



La réponse aux incidents cloud est une approche stratégique conçue pour détecter, contenir et remédier aux cyberattaques visant des systèmes basés sur le cloud. Elle repose sur une série coordonnée de procédures permettant d'identifier les menaces, d'éradiquer les acteurs malveillants et de rétablir les services de manière organisée, efficace et dans des délais maîtrisés.
Si elle poursuit les mêmes objectifs que la réponse aux incidents dans un environnement IT traditionnel, la manière d'atteindre ces objectifs diffère sensiblement en raison des spécificités d'infrastructure et des modes d'attaque propres aux applications cloud.
Ainsi, votre stratégie de réponse aux incidents doit s'adapter à une surface d'attaque et à des types d'attaques différents. En outre, si vous utilisez plusieurs fournisseurs de services cloud (CSP), chacun avec ses concepts de service et ses outils natifs, vous aurez souvent besoin d'ensembles de mesures propres à chaque plateforme.
Aujourd'hui, à mesure que l'adoption du cloud public progresse, la réponse aux incidents cloud devient de plus en plus essentielle et s'impose rapidement comme la norme pour gérer efficacement les attaques.
Un modèle de plan de réponse aux incidents opérationnel
Un guide de démarrage rapide pour créer un plan de réponse aux incidents robuste, conçu spécifiquement pour les entreprises disposant de déploiements cloud.

Réponse aux incidents cloud vs. traditionnelle : comparaison rapide
La réponse aux incidents (IR) est un pilier de toute stratégie de cybersécurité, permettant de détecter, contenir et rétablir après des incidents de sécurité. Si les objectifs fondamentaux — limiter les dégâts, rétablir le fonctionnement normal et prévenir les incidents futurs — restent constants, les stratégies et outils diffèrent sensiblement entre environnements cloud et traditionnels (on-premises). Ainsi, comprendre ces différences est crucial pour les organisations évoluant dans des environnements hybrides ou entièrement cloud.
1. Caractéristiques d'infrastructure
Réponse aux incidents traditionnelle : dans un environnement IT classique, la réponse s'effectue au sein d'une infrastructure statique et maîtrisée. Elle s'appuie sur des serveurs physiques, des équipements de stockage et des composants réseau situés sur site. Les équipes de sécurité disposent d'un accès physique direct à ces actifs, facilitant ainsi la supervision, la journalisation et l'analyse forensique. En outre, les environnements traditionnels hébergent souvent des applications monolithiques et un périmètre réseau bien défini, ce qui facilite l'application de mesures de sécurité et la détection des compromissions.
Réponse aux incidents cloud : à l'inverse, les environnements cloud sont dynamiques et distribués. Les ressources sont virtualisées et peuvent être créées ou supprimées à la demande, souvent dans plusieurs régions géographiques. L'infrastructure est gérée conjointement par l'organisation et le fournisseur de services cloud (CSP), ce qui signifie que les équipes de sécurité n'ont pas toujours le contrôle ou l'accès direct à l'infrastructure physique sous-jacente. En outre, le cloud introduit de nouvelles architectures, comme les microservices, les conteneurs et le serverless, complexifiant les efforts de réponse aux incidents.
