

Réponse aux incidents : définition et enjeux en cybersécurité
La réponse aux incidents désigne l’ensemble des actions coordonnées mises en place pour identifier, analyser et contenir un incident de sécurité informatique, puis rétablir un fonctionnement normal dans les plus brefs délais. Ce processus vise à limiter l’impact d’une attaque ou d’une faille de sécurité tout en tirant les leçons nécessaires pour éviter qu’un tel événement ne se reproduise à l’avenir.
La réponse aux incidents ne se limite donc pas à la phase de réaction. Elle inclut également une préparation proactive avec des politiques de sécurité, des plans d’intervention documentés, des playbooks (protocoles ou guides d'intervention automatisés), des outils technologiques et des tests réguliers pour assurer une réponse rapide et efficace. Enfin, la réponse aux incidents fait partie de la Gestion des incidents de sécurité informatique, une approche plus large qui implique des équipes pluridisciplinaires rassemblant le service IT dans son ensemble et les services juridiques mais aussi les équipes RH ou communication afin de gérer l’incident sous tous les angles possibles.
Dans cet article, nous allons donc nous concentrer sur la réponse technique aux incidents de cybersécurité tout en évoquant également les aspects organisationnels indispensables à une protection globale.
How to Prepare for a Cloud Cyberattack: An Actionable Incident Response Plan Template
A quickstart guide to creating a robust incident response plan – designed specifically for companies with cloud-based deployments
Download Template

Incident de sécurité : comment le reconnaître et le différencier d’un événement ou d’une attaque ?
Avant d’intervenir, les équipes de réponse aux incidents informatiques doivent savoir précisément ce qu’elles doivent traiter. En effet, une mauvaise interprétation de la situation peut entraîner une perte de temps précieuse ou l’escalade inutile d’un incident.
Voici les trois concepts de gestion des incidents à bien distinguer.
Événement de sécurité : une activité inhabituelle ou suspecte observée dans un système informatique comme une élévation de privilèges, un accès anormal ou une modification de configuration. Cela peut signaler une menace potentielle. Mais, il ne s’agit pas nécessairement d’un problème de sécurité confirmé.
Incident de sécurité : un incident se produit lorsqu’un ou plusieurs événements sont confirmés comme ayant un impact négatif potentiel ou réel. Par exemple, un accès non autorisé à des données, une compromission de compte ou une altération de systèmes. Il peut résulter d’une erreur humaine, d’une mauvaise configuration ou d’un acte malveillant.
Attaque : une attaque est un incident délibéré mené avec une intention malveillante, souvent dans le but de voler, de corrompre ou de rendre inaccessibles des données sensibles. Elle peut prendre la forme de ransomware, d’exfiltration de données ou d’intrusion dans un environnement cloud.
Comprendre cette terminologie est donc essentiel pour garantir une réponse aux incidents rapide et efficace fondée sur une détection précise et une prise de décision adaptée.
Les principaux types d’incidents de sécurité à connaître
Pour garantir une réponse aux incidents efficace, il est également crucial de bien connaître les différents types d’incidents de sécurité auxquels une organisation peut être confrontée. En effet, chaque scénario nécessite une approche spécifique tant sur le plan de la détection que de la remédiation. En outre, ces incidents peuvent viser des applications, des données, des infrastructures on-premise ou cloud et prennent des formes variées.
Voici les formes les plus courantes de cyberattaques.
Déni de service (DoS/DDoS) : une attaque visant à submerger un service ou un système par un grand volume de requêtes dans le but de le rendre indisponible pour les utilisateurs légitimes.
Compromission d’application : des failles de sécurité que les attaquants vont exploiter via des vecteurs comme l’injection SQL, le cross-site scripting (XSS) ou l’empoisonnement DNS pour manipuler les données, détourner des sessions ou exécuter du code malveillant.
Ransomware : un logiciel malveillant qui chiffre les données d’un système et exige une rançon pour les restituer. De plus en plus répandu, ce type d’incident peut entraîner des interruptions majeures d’activité et des pertes financières conséquentes.
