

Los modelos de IA maliciosos son Artefactos de modelos intencionadamente armados que ejecutan acciones dañinas cuando están cargadas o en funcionamiento. A diferencia de los modelos vulnerables —que contienen fallos accidentales— los modelos maliciosos están diseñados para comprometer el entorno en el que se despliegan.
La característica definitoria de los modelos de IA maliciosa es que la amenaza está incrustada dentro del propio archivo modelo. En muchos casos, los atacantes abusan de formatos de serialización inseguros para ocultar código ejecutable dentro de pesos de modelos o lógica de carga. Cuando el modelo se importa o se deserializa, ese código se ejecuta automáticamente, a menudo antes de que ocurra cualquier inferencia.
Esto convierte a los modelos de IA maliciosos en una amenaza clara en la cadena de suministro. Aprovechan la confianza que las organizaciones depositan en modelos preentrenados descargados de repositorios públicos o compartidos internamente entre equipos. Debido a que los artefactos del modelo no se tratan como el código fuente tradicional, con frecuencia saltan controles de seguridad como la revisión de código, el análisis estático y el escaneo de dependencias.
A medida que la adopción de la IA se acelera, los modelos preentrenados se han convertido en un pilar fundamental para el desarrollo moderno. Esa misma comodidad ha convertido los artefactos del modelo en un vector de ataque de alto valor, uno para el que las herramientas tradicionales de seguridad de aplicaciones nunca fueron diseñadas para inspeccionar.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Por qué los modelos de IA maliciosos son un riesgo real en la cadena de suministro
Los modelos de IA maliciosos surgen de las mismas fuerzas que transformaron el desarrollo moderno de software: reutilización, automatización y confianza en componentes externos. Los modelos preentrenados se extraen rutinariamente de repositorios públicos para acelerar el desarrollo, reducir costes y evitar reentrenarse desde cero. En muchas organizaciones, descargar y desplegar modelos se ha vuelto tan rutinario como instalar una biblioteca.