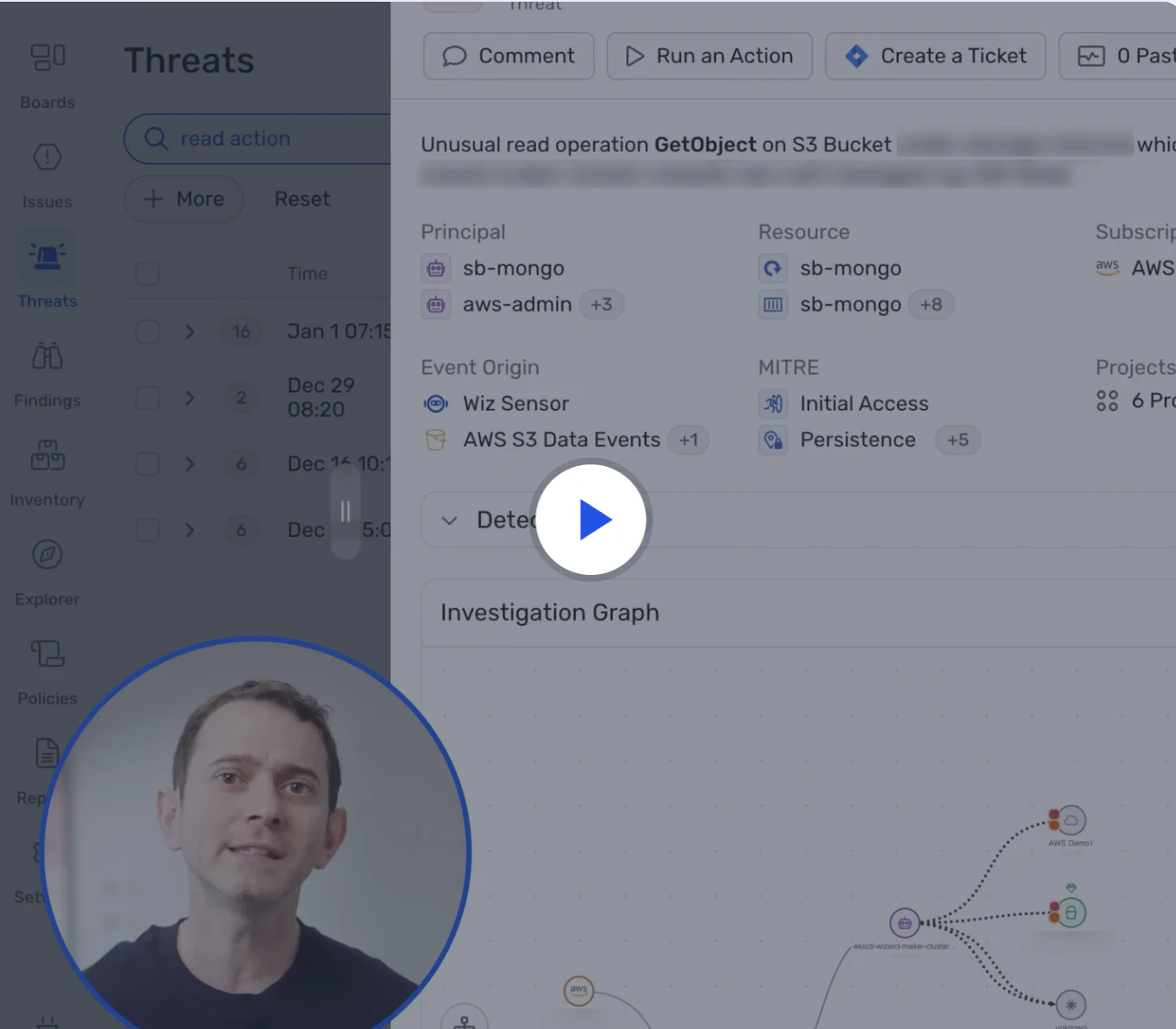
Voir la démo (5 min)
Regardez la démo pour découvrir comment Wiz Defend corrèle l’activité en temps réel avec le contexte cloud afin de détecter de véritables attaques, retracer le périmètre d’impact et accélérer les investigations.
Voir maintenant
2. Visibilité et supervision
Réponse aux incidents traditionnelle : dans un environnement traditionnel, la visibilité est généralement plus simple à obtenir grâce au caractère statique de l'infrastructure. Ainsi, les équipes peuvent déployer des outils de supervision au périmètre et à l'intérieur du réseau pour capturer et analyser le trafic, détecter des anomalies et collecter des preuves forensiques. En outre, l'accès aux équipements physiques permet des analyses approfondies, notamment l'imagerie disque et l'analyse mémoire.
Réponse aux incidents cloud : dans le cloud, la visibilité est plus difficile à obtenir en raison du caractère éphémère des ressources et de la complexité des architectures. Les logs constituent la source principale de visibilité, mais ils doivent être collectés depuis diverses couches (CSP, réseaux virtuels, couches applicatives). De plus, comme les actifs cloud peuvent être de courte durée, les logs doivent être collectés et analysés en temps réel pour éviter de perdre des données forensiques cruciales. En effet, les organisations s'appuient fortement sur les outils et services fournis par les CSP, qui n'offrent pas toujours la même profondeur de visibilité que les solutions on-premises.
