Qu’est-ce que le LLM Jacking ?
Le LLM jacking est une technique d’attaque que les cybercriminels utilisent pour manipuler et exploiter les LLM (grands modèles de langage) basés sur le cloud d’une entreprise. Le LLM jacking consiste à voler et à vendre les informations d’identification d’un compte cloud pour permettre un accès malveillant aux LLM d’une entreprise, tandis que la victime couvre sans le savoir les coûts de consommation.
Notre recherche montre que 7 entreprises sur 10 exploitent les services d’intelligence artificielle (IA), y compris les offres d’IA générative (GenAI) de fournisseurs de cloud, notamment Amazon Bedrock et SageMaker, Google Vertex AI et Azure OpenAI Service. Ces services permettent aux développeurs d’accéder à des modèles LLM tels que Claude, Jurassic-2, la série GPT, DALL-E, OpenAI Codex, Amazon Titan et Stable Diffusion. En vendant l’accès aux modèles LLM, les cybercriminels peuvent déclencher un effet domino néfaste sur plusieurs piliers de l’organisation.
Bien que les acteurs malveillants puissent mener des attaques de détournement de LLM pour voler eux-mêmes des données, ils vendent souvent l’accès LLM à un plus grand nombre de cybercriminels. C’est d’autant plus dangereux que cela étend la portée et l’ampleur des attaques potentielles. En détournant les LLM d’une entreprise, tout cybercriminel qui achète des informations d’identification LLM basées sur le cloud peut orchestrer des attaques uniques.
LLM Security Best Practices [Cheat Sheet]
This 7-page checklist offers practical, implementation-ready steps to guide you in securing LLMs across their lifecycle, mapped to real-world threats.

Quelles sont les conséquences potentielles d’une attaque de LLM jacking ?
Augmentation des coûts de consommation
Lorsque les cybercriminels mènent des attaques de LLM jacking, les coûts de consommation excessifs sont la première répercussion. En effet, les services GenAI et LLM basés sur le cloud, aussi bénéfiques soient-ils, peuvent être assez coûteux à héberger pour les entreprises. Par conséquent, lorsque des adversaires vendent l’accès à ces services et permettent une utilisation secrète et malveillante, les coûts peuvent s’accumuler. D’après Chercheurs, les attaques de jacking LLM peuvent entraîner des coûts de consommation allant jusqu’à 46 000 USD par jour. Ce montant peut fluctuer en fonction des modèles de tarification LLM.
Militarisation des LLM d’entreprise
Si les modèles LLM d’une entreprise manquent d’intégrité ou ne disposent pas de garde-fous robustes, ils peuvent générer des résultats dommageables. En détournant des modèles LLM spécifiques à l’organisation ou en faisant de la rétro-ingénierie d’architectures LLM, les adversaires peuvent utiliser l’écosystème GenAI d’une entreprise comme une arme pour des attaques et des activités malveillantes. Par exemple, en manipulant les LLM d’entreprise, les acteurs malveillants peuvent les amener à générer des sorties fausses ou malveillantes pour les cas d’utilisation backend et clients. Les entreprises peuvent mettre un certain temps à identifier ce type de détournement, et le mal est souvent fait.
Exacerbation des vulnérabilités LLM existantes
L’adoption de LLM présente des défis de sécurité inhérents. D’après L’OWASP, les 10 principales vulnérabilités LLM comprennent l’injection rapide, l’empoisonnement des données de formation, le déni de service de modèle, la divulgation d’informations sensibles, l’agence excessive, la dépendance excessive et le vol de modèle. Lorsque les cybercriminels utilisent des attaques de jacking LLM, ils exacerbent considérablement les risques et les vulnérabilités inhérents aux LLM.
Effet de chute de neige de haut niveau
Compte tenu de la rapidité avec laquelle les entreprises intègrent GenAI et LLM dans des contextes critiques, les attaques de LLM jacking peuvent avoir de graves implications à long terme. Par exemple, le LLM jacking peut étendre la surface d’attaque d’une entreprise, entraînant des violations de données et d’autres exploits majeurs.
De plus, étant donné que la maîtrise de l’IA est une mesure de réputation essentielle pour les entreprises d’aujourd’hui, les attaques de LLM jacking peuvent entraîner une perte de confiance et de respect de la part des pairs et du public. N’oubliez pas les retombées financières dévastatrices du LLM jacking, notamment la baisse des marges bénéficiaires, la perte de données, les coûts des temps d’arrêt et les frais juridiques.
Comment fonctionnent les attaques de jacking LLM ?
En principe, le LLM jacking est similaire à des attaques telles que Cryptojacking, où des acteurs malveillants extraient secrètement des cryptomonnaies en utilisant la puissance de traitement d’une entreprise. Dans les deux cas, les auteurs de menace utilisent les ressources et l’infrastructure d’une organisation contre eux. Cependant, avec les attaques de jacking LLM, le pirate est fermement dans la ligne de mire des services LLM hébergés dans le cloud et des propriétaires de comptes cloud.
Pour comprendre comment fonctionne le LLM jacking, regardons-le sous deux angles. Tout d’abord, nous explorerons comment les entreprises utilisent les LLM, puis nous passerons à la façon dont les acteurs malveillants les exploitent.
Comment les entreprises interagissent-elles avec les services LLM hébergés dans le cloud ?
La plupart des fournisseurs de cloud fournissent aux entreprises une interface facile à utiliser et des fonctions simples conçues pour l’adoption agile de LLM. Cependant, ces modèles tiers ne sont pas automatiquement prêts à l’emploi. Tout d’abord, ils nécessitent une activation.
Pour activer les LLM, les développeurs doivent faire une demande à leurs fournisseurs de cloud. Les développeurs peuvent faire des requêtes de différentes manières, notamment via de simples formulaires de demande. Une fois que les développeurs ont soumis ces formulaires de demande, les fournisseurs de cloud peuvent rapidement activer les services LLM. Après l’activation, les développeurs peuvent interagir avec leurs LLM basés sur le cloud à l’aide de commandes d’interface de ligne de commande (CLI).
Gardez à l’esprit que le processus d’envoi d’un formulaire de demande d’activation à un fournisseur de cloud n’est pas protégé par une couche de sécurité à toute épreuve. Les acteurs de la menace peuvent facilement faire de même, de sorte que les entreprises doivent se concentrer sur d’autres types de sécurité de l’IA et de la LLM.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Comment les acteurs malveillants mènent-ils des attaques de LLM jacking ?
Maintenant que vous comprenez comment les entreprises interagissent généralement avec les services LLM hébergés dans le cloud, voyons comment les acteurs malveillants facilitent les attaques de LLM jacking.
Voici les étapes suivies par les acteurs de la menace pour orchestrer une attaque de LLM jacking :
Pour vendre des identifiants cloud, les acteurs malveillants doivent d’abord les voler. Lorsque les chercheurs ont découvert pour la première fois des techniques d’attaque par détournement de LLM, ils ont retracé les informations d’identification volées jusqu’à un système à l’aide d’une version vulnérable de Laravel (CVE-2021-3129).
