

Was ist Incident Response?
Incident Response ist ein strategischer Ansatz zur Erkennung und Reaktion auf Cyberangriffe. Es umfasst eine koordinierte Reihe von Verfahren, die Ihnen helfen, die Auswirkungen einer Bedrohung organisiert, effizient und zeitnah zu erkennen, zu beseitigen und sich davon zu erholen. Darüber hinaus umfasst es Vorbereitungs- und Feinabstimmungsmaßnahmen, wie z. B. dokumentierte Pläne und Playbooks, Tools und Technologien, Tests und Überprüfungen, um sicherzustellen, dass diese Ziele erreicht werden.
Incident Response ist ein Teil der Management von Vorfällen, die sich auf die umfassendere Art und Weise bezieht, wie Sie mit einem Angriff umgehen würden, Geschäftsleitung, Rechtsabteilungen, HR, Kommunikationenund die breitere IT-Abteilung.
Dieser Leitfaden konzentriert sich im Wesentlichen auf die Reaktion auf Vorfälle. Aber es werden kurz andere Aspekte des Incident Managements behandelt, da es'Es ist wichtig, dass eine Organisation einen ganzheitlichen Ansatz für den Umgang mit zukünftigen Vorfällen verfolgt.
Lassen'S beginnt mit der Wiederholung einiger grundlegender Konzepte.
How to Prepare for a Cloud Cyberattack: An Actionable Incident Response Plan Template
A quickstart guide to creating a robust incident response plan – designed specifically for companies with cloud-based deployments
Download Template

Was ist ein Sicherheitsvorfall?
Incident-Response-Teams müssen schnell handeln, falls sie'wieder in Aktion gerufen werden. Zeitraubende Missverständnisse, die durch die falsche Verwendung von Begrifflichkeiten entstehen können, können sie sich also nicht leisten. Das'Aus diesem Grund müssen sie genau verstehen, was einen Sicherheitsvorfall ausmacht und wie er sich von ähnlichen Begriffen wie Sicherheitsereignis und angreifen.
Ein Sicherheitsereignis ist das Vorhandensein von ungewöhnlichem Netzwerkverhalten, wie z. B. ein plötzlicher Anstieg des Datenverkehrs oder eine Rechteausweitung, das der Indikator für eine Sicherheitsverletzung sein könnte. Dies ist jedoch nicht der Fall'Das bedeutet nicht unbedingt, dass Sie ein Sicherheitsproblem haben. Bei weiteren Untersuchungen könnte sich herausstellen, dass es sich um eine völlig legitime Aktivität handelt.
Ein Sicherheitsvorfall ist ein oder mehrere korrelierte Sicherheitsereignisse mit bestätigten potenziellen negativen Auswirkungen, wie z. B. der Verlust oder der unbefugte Zugriff auf Daten – ob absichtlich oder versehentlich.
Einangreifenist eine vorsätzliche Sicherheitsverletzung mit böswilliger Absicht.
Arten von Sicherheitsvorfällen
Sie sollten auf verschiedene Arten von Vorfällen, unabhängig von ihrer Art, angemessen vorbereitet sein. Sie können also'müssen eine Reihe von Szenarien in Betracht gezogen werden. Dazu gehören unterschiedliche Arten von Anwendungen und die zugrundeliegende Infrastruktur – vor allem aber unterschiedliche Arten von Angriffen.
Die gebräuchlichsten davon sind:
Denial-of-Service (DoS): Ein Versuch, einen Dienst mit gefälschten Anfragen zu überfluten, wodurch er für legitime Benutzer nicht verfügbar ist.
Kompromittierung der Anwendung: Eine Anwendung, die'gehackt wurden, unter Verwendung von Techniken wie Einschleusung von SQL-Befehl, Cross-Site-Scripting (XSS)und Cache-Vergiftung, um Daten zu beschädigen, zu löschen oder zu exfiltrieren oder andere Formen von bösartigem Code auszuführen.
Ransomware: Eine Art von Malware, die mithilfe von Verschlüsselung den Zugriff auf Ihre Daten blockiert. Der Angreifer verlangt dann ein Lösegeld im Austausch für die Verschlüsselungsschlüssel.
Datenschutzverletzung: Eine Sicherheitsverletzung, die speziell den unbefugten Zugriff auf sensible oder vertrauliche Daten beinhaltet.
Man-in-the-Middle (MitM): Eine moderne Form des Abhörens, bei der ein Angreifer heimlich den Datenaustausch zwischen zwei Parteien abfängt und die Kommunikation zwischen ihnen manipuliert.