3. Outillage et automatisation
Réponse aux incidents traditionnelle : elle s'appuie sur une suite d'outils éprouvés conçus pour des environnements statiques sur site : pare-feu, IDS/IPS, EDR et SIEM. Ces outils, déployés dans le datacenter de l'organisation, assurent une supervision en temps réel, une détection des menaces et des capacités de réponse avancées.
Réponse aux incidents cloud : dans le cloud, les outils traditionnels peuvent être incompatibles ou moins efficaces du fait de la nature dynamique des environnements. Des outils spécifiques au cloud sont donc nécessaires pour superviser, détecter et répondre efficacement. Ils ciblent des problématiques cloud-natives, comme l'IAM, la prévention des pertes de données (DLP) et la protection des workloads. En outre, l'automatisation est encore plus critique via le Security Orchestration, Automation and Response (SOAR), pour gérer l'échelle et la vélocité des opérations cloud.
4. Surface d'attaque et menaces
Réponse aux incidents traditionnelle : la surface d'attaque se limite essentiellement à l'infrastructure physique de l'organisation. Les menaces ciblent souvent le périmètre réseau, les postes de travail et les applications on-premises. Les vecteurs courants incluent les malwares, le phishing et les ransomwares, visant à compromettre des équipements ou à voler des données sensibles hébergées dans le datacenter.
Réponse aux incidents cloud : le cloud élargit considérablement la surface d'attaque, l'organisation étant responsable de la sécurité des données, des applications et des services sur plusieurs environnements cloud. Outre les menaces classiques, des vecteurs spécifiques au cloud incluent les erreurs de configuration, les API non sécurisées et les identifiants compromis. Ainsi, les attaquants peuvent détourner des ressources pour du cryptojacking ou chercher à mener une data exfiltration depuis des services de stockage cloud. En outre, le modèle de responsabilité partagée impose aux organisations de sécuriser leur partie de la pile cloud, tout en s'appuyant sur le CSP pour l'infrastructure sous-jacente.
5. Réponse et rétablissement
Réponse aux incidents traditionnelle : les processus de réponse et de rétablissement sont bien définis et impliquent souvent des actions manuelles. Ainsi, les équipes isolent les équipements touchés, restaurent depuis des sauvegardes et appliquent des correctifs directement sur les systèmes sur site. En outre, les délais de rétablissement sont relativement prévisibles selon la gravité de l'incident et la disponibilité des ressources.
Réponse aux incidents cloud : elle exige une approche plus agile compte tenu de la vitesse et de l'échelle du cloud. Des playbooks et scripts automatisés sont souvent employés pour isoler rapidement des ressources compromises, faire pivoter des identifiants et restaurer des services. Le rétablissement peut être plus complexe s'il faut coordonner plusieurs plateformes ou régions cloud. Cependant, la redondance et l'élasticité inhérentes du cloud peuvent accélérer la reprise si les processus sont bien intégrés avec les outils et services cloud-natives.
6. Compétences et expertise
Réponse aux incidents traditionnelle : les intervenants possèdent généralement une expertise des technologies on-premises, du réseau et de la sécurité des endpoints, avec des compétences axées sur l'infrastructure physique et des outils historiques.
Réponse aux incidents cloud : elle requiert un ensemble de compétences différent, incluant la connaissance des architectures cloud, des outils de sécurité propres aux CSP et des technologies d'automatisation. En outre, les environnements cloud évoluant rapidement, les équipes doivent mettre à jour en continu leurs compétences et suivre les dernières pratiques de sécurité et paysages de menaces. Malheureusement, la pénurie d'expertise cloud peut représenter un défi majeur pour les organisations en transition.
L'importance des logs dans la réponse aux incidents cloud
Les logs jouent un rôle central en réponse aux incidents cloud, en tant que source principale de preuves pour détecter, enquêter et répondre aux incidents de sécurité. En effet, en raison du caractère éphémère et distribué des ressources cloud, les méthodes traditionnelles d'investigation (imagerie forensique, analyse mémoire) sont souvent insuffisantes.