Une fois qu’un auteur de menace vole les identifiants d’un système vulnérable, il peut les vendre sur des marchés illicites à d’autres cybercriminels qui peuvent les acheter et les exploiter pour des attaques plus avancées.
Une fois les informations d’identification cloud volées en main, les acteurs malveillants doivent évaluer leurs privilèges d’accès et d’administration. Pour évaluer furtivement les limites de leurs privilèges d’accès au cloud, les cyberattaquants peuvent exploiter le
InvokeModel APIappeler.Même si le
InvokeModel APIest une requête valide, les acteurs de la menace peuvent provoquer une erreur « ValidationException » en définissant la fonctionmax_tokens_to_sampleà -1. Cette étape consiste simplement à déterminer si les informations d’identification volées peuvent accéder aux services LLM. À l’inverse, si une erreur « AccessDenied » apparaît, les acteurs de la menace savent alors que les informations d’identification volées ne sont pas'T avoir des privilèges d’accès exploitables.
Les adversaires peuvent également invoquer GetModelInvocationLoggingConfiguration pour déterminer les paramètres de configuration des services d’IA hébergés dans le cloud d’une entreprise. N’oubliez pas que cette étape dépend des garde-fous et des capacités de chaque fournisseur et service cloud. C’est pourquoi, dans certains cas, les acteurs malveillants peuvent ne pas avoir une visibilité complète sur les entrées et les sorties LLM d’une entreprise.
La réalisation d’une attaque de LLM jacking ne garantit pas la monétisation pour les acteurs de la menace. Cependant, il existe plusieurs façons pour les acteurs de la menace de s’assurer que le LLM jacking est rentable. Au cours de l’autopsie d’une attaque de détournement LLM, les chercheurs ont découvert que les adversaires peuvent potentiellement utiliser le serveur open source OAI Reverse Proxy comme panneau centralisé pour gérer les informations d’identification cloud volées avec des privilèges d’accès LLM.
Une fois que les acteurs de la menace monétisent leurs attaques de LLM jacking et vendent l’accès aux modèles LLM d’une entreprise, il n’y a aucun moyen de prédire le type de dommages qui peuvent en découler. D’autres adversaires d’horizons différents et avec des motivations diverses peuvent acheter l’accès LLM et utiliser l’infrastructure GenAI d’une entreprise à leur insu. Si les conséquences des attaques de LLM jacking peuvent initialement rester cachées, les retombées peuvent être catastrophiques.


Tactiques de prévention et de détection du LLM Jacking
Voici quelques moyens puissants pour les entreprises de se protéger contre les attaques de LLM jacking :
Tactiques de prévention
Formation de modèle robuste :
Ensembles de données diversifiés et de haute qualité : assurez-vous que le modèle est entraîné sur un large éventail de données afin d’éviter les biais et les vulnérabilités.
Formation contradictoire : exposez le modèle à des entrées malveillantes pour améliorer sa résilience.
Apprentissage par renforcement à partir de la rétroaction humaine (RLHF) : Aligner le modèle'avec des valeurs et des attentes humaines.
Validation stricte des entrées :
Filtrage : mettez en place des filtres pour bloquer les invites nuisibles ou malveillantes.
Assainissement : Nettoyez les entrées pour éliminer les éléments potentiellement nocifs.
Limitation du débit : limitez le nombre de demandes pour éviter les abus.
Audit régulier des modèles :
Évaluations des vulnérabilités : identifiez les faiblesses potentielles du modèle.
Détection des biais : Surveiller les biais involontaires dans le modèle'.
Surveillance des performances : suivez les performances du modèle au fil du temps pour détecter les anomalies.
Documentation transparente du modèle :
Directives claires : Fournissez des instructions claires sur la façon d’utiliser le modèle de manière responsable.
Limites : Communiquer le modèle'limites et les biais potentiels.
Apprentissage continu et adaptation :
Restez informé : tenez-vous au courant des dernières menaces et contre-mesures LLM.
Mises à jour du modèle : mettez régulièrement à jour le modèle pour corriger les nouvelles vulnérabilités.
Tactiques de détection
Détection d’anomalies :
Identification des valeurs aberrantes : identifiez les comportements inhabituels ou inattendus du modèle.
Analyse statistique : Utilisez des méthodes statistiques pour détecter les écarts par rapport aux modèles normaux.
Surveillance du contenu :
Filtrage des mots-clés : surveillez les sorties pour des mots-clés ou des expressions spécifiques associés à du contenu préjudiciable.
Analyse des sentiments : analysez le sentiment du contenu généré pour identifier les problèmes potentiels.
Analyse de style : Détecter les anomalies dans le style d’écriture du contenu généré.
Analyse du comportement de l’utilisateur :
Modèles inhabituels : identifiez les comportements anormaux de l’utilisateur, tels que les demandes rapides ou les invites répétitives.
Surveillance des comptes : surveillez les comptes d’utilisateurs pour détecter toute activité suspecte.
Vérification humaine dans la boucle :
Assurance qualité : Faites appel à des examinateurs humains pour évaluer la qualité et la sécurité du contenu généré.
Mécanismes de rétroaction : recueillez les commentaires des utilisateurs pour identifier les problèmes potentiels.
Get an AI-SPM Sample Assessment
In this Sample Assessment Report, you’ll get a peek behind the curtain to see what an AI Security Assessment should look like.

