

À medida que as organizações incorporam cada vez mais IA em seus produtos e operações, a segurança dos sistemas de IA tornou-se uma prioridade máxima para SecOps. Mas proteger IA não é como proteger software tradicional – IA é um ecossistema de modelos, pipelines de dados, código, APIs e integrações de terceiros, todos introduzindo novos riscos de segurança e conformidade.
Se seus aplicativos de IA forem executados na nuvem, esses riscos se tornarão ainda mais desafiadores. Os modelos de IA hospedados na nuvem interagem dinamicamente com conjuntos de dados externos, APIs e usuários, tornando-os mais suscetíveis a envenenamento de dados, injeção de prompt e ataques adversários.
Os testes de segurança tradicionais não são suficientes para lidar com a IA'superfície de ataque expandida e complexa. É por isso que o red teaming da IA – uma prática que simula ativamente ataques adversariais em condições reais – está emergindo como um componente crítico nas estratégias modernas de segurança da IA e um contribuinte fundamental para o Crescimento do mercado de cibersegurança em IA.
Com Regulamentos de segurança de IA mais rígidos e a adoção da IA disparando, as organizações devem adotar a equipe vermelha de IA para ficar à frente das ameaças em evolução e novas oportunidades.
O que é equipe vermelha de IA?
O red teaming de IA é uma prática de segurança cibernética que simula ataques a sistemas de IA para identificar vulnerabilidades em condições do mundo real.
Ao contrário dos benchmarks de segurança padrão e dos testes de modelo controlados, o red teaming de IA vai além da avaliação da precisão e da imparcialidade do modelo. Ele examina todo o ciclo de vida e cadeia de suprimentos da IA – desde modelos e pipelines de dados até serviços de IA hospedados na nuvem e interações usuário-IA, garantindo que cada componente seja resiliente contra potenciais adversários.
Ao adotar uma postura adversarial, o red teaming da IA descobre proativamente fraquezas ocultas de segurança – seja introduzidas por meio de treinamento de modelos, pipelines de inferência ou interações em tempo real com usuários. Ele vai além das avaliações de modelos estáticos e garante que os sistemas de IA permaneçam resilientes em condições dinâmicas do mundo real.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Quais testes são normalmente realizados para o red teaming de IA?
A equipe vermelha de IA eficaz requer uma abordagem abrangente que abranja aspectos técnicos e operacionais para cobrir a superfície de ataque expandida das implantações corporativas. As principais áreas de teste incluem:
Viés & Teste de imparcialidade: Avalia se os modelos de IA produzem resultados discriminatórios ou tendenciosos, inclusive quando sob estresse ou pressão adversária
Violações de privacidade de dados: Identifica riscos de Vazamento de dados ou acesso não autorizado, garantindo que informações sensíveis sejam protegidas em todo o pipeline de dados
Riscos de interação entre humanos e IA: Testa como sistemas de IA respondem a entradas e uso maliciosos ou inesperados de usuários, o que é fundamental para detectar vulnerabilidades como Injeção Rápida
Defesa de ML adversarial: Avalia a capacidade dos sistemas de IA de resistir a ataques adversários direcionados, como injeção rápida e Envenenamento de dados
Áreas adicionais de teste incluem desempenho sob estresse, análise de vulnerabilidade de integração e modelagem de ameaças específicas do cenário.
Esses testes devem levar em conta a natureza em constante evolução dos sistemas de IA, onde o retreinamento contínuo e o desvio do modelo exigem medidas de segurança dinâmicas e adaptativas. Como a IA está em constante evolução, as organizações também devem investir em estratégias robustas de medição e mitigação para se manterem à frente Riscos de segurança da IA.
Qual é o objetivo do red teaming de IA?
A equipe vermelha de IA visa proteger usuários e empresas do uso indevido da IA, destacando (e corrigindo) falhas nos sistemas de IA para que os sistemas de IA sejam resilientes e confiáveis. Os principais objetivos do red teaming de IA incluem:
Identificação de riscos: Detectar e resolver vulnerabilidades de IA antes que os invasores as explorem
Construção de resiliência: Fortalecimento dos modelos e da infraestrutura de IA contra ameaças adversárias
Alinhamento regulatório: Atender aos requisitos de conformidade, incluindo os do Lei da UE sobre IA e o Ordem executiva da Casa Branca dos EUA sobre IA
Confiança pública: Garantir que a IA seja segura, confiável e alinhada com os padrões éticos
Integrando o red teaming de IA em um contexto mais amplo Gestão de riscos de IA estratégia e Estrutura de governança de IA é fundamental para alcançar segurança proativa e de longo prazo em toda a sua organização.
