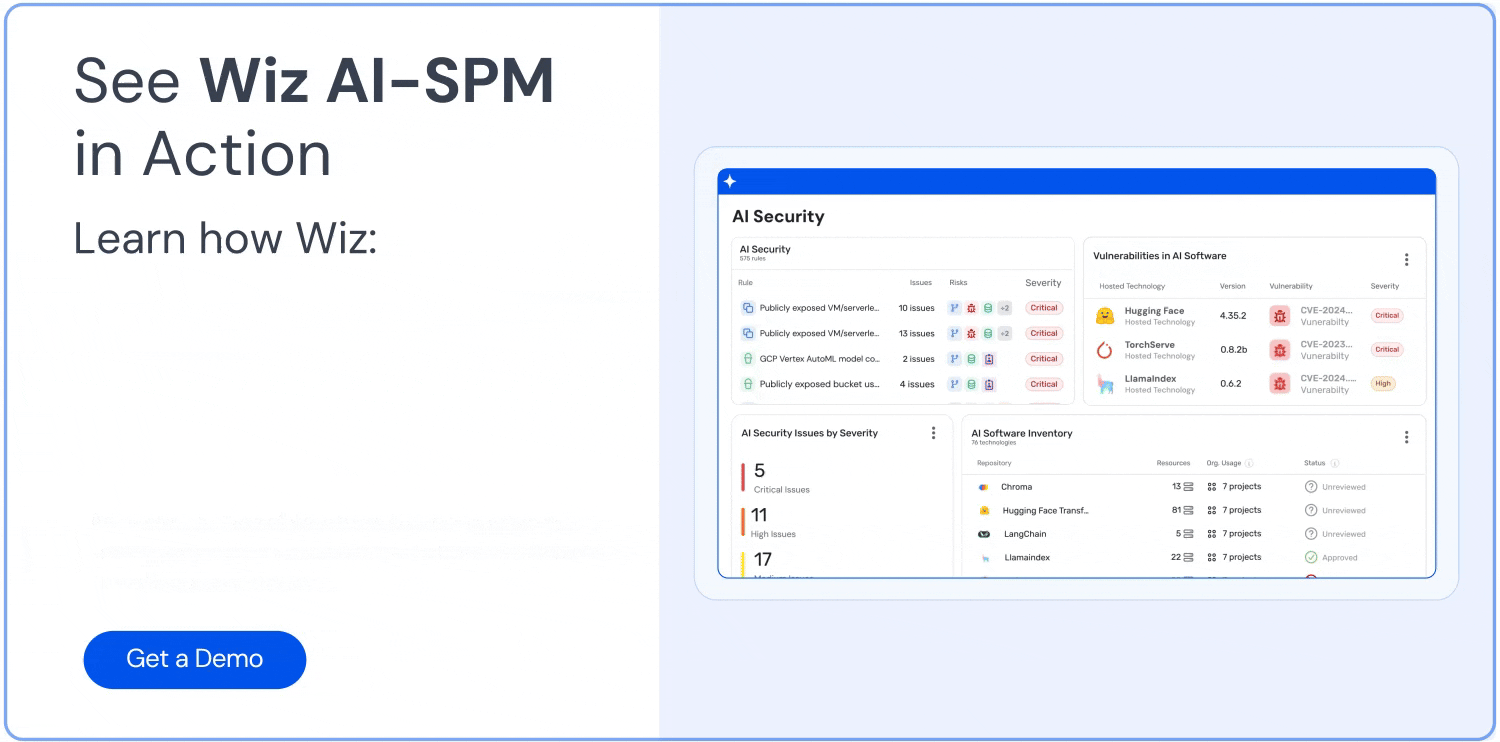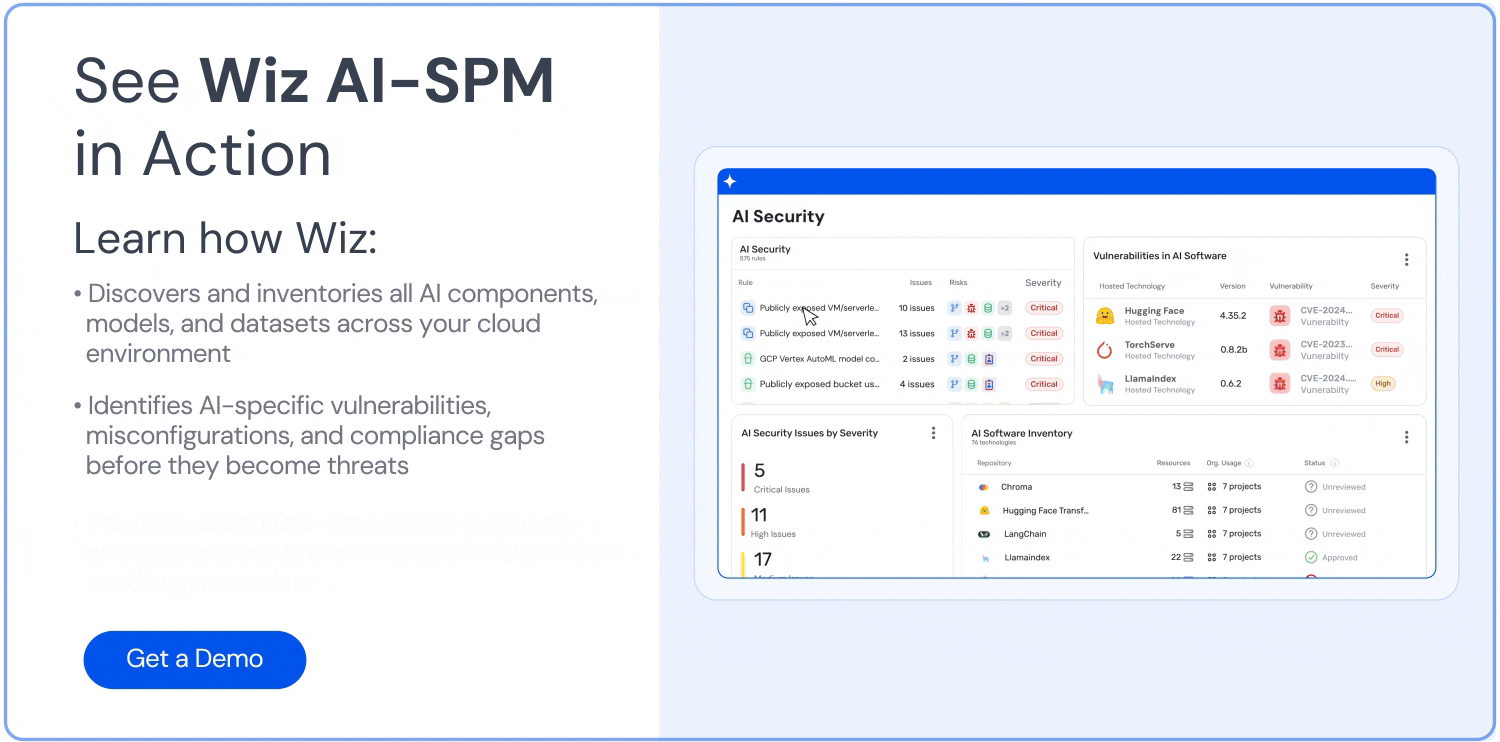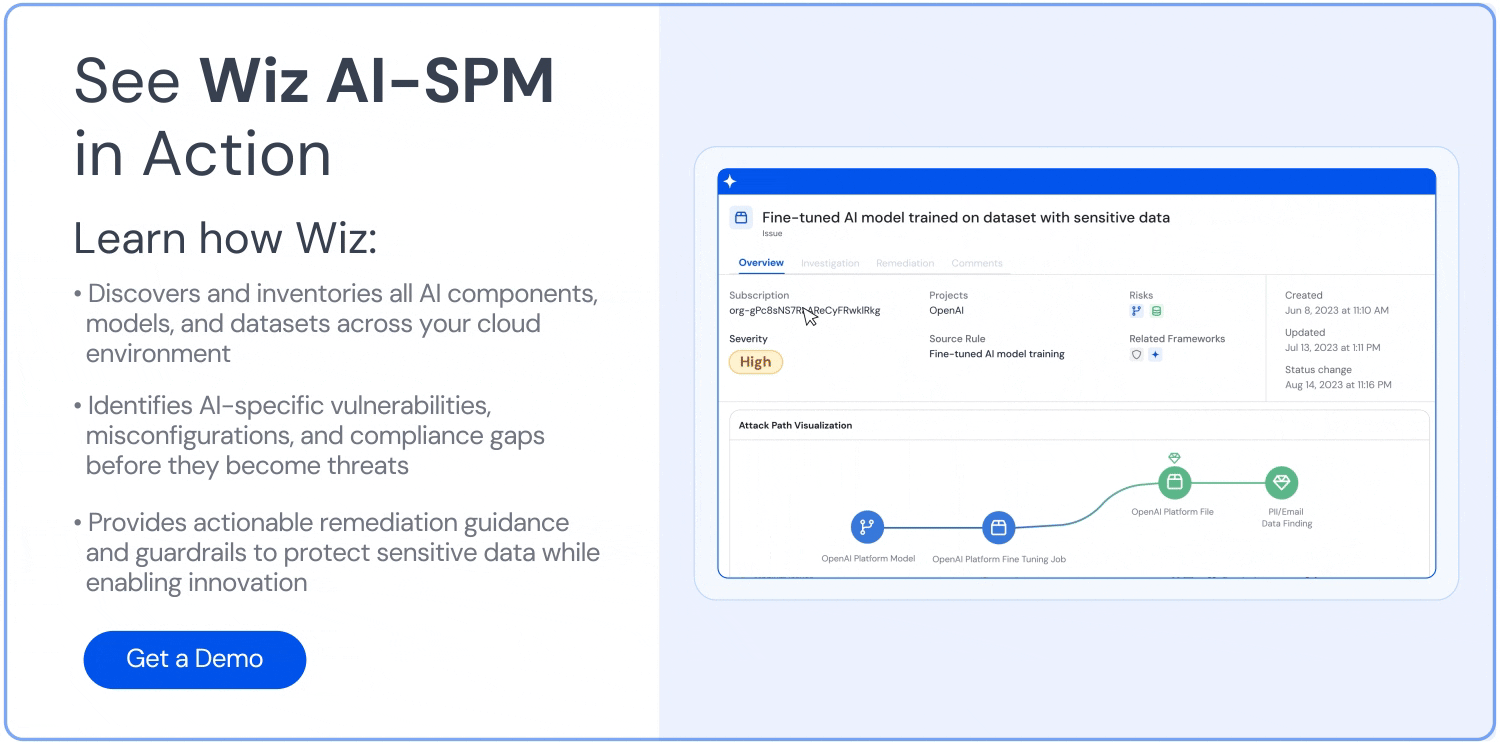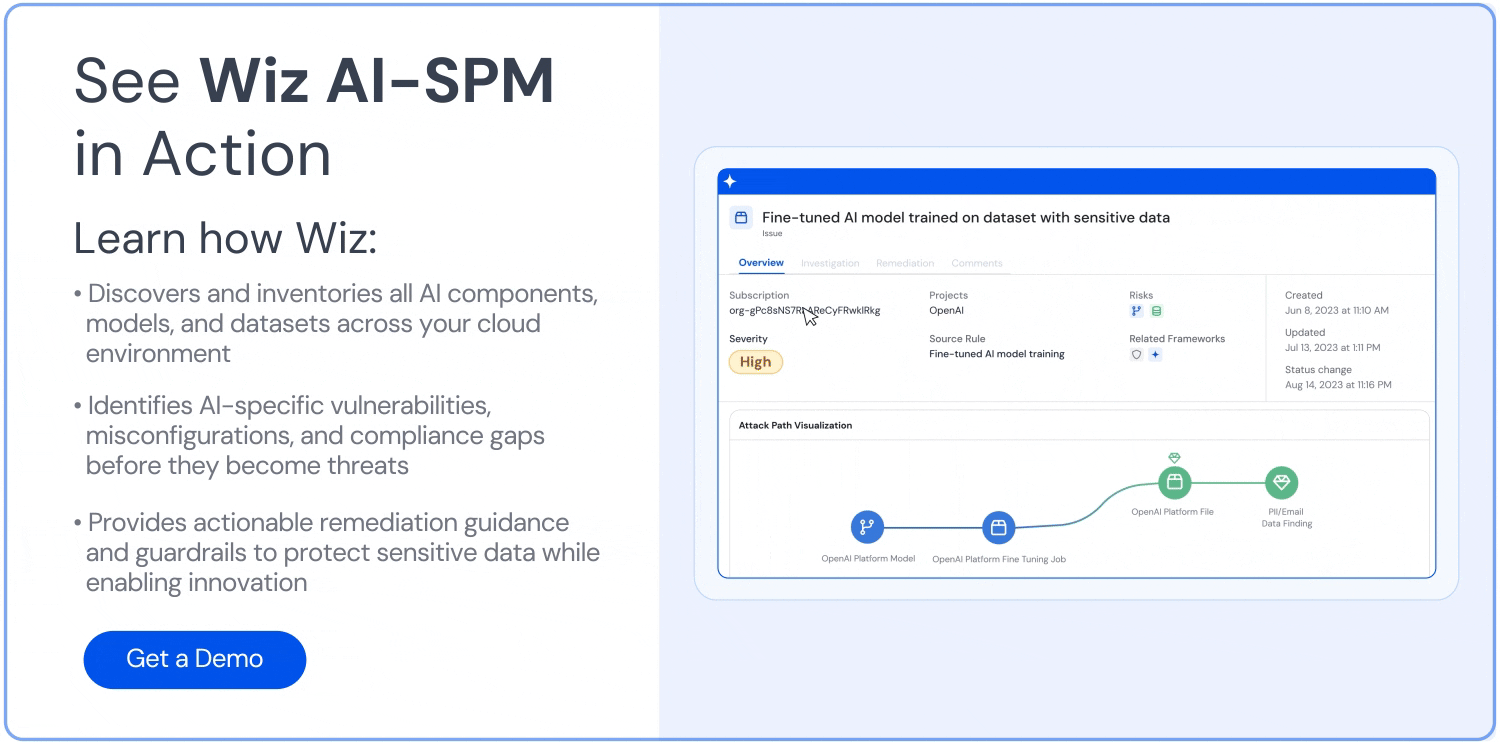
La sécurité des LLM protège les large language models contre les cybermenaces, les violations de données et les attaques malveillantes tout au long de leur cycle de vie. En effet, cette discipline combine les pratiques de cybersécurité traditionnelles avec des protections spécifiques à l'IA pour traiter des vulnérabilités uniques. Ainsi, le NIST AI Risk Management Framework indique que les préoccupations récurrentes portent sur les exemples adversariaux, l'empoisonnement des données et l'exfiltration de modèles ou de données d'entraînement — souvent désignés sous les termes de vol de modèle et d'empoisonnement des données. Pour les entreprises qui déploient des LLM à grande échelle, la mise en place de mesures de sécurité complètes permet d'obtenir des avantages compétitifs sans compromettre des données sensibles ni les opérations.