Comment Wiz peut prévenir les attaques de LLM jacking
La solution révolutionnaire d’outil AI-SPM de Wiz peut aider à prévenir et à atténuer les attaques de détournement LLM pour qu’elles ne se transforment en catastrophes à grande échelle. Wiz AI-SPM peut aider à se défendre contre le jacking LLM de plusieurs manières :
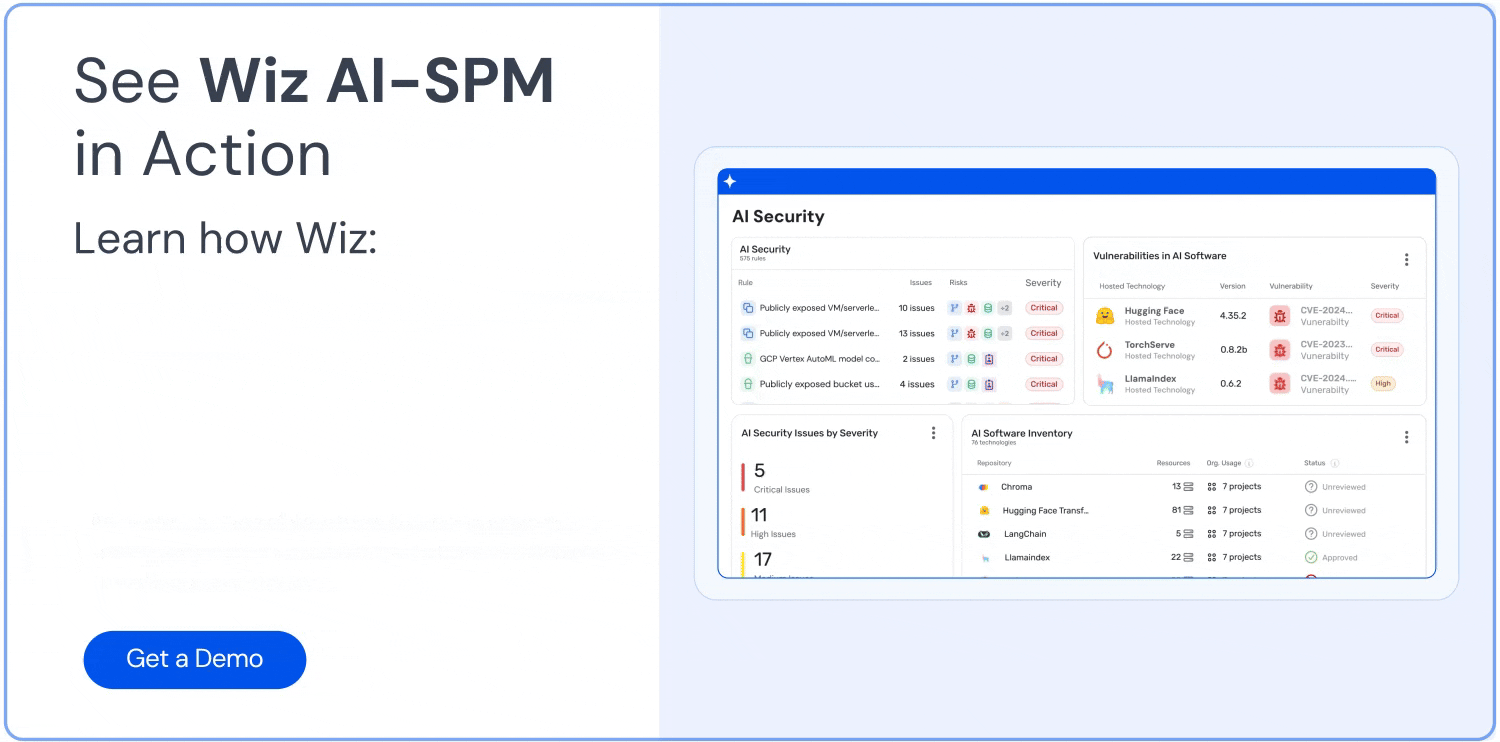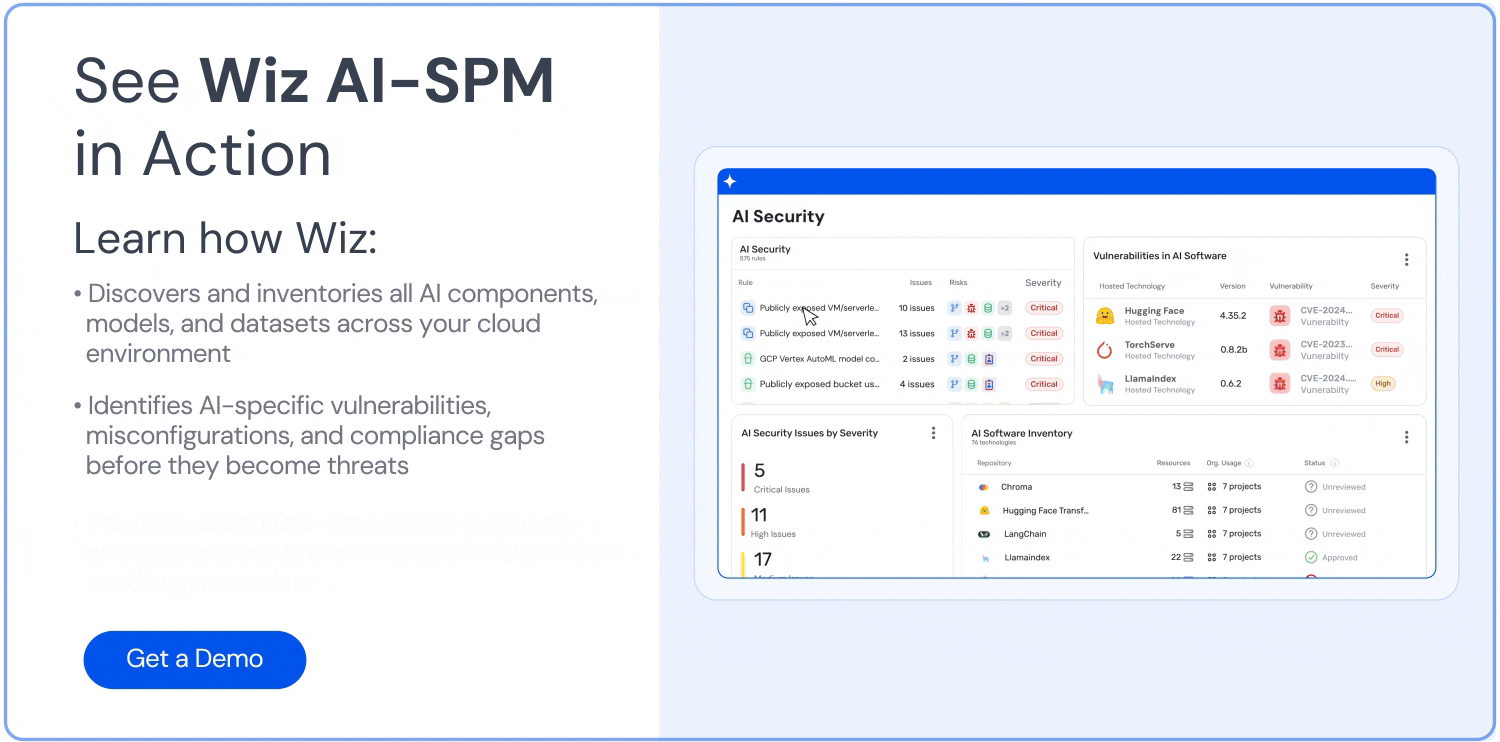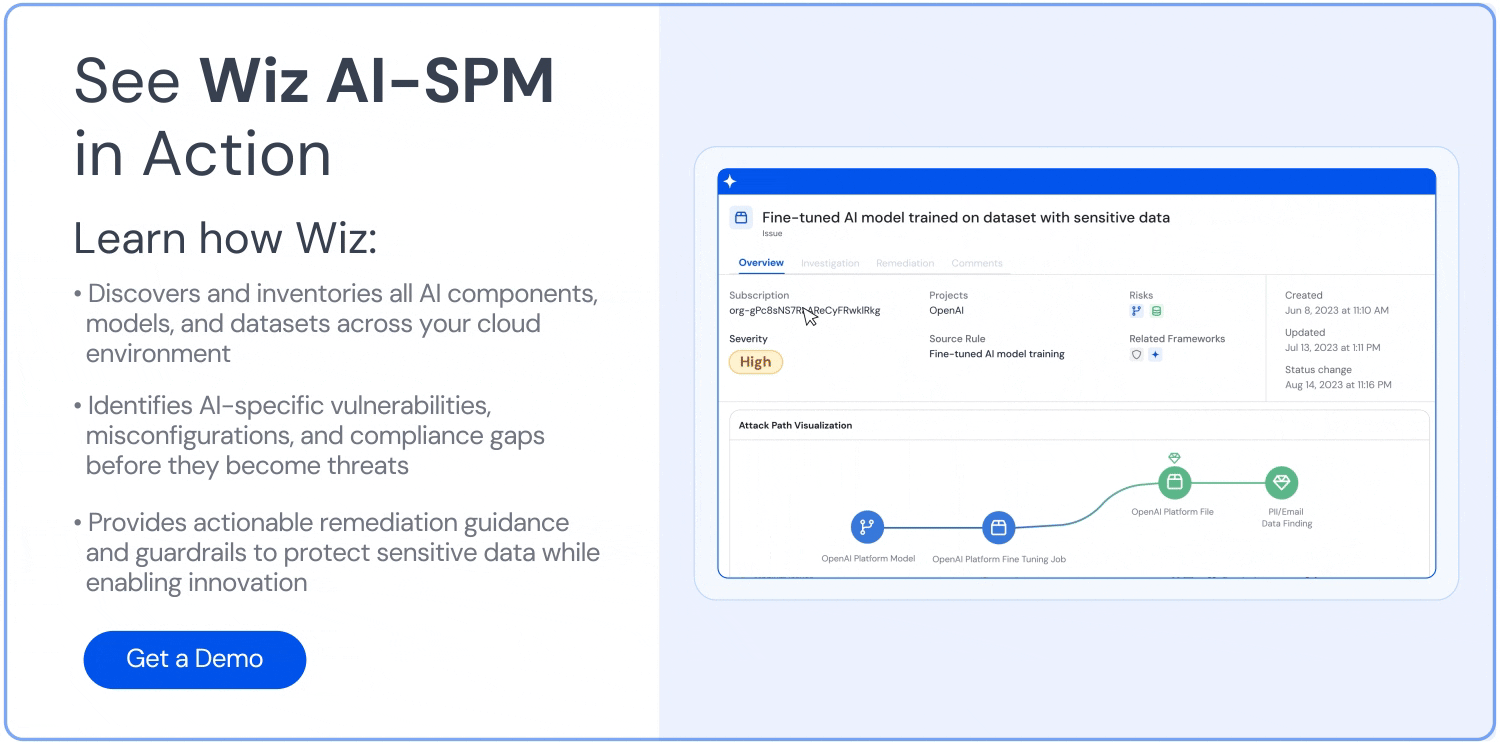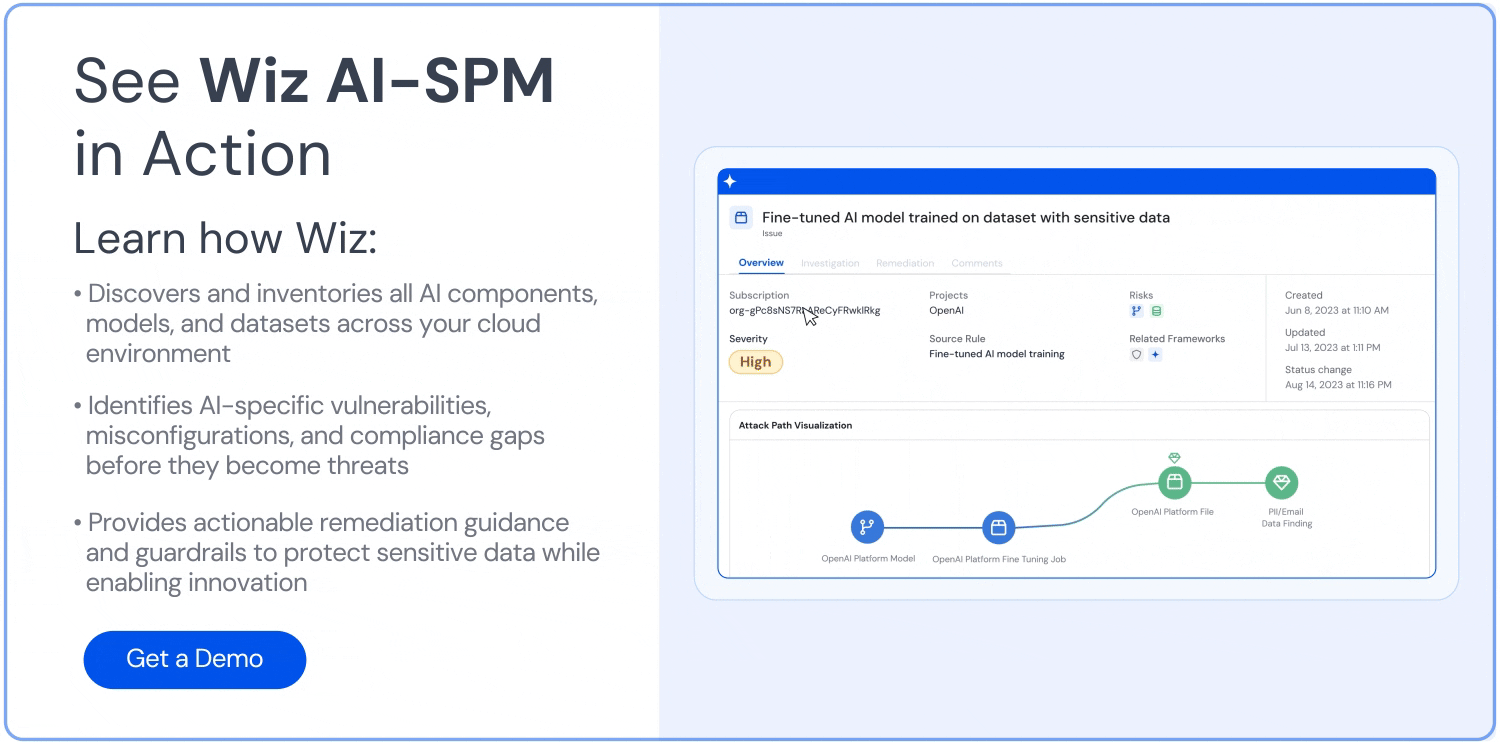