Dementsprechend sollten Sie ein tiefes Verständnis für die verschiedenen Arten von Angriffen und potenzielle Schwachstellen in Ihren Systemen entwickeln. Dies hilft Ihnen bei der Formulierung von Reaktionsverfahren und der Identifizierung von Werkzeug- und Technologieanforderungen. Gleichzeitig hilft es Ihnen, Ihre Sicherheitsvorkehrungen zu verbessern und das Risiko eines größeren Vorfalls von vornherein zu verringern.
The Cloud Security Threat Report
The Wiz Threat Research team looks back on the past year to highlight trends and the state of multi cloud usage based on visibility across our customer base.
Download Report

Incident Response in der Cloud
Angesichts der weit verbreiteten Einführung der Cloud entwickelt sich die Incident Response weiter, um den Herausforderungen gerecht zu werden, die durch neue Arten von Bedrohungen und unterschiedliche Anwendungsbereitstellungsmodelle entstehen.
Viele Unternehmen verlassen sich jedoch immer noch auf veraltete Verfahren zur Reaktion auf Vorfälle. Sie müssen daher angemessen vorbereitet bleiben, indem sie ihre Reaktionsstrategien an die neue Angriffsfläche anpassen. Zum Beispiel durch:
Sicherstellen, dass das Incident-Response-Team ausreichend geschult wird, um Ihre Cloud-basierte IT-Umgebung zu verstehen
Implementierung von Tools, die's wurde speziell für die komplexe und dynamische Natur der Cloud entwickelt
Nutzung der Telemetriedaten, die vom Clouddienstanbieter (Cloud Service Provider, CSP) zur Verfügung gestellt werden
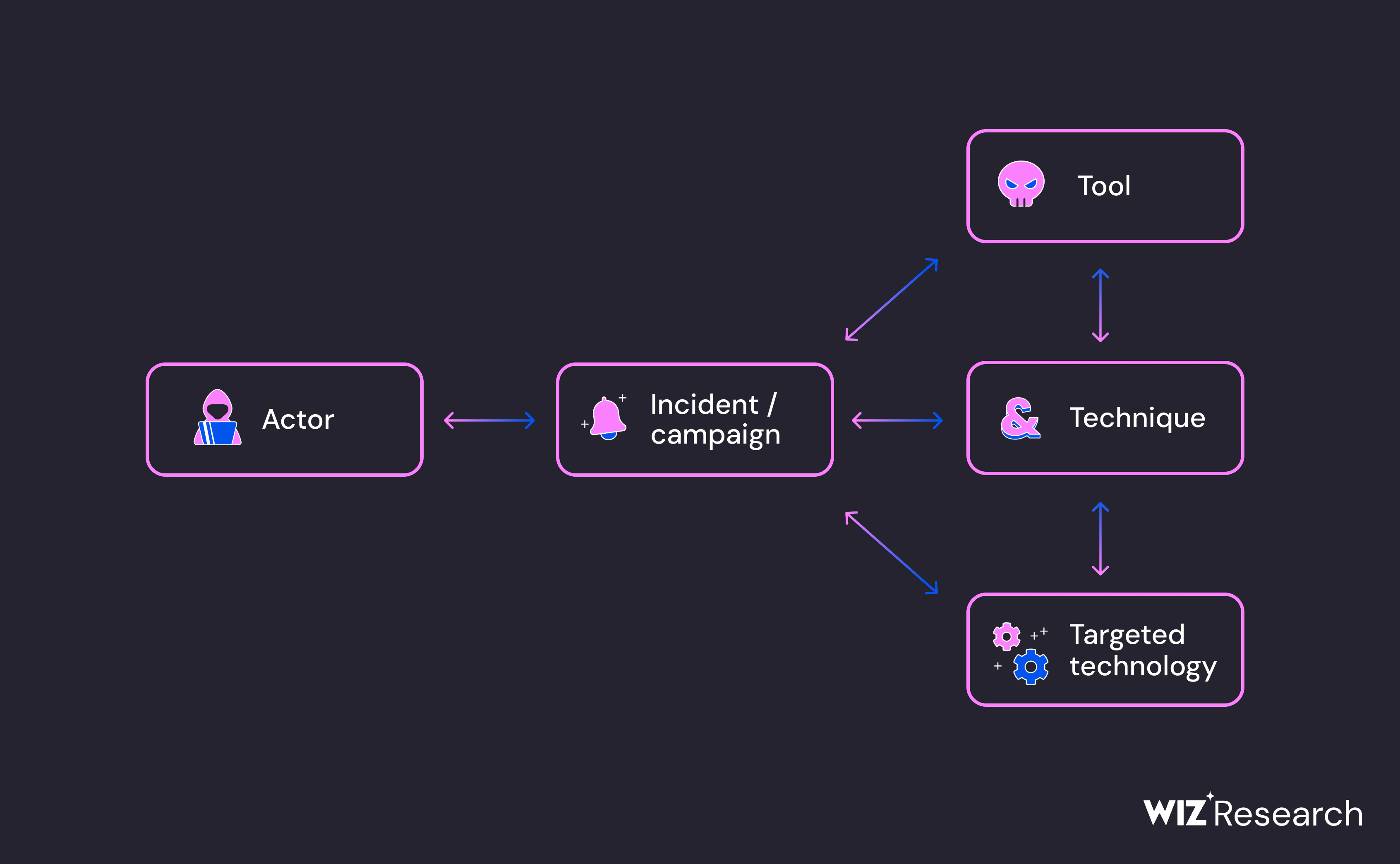
The Cloud Threat Landscape
A comprehensive threat intelligence database of cloud security incidents, actors, tools and techniques.