Les modèles LLM, comme GPT et d'autres modèles de fondation, exposent des risques significatifs s'ils ne sont pas correctement sécurisés. De la prompt injection à l'empoisonnement des données d'entraînement, les vulnérabilités potentielles sont nombreuses et étendues.
Cela dit, il est possible de tirer le meilleur parti des LLM sans sacrifier la sécurité. Dans cet article, nous présentons les principaux risques liés aux LLM, les bonnes pratiques pour sécuriser leur déploiement, et comment des outils comme AI‑SPM peuvent aider à gérer la sécurité de l'IA à grande échelle.
Bonnes pratiques de sécurité des LLM
Cette checklist de 7 pages propose des étapes concrètes et directement applicables pour sécuriser les LLM tout au long de leur cycle de vie, en lien avec des menaces réelles.

Principaux risques pour les applications LLM en entreprise
Les défis de la sécurité des LLM découlent de la nature même des systèmes d'IA qui traitent de vastes volumes de données provenant de sources diverses, souvent inconnues. Contrairement aux applications traditionnelles, les LLM interagissent de manière dynamique avec les utilisateurs et des systèmes externes, élargissant considérablement la surface d'attaque potentielle.
En outre, le rythme soutenu de l'innovation en IA fait apparaître des vulnérabilités plus vite que ne s'adaptent les cadres de sécurité classiques. Ainsi, les attaquants développent en continu de nouvelles techniques comme la prompt injection et l'extraction de modèles, tandis que les équipes de sécurité manquent souvent d'expertise spécifique à l'IA. Il en résulte une course permanente entre acteurs malveillants et défenseurs, dans un paysage en évolution constante où les mesures de sécurité traditionnelles sont souvent insuffisantes.
OWASP Top 10 for LLM Applications constitue le cadre de référence du secteur pour comprendre et atténuer les risques de sécurité liés à l'IA. En effet, élaboré par une communauté mondiale de plus de 600 experts contributeurs, ce cadre identifie les vulnérabilités les plus critiques qui menacent les déploiements LLM en entreprise.
Ces risques correspondent à des vecteurs d'attaque concrets rencontrés au quotidien par les équipes de sécurité. Ainsi, comprendre chaque menace aide les organisations à prioriser leurs investissements et à construire des stratégies de défense globales adaptées aux vulnérabilités propres à l'IA.
1. Prompt injection
La prompt injection survient lorsque des attaquants conçoivent des entrées malveillantes visant à contourner les consignes de sécurité ou le comportement attendu d'un LLM. Ainsi, ces attaques amènent le modèle à ignorer sa programmation initiale, pouvant entraîner la fuite d'informations sensibles, l'exécution d'actions non autorisées ou la génération de contenus nuisibles.
Pour les entreprises, la prompt injection peut contourner les security controls intégrés aux applications LLM. Par exemple, des attaquants peuvent piéger un chatbot de service client pour qu'il divulgue des données confidentielles, ou pousser un assistant IA à fournir des instructions illégales, entraînant des violations de conformité et des dommages réputationnels.
Exemple : un attaquant injecte un prompt qui outrepasse la logique de sécurité d'un chatbot, conduisant à des fuites de données ou à des actions non autorisées.
Sécurité IA générative [Aide-mémoire]
Découvrez les 7 stratégies essentielles pour sécuriser vos applications d’IA générative grâce à notre fiche pratique complète dédiée aux meilleures pratiques de sécurité.

2. Empoisonnement des données d'entraînement
La qualité et la fiabilité des données d'entraînement sont fondamentales pour la sécurité des LLM. En effet, si des attaquants parviennent à insérer des données malveillantes dans les datasets d'entraînement, c'est l'ensemble du modèle qui peut être compromis, avec à la clé des performances dégradées et une fiabilité remise en question.
Exemple : un moteur de recommandation entraîné sur des données empoisonnées peut se mettre à promouvoir des produits nuisibles ou contraires à l'éthique, sapant l'intégrité du service et la confiance des utilisateurs.


3. Vol de modèle
L'avantage compétitif de nombreuses entreprises réside dans les modèles propriétaires qu'elles conçoivent ou affinent. Si des adversaires volent ces modèles, l'entreprise risque de perdre de la propriété intellectuelle et, au pire, de subir un désavantage concurrentiel important.
Exemple : un cybercriminel exploite une vulnérabilité dans votre service cloud pour dérober votre modèle de fondation, puis s'en sert pour créer une application IA contrefaite qui nuit directement à votre activité.
4. Outputs non sécurisés
Les LLM génèrent des outputs textuels susceptibles d'exposer des informations sensibles ou de permettre des exploits de sécurité comme le cross‑site scripting (XSS) ou même l'exécution de code à distance.
Exemple : un LLM intégré à une plateforme de support peut, à partir d'entrées malveillantes formulées de manière crédible, produire des réponses contenant des scripts malveillants ensuite transmis à une application web, permettant à un attaquant d'exploiter ce système.
