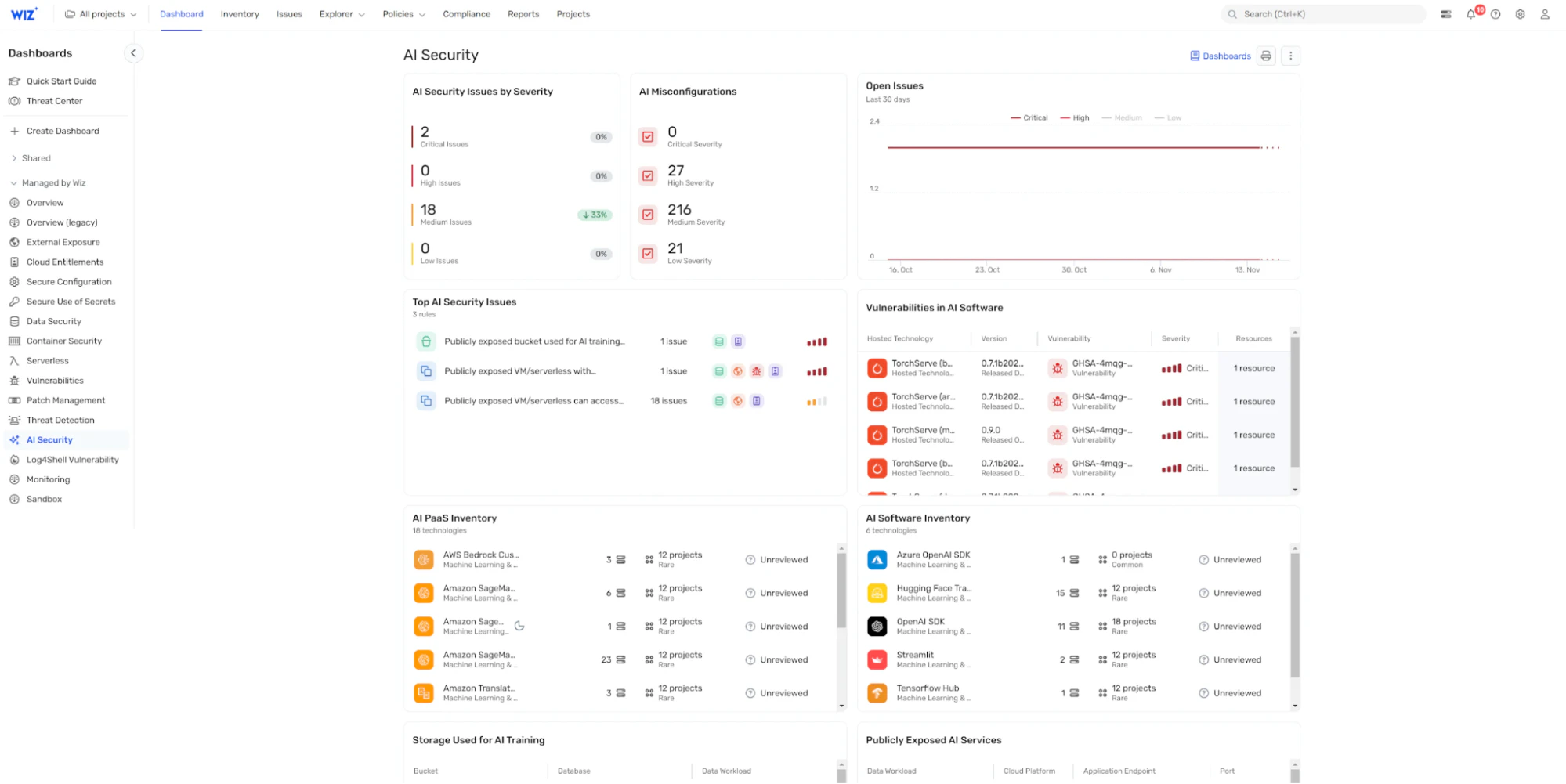
중앙 집중식 AI 보안 대시보드를 통해 위즈 AI-SPM 다음을 제공합니다.
AI BOM(AI BOM): AI 구성 요소 및 종속성에 대한 자세한 맵으로 전체 생태계에 대한 명확한 가시성을 제공합니다.
잘못된 구성 감지: AI 파이프라인 및 클라우드 서비스 전반의 보안 격차를 자동으로 식별하여 취약점이 확대되기 전에 해결하도록 지원
공격 경로 분석: 공격자가 AI 보안 위험을 악용하는 데 사용할 수 있는 잠재적 경로를 시각화하여 더 많은 정보에 입각한 위험 관리를 가능하게 합니다.
AI 기반 조사: Mika AI를 통해 AI 레드팀 활동을 가속화하세요. 이 AI는 잠재적인 취약점을 빠르게 조사하고, 복잡한 공격 시나리오를 이해하며, 자연어로 실행 가능한 해결 지침을 받을 수 있도록 도와줍니다
자동 응답: AI 레드팀이 치명적인 취약점을 발견하면, 위즈 세코옵스 AI 에이전트 자동으로 분류, 조사, 대응 워크플로우를 시작할 수 있어 탐지부터 복구까지의 시간을 단축할 수 있습니다
이러한 기능을 통합함으로써 Wiz AI-SPM은 AI 보안 모범 사례를 구현할 뿐만 아니라 귀사의 조직에 대한 지속적인 모니터링 및 자동화된 위험 관리를 간소화하여 강력한 AI 거버넌스를 보장합니다.
다음 단계
AI 레드팀은 특히 규제 요구가 증가함에 따라 AI 채택을 보호하기 위해 노력하는 조직에게 중요한 보안 기능이 되고 있습니다. 이 분야는 계속 발전하고 있지만 복잡한 공격, 상황별 상호 운용성, 표준화 부족과 같은 과제는 여전히 남아 있습니다.
Wiz와 같은 보안 플랫폼은 방어를 선제적으로 갖추고 지속적인 개선을 보장함으로써 AI 보안 모범 사례를 선도할 수 있도록 도울 수 있습니다. 더 알고 싶으신가요? 방문해 보세요
Wiz와 같은 보안 플랫폼은 방어를 부트스트래핑하고 지속적인 개선을 보장함으로써 AI 보안 모범 사례보다 앞서 나가는 데 도움이 될 수 있습니다. 더 자세히 알아볼 준비가 되셨나요? 더 알아보기 위즈 AI-SPM, 또는 원한다면 라이브 데모저희는 여러분과 연결되고 싶습니다.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