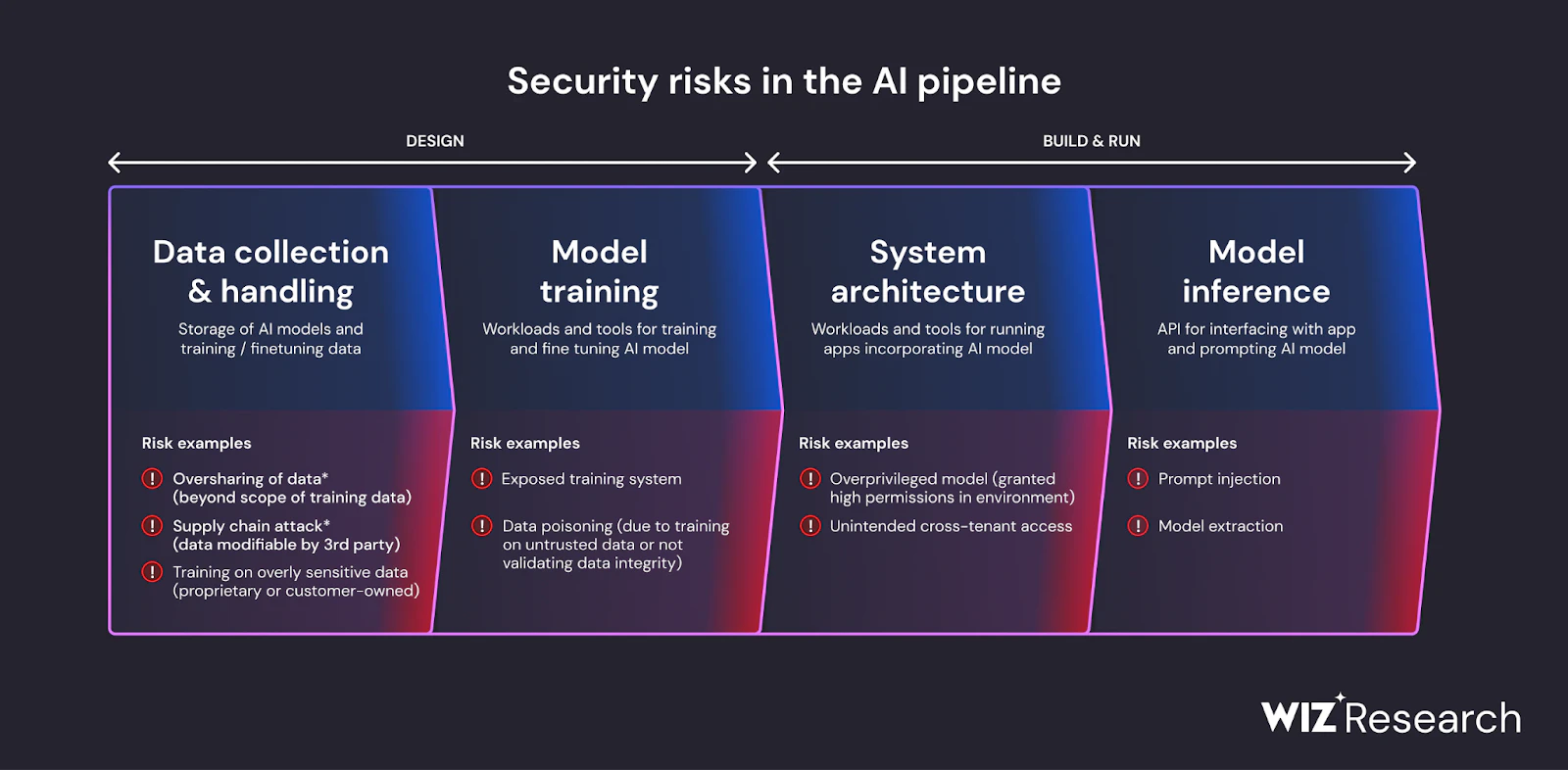
Visibilité complète : Wiz AI-SPM offre une visibilité complète sur les pipelines d’IA, y compris les services d’IA, les technologies et les SDK, sans nécessiter d’agents. Cette visibilité aide les organisations à détecter et à surveiller tous les composants d’IA de leur environnement, y compris les LLM, ce qui rend plus difficile pour