

A medida que las organizaciones incorporan cada vez más la IA en sus productos y operaciones, asegurar los sistemas de IA se ha convertido en una prioridad máxima para SecOps. Pero asegurar la IA no es como proteger el software tradicional: la IA es un ecosistema de modelos, canales de datos, código, APIs e integraciones de terceros, todos ellos introduciendo nuevos riesgos de seguridad y cumplimiento.
Si sus aplicaciones de IA se ejecutan en la nube, estos riesgos se vuelven aún más desafiantes. Los modelos de IA alojados en la nube interactúan dinámicamente con conjuntos de datos externos, API y usuarios, lo que los hace más susceptibles al envenenamiento de datos, la inyección rápida y los ataques adversarios.
Las pruebas de seguridad tradicionales no son suficientes para lidiar con la IA'. Por eso el red teaming con IA —una práctica que simula activamente ataques adversariales en condiciones reales— está emergiendo como un componente crítico en las estrategias modernas de seguridad de IA y un contribuyente clave a la Crecimiento del mercado de ciberseguridad por IA.
Con Regulaciones de seguridad de IA más estrictas y la adopción de la IA se dispara, las organizaciones deben adoptar el equipo rojo de la IA para adelantarse a las amenazas en evolución y a las nuevas oportunidades.
¿Qué es el red teaming de IA?
El equipo rojo de IA es una práctica de ciberseguridad que simula ataques a sistemas de IA para identificar vulnerabilidades en condiciones reales.
A diferencia de los puntos de referencia de seguridad estándar y las pruebas de modelos controlados, el equipo rojo de IA va más allá de evaluar la precisión y la equidad del modelo. Examina todo el ciclo de vida y la cadena de suministro de la IA, desde modelos de IA y canales de datos hasta servicios de IA alojados en la nube e interacciones usuario-IA, asegurando que cada componente sea resistente frente a posibles adversarios.
Al adoptar una postura adversarial, el red teaming de IA descubre proactivamente debilidades ocultas de seguridad, ya sea introducidas mediante entrenamiento de modelos, pipelines de inferencia o interacciones en tiempo real con los usuarios. Va más allá de las evaluaciones de modelos estáticos y garantiza que los sistemas de IA sigan siendo resistentes en condiciones dinámicas del mundo real.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

¿Qué pruebas se realizan típicamente para el equipo rojo de IA?
El equipo rojo de IA efectivo requiere un enfoque integral que abarque aspectos técnicos y operativos para cubrir la superficie de ataque ampliada de las implementaciones empresariales. Las áreas de prueba clave incluyen:
Predisposición & Pruebas de equidad: Evalúa si los modelos de IA producen resultados discriminatorios o sesgados, incluso cuando están bajo estrés o presión adversa
Violaciones de la privacidad de datos: Identifica los riesgos de Fuga de datos o acceso no autorizado, asegurando que la información sensible esté protegida en toda la cadena de datos
Riesgos de interacción humano-IA: Prueba cómo responden los sistemas de IA a entradas y usos maliciosos o inesperados de los usuarios, lo cual es fundamental para detectar vulnerabilidades como Inyección rápida
Defensa adversarial de ML: Evalúa la capacidad de los sistemas de IA para resistir ataques adversarios dirigidos, como la inyección inmediata y Envenenamiento de datos
Las áreas adicionales de prueba incluyen el rendimiento bajo estrés, análisis de vulnerabilidad de integración y modelado de amenazas específico de escenarios.
Estas pruebas deben tener en cuenta la naturaleza en constante evolución de los sistemas de IA, donde el reentrenamiento continuo y la deriva del modelo exigen medidas de seguridad dinámicas y adaptativas. Dado que la IA está en constante evolución, las organizaciones también deberían invertir en estrategias sólidas de medición y mitigación para mantenerse por delante Riesgos de seguridad de la IA.
¿Cuál es el objetivo del equipo rojo de IA?
El equipo rojo de IA tiene como objetivo proteger a los usuarios y las empresas del uso indebido de la IA destacando (y corrigiendo) fallas en los sistemas de IA para que los sistemas de IA sean resistentes y confiables. Los objetivos clave del equipo rojo de IA incluyen:
Identificación de riesgos: Detectar y abordar las vulnerabilidades de la IA antes de que los atacantes las exploten
Construcción de resiliencia: Fortalecimiento de los modelos y la infraestructura de IA contra las amenazas adversas
Alineación regulatoria: Cumplir con los requisitos de cumplimiento, incluidos los de la Ley de IA de la UE y la Orden ejecutiva de la Casa Blanca de EE. UU. sobre IA
Confianza pública: Garantizar que la IA sea segura, confiable y esté alineada con los estándares éticos
Integrando el red teaming de IA en un ámbito más amplio Gestión de riesgos por IA estrategia y Marco de gobernanza de la IA es fundamental para lograr una seguridad proactiva y a largo plazo en toda tu organización.
