



Le Server-side request forgery (SSRF) est une vulnérabilité critique de sécurité où un acteur malveillant manipule un serveur pour qu’il effectue des requêtes HTTP en son nom, souvent vers des services internes non exposés publiquement.
En effet, un serveur fait généralement confiance à son propre environnement. Ainsi, des URL malicieuses peuvent être traitées sans méfiance, révélant des API internes, des services de métadonnées ou d’autres données sensibles. Le SSRF peut survenir même lorsque des systèmes se trouvent protégés derrière un VPN, un pare-feu ou une liste de contrôle d’accès réseau (ACL). De ce fait, le SSRF a été ajouté à l’OWASP Top 10 en 2021 et figure parmi le CWE Top 25 de MITRE des faiblesses logicielles les plus dangereuses.
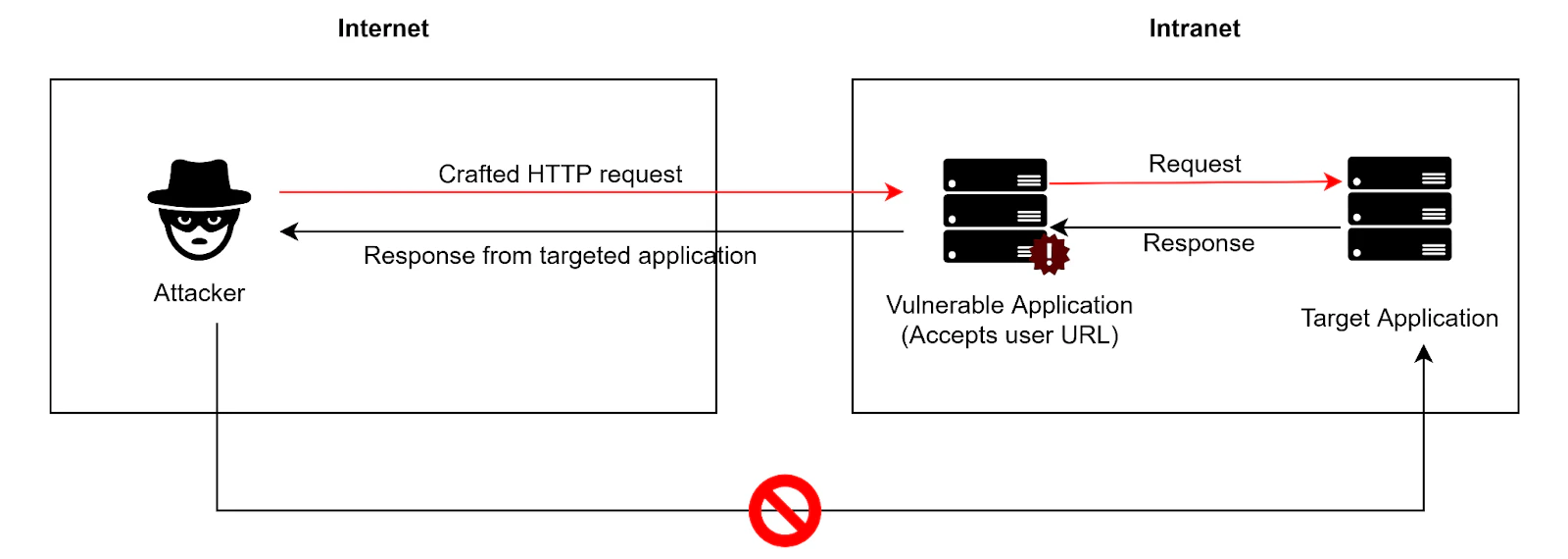
En apparence, le SSRF ressemble à un simple proxy d’URL fournies par l’utilisateur. En réalité, c’est une porte d’entrée vers des endpoints de métadonnées cloud et des ressources réseau privées. Cela en fait une vulnérabilité particulièrement dangereuse dans les architectures cloud et microservices. Au-delà de l’accès non autorisé à des données système sensibles, d’autres impacts incluent le scan de ports internes et l’enchaînement d’exploits vers d’autres attaques, telles que l’exécution de code à distance et l’XSS réfléchi. Le SSRF est donc l’une des raisons majeures pour lesquelles la visibilité continue sur les API et la validation stricte des URL sont absolument essentielles.