Este flujo de trabajo desplaza la confianza del código revisado internamente hacia artefactos externos que rara vez se inspeccionan. Los archivos modelo suelen tratarse como binarios opacos: almacenados, compartidos y cargados sin el escrutinio aplicado al código de aplicación o a las imágenes del contenedor. Como resultado, frecuentemente saltan los controles de seguridad establecidos como la revisión de código, el análisis estático y el escaneo de dependencias.
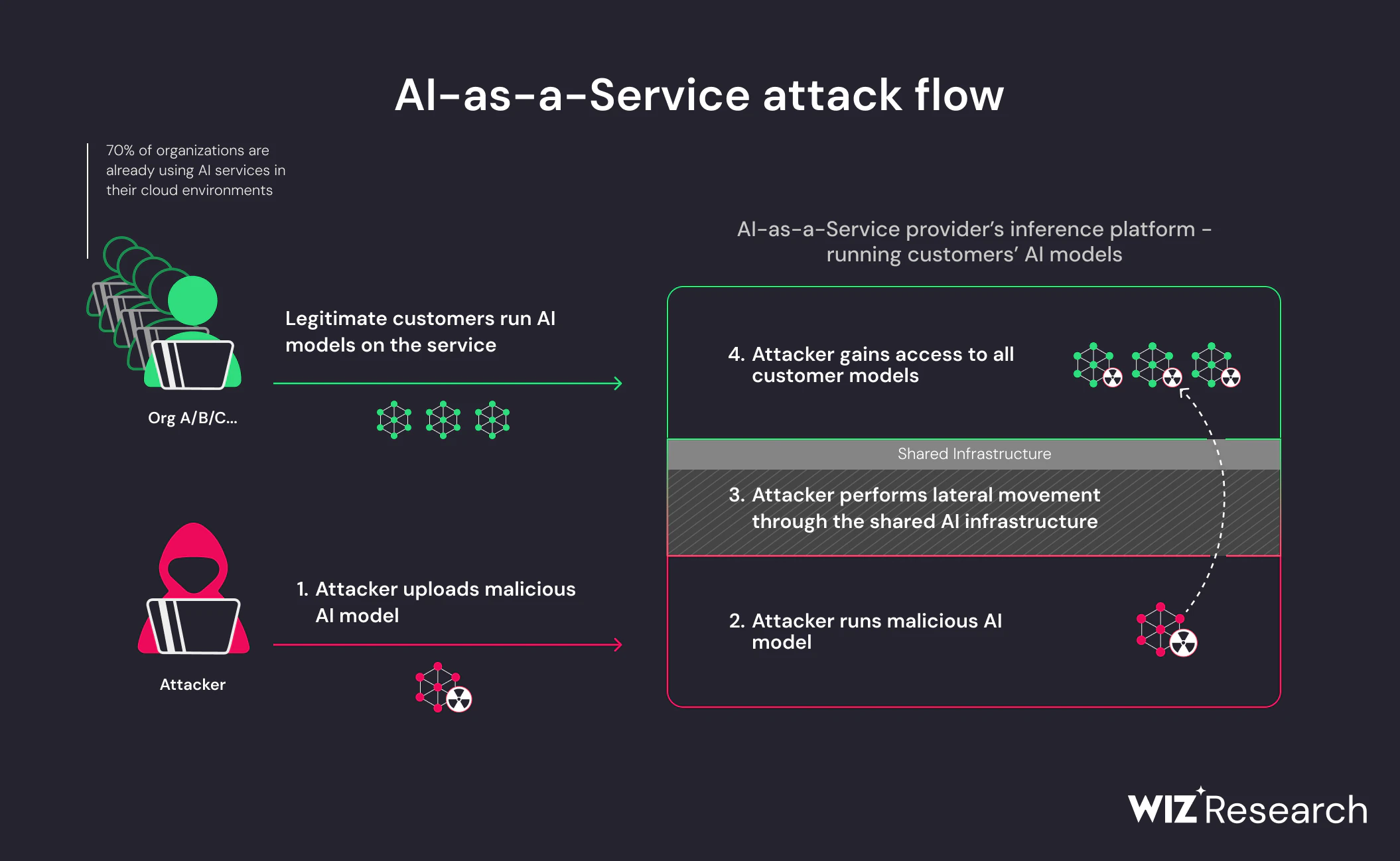
Lo que hace que este riesgo sea especialmente agudo es que los modelos maliciosos explotan Comportamiento esperado. Cargar un modelo es una acción normal y confiable en pipelines de IA. Cuando los atacantes incrustan lógica ejecutable en artefactos del modelo, esa confianza se convierte en el mecanismo de entrega. No se requiere ninguna cadena de exploits; el compromiso ocurre porque el sistema está haciendo exactamente lo que fue diseñado para hacer.
Por eso los modelos de IA maliciosos representan un Amenaza en la cadena de suministro en lugar de un error de la aplicación. El riesgo no proviene de cómo se utiliza un modelo, sino de de dónde viene y cómo se carga. A medida que la reutilización de modelos sigue escalando entre equipos y entornos, la capacidad de validar la procedencia y el comportamiento del modelo se convierte en un requisito fundamental de seguridad.
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
Leer más

Cómo funcionan los modelos de IA maliciosos a un nivel general
Los modelos de IA maliciosos explotan cómo se empaquetan, distribuyen y cargan los modelos en los flujos de trabajo modernos de IA. El riesgo central no son las predicciones del modelo, sino el Ruta de ejecución activada cuando un archivo modelo se deseriariza o inicializa.