Explore
Dokumentation zur Reaktion auf Vorfälle
Eine formal dokumentierte Vorgehensweise ist ein wesentlicher Bestandteil jeder robusten Incident-Response-Strategie, da sie einen klaren Fahrplan für den Umgang mit Vorfällen bietet und sicherstellt, dass Sie'dafür angemessen ausgerüstet sind.
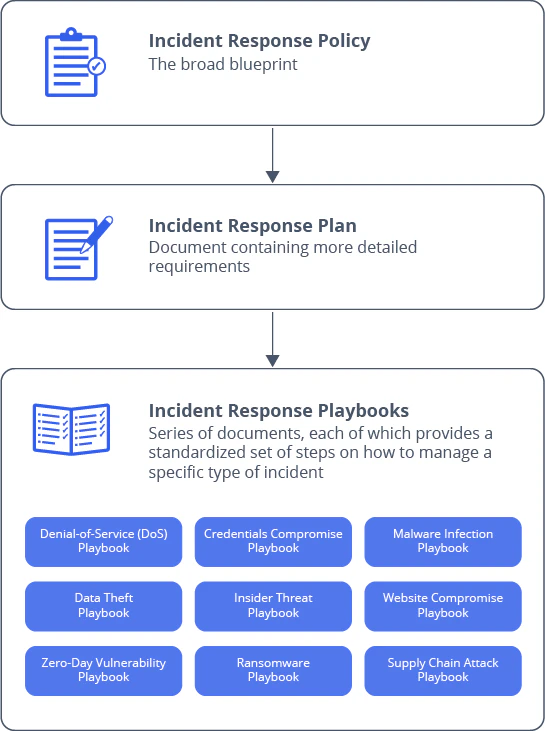
In der Regel besteht Incident Response Material aus drei Arten von Dokumenten, wie folgt.
Richtlinie zur Reaktion auf Vorfälle
Das Politik Das Dokument bringt den Stein für Ihre Initiative ins Rollen und dient als umfassende Blaupause für Ihre Incident-Response-Strategie.
Es sucht die Zustimmung von hochrangigen Entscheidungsträgern, indem es den Business Case für die Reaktion auf Vorfälle darlegt. Es schreibt die Schaffung eines Incident-Response-Teams und eines vollwertigen Incident-Response-Programms vor. Es sollte vom Führungsteam genehmigt werden und Ihnen die Befugnis geben, Ihre Mission voranzutreiben.
Es handelt sich um ein einzelnes Dokument, das das Sprungbrett für eine detailliertere Dokumentation bildet, die auf die praktischen Aspekte des Incident-Response-Prozesses ausgerichtet ist.
How to Create an Incident Response Policy: An Actionable Checklist and Template
Mehr lesen

Plan zur Reaktion auf Vorfälle
Das Plan zur Reaktion auf Vorfälle Erweitert Ihr Richtliniendokument, indem es die Maßnahmen, die Sie für den Umgang mit Cybersicherheitsvorfällen ergreifen sollten, detaillierter erläutert. Es durchläuft den gesamten Reaktionszyklus mit Gliederungsplänen für Folgendes:
Erkennen und Klassifizieren eines Sicherheitsvorfalls
Ermitteln der vollständigen Funktionsweise des Angriffs
Begrenzen Sie die Auswirkungen auf Ihre IT-Systeme und Ihren Geschäftsbetrieb
Beseitigen Sie die Bedrohung
Wiederherstellung nach dem Vorfall
Darüber hinaus wird Folgendes festgelegt:
Vorbereitungen Sie'in Erwartung eines Angriffs
Vorschläge für Maßnahmen nach einem Vorfall zur Analyse und Überprüfung
Ein Plan zur Reaktion auf Vorfälle ist auch ein einzelnes Dokument, das die Grundlage für Ihre Incident-Response-Playbooks bildet.