Violation de données : désigne l’accès non autorisé à des données sensibles ou confidentielles, que ce soit à des fins d’exfiltration, de vol ou de compromission. Elle constitue l’un des incidents les plus critiques sur le plan réglementaire et de réputation.
Attaque Man-in-the-middle (MitM) : un cybercriminel va intercepter et altérer les échanges entre deux parties sans qu’elles s’en rendent compte. Cette attaque peut compromettre la confidentialité et l’intégrité des données.
En définitive, comprendre ces scénarios d’incidents de sécurité permet non seulement de renforcer ses défenses, mais aussi de construire des plans de réponse aux incidents adaptés à chaque type de menace. C’est également un prérequis pour identifier les bons outils de détection, d’automatisation et d’analyse.
The Cloud Security Threat Report
The Wiz Threat Research team looks back on the past year to highlight trends and the state of multi cloud usage based on visibility across our customer base.
Download Report

Réponse aux incidents dans les environnements cloud : nouveaux défis, nouvelles approches
Avec la généralisation des environnements cloud et cloud-native, la réponse aux incidents doit évoluer pour répondre à une surface d’attaque toujours plus complexe, éphémère et distribuée. Or, de nombreuses entreprises appliquent encore des pratiques héritées du monde on-premise qui ne sont pas toujours adaptées aux réalités du cloud.
Pour renforcer leur cybersécurité cloud, les organisations doivent donc faire évoluer leur approche en tenant compte des spécificités du cloud :
former les équipes d’intervention à la compréhension des environnements multicloud, des services managés et de l’architecture cloud-native y compris les modèles de responsabilité partagée ;
utiliser des outils cloud-native capables de détecter et de corréler les incidents à travers des environnements hybrides et dynamiques. En effet, les solutions traditionnelles manquent souvent de visibilité sur ces environnements complexes ;
exploiter la télémétrie des fournisseurs cloud (CSP) : logs d’audit, métriques, alertes de sécurité, activités IAM… ces données sont précieuses pour comprendre le contexte d’un incident, identifier les causes racines et réagir rapidement.
