



Qu’est-ce qu’une fuite de données ?
La fuite de données est l’exfiltration incontrôlée de données organisationnelles vers un tiers. Elle se produit par divers moyens tels que des bases de données mal configurées, des serveurs réseau mal protégés, des attaques de phishing ou encore une manipulation négligente des données.
Une fuite de données peut se produire accidentellement : 82 % de toutes les organisations Donner à des tiers un large accès en lecture à leurs environnements, ce qui pose des risques majeurs pour la sécurité et de graves problèmes de confidentialité. Cependant, les fuites de données se produisent également en raison d’activités malveillantes, notamment le piratage, le phishing ou les menaces internes où les employés volent intentionnellement des données.
GenAI Security Best Practices [Cheat Sheet]
Discover the 7 essential strategies for securing your generative AI applications with our comprehensive GenAI Security Best Practices Cheat Sheet.
Download Cheat Sheet

Impacts potentiels de la fuite de données
La fuite de données peut avoir des impacts profonds et d’une portée considérables :
| Impact | Description |
|---|---|
| Financial losses and reputational damage | Organizations can incur significant expenses after a data leak; these include hiring forensic experts to investigate the breach, patching vulnerabilities, and upgrading security systems. Companies may also need to pay for attorneys to handle lawsuits and regulatory investigations. The immediate aftermath of a data breach also often sees a decline in sales as customers and clients take their business elsewhere due to a lack of trust. |
| Legal consequences | Individuals or entities affected by a data leak can sue a company for negligence and damages. Regulatory entities might impose penalties for failing to comply with data protection laws and regulations like GDPR, CCPA, or HIPAA. The severity of consequences can range from financial fines to operational restrictions. Post-incident, organizations may also be subjected to stringent audits and compliance checks, increasing operational burdens and costs. |
| Operational disruptions | Data leaks disrupt everyday operations and efficiency—everything stops. The leak may also lead to the loss of important business information, including trade secrets, strategic plans, and proprietary research, which can have a lasting impact on competitive advantage. |
La menace croissante des fuites de machine learning (ML)
Lors de l’entraînement d’un modèle à l’aide d’un ensemble de données différent de celui d’un grand modèle de langage (LLM), des biais d’apprentissage automatique ou d’intelligence artificielle (IA) peuvent se produire. Cette situation se produit généralement en raison d’une mauvaise gestion de la phase de prétraitement du développement du ML. Un exemple typique de fuite de ML est l’utilisation de la moyenne et de l’écart-type d’un ensemble de données d’entraînement entier au lieu de l’ensemble du sous-ensemble d’entraînement.
Les fuites de données se produisent dans les modèles d’apprentissage automatique par le biais d’une fuite de cible ou d’une contamination lors des tests d’entraînement. Dans ce dernier, les données destinées à tester le modèle fuient dans l’ensemble d’apprentissage. Si un modèle est exposé à des données de test pendant l’entraînement, ses indicateurs de performance seront trompeusement élevés.
Dans la fuite de cible, les sous-ensembles utilisés pour l’entraînement incluent des informations non disponibles lors de la phase de prédiction du développement du ML. Bien que les LLM fonctionnent bien dans ce scénario, ils donnent aux parties prenantes un fausse impression de l’efficacité du modèle, entraînant des performances médiocres dans les applications réelles.


Causes courantes de fuite de données
Les fuites de données se produisent pour diverses raisons. Voici quelques-uns des plus courants.
Erreur humaine
L’erreur humaine peut se produire à n’importe quel niveau d’une organisation, souvent sans intention malveillante. Par exemple, les employés peuvent envoyer accidentellement des informations sensibles, telles que des dossiers financiers ou des données personnelles, à la mauvaise adresse e-mail.
Attaques de phishing
Les attaques de phishing se manifestent sous diverses formes, mais ont une méthode : les cybercriminels appâtent les comptes privilégiés pour qu’ils fournissent des informations précieuses. Par exemple, les attaquants peuvent envoyer des e-mails apparemment légitimes demandant aux employés de cliquer sur des liens malveillants et de se connecter à un compte donné. Ce faisant, l’employé transmet volontairement ses identifiants de connexion à l’attaquant, qui sont ensuite utilisés à une ou plusieurs fins malveillantes.