Playbooks für die Reaktion auf Vorfälle
Im Allgemeinen handelt es sich bei einem Incident Response Playbook um ein Dokument, das eine sehr detaillierte Reihe von Verfahren für den Umgang mit einer bestimmten Art von Vorfall enthält.
Jedes Playbook ist auf unterschiedliche Umstände zugeschnitten. Sie können z. B.'D Erstellen Sie in der Regel eine Reihe von Playbooks für verschiedene Angriffsvektoren. Sie können jedoch auch ein Playbook verwenden, um Anweisungen für eine bestimmte Rolle im Incident-Response-Team bereitzustellen. Dies ist im breiteren Prozess des Incident Managements üblich. Zum Beispiel können Sie'd erstellt in der Regel Playbooks für Rechts- und PR-Teams, um sie bei der Erfüllung von Compliance-Anforderungen und der Abwicklung der Kommunikation zu unterstützen.
Das Incident-Response-Team
Das Incident Response Team ist eine funktionsübergreifende Gruppe von Personen, die für die Orchestrierung der Incident Response Operation verantwortlich sind.
Es setzt sich aus einer Vielzahl von Jobrollen im gesamten Unternehmen zusammen und umfasst in der Regel Folgendes:
Ausführender Sponsor.Ein Mitglied der Geschäftsleitung, z. B. der Chief Security Officer (CSO) oder der Chief Information Security Officer (CISO), das als Fürsprecher für Ihre Incident-Response-Initiative fungiert. Sie übernehmen oft die Verantwortung für die Berichterstattung über den Fortschritt in Ihrem Unternehmen's Führungsteam.
Incident-Response-Manager: Der Teamleiter, der die Incident-Response-Strategie entwickelt und verfeinert und die Aktivitäten koordiniert. Sie übernehmen die Gesamtverantwortung und Autorität während des gesamten Reaktionsprozesses.
Kommunikationsteam: Vertreter Ihrer PR-, Social-Media- und HR-Abteilungen sowie Sprecher und Unternehmensblogger, die dafür verantwortlich sind, Mitarbeiter, Kunden, die Öffentlichkeit und andere Stakeholder über die Entwicklungen auf dem Laufenden zu halten.
Juristisches Team: Benannte Rechtsvertreter, die sich mit der Einhaltung und den strafrechtlichen Auswirkungen eines Vorfalls sowie mit potenziellen Vertragsverletzungen befassen.
Technisches Team.Personen aus Ihren IT- und Sicherheitsteams, die für die technischen Aufgaben bei der Erkennung, Analyse, Eindämmung und Beseitigung der Bedrohung qualifiziert sind.
Lebenszyklus der Reaktion auf Vorfälle
Ein gut strukturierter und systematischer Incident-Response-Lebenszyklus ist das Herzstück eines effektiven Incident-Managements und bietet einen schrittweisen Prozess für den Umgang mit einem Angriff. Sie müssen jedoch nicht'Sie müssen nicht bei Null anfangen, um Ihren eigenen Reaktionszyklus zu entwickeln, da eine Reihe von Frameworks zur Verfügung stehen, die Sie durch den Prozess führen.
Dazu gehören:
NIST 800-61: Leitfaden zur Behandlung von Computersicherheitsvorfällen
SANS 504-B Incident-Response-Zyklus
ISO/IEC 27035 Reihe: Informationstechnologie – Management von Informationssicherheitsvorfällen
In ähnlicher Weise veröffentlichte Wiz kürzlich einen Vorlage für einen Incident-Response-Plan das'richtet sich speziell an diejenigen, die für den Schutz der Öffentliche Cloud, Hybride Cloud und Multicloud (Multicloud) Bereitstellungen.
Obwohl jedes Incident-Response-Framework einen etwas anderen Ansatz verfolgt, unterteilen sie alle den Lebenszyklus im Wesentlichen in die folgenden Phasen.
Präparat
Der schlechteste Zeitpunkt, um mit der Arbeit an einer Reaktionsstrategie zu beginnen, ist genau dann, wenn ein Vorfall eintritt, da Sie schnell handeln müssen, um den Schaden zu minimieren und Unterbrechungen für Ihr Unternehmen zu reduzieren. Das'Deshalb ist die Vorbereitung so wichtig.