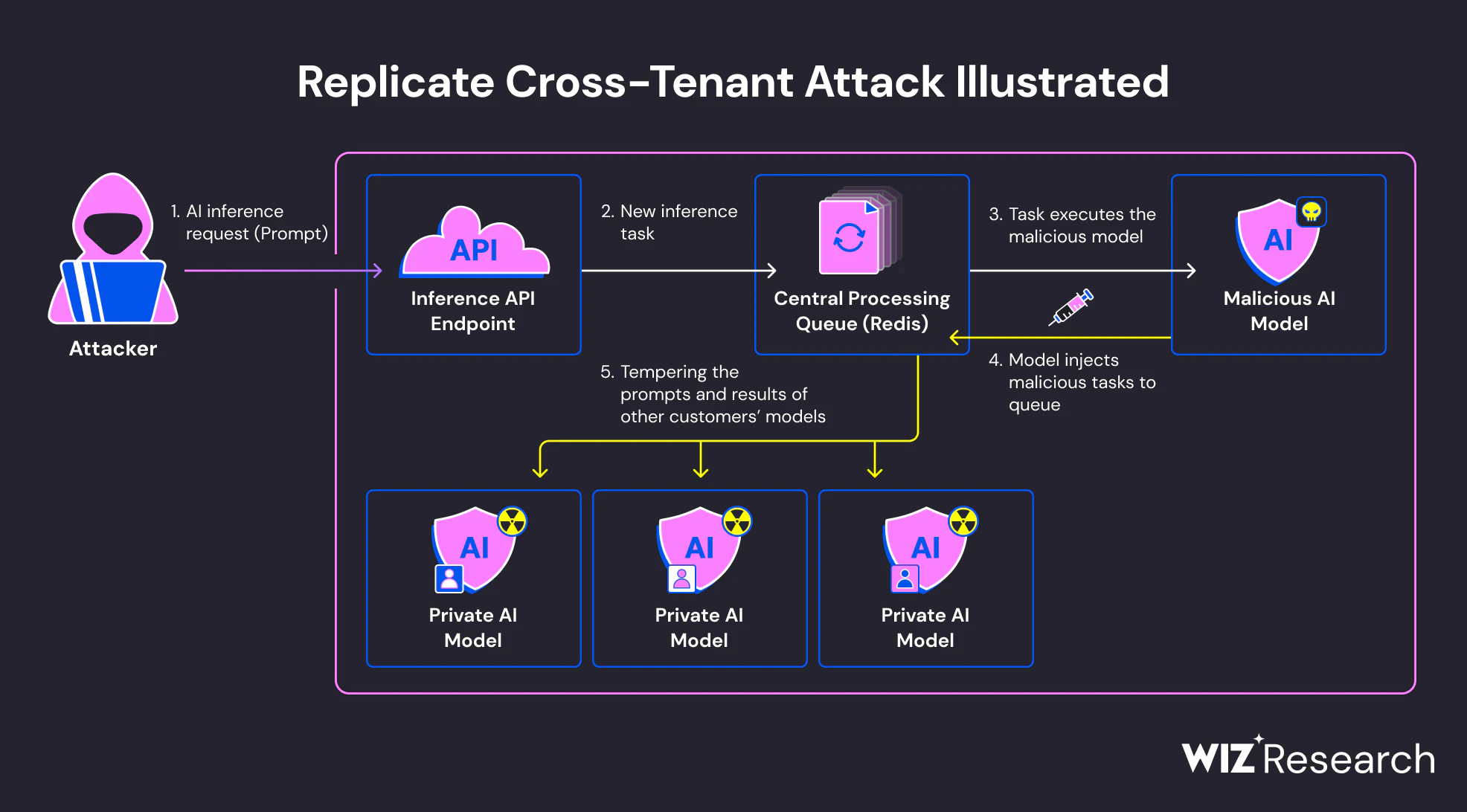
Ejecución durante la carga del modelo
Muchos frameworks de IA soportan formatos de serialización que permiten ejecutar la lógica ejecutable como parte del proceso de carga del modelo. En particular, Python Pepinillolos formatos basados en -– comúnmente usados en PyTorch y herramientas relacionadas – pueden ejecutar código arbitrario cuando un modelo se deserializa. Este comportamiento está documentado, pero a menudo se pasa por alto en la práctica.
Cuando se carga un modelo malicioso, el código incrustado puede ejecutarse inmediatamente, antes de que ocurra la inferencia o la evaluación. Desde la perspectiva del sistema, esto parece una importación normal de modelos. Desde la perspectiva de un atacante, es un punto de ejecución fiable dentro de un entorno de confianza.
