

Understanding attack surface scanning in modern environments
Attack surface scanning is the practice of continuously discovering and assessing everything you have exposed to the internet. This means you continuously watch every public domain, IP, API, and cloud endpoint that an attacker could try to reach.
In older, on‑prem environments, you usually knew your perimeter and could list your internet-facing systems by hand. Today, you spin up and tear down cloud resources, SaaS apps, and AI services so quickly that static lists stop working. According to PwC's 2025 Global Digital Trust Insights survey, 67% of security leaders report GenAI has expanded their attack surface over the past year.
Modern attack surface scanning has to discover assets you didn't plan for. That includes shadow IT projects, forgotten test environments, and misconfigured cloud storage that traditional asset management never recorded.In 2025, 20% of organizations reported breaches linked to 'shadow AI,' with average breach costs rising by approximately $670,000 according to industry analysis.
The scanning itself looks like continuous probing from the outside. You send simple requests to external services to see what is open, how it is configured, and whether there are obvious weaknesses you should fix.
You will hear a few recurring terms in this space:
External attack surface: All assets reachable from the public internet.
Internet-facing assets: Systems that accept traffic directly from outside your network.
Shadow IT: Systems built or deployed without going through your standard process.
Digital footprint: The total set of domains, IPs, and services that represent you online.
You can think of attack surface discovery as building a living map of that footprint. External attack surface scanning and cyber asset attack surface management are simply structured ways to keep that map accurate and useful.
AWS Security Cheat Sheet
Get the essential AWS security controls and best practices in one comprehensive reference guide.

Asset discovery and inventory management
Asset discovery is the first big question you need to answer: "What do we actually have exposed right now?" You start by mapping every external-facing asset across your digital estate, not just the ones in your CMDB.
That usually covers:
Domains and subdomains: All DNS names, including old and delegated ones.
IP addresses and ranges: Both static and dynamic, across data centers and clouds.
Cloud resources: Load balancers, storage endpoints, managed services with public access.
APIs and web apps: Any endpoint that accepts HTTP or other protocols from the internet.
Certificates: TLS certificates that hint at hidden hostnames and services.
You can use passive techniques to gather candidates. DNS enumeration, WHOIS/RDAP records, and certificate transparency logs will surface names and addresses with almost no impact on production systems.
Then you combine this with active scanning to see what is really live. You probe those addresses to check which ports respond, what services they run, and whether they still belong to you.
Shadow assets are where a lot of surprises live. These might be developer‑owned test servers, proof‑of‑concept deployments, or resources created as part of an acquisition that never got fully integrated.
Cloud provider APIs are powerful tools for this. By querying AWS, Azure, GCP, and others, you can list current public IPs, endpoints, and resources even if no DNS record points to them.
A common pattern looks like this:
Asset enumeration: Build the full list from DNS, certificates, and cloud APIs.
Subdomain discovery: Sweep for all hostnames under your domains.
Certificate transparency checks: Spot hidden hostnames from issued certificates.
Shadow assets inventory: Flag anything not tied to an official owner or system of record.
When a major issue like Log4j appears, organizations that already have this inventory can search once and know where they are exposed. That is much easier than trying to build the list in a panic after the fact.


Implementing continuous scanning strategies
Once you find your assets, the next question is "How often do we look at them?" In fast‑moving environments, running a scan once a quarter or even once a month is not enough.
Continuous scanning means you always have a reasonably fresh view of your attack surface. You do not necessarily scan everything every minute, but you design a cadence that matches how risky and how dynamic each asset is.
A simple pattern looks like this:
Critical production apps: Near real-time or very frequent checks.
Standard production services: Daily or multi‑day scans.
Dev and test environments: Daily or weekly, as long as they cannot silently become public.
Change detection is the core idea. You care most about when new services appear, ports open, certificates change, or security settings drift from your baseline.
You can use events to trigger scans at the right time. For example, when your cloud platform allocates a new public IP, or when your CI/CD pipeline deploys a new internet-facing service, you immediately kick off a targeted scan.
Some helpful terms here:
Continuous monitoring: Keeping scanners running regularly instead of doing one‑off tests.
Scanning cadence: The schedule you pick for each group of assets.
Baseline drift: Gradual configuration changes that move systems away from your intended secure state.
Event‑driven scanning: Launching scans when something changes rather than on a fixed clock.
This approach helps you catch risky changes shortly after they are introduced. It also keeps the volume of scan data manageable, because you are focusing on what actually changed.


Context-driven risk assessment and prioritization
After you find exposures, you face the next big question: "Which ones should we fix first?" Not every open port or public endpoint is equally dangerous.
Context-driven risk assessment means you never look at an exposure in isolation. You link it to what it can reach, what data it touches, and what identities and privileges sit behind it.
Here's a simple example. A small test site open to the internet is less of a problem if it is fully segmented from production and holds no sensitive data. A narrow admin API with no login page, but direct access to your payment systems, is far more serious even if it looks less "obvious" at first glance.
You can bring internal context into your decisions by correlating:
Identity and access data: Who or what can do dangerous actions behind that endpoint.
Network segmentation: Which networks and services the exposed asset can reach.
Data classification: Whether sensitive or regulated data is accessible from there.
Existing vulnerabilities: Whether the backing workload has known exploitable flaws.
When several of these align, you get a toxic combination. That is when an attacker can move from a public point of entry through a series of weaknesses to a crown jewel system or dataset.
In practice, you want to focus remediation on exposures that create complete attack paths. Those are the ones that represent actual attack surface risk, not just theoretical misconfigurations.
Attack Path Analysis (APA) Explained
Attack path analysis (APA) is a cybersecurity technique that identifies and maps how potential attackers could infiltrate your network and systems
Read more
Cloud-native attack surface challenges
Cloud-native architectures make your attack surface more dynamic and harder to see. Resources are not static servers anymore; they are containers, functions, and managed services that appear and disappear quickly.
Ephemeral infrastructure is a big part of this. Containers and auto‑scaled instances may only exist for minutes, but if they are internet-facing during that time, they still add risk.
Cloud providers also assign IP addresses and DNS names in their own ways. A public storage bucket, for example, might be reachable at a provider-owned hostname (like s3.amazonaws.com/bucket-name) that isn't tied to your primary domains, so DNS-only discovery can miss it.
Operating in more than one cloud adds another layer of complexity. AWS, Azure, and GCP all have their own service names, exposure patterns, and default settings.
To keep up, you need to normalize findings across clouds. A misconfigured storage bucket in one provider should be treated similarly to an open storage account in another.
Cloud-native attack surface management has to understand provider-specific issues:
AWS exposures:
S3 buckets with public read/write ACLs or bucket policies
EC2 instances with public IPs and permissive security groups
Lambda function URLs without authentication
RDS databases with public accessibility enabled
IMDSv1 metadata service accessible from compromised instances
Azure exposures:
Blob Storage containers with anonymous access
Virtual machines with public IPs and open NSG rules
Azure Functions with anonymous HTTP triggers
SQL databases with 'Allow Azure services' enabled
Managed identities with excessive role assignments
GCP exposures:
Cloud Storage buckets with allUsers or allAuthenticatedUsers permissions
Compute Engine instances with external IPs and permissive firewall rules
Cloud Functions with unauthenticated invocation
Cloud SQL instances with public IPs
Service accounts with overly broad IAM bindings
Each provider uses different terminology and default settings, so normalize findings to consistent risk categories across clouds.
Some key terms:
Ephemeral infrastructure: Short‑lived compute resources like containers and spot instances.
Auto-scaling resources: Systems that grow and shrink automatically based on load.
Cloud service provider APIs: Native APIs you query to find and monitor resources.
Metadata service exposure: When an instance's metadata endpoint can be hit by attacker‑controlled code.
If your scanning ignores these patterns, you end up with blind spots even if your traditional perimeter looks clean. Cloud attack surface management is about closing those gaps.
What is External Attack Surface Management (EASM)?
External Attack Surface Management (EASM) refers to the process of identifying, analyzing, and managing an organization's external attack surface.
Read moreIntegration with security workflows and tools
Once you are detecting exposures, the next question is "How do we actually get them fixed?" If findings live in a separate console no one owns, they will sit there.
You want attack surface scanning to plug into the tools your teams already use. That usually means ticketing systems, SIEM, SOAR, and your existing vulnerability management platform.
A typical workflow might look like this:
Ticket creation: High‑priority exposures automatically create tickets in your issue tracker.
Ownership context: Each ticket is tagged with the owning app, team, or service.
Status sync: Closing an exposure in your platform updates the ticket, and vice versa.
APIs are the glue that make this work. They let scanning platforms push findings into other tools and pull in extra context from them.
You may also hear about STIX and TAXII. These are standard formats and transport methods for sharing threat intelligence and indicators between tools. For exposure and telemetry normalization, many teams adopt schemas like OCSF (Open Cybersecurity Schema Framework).
This kind of security orchestration lets you automate the boring parts. Teams like Ansarada have used it to route new exposures directly to the relevant application owners, removing manual triage and cutting response times.
Platforms that unify scanning with graph context and ownership routing can auto-assign exposures to service owners via Jira or ServiceNow and track MTTR end-to-end, eliminating manual triage and routing delays.
Attack surface monitoring: Your first line of cloud defense
Attack surface monitoring involves continuously identifying and tracking internet-reachable assets. In cloud-native environments, where endpoints, identities, and services
Read more
Monitoring ephemeral and dynamic resources
A lot of your modern attack surface comes from things that do not live very long. You might have containers, serverless functions, or on‑demand environments that exist only for a single test run.
The challenge is simple: if you only run scans on a strict schedule, you may never see them. Attackers, on the other hand, only need that short window to try something.
To handle this, you can use snapshot-based scanning. You capture the configuration and state of a resource—open ports, software versions, permissions—as soon as it is created, then analyze it even if the resource disappears later.
Cloud-native APIs and event streams are useful here as well. You subscribe to events like "new function deployed," "new container pushed," or "new public IP allocated," and trigger scans whenever those events fire.
You also want to push scanning earlier in the lifecycle. By checking container images in registries, serverless packages before deployment, and infrastructure-as-code templates in your repositories, you catch exposures before they ever become live internet-facing endpoints.
Key concepts in this space include:
Ephemeral resource tracking: Keeping records on short‑lived resources and how they were configured.
Snapshot scanning: Taking a point‑in‑time capture for later analysis.
Event stream monitoring: Watching cloud and CI/CD events to drive near real‑time checks.
Container registry scanning: Reviewing images before they get used to run workloads.
This combination makes continuous attack surface management realistic even in highly dynamic environments. You stay ahead of exposures instead of chasing after them.
Watch 12-min demo
See how agentless scanning secures encrypted workloads across AWS, Azure, and GCP without compromising data protection.
Watch now
Automated response and remediation workflows
The next practical question is "How do we fix exposures quickly without burning out the team?" You do not want people manually repeating the same steps for every similar issue.
Automated remediation workflows, or playbooks, help here. They define exactly what should happen when a specific kind of exposure is found.
Common examples include:
Network issues: Closing unnecessary open ports or tightening security group rules.
Public access: Removing public IPs from services that should be internal only.
Credentials: Rotating keys or tokens that appeared in public code or responses—critical given reports that credential theft surged by 160% in 2025 and accounts for roughly one in five data breaches according to industry analysis.
You can run these playbooks directly from your attack surface management platform or invoke them via your SOAR tool. For high‑risk changes, you can keep a human in the loop to approve the fix before it runs.
Preventive controls are the next step up. If you scan infrastructure-as-code and block deployments that would open a dangerous exposure, you avoid creating many issues in the first place.
In Kubernetes, admission controllers can reject pods that break your security rules. That might include workloads with dangerous capabilities, host networking, or public exposure that you have not approved.
Attack surface reduction in the cloud
Attack surface reduction strategies help you keep up with fast-changing cloud environments by continuously identifying, validating, and shrinking the set of externally reachable assets and misconfigurations attackers can target.
Read more

Measuring attack surface scanning effectiveness
You improve what you measure, so you need to know whether your attack surface work is paying off. That means picking a small set of useful metrics and tracking them over time.
Some of the most helpful ones are:
Mean time to detect (MTTD): How long it takes you to find new internet‑facing assets after they appear.
Coverage: What percentage of your known IPs, domains, and accounts are under active scanning.
Mean time to remediate (MTTR): How long it takes you to fix confirmed high‑risk exposures.
False positive rate: How often findings turn out to be non‑issues after a quick review.
Attack path reduction: How many complete, validated paths from internet to crown jewels you have removed.
Ownership SLA attainment: Percentage of high-risk exposures remediated within team SLAs when routed with owner context.
You can use these metrics to see where the bottlenecks are. For example, good MTTD but poor MTTR usually points to process or ownership problems rather than tool gaps.
You should also look at how often your exposures show up in real incidents. If you see fewer breaches, fewer emergency changes, and fewer third‑party findings related to internet exposure, that is a strong sign your scanning program is working.
These measurements help you justify ongoing investment. They also highlight where to adjust your scanning configuration to reduce noise and improve coverage.
Attack surface management tools: 2026 comparison guide
Facing the attack surface head-on requires investing in top-tier solutions. Platforms that combine agentless discovery, context-based risk prioritization, and seamless developer workflow integration are your best bet.
Read more

Building a comprehensive attack surface scanning program
At this point, you have the "what," "how often," and "how to fix" pieces. The final big question is "How do we run this as a real program across teams?"
Start with clear ownership. Decide who runs the scanning platform, who responds to findings, and how security, IT, and development teams share responsibilities.
Then define your scanning scope. List which domains, IP ranges, cloud accounts, and business units are in scope today and how that will expand over time.
You also need policies for acceptable risk and remediation timelines. For instance, you might say that critical exposures on production admin systems must be fixed within a short, defined window, while lower‑risk issues on test systems can have longer.
Exceptions are a reality in most organizations. Sometimes a risky exposure is needed temporarily for a project or integration.
When that happens:
Document it: Record why the exception exists and who approved it.
Time‑limit it: Set an expiry date where it must be reviewed or retired.
Audit it: Make sure you can show auditors and leadership what is going on.
This is part of broader program governance. You also want to document your scanning methods, tool settings, and response playbooks, so new team members can operate them consistently.
Finally, clarify how attack surface management, vulnerability management, and continuous threat exposure management (CTEM) relate. Attack surface management focuses on external-facing exposures, vulnerability management addresses weaknesses everywhere, and CTEM provides the programmatic framework for continuous prioritization across both.
Advanced scanning techniques for complex environments
As your environment and applications grow more complex, you may need more advanced scanning techniques. Perimeter-only, unauthenticated scanning can miss important issues hidden behind login screens or complex protocols.
Authenticated scanning is one option. With proper authorization and least-privilege principles, you give the scanner limited credentials to mirror a normal user or service account and safely check for misconfigurations not visible from the outside.
You should keep these accounts minimal. They should have just enough permission to allow useful assessment without creating new risk.
Modern applications often rely heavily on APIs, GraphQL, and WebSockets. Standard web scanners do not always handle these well.
API discovery challenges include:
Unmanaged and shadow APIs appear when developers deploy endpoints outside the official API gateway. These might be test APIs, legacy integrations, or microservice-to-microservice communication accidentally exposed to the internet.
Spec drift happens when the actual API behavior diverges from OpenAPI/Swagger documentation. Scanners relying only on specs miss undocumented endpoints and parameters.
Gateway blind spots occur when API gateways route traffic but don't enforce authentication or rate limiting consistently across all paths.
GraphQL introspection can expose your entire schema if not disabled in production, revealing all queries, mutations, and data relationships to attackers.
WebSocket authentication gaps are common because WebSocket connections often bypass standard HTTP authentication after the initial handshake.
To cover these properly, combine API gateway logs, traffic analysis, code repository scanning, and active endpoint enumeration. Test for OWASP API Security Top 10 risks including broken object level authorization (BOLA), broken authentication, and excessive data exposure.
A hybrid approach works best. You combine active probing from outside, passive monitoring of traffic, and configuration analysis of your gateways and app settings.
When people ask "What is attack surface management really doing for me?" this is the answer. It pulls these different techniques together to reduce the number of ways an attacker can get from the internet to something you care about.
How Wiz streamlines attack surface scanning with context-driven insights
Wiz takes a context‑first approach to attack surface scanning so you do not just get a long list of exposed assets. You get a clear view of which exposures matter most and why.
Wiz ASM discovers known and shadow assets across multi‑cloud, on‑premises, SaaS, and AI environments using unified external scanning.
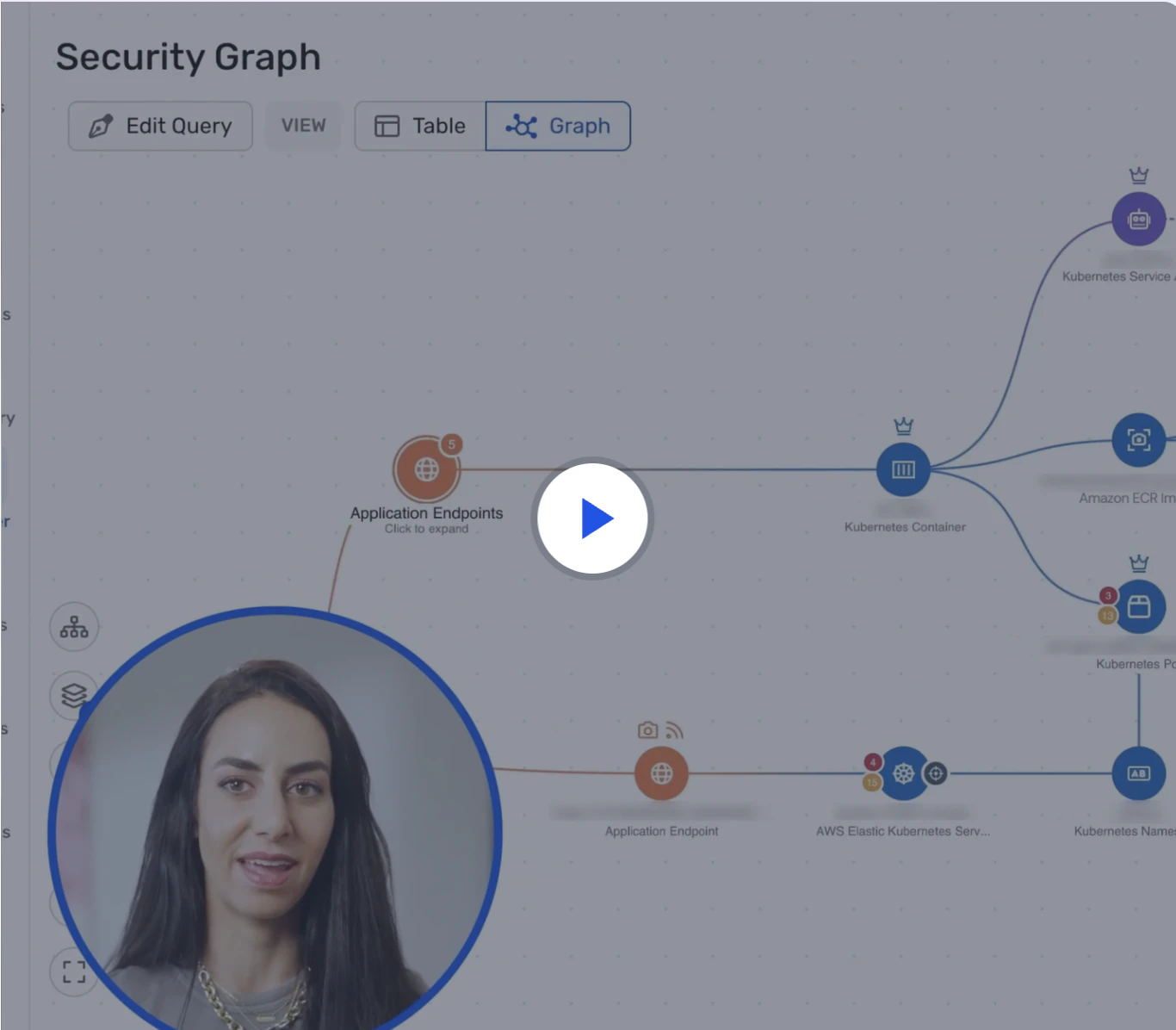
Wiz Security Graph connects each external exposure with internal context like vulnerabilities, identities, data, and network paths to highlight toxic combinations and true attack routes. The graph also maps ownership to projects, services, and teams so exposures are instantly routed to the right fix owners.
Agentless scanning builds a complete inventory of internet-facing cloud resources without agents or performance impact. Non-intrusive, agentless discovery pairs with safe, non-destructive validation to confirm real-world exploitability without impacting performance.
Code-to-cloud traceability links exposures to IaC templates, repos, and owning teams to fix root causes and prevent regressions.
Dynamic API scanning finds managed, unmanaged, and shadow APIs and assesses them against common API risks such as broken authentication, excessive data exposure, and injection. Findings align to OWASP API Security Top 10 to standardize remediation and reporting.
This combination lets you go from "we have an open endpoint" to "we know exactly how risky it is, who owns it, and how to fix it" in a single platform. That is the heart of modern, context-driven attack surface management. For a view that combines outside-in exposure validation with inside-out cloud context, explore Wiz's Attack Surface Management capabilities or request a live demo.
Surface the exposures that matter most
Detect critical exposures that span across your cloud, code, SaaS, APIs and more.
