

What is adversarial AI?
Adversarial AI, a type of cyberattack, feeds subtly altered data into artificial intelligence (AI) and machine learning (ML) systems and tricks them into making incorrect decisions.
These attacks weaponize the same capabilities that make AI valuable. Threat actors craft malicious inputs designed to bypass guardrails, poison training data, or extract sensitive information from model behavior. The result is AI systems that appear to function normally while quietly serving attacker objectives.
When these systems run in the cloud, adversarial AI is rarely a model-only problem. It’s usually tied to cloud realities like who can call the endpoint, what data the model can read, and what the hosting workload can reach if it gets compromised, which is part of what makes adversarial AI dangerous.
The 4-Step Framework for AI Threat Readiness
Wiz has designed a 4-step framework to help organizations defend against rapid, automated exploitation in a post-Mythos world.

What makes adversarial AI attacks dangerous?
The rapid adoption of AI across mission-critical systems has turned adversarial AI into an urgent security priority. When AI powers fraud detection, autonomous vehicles, or customer-facing applications, a successful adversarial attack can cause real-world harm at scale.
Wiz research shows that 87% of security professionals use AI services in one way or another, and AI deployment can open up potential entry points for adversarial manipulation, as illustrated in the following image:
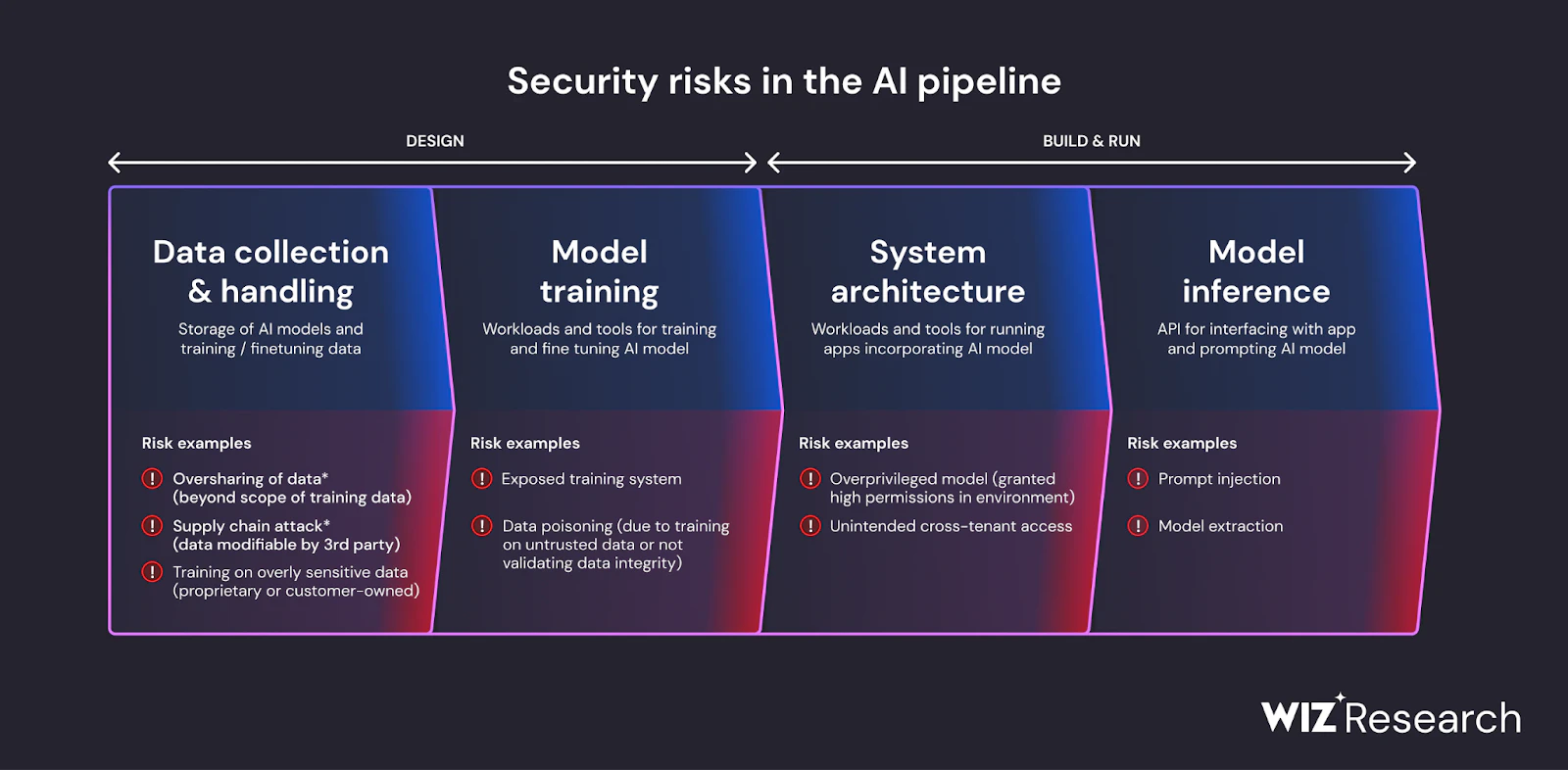
The most dangerous adversarial AI attacks are not the ones that cause obvious failures. They are the subtle manipulations that corrupt model integrity over time while evading detection. Attackers bypass guardrails without triggering alerts, allowing compromised models to reach production and operate undetected.