5. Attaques adversariales
Les attaques adversariales consistent à piéger un LLM via des entrées spécialement conçues pour le faire réagir de manière inattendue. Ainsi, elles peuvent compromettre la prise de décision et l'intégrité du système, avec des conséquences imprévisibles sur des applications critiques.
Exemple : des entrées manipulées amènent un modèle de détection de fraude à classer à tort des transactions frauduleuses comme légitimes, entraînant des pertes financières directes.


6. Violations de conformité
Qu'il s'agisse du RGPD ou d'autres normes de confidentialité, les violations peuvent avoir d'importantes conséquences juridiques et financières. Ainsi, s'assurer que les outputs des LLM ne contreviennent pas aux lois de protection des données est un enjeu de sécurité critique.
Exemple : un LLM qui génère des réponses sans garde‑fous adéquats peut divulguer des informations personnelles identifiables (PII) telles que des adresses ou des numéros de carte bancaire — et ce, à grande échelle.
7. Vulnérabilités de la chaîne d'approvisionnement
Les applications LLM s'appuient souvent sur un enchevêtrement complexe de modèles tiers, de bibliothèques open source et de composants pré‑entraînés. Or, une vulnérabilité dans n'importe quelle partie de cette chaîne d'approvisionnement peut introduire un risque significatif, permettant à des attaquants d'injecter du code malveillant ou de compromettre l'intégrité de l'ensemble du système.
Exemple : un attaquant publie une version compromise d'une bibliothèque de machine learning populaire, incluant une porte dérobée qui lui donne accès à tout modèle qui l'utilise.
Wiz AI‑SPM étend la visibilité de la chaîne d'approvisionnement aux modèles d'IA et à leurs dépendances, en identifiant les risques au sein des frameworks tiers et des datasets d'entraînement. En effet, en cartographiant l'ensemble du pipeline IA, Wiz vous aide à comprendre votre exposition aux vulnérabilités des composants dont vous dépendez.
8. Divulgation d'informations sensibles
Les LLM peuvent faire fuiter des données sensibles — informations personnelles identifiables (PII), propriété intellectuelle ou informations d'affaires confidentielles — dans leurs réponses. Cela peut se produire si le modèle a été entraîné sur des données sensibles sans assainissement adéquat, ou s'il est incité à révéler des informations auxquelles il a accès.
Exemple : un chatbot de service client peut être amené à révéler les détails de compte ou l'historique de commandes d'un autre utilisateur, provoquant une grave atteinte à la vie privée et une violation de conformité.
Au‑delà de ces risques intrinsèques aux LLM, des menaces classiques comme les attaques par déni de service, des plugins non sécurisés et l'ingénierie sociale demeurent des défis majeurs. Ainsi, les traiter impose une stratégie de sécurité globale et tournée vers l'avenir pour toute entreprise déployant des LLM.
State of AI in the Cloud [2025]
LLM security is a top priority, but understanding the broader AI security landscape is key. Wiz’s State of AI Security Report 2025 provides insights into how organizations are securing LLMs and other AI models in the cloud.

Bonnes pratiques pour sécuriser les déploiements LLM