Por qué esto ocurre antes de la inferencia
A diferencia del código de aplicación, los modelos se tratan como datos. Los controles de seguridad tienden a centrarse en cómo se usan los modelos, no en cómo se cargan. Como resultado, la actividad más peligrosa ocurre al principio del ciclo de vida —en el momento de carga— antes de que se apliquen la monitorización en tiempo de ejecución, los controles de acceso o las comprobaciones de comportamiento.
Esto es lo que dificulta la detección de modelos maliciosos con herramientas tradicionales. Puede no haber llamadas sospechosas a la API, ni entradas malformadas ni salidas anormales. El compromiso se produce simplemente porque el modelo fue aceptado como legítimo.
Objetivos comunes de los atacantes
Una vez lograda la ejecución, los atacantes suelen perseguir objetivos familiares:
Robar credenciales o tokens disponibles en el entorno
Acceso a datos de entrenamiento o almacenes de datos aguas abajo
Establecer persistencia mediante puertas traseras o tareas programadas
Consumo de recursos de cómputo para la minería de criptomonedas o para compromisos adicionales
Estas acciones no son exclusivas de los entornos de IA, pero los modelos suelen ejecutarse con permisos elevados y la proximidad a datos sensibles, lo que incrementa su impacto.
Formatos más seguros, valores predeterminados más seguros
No todos los formatos de modelo conllevan el mismo riesgo. Formatos diseñados para separar pesos de la lógica ejecutable – como SafeTensors y ONNX –reducir la probabilidad de ejecución de código durante la carga del modelo. Estos formatos almacenan datos de modelos sin rutas de ejecución integradas, lo que los hace más seguros por diseño.
En cambio, los mecanismos de serialización que permiten la lógica ejecutable durante la deserialización aumentan el riesgo a menos que estén estrictamente controlados. En la práctica, la compatibilidad y la comodidad suelen llevar a los equipos a recurrir por defecto a formatos inseguros a menos que se apliquen estándares de seguridad explícitos.
Comprensión cómo por tanto, los modelos están cargados es fundamental para defenderse contra modelos de IA maliciosos. La amenaza no depende de entradas adversariales ni de comportamientos novedosos de la IA: se basa en caminos de ejecución predecibles y confiables en las herramientas comunes de ML.


Vectores de ataque principales para modelos de IA maliciosos
Los modelos de IA maliciosos suelen llegar a producción a través de un pequeño número de vectores de ataque repetibles. Estos vectores aprovechan la confianza en artefactos del modelo y la automatización en los flujos de trabajo de IA en lugar de comportamientos novedosos de IA.
Repositorios públicos de modelos
Los repositorios públicos son el canal de distribución más común para modelos maliciosos. Los atacantes suben modelos armados a plataformas populares o utilizan el typosquatting para imitar proyectos conocidos. Con el tiempo, pueden ganar reputación mediante lanzamientos benignos antes de introducir una versión maliciosa.
Dado que los modelos preentrenados suelen descargarse directamente en entornos de desarrollo o entrenamiento, estos artefactos pueden eludir los procesos de revisión aplicados al código de aplicación o a las imágenes del contenedor.
Ejecución remota de código mediante cargadores de modelos
Algunos flujos de trabajo de IA permiten explícitamente la ejecución remota o personalizada de código durante la carga del modelo. Configuraciones como flags de cargador permisivo o clases de modelos personalizadas amplían la superficie de ataque permitiendo obtener y ejecutar la lógica ejecutable de forma dinámica.
En estos casos, el riesgo no proviene de los pesos del modelo en sí, sino del mecanismo de carga que confía implícitamente en el código externo. Esto hace que la configuración del cargador sea una parte importante del modelo de amenazas.
Modelos de Troyanos y puertas traseras aprendidas
No todos los modelos maliciosos dependen de la ejecución durante la carga. Algunos están diseñados para comportarse normalmente bajo la mayoría de las condiciones durante la producción salidas maliciosas cuando hay disparadores específicos presentes. Estos modelos "troyanos" incrustan comportamientos dañinos directamente en pesos aprendidos en lugar de código ejecutable.