To help organizations understand the nuances and risks of adversarial AI, MITRE released the Adversarial Threat Landscape for Artificial Intelligence Systems (ATLAS). MITRE ATLAS is a comprehensive knowledge base of 155 techniques and 52 case studies that malicious actors use to attack AI systems, helping entities safeguard across adversarial AI types and tactics.
What are the different types of adversarial AI?
Adversarial AI attacks fall into two broad categories based on attacker knowledge:
White box attacks: The attacker has detailed knowledge of the target model's architecture, training data, and parameters. This insider-level access enables highly precise attacks but requires significant reconnaissance or insider access.
Black box attacks: The attacker has no direct visibility into model internals and must infer vulnerabilities by observing input-output behavior. These attacks are more common in practice because they require only API access to the target system.
Most real-world adversarial AI incidents are black box attacks, and the methods threat actors use to carry out these attacks depend on their objectives, the type of attack, and the victim's infrastructure.
Defenders should assume attackers can probe their models externally and design defenses accordingly, securing against specific attack types that target different parts of the AI lifecycle:
Evasion attacks: Attackers modify inputs to cause misclassification without changing the underlying content's meaning to humans. Evasion attacks can be targeted, where the attacker wants a specific wrong output, or untargeted, where any misclassification serves the attacker's goal.
Poisoning attacks: Adversaries inject inaccurate and malicious data into training datasets—sometimes by controlling a few dozen training samples—affecting the system's learning process and influencing future autonomous decisions and outputs.
Transfer attacks: Cybercriminals design adversarial AI models for a certain victim and then use that model to compromise the AI and ML systems of other potential targets.
Model extraction attacks: Threat actors steal proprietary machine learning algorithms to create their own illegal duplicates quickly and inexpensively.
Byzantine attacks: Threat actors cripple a distributed ML system by feeding various models and components with manipulative and contradictory data and inputs.
Trojan AI attacks: Malicious actors weave a trigger into the AI or ML model during the training phase. As a result, the AI model will function normally for the most part and only fully initiate the attack when triggered.
Model inversion attacks: Threat actors analyze the outputs of an AI/ML model to make assumptions about details within its training data. This typically occurs in scenarios where threat actors cannot access training datasets.
Membership inference attacks: Threat actors study AI and ML models to determine whether exploitable sensitive information about individuals or institutions exists within training data.
How do adversarial AI attacks work?
Unlike many traditional cyber threats that try to circumvent the capabilities of their target, adversarial AI attacks weaponize AI's inherent capabilities. AI systems make autonomous decisions and generate output based on training data and prompts, and that's exactly what adversarial AI attacks take advantage of.
Adversarial AI attacks typically follow a structured progression:
Reconnaissance: Attackers study the target's AI systems to identify weaknesses in model architectures, guardrails, and underlying infrastructure. Techniques range from public research to reverse engineering model behavior through API probing.
Input crafting: Armed with knowledge of the target system, attackers design malicious inputs tailored to exploit specific vulnerabilities. These inputs target systems where accuracy is critical, such as fraud detection, image recognition, or natural language processing.