Sécuriser des déploiements LLM ne consiste pas à colmater les vulnérabilités au fil de l'eau : cela exige un effort structuré à l'échelle de l'organisation. En effet, la sécurité des LLM doit s'inscrire dans une stratégie de gestion des risques IA plus large, intégrée aux cadres de sécurité existants de l'entreprise.
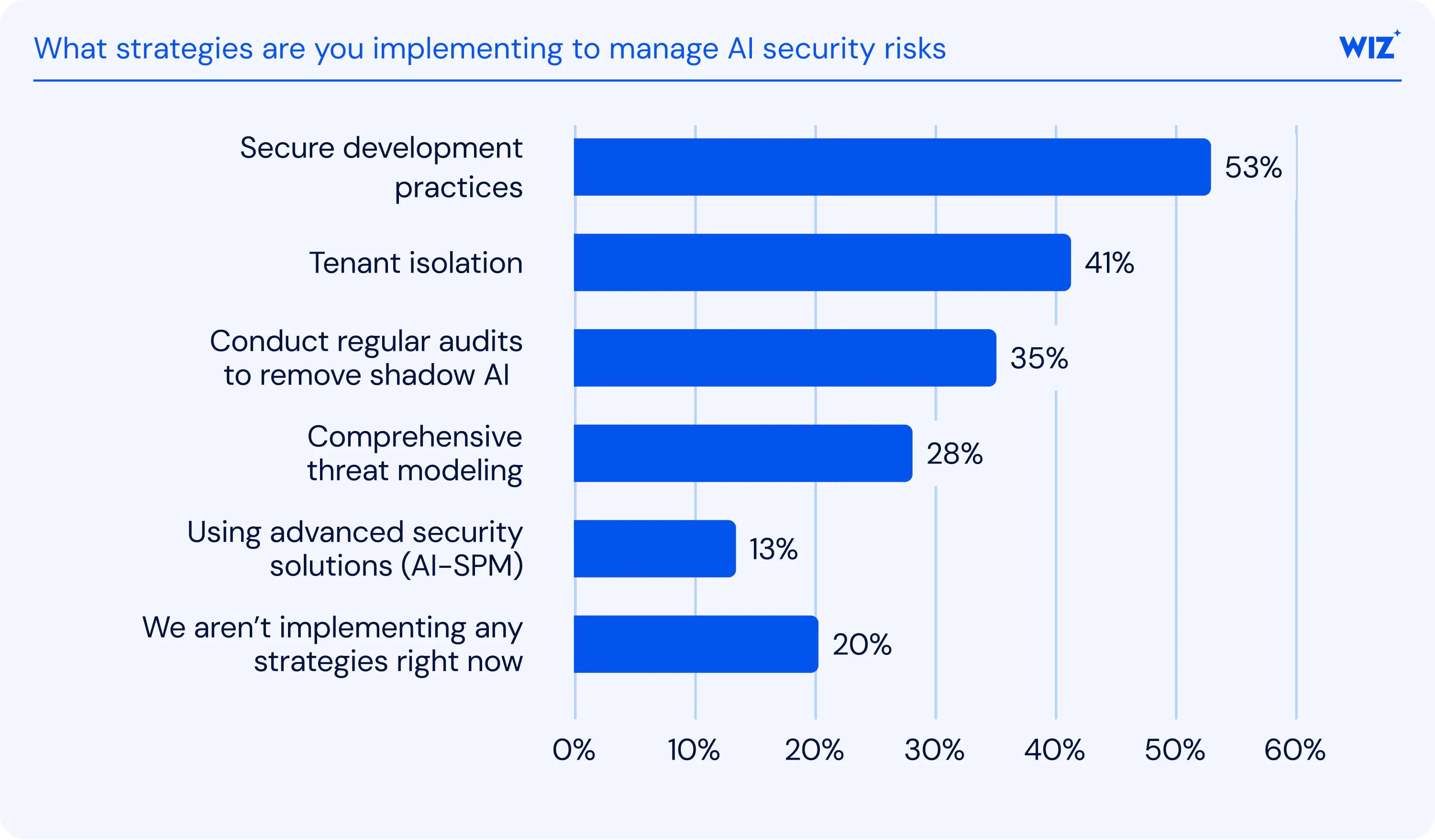
MITRE ATLAS fait office de base de connaissances de référence pour comprendre les tactiques adversariales visant les systèmes de machine learning. En effet, développé par MITRE Corporation, ce cadre met en correspondance des techniques d'attaque IA réelles avec des contre‑mesures spécifiques. Ainsi, il documente plus de 130 techniques, 26 mesures d'atténuation et de nombreuses études de cas, fournissant aux équipes sécurité des stratégies de défense actionnables.
Entraînement et ajustement adversarial
Exposer les LLM à des exemples adversariaux durant l'entraînement ou l'ajustement améliore leur capacité à résister aux entrées malveillantes et renforce leur robustesse face aux inputs inattendus.
Actions concrètes
Mettez régulièrement à jour les datasets d'entraînement avec des exemples adversariaux pour rester protégé face aux nouvelles menaces.
Déployez des systèmes automatisés de détection d'attaques adversariales pendant l'entraînement pour signaler et gérer en temps réel les entrées nuisibles.
Testez le modèle contre des stratégies d'attaque inédites afin que ses défenses évoluent au rythme des techniques émergentes.
Utilisez le transfer learning pour affiner des modèles avec des datasets robustes aux attaques adversariales, afin de mieux généraliser en environnement hostile.
Adversarial Robustness Toolbox (ART) et CleverHans sont deux projets open source intéressants pour bâtir des défenses contre les attaques adversariales.
Évaluation des modèles
Effectuer une évaluation approfondie de votre LLM dans un large éventail de scénarios est le meilleur moyen de détecter des vulnérabilités potentielles et de traiter les risques de sécurité avant le déploiement.
Actions concrètes
Menez des exercices de red team (où des experts sécurité tentent activement de compromettre le modèle) pour simuler des attaques réelles.
Soumettez le LLM à des tests d'effort en environnement opérationnel, y compris des cas limites et des scénarios à haut risque, pour observer son comportement réel.
Évaluez la réaction du LLM à des entrées anormales ou limites, afin d'identifier les angles morts de ses mécanismes de réponse.
Faites du benchmarking face à des attaques adversariales standard pour comparer la résilience de votre LLM à celle de ses pairs.
Validation et assainissement des entrées
Valider et assainir toutes les entrées réduit le risque de prompt injection et d'alimentation du modèle avec des données nuisibles.
Actions concrètes
Appliquez des mécanismes stricts de validation des entrées afin de filtrer les inputs manipulés ou dangereux avant qu'ils n'atteignent le modèle.
Mettez en place des listes d'autorisation (allowlists) et des listes de blocage (blocklists) pour contrôler finement les types d'entrées que le modèle est autorisé à traiter.
Déployez une surveillance dynamique des entrées afin de détecter des schémas anormaux pouvant signaler une attaque en cours.
Utilisez des techniques de fuzzing des entrées pour tester automatiquement la réaction du modèle à des inputs inhabituels ou inattendus.


