

Qu’est-ce que les garde-fous de l’IA ?
Les garde-fous de l’IA (également appelés garde-corps LLM ou garde-fous GenAI) sont Contrôles de sécurité préventifs qui contraignent le comportement d’un système d’IA dans des limites politiques définies. Ils façonnent ce qu’un modèle peut voir, faire et reproduire, réduisant ainsi le risque de résultats nuisibles, biaisés ou enfreignant les politiques lors de l’exécution du modèle.
Les garde-corps sont Contrôles préventifs appliquée avant et pendant l’inférence. Ils travaillent ensemble Contrôles de détective tels que la journalisation, la surveillance et l’alerte, qui identifient les violations après leur survenue, et Contrôles de gouvernance telles que les politiques, la documentation et les exigences d’audit.
En pratique, trois couches de garde-corps sont utilisées ensemble :
Garde-corps d’entrée : Filtrez, validez et remodelez les invites avant qu’elles n’atteignent le modèle.
Limites de traitement : Contrôler le contexte, les données et les outils auxquels le modèle peut accéder, et appliquer les règles métier lors du raisonnement.
Rampes de sécurité de sortie : Évaluez la réponse du modèle et bloquez-le, modifiez-le ou rejetez-le avant de le retourner à l’utilisateur.
Ces garde-corps diffèrent de la sécurité traditionnelle des applications. Les contrôles traditionnels protègent le code déterministe et les entrées structurées comme les champs de formulaire ou le JSON. Les garde-fous de l’IA doivent gérer les systèmes non déterministes et le langage naturel, où la même requête peut produire des sorties différentes à chaque fois et où le comportement du modèle peut être influencé par l’intégration du contexte ou l’injection de prompts.
Pour les entreprises – surtout lorsqu’il s’agit de gérer des données réglementées ou de flux de travail en contact avec la clientèle – les garde-fous sont la solution transformer un prototype en système de production. Ils appliquent vos exigences de sécurité, de sûreté et de conformité tout en permettant aux équipes de s’appuyer sur des modèles de fondation puissants.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Pourquoi les garde-fous de l’IA sont importants pour la sécurité cloud
Lorsque vous déployez l’IA dans le cloud, vous combinez deux propriétés complexes : entrées de langage naturel non fiables et Accès aux données et systèmes sensibles. Un modèle peut être influencé par un texte arbitraire, mais il fonctionne sur une infrastructure partagée, derrière des API publiques ou internes, et souvent avec un accès à de vraies données métier. Cela brise de nombreuses hypothèses derrière les contrôles de sécurité traditionnels.
Les systèmes d’IA cloud traitent des données sensibles telles que des informations personnelles, des documents financiers ou des documents propriétaires. Des contrôles traditionnels comme les règles réseau et les pare-feux Impossible d’évaluer les invites, les fenêtres de contexte ou le comportement du modèle, donc ils ne préviennent pas des attaques comme l’injection rapide, la manipulation de la récupération ou l’utilisation inattendue d’outils. Les principaux fournisseurs cloud intègrent désormais des contrôles de sécurité dans leurs services d’IA (par exemple, Guardrails for Amazon Bedrock, les filtres de contenu Azure OpenAI et les filtres de sécurité Google Vertex AI), mais ceux-ci doivent être combinés avec Politiques spécifiques à l’organisation, contrôles IAM et surveillance à l’exécution pour être efficace.