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

Como o red teaming para IA difere do red teaming tradicional?
Embora tanto o red teaming de IA quanto o red teaming tradicional se concentrem em identificar vulnerabilidades antes que os invasores possam explorá-las, eles diferem fundamentalmente em escopo, metodologias e objetivos.
Equipe vermelha tradicional: Focada em infraestrutura, redes e aplicativos
A equipe vermelha tradicional simula ataques cibernéticos do mundo real contra a infraestrutura de TI, os aplicativos e os funcionários de uma organização. O objetivo principal é avaliar o desempenho das defesas de segurança contra adversários, visando:
Segurança de rede: Exploração de configurações incorretas, escalonamento de privilégios, movimento lateral
Segurança do aplicativo: Identificar vulnerabilidades de aplicativos da web, como injeção de SQL (SQLi), execução remota de código (RCE)e XSS (cross-site scripting)
Engenharia social: Manipular funcionários para revelar credenciais ou clicar em links de phishing
A equipe vermelha tradicional é bem definida, seguindo os padrões da indústria, como o MITRE ATT&CK, NIST 800-53 e OSSTMM. As vulnerabilidades encontradas geralmente têm correções claras (aplicação de patches de software, atualização de configurações, melhoria da conscientização do usuário).
Equipe vermelha de IA: Expandindo a superfície de ataque além da segurança tradicional
A equipe vermelha de IA se expande além das preocupações tradicionais de segurança para levar em conta os riscos exclusivos representados pelos sistemas de IA. Em vez de apenas proteger a infraestrutura onde a IA é executada, ela simula ataques adversários ao próprio modelo de IA, seu pipeline de dados, APIs e interações em tempo real.
Principais diferenças
Ameaças orientadas por dados: Ao contrário das vulnerabilidades de software tradicionais, as ameaças de IA se originam da manipulação de dados, envenenamento de modelos e injeção imediata.
Superfície de ataque em evolução: Os modelos de IA mudam dinamicamente à medida que são retreinados, exigindo avaliações contínuas de segurança.
Segurança & Sobreposição de ética: As vulnerabilidades da IA incluem viés, desinformação, alucinações e problemas de confiabilidade, que são't preocupações típicas na segurança cibernética tradicional.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
Como a equipe vermelha de IA difere do teste padrão de modelos de IA
A maioria dos testes de IA se concentra na precisão, detecção de viés e princípios de IA responsável. A equipe vermelha de IA, no entanto, simula cenários de ataque reais para descobrir lacunas de segurança além dos benchmarks de desempenho.
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
Integrando a equipe vermelha de IA na gestão de riscos de IA e governança de segurança, as organizações podem se manter à frente das ameaças emergentes, garantir conformidade com regulamentos em evolução (como a Lei de IA da UE) e manter a confiança pública em aplicações impulsionadas por IA.
Vulnerabilidades comuns e casos de uso reais de red teaming de IA
Apesar da complexidade da IA, os ataques do mundo real costumam ser surpreendentemente simples, explorando configurações incorretas, pontos fracos negligenciados ou má higiene de segurança da IA. Alguns dos ataques de IA mais comuns incluem:
Ataques de backdoor: Gatilhos ocultos inseridos em sistemas de IA podem permitir que invasores manipulem secretamente as saídas, criando caminhos para controle não autorizado.
Injeção imediata: Ao criar entradas maliciosas, os invasores podem alterar sutilmente as respostas da IA ou até mesmo desencadear vazamentos de dados não intencionais, como colocar um cavalo de Tróia em um sistema confiável.
Envenenamento de dados: A injeção de dados de treinamento corrompidos pode distorcer lentamente o comportamento da IA, ensinando-a efetivamente a agir de maneiras que favoreçam a agenda de um invasor.
Pontos fracos de integração: Vulnerabilidades em APIs e conexões de nuvem podem expor os sistemas à exploração, permitindo que os invasores ignorem as medidas de segurança e obtenham acesso a dados críticos.