Modération et filtrage des contenus
Les outputs des LLM doivent être filtrés pour éviter la génération de contenus nuisibles ou inappropriés et garantir le respect des standards éthiques et des valeurs de l'entreprise.
Actions concrètes
Intégrez des outils de modération capables d'analyser et de bloquer automatiquement des outputs dangereux ou inappropriés.
Définissez des règles éthiques claires et intégrez‑les dans la logique décisionnelle du LLM pour que les outputs soient alignés sur les standards de votre organisation.
Auditez régulièrement les outputs générés pour confirmer qu'ils ne sont pas nuisibles, biaisés ou contraires aux exigences de conformité.
Mettez en place une boucle de feedback permettant aux utilisateurs de signaler des outputs problématiques, afin d'améliorer en continu les politiques de modération.
Intégrité et provenance des données
Garantir l'intégrité et la fiabilité des données utilisées à l'entraînement comme en entrée temps réel est déterminant pour prévenir l'empoisonnement des données et préserver la confiance des clients.
Actions concrètes
Vérifiez la source de toutes les données d'entraînement afin de vous assurer qu'elles n'ont pas été altérées ou manipulées.
Utilisez des outils de provenance des données pour suivre l'origine et les modifications des sources, favorisant transparence et responsabilité.
Recourez au hachage cryptographique ou au filigranage des datasets d'entraînement pour garantir leur intégrité tout au long du cycle de vie du modèle.
Mettez en œuvre une surveillance temps réel de l'intégrité des données pour alerter sur toute modification suspecte des flux ou des accès pendant l'entraînement.
Contrôle d'accès et authentification
Des mesures strictes de contrôle d'accès permettent d'empêcher les accès non autorisés et le vol de modèles, en veillant à ce que chacun n'accède qu'aux ressources pour lesquelles il dispose des droits.
Actions concrètes
Limitez l'accès aux ressources en fonction des rôles afin que seules les personnes autorisées interagissent avec les composants sensibles du LLM.
Implémentez l'authentification multifacteur (MFA) pour l'accès au modèle et à ses API, ajoutant une couche de sécurité supplémentaire.
Auditez et journalisez toutes les tentatives d'accès, en suivant les schémas d'accès et en détectant les anomalies ou activités non autorisées.
Chiffrez à la fois les données du modèle et ses outputs pour éviter les fuites lors de la transmission ou de l'inférence.
Utilisez des jetons d'accès assortis de politiques d'expiration pour les intégrations externes, afin de limiter tout accès non autorisé prolongé.
Déploiement sécurisé des modèles
Un déploiement maîtrisé des LLM réduit significativement des risques comme l'exécution de code à distance et garantit l'intégrité et la confidentialité du modèle et des données.
Actions concrètes
Isolez l'environnement du LLM via de la conteneurisation ou du sandboxing pour limiter ses interactions avec des systèmes critiques.
Appliquez régulièrement des correctifs au modèle et à l'infrastructure sous‑jacente pour traiter rapidement les vulnérabilités émergentes.
Réalisez des tests d'intrusion réguliers sur le modèle déployé afin d'identifier et d'atténuer d'éventuelles faiblesses de posture de sécurité.
Exploitez des outils de sécurité runtime qui surveillent le comportement du modèle en production et signalent des anomalies indicatrices d'une exploitation active.
Si ces bonnes pratiques ciblent la prévention, il est tout aussi essentiel de maintenir un plan de réponse aux incidents solide pour traiter les problèmes de sécurité au fil de l'eau. Ainsi, des audits et évaluations réguliers maintiendront une stratégie proactive, garantissant la conformité et l'atténuation des risques avant qu'ils ne prennent de l'ampleur.
Wiz Research Finds Critical NVIDIA AI Vulnerability Affecting Containers Using NVIDIA GPUs, Including Over 35% of Cloud Environments
En savoir plus

Protéger vos applications LLM en entreprise avec Wiz AI‑SPM
AI Security Posture Management (AI‑SPM) fournit une visibilité continue et une évaluation des risques pour les déploiements IA en entreprise, y compris les LLM, les données d'entraînement et les pipelines d'inférence. En effet, cette approche étend la gestion de posture de sécurité traditionnelle pour adresser des vulnérabilités spécifiques à l'IA que les outils génériques ne détectent pas, car certaines manipulations peuvent être difficiles à déceler via des évaluations de performance généralistes.
Wiz AI‑SPM répond au défi singulier de sécuriser des systèmes IA dynamiques qui traitent des données sensibles et interagissent avec des systèmes externes. Ainsi, la plateforme apporte trois capacités essentielles qui transforment la manière dont les entreprises protègent leurs investissements LLM.
Visibilité via des AI‑BOM : Wiz AI‑SPM offre une vision complète de votre pipeline LLM, en produisant une bill of materials (BOM) de tous les actifs IA utilisés. Cette visibilité aide à identifier les vulnérabilités et risques potentiels associés à des déploiements LLM spécifiques.
Évaluation des risques : en analysant en continu les pipelines LLM, Wiz AI‑SPM évalue des risques comme les attaques adversariales, le vol de modèle ou l'empoisonnement des données d'entraînement. Ainsi, la plateforme signale les problèmes pouvant compromettre la sécurité et les priorise correctement pour rendre les organisations conscientes de leur exposition réelle.