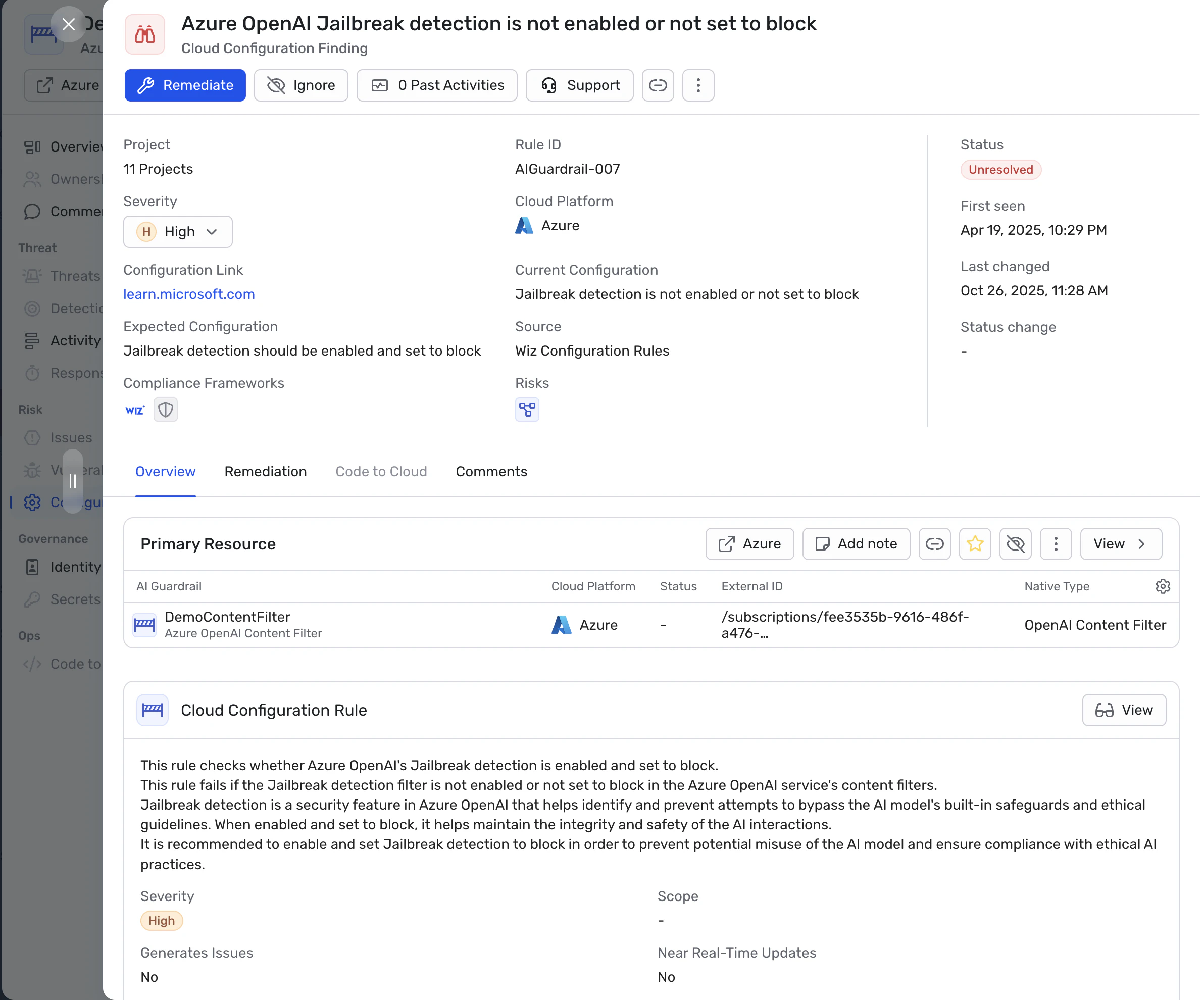
Dans un environnement cloud, votre Surface d’attaque IA Comprend désormais :
Mannequins : des LLM hébergeants, des modèles affinés et des embeddings personnalisés.
Données d’entraînement et d’inférence : des lacs de données, des entrepôts vectoriels et des journaux pouvant contenir du contenu confidentiel.
Points d’extrémité d’inférence : API publiques et internes pour le chat, la recherche ou les appels d’outils.
Agents et orchestration : un code qui permet aux modèles d’appeler des outils internes ou des services externes.
Artefacts de modèles : des poids, des points de contrôle et des images de conteneurs pouvant être modifiés dans la chaîne d’approvisionnement.