A diferencia de los ataques basados en serialización, los modelos de Troyano suelen dirigirse a la Proceso de entrenamiento o ajuste fino, como mediante datos de entrenamiento envenenados o flujos de trabajo de ajuste fino manipulados. Debido a que el comportamiento malicioso está codificado en los parámetros del modelo, el escaneo estático del artefacto ofrece una visibilidad limitada de la amenaza.
Esto convierte a los modelos de Troyano en una categoría de riesgo distinta. Su detección generalmente requiere pruebas adversariales, análisis de comportamiento o validación de datos de entrenamiento y linaje, en lugar de inspeccionar únicamente el archivo del modelo.
Riesgo de dependencia y de insider
Los modelos maliciosos también pueden entrar en entornos mediante dependencias comprometidas o canales internos de confianza. Esto incluye bibliotecas de ML envenenadas, registros internos inseguros o modelos introducidos por personas internas con acceso legítimo.
Debido a que estos vectores dependen de relaciones de confianza existentes, a menudo se pasan por alto en la modelización temprana de amenazas, a pesar de tener el potencial de un impacto amplio.
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

Por qué los entornos en la nube amplifican el riesgo
Los entornos en la nube no crean modelos de IA maliciosos, pero sí de forma significativa aumentar el impacto y la velocidad de compromiso cuando se presenta uno. Las mismas características que hacen que las plataformas en la nube sean ideales para la IA —automatización, escalabilidad y acceso a datos sensibles— también aumentan el riesgo en la cadena de suministro.
Las cargas de trabajo de IA suelen ejecutarse con permisos elevados. Los trabajos de entrenamiento y los servicios de inferencia a menudo requieren acceso a grandes conjuntos de datos, almacenamiento de objetos, secretos y servicios posteriores. Cuando un modelo malicioso se ejecuta dentro de este contexto, puede heredar inmediatamente esos privilegios, ampliando el radio de explosión más allá del propio modelo.
La automatización amplifica aún más el riesgo. Los modelos suelen desplegarse a través de pipelines CI/CD, marcos de orquestación o flujos de trabajo programados de reentrenamiento. Una vez que un artefacto malicioso entra en uno de estos caminos, puede propagarse rápidamente a través de los entornos sin intervención humana, haciendo que la inspección manual sea poco práctica.
La infraestructura en la nube también cambia en la ejecución relativa a datos sensibles. Los modelos maliciosos suelen ejecutarse dentro del mismo plano de datos al que deben acceder, en lugar de adyacente a ella. A diferencia de una aplicación web comprometida que debe pivotar lateralmente para acceder a una base de datos, un modelo suele ejecutarse dentro del entorno que ya tiene acceso directo a datos de entrenamiento, entradas de inferencia o sistemas aguas abajo. Esto reduce la distancia entre la ejecución y el impacto.
Por último, las cargas de trabajo de IA dependen de pilas complejas de servicios gestionados, contenedores, GPUs y dependencias en tiempo de ejecución. Cada capa introduce desafíos de configuración y aislamiento que los atacantes pueden explotar si los controles se aplican mal. En la práctica, esto significa que los modelos maliciosos se benefician de las mismas configuraciones erróneas que hoy en día provocan muchas brechas en la nube.
En conjunto, estos factores convierten los modelos de IA maliciosos de un riesgo localizado en un Preocupación de seguridad a nivel de sistema, reforzando por qué la seguridad de los modelos debe evaluarse en el contexto de identidades en la nube, acceso a datos y canales de despliegue, no de forma aislada.
Defensa contra modelos de IA maliciosos
Defenderse contra modelos de IA maliciosos requiere un cambio de enfoque del comportamiento del modelo a Procedencia del modelo, rutas de carga y contexto de ejecución. Debido a que la amenaza está incrustada en el propio artefacto o proceso de entrenamiento, tradicional Controles de seguridad de aplicaciones son necesarias pero aren'No son suficientes por sí solas.