Ainsi, la réponse aux incidents cloud exige des capacités d’observation et d’automatisation avancées intégrées à une stratégie globale de détection et de remédiation. C’est pourquoi, il est indispensable d’adapter ses processus à cet environnement pour garder une longueur d’avance sur les attaquants potentiels.
The Cloud Threat Landscape
A comprehensive threat intelligence database of cloud security incidents, actors, tools and techniques.
Explore
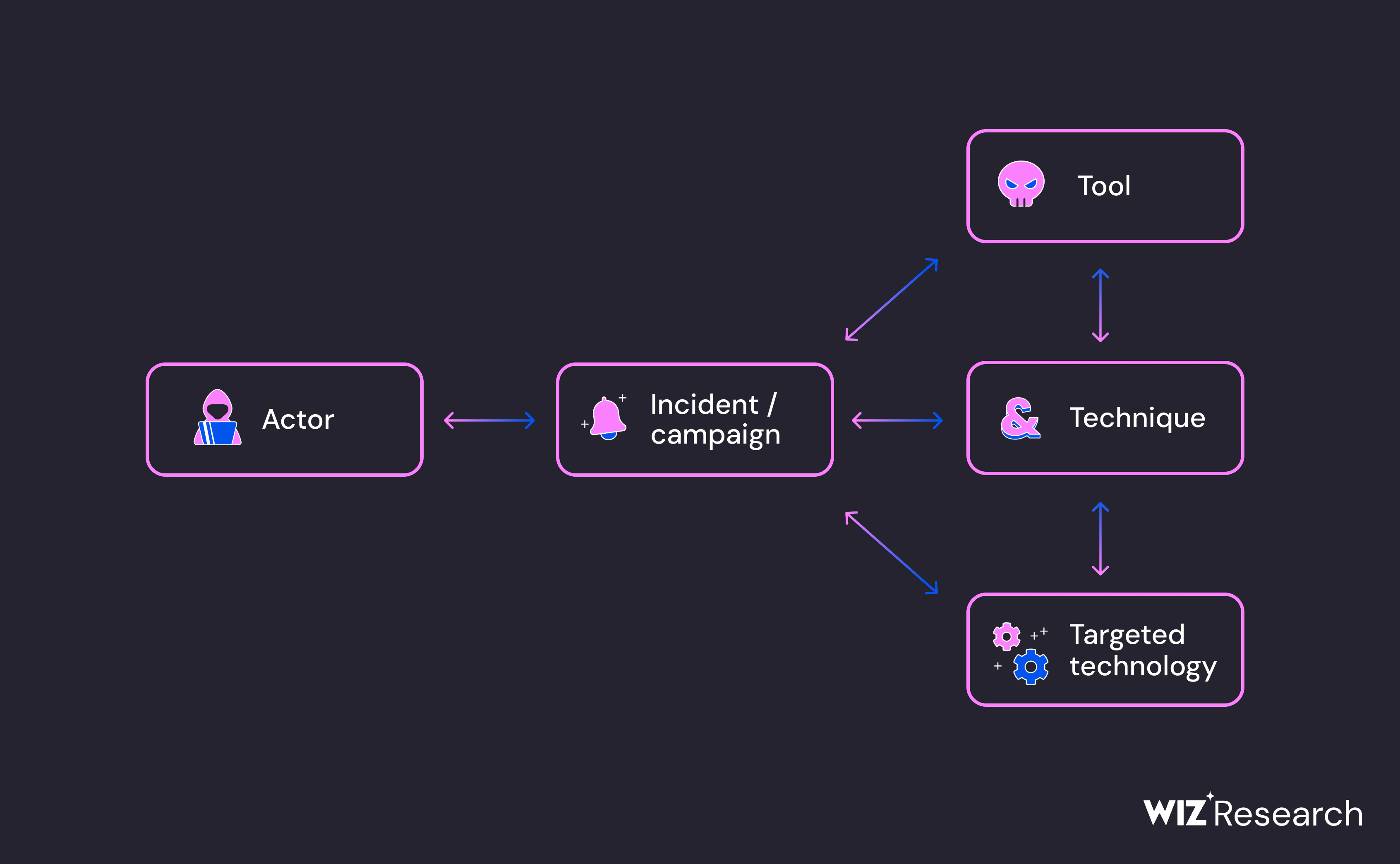
Structurer sa réponse aux incidents : les documents clés à mettre en place
Une réponse aux incidents efficace repose sur bien plus que de simples compétences techniques. En effet, elle nécessite une documentation formelle et structurée qui va servir de feuille de route lors des moments critiques. Cette documentation constitue donc le socle de toute bonne stratégie de sécurité en assurant clarté, cohérence et coordination au sein des équipes concernées.
Trois types de documents jouent un rôle central dans cette architecture : la politique de réponse aux incidents, le plan d’intervention et les playbooks de cybersécurité. Chacun d’eux répond à un besoin spécifique allant de la vision stratégique à l’exécution opérationnelle.
1. Politique de réponse aux incidents : poser les fondations stratégiques de sa posture de sécurité
La Politique de réponse aux incidents définit les grandes lignes de sa posture de sécurité face aux cybermenaces. C’est donc un document de référence qui légitime l’existence d’un programme formel d’intervention en cas d’incident en mobilisant les décideurs autour d’une stratégie proactive.
Concrètement, la politique de réponse aux incidents précise les objectifs de sa démarche, la nécessité de constituer une équipe dédiée (CSIRT ou autre) ainsi que les principes directeurs du programme. En outre, cette politique doit être validée par la direction générale car elle confère à l’équipe de sécurité l’autorité nécessaire pour déclencher des actions, impliquer les parties prenantes et allouer les ressources critiques.
En résumé, la politique de réponse aux incidents est le point de départ indispensable pour bâtir une gouvernance robuste autour de la gestion des incidents de sécurité.
