Kubernetes is incredible, but there can be surprises when the bill arrives. The very abstractions that let your teams move with speed and agility also make it nearly impossible to see where resources—and your money—actually go. What you gain in deployment velocity, you can easily lose to opaque, runaway costs. Achieving transparency is about more than just shaving a few dollars off your cloud invoice; it's about building sustainable, efficient systems.
This blog post covers the ins and outs of cloud cost optimization in Kubernetes. We'll skip the usual clichés and get straight to advanced principles, practical strategies, and some emerging, hard-to-find techniques. The goal? To provide you with a framework for aligning cost, performance, and security.
Kubernetes Security Best Practices [Cheat Sheet]
This 6 page cheat sheet goes beyond the basics and covers security best practices for Kubernetes pods, components, and network security.

Challenges & common mistakes of Kubernetes cost optimization
If you've ever looked at a six-figure cloud bill and struggled to map it to specific microservices, you already know the pain. The problem isn't just one thing—it's a collection of interconnected issues inherent to how Kubernetes operates:
Overprovisioning due to "safety margins"
Developers often set CPU and memory requests with huge buffers. They'd rather waste resources than face the rage of the OOM Killer. These small, individual "just-in-case" decisions add up across hundreds of pods, creating massive, system-wide cloud waste.
Hidden spending in shared infrastructure
When multiple teams share a cluster, the bill often arrives as a single, monolithic line item. Without granular cost allocation, no single team feels the direct financial impact of their workloads.
Autoscaling masks latent inefficiencies
The Horizontal Pod Autoscaler (HPA) is valuable, but without optimization, it can mask deeper issues like inefficient code or inflated resource requests. If an application is poorly coded or configured, the HPA will scale it out to meet demand, burning through cash to support a fundamentally inefficient process.
Ephemeral control-plane overhead
The hidden cost of Kubernetes is the control plane itself. Controllers and operators are designed to run constantly, reconciling states and consuming resources. While each one is small, the collective overhead creates a perpetual cost leak. Without careful management, ephemeral controllers and other control-plane processes become a constant drain on resources.
Bin-packing fragmentation
Bin packing can be like a losing game of Tetris: Long-lived pods create awkward, unused gaps on your nodes. New pods can't fit into these fragments, so the cluster autoscaler spins up a fresh, expensive node, even though you have enough total capacity. Fixing this fragmentation requires active rebalancing with tools like the Kubernetes Descheduler.
Key principles for Kubernetes cost optimization
Tackling the challenges we’ve discussed starts with a shift in mindset. Here are the cloud spend management principles to keep in mind:
Right-size and clean up: Use real usage metrics from tools like Prometheus to set accurate resource requests/limits. Aggressively hunt down and delete "zombie" deployments, abandoned workloads, and unused namespaces.
Use multi-metric autoscaling: Go beyond CPU. Combine the Horizontal Pod Autoscaler (HPA) with the Vertical Pod Autoscaler (VPA) to react to CPU, memory, custom metrics, and energy profiles for more intelligent scaling.
Implement workload-based cost visibility: Break down costs by namespace, team, or service. When you can attribute spending directly, you create accountability.
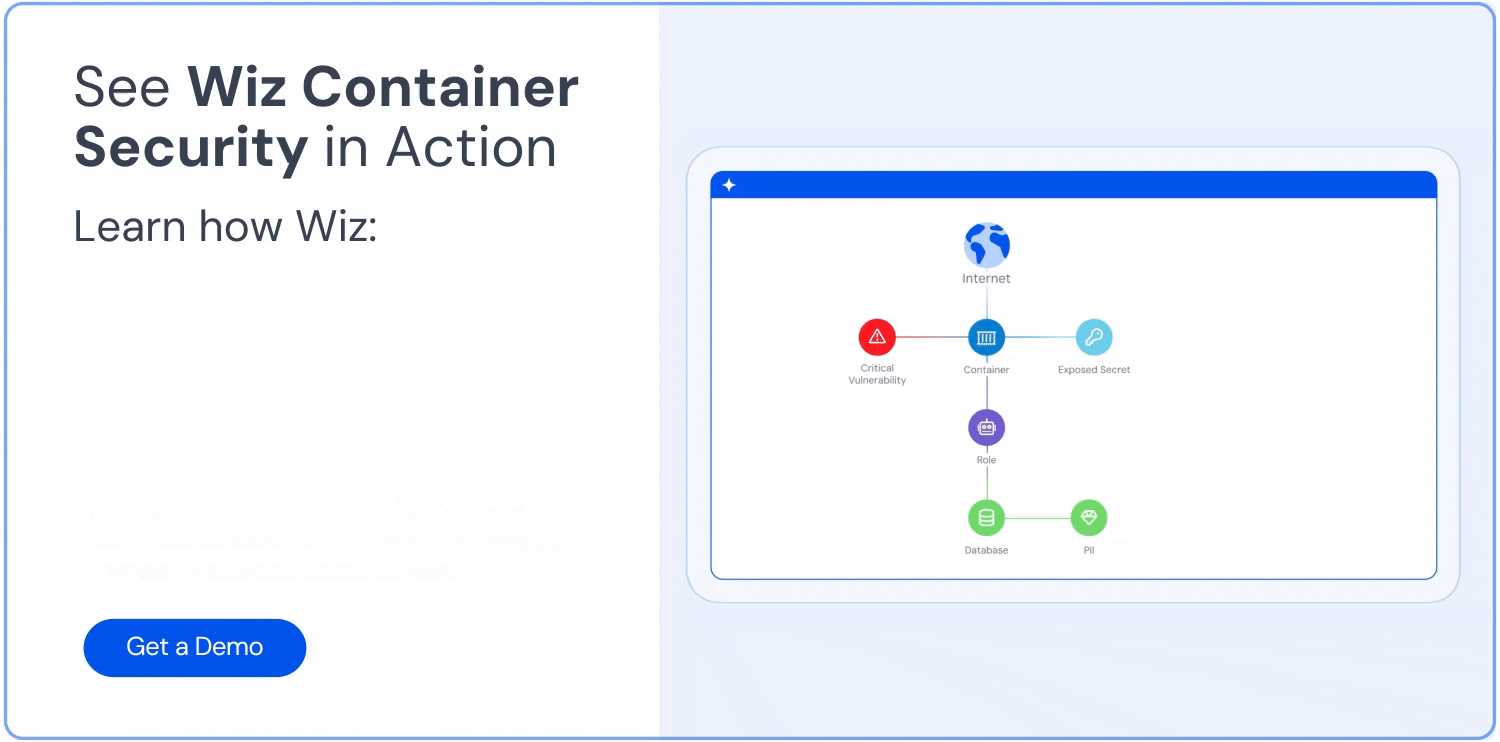