Dans cet article, nous allons voir comment détecter et prévenir les attaques SSRF. Mais, commençons par comprendre le fonctionnement précis d’une attaque SSRF et où se situe exactement le risque.
Advanced API Security Best Practices [Cheat Sheet]
Download the Wiz API Security Best Practices Cheat Sheet and fortify your API infrastructure with proven, advanced techniques tailored for secure, high-performance API management.

Fonctionnement d’une attaque SSRF : un exemple concret
Les applications qui proposent des fonctionnalités acceptant une URL fournie par l’utilisateur et la récupérant côté serveur sont des cibles classiques de SSRF. On pense notamment aux aperçus d’images, aux services de « unfurling » de liens, aux convertisseurs web-vers-PDF, aux récupérateurs de métadonnées, etc. Si le serveur suit aveuglément les redirections ou ne restreint pas les destinations autorisées, un attaquant peut alors diriger le serveur vers des adresses internes, des hôtes de métadonnées cloud en link-local ou des plages IPv6 locales/ULA.
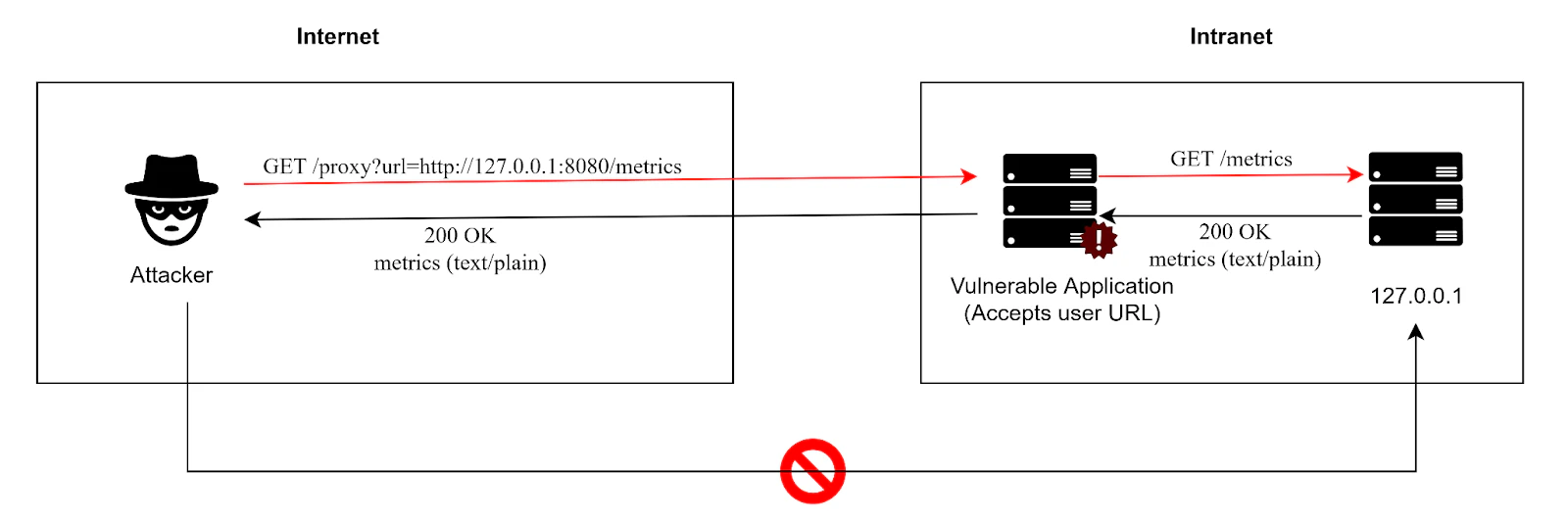
Par exemple, le route handler Express.js ci-dessous récupère toute URL fournie par l’utilisateur. Comme il s’exécute à l’intérieur du périmètre de confiance de l’application, il peut accéder à des réseaux et services qu’un attaquant ne pourrait pas atteindre directement. Ainsi, une attaque SSRF se produit lorsqu’un utilisateur malveillant fournit une URL telle que http://127.0.0.1:8080/metrics, amenant le serveur à requêter des données internes et à les renvoyer directement à l’attaquant :
app.get("/proxy", async (req, res) => {
const target = req.query.url;
const resp = await fetch(target, { redirect: "follow" });
const body = await resp.text();
res.type(resp.headers.get("content-type") || "text/plain").send(body);
});Dans des systèmes centrés sur les API, le risque SSRF augmente considérablement lorsque des endpoints autorisent une saisie d’URL dynamique sans validation adéquate :
API qui génèrent des aperçus d’images ou de vidéos à partir de liens fournis par des utilisateurs
Gestionnaires de téléversement de fichiers acceptant des URL distantes
Processeurs de webhooks et intégrations tierces qui appellent des URL arbitraires
Ces fonctionnalités agissent donc comme des proxies ouverts à l’intérieur du périmètre de confiance du système, ouvrant la porte à des accès non autorisés.