Sans garde-fous, le comportement normal de l’IA peut devenir un incident de sécurité : une attaque par injection prompte extrait des données sensibles d’un magasin vectoriel, un agent exécute une action non intentionnelle contre des API internes, ou un point de terminaison mal configuré expose des informations clients. Ces défaillances créent à la fois un risque de sécurité et un risque de marque, car la sortie du modèle est directement visible pour les utilisateurs.
Les entreprises des secteurs réglementés utilisent déjà des garde-fous multi-couches pour assurer la sécurité des déploiements. Par exemple, les constructeurs automobiles utilisent des assistants cloud avec un filtrage strict des entrées, un accès contrôlé aux données des véhicules et des vérifications en temps réel des réponses pouvant être renvoyées aux conducteurs. Cela leur permet d’adopter des modèles avancés tout en respectant des limites strictes de sécurité et de conformité.
Types de garde-fous de l’IA
Les garde-corps pratiques fonctionnent comme un Pipeline. Les entrées sont vérifiées avant d’atteindre le modèle, le modèle s’exécute dans un contexte d’exécution contrôlée, et les sorties sont validées avant d’atteindre les utilisateurs ou les systèmes en aval.
1. Glissières d’entrée
Les garde-fous d’entrée évaluent et reconfigurent les requêtes entrantes Avant l’inférence. C’est la première couche de prévention contre les comportements dangereux.
Les garde-corps d’entrée courants incluent :
Injection rapide et détection de l’évasion : Identifier les tentatives de contournement des instructions système ou d’accès à des données restreintes.
Analyse des données sensibles : Détectez et caviardez les PII, PHI, identifiants ou clés dans les invites.
Contenu illégal ou interdit : Bloquez les demandes qui cherchent des instructions nuisibles ou du matériel interdit.
Contrôles abusifs et abusifs : Faire respecter les limites de débit, identifier l’utilisation anormale et bloquer les tentatives de force brute contre les filtres de sécurité.
En pratique, les garde-fous d’entrée peuvent rejeter une consigne, demander une clarification, ou Désinfectez l’entrée (par exemple, identifiants de masquage) avant de l’envoyer au modèle.
2. Rampes de traitement
Les garde-fous de traitement façonnent le contexte d’exécution dans lequel le modèle fonctionne. Ils déterminent ce à quoi le modèle est autorisé à accéder et comment il peut agir, au-delà du texte de la consigne.
Les garde-fous de traitement incluent généralement :
Contrôles contextuels : Restreignez quels documents, champs ou journaux peuvent être fournis au modèle pour chaque requête.
Sécurité RAG : Limitez les collections qu’un pipeline de récupération peut interroger, le nombre de résultats qu’il peut utiliser, et appliquez un filtrage au contenu récupéré.
Application des politiques : Codez des règles métier telles que « ce modèle ne peut pas accéder aux API de paiement en production » ou « uniquement retourner les données de la même région ».
Contrôles d’identité et de moindre privilège : Utilisez les politiques IAM pour restreindre le compte de service du modèle dans l’accès à des sources ou services de données non autorisés.
Garde-corps d’outils et d’agents : Définissez quels outils un agent IA peut appeler, quelles actions nécessitent l’approbation humaine, et comment les paramètres sont validés avant exécution.
Les fonctionnalités de sécurité des fournisseurs cloud (par exemple, des filtres de contenu ou des filtres thématiques dans Azure OpenAI, Bedrock ou Vertex AI) peuvent prendre en charge cette couche, mais doivent être combinées avec
3. Glissières de sortie
Les garde-corps de sortie évaluent la réponse du modèle
Les garde-corps de sortie courants incluent :
Toxicité et sécurité du contenu : Détectez la haine, le harcèlement, le contenu d’automutilation ou d’autres catégories interdites.
Détection d’hallucinations : Comparez les affirmations avec des sources fiables ou des contextes récupérés pour identifier les affirmations non étayées.