les attaquants d’exploiter des applications inconnues ou IA de l’ombre ressources.
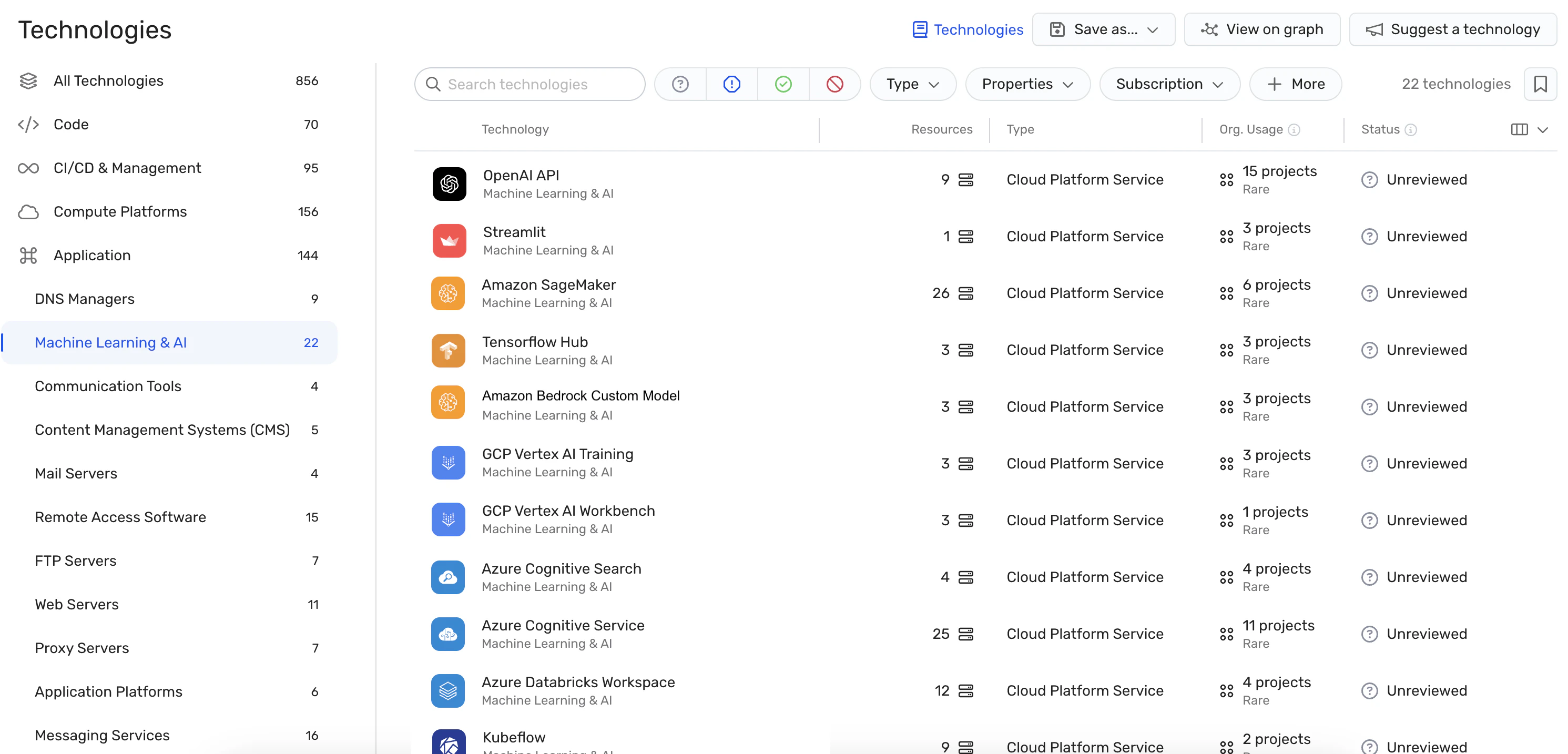
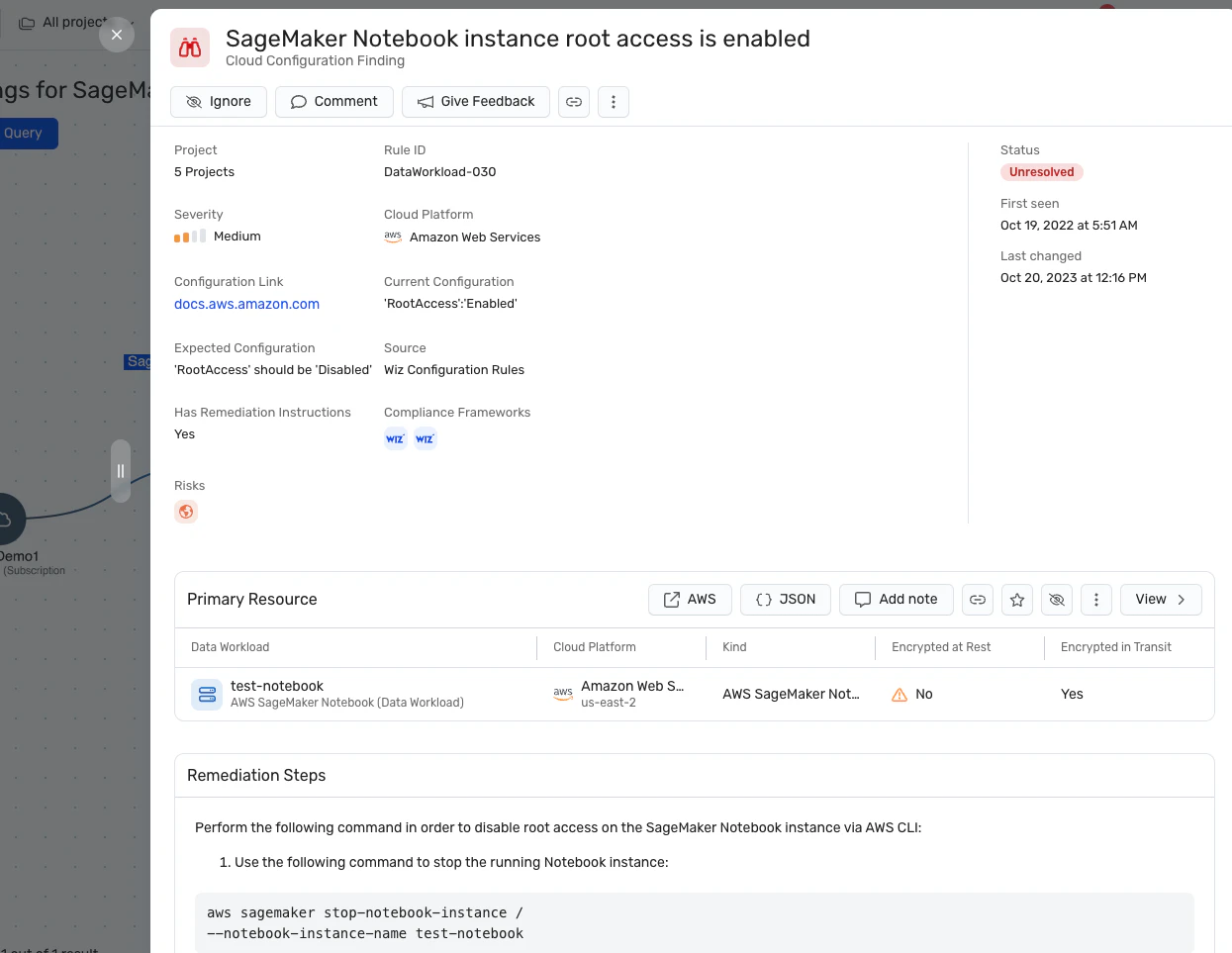
Détection des erreurs de configuration : La plateforme fait respecter Bonnes pratiques en matière de sécurité de l’IA en détectant les erreurs de configuration dans les services d’IA avec des règles intégrées. Cela peut aider à prévenir les vulnérabilités qui pourraient être exploitées dans les attaques de jacking LLM.
Analyse du chemin d’attaque : Wiz AI-SPM identifie et supprime de manière proactive les chemins d’attaque vers les modèles d’IA en évaluant les vulnérabilités, les identités, les expositions à Internet, les données, les erreurs de configuration et les secrets. Cette analyse complète peut aider à prévenir les points d’entrée potentiels pour les tentatives de jacking LLM.