Exploitation: Attackers deliver the crafted inputs to corrupt model behavior. The impact ranges from subtle output manipulation that goes unnoticed to large-scale failures that damage business operations and reputation.
Escalation: While defenders scramble to understand what went wrong, attackers leverage the confusion to move laterally, exploit additional vulnerabilities, or spread AI-generated disinformation.
Remember that adversarial AI attacks can affect the entire AI and ML model journey, from development to deployment.
Real-world examples of adversarial AI
Now that we know the different types of adversarial AI attacks, let's take a look at a few of real-world examples.
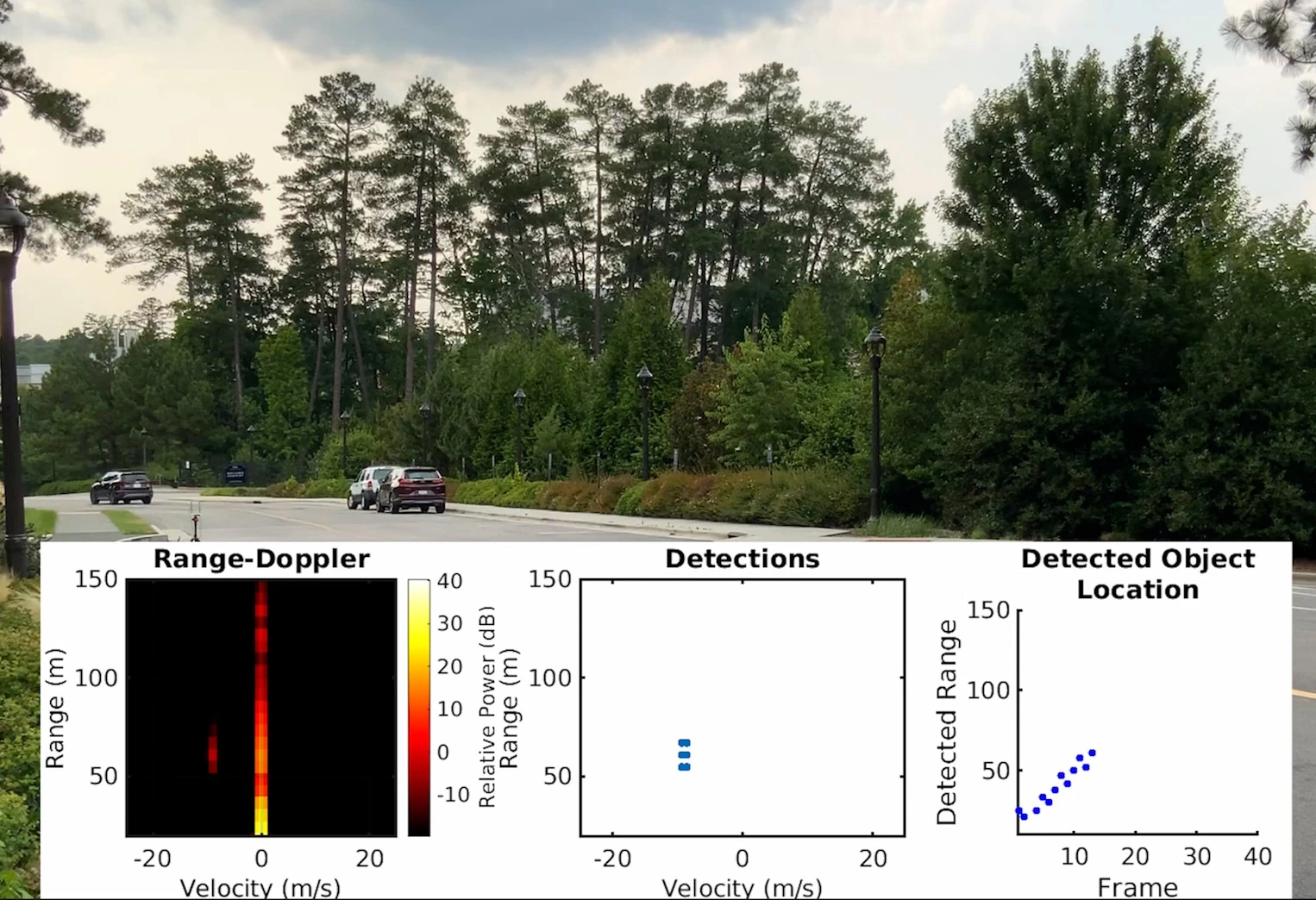
1. MadRadar
Engineers at Duke University hacked the radar systems of autonomous vehicles and made them hallucinate other cars. A potential scenario where hackers make vehicles perceive phantom cars could cause major accidents.