Mauvaise configuration
Des bases de données, des services cloud et des paramètres logiciels mal configurés créent des vulnérabilités qui exposent les données sensibles à un accès non autorisé. Erreurs de configuration se produisent souvent en raison d’une surveillance, d’un manque d’expertise ou du non-respect des meilleures pratiques de sécurité. Laisser les paramètres par défaut inchangés, tels que les noms d’utilisateur et les mots de passe par défaut, peut permettre aux cybercriminels d’accéder facilement.
Des paramètres d’application incorrects, l’absence d’application des correctifs et des mises à jour de sécurité, et des paramètres de contrôle/autorisations d’accès inadéquats peuvent également créer des failles de sécurité.
Faiblesse des mesures de sécurité
Des mesures de sécurité faibles diminuent une organisation'. Utiliser des mots de passe simples et faciles à deviner ; ne pas mettre en œuvre de politiques de mots de passe forts ; accorder des autorisations excessives et ne pas suivre le principe du moindre privilège (PoLP) ; La réutilisation des mots de passe de plusieurs comptes augmente le risque de fuite de données.
Aussi, laisser des données Clair– au repos et en transit – prédispose les données aux fuites. Ne pas mettre en œuvre le principe du moindre privilège (PoLP) Et s’appuyer sur des protocoles/technologies de sécurité obsolètes peut créer des failles dans votre cadre de sécurité.
Stratégies pour prévenir les fuites
1. Prétraitement et nettoyage des données
Anonymisation et rédaction
L’anonymisation consiste à modifier ou à supprimer des informations personnellement identifiables (PII) et des données sensibles afin d’éviter qu’elles ne soient reliées à des individus. La rédaction est un processus plus spécifique qui consiste à supprimer ou à masquer des parties sensibles des données, telles que les numéros de carte de crédit, les numéros de sécurité sociale ou les adresses.
Sans anonymisation et rédaction appropriées, les modèles d’IA peuvent "mémoriser" des données sensibles de l’ensemble d’apprentissage, qui pourraient être reproduites par inadvertance dans les sorties du modèle. Ceci est particulièrement dangereux si le modèle est utilisé dans des applications publiques ou orientées client.
Bonnes pratiques:
Utilisez des techniques de tokenisation, de hachage ou de cryptage pour anonymiser les données.
Assurez-vous que toutes les données caviardées sont définitivement supprimées des ensembles de données structurés (par exemple, les bases de données) et non structurés (par exemple, les fichiers texte) avant l’entraînement.
Mettre en œuvre la confidentialité différentielle (voir plus loin) pour réduire davantage le risque d’exposition des données individuelles.
Minimisation des données
La minimisation des données implique de collecter et d’utiliser uniquement le plus petit ensemble de données nécessaire pour atteindre l’objectif du modèle d’IA. Moins il y a de données collectées, plus le risque de fuite d’informations sensibles est faible.
La collecte excessive de données augmente la surface de risque de violations et les risques de fuite d’informations sensibles. En utilisant uniquement ce que'Si nécessaire, vous assurez également le respect des réglementations en matière de confidentialité telles que le RGPD ou le CCPA.
Bonnes pratiques:
Réalisez un audit de données pour évaluer quels points de données sont essentiels pour la formation.
Mettez en œuvre des politiques pour éliminer les données non essentielles au début du pipeline de prétraitement.
Examinez régulièrement le processus de collecte de données pour vous assurer qu’aucune donnée inutile n’est conservée.
2. Garanties de formation des modèles
Séparation correcte des données
La division des données sépare l’ensemble de données en ensembles d’entraînement, de validation et de test. Le kit d’entraînement enseigne le modèle, tandis que les kits de validation et de test garantissent la précision du modèle sans surapprentissage.
Si les données sont mal divisées (par exemple, les mêmes données sont présentes dans les ensembles d’entraînement et de test), le modèle peut effectivement « mémoriser » l’ensemble de test, ce qui entraîne une surestimation de ses performances et une exposition potentielle d’informations sensibles dans les phases d’entraînement et de prédiction.
Bonnes pratiques:
Randomisez les jeux de données lors du fractionnement pour éviter tout chevauchement entre les jeux d’entraînement, de validation et de test.