How to Create an Incident Response Policy: An Actionable Checklist and Template
En savoir plus

2. Plan d’intervention en cas d’incident : organiser la réponse opérationnelle
Le Plan d’intervention en cas d’incident (IRP) ou Incident Response Plan en anglais traduit la politique de réponse aux incidents en actions concrètes. Ainsi, il décrit l’ensemble du cycle de vie de la réponse aux incidents en détaillant les étapes à suivre avant, pendant et après une attaque.
Le plan d’intervention en cas d’incident (IRP) inclut notamment des procédures pour :
détecter, analyser et classifier un incident de sécurité ;
comprendre l’ampleur et l’origine de l’attaque ;
contenir l’incident pour éviter sa propagation ;
éliminer la menace de manière définitive ;
restaurer les systèmes et reprendre normalement les opérations.
En outre, le plan d’intervention en cas d’incident (IRP) précise les actions de préparation à mettre en œuvre comme les tests, simulations et formations nécessaires ainsi que les démarches post-incident telles que les retours d’expérience, l'analyse des causes racine, les rapports d’incident, etc. Ainsi, le plan d'intervention est un document unique constituant la colonne vertébrale de sa stratégie de cybersécurité opérationnelle tout en jetant les bases de ses playbooks de réponse aux incidents.
3. Playbooks de réponse aux incidents : automatiser et guider les actions
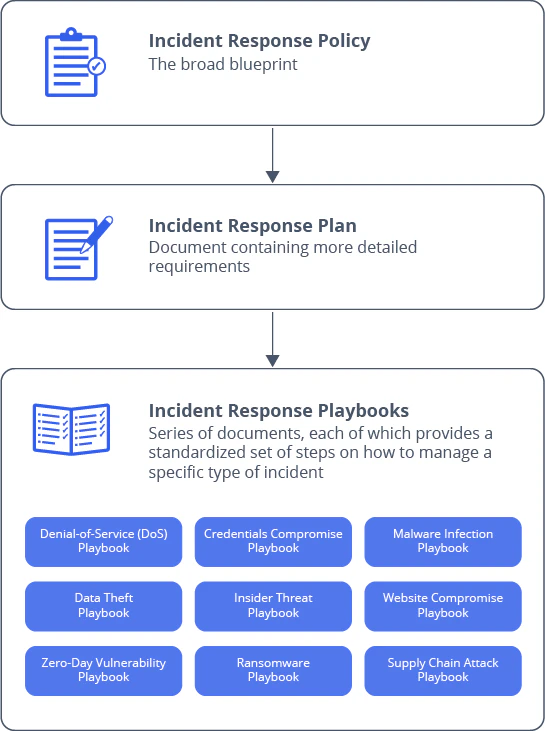
Les playbooks de réponse aux incidents sont des guides pratiques ultra-spécifiques conçus pour gérer différents types d’incidents ou de rôles spécifiques dans l’équipe de réponse aux incidents. Ainsi, contrairement au Plan d'intervention général, chaque playbook de cybersécurité se concentre sur un scénario précis. Par exemple, une attaque par ransomware, une compromission d’identifiants ou une fuite de données. Chacun de ces manuels doit donc contenir des instructions étape par étape, parfois automatisables via SOAR ou scripts, pour réagir rapidement sans perdre de temps à improviser. Ils peuvent aussi être ciblés par fonction. Par exemple, on peut créer un playbook communication de crise pour les équipes RP ou un playbook conformité pour le service juridique en cas de notification aux régulateurs.
Bien conçus, les playbooks réduisent donc les temps de réaction, évitent les erreurs de réponse inadaptées et renforcent la coordination interfonctionnelle.
Composition de l’équipe de réponse aux incidents : rôles et responsabilités clés
Une réponse aux incidents réussie repose sur une coordination fluide entre plusieurs expertises. C’est pourquoi, il est essentiel de constituer une équipe d’intervention en cas d’incident multidisciplinaire afin d’être capable de prendre des décisions rapides, d’exécuter les actions nécessaires et de maintenir une communication claire en interne comme en externe.