State of AI in the Cloud
Based on the sample size of hundreds of thousands of public cloud accounts, our second annual State of AI in the Cloud report highlights where AI is growing, which new players are emerging, and just how quickly the landscape is shifting.

¿En qué se diferencia el equipo rojo para IA del equipo rojo tradicional?
Mientras que tanto el equipo rojo de IA como el equipo rojo tradicional se centran en Identificar vulnerabilidades antes de que los atacantes puedan explotarlas, difieren fundamentalmente en alcance, metodologías y objetivos.
Equipo rojo tradicional: Centrado en infraestructura, redes y aplicaciones
El equipo rojo tradicional simula ciberataques del mundo real contra la infraestructura de TI, las aplicaciones y los empleados de una organización. El objetivo principal es evaluar qué tan bien se mantienen las defensas de seguridad contra los adversarios al apuntar:
Seguridad de red: Explotación de configuraciones incorrectas, escalada de privilegios, movimiento lateral
Seguridad de la aplicación: Identificación de vulnerabilidades de aplicaciones web como inyección SQL (SQLi), ejecución remota de código (RCE)y XSS (secuencias de comandos entre sitios)
Ingeniería social: Manipular a los empleados para que revelen credenciales o hagan clic en enlaces de phishing
El equipo rojo tradicional está bien definido, siguiendo estándares de la industria como MITRE ATT&CK, NIST 800-53 y OSSTMM. Las vulnerabilidades encontradas a menudo tienen soluciones claras (parchear software, actualizar configuraciones, mejorar la conciencia del usuario).
Equipos rojos de IA: Expandiendo la superficie de ataque más allá de la seguridad tradicional
El equipo rojo de IA se expande más allá de las preocupaciones de seguridad tradicionales para tener en cuenta los riesgos únicos que plantean los sistemas de IA. En lugar de limitarse a proteger la infraestructura en la que se ejecuta la IA, simula ataques adversarios al propio modelo de IA, su canalización de datos, las API y las interacciones en tiempo real.
Diferencias clave
Amenazas basadas en datos: A diferencia de las vulnerabilidades de software tradicionales, las amenazas de IA se originan en la manipulación de datos, el envenenamiento de modelos y la inyección rápida.
Superficie de ataque en evolución: Los modelos de IA cambian dinámicamente a medida que se vuelven a entrenar, lo que requiere evaluaciones de seguridad continuas.
Seguridad & Superposición ética: Las vulnerabilidades de la IA incluyen sesgos, desinformación, alucinaciones y problemas de confiabilidad, que son't preocupaciones típicas en la ciberseguridad tradicional.
Looking for AI security vendors? Check out our review of the most popular AI Security Solutions ->
Cómo difiere el equipo rojo de IA de las pruebas estándar de modelos de IA
La mayoría de las pruebas de IA se centran en la precisión, la detección de sesgos y los principios responsables de la IA. Sin embargo, el equipo rojo de IA simula escenarios de ataque reales para descubrir brechas de seguridad más allá de los puntos de referencia de rendimiento.
| AI Model Testing | AI Red Teaming |
|---|---|
| Evaluates model fairness, accuracy, explainability | Simulates real-world adversarial attacks |
| Uses controlled datasets & scenarios | Tests AI in live, unpredictable environments |
| Focuses on ML robustness | Assesses entire AI supply chain & infrastructure |
| Ensures responsible AI compliance | Validates security, privacy, and resilience |
Al integrar equipos rojos de IA en la gestión de riesgos de IA y la gobernanza de seguridad, las organizaciones pueden mantenerse por delante de las amenazas emergentes, asegurar el cumplimiento con regulaciones en evolución (como la Ley de IA de la UE) y mantener la confianza pública en las aplicaciones impulsadas por IA.
Vulnerabilidades comunes y casos de uso en el mundo real del equipo rojo de IA
A pesar de la complejidad de la IA, los ataques en el mundo real suelen ser sorprendentemente simples: explotan configuraciones incorrectas, debilidades pasadas por alto o una higiene de seguridad deficiente de la IA. Algunos de los ataques de IA más comunes incluyen:
Ataques de puerta trasera: Los disparadores ocultos insertados en los sistemas de IA pueden permitir a los atacantes manipular secretamente las salidas, creando vías para el control no autorizado.