Fuite de données sensibles : Scannez les informations personnelles, les informations personnelles, les identifiants ou les secrets dans les sorties et les retirez ou bloquez selon les besoins.
Alignement de la marque et des politiques : Ajustez le ton, incluez les divulgations requises et faites respecter les règles de conformité dans les domaines réglementés.
Les garde-fous de sortie peuvent bloquer la réponse, demander des clarifications, ou
De nombreuses équipes combinent des vérifications basées sur des règles (patrons d’acceptation/refus, règles de caviardage, politiques de prompt) avec des classificateurs basés sur le ML (détection de toxicité, détection de jailbreak, détection de renseignements personnels). D’autres enveloppent les modèles de fournisseurs d’une couche de sécurité cohérente entre les fournisseurs en utilisant des API de modération ou des frameworks de garde-forme open source.
100 Experts Weigh In on AI Security
Learn what leading teams are doing today to reduce AI threats tomorrow.

Risques liés à l’IA que les garde-fous sont conçus pour traiter
Il existe des garde-fous de l’IA pour prévenir certaines catégories de défaillances. Comprendre ces menaces vous aide à concevoir des contrôles qui protègent à la fois vos données et votre infrastructure.
La plupart des risques liés à l’IA relèvent de Quatre catégories:
1. Manipulation du comportement du modèle
Les attaquants tentent d’influencer ou de contourner les instructions du modèle pour produire des actions ou des sorties non sécurisées.
Injection rapide : Créer des entrées qui supplantent les instructions système et extraient des données ou déclenchent des actions interdites.
Injection indirecte par prompt : Intégrer des instructions malveillantes dans des documents ou des données que le modèle intègre ensuite via la récupération ou le contexte.
Évasions : Forçant le modèle à ignorer les contraintes de sécurité intégrées à l’aide de jeux de rôle, de traduction ou d’autres schémas de requêtes indirectes.
Prompts adversaires : Des motifs subtils de prompts conçus pour provoquer des sorties incorrectes sans paraître malveillantes.
Ces risques sont principalement abordés par
2. Manipulation des données et du contexte
Au lieu d’attaquer directement le modèle, les adversaires ciblent le Pipelines de données qui façonnent le comportement modèle.
Empoisonnement des données : Injecter des données malveillantes ou biaisées dans des ensembles d’entraînement ou d’ajustement fin afin que le modèle apprenne des motifs dangereux.
Empoisonnement contextuel : Manipuler les documents ou l’index de récupération utilisés par les systèmes RAG pour influencer les réponses.
Intoxication au chiffon : Contrôler quels documents sont récupérés afin que le modèle répète les informations trompeuses.
Détournement de détournement : Compromettre les ajustements finis pour insérer des portes dérobées.
Ces menaces nécessitent
3. Extraction d’informations sensibles et de propriété intellectuelle
Les attaquants tentent de récupérer des données du modèle ou de ses composants supportifs.
Extraction du modèle : Reproduire le comportement d’un modèle propriétaire à travers des requêtes répétées.
Inférence d’appartenance : Déterminer si des enregistrements spécifiques faisaient partie des données d’entraînement en sondant les réponses du modèle.
Fuite de données sensibles : Le modèle reproduit le contenu mémorisé à partir de journaux, de données d’entraînement ou de magasins vectoriels.