2. Google's Search Generative Experience
Although the exact reasons behind its malicious outputs are unclear, Google's new AI search engine sometimes misdirects users to malicious links containing malware, suggesting some form of adversarial AI. The most concerning aspect of this example is how realistic and believable the AI search engine is when presenting dangerous information.
3. Microsoft 365 Copilot’s EchoLeak
Aim Labs found a vulnerability in Microsoft 365 Copilot, dubbed EchoLeak, that got around security measures for prompt injection attacks. With this gap, attackers could access sensitive data by using a single email, exposing potential vulnerabilities in AI agents and copilots.
Inside MCP Security: A Field Guide
Explore emerging risks in AI agent protocols, from prompt injection to model context manipulation.

Best practices to mitigate adversarial AI
Defending against adversarial AI requires layered controls and methods for mitigating consequences across the model lifecycle, from training data integrity to runtime monitoring.
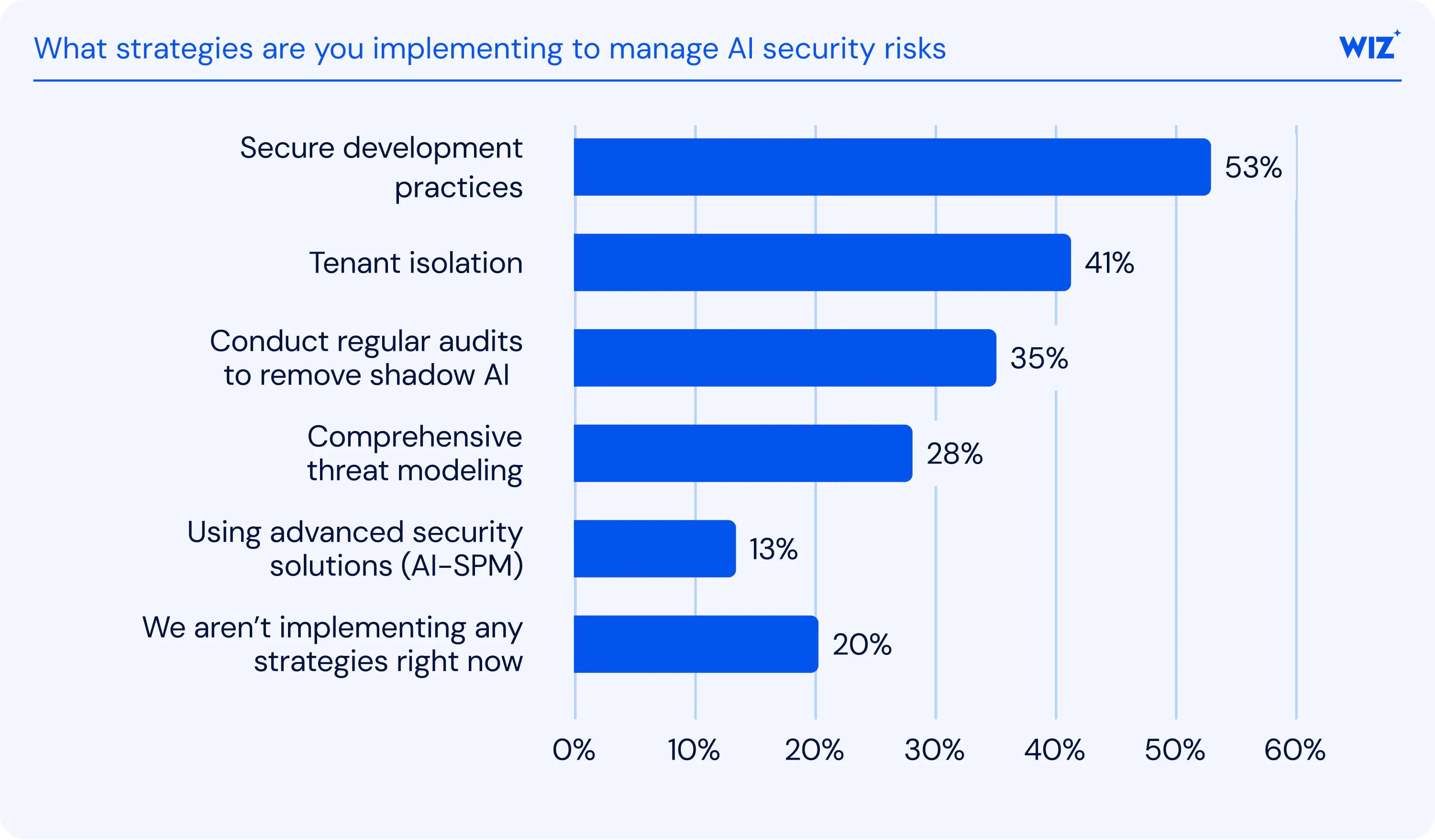
For the most secure setup, follow these best practices:
24/7 monitoring and detection
AI systems require continuous monitoring that builds on traditional infrastructure and tracks model input patterns for anomalies, monitors output distributions for drift, and correlates AI behavior with cloud activity logs.