Ainsi, les logs apportent la visibilité nécessaire sur l'activité cloud, avec des enregistrements détaillés aidant les équipes de réponse aux incidents à comprendre l'étendue, l'impact et la cause racine d'un incident.
1. Visibilité renforcée
Dans le cloud, des actifs peuvent être créés, modifiés ou détruits en quelques minutes. Sans logging, il est donc difficile de suivre ces changements et de détecter des actions non autorisées ou suspectes. Ainsi, les logs offrent une visibilité continue sur les opérations des ressources cloud, permettant une supervision en temps réel et une réponse rapide aux incidents potentiels.
2. Analyse forensique
Les logs sont indispensables pour reconstituer les événements lors d'une enquête forensique. En effet, ils aident à bâtir une chronologie précise, identifier les ressources compromises et retracer les actions de l'attaquant. Ce niveau de détail est nécessaire pour déterminer la cause racine, évaluer l'étendue des dommages et élaborer une stratégie efficace de confinement et d'éradication.
3. Conformité et reporting
De nombreux référentiels réglementaires imposent de conserver des logs pendant une période définie et de pouvoir les produire lors d'audits ou d'investigations. Ainsi, le logging est essentiel pour démontrer la conformité et fournir des preuves en cas de litige ou d'enquête réglementaire.


Types de logs nécessaires pour la réponse aux incidents cloud
Différents types de logs jouent des rôles complémentaires dans la réponse aux incidents cloud. Voici les principales catégories :
1. Logs d'audit
Objectif : tracer les actions d'administration et d'accès, en documentant qui a fait quoi, quand et où.
Exemples : AWS CloudTrail, Azure Activity Logs, Google Cloud Audit Logs.
Importance : essentiels pour identifier des accès non autorisés, des élévations de privilèges ou des changements de configuration indiquant une compromission potentielle.
2. Logs réseau
Objectif : capturer les données relatives aux flux réseau au sein des réseaux cloud et entre eux.
Exemples : VPC Flow Logs, logs des groupes de sécurité réseau.
Importance : vitaux pour détecter des schémas de trafic inhabituels, comme des tentatives de data exfiltration ou des mouvements latéraux d'attaquants dans l'infrastructure.
3. Logs applicatifs
Objectif : enregistrer les activités et événements des applications cloud.
Exemples : logs de serveurs web, logs de requêtes base de données, logs d'erreurs applicatives.
Importance : utiles pour identifier des vulnérabilités exploitées et comprendre comment l'application a été compromise.
4. Logs de sécurité
Objectif : les logs de sécurité capturent des événements liés à la sécurité de l'environnement cloud, y compris les activités de pare-feu, les alertes IDS/IPS et les événements de Cloud Detection and Response (CDR).
Exemples : logs de Web Application Firewall (WAF), logs des security groups.
Importance : indispensables pour identifier et atténuer les menaces, suivre l'efficacité des mesures de sécurité et détecter des anomalies comportementales.
5. Logs des conteneurs et de l'orchestration
Objectif : tracer l'activité des conteneurs et des plateformes d'orchestration comme Kubernetes.
Exemples : logs d'audit Kubernetes, logs du runtime des conteneurs.
Importance : dans des environnements utilisant microservices ou conteneurs, ces logs sont critiques pour suivre l'activité, détecter des changements non autorisés et comprendre comment l'orchestration a été manipulée.
Principales sources de logs pour la réponse aux incidents
Pour gérer efficacement la réponse aux incidents cloud, il est essentiel de savoir où collecter les logs pertinents. Voici les sources majeures :
1. Logs des fournisseurs de services cloud (CSP)
Exemples : AWS CloudTrail, Azure Monitor Logs, Google Cloud Logging.
Importance : offrent une visibilité complète sur les opérations et événements de sécurité de l'infrastructure cloud. Ils constituent la source principale de logs d'audit, d'accès et d'événements de sécurité.
2. Systèmes de SIEM (Security Information and Event Management)
Exemples : Splunk, IBM QRadar, Azure Sentinel.