Ces risques sont atténués par
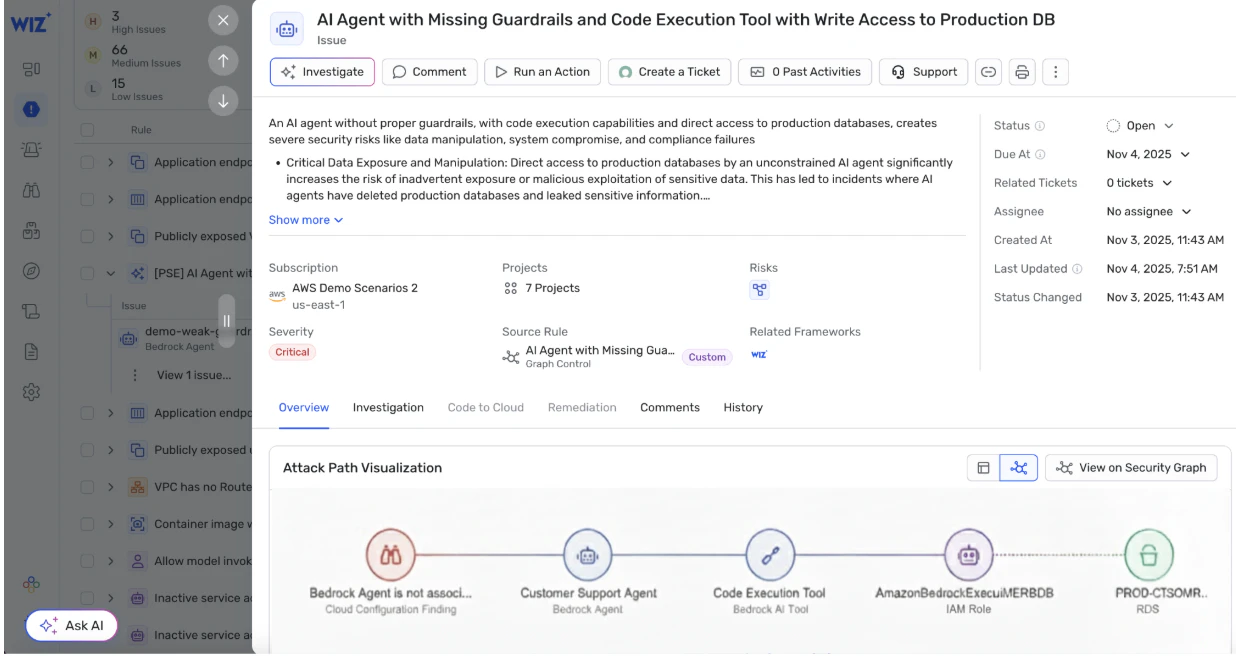
4. Exploitation de l’accès via des agents et des outils
La catégorie de risque à la croissance la plus rapide concerne des modèles qui peuvent
Agents surautorisés : Des agents ayant un large accès aux API internes, bases de données ou services cloud.
Abus d’outils : Utiliser des outils autorisés de manière inattendue, menant à des opérations non autorisées.
Escalade d’identité : Un modèle agissant sous un compte de service privilégié sans isolation appropriée.
Ces risques nécessitent
Sample AI Security Assessment
Get a glimpse into how Wiz surfaces AI risks with AI-BOM visibility, real-world findings from the Wiz Security Graph, and a first look at AI-specific Issues and threat detection rules.
Get Sample Report

Comment fonctionnent les garde-fous de l’IA en pratique
Dans un système réel, les garde-corps ne sont pas un filtre unique que l’on ajoute à la fin. Ce sont plusieurs contrôles appliqués sur le chemin de la requête, du point d’entrée de l’API à la validation de la sortie. Chaque couche élimine une classe de risque différente.
Un courant Flux d’inférence avec glissières de sécurité Ressemble à ceci :
Demande utilisateur : Un utilisateur envoie une invite ou un appel API.
Garde-corps d’entrée : La demande est validée, aseptisée ou rejetée avant d’atteindre le modèle.
Construction du contexte (RAG) : Si la récupération est utilisée, seules les sources de données et documents approuvés sont récupérés et filtrés.
Application des politiques : Les règles métier et les contrôles de sécurité déterminent ce que le modèle peut accéder et quels outils il peut utiliser.
Inférence du modèle : Le modèle génère une réponse dans le cadre de ces contraintes.
Exécution de l’outil (agents) : Si le modèle demande des actions, les paramètres sont validés et exécutés sous le moindre privilège, ou nécessitent une approbation humaine.