Inyección inmediata: Al crear entradas maliciosas, los atacantes pueden alterar sutilmente las respuestas de la IA o incluso desencadenar fugas de datos no deseadas, al igual que deslizar un caballo de Troya en un sistema confiable.
Envenenamiento de datos: La inyección de datos de entrenamiento corruptos puede sesgar lentamente el comportamiento de la IA, enseñándole efectivamente a actuar de manera que favorezca la agenda de un atacante.
Debilidades de integración: Las vulnerabilidades en las API y las conexiones en la nube pueden exponer los sistemas a la explotación, lo que permite a los atacantes eludir las medidas de seguridad y obtener acceso a datos críticos.
Estas vulnerabilidades no son solo teóricas. Exploremos casos del mundo real, descubiertos por el Equipo de investigación de Wiz, que han puesto de relieve estos riesgos:
Fuga de base de datos de DeepSeek: Las fallas de integración en el último modelo de DeepSeek llevaron a la exposición de datos confidenciales de entrenamiento de IA.
🔍Este ejemplo del mundo real muestra cómo… pueden surgir nuevas amenazas de IA a partir de configuraciones incorrectas de acceso a modelos y API pasadas por alto.
Vulnerabilidades de SAP AI: Las configuraciones incorrectas en los sistemas de IA de SAP crearon riesgos ocultos de puerta trasera, lo que potencialmente permitió a los atacantes manipular los resultados de IA.
🔍Este ejemplo del mundo real muestra cómo…incluso las plataformas empresariales de IA bien establecidas pueden sufrir puntos ciegos de seguridad.
Vulnerabilidad de IA de NVIDIA: Las debilidades en el kit de herramientas de contenedores de IA de NVIDIA permitieron ataques de inyección rápida, exponiendo brechas en la seguridad de IA a nivel de infraestructura.
🔍Este ejemplo del mundo real muestra cómo…los atacantes pueden manipular el comportamiento de la IA a través de ataques basados en la entrada, afectando las decisiones y salidas impulsadas por la IA.
Riesgos del modelo Hugging Face: Las vulnerabilidades de envenenamiento de datos en las populares plataformas de IA como servicio de Hugging Face permitieron a los adversarios introducir alteraciones sutiles y maliciosas en los datos de entrenamiento.
🔍Este ejemplo del mundo real muestra cómo…incluso los servicios de IA ampliamente confiados son susceptibles a la manipulación adversarial de datos, enfatizando la necesidad de pruebas de seguridad continuas.
Cuando se trata de Seguridad de la IA, incluso los errores más simples pueden tener consecuencias profundas. Su organización necesita un equipo rojo de IA continuo y proactivo para detectar y solucionar estos problemas antes de que se conviertan en violaciones de seguridad en toda regla.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Mejores prácticas para el equipo rojo de IA: un marco de 5 pasos
Para crear equipos de IA de manera efectiva, las organizaciones necesitan un marco de seguridad escalable, repetible y en continua evolución. Los modelos de IA se vuelven a entrenar y actualizar dinámicamente, lo que hace que las medidas de seguridad estáticas sean ineficaces. Un proceso de equipo rojo de IA bien estructurado garantiza que la IA siga siendo resistente contra ataques adversarios, exploits de sesgo y configuraciones incorrectas.
Paso 1: Definir el alcance del equipo rojo de IA
Antes de probar la seguridad de la IA, las organizaciones deben definir:
¿Qué componentes de la IA necesitan prueba?
Robustez del modelo, integraciones de API, seguridad de la IA basada en la nube, integridad de los datos de entrenamiento
¿Cuáles son los escenarios de ataque?
Ataques de ML adversarios (evasión, envenenamiento), abuso de API, inyección de prompt, riesgos de la cadena de suministro
¿Qué seguridad & ¿Se aplican requisitos de cumplimiento?
Seguridad de IA de OWASP, Marco de Referencia de IA de NIST, Acto de IA de la UE, SOC 2, GDPR
Paso 2: Selecciona e implementa métodos de pruebas adversarias de IA
El red teaming de IA va más allá de la prueba de penetración, requiere técnicas de ML adversarias para simular amenazas de IA del mundo real.