Importance : agrègent les logs de multiples sources (CSP, applications, équipements réseau) pour une supervision, une analyse et une réponse centralisées.
3. Outils de sécurité cloud-natives
Exemples : AWS GuardDuty, Azure Security Center, Google Cloud Security Command Center.
Importance : offrent des capacités spécialisées de journalisation et d'alerte adaptées au cloud, avec une visibilité sur les menaces et vulnérabilités propres à l'infrastructure cloud.
4. Outils d'APM (Application Performance Management)
Exemples : Datadog, New Relic, AppDynamics.
Importance : fournissent des logs offrant une visibilité fine sur la performance et le comportement applicatifs, cruciale pour détecter et investiguer des incidents au niveau applicatif.
5. Logs d'orchestration de conteneurs
Exemples : logs d'audit Kubernetes, logs Docker.
Importance : dans des environnements conteneurisés et microservices, ils apportent de la visibilité sur les déploiements, la montée en charge et les changements de configuration, essentiels en réponse aux incidents.
Le cycle de réponse
Dans cette section, nous détaillons les points d'attention et les bonnes pratiques à chaque étape du cycle de réponse aux incidents dans le cloud.
Préparation
Compte tenu de la pénurie actuelle de compétences cloud, il est essentiel de former toutes les parties prenantes de la réponse aux incidents afin qu'elles maîtrisent le cloud public et les technologies cloud que vous utilisez. Il est aussi judicieux de définir en amont des politiques d'accès basées sur les rôles (RBAC) pour que l'équipe de réponse aux incidents puisse agir sans délai lorsqu'un incident survient.
Veillez également à automatiser autant que possible la collecte d'artefacts forensiques traditionnels, tels que des instantanés disques et mémoire. Comme ces artefacts seront collectés via des API plutôt que par accès physique, mettez en place des playbooks automatisés que les intervenants pourront exécuter immédiatement pour garantir la collecte des données critiques avant qu'elles ne disparaissent.
N'oubliez pas que les logs joueront un rôle bien plus important dans l'investigation d'incidents cloud. En effet, ils peuvent être très variés — des logs d'audit CSP et logs de flux réseau (VPC) aux logs d'orchestration des conteneurs (Kubernetes).
Vous devez donc collecter les logs pertinents et les stocker de façon sécurisée pour une analyse immédiate le moment venu. Tenez toutefois compte du coût de la collecte et n'activez que les logs susceptibles d'être utilisés en cas d'incident. En outre, de nombreux services de logging sont désactivés par défaut : ne partez donc pas du principe que toute la télémétrie nécessaire est déjà en place.


Détection et investigation
Les déploiements cloud-natives sont généralement composés d'une myriade de composants, rendant l'investigation souvent particulièrement complexe.

Au cœur de l'investigation se trouve la construction d'une chronologie d'incident : vous devez savoir précisément qui a fait quoi et quand pour reconstituer l'attaque. Or, du fait de la complexité des environnements cloud, vous devrez mobiliser un éventail plus large d'outils, nouveaux et existants, pour bâtir cette chronologie. Elle vous aidera à recouper les événements et à déterminer :
la cause racine de l'incident ;
le périmètre d'impact ;
l'impact probable de l'attaque ;
la mesure corrective la plus appropriée.
Ces outils incluent généralement :
la découverte d'actifs et la cartographie d'inventaire ;
un SIEM (Security Information and Event Management) ;
la forensique numérique et la création de chronologies machine.