Rampes de sécurité de sortie : La réponse est vérifiée pour la sécurité, les réclamations étayées, les données sensibles et la conformité avant de la restituer à l’utilisateur.
Journalisation et suivi : L’interaction complète est enregistrée pour analyse, alerte et amélioration.
Ce schéma vous permet de prévenir les comportements dangereux avant qu’ils ne surviennent, et de détecter les problèmes qui passent inaperçus.
Où les garde-corps sont appliqués
Les garde-fous peuvent être intégrés à plusieurs points de votre architecture :
Passerelle API : Authentification, limitation de vitesse, vérifications de contenu grossier.
Couche d’orchestration : Chaînes, middlewares et validateurs qui implémentent des filtres d’invites, des contrôles de contexte et de la logique de politique.
Services cloud : Filtres de sécurité du fournisseur (par exemple, filtres de toxicité ou de sujet) qui s’exécutent lors de l’inférence.
Couche identité : Des politiques IAM qui définissent les sources de données, API et outils auxquels le compte de service du modèle peut accéder.
Limites des outils : Flux de validation et d’approbation pour les actions de l’agent.
Stockage vectoriel : Contrôles d’accès et filtrage au niveau des documents pour éviter l’empoisonnement contextuel ou la fuite de données.
Filtres de sortie : Des modèles ou règles de classification qui bloquent ou réécrivent des réponses non sûres.
Chaque couche est conçue pour éliminer une catégorie de risque différente, de sorte que les défaillances d’une couche sont captées par une autre.
Comment Wiz permet des garde-fous complets en IA tout au long du cycle de vie de la sécurité
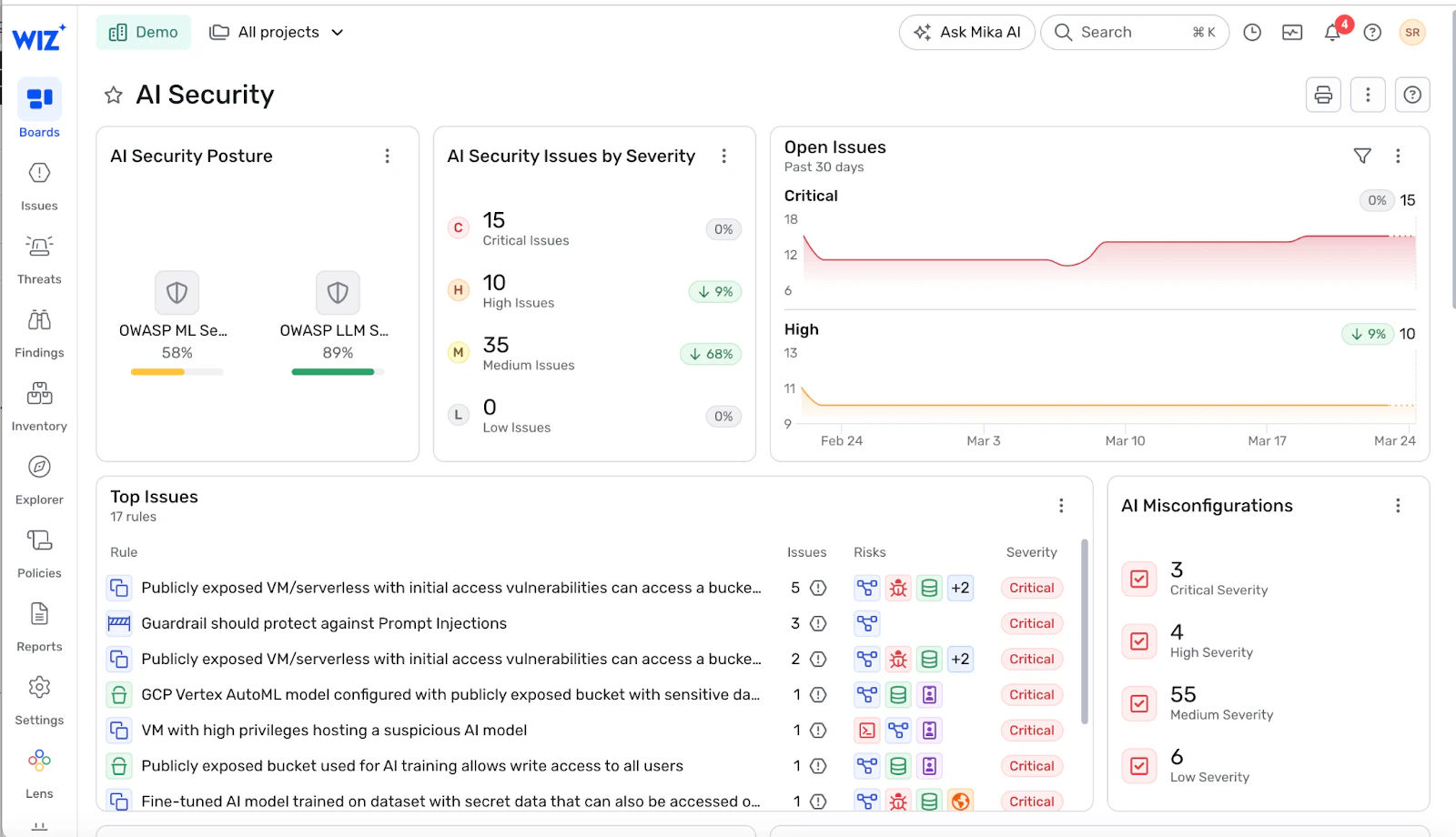
Wiz AI-SPM vous offre une visibilité de bout en bout sur votre patrimoine IA via AWS, Azure et GCP – des services d’IA gérés et des terminaux d’inférence aux pipelines de récupération et aux identités qui les sous-tendent. Wiz détecte des erreurs de configuration sur des plateformes comme Amazon SageMaker, Azure OpenAI et Google Vertex AI qui peuvent contourner vos limites, comme les points publics ayant accès à des données sensibles ou les agents fonctionnant sous des rôles surautorisés.