When monitoring reveals suspicious patterns, such as unusual query volumes or outputs that deviate from baseline models, security teams need the context to investigate quickly. This means connecting AI telemetry to the underlying cloud infrastructure where models run.
Implement adversarial training
Adversarial training exposes models to potential attacks during the training process so they learn to recognize and resist manipulation. It often involves generating adversarial inputs using known techniques, adding them to training datasets, and retraining the model on this augmented data.
However, models trained this way may show slightly reduced accuracy on normal inputs, and adversarial training only protects against attack types the model’s exposed to, meaning training data must be updated continuously.
Strengthen AI and ML development environments
By reinforcing critical components of AI/ML development environments, businesses can strengthen their overall AI security posture. Some essential security practices include sanitizing training data, developing or leveraging more robust ML algorithms (like Byzantine-resistant algorithms), using AI to write or validate ML algorithms and reduce human error, and integrating security into AI pipelines as early as possible.
Optimize the architectures of AI/GenAI services
Enterprises should be very deliberate with what tenant architecture model they use for GenAI-incorporating services. The three fundamental types of GenAI tenant architectures are multi-tenant, single-tenant, and hybrid architectures.
Businesses should spread some components of their GenAI services across multiple tenants and provide others with dedicated tenants. This is a critical means of reducing large-scale damage and facilitating swift incident responses.
Input preprocessing
Apply preprocessing techniques to inputs before feeding them into the model to help detect and mitigate adversarial perturbations. Feature squeezing reduces the precision of input features to remove adversarial noise, and input transformation applies random resizing, padding, or other transformations to disrupt carefully crafted adversarial inputs. Plus, anomaly detection uses statistical methods to identify inputs that deviate significantly from expected patterns.
Implement AI security posture management (AI-SPM)
To secure your business from adversarial AI attacks, choose a unified cloud security tool that has AI-SPM as a central capability.
Wiz's AI Security Readiness report found that only 13% of organizations have adopted AI-SPM solutions, despite 87% actively using AI services. But with a robust AI-SPM tool, adversarial AI attacks will have little to no effect on AI adoption and implementation within your business.
How Wiz helps address the threat of adversarial AI
Adversarial AI risks don’t exist in isolation. They emerge from a combination of model vulnerabilities, cloud misconfigurations, and overpermissioned identities. You can defend against these attacks with visibility that connects AI assets to the infrastructure powering them.
Wiz AI Security Posture Management (AI-SPM) provides this unified view, helping teams detect and mitigate adversarial AI risks before they reach production.