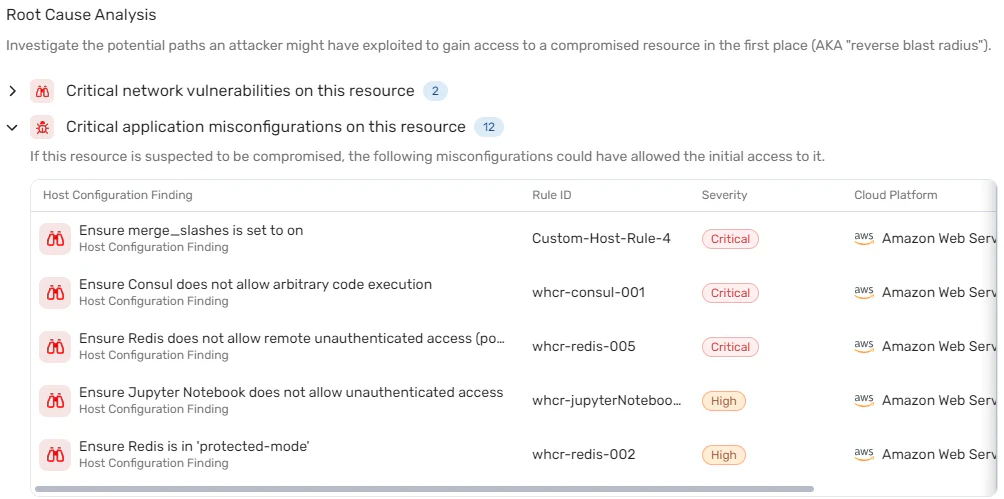
À un niveau plus granulaire, vous effectuerez par exemple :
la compréhension du profil comportemental de l'identité affectée ;
la détermination des autres ressources auxquelles cette identité a accès ;
l'identification d'erreurs de configuration ;
la prise et l'examen d'instantanés (snapshots).
Confinement
Comme pour l'investigation, la nature distribuée et dynamique du cloud public rend le confinement — et l'éradication — plus difficiles qu'en environnement traditionnel.
En effet, la manière de contenir un incident cloud diffère souvent des méthodes classiques. Par exemple, alors qu'une solution EDR isole rapidement une machine compromise dans un réseau traditionnel, dans le cloud, l'option la plus efficace consiste souvent à modifier ses paramètres de security group via le plan de contrôle cloud.

Votre équipe de sécurité devra donc adopter de nouvelles approches de confinement adaptées au cloud. Elle devra aussi se familiariser avec les capacités natives des CSP pour soutenir le confinement, comme la simplification de la configuration réseau et la gestion des droits d'accès à l'infrastructure cloud (CIEM).
Éradication
De même, vous devrez employer de nouvelles méthodes pour supprimer une menace de votre environnement cloud.
Les mesures typiques incluent :
la rotation des secrets tels que jetons d'API, clés de chiffrement et mots de passe ;
le blocage des points d'entrée utilisés par l'attaquant ;
la restauration des ressources à leur état pré-infection ;
la purge des images de conteneurs et de machines infectées ;
l'assainissement des templates d'infrastructure-as-code (IaC) ;
la suppression du code malveillant injecté dans des fonctions serverless ;
la correction des vulnérabilités exploitées.
Or, exécuter ces tâches à l'échelle du cloud est très chronophage — précisément quand il faut agir vite. D'où l'importance de technologies telles que le Security Orchestration, Automation and Response (SOAR), qui accélèrent les temps de réponse grâce à l'automatisation intégrée de ces processus.
N'oubliez pas que l'éradication vise la suppression complète de la menace afin qu'elle ne soit plus présente nulle part dans votre réseau. Dans cette phase, surveillez ensuite votre environnement cloud pour tout signe d'activité malveillante résiduelle, comme des appels d'API inhabituels, signes potentiels de persistance de l'attaquant.
Bonnes pratiques de réponse aux incidents cloud en environnement multi-cloud
Gérer la réponse aux incidents (IR) dans un environnement multi-cloud apporte son lot de défis spécifiques. En effet, les organisations exploitent souvent plusieurs CSP pour bénéficier de fonctionnalités, de modèles tarifaires et de disponibilités géographiques variés. Cette approche complique toutefois la réponse aux incidents du fait des outils, des architectures et des mesures de sécurité propres à chaque CSP. Pour être efficace en multi-cloud, adoptez les bonnes pratiques suivantes :
Centralisation du logging et de la supervision
La centralisation est cruciale en environnement multi-cloud :
agrégez les logs de tous les fournisseurs cloud dans un référentiel central pour une visibilité unifiée ;
utilisez des outils de supervision cloud-natives et des solutions tierces capables d'intégrer des données multi-cloud ;
établissez des standards de logging cohérents sur tous les environnements pour faciliter l'analyse et la corrélation.