Establecer controles antes de que los modelos lleguen a la producción
Las defensas más efectivas operan antes de que se cargue un modelo. Esto incluye validar de dónde provienen los modelos, cómo se empaquetan y qué rutas de código se ejecutan durante la carga. Tratar los artefactos del modelo como componentes de primera clase de la cadena de suministro – sujetos a inspección, aprobación y control de versiones – reduce la probabilidad de que los modelos armados lleguen a entornos sensibles.
En la práctica, esto significa aplicar la misma gobernanza a Registros de modelos que las organizaciones ya aplican a registros de contenedores o repositorios de artefactos. Si las imágenes de contenedores están firmadas, escaneadas y promocionadas mediante pipelines controlados, los artefactos del modelo deberían seguir la misma disciplina, independientemente de si se originan internamente o de fuentes públicas.
Cuando sea posible, los equipos deberían preferir formatos de modelo que separen los datos de la lógica ejecutable y restrinjan configuraciones de cargadores que confíen implícitamente en el código externo. Estos controles no eliminan el riesgo, pero reducen significativamente la superficie de ataque.
Restringir la ejecución mediante controles de identidad y acceso
Los modelos maliciosos son más peligrosos cuando heredan permisos amplios. Limitar las identidades y roles disponibles para las cargas de entrenamiento e inferencia reduce el radio de explosión si un modelo se ve comprometido. Esto incluye hacer cumplir el privilegio mínimo para las cuentas de servicio, aislar entornos y evitar credenciales compartidas entre pipelines.
Como los modelos suelen ejecutarse dentro del plano de datos, el control de acceso se convierte en una línea principal de defensa, no en una protección secundaria.
Monitorizar el comportamiento en contexto, no de forma aislada
La inspección estática por sí sola no puede detectar todos los modelos maliciosos, especialmente aquellos que incrustan comportamientos en pesos aprendidos. La visibilidad en tiempo de ejecución ayuda a cubrir esa carencia observando cómo los modelos interactúan con su entorno a lo largo del tiempo.
El monitoreo efectivo se centra en Señales contextuales: acceso inesperado a la red, operaciones de archivo inusuales, uso anormal de identidad o desviaciones de los patrones de ejecución establecidos. Estas señales son más significativas cuando se correlacionan con el contexto de la nube: qué datos puede acceder el modelo, qué identidades utiliza y cómo se desplegó.
Trata la seguridad de modelos como parte de la seguridad en la nube
En última instancia, defenderse contra modelos de IA maliciosos no es una disciplina independiente. Requiere integrar consideraciones específicas de IA en la existencia Prácticas de seguridad en la nube, incluyendo la gobernanza de la cadena de suministro, la gestión de identidad y el monitoreo de la carga de trabajo.
Al evaluar los modelos como parte del sistema más amplio en el que operan —en lugar de como cajas negras opacas— los equipos de seguridad pueden reducir la exposición a artefactos maliciosos sin depender de la detección especulativa o de suposiciones sobre el comportamiento del modelo.