Comprehensive visibility
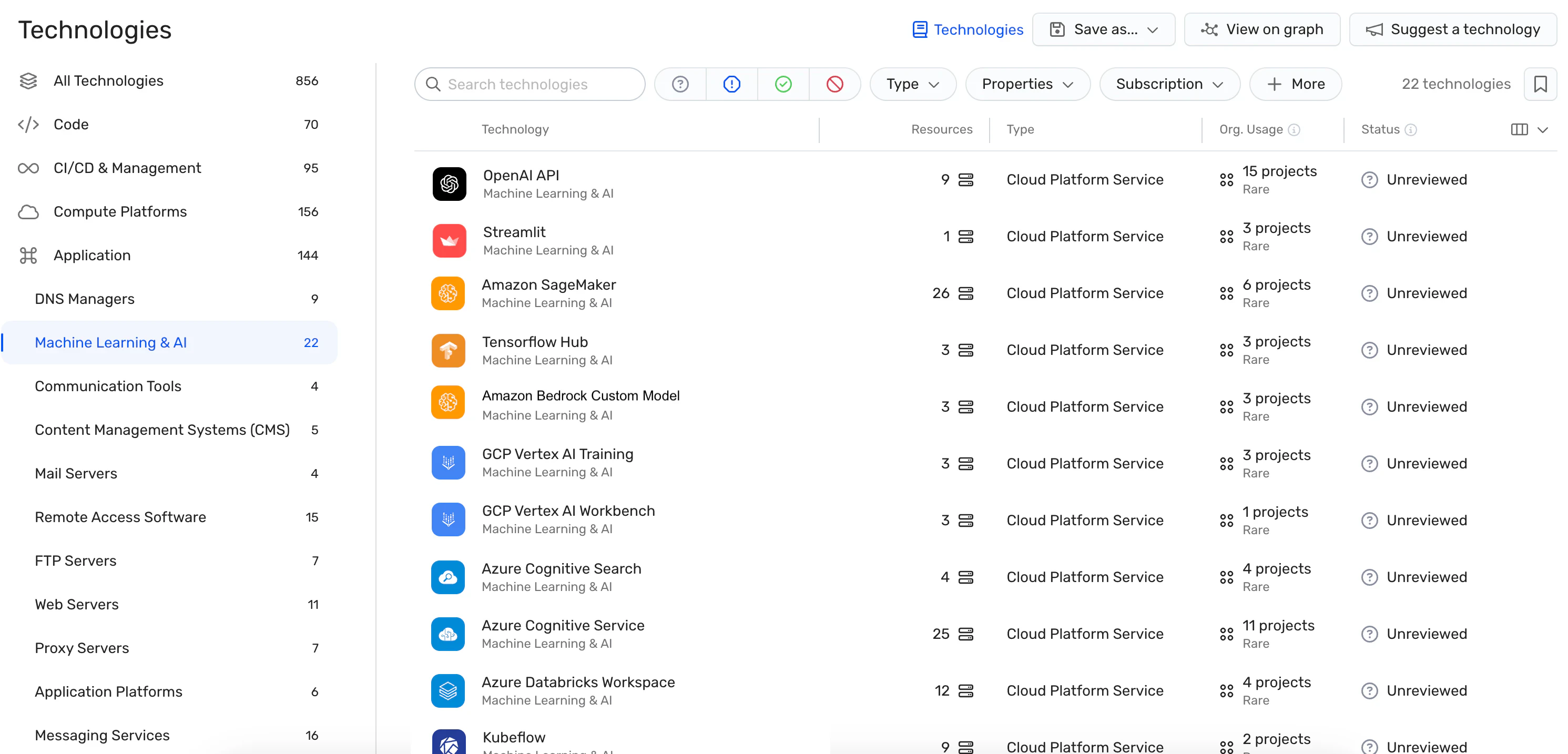
Wiz AI-SPM provides full-stack visibility into AI pipelines and resources through its agentless AI-BOM (Bill of Materials) capabilities. This allows you to see all AI services, technologies, and SDKs used across your environment, detect shadow AI projects that may have been introduced without proper oversight, and gain a holistic view of the AI attack surface.
Misconfiguration detection
Wiz enforces AI security best practices by detecting misconfigurations in AI services like OpenAI and Amazon Bedrock, using built-in rules and extending security checks to the development pipeline through Infrastructure-as-Code (IaC) scanning.
