

Les modèles d’IA malveillants sont Artefacts de modèles intentionnellement militarisés qui exécutent des actions nuisibles lorsqu’elles sont chargées ou en cours. Contrairement aux modèles vulnérables – qui contiennent des défauts accidentels – les modèles malveillants sont conçus pour compromettre l’environnement dans lequel ils sont déployés.
La caractéristique définissante des modèles d’IA malveillante est que la menace est intégrée À l’intérieur du fichier modèle lui-même. Dans de nombreux cas, les attaquants abusent de formats de sérialisation dangereux pour masquer du code exécutable dans les poids des modèles ou la logique de chargement. Lorsque le modèle est importé ou désérialisé, ce code s’exécute automatiquement – souvent avant toute inférence.
Cela fait des modèles d’IA malveillants une menace distincte dans la chaîne d’approvisionnement. Ils exploitent la confiance que les organisations placent dans des modèles pré-entraînés téléchargés depuis des dépôts publics ou partagés en interne entre équipes. Comme les artefacts du modèle ne sont pas traités comme le code source traditionnel, ils contournent fréquemment les contrôles de sécurité tels que la revue de code, l’analyse statique et l’analyse des dépendances.
À mesure que l’adoption de l’IA s’accélère, les modèles pré-entraînés sont devenus une pierre angulaire du développement moderne. Cette même commodité a transformé les artefacts du modèle en un vecteur d’attaque à forte valeur – un vecteur que les outils de sécurité applicatifs traditionnels n’ont jamais été conçus pour inspecter.
25 AI Agents. 257 Real Attacks. Who Wins?
From zero-day discovery to cloud privilege escalation, we tested 25 agent-model combinations on 257 real-world offensive security challenges. The results might surprise you 👀

Pourquoi les modèles d’IA malveillants représentent un véritable risque dans la chaîne d’approvisionnement
Les modèles d’IA malveillants émergent des mêmes forces qui ont transformé le développement logiciel moderne : la réutilisation, l’automatisation et la confiance dans les composants externes. Les modèles pré-entraînés sont régulièrement retirés des dépôts publics pour accélérer le développement, réduire les coûts et éviter une rééducation à partir de zéro. Dans de nombreuses organisations, télécharger et déployer des modèles est devenu aussi courant que l’installation d’une bibliothèque.
Ce flux de travail déplace la confiance du code examiné en interne vers des artefacts externes rarement inspectés. Les fichiers modèles sont souvent traités comme des binaires opaques – stockés, partagés et chargés sans la surveillance appliquée au code applicatif ou aux images conteneurs. En conséquence, ils contournent fréquemment les contrôles de sécurité établis tels que la revue de code, l’analyse statique et le scan des dépendances.
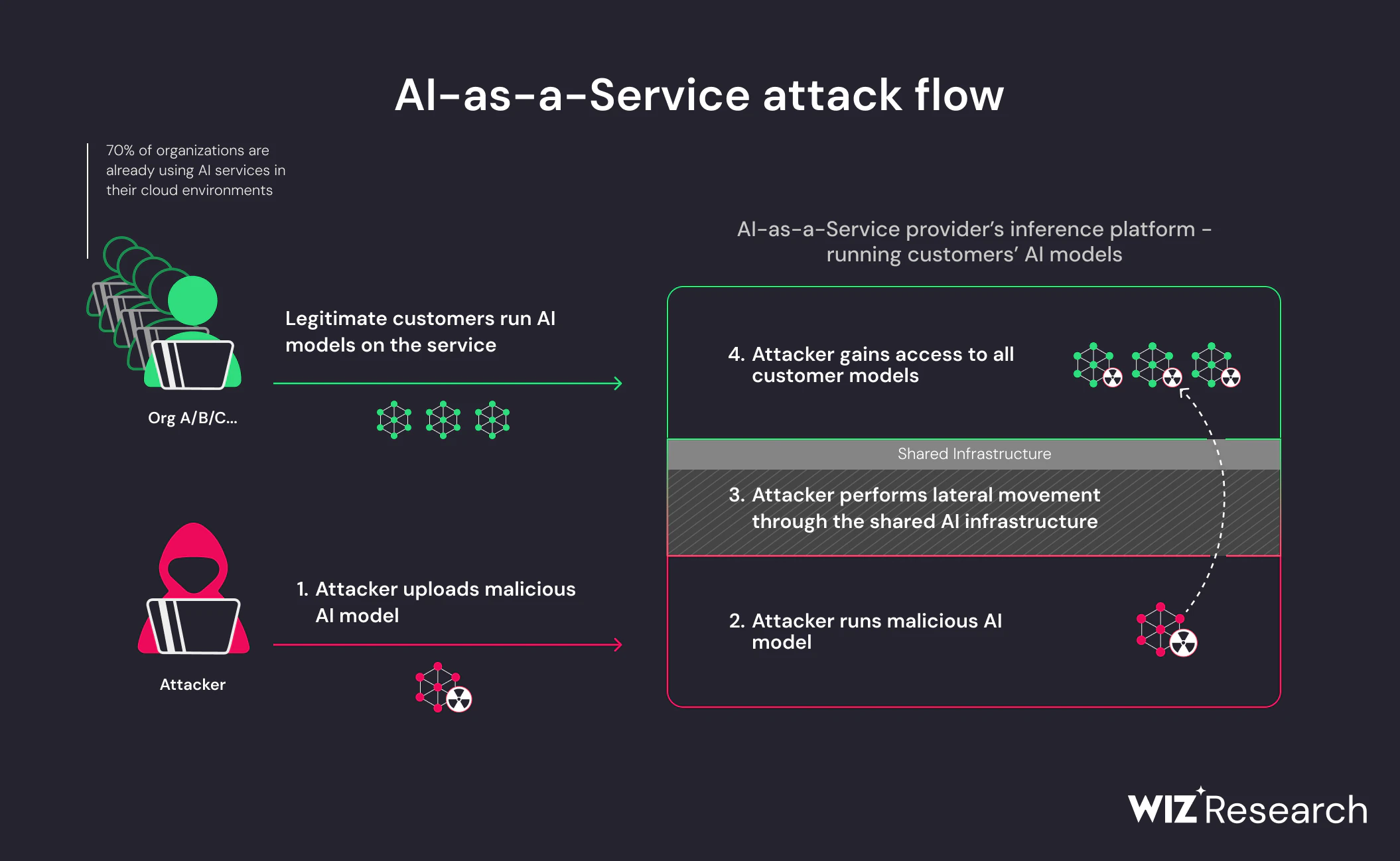
Ce qui rend ce risque particulièrement aigu, c’est que les modèles malveillants exploitent Comportement attendu. Le chargement d’un modèle est une action normale et fiable dans les pipelines d’IA. Lorsque les attaquants intègrent la logique exécutable dans des artefacts de modèles, cette confiance devient le mécanisme de livraison. Aucune chaîne d’exploits n’est requise ; la compromission survient parce que le système fait exactement ce pour quoi il a été conçu.
C’est pourquoi les modèles d’IA malveillants représentent un Menace de la chaîne d’approvisionnement plutôt qu’un bug d’application. Le risque ne provient pas de la manière dont un modèle est utilisé, mais de d’où elle vient et comment elle est chargée. À mesure que la réutilisation des modèles continue de s’étendre dans les équipes et les environnements, la capacité à valider la provenance et le comportement des modèles devient une exigence fondamentale de sécurité.
The risk in malicious AI models: Wiz Research discovers critical vulnerability in AI-as-a-Service provider, Replicate
En savoir plus

Comment fonctionnent les modèles d’IA malveillants à un niveau élevé
Les modèles d’IA malveillants exploitent la manière dont les modèles sont emballés, distribués et chargés dans les flux de travail modernes de l’IA. Le risque central ne réside pas dans les prédictions du modèle, mais dans le Chemin d’exécution déclenché lorsqu’un fichier modèle est désérialisé ou initialisé.
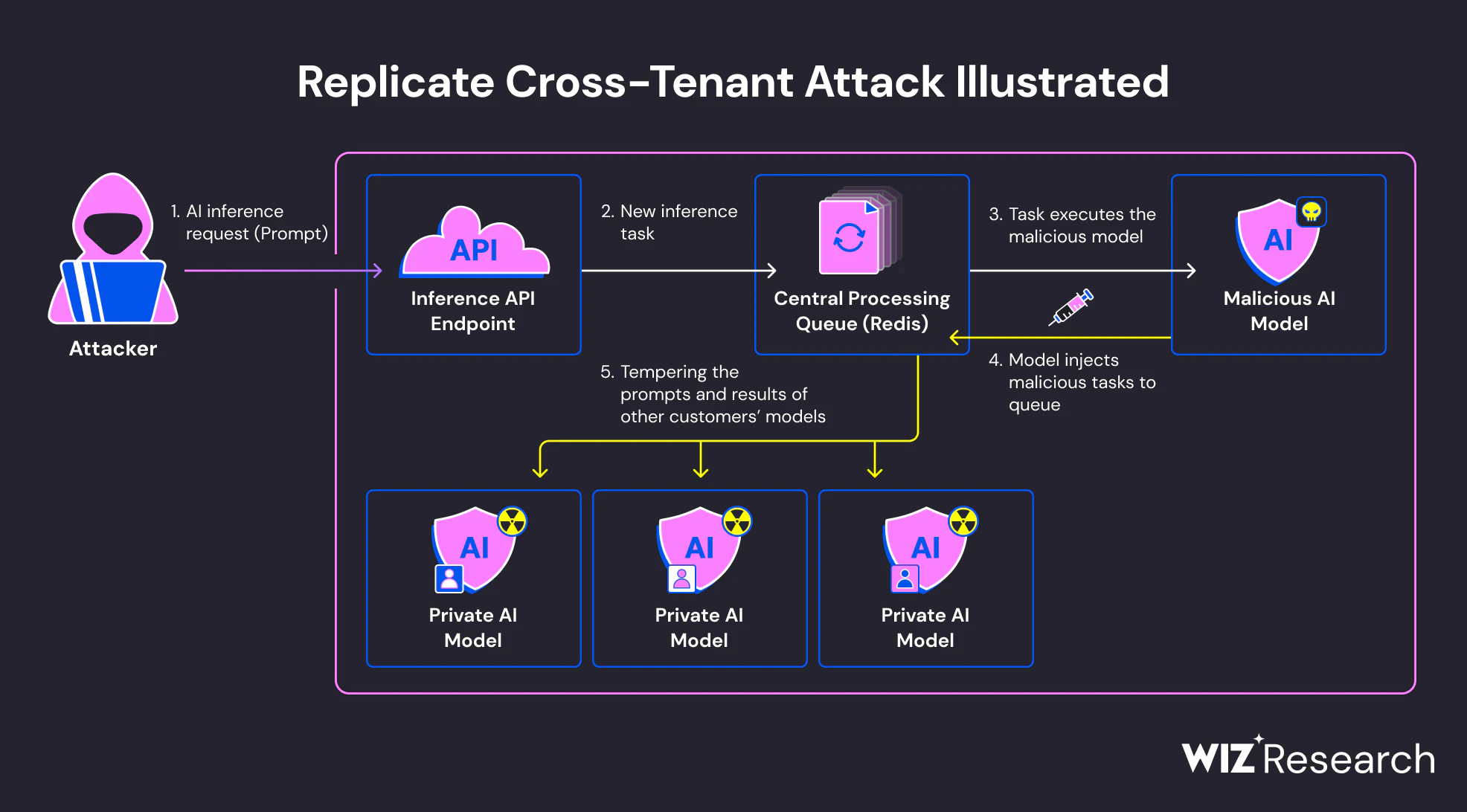
Exécution lors du chargement du modèle
De nombreux frameworks d’IA prennent en charge les formats de sérialisation qui permettent à la logique exécutable d’exécuter dans le cadre du chargement du modèle. En particulier, Python Pickleles formats basés sur -– couramment utilisés dans PyTorch et les outils associés – peuvent exécuter un code arbitraire lorsqu’un modèle est désérialisé. Ce comportement est documenté, mais souvent négligé en pratique.
Lorsqu’un modèle malveillant est chargé, le code intégré peut s’exécuter immédiatement, avant que l’inférence ou l’évaluation n’ait lieu. Du point de vue du système, cela ressemble à une importation normale de modèle. Du point de vue de l’attaquant, c’est un point d’exécution fiable dans un environnement de confiance.
Pourquoi cela se produit avant l’inférence
Contrairement au code applicatif, les modèles sont traités comme des données. Les contrôles de sécurité se concentrent généralement sur la manière dont les modèles sont utilisés, pas sur leur chargement. En conséquence, l’activité la plus dangereuse survient tôt dans le cycle de vie – au moment du chargement – avant que la surveillance en temps réel, les contrôles d’accès ou les contrôles comportementaux ne soient appliqués.
C’est ce qui rend les modèles malveillants difficiles à détecter avec les outils traditionnels. Il peut n’y avoir aucun appel API suspect, aucune entrée mal formée, et aucune sortie anormale. Le compromis survient simplement parce que le modèle a été accepté comme légitime.
Objectifs courants des attaquants
Une fois l’exécution accomplie, les attaquants poursuivent généralement des objectifs familiers :
Voler des identifiants ou jetons disponibles dans l’environnement
Accès aux données d’entraînement ou aux magasins de données en aval
Établir la persistance via des portes dérobées ou des tâches planifiées
Consommation de ressources de calcul pour le cryptominage ou une compromission supplémentaire
Ces actions ne sont pas propres aux environnements d’IA, mais les modèles fonctionnent souvent avec des permissions élevées et une proximité avec des données sensibles, ce qui augmente leur impact.
Formats plus sûrs, valeurs par défaut plus sûres
Tous les formats de modèles n’entraînent pas le même risque. Des formats conçus pour séparer les poids de la logique exécutable – tels que SafeTensors et ONNX –Réduire la probabilité d’exécution du code lors du chargement du modèle. Ces formats stockent les données du modèle sans chemins d’exécution intégrés, les rendant plus sûrs par conception.
En revanche, les mécanismes de sérialisation qui permettent la logique exécutable lors de la désérialisation augmentent le risque à moins d’être strictement contrôlés. En pratique, la compatibilité et la commodité conduisent souvent les équipes à adopter des formats non sûrs à moins que des normes de sécurité explicites ne soient appliquées.
Compréhension comment les modèles sont chargés est donc essentiel pour se défendre contre les modèles d’IA malveillants. La menace ne repose pas sur des entrées adverses ou un comportement innovant de l’IA – elle repose sur des chemins d’exécution prévisibles et fiables dans les outils ML courants.


Vecteurs d’attaque principaux pour les modèles d’IA malveillants
Les modèles d’IA malveillants atteignent généralement la production grâce à un petit nombre de vecteurs d’attaque répétables. Ces vecteurs exploitent la confiance dans les artefacts du modèle et l’automatisation dans les flux de travail de l’IA plutôt que des comportements innovants de l’IA.
Dépôts publics de modèles
Les dépôts publics sont le canal de distribution le plus courant pour les modèles malveillants. Les attaquants téléchargent des modèles militaires sur des plateformes populaires ou utilisent le typosquatting pour imiter des projets bien connus. Avec le temps, ils peuvent se forger une réputation grâce à des versions indésirables avant d’introduire une version malveillante.
Comme les modèles pré-entraînés sont souvent téléchargés directement dans des environnements de développement ou d’entraînement, ces artefacts peuvent contourner les processus de révision appliqués au code applicatif ou aux images de conteneurs.
Exécution de code à distance via des chargeurs de modèles
Certains flux de travail d’IA permettent explicitement l’exécution de code à distance ou personnalisée lors du chargement du modèle. Des paramètres tels que les drapeaux de chargeur permissif ou les classes de modèles personnalisés élargissent la surface d’attaque en permettant de récupérer et d’exécuter dynamiquement la logique exécutable.
Dans ces cas, le risque ne provient pas des poids du modèle eux-mêmes, mais du mécanisme de chargement qui fait implicitement confiance au code externe. Cela fait de la configuration des chargeurs une partie importante du modèle de menace.
Modèles de chevaux de Troie et portes dérobées apprises
Tous les modèles malveillants ne dépendent pas de l’exécution lors du chargement. Certains sont conçus pour se comporter normalement dans la plupart des conditions lors de la production Sorties malveillantes lorsque des déclencheurs spécifiques sont présents. Ces modèles « Trojan » intègrent directement des comportements nuisibles dans des poids acquis plutôt que dans du code exécutable.
Contrairement aux attaques basées sur la sérialisation, les modèles de chevaux de Troie ciblent généralement le Processus d’entraînement ou d’ajustement fin, par exemple via des données d’entraînement empoisonnées ou des flux de travail d’ajustement fin manipulés. Parce que le comportement malveillant est codé dans les paramètres du modèle, le balayage statique de l’artefact du modèle offre une visibilité limitée sur la menace.
Cela fait des modèles de Troie une catégorie de risque distincte. Leur détection nécessite généralement des tests adversariaux, une analyse comportementale ou la validation des données d’entraînement et de la lignée, plutôt que l’inspection du seul fichier modèle.
Risque de dépendance et d’initié
Les modèles malveillants peuvent également pénétrer dans les environnements via des dépendances compromises ou des canaux internes de confiance. Cela inclut des bibliothèques de machine learning empoisonnées, des registres internes peu sécurisés ou des modèles introduits par des initiés ayant un accès légitime.
Parce que ces vecteurs reposent sur des relations de confiance existantes, ils sont souvent négligés dans la modélisation précoce des menaces, malgré leur potentiel d’impact général.
Get an AI-SPM Sample Assessment
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities.

Pourquoi les environnements cloud amplifient le risque
Les environnements cloud ne créent pas de modèles d’IA malveillants, mais ils sont significatifs Augmenter l’impact et la vitesse de compromis lorsqu’on en présente une. Les mêmes caractéristiques qui rendent les plateformes cloud idéales pour l’IA – automatisation, mise à l’échelle et accès aux données sensibles – amplifient également le risque de la chaîne d’approvisionnement.
Les charges de travail IA fonctionnent fréquemment avec des permissions élevées. Les emplois d’entraînement et les services d’inférence nécessitent souvent l’accès à de grands ensembles de données, au stockage d’objets, aux secrets et aux services en aval. Lorsqu’un modèle malveillant s’exécute dans ce contexte, il peut immédiatement hériter de ces privilèges, étendant ainsi le rayon de blast au-delà du modèle lui-même.
L’automatisation amplifie encore davantage le risque. Les modèles sont couramment déployés via des pipelines CI/CD, des cadres d’orchestration ou des flux de réentraînement programmés. Une fois qu’un artefact malveillant pénètre dans l’un de ces chemins, il peut se propager rapidement à travers les environnements sans intervention humaine, rendant l’inspection manuelle peu pratique.
L’infrastructure cloud change également là où l’exécution a lieu par rapport aux données sensibles. Les modèles malveillants s’exécutent généralement dans le même plan de données que les données auxquelles ils sont censés accéder, plutôt que adjacente. Contrairement à une application web compromise qui doit pivoter latéralement pour accéder à une base de données, un modèle s’exécute souvent dans un environnement qui a déjà un accès direct aux données d’entraînement, aux entrées d’inférence ou aux systèmes en aval. Cela réduit la distance entre l’exécution et l’impact.
Enfin, les charges de travail de l’IA dépendent de piles complexes de services managés, conteneurs, GPU et dépendances à l’exécution. Chaque couche introduit des défis de configuration et d’isolation que les attaquants peuvent exploiter si les contrôles sont mal appliqués. En pratique, cela signifie que les modèles malveillants bénéficient des mêmes erreurs de configuration qui provoquent aujourd’hui de nombreuses violations du cloud.
Ensemble, ces facteurs transforment les modèles d’IA malveillants d’un risque localisé en un Préoccupation de sécurité au niveau système, renforçant pourquoi la sécurité des modèles doit être évaluée dans le contexte des identités cloud, de l’accès aux données et des pipelines de déploiement – et non isolément.
Défense contre des modèles d’IA malveillants
Se défendre contre les modèles d’IA malveillants nécessite un changement de focus du comportement du modèle vers Provenance du modèle, chemins de chargement et contexte d’exécution. Parce que la menace est intégrée dans l’artefact ou le processus d’entraînement lui-même, traditionnellement Contrôles de sécurité des applications sont nécessaires mais aren'pas assez seuls.
Établir les contrôles avant que les modèles n’atteignent la production
Les défenses les plus efficaces fonctionnent avant qu’un modèle ne soit chargé. Cela inclut la validation de l’origine des modèles, de leur conditionnement et des chemins de code exécutés lors du chargement. Traiter les artefacts des modèles comme des composants de la chaîne d’approvisionnement de première classe – soumis à inspection, approbation et contrôle de version – réduit la probabilité que les modèles militarisés atteignent des environnements sensibles.
En pratique, cela signifie appliquer la même gouvernance à Registres de modèles que les organisations s’appliquent déjà aux registres de conteneurs ou aux dépôts d’artefacts. Si les images des conteneurs sont signées, numérisées et promues via des pipelines contrôlés, les artefacts du modèle devraient suivre la même discipline – qu’ils proviennent en interne ou de sources publiques.
Lorsque possible, les équipes devraient préférer des formats de modèles qui séparent les données de la logique exécutable et restreignent les configurations de chargeurs qui font implicitement confiance au code externe. Ces contrôles n’éliminent pas le risque, mais réduisent considérablement la surface d’attaque.
Contraindre l’exécution via des contrôles d’identité et d’accès
Les modèles malveillants sont les plus dangereux lorsqu’ils héritent de permissions larges. Limiter les identités et rôles disponibles pour les charges de travail d’entraînement et d’inférence réduit le rayon de blast si un modèle est compromis. Cela inclut l’application du privilège minimum pour les comptes de service, l’isolement des environnements et l’évitement des identifiants partagés entre pipelines.
Parce que les modèles s’exécutent souvent à l’intérieur du plan de données, le contrôle d’accès devient une ligne de défense principale – et non une protection secondaire.
Surveillez le comportement dans le contexte, pas isolément
L’inspection statique seule ne peut pas détecter tous les modèles malveillants, en particulier ceux qui intègrent des comportements dans des poids appris. La visibilité à l’exécution aide à combler ce manque en observant comment les modèles interagissent avec leur environnement au fil du temps.
Un suivi efficace se concentre sur Signaux contextuels: accès réseau inattendu, opérations de fichiers inhabituelles, utilisation anormale de l’identité ou déviations par rapport aux schémas d’exécution établis. Ces signaux sont particulièrement pertinents lorsqu’ils sont corrélés au contexte cloud – quelles données le modèle peut accéder, quelles identités il utilise et comment il a été déployé.
Considérer la sécurité des modèles comme faisant partie de la sécurité cloud
En fin de compte, se défendre contre des modèles d’IA malveillants n’est pas une discipline autonome. Cela nécessite d’intégrer des considérations spécifiques à l’IA dans les éléments existants Pratiques de sécurité cloud, y compris la gouvernance de la chaîne d’approvisionnement, la gestion des identités et la surveillance de la charge de travail.
En évaluant les modèles dans le cadre du système plus large dans lequel ils opèrent – plutôt que comme des boîtes noires opaques – les équipes de sécurité peuvent réduire l’exposition aux artefacts malveillants sans dépendre de la détection spéculative ou des hypothèses sur le comportement du modèle.