Cette équipe doit donc être bien définie à l’avance avec des rôles précis et des responsabilités formalisées. Voici les profils clés à intégrer pour orchestrer une intervention de cybersécurité efficace.
Sponsor exécutif : un appui stratégique au plus haut niveau
Un membre de la direction, souvent le Chief Information Security Officer (CISO) ou le Chief Security Officer (CSO) qui joue le rôle de sponsor exécutif. Ce leader porte la responsabilité globale du programme de réponse aux incidents au sein de l’organisation. Il soutient activement les efforts de l’équipe, facilite la prise de décision rapide et rend compte à la direction générale ou au conseil d’administration en cas de crise majeure. Son soutien est crucial pour obtenir les ressources nécessaires et garantir une gouvernance efficace de la cybersécurité organisationnelle.
Responsable de la réponse aux incidents : chef d’orchestre de la gestion de crise
Le responsable de la réponse aux incidents coordonne l’ensemble des opérations lors d’un incident de sécurité. Il définit les priorités, attribue les tâches, surveille les délais et adapte la stratégie d’intervention en temps réel. Ce rôle central nécessite une vision globale de la situation, une excellente capacité à prendre des décisions sous pression et une parfaite maîtrise des processus documentés dans les plans et playbooks d’intervention.
Équipe technique : les spécialistes de l’analyse et de la remédiation
L’équipe technique regroupe des analystes SOC, ingénieurs sécurité, administrateurs systèmes et experts cloud. Ce sont eux qui prennent en charge les aspects opérationnels de la réponse :
analyse des alertes et des logs ;
containment de la menace ;
éradication du malware ;
restauration des systèmes ;
collecte des preuves pour les audits post-incident.
Ils sont donc en première ligne pour neutraliser l’attaque et limiter son impact.
Équipe juridique : garantir conformité et gestion du risque réglementaire
En cas d’incident de sécurité, les responsables juridiques jouent un rôle critique. En effet, ils évaluent les implications réglementaires (RGPD, loi sur la cybersécurité, notification des violations, etc.), gèrent les obligations contractuelles et préparent les réponses aux autorités compétentes. Leur collaboration avec le reste de l’équipe garantit donc que la gestion de l’incident respecte les cadres juridiques nécessaires et protège les intérêts de l’entreprise.
Équipe communication et RH : piloter la communication de crise
L’équipe communication, souvent appuyée par les RH, prend en charge les messages à adresser aux employés, aux clients, aux partenaires, aux médias et, si nécessaire, au public. Elle joue donc un rôle fondamental dans la gestion de crise en s’assurant que l’information diffusée est précise, cohérente et conforme aux obligations légales. En effet, un seul mauvais message au mauvais moment peut aggraver la situation. C’est pourquoi, il est essentiel d’intégrer la communication dès le début du plan d’intervention.
En constituant une équipe de réponse aux incidents bien structurée, vous renforcez donc votre capacité à réagir de manière coordonnée, à contenir les menaces rapidement et à préserver la confiance de vos parties prenantes en cas de crise.
Cycle de vie de la réponse aux incidents : les six étapes essentielles
Pour réagir efficacement à une cyberattaque, il est indispensable de s’appuyer sur un cycle de vie de réponse aux incidents bien structuré. Ce processus par étapes permet de détecter, d’analyser, de contenir et d’éliminer les menaces tout en minimisant leur impact sur l’entreprise. Heureusement, il n’est pas nécessaire de partir de zéro. Plusieurs cadres reconnus peuvent vous guider dans cette démarche.
Parmi les frameworks les plus utilisés figurent :
NIST 800-61 : guide de gestion des incidents de cybersécurité ;
SANS 504-B : méthodologie orientée opération de sécurité ;
ISO/IEC 27035 : norme internationale de gestion des incidents de sécurité de l’information.
En outre, Wiz propose également un modèle gratuit de plan de réponse aux incidents cloud (en anglais) conçu pour les environnements cloud publics, hybrides et multicloud.