Attack path analysis
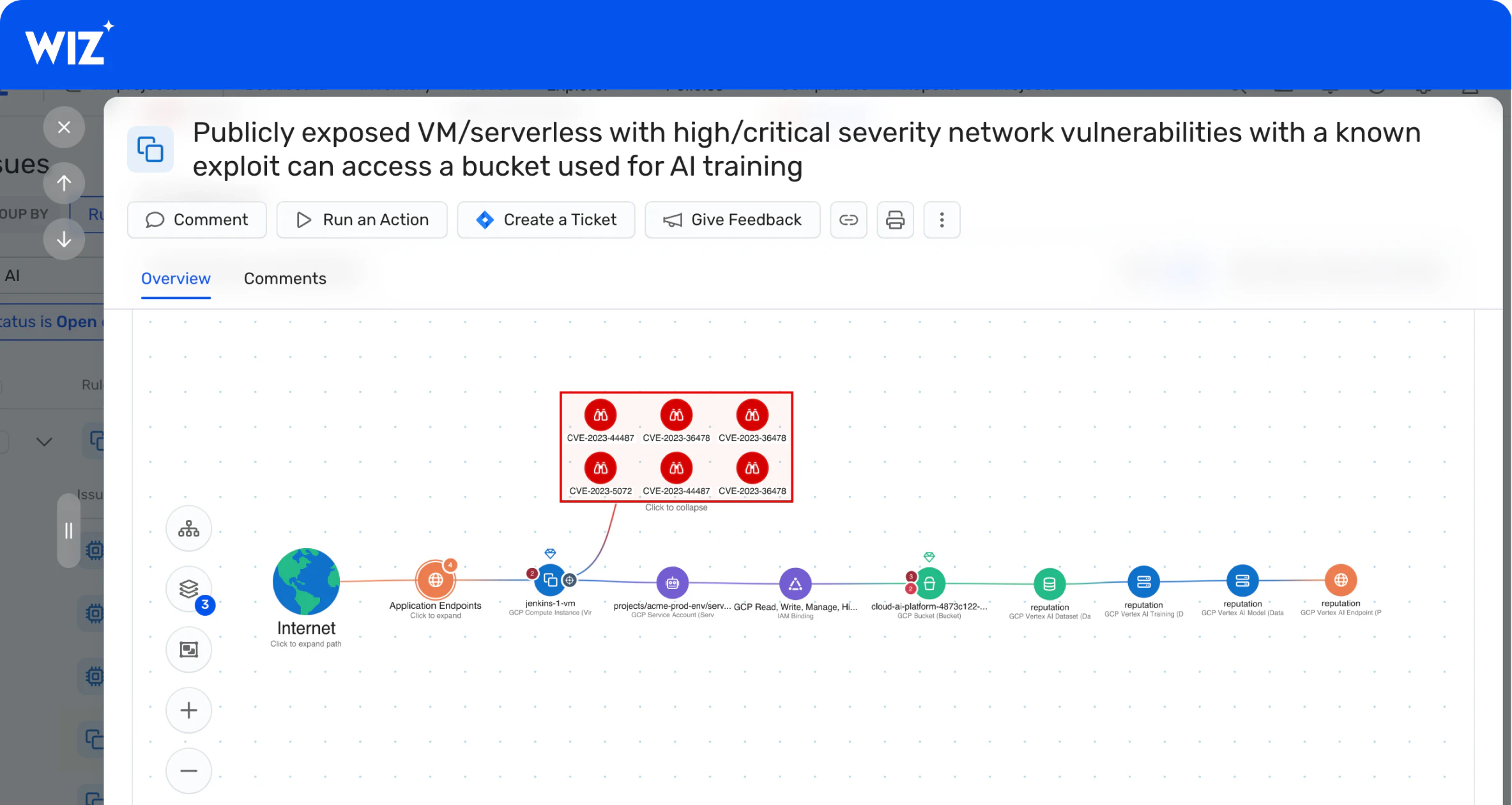
Wiz AI-SPM extends attack path analysis capabilities to AI resources, allowing organizations to detect potential attack paths to AI models and services; assess risks across vulnerabilities, identities, network exposures, data access, and more; and proactively remove critical AI attack paths before they can be exploited.
Data security for AI
To protect against data poisoning and other adversarial attacks on training data, Wiz offers automatic detection of sensitive AI training data, out-of-the-box Data Security Posture Management (DSPM) controls for AI, and remediation guidance for data leakage risks.
Explore how Wiz maps adversarial AI attack paths across your cloud environment – Get a demo to see AI-SPM in action.
See how AI-APP connects the full stack
Experience Wiz's unified security graph mapping code, cloud, and runtime for your AI workloads.