Essas vulnerabilidades não são apenas teóricas. Vamos explorar casos do mundo real, descobertos pelo Equipe de pesquisa da Wiz, que colocaram esses riscos em foco:
Vazamento de banco de dados do DeepSeek: Falhas de integração no modelo DeepSeek mais recente levaram à exposição de dados confidenciais de treinamento de IA.
🔍Este exemplo do mundo real mostra como… novas ameaças de IA podem surgir de configurações incorretas de acesso a APIs e modelos negligenciadas.
Vulnerabilidades de IA da SAP: Configurações incorretas nos sistemas de IA da SAP criaram riscos ocultos de backdoor, potencialmente permitindo que invasores manipulassem as saídas de IA.
🔍Este exemplo do mundo real mostra como…até mesmo plataformas empresariais bem estabelecidas de IA podem sofrer de pontos cegos de segurança.
Vulnerabilidade de IA da NVIDIA: Pontos fracos no kit de ferramentas de contêiner de IA da NVIDIA permitiram ataques de injeção imediata, expondo lacunas na segurança de IA no nível da infraestrutura.
🔍Este exemplo do mundo real mostra como…atacantes podem manipular o comportamento da IA através de ataques baseados em entradas, impactando nas decisões e saídas orientadas pela IA.
Abraçando os riscos do modelo de rosto: Vulnerabilidades de envenenamento de dados nas populares plataformas de IA como serviço da Hugging Face permitiram que os adversários introduzissem alterações sutis e maliciosas nos dados de treinamento.
🔍Este exemplo do mundo real mostra como…até mesmo serviços de IA amplamente confiáveis são suscetíveis à manipulação de dados adversa, enfatizando a necessidade de testes de segurança contínuos.
Quando se trata de Segurança de IA, até mesmo os erros mais simples podem ter consequências profundas. Sua organização precisa de uma equipe vermelha de IA contínua e proativa para detectar e corrigir esses problemas antes que eles se transformem em violações de segurança completas.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Práticas recomendadas para equipe vermelha de IA: Um framework de 5 etapas
Para efetivamente equipar sistemas de IA, as organizações precisam de uma estrutura de segurança escalável, repetível e em constante evolução. Os modelos de IA treinam e atualizam dinamicamente, tornando as medidas de segurança estáticas ineficazes. Um processo de red teaming de IA bem estruturado garante que a IA permaneça resiliente contra ataques adversários, explorações de viés e configurações incorretas.
Etapa 1: Defina o escopo da equipe vermelha de IA
Antes de testar a segurança de IA, as organizações devem definir:
Quais componentes de IA precisam ser testados?
Robustez do modelo, integrações de API, segurança de IA baseada na nuvem, integridade dos dados de treinamento
Quais são os cenários de ataque?
Ataques de ML adversários (evasão, envenenamento), abuso de API, injeção de prompt, riscos na cadeia de suprimentos
Que segurança & Aplicam-se os requisitos de conformidade?
Segurança de IA, NIST AI RMF, EU AI Act, SOC 2, GDPR
Passo 2: Selecione e implemente métodos de teste adversarial de IA
O red teaming de IA vai além dos testes de penetração - ele requer técnicas de ML adversarial para simular ameaças de IA do mundo real.
Teste centrado no modelo (avaliação de robustez de IA)
Teste de perturbação contraditório: Gera entradas para enganar a IA em classificação incorreta
Inversão de modelo & extração: Tentativas de reconstruir dados de treinamento privados a partir de respostas de IA
Teste de segurança do pipeline de dados
Simulações de envenenamento de dados: Testa se a injeção de dados de treinamento mal-intencionados distorce o comportamento da IA
Viés & Teste de imparcialidade: Avalia se os adversários podem explorar o viés do modelo de IA para manipulação
Interação humano-IA & Segurança de API
Ataques de injeção imediata: Testa se a IA ignora as proteções por meio de entradas manipuladas
Teste de abuso de API: Explora as vulnerabilidades da API do modelo de IA (por exemplo, recuperação irrestrita de dados)
Passo 3: Automatizar o red teaming de IA para escalabilidade
Testar manualmente as vulnerabilidades de IA em implantações em escala de nuvem é ineficiente. A automação ajuda a simular ataques adversários em larga escala.