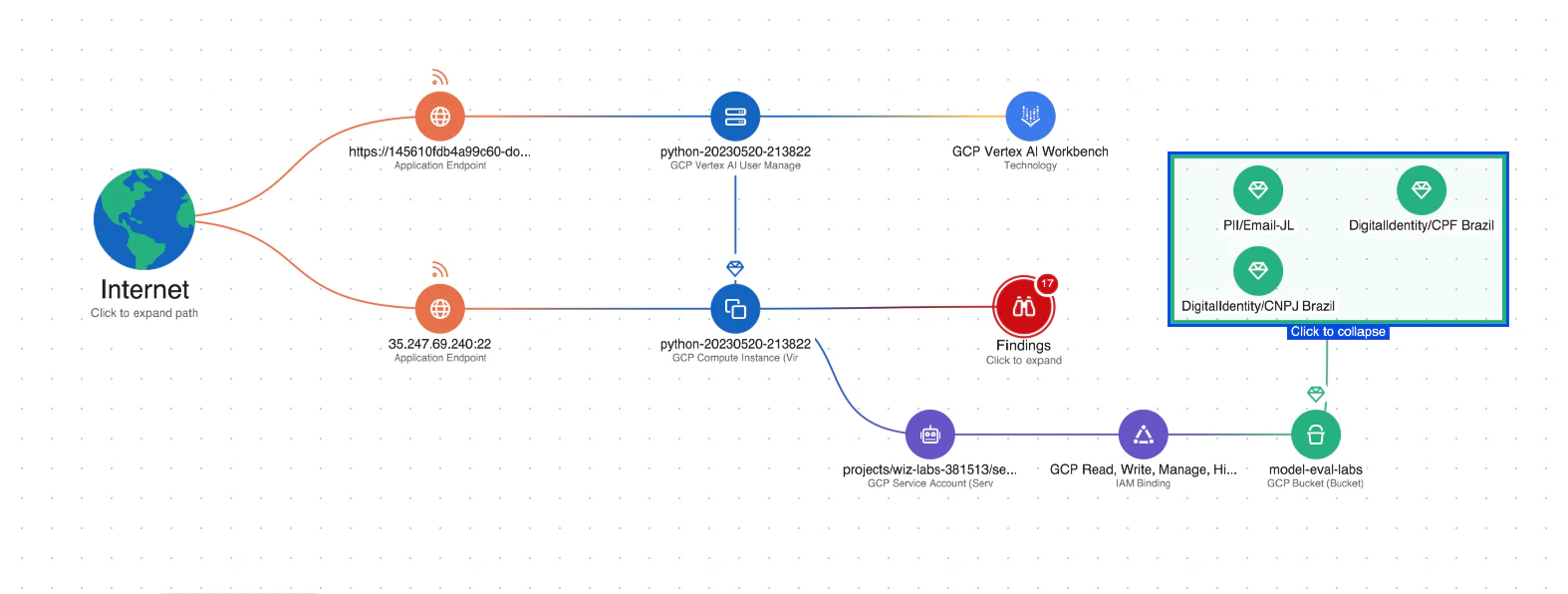
Sécurité des données pour l’IA : La plateforme comprend la gestion de la posture de sécurité des données (DSPM) spécifiquement pour l’IA, qui peut détecter automatiquement les données d’entraînement sensibles et supprimer les chemins d’attaque vers celles-ci. Cela aide à protéger contre Fuite de données qui pourraient être utilisés dans des attaques de jacking LLM.
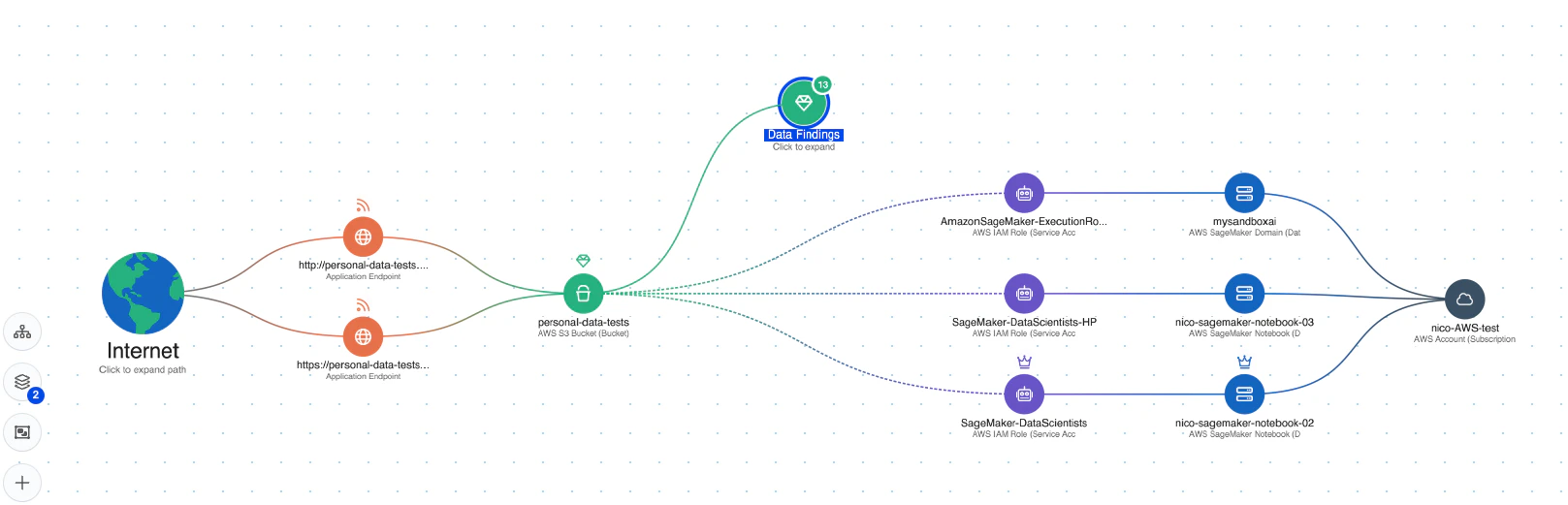
Détection des menaces en temps réel : Wiz AI-SPM offre une protection d’exécution contre les comportements suspects provenant de modèles d’IA. Cette capacité peut aider à détecter et à répondre aux tentatives de jacking LLM en temps réel, minimisant ainsi l’impact potentiel.
Numérisation du modèle : La plateforme prend en charge l’identification et l’analyse des modèles d’IA hébergés, ce qui permet aux organisations de détecter les modèles malveillants susceptibles d’être utilisés dans des attaques de jacking LLM. Ceci est particulièrement important pour les organisations qui hébergent elles-mêmes des modèles d’IA, car cela permet de gérer les risques de la chaîne d’approvisionnement associés aux modèles open source.