Mais, dans tous les cas, tous ces modèles convergent vers un processus de réponse aux incidents qui se déroule en six grandes étapes.
1. Préparation
La préparation est la phase fondatrice du cycle de vie de la réponse aux incidents. En effet, attendre simplement qu’un incident se produise pour réagir est risqué et coûteux. Cette étape vise donc à anticiper les menaces et à se doter des moyens humains, techniques et organisationnels nécessaires à une réponse rapide.
Elle inclut :
la constitution et la formation de l’équipe de réponse aux incidents ;
l’inventaire des actifs critiques ;
la collecte et la conservation des journaux d’activité (logs) ;
l’acquisition des outils de détection et de confinement ;
la mise en place d’un système de ticketing pour suivre les incidents ;
des plans de continuité d’activité ;
des exercices de simulation et des formations à la gestion de crise ;
une assurance cyber adaptée.
2. Détection
La détection consiste à identifier les signes précurseurs ou manifestes d’un incident de sécurité. Cette étape repose sur la corrélation d’événements issus de multiples sources de données.
Parmi les signaux d’alerte fréquents, on peut citer :
un nombre inhabituel de tentatives de connexion échouées ;
accès inhabituels à certains services ;
élévations de privilèges injustifiées ;
données manquantes ou systèmes anormalement lents ;
panne du système ;
comportements suspects détectés par les outils EDR, SIEM ou CSPM.
Ces signaux peuvent provenir de diverses sources telles que :
télémétrie des workloads ;
logs des fournisseurs cloud ;
renseignements sur les menaces (threat intelligence) ;
retours des utilisateurs ou partenaires.
Mais, dans tous les cas, une détection précoce est essentielle pour contenir la menace avant qu’elle ne se propage.
3. Enquête et analyse
Une fois l’incident de sécurité confirmé, la phase d’analyse vise à comprendre ce qui s’est passé pour dresser un tableau complet de l’incident. Elle permet de déterminer :
la cause racine de l’incident ;
son étendue et quels systèmes ou données ont été touchés ;
les points d’entrée et les vulnérabilités exploitées.
Cette étape implique donc d’examiner en détail les journaux systèmes, les alertes de sécurité et les indicateurs de compromission. Ainsi, la phase d’analyse guide la prise de décision pour les prochaines étapes : confinement, éradication et remédiation.
4. Confinement

L’objectif du confinement est de limiter la propagation de l’attaque et de réduire son impact opérationnel. Mais, les méthodes varient selon le type d’incident et le type d’infrastructure.
En environnement traditionnel : outils de type EDR (Endpoint Detection & Response),
En environnement cloud : ajustement rapide des groupes de sécurité via le plan de contrôle. Par exemple, isolement d’un bucket ou d’une VM compromise pour empêcher tout mouvement latéral de l’attaque.
Dans tous les cas, cette étape sert à gagner du temps pour éradiquer la menace tout en assurant une continuité minimale des opérations.
Bon à savoir Gartner identifie la Cloud Investigation and Response Automation (CIRA) ou automatisation des enquêtes et des réponses dans le cloud en français comme une technologie stratégique pour renforcer sa posture de sécurité dans les environnements cloud-native. En effet, l’automatisation des réponses accélère la détection, réduit le temps de réaction et renforce la posture de sécurité. En résumé, le passage au cloud computing offre des opportunités sans précédent, mais introduit également de nouveaux risques.
5. Éradication
Une fois la menace contenue, l’étape suivante du cycle de vie de la réponse aux incidents consiste à l’éliminer complètement du système. Voici quelques exemples de solutions pour débarrasser vos systèmes d’une menace :
suppression de logiciels malveillants ou backdoors ;
réinstallation d’applications compromises ;
rotation des identifiants, mots de passe et tokens API ;
fermeture des ports ou points d’entrée exploités ;
application des correctifs de sécurité ;
revue et mise à jour du code IaC (infrastructure as code) ;
restauration des données saines.