Cómo Wiz ayuda a reducir el riesgo de modelos de IA maliciosos
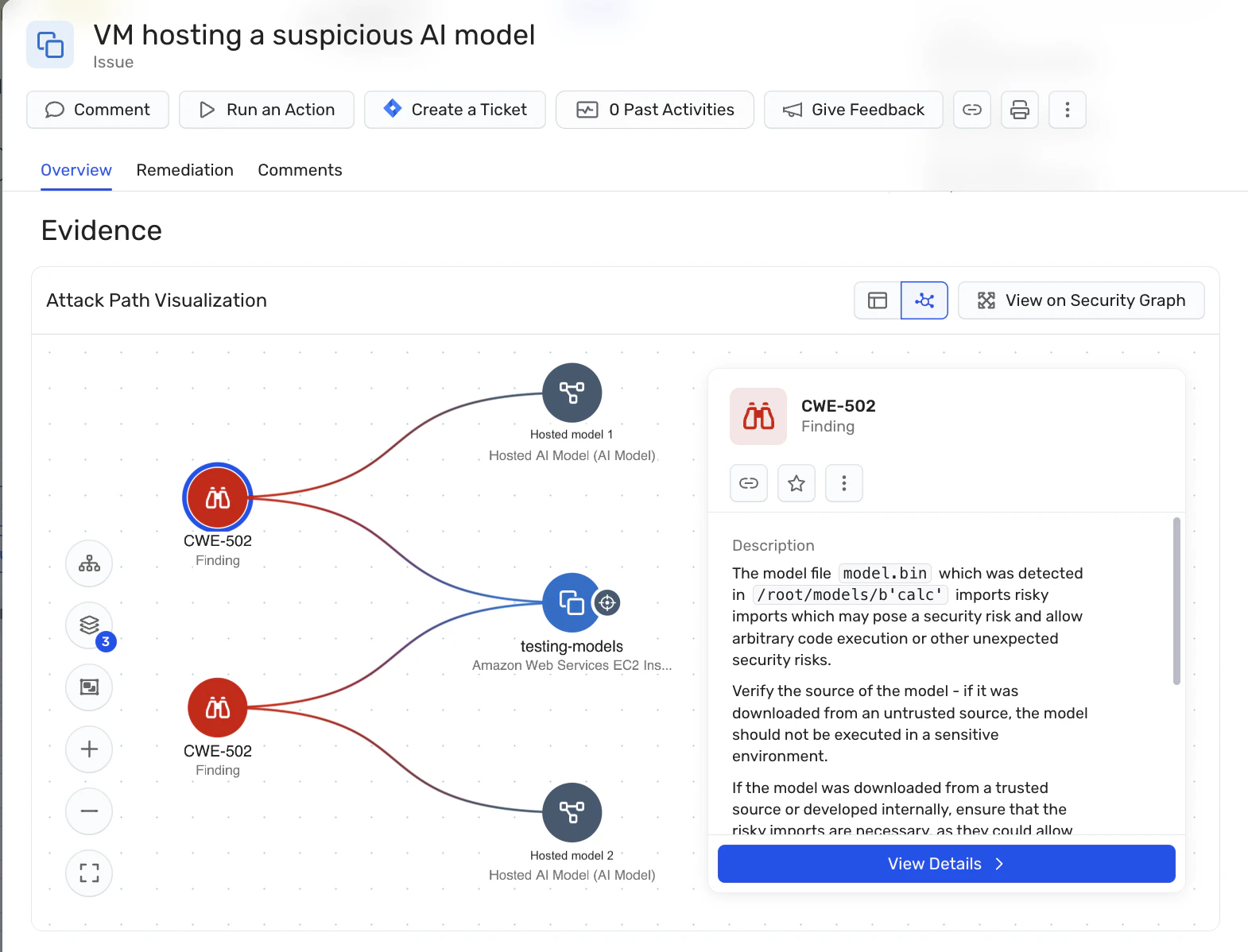
Wiz ayuda a las organizaciones a reducir el riesgo de modelos de IA maliciosos al fundamentar la seguridad de los modelos en la nube. En lugar de intentar clasificar la intención o el comportamiento del modelo, Wiz se centra en validar los controles que determinan de dónde provienen los modelos, cómo se cargan y a qué pueden acceder una vez desplegados.
A través de Gestión de la Postura de Seguridad de IA (IA-SPM) y la Grafo de Seguridad Wiz, los modelos de IA, los trabajos de formación, los servicios de inferencia y los registros se tratan como activos en la nube de primera clase. Wiz proporciona visibilidad sobre artefactos de modelos alojados y realiza inspecciones a nivel de formato para detectar métodos de serialización riesgosos o fuentes no confiables, extendiendo la disciplina de la cadena de suministro de software a modelos de IA antes de que lleguen a producción.
Al correlacionar artefactos del modelo con identidades, permisos, exposición a la red y acceso a datos sensibles, Wiz ayuda a los equipos a identificar cuándo un modelo se vuelve riesgoso o potencialmente malicioso explotable en la práctica, comprenda su verdadero radio de explosión y priorice la remediación basándose en rutas de ataque reales, sin ralentizar el desarrollo de IA ni introducir herramientas de seguridad separadas.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