Die Vorbereitungsphase der Incident Response stellt sicher, dass Sie alles im Voraus vorbereitet haben, damit Sie ohne Verzögerung auf einen Vorfall reagieren können. Es wird Vorkehrungen treffen wie:
Die Bildung des Incident Response Teams
Ein aktuelles Asset-Inventar, um sicherzustellen, dass Sie alle Grundlagen abgedeckt haben
Erfassung von Protokolldaten zur Unterstützung der Timeline-Analyse nach einem Vorfall
Beschaffung von Werkzeugen für die schnelle Erkennung und Eindämmung
Implementierung eines Issue-Tracking-Systems zur Eskalation von Fällen und zur Überwachung des Fortschritts
Notfallmaßnahmen zur Minimierung von Unterbrechungen des Geschäftsbetriebs
Schulung zur Reaktion auf Vorfälle
Testübungen zur Reaktion auf Vorfälle
Cyber-Versicherungsschutz
Erkennung
In der Erkennungsphase wird methodisch festgestellt, ob ein Sicherheitsvorfall aufgetreten ist oder kurz bevorsteht. Zu den ersten Anzeichen eines Angriffs gehören:
eine hohe Anzahl an fehlgeschlagenen Anmeldeversuchen
Ungewöhnliche Servicezugriffsanfragen
Privilegien-Eskalationen
Blockierter Zugriff auf Konten oder Ressourcen
Fehlende Datenbestände
Langsam laufende Systeme
ein Systemabsturz
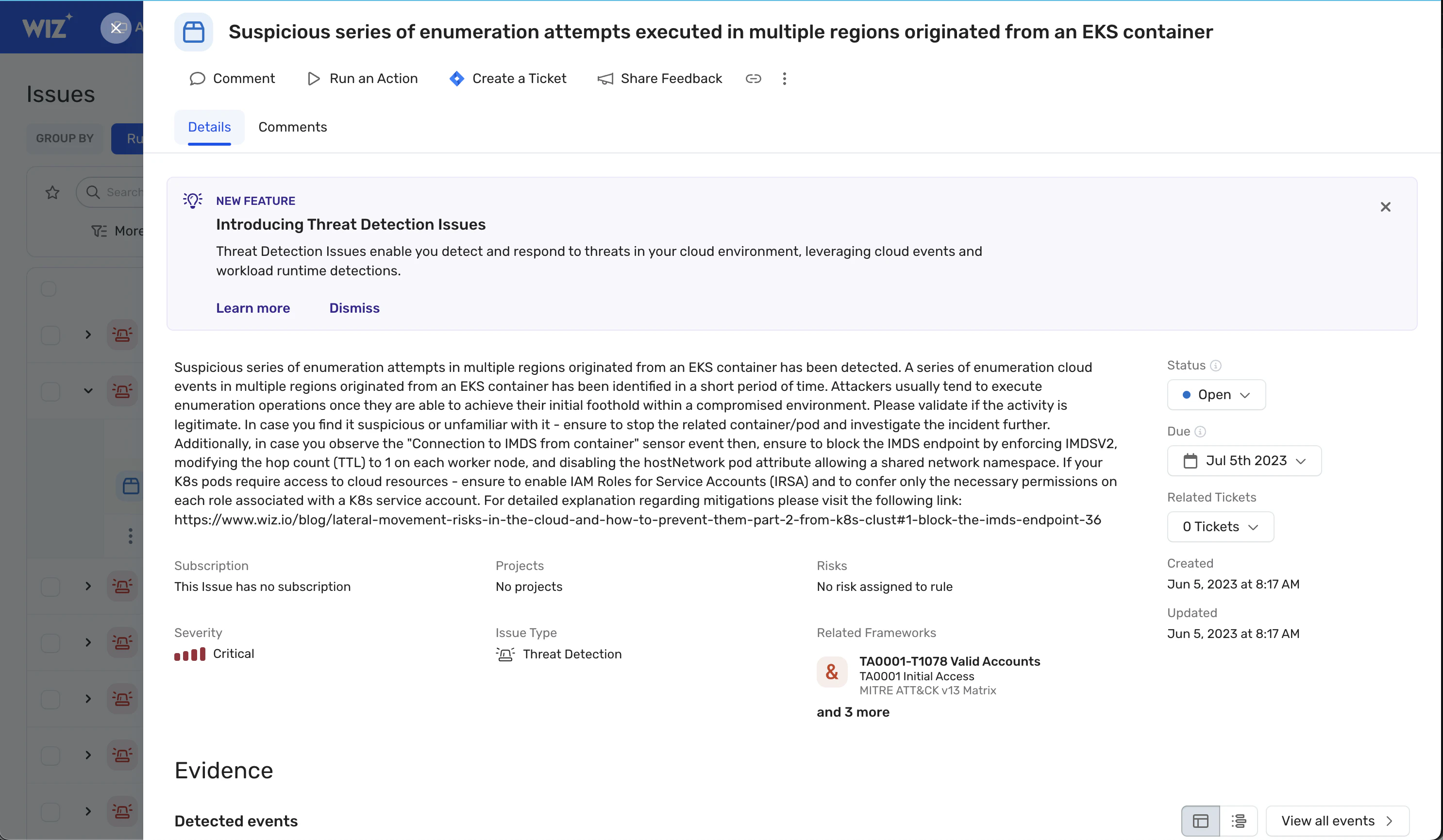
Die Erkennung ist jedoch einer der schwierigsten Aspekte der Reaktion auf Vorfälle, da sie die Korrelation von Informationen aus einer Reihe von Quellen erfordert, um zu bestätigen, dass es sich bei solchen Ereignissen um einen tatsächlichen Sicherheitsvorfall handelt. Zu den Quellen können gehören:
Telemetrie der Arbeitsauslastung
Von einem CSP verfügbare Telemetriedaten
Bedrohungsinformationen von Drittanbietern
Feedback von Endnutzern
Andere Parteien in Ihrer Software-Lieferkette
Untersuchung/Analyse
Die Phase der Vorfalluntersuchung umfasst eine systematische Reihe von Schritten, um die Ursache des Angriffs, die wahrscheinlichen Auswirkungen auf Ihre Bereitstellungen und geeignete Korrekturmaßnahmen zu ermitteln.
Wie in der Erkennungsphase geht es darum, Ereignisdaten aus verschiedenen Protokollquellen zusammenzuführen, um ein vollständiges Bild des Vorfalls zu erhalten.
Eindämmung
Der Zweck der Eindämmungsphase besteht darin,
Minimieren Sie den Explosionsradius eines Angriffs
Begrenzen Sie die Auswirkungen auf Ihre IT-Systeme und Ihren Geschäftsbetrieb