Enfin, un scan complet des systèmes est indispensable après l’éradication pour vérifier l’absence de résidus de l’intrusion.
6. Examen post-incident
Dernière étape mais pas des moindres, l’analyse post-incident. C’est le moment de tirer les leçons de l’incident de sécurité pour renforcer ses défenses cloud. En effet, seul ce retour d’expérience permet d’améliorer ses processus, sa documentation, ses outils et la collaboration entre équipes.
Voici les bonnes questions à se poser :
Avons-nous identifié l’incident assez tôt ?
L’équipe d’intervention savait-elle quoi faire ?
Le plan d’intervention était-il clair et efficace ?
Quels sont les points à améliorer dans notre arsenal de sécurité ?
Comment éviter qu’un incident similaire se reproduise ?
Avons-nous respecté nos obligations de conformité ?
Enfin, un rapport d’incident documenté est souvent exigé par les autorités de régulation et constitue une base pour les audits futurs.
Si elles suivent ces six phases du cycle de vie de la réponse aux incidents, les organisations peuvent donc réagir avec méthode, rapidité et efficacité face aux cybermenaces tout en minimisant les impacts financiers, juridiques et réputationnels sur leur entreprise.
Continuité d’activité et reprise après sinistre (BCDR)
La continuité d’activité (BC pour Business Continuity) et la reprise après sinistre (DR pour Disaster Recovery) sont des composantes clés d’une stratégie de réponse aux incidents efficace. En effet, la continuité d’activité (BC) désigne les mesures préventives mises en œuvre pour maintenir les opérations essentielles pendant une perturbation. La reprise après sinistre (DR), quant à elle, se concentre sur le retour à la normale des systèmes critiques avec un minimum de perte de données ou de temps d’arrêt. Ensemble, elles garantissent donc que votre organisation peut continuer à fonctionner malgré une interruption et retrouver rapidement un état opérationnel normal après un incident.
Ainsi, ces deux volets doivent être étroitement alignés avec votre plan de réponse aux incidents pour :
déclencher les procédures BCDR au moment opportun dans le cycle de vie de l’incident ;
éviter que la menace ne persiste ou ne se propage pendant la phase de reprise.
Voici quelques éléments à considérer pour une coordination efficace entre BCDR et gestion des incidents :
la sécurité des systèmes de basculement pour éviter toute compromission secondaire ;
les bonnes pratiques de sauvegarde et de restauration, sans infection ni faille résiduelle ;
la priorisation des systèmes à restaurer selon leur impact métier ;
la cartographie claire des dépendances entre systèmes pour éviter les effets en cascade.
Dans un contexte cloud-native, l’intégration de la BCDR dans la posture de sécurité globale est donc essentielle pour garantir une résilience continue face aux menaces émergentes.
Outils et technologies de réponse aux incidents
Disposer des bons outils de sécurité cloud-native est fondamental pour détecter, analyser, contenir et éliminer rapidement les menaces. C’est pourquoi, une réponse efficace repose sur une combinaison cohérente d’outils et de technologies spécialisés couvrant l’ensemble du cycle de vie d’un incident.