Use a segurança de IA & Ferramentas de teste contraditório
Garak: Ferramenta de teste contraditório de código aberto para segurança LLM
PyRIT (Identificação de Risco Python para IA Generativa): Simula ataques de evasão e extração de modelos
Contra-ajuste da Microsoft: Teste de segurança de IA para modelos de aprendizado de máquina
Caixa de ferramentas de robustez adversária (ART): Simula ataques e defesas adversárias de IA
Etapa 4: Implementar o monitoramento contínuo de riscos de IA & resposta
O teste de equipe vermelha de IA não é um teste único — ele deve evoluir continuamente à medida que os modelos de IA são atualizados e retreinados.
Estratégias contínuas de equipe vermelha de IA
Estabeleça o compartilhamento de inteligência de ameaças de IA: Acompanhe as ameaças em evolução do MITRE ATLAS e do OWASP AI Top 10.
Adote testes contínuos de segurança de IA: Integre testes contraditórios em pipelines de CI/CD.
Desenvolva pontuação de risco automatizada para IA: Priorize vulnerabilidades de IA de alto risco para correção.
Etapa 5: Alinhe a equipe vermelha de IA com a governança e conformidade
Além da segurança, a equipe vermelha de IA deve apoiar as diretrizes éticas e regulatórias de IA para garantir conformidade.
Principais seguranças de IA & Padrões de conformidade
Estrutura de gerenciamento de risco de IA do NIST (AI RMF): Práticas recomendadas de segurança de IA
Lei de IA da UE: Requisitos de conformidade para aplicativos de IA de alto risco
SOC 2, GDPR, CCPA: Proteja dados pessoais orientados por IA
Integre a equipe vermelha de IA ao gerenciamento de riscos empresariais (ERM)
Relate as descobertas às equipes de governança de IA: Alinhe-se com a ética e os princípios de IA responsável.
Colaboração multifuncional: Envolva as equipes de segurança, ciência de dados e conformidade no gerenciamento de riscos de IA.


Como a Wiz aprimora sua segurança de IA?
Wiz oferece uma plataforma abrangente de segurança em nuvem que amplia suas capacidades para proteger infraestrutura de IA com seus Gestão da postura de segurança de IA (IA-SPM).
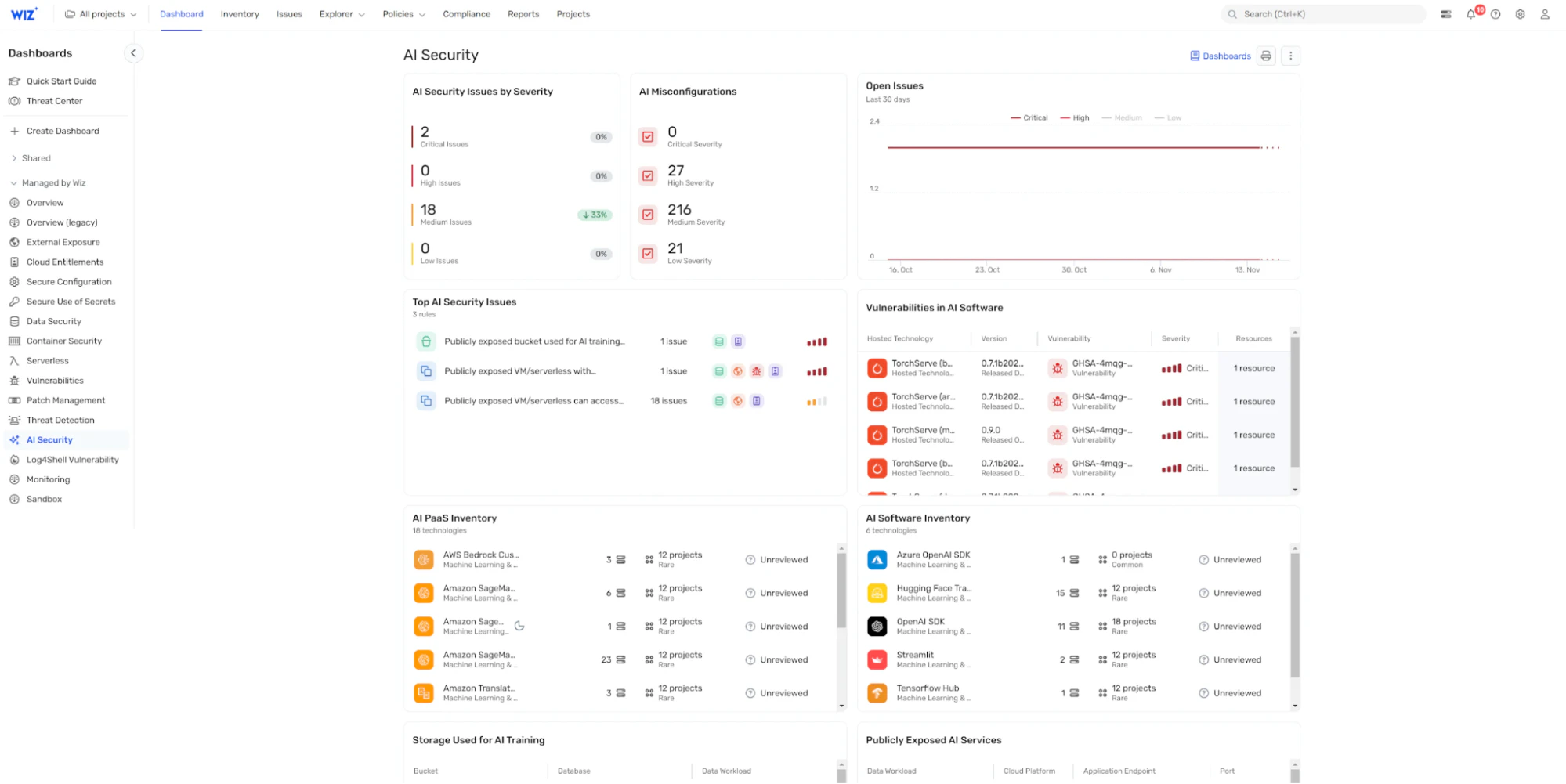
Por meio de seu painel de segurança de IA centralizado, Wiz AI-SPM oferece a você:
Uma lista de materiais de IA (AI BOM): Um mapa detalhado de seus componentes e dependências de IA, oferecendo visibilidade clara de todo o seu ecossistema
Detecção de configuração incorreta: Identificação automatizada de lacunas de segurança em pipelines de IA e serviços em nuvem, ajudando você a lidar com vulnerabilidades antes que elas aumentem
Análise do caminho de ataque: Visualização de possíveis rotas que os invasores podem usar para explorar os riscos de segurança da IA, permitindo um gerenciamento de riscos mais informado
Investigação alimentada por IA: Acelere seus esforços de red teaming em IA com o Mika AI, que ajuda você a investigar rapidamente potenciais vulnerabilidades, entender cenários de ataque complexos e obter orientações práticas de remediação em linguagem natural
Resposta automática: Quando o red teaming de IA descobre vulnerabilidades críticas, o Agente de IA do Wiz SecOps pode triar, investigar e iniciar automaticamente fluxos de trabalho de resposta – reduzindo o tempo desde a detecção até a remediação
Ao integrar essas capacidades, o Wiz AI-SPM não apenas implementa as melhores práticas de Segurança de IA, mas também aprimora o monitoramento contínuo e a gestão automatizada de riscos para sua organização, garantindo uma governança robusta de IA.
O que vem a seguir?
A equipe vermelha de IA está se tornando uma função de segurança crítica para organizações comprometidas em proteger sua adoção de IA, especialmente à medida que as demandas regulatórias aumentam. Embora o campo continue a evoluir, desafios como ataques complexos, interoperabilidade contextual e falta de padronização persistem.
Uma plataforma de segurança como a Wiz pode ajudá-lo a se manter à frente das melhores práticas de Segurança de IA, fortalecendo suas defesas e garantindo melhoria contínua. Pronto para saber mais? Visite
Uma plataforma de segurança como o Wiz pode ajudá-lo a ficar à frente das melhores práticas de segurança de IA, inicializando suas defesas e garantindo a melhoria contínua. Pronto para saber mais? Saiba mais sobre Wiz AI-SPM, ou se preferir um Demo ao vivo, adoraríamos entrar em contato com você.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