Verschaffen Sie sich Zeit, bevor Sie umfassendere Abhilfemaßnahmen ergreifen

Die Methoden variieren je nach Art des Vorfalls. Um beispielsweise einen Denial-of-Service-Angriff (DoS) einzudämmen,'d Implementierung von Netzwerkmaßnahmen, wie z. B. IP-Adressfilterung. Aber in vielen anderen Fällen können Sie'd Isolieren Sie Ressourcen, um eine laterale Bewegung des Angriffs zu verhindern. Die Art und Weise, wie Sie'Dies hängt von der Art der Infrastruktur ab. In einer traditionellen IT-Umgebung wäre ein Sicherheitstool wie Endpoint Detection and Response (EDR) die effizienteste Methode. Aber in einer Cloud-basierten Umgebung ist es'Im Allgemeinen ist es einfacher, die Sicherheitsgruppeneinstellungen der Ressource über die Steuerungsebene zu ändern.
Did you know? Gartner recognizes cloud investigation and response automation (CIRA) as an indispensable technology in the cybersecurity landscape. Gartner views CIRA as a strategic investment for organizations looking to fortify their security posture in the cloud. Simply put, the shift to cloud computing brings unprecedented opportunities but also introduces new risks.
Ausrottung
Die Ausrottung ist die Phase, in der Sie die Bedrohung vollständig entfernen, so dass sie's nicht mehr vorhanden irgendwohin innerhalb des Netzwerks Ihrer Organisation.
Zu den Möglichkeiten, Ihre Systeme von einer Bedrohung zu befreien, gehören:
Entfernen von bösartigem Code
Neuinstallation von Anwendungen
Rotieren von Geheimnissen wie Anmeldeinformationen und API-Token
Blockieren von Zugangspunkten
Patchen von Schwachstellen
Aktualisieren von Infrastructure-as-Code-Vorlagen (IaC)
Wiederherstellen von Dateien in den Zustand vor der Infektion
Es'Es ist auch wichtig, sowohl betroffene als auch nicht betroffene Systeme nach der Behebung zu scannen, um sicherzustellen, dass keine Spuren des Eindringens hinterlassen wurden.
Überprüfung nach dem Vorfall
Die Überprüfungsphase bietet Ihnen die Möglichkeit, Ihre Reaktionsstrategie zu verfeinern, damit Sie'besser gerüstet sind, um potenzielle Vorfälle in der Zukunft zu bewältigen. Dabei sollten die Art und Weise, wie Sie auf den Vorfall reagiert haben, das Feedback des Incident-Response-Teams und die Auswirkungen des Vorfalls auf Ihren Geschäftsbetrieb berücksichtigt werden.