| Technology | Description | Role in response lifecycle |
|---|---|---|
| Détection et réponse aux menaces (TDR) | Outils conçus pour surveiller, détecter et remédier aux activités malveillantes dans les environnements cloud et traditionnels. Inclut les solutions EDR (endpoint) et CDR (cloud). | Détection, investigation, confinement et élimination |
| Gestion des informations et des événements de sécurité (SIEM) | Plateforme qui agrège et corrèle les logs, alertes et événements pour fournir une visibilité centralisée sur les menaces potentielles. | Détection et investigation |
| Orchestration, automatisation et réponse en matière de sécurité (SOAR) | Plateforme unifiée permettant d’orchestrer l’ensemble des outils de sécurité, d’automatiser les workflows de réponse et de standardiser les interventions. | Détection, investigation, confinement et éradication |
| Système de détection et de prévention des intrusions (IDPS) | Outil traditionnel qui analyse le trafic réseau pour identifier et bloquer les menaces avant qu’elles n’atteignent les systèmes cibles. | Détection et investigation |
| Plateforme de renseignements sur les menaces (TIP) | Système qui centralise les renseignements sur les menaces connues (indicateurs de compromission et tactiques d’attaque) pour une détection et une priorisation plus rapide des incidents. | Détection, investigation, confinement et éradication |
| Gestion des vulnérabilités basée sur les risques (RBVM) | Solution de sécurité qui identifie les vulnérabilités critiques dans son environnement en hiérarchisant leur correction selon le risque réel pour l’organisation. | Confinement et éradication |
Ainsi, une plateforme cloud-native de réponse aux incidents comme celle de Wiz intègre naturellement plusieurs de ces technologies pour fournir une approche unifiée et automatisée essentielle à la protection des environnements modernes.
Wiz pour la réponse aux incidents cloud-native
Wiz propose une solution complète de Cloud Detection & Response (CDR) conçue pour répondre plus rapidement et plus efficacement aux incidents de sécurité dans des environnements cloud complexes. Ainsi, avec son approche cloud-native, Wiz transforme quotidiennement la manière dont les organisations détectent, analysent et neutralisent les menaces cloud.
Détection contextualisée des menaces : Wiz corrèle les signaux de sécurité en temps réel avec l’activité du cloud dans une vue unifiée. Cette contextualisation permet d’identifier rapidement les mouvements latéraux des attaquants et de hiérarchiser les alertes selon leur niveau de risque réel. Ainsi, on subit moins de faux positifs, donc moins de signaux inutiles et une meilleure concentration sur les incidents critiques.
Surveillance cloud-native en continu : Wiz surveille de manière proactive les workloads et l’activité du cloud pour détecter des comportements malveillants, même inédits. Ainsi, contrairement aux outils traditionnels, cette approche s’adapte parfaitement à la dynamique des environnements cloud-native.
Playbooks de réponse automatisée : la plateforme propose des playbooks de réponses aux incidents prêts à l’emploi qui automatisent la collecte de preuves, l’analyse initiale et l’isolation des ressources affectées. Ainsi, les équipes d’intervention gagnent un temps précieux lors des phases de confinement, d’éradication et de reprise.
Analyse via graphe de sécurité : le Security Graph de Wiz fournit des automatisations d’analyse des causes profondes et du rayon d’impact. Ainsi, il identifie les chemins d’attaque potentiels et répond aux questions essentielles : comment une ressource a-t-elle été compromise et quel est l’impact global ?
Pour en savoir plus (en anglais)
Cloud Forensics intégré : Wiz facilite les investigations grâce à la collecte automatisée de preuves : copie de volumes VM, extraction de logs, artefacts de sécurité et inspection runtime. Cela donne donc aux équipes IR une base solide pour comprendre ce qui s’est réellement passé.
Évaluation précise du rayon d’impact : grâce au Security Graph, les analystes peuvent rapidement évaluer l’étendue d’un incident, cartographier les chemins d’attaque exploités et anticiper les impacts métier potentiels.
Pour en savoir plus (en anglais)
Surveillance en temps réel du runtime : Wiz ajoute une couche essentielle à l’analyse des incidents : la surveillance du runtime. Ainsi, elle détecte les actions suspectes menées par des identités machines ou utilisateurs offrant un contexte supplémentaire à chaque alerte.
Protégez votre environnement cloud avec Wiz
Dans un monde où les attaques évoluent plus vite que jamais, réagir efficacement aux incidents cloud-native est devenu indispensable. Grâce à sa vision unifiée, ses automatisations intelligentes et son graphe de sécurité, Wiz permet aux équipes IR de reprendre le contrôle face aux menaces modernes.
Vous voulez renforcer votre posture de sécurité et réagir plus vite aux incidents ? Alors demandez une démo et découvrez comment Wiz peut transformer efficacement votre réponse aux incidents cloud-native.