Atténuation proactive : Wiz ne se contente pas de signaler les risques ; la plateforme fournit des recommandations contextuelles pour les réduire efficacement. Par exemple, si une prompt injection est détectée, elle propose des pistes concrètes pour renforcer la validation des entrées et durcir la sécurité du modèle contre de futures attaques.
Des risques IA concrets impliquent souvent des vulnérabilités d'infrastructure en apparence indépendantes, qui ouvrent en réalité des accès vers les systèmes IA. Scénario courant : une équipe de développement déploie un conteneur d'application web contenant des identifiants d'API codés en dur pour les services LLM de votre organisation.
Ce conteneur exposé devient une porte dérobée vers votre infrastructure IA. Ainsi, des attaquants qui découvrent ces identifiants peuvent manipuler vos LLM, extraire des données d'entraînement ou utiliser vos ressources IA à des fins malveillantes. Les outils de sécurité traditionnels détecteront peut‑être la vulnérabilité du conteneur mais ignoreront le risque spécifique qu'elle crée pour l'IA.
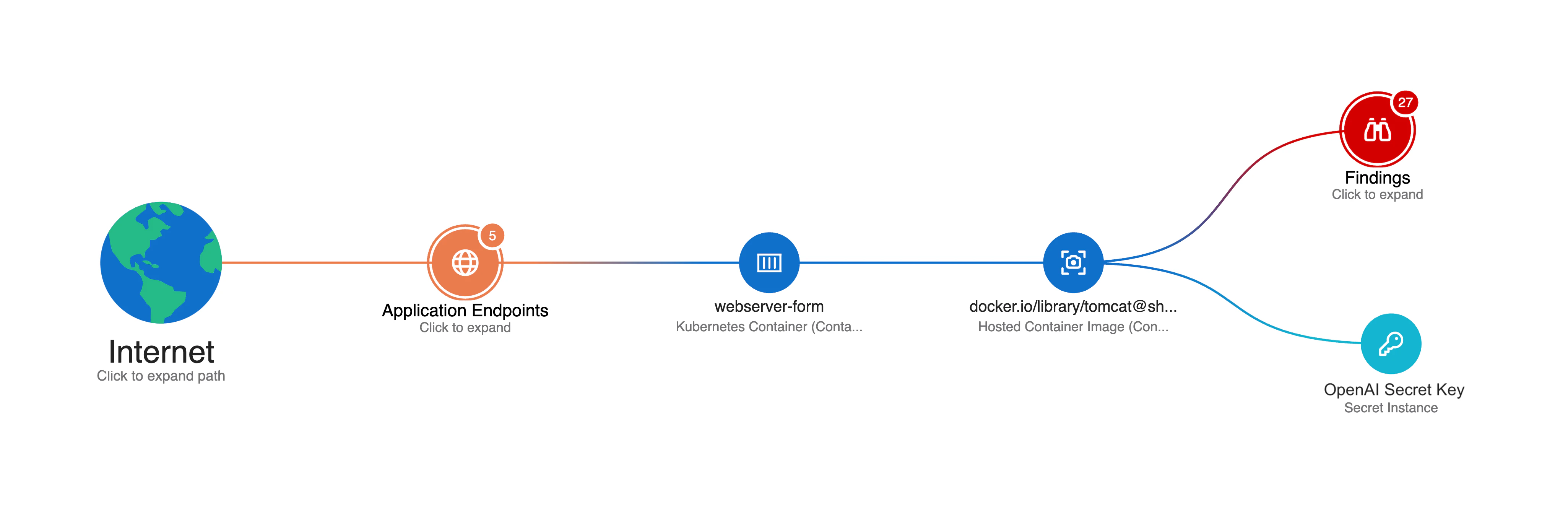
Lorsqu'il vous alerte sur une clé d'API exposée, Wiz propose à la fois des actions immédiates (p. ex. rotation de la clé d'API) et des stratégies d'atténuation à long terme (p. ex. verrouillage de l'endpoint exposé) pour sécuriser votre déploiement — protégeant ainsi votre environnement LLM contre les violations potentielles et les interruptions de service.
Prochaines étapes
La sécurité des LLM est un volet complexe mais essentiel de la gestion des risques en entreprise. En effet, en comprenant les principaux risques — comme la prompt injection, le vol de modèle et les attaques adversariales — et en appliquant les bonnes pratiques — telles que l'entraînement adversarial, la validation des entrées et le déploiement sécurisé des modèles — vous pouvez sécuriser durablement vos investissements en IA générative (GenAI).
Wiz AI‑SPM accélère cette démarche en fournissant aux organisations les moyens de surveiller, d'évaluer et d'atténuer les risques de sécurité liés aux LLM. En outre, Wiz propose également un connecteur OpenAI direct pour une sécurité ChatGPT prête à l'emploi.
Pour en savoir plus sur la manière dont Wiz peut renforcer votre sécurité IA, rendez‑vous sur Wiz for AI ou planifiez une démo en direct.