Im Folgenden finden Sie folgende Arten von Fragen, die Sie bei der Durchführung Ihrer Überprüfung stellen sollten:
War unsere Dokumentation ausreichend klar?
Waren die Informationen korrekt?
Haben die Mitglieder des Incident-Response-Teams ihre Rollen und Verantwortlichkeiten verstanden?
Wie lange hat es gedauert, verschiedene Aufgaben zu erledigen?
Brauchen wir weitere Maßnahmen, um ähnliche Vorfälle in Zukunft zu verhindern?
Gab es Lücken in unseren Sicherheitstools?
Haben wir Fehler gemacht, die die Wiederherstellungszeit verzögert haben?
Wurde bei dem Vorfall ein Verstoß gegen Compliance-Anforderungen festgestellt?
Geschäftskontinuität und Notfallwiederherstellung (BCDR)
Geschäftskontinuität (BC) ist die Reihe von Notfallmaßnahmen, über die Ihr Unternehmen verfügen sollte, um geschäftskritische Vorgänge während einer Unterbrechung, wie z. B. eines Sicherheitsvorfalls, am Laufen zu halten. Notfallwiederherstellung (DR)auf der anderen Seite ist die Gesamtheit der Vorkehrungen, die Sie treffen, um Systeme wieder in den Normalzustand zu versetzen – mit minimalen Ausfallzeiten und Auswirkungen auf Ihr Unternehmen.
Beide Disziplinen sind daher ein wesentlicher Bestandteil für den Erfolg Ihrer Reaktion. Sie müssen sich jedoch mit Ihrer Incident-Management-Strategie abstimmen, um:
Stellen Sie sicher, dass Sie BCDR-Verfahren an der am besten geeigneten Stelle im Reaktionszyklus auslösen.
Minimieren Sie das Risiko der Persistenz von Bedrohungen
Um diese Ziele zu erreichen, müssen Sie Folgendes berücksichtigen:
Die Sicherheit eines jeden Failover-Systems
Sichern Sie Hygienepraktiken zur Vermeidung von Infektionen
Prioritäten des Wiederaufbaus
Systemabhängigkeiten
Tools und Technologien
Die richtigen Tools sind ein Geschenk des Himmels, wenn Sie mit einem Live-Sicherheitsvorfall konfrontiert sind und die Bedrohung so schnell wie möglich angehen müssen. Zum Schluss wollen wir'Wir haben einige der Tools zur Reaktion auf Vorfälle und Technologien, die Sie'Eine effektive Reaktion ist erforderlich, zusammen mit der Rolle, die sie im Reaktionszyklus spielen.
| Technology | Description | Role in response lifecycle |
|---|---|---|
| Threat detection and response (TDR) | A category of security tools that monitor environments for signs of suspicious activity and provide remediation capabilities to contain and eradicate threats. Examples of TDR technology include endpoint detection and response (EDR) and cloud detection and response (CDR). | Detection, investigation, containment, and eradication |
| Security information and event management (SIEM) | An aggregation platform that enriches logs, alert, and event data from disparate sources with contextual information, thereby enhancing visibility and understanding for better incident detection and analysis. | Detection and investigation |
| Security orchestration, automation and response (SOAR) | A security orchestration platform that integrates different security tools, providing streamlined security management through a unified interface. Allows you to create playbooks to perform predefined automated responses. | Detection, investigation, containment, and eradication |
| Intrusion detection and prevention system (IDPS) | A traditional defense system that detects and blocks network-level threats before they reach endpoints. | Detection and investigation |
| Threat intelligence platform (TIP) | An emerging technology that collects and rationalizes external information about known malware and other threats. TIP helps security teams quickly identify the signs of an incident and prioritize their efforts through insights into the latest attack methods adversaries are using. | Detection, investigation, containment, and eradication |
| Risk-based vulnerability management (RBVM) | A security solution that scans your IT environment for known vulnerabilities and helps you prioritize remediation activity based on the risk such vulnerabilities pose to your organization. | Containment and eradication |
Wiz für Cloud-native IR
Wiz bietet eine umfassende Cloud Detection and Response (CDR)-Lösung Um Unternehmen dabei zu unterstützen, Sicherheitsvorfälle in Cloud-Umgebungen effektiv zu erkennen, zu untersuchen und darauf zu reagieren. Hier sind die wichtigsten Aspekte von Wiz's Ansatz für die Reaktion auf Cloud-Incidents:
Kontextualisierte Bedrohungserkennung: Wiz korreliert Bedrohungen über Echtzeitsignale und Cloud-Aktivitäten hinweg in einer einheitlichen Ansicht, sodass Verteidiger die Bewegungen von Angreifern in der Cloud schnell aufdecken können. Diese Kontextualisierung hilft bei der Priorisierung von Warnungen und der Reduzierung von Fehlalarmen, wodurch das Problem der Alarmmüdigkeit gelöst wird, mit dem viele Sicherheitsteams konfrontiert sind.