Le Graphe de sécurité Wiz cartographie la façon dont l’infrastructure, les identités, les données et les charges de travail de l’IA interagissent. Cela vous permet de repérer des combinaisons toxiques cachées dans l’environnement – par exemple, un point de terminaison exposé communiquant avec un magasin vectoriel rempli de données d’entraînement sensibles, accessible via un compte de service large rattaché à un agent. Wiz met en avant ces risques afin que vous puissiez supprimer les voies de contournement qui se trouvent sous vos garde-corps.
Wiz étend ces contrôles tout au long du cycle de développement et d’exécution. Wiz Code scanne l’IaC et le code applicatif définissant votre infrastructure IA pour détecter des problèmes tels que des clés de modèle codées en dur, des règles réseau risquées ou des services d’IA mal configurés avant le déploiement. Wiz Defend surveille les charges de travail liées à l’IA à l’exécution pour détecter des schémas d’API inhabituels, des accès non autorisés aux données ou des tentatives d’exfiltration potentielles liées au comportement du modèle. Intégré DSPM Les capacités classifient les données sensibles utilisées lors de l’entraînement ou de l’inférence et montrent comment elles s’intègrent dans les modèles et les points d’extrémité, afin de pouvoir construire des garde-fous axés sur les données ancrés dans la réalité.
Parce que tout ce contexte se trouve sur une seule plateforme, les organisations peuvent appliquer des politiques de sécurité IA unifiées à travers les dépôts de code, les pipelines CI/CD, les ressources cloud et les environnements d’exécution. En d’autres termes, Wiz fournit des garde-corps pour vos garde-corps – Veiller à ce que l’infrastructure, les chemins de données et les identités autour de vos modèles soient correctement configurés, surveillés et protégés.
Develop AI applications securely
Learn why CISOs at the fastest growing organizations choose Wiz to secure their organization's AI infrastructure.