Utilisez des techniques telles que la validation croisée k-fold pour évaluer de manière robuste les performances du modèle sans fuite de données.
Techniques de régularisation
Des techniques de régularisation sont employées pendant l’entraînement pour éviter le surapprentissage, lorsque le modèle devient trop spécifique aux données d’entraînement et apprend à « mémoriser » plutôt qu’à généraliser à partir de celles-ci. Le surajustement augmente la probabilité de fuite de données, car le modèle peut mémoriser des informations sensibles à partir des données d’entraînement et les reproduire pendant l’inférence.
Bonnes pratiques:
Marginal: Supprimer aléatoirement certaines unités (neurones) du réseau de neurones pendant l’entraînement, forçant le modèle à généraliser plutôt qu’à mémoriser des motifs.
Perte de poids (régularisation L2): Pénaliser les poids importants pendant l’entraînement pour éviter que le modèle ne s’ajuste trop près des données d’entraînement.
Arrêt anticipé: Surveiller les performances du modèle sur un jeu de validation et arrêter l’entraînement lorsque le modèle'commence à se dégrader en raison d’un surapprentissage.
Confidentialité différentielle
La confidentialité différentielle ajoute un bruit contrôlé aux données ou aux sorties du modèle, ce qui fait qu’il devient difficile pour les attaquants d’extraire des informations sur un point de données individuel dans l’ensemble de données.
En appliquant la confidentialité différentielle, les modèles d’IA sont moins susceptibles de divulguer les détails d’individus spécifiques pendant l’entraînement ou la prédiction, offrant ainsi une couche de protection contre les attaques adverses ou les fuites de données involontaires.
Bonnes pratiques:
Ajoutez du bruit gaussien ou de Laplace aux données d’entraînement, aux gradients de modèle ou aux prédictions finales pour masquer les contributions de données individuelles.
Utilisez des frameworks tels que TensorFlow Privacy ou PySyft pour appliquer la confidentialité différentielle dans la pratique.
AI Security Posture Assessment Sample Report
Take a peek behind the curtain to see what insights you’ll gain from Wiz AI Security Posture Management (AI-SPM) capabilities. In this Sample Assessment Report, you’ll get a view inside Wiz AI-SPM including the types of AI risks AI-SPM detects.
Download Sample Assessment

3. Déploiement sécurisé du modèle
Isolation du locataire
Dans un environnement multilocataire, l’isolation du locataire crée une limite logique ou physique entre chaque locataire', ce qui rend impossible pour un locataire d’accéder à un autre ou de manipuler un autre'. En isolant chaque locataire', les entreprises peuvent empêcher tout accès non autorisé, réduire le risque de violation de données et assurer la conformité aux réglementations en matière de protection des données.
L’isolation des locataires fournit une couche de sécurité supplémentaire, ce qui permet aux organisations d’avoir l’esprit tranquille en sachant que leur données sensibles d’entraînement de l’IA est protégé contre les fuites potentielles ou les accès non autorisés.
Bonnes pratiques:
Séparation logique: utilisez des techniques de virtualisation telles que des conteneurs ou des machines virtuelles (VM) pour vous assurer que les données et le traitement de chaque locataire sont isolés les uns des autres.
Contrôles d’accès: Mettez en œuvre des politiques de contrôle d’accès strictes pour vous assurer que chaque locataire ne peut accéder qu’à ses propres données et ressources.
Chiffrement et gestion des clés: utilisez des clés de chiffrement spécifiques au locataire pour séparer davantage les données, en veillant à ce que même en cas de violation, les données des autres locataires restent sécurisées.
Limitation et surveillance des ressources: Empêchez les locataires d’épuiser les ressources partagées en appliquant des limites de ressources et en surveillant les comportements anormaux susceptibles de compromettre l’isolation du système.
Assainissement de sortie
Le nettoyage des sorties implique la mise en œuvre de vérifications et de filtres sur les sorties du modèle afin d’éviter l’exposition accidentelle de données sensibles, en particulier dans le traitement du langage naturel (NLP) et les modèles génératifs.
Dans certains cas, le modèle peut reproduire des informations sensibles qu’il a rencontrées pendant l’entraînement (par exemple, des noms ou des numéros de carte de crédit). Le nettoyage des sorties garantit qu’aucune donnée sensible n’est exposée.