Cloud-native Überwachung: Die Plattform überwacht Workload-Ereignisse und Cloud-Aktivitäten, um sowohl bekannte als auch unbekannte Bedrohungen und bösartiges Verhalten zu erkennen. Dieser Cloud-native Ansatz ist von entscheidender Bedeutung, da herkömmliche Sicherheitslösungen oft mit der dynamischen Natur von Cloud-Umgebungen zu kämpfen haben.
Playbooks für automatisierte Antworten: Wiz bietet sofort einsatzbereite Reaktions-Playbooks, mit denen betroffene Ressourcen mithilfe von Cloud-nativen Funktionen untersucht und isoliert werden können. Darüber hinaus wird die Sammlung von Beweismitteln automatisiert, sodass Sicherheitsteams schnell durch die Eindämmungs-, Löschungs- und Wiederherstellungsphasen gehen können.
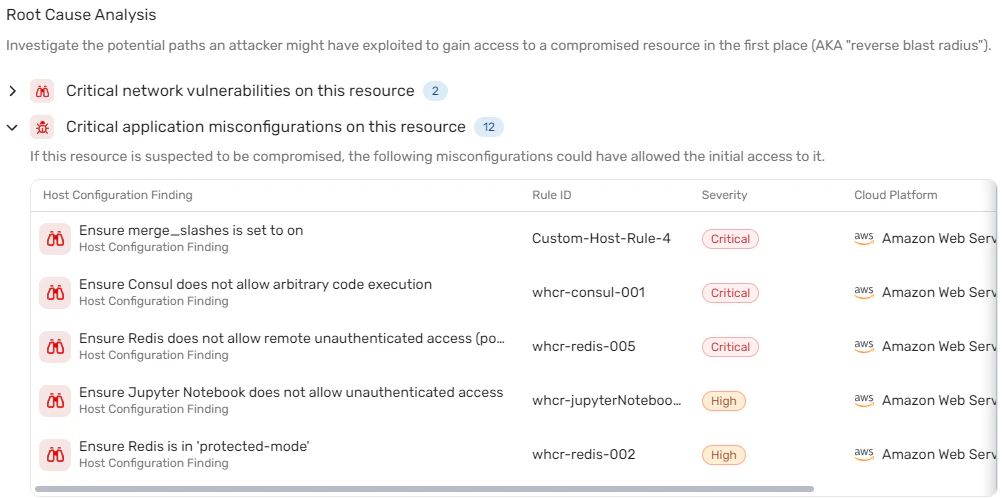
Sicherheitsdiagramm für die Ursachenanalyse: Genie's Security Graph bietet eine automatisierte Ursachen- und Explosionsradiusanalyse, die für die Reaktion auf Vorfälle unerlässlich ist. Es hilft bei der Beantwortung kritischer Fragen, z. B. wie eine Ressource kompromittiert wurde und welche potenziellen Pfade ein Angreifer in der Umgebung nehmen könnte. Weitere Informationen->
Cloud-Forensik: Wiz erweitert seine forensischen Fähigkeiten, indem es eine automatisierte Möglichkeit bietet, wichtige Beweise zu sammeln, wenn eine Ressource möglicherweise kompromittiert wurde. Dazu gehören das Kopieren von VM-Volumes, das Herunterladen von Forensikpaketen mit Protokollen und Artefakten und die Verwendung von Laufzeitsensoren zum Anzeigen von Prozessen auf Containern oder VMs.
Bewertung des Explosionsradius: Der Security Graph ermöglicht es IR-Teams, schnell das Ausmaß der Auswirkungen zu identifizieren, Angriffspfade zu verfolgen und die Ursache von Vorfällen zu erkennen. Dies ist besonders nützlich, um die potenziellen Auswirkungen einer kompromittierten Ressource auf das Geschäft zu verstehen. Weitere Informationen->
Laufzeit-Überwachung: Wiz überwacht die Workloads zur Laufzeit kontinuierlich auf verdächtige Aktivitäten und fügt der Explosionsradiusanalyse Kontext hinzu. Dazu gehört auch die Erkennung verdächtiger Ereignisse, die von Geräteservicekonten oder bestimmten Benutzern ausgeführt werden.