Payloads SSRF courants
Il existe plusieurs payloads (charges utiles) SSRF prévisibles pointant vers des services de métadonnées et des endpoints internes uniquement. Parmi les exemples couramment ciblés, on retrouve :
http://169.254.169.254/latest/meta-data/:Il s’agit du service de métadonnées des instances AWS EC2, une cible particulièrement prisée car il peut divulguer des identifiants de rôles IAM. Des endpoints similaires existent également sur GCP et Azure.http://localhost/admin:Les applications disposent souvent de consoles d’administration locales non destinées à un accès externe mais atteignables via SSRF.http://internal-service.local/api/keys:Des microservices internes peuvent exposer des API sensibles devenant accessibles si le SSRF permet la traversée du réseau interne.Chaînes de redirections (Ex.:
http://evil.com/redirect?url=http://localhost): Les attaquants exploitent les redirections ouvertes pour pivoter depuis un domaine apparemment bénin vers des cibles privées ou internes.
Inside the vault: how financial institutions protect their cloud environments
En savoir plus

Dangerosité particulière du SSRF dans le cloud
Une combinaison toxique se forme lorsque des facteurs de risque coexistent dans des environnements cloud :
l’exposition publique ;
l’absence ou la faiblesse de l’autorisation ;
des permissions excessives ;
la proximité de données sensibles.
Résultat : des vulnérabilités SSRF à fort impact peuvent se transformer en violations de données majeures.
Malheureusement, ces vulnérabilités peuvent facilement passer inaperçues. Par exemple, lorsque AWS IMDSv1 (Instance Metadata Service v1) est activé, une simple requête côté serveur vers l’endpoint de métadonnées de l’instance peut renvoyer des identifiants de rôle temporaires. Il est donc crucial d’imposer IMDSv2 (HttpTokens=required) et de définir correctement HttpPutResponseHopLimit. AWS recommande une valeur de 2 pour les environnements conteneurisés afin d’éviter les ruptures via des chemins NAT. N’utilisez 1 que si vous avez vérifié que les workloads fonctionnent correctement. Cette configuration réduit significativement l’impact du SSRF, en particulier lorsque le primitif SSRF ne peut pas envoyer de requêtes PUT ou d’en-têtes personnalisés. Source : AWS EC2 User Guide
La violation chez Capital One en 2019 illustre parfaitement comment un SSRF peut être exploité pour passer d’une erreur de configuration initiale à une fuite de données à grande échelle. Le point d’entrée de ce chemin d’attaque était un WAF mal configuré sur une instance EC2. Après avoir obtenu l’accès, les acteurs malveillants ont utilisé un SSRF pour récupérer des identifiants de rôle IAM temporaires via des requêtes vers le service de métadonnées AWS. Or, le rôle IAM exploité disposait de permissions excessives et d’un accès direct à des buckets S3, entraînant une fuite massive de données. Ainsi, les attaquants ont pu lister et exfiltrer près de 30 Go de demandes de crédit, incluant des PII extrêmement sensibles de plus de 100 millions de clients de Capital One (numéros de sécurité sociale, scores de crédit, etc.).
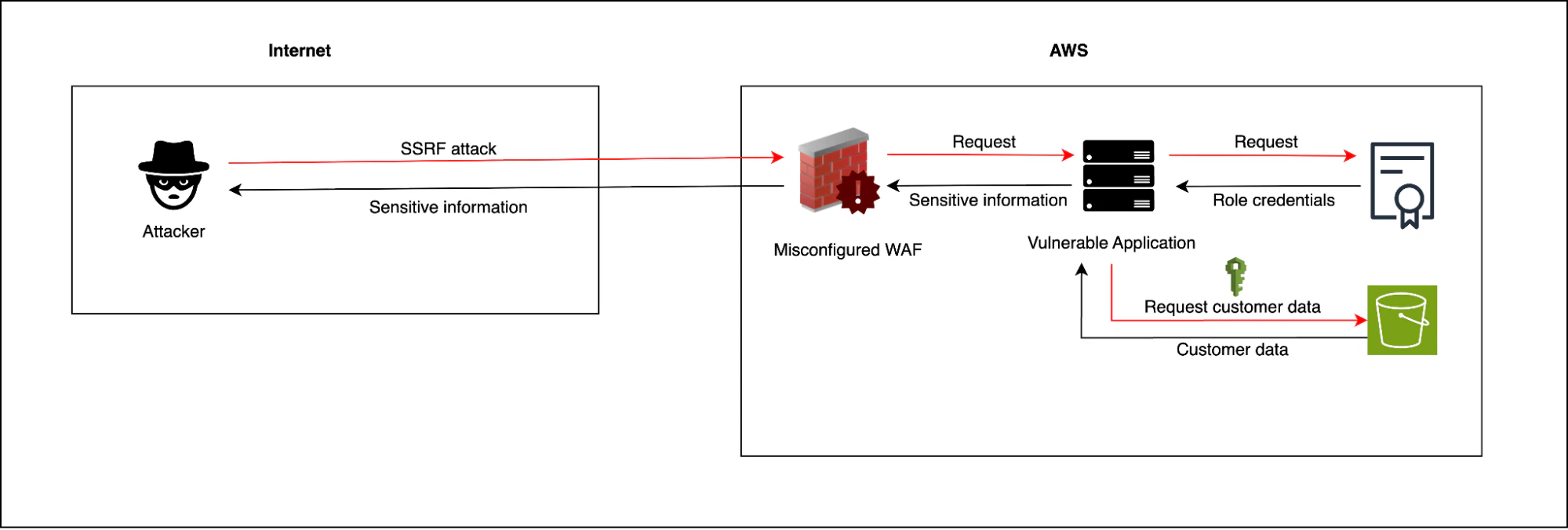
À retenir : Le cloud amplifie considérablement l’impact du SSRF. Aujourd’hui, ces attaques sont plus rapides et plus dommageables que jamais, ce qui fait de leur détection et de leur prévention une priorité absolue. Pour hiérarchiser efficacement les risques SSRF formant des combinaisons toxiques, il est essentiel de disposer d’un contexte reliant exposition publique, permissions d’identité, sensibilité des données et comportement runtime.

Détection et prévention du SSRF : bonnes pratiques pour les applications cloud
Les bonnes pratiques présentées ci-dessous sont efficaces pour empêcher des attaques SSRF de faire le pont entre des endpoints publics peu sécurisés et des systèmes internes sensibles. Gardez cependant en tête que détection et prévention doivent être traitées comme un processus continu et évolutif. En effet, relier les détections et les contrôles à leurs responsables (code, pipeline, service et données) accélère la remédiation et réduit significativement le temps moyen de résolution (MTTR).
Méthodes de détection
Surveillez les flux sortants pour détecter des anomalies : suivez en continu les requêtes sortantes des workloads et des API vers des plages IP privées et internes (par exemple
RFC1918, 127.0.0.0/8), les adresses link-local (y compris les IP de métadonnées cloud comme AWS169.254.169.254etIPv6 [fd00:ec2::254]), ainsi que les plages locales IPv6 (par ex,::1/128 loopback). Déclenchez des alertes dès que ces requêtes proviennent de services qui n’ont normalement pas besoin d’accéder à des endpoints privés ou de métadonnées.Détectez les chaînes de redirections suspectes : les attaquants exploitent souvent des URL sur liste blanche qui émettent une redirection 301/302 vers une cible interne. Pour éviter cela, maintenez une visibilité complète sur les requêtes HTTP et leurs redirections et signalez immédiatement les chaînes où le dernier saut se résout vers une IP privée ou de métadonnées.
Exploitez l’échantillonnage des requêtes runtime : capturez périodiquement les requêtes HTTP sortantes, y compris les URL complètes et les en-têtes associés, afin d’identifier des destinations suspectes pendant les opérations courantes.
Des outils open source comme SSRFire et ZAP peuvent tester activement des points d’injection SSRF et aider à valider l’acheminement des payloads et des callbacks hors bande. Toutefois, ils ne sont pas conçus pour surveiller le trafic runtime à la recherche d’anomalies en continu.
Cross-Site Request Forgery (CSRF): Examples and Prevention
Discover how CSRF attacks work, identify common vulnerabilities, and learn the best methods for preventing CSRF attacks to keep your applications secure.
En savoir plus
Méthodes de prévention
Utilisez cette checklist actionnable pour lancer votre stratégie de prévention SSRF et renforcer votre posture de sécurité :
1. Validation des entrées
Analysez et normalisez les URL avant traitement. Évitez de vous reposer uniquement sur des expressions régulières ; imposez des listes blanches de schémas autorisés, canonicalisez les noms d’hôte et résolvez à nouveau le DNS à chaque saut de redirection. Utilisez des bibliothèques d’analyse d’URL qui normalisent et valident l’entrée par rapport à une liste blanche de schémas autorisés (par ex. http, https) et rejettent explicitement les schémas dangereux tels que
file://, gopher://, or ftp://.Imposez des listes blanches strictes d’hôtes ou de domaines autorisés pour les fonctionnalités qui récupèrent du contenu distant. Résolvez les noms d’hôte en IP au moment de la validation et vérifiez qu’ils appartiennent à la liste blanche pour bloquer efficacement les attaques de DNS rebinding.
Rejetez les schémas d’URL non utilisés (
file://, gopher://, ftp://, dict://, gestionnaires personnalisés). Le plus sûr est de n’autoriser que HTTP et HTTPS tant qu’aucun cas d’usage métier ne justifie l’utilisation d’autres schémas.Bloquez les destinations qui se résolvent vers des adresses loopback, privées, link-local ou de métadonnées. Appliquez systématiquement ces contrôles à la résolution initiale, lors des redirections et au moment de la connexion effective.
2. Network-level controls
Deny unnecessary egress by default. Block outbound traffic to private and local ranges unless explicitly required. Cover
IPv4 127/8, 10/8, 172.16/12, 192.168/16, 169.254/16 and IPv6 ::1/128, fc00::/7, fe80::/10. Imposez ces contrôles sur les passerelles egress, NAT et proxies pour tout le trafic routable.Restreignez l’accès aux services de métadonnées. Traitez les endpoints de métadonnées comme link-local et bloquez-les avec des contrôles au niveau hôte ou nœud. Sur Kubernetes, appliquez des politiques egress CNI pour les pods n’ayant pas besoin des métadonnées. Assurez-vous que les endpoints
IPv4etIPv6 IMDSsont correctement bloqués selon la documentation actuelle du fournisseur cloud. Source : AWS EC2 User GuideMettez en place des listes blanches d’egress pour le trafic HTTP/HTTPS sortant, limitées aux destinations strictement nécessaires, afin de prévenir la data exfiltration vers des réseaux externes si une attaque se produit.
Sur Kubernetes, utilisez des NetworkPolicies pour refuser l’egress par défaut, bloquez les endpoints de métadonnées
IPv4etIPv6à l’échelle du cluster, préférez IRSA (IAM Roles for Service Accounts) ou Workload Identity aux métadonnées de nœud et envisagez une passerelle egress mesh pour gérer efficacement les listes blanches de domaines et l’application du TLS.
3. Défenses cloud-native
Utilisez IMDSv2 sur AWS. Imposez des limites de sauts appropriées, exigez des jetons de session et désactivez complètement l’IMDSv1 moins sécurisé s’il était utilisé auparavant.
Appliquez les bonnes pratiques avec Azure Instance Metadata Service (IMDS). Spécifiez toujours la version d’API, ajoutez l’en-tête requis Metadata: true, obtenez des jetons d’accès d’identité managée et minimisez strictement les permissions attribuées.
Sur GCP, activez Workload Identity et assurez-vous que les requêtes incluent systématiquement l’en-tête Metadata-Flavor: Google ; évitez les clés de comptes de service longue durée et limitez strictement les identités runtime.
Limitez la durée de vie et les permissions des jetons car les payloads SSRF cherchent souvent à capturer ces jetons avant leur rotation automatique.
Désactivez les services cloud inutilisés au niveau compte ou projet pour réduire significativement votre surface d’attaque et restreindre les cibles potentiellement atteignables.
4. Contrôles spécifiques aux API
Identifiez et documentez les shadow APIs afin de garantir leur gouvernance appropriée et leur supervision continue.
Imposez l’authentification et la validation des jetons sur tous les endpoints. Pensez aussi à détecter les erreurs de configuration d’autorisation dans les tokens JWT.
Surveillez en continu les modèles de requêtes API pour repérer rapidement des anomalies comme des pics inhabituels de paramètres d’URL ou des appels vers des domaines non approuvés.
Appliquez des rôles IAM selon le principe du moindre privilège (PoLP) aux workloads API afin qu’un seul compromis SSRF ne permette pas un mouvement latéral étendu dans votre infrastructure.
Maintenez un inventaire d’API exact et à jour pour obtenir une visibilité complète, éliminer tout angle mort et évaluer rapidement l’exposition réelle pendant des incidents de sécurité.
La prévention efficace du SSRF ne repose pas sur un seul type de contrôle isolé. Elle combine une sanitation et une validation strictes des entrées, une supervision et une segmentation rigoureuses du réseau, ainsi qu’une gouvernance API continue et proactive. Un moteur de politiques unifié couvrant le code, le CI/CD, le cloud et le runtime garantit la cohérence et l’efficacité des défenses SSRF à mesure que les services évoluent et se transforment.
En complément, de nombreuses organisations utilisent des outils de sécurité sensibles au runtime. Elles obtiennent ainsi une meilleure visibilité sur le comportement des applications en environnements de production et de préproduction. Des outils comme Falco, ZAP et Burp Suite aident à détecter des motifs SSRF en surveillant les requêtes, en observant le comportement réseau et en validant les réponses applicatives dans des conditions de test contrôlées.
Ces outils s’inscrivent souvent dans une approche de sécurité plus large et stratégique. En effet, beaucoup d’équipes combinent des informations runtime avec du contexte au niveau plateforme. Ainsi, elles comprennent mieux comment les risques se rattachent à l’architecture applicative, aux identités cloud et aux services exposés. Des plateformes comme Wiz intègrent ces informations contextuelles en une vue unifiée. Cela aide énormément les équipes sécurité et engineering à prioriser intelligemment les risques SSRF selon leur impact réel et à les traiter plus tôt dans le cycle de développement.
Wiz aide à sécuriser vos API et à réduire l’exposition au SSRF
La plupart des recommandations de prévention SSRF partent du principe que vous connaissez parfaitement chaque API exécutée dans votre environnement. Or, beaucoup d’organisations peinent à suivre ce rythme : les environnements cloud évoluent très vite, rendant impossible la mise à jour d’inventaires statiques. Chaque nouveau déploiement apporte de nouveaux endpoints, et il arrive fréquemment que des développeurs intègrent de nouvelles API en dehors des processus officiels. Résultat : des shadow APIs se glissent en production sans être détectées ni supervisées.
Fournir une visibilité totale sur chaque point de terminaison API, c’est précisément là que Wiz excelle.
Wiz propose une approche moderne de la sécurité des API avec des solutions conçues spécifiquement pour les environnements cloud. Notre plateforme de référence vous permet de :
découvrir automatiquement tous les endpoints API et leur contexte d’hébergement complet ;
cartographier précisément les modèles d’accès, les données sensibles et les erreurs de configuration d’authentification ;
faire remonter les combinaisons toxiques comme des endpoints publics récupérant des données internes sensibles ;
offrir un tableau de bord unifié de sécurité des API donnant aux équipes une vue claire et globale de l’exposition réelle pour réduire rapidement le risque, sans se reposer sur des suppositions hasardeuses ni sur des outils fragmentés.
Prêt à prioriser intelligemment la remédiation, à réduire significativement votre surface d’attaque et à garder une longueur d’avance sur les menaces potentielles ? Demandez une démo personnalisée de Wiz dès aujourd’hui !
Catch code risks before you deploy
Learn how Wiz Code scans IaC, containers, and pipelines to stop misconfigurations and vulnerabilities before they hit your cloud.