Bonnes pratiques:
Utilisez des algorithmes de correspondance de modèles pour identifier et caviarder les informations personnelles (par exemple, les adresses e-mail, les numéros de téléphone) dans les sorties du modèle.
Définissez des seuils sur les sorties probabilistes pour éviter que le modèle ne fasse des prédictions trop fiables qui pourraient exposer des détails sensibles.
4. Pratiques organisationnelles
Formation des employés
La formation des employés permet de s’assurer que toutes les personnes impliquées dans le développement, le déploiement et la maintenance des modèles d’IA comprennent les risques de fuite de données et les meilleures pratiques pour les atténuer. De nombreuses violations de données sont dues à une erreur humaine ou à une négligence. Une formation appropriée peut empêcher l’exposition accidentelle d’informations sensibles ou de vulnérabilités de modèle.
Bonnes pratiques:
Offrez régulièrement des formations en cybersécurité et en confidentialité des données à tous les employés qui manipulent des modèles d’IA et des données sensibles.
Informer le personnel des risques émergents pour la sécurité de l’IA et des nouvelles mesures préventives.
Politiques de gouvernance des données
Les politiques de gouvernance des données établissent des directives claires sur la manière dont les données doivent être collectées, traitées, stockées et accessibles dans l’ensemble de l’organisation, en veillant à ce que les pratiques de sécurité soient appliquées de manière cohérente.
Une politique de gouvernance bien définie garantit que le traitement des données est standardisé et conforme aux lois sur la protection de la vie privée telles que le RGPD ou la HIPAA, ce qui réduit les risques de fuite.
Bonnes pratiques:
Définissez la propriété des données et établissez des protocoles clairs pour le traitement des données sensibles à chaque étape du développement de l’IA.
Examiner et mettre à jour régulièrement les politiques de gouvernance pour tenir compte des nouveaux risques et des exigences réglementaires.
5. Tirez parti des outils de gestion de la posture de sécurité de l’IA (AI-SPM)
Solutions AI-SPM fournir une visibilité et un contrôle sur les composants critiques de la sécurité de l’IA, y compris les données utilisées pour l’entraînement/l’inférence, l’intégrité des modèles et l’accès aux modèles déployés. En intégrant un outil AI-SPM, les organisations peuvent gérer de manière proactive la posture de sécurité de leurs modèles d’IA, en minimisant le risque de fuite de données et en assurant une gouvernance robuste des systèmes d’IA.
Comment AI-SPM aide à prévenir les fuites de modèles ML :
Découvrir et inventorier toutes les applications, modèles et ressources d’IA associés
Identifier les vulnérabilités de la chaîne d’approvisionnement de l’IA et les erreurs de configuration qui pourraient entraîner des fuites de données
Surveillez les données sensibles dans la pile d’IA, y compris les données d’entraînement, les bibliothèques, les API et les pipelines de données
Détectez les anomalies et les fuites de données potentielles en temps réel
Mettre en place des garde-fous et des contrôles de sécurité spécifiques aux systèmes d’IA
Effectuer régulièrement des audits et des évaluations des applications de l’IA


Comment Wiz peut vous aider
Grâce à sa gestion complète de la posture de sécurité des données (DSPM), Wiz aide à prévenir et à détecter les fuites de données de la manière suivante.
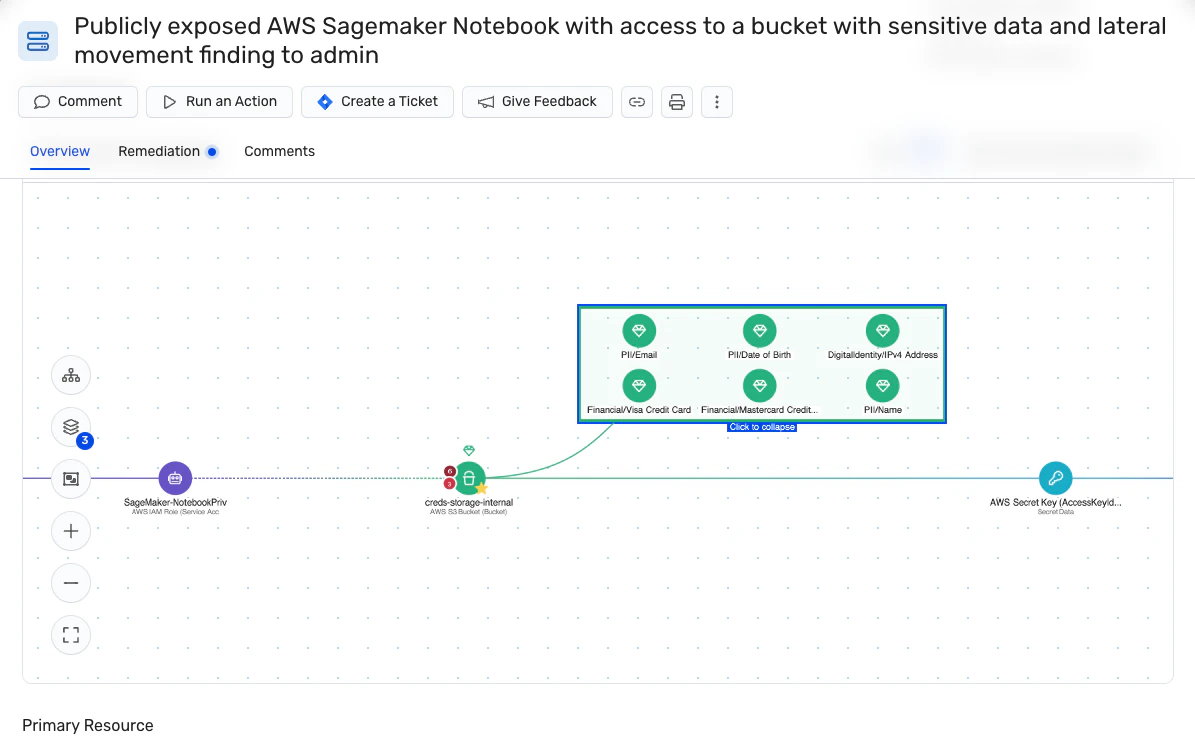
Découvrir et classer automatiquement les données
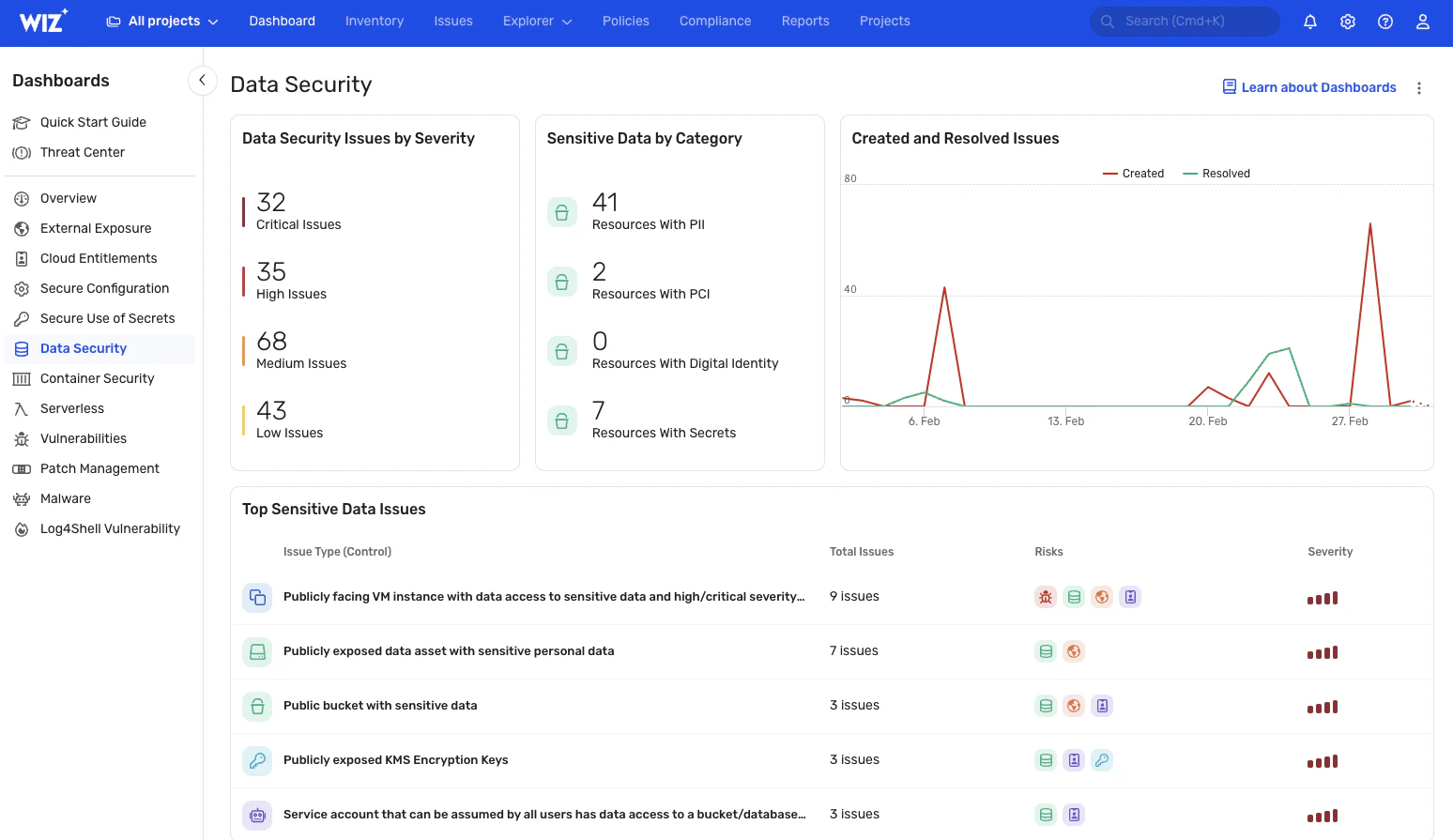
Wiz surveille en permanence l’exposition des données critiques, offrant une visibilité en temps réel sur les informations sensibles telles que les données PII, PHI et PCI. Il fournit une vue à jour de l’emplacement des données et de la manière dont elles sont accessibles (même dans vos systèmes d’IA avec notre Solution AI-SPM). Vous pouvez également créer des classificateurs personnalisés pour identifier les données sensibles propres à votre entreprise. Ces caractéristiques facilitent en outre une réponse rapide aux incidents de sécurité, évitant ainsi tout dommage ou minimisant considérablement le rayon d’explosion potentiel.
Évaluation des risques liés aux données
Wiz détecte les chemins d’attaque en corrélant les résultats des données aux vulnérabilités, aux erreurs de configuration, aux identités et aux expositions qui peuvent être exploitées. Vous pouvez ensuite fermer ces chemins d’exposition avant que les acteurs malveillants ne puissent les exploiter. Wiz visualise et hiérarchise également les risques d’exposition en fonction de leur impact et de leur taux de gravité, en veillant à ce que les problèmes les plus critiques soient traités en premier.
De plus, Wiz facilite la gouvernance des données en détectant et en affichant qui peut accéder à quelles données.
Sécurité des données pour les données d’entraînement de l’IA
Wiz fournit une évaluation complète des risques de vos actifs de données, y compris le risque de fuite de données, avec des solutions prêtes à l’emploi DSPM AI Contrôles. Nos outils fournissent une vue globale de la posture de sécurité des données de votre organisation, mettent en évidence les domaines qui nécessitent une attention particulière et offrent des conseils détaillés pour renforcer vos mesures de sécurité et résoudre rapidement les problèmes.
Évaluation continue de la conformité
L’évaluation continue de la conformité de Wiz garantit que votre organisation's’aligne en temps réel sur les normes de l’industrie et les exigences réglementaires. Notre plateforme analyse les erreurs de configuration et les vulnérabilités, en fournissant des recommandations exploitables pour y remédier et en automatisant les rapports de conformité.
Avec Wiz DSPM, vous pouvez aider efficacement votre organisation à atténuer les risques de fuite de données et à garantir une protection des données et la conformité. Réserver une démo aujourd’hui pour en savoir plus.
Accelerate AI Innovation, Securely
Learn why CISOs at the fastest growing companies choose Wiz to secure their organization's AI infrastructure.