Pruebas centradas en el modelo (evaluación de robustez de IA)
Pruebas de perturbación adversaria: Genera entradas para engañar a la IA para que clasifique erróneamente
Inversión del modelo & extracción: Intentos de reconstruir datos de entrenamiento privados a partir de respuestas de IA
Pruebas de seguridad en la canalización de datos
Simulaciones de envenenamiento de datos: Comprueba si la inyección de datos de entrenamiento maliciosos sesga el comportamiento de la IA
Predisposición & Pruebas de equidad: Evalúa si los adversarios pueden explotar el sesgo del modelo de IA para la manipulación
Interacción humano-IA & Seguridad de API
Ataques de inyección rápida: Pruebas si la IA ignora las salvaguardas a través de entradas manipuladas
Pruebas de abuso de API: Explora las vulnerabilidades de la API del modelo de IA (por ejemplo, recuperación de datos sin restricciones)
Paso 3: Automatizar el red teaming de IA para escalabilidad
Probar manualmente las vulnerabilidades de IA en implementaciones a escala de nube es ineficiente. La automatización ayuda a simular ataques adversarios a gran escala.
Usar seguridad de IA & Herramientas de pruebas adversarias
Garak: Herramienta de pruebas adversarias de código abierto para la seguridad de LLM
PyRIT (Identificación de riesgos de Python para IA generativa): Simula ataques de evasión y extracción de modelos
Contraajuste de Microsoft: Pruebas de seguridad de IA para modelos de aprendizaje automático
Caja de herramientas de robustez adversaria (ART): Simula ataques y defensas de IA adversarios
Paso 4: Implementar el monitoreo continuo de riesgos de IA & respuesta
El equipo rojo de IA no es una prueba única, debe evolucionar continuamente a medida que los modelos de IA se actualizan y reentrenan.
Estrategias continuas de equipo rojo de IA
Establecer el intercambio de inteligencia de amenazas de IA: Realice un seguimiento de las amenazas en evolución de MITRE ATLAS y OWASP AI Top 10.
Adopte pruebas continuas de seguridad de IA: Integre pruebas adversarias en canalizaciones de CI/CD.
Desarrollar una puntuación de riesgo automatizada para la IA: Priorice las vulnerabilidades de IA de alto riesgo para su corrección.
Paso 5: Alinear equipo rojo de IA con gobernanza y cumplimiento
Más allá de la seguridad, el equipo rojo de IA debe apoyar directrices regulatorias y éticas de AI para asegurar el cumplimiento.
Seguridad clave de IA & Estándares de cumplimiento
Marco de gestión de riesgos de IA del NIST (AI RMF): Mejores prácticas de seguridad de IA
Ley de IA de la UE: Requisitos de cumplimiento para aplicaciones de IA de alto riesgo
SOC 2, GDPR, CCPA: Proteja los datos personales impulsados por IA
Integrar equipo rojo de IA en la gestión de riesgos empresariales (ERM)
Informe los hallazgos a los equipos de gobernanza de IA: Alinearse con la ética y los principios de IA responsable.