Comment Wiz aide à réduire le risque de modèles d’IA malveillants
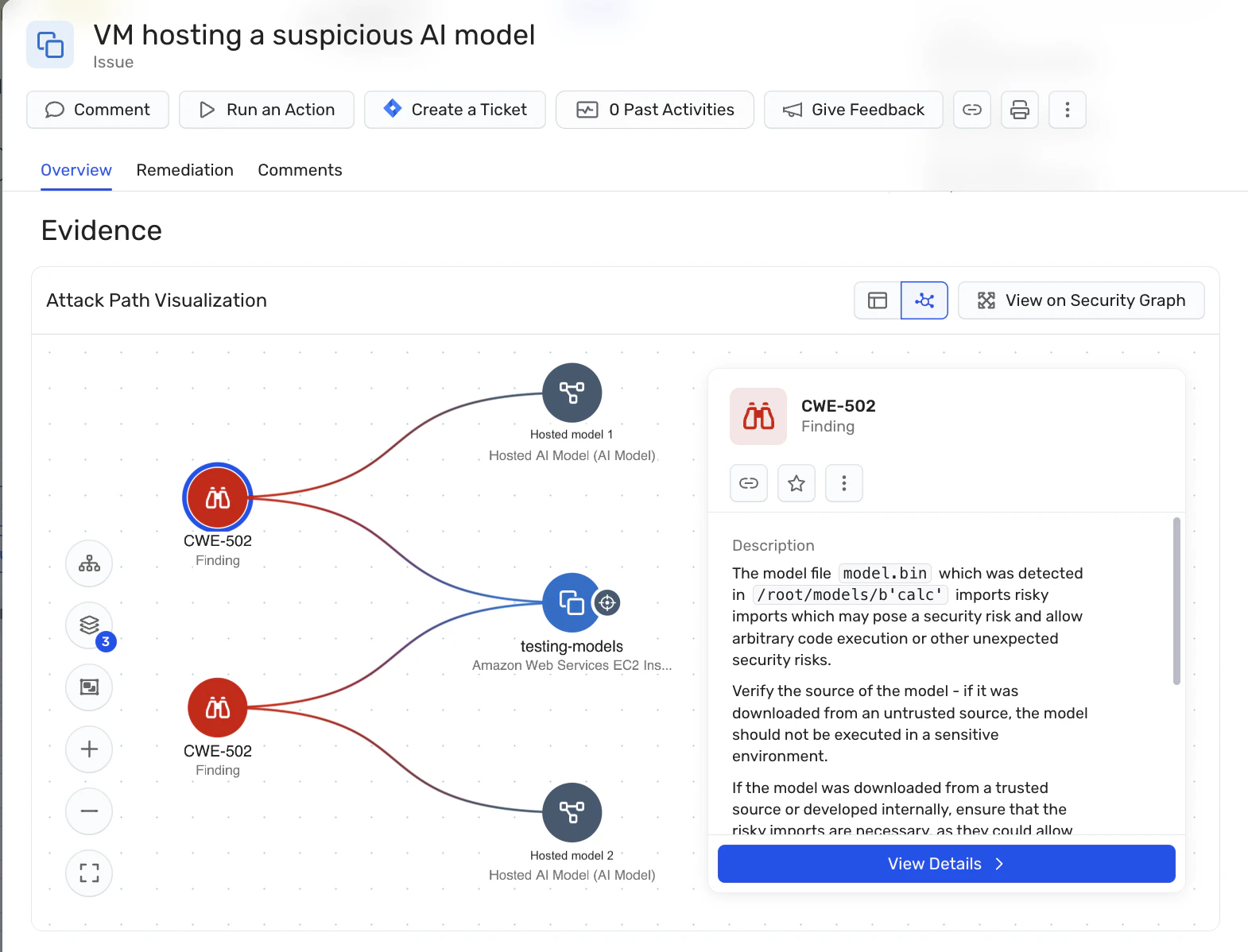
Wiz aide les organisations à réduire le risque de modèles d’IA malveillants en ancrant la sécurité des modèles dans les fondamentaux de la sécurité cloud. Plutôt que de tenter de classifier l’intention ou le comportement du modèle, Wiz se concentre sur la validation des contrôles qui déterminent D’où viennent les modèles, comment ils sont chargés, et à quoi ils peuvent accéder une fois déployés.
À travers Gestion de la posture de sécurité de l’IA (IA-SPM) et le Graphe de sécurité Wiz, les modèles d’IA, les emplois de formation, les services d’inférence et les registres sont traités comme des actifs cloud de premier ordre. Wiz offre une visibilité sur les artefacts du modèle hébergé et effectue des inspections au niveau du format pour mettre en lumière des méthodes de sérialisation risquées ou des sources non fiables – étendant ainsi la discipline de la chaîne d’approvisionnement logicielle aux modèles d’IA avant leur entrée en production.
En corrélant les artefacts du modèle avec les identités, les permissions, l’exposition réseau et l’accès aux données sensibles, Wiz aide les équipes à identifier quand un modèle risqué ou potentiellement malveillant devient exploitable en pratique, comprendre son véritable rayon d’explosion, et prioriser la remédiation en fonction des véritables chemins d’attaque – sans ralentir le développement de l’IA ni introduire des outils de sécurité distincts.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