Plan de réponse aux incidents unifié
Élaborez un plan de réponse aux incidents couvrant tous les environnements cloud :
définissez clairement les rôles et responsabilités de l'équipe de réponse aux incidents sur les différentes plateformes ;
établissez des procédures standardisées pour la détection, le confinement et la remédiation ;
mettez le plan à jour régulièrement et testez-le pour garantir son efficacité en contexte multi-cloud.
How to Create an Incident Response Policy: An Actionable Checklist and Template
En savoir plus

Capacités de réponse automatisée
Exploitez l'automatisation pour gagner en efficacité et en rapidité :
mettez en place des alertes automatisées capables de détecter et notifier des incidents potentiels sur tous les environnements cloud ;
utilisez des outils d'orchestration pour automatiser les premières actions, comme l'isolement de ressources affectées ou la révocation d'identifiants compromis ;
développez des playbooks pour les incidents courants, exécutables automatiquement ou avec un minimum d'intervention humaine.
Mesures de sécurité spécifiques au cloud
Adaptez les mesures de sécurité aux spécificités de chaque fournisseur :
implémentez des politiques IAM robustes et spécifiques à chaque plateforme cloud ;
exploitez les services de sécurité natifs, tels qu'AWS GuardDuty ou Azure Security Center ;
assurez une configuration correcte des security groups réseau, des pare-feu et des autres mesures de sécurité de chaque environnement.
Visibilité cross-plateforme
Maintenez une visibilité complète sur tous les environnements cloud :
déployez des outils offrant une vue unifiée de la posture de sécurité sur plusieurs environnements cloud ;
réalisez régulièrement un inventaire des actifs et des analyses de vulnérabilités sur toutes les plateformes ;
utilisez des solutions de gestion de la posture de sécurité cloud (CSPM) pour identifier erreurs de configuration et problèmes de conformité.
Formation à la réponse aux incidents
Préparez l'équipe de réponse aux incidents aux scénarios multi-cloud :
formez-la aux outils et services spécifiques à chaque plateforme cloud ;
menez des exercices sur table réguliers et des tests d'intrusion couvrant des scénarios multi-cloud ;
tenez l'équipe informée des dernières menaces et vecteurs d'attaque spécifiques au cloud.
BESOIN D'UN POINT DE DÉPART POUR CONSTRUIRE OU AFFINER VOTRE PLAN DE RÉPONSE AUX INCIDENTS ? DÉCOUVREZ NOTRE SÉLECTION DE MODÈLES GRATUITS DE PLANS DE RÉPONSE AUX INCIDENTS — DES EXEMPLES PRATIQUES, PRÊTS POUR LE CLOUD, POUR ACCÉLÉRER VOS DÉMARCHES.
Protection et récupération des données
Mettez en œuvre des mécanismes robustes de protection et de reprise :
chiffrez les données au repos et en transit sur tous les environnements cloud ;
implémentez des procédures cohérentes de sauvegarde et de reprise après sinistre pour les données et systèmes critiques ;
testez régulièrement les processus de restauration pour garantir leur efficacité sur différentes plateformes cloud.
La prochaine étape de vos préparatifs en réponse aux incidents
Cet article constitue un guide de démarrage rapide de la réponse aux incidents cloud, présentant quelques défis et pratiques à adopter dans le cloud. Cependant, la gestion des incidents comporte de nombreux autres aspects à considérer pour une préparation complète.
C'est pourquoi Wiz a récemment publié un modèle de plan de réponse aux incidents destiné spécifiquement aux équipes d'opérations de sécurité chargées de protéger des déploiements cloud public, hybride et multicloud. Ce guide détaillé explique ce que votre propre plan devrait inclure et les mesures à prévoir pour gérer efficacement les incidents de sécurité affectant votre environnement cloud.
Téléchargez dès aujourd'hui votre exemplaire du modèle et renforcez votre posture de réponse aux incidents cloud.
Réponse aux incidents cloud-native
Découvrez pourquoi les équipes des opérations de sécurité s’appuient sur Wiz pour détecter et répondre de manière proactive aux menaces cloud en cours.