Colaboración multifuncional: Involucre a los equipos de seguridad, ciencia de datos y cumplimiento en la gestión de riesgos de IA.


¿Cómo mejora Wiz tu seguridad de IA?
Wiz ofrece una plataforma integral de seguridad en la nube que amplía sus capacidades para proteger la infraestructura de IA con su Gestión de la postura de seguridad de la IA (IA-SPM).
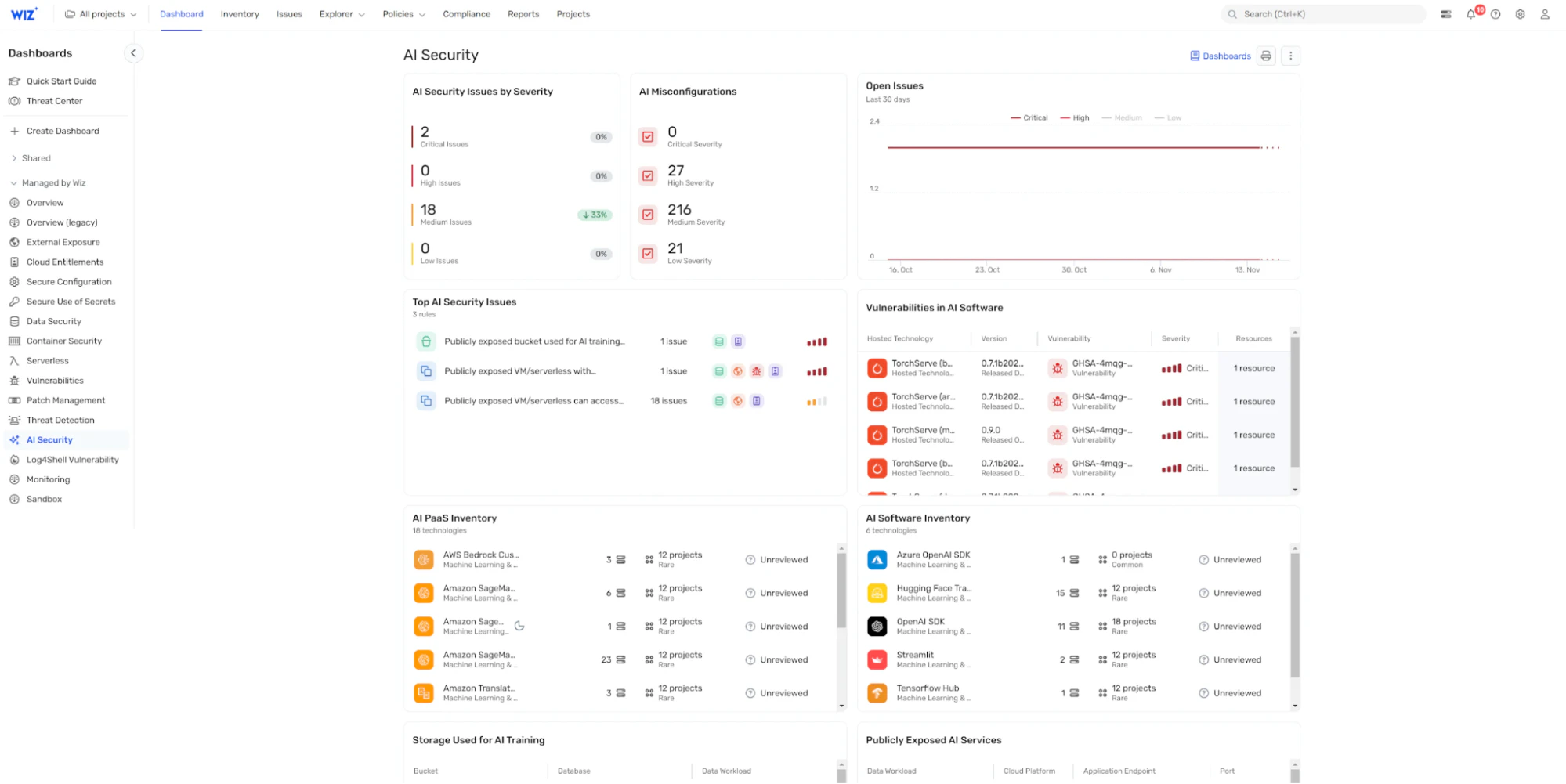
A través de su panel de seguridad de IA centralizado, Wiz AI-SPM te ofrece:
Una lista de materiales de IA (lista de materiales de IA): Un mapa detallado de sus componentes y dependencias de IA, que ofrece una visibilidad clara de todo su ecosistema
Detección de errores de configuración: Identificación automatizada de brechas de seguridad en canalizaciones de IA y servicios en la nube, lo que lo ayuda a abordar las vulnerabilidades antes de que se intensifiquen
Análisis de la ruta de ataque: Visualización de rutas potenciales que los atacantes podrían usar para explotar los riesgos de seguridad de la IA, lo que permite una gestión de riesgos más informada
Investigación impulsada por IA: Acelera tus esfuerzos de red teaming en IA con Mika AI, que te ayuda a investigar rápidamente posibles vulnerabilidades, comprender escenarios de ataque complejos y obtener orientación práctica de remediación en lenguaje natural
Respuesta automática: Cuando el red teaming de IA descubre vulnerabilidades críticas, el Agente de IA de Wiz SecOps puede triar, investigar e iniciar automáticamente flujos de trabajo de respuesta, reduciendo el tiempo desde la detección hasta la remediación
Integrando estas capacidades, Wiz AI-SPM no solo implementa las mejores prácticas de seguridad de IA, sino que también facilita el monitoreo continuo y la gestión automatizada de riesgos para su organización, asegurando una gobernanza de IA robusta.
¿Qué sigue?
El equipo rojo de IA se está convirtiendo en una función de seguridad crítica para las organizaciones comprometidas con salvaguardar su adopción de IA, especialmente a medida que aumentan las demandas regulatorias. Aunque el campo continúa evolucionando, persisten desafíos como ataques complejos, interoperabilidad contextual y falta de estandarización.
Una plataforma de seguridad como Wiz puede ayudarte a mantenerte a la vanguardia de las mejores prácticas de seguridad de IA al iniciar tus defensas y asegurar una mejora continua. ¿Listo para aprender más? Visita el
Una plataforma de seguridad como Wiz puede ayudarlo a mantenerse a la vanguardia de las mejores prácticas de seguridad de IA al iniciar sus defensas y garantizar la mejora continua. ¿Listo para aprender más? Más información sobre Wiz AI-SPM, o si prefieres un Demo en directo, nos encantaría conectar contigo.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