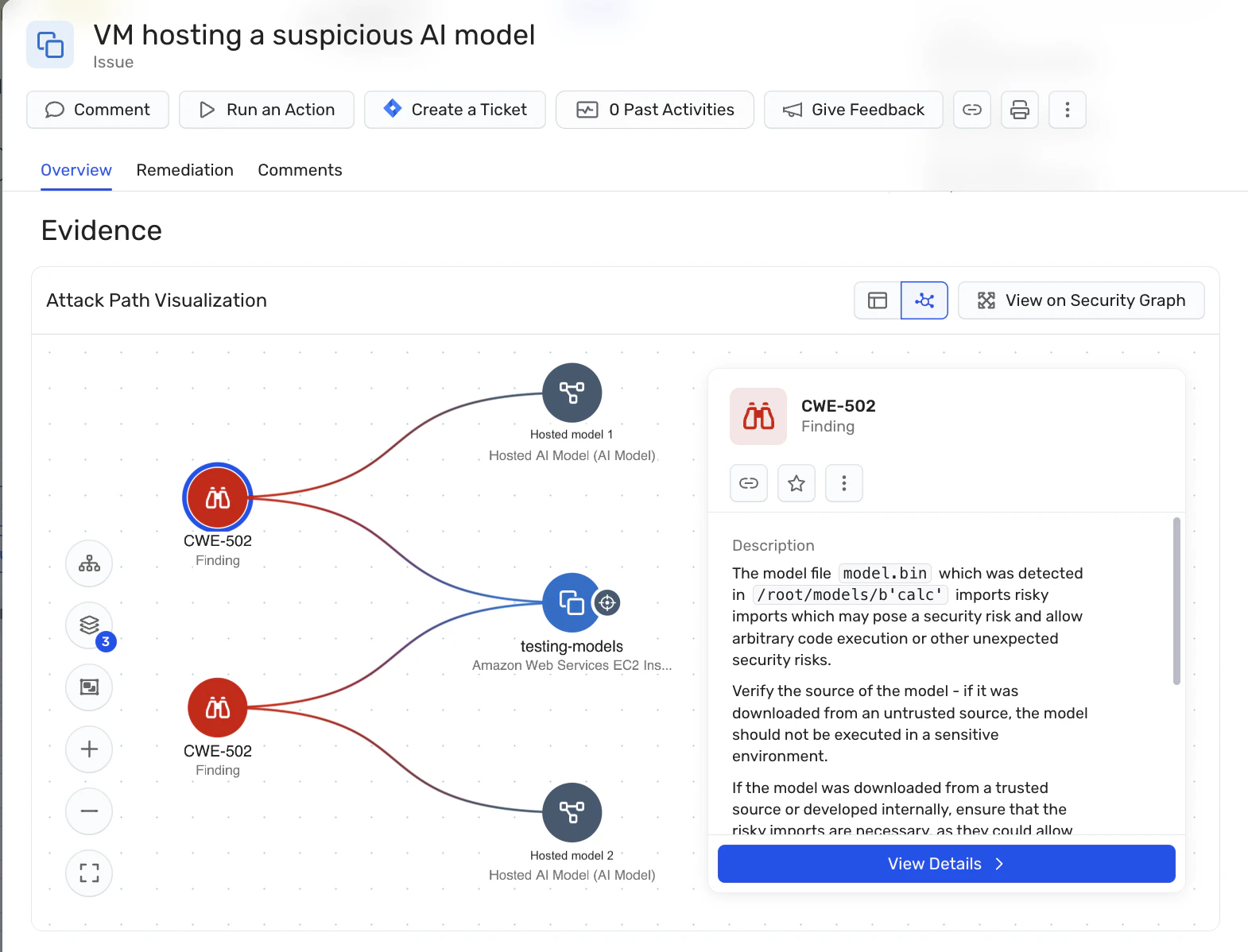
Tableau de bord de sécurité AI : Wiz AI-SPM fournit un tableau de bord de sécurité de l’IA qui offre une vue d’ensemble de la posture de sécurité de l’IA avec une file d’attente de risques hiérarchisée. Cela permet aux développeurs d’IA et aux équipes de sécurité de se concentrer rapidement sur les problèmes les plus critiques, y compris les vulnérabilités susceptibles d’entraîner le piratage LLM.
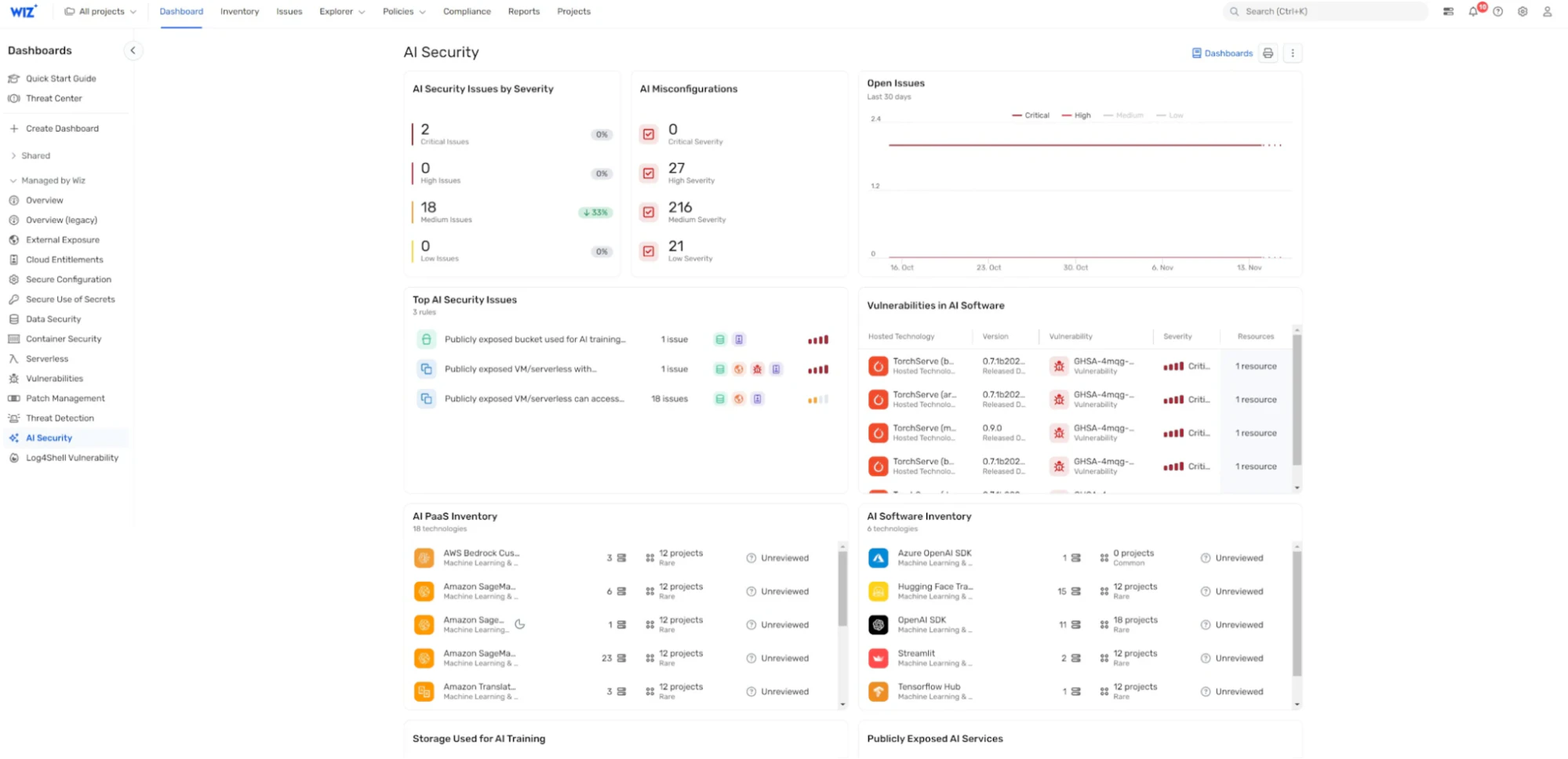
En mettant en œuvre ces fonctionnalités, Wiz AI-SPM aide les organisations à maintenir une posture de sécurité solide pour leurs systèmes d’IA, ce qui rend plus difficile pour les attaquants d’exécuter avec succès des attaques de LLM jacking et d’autres menaces liées à l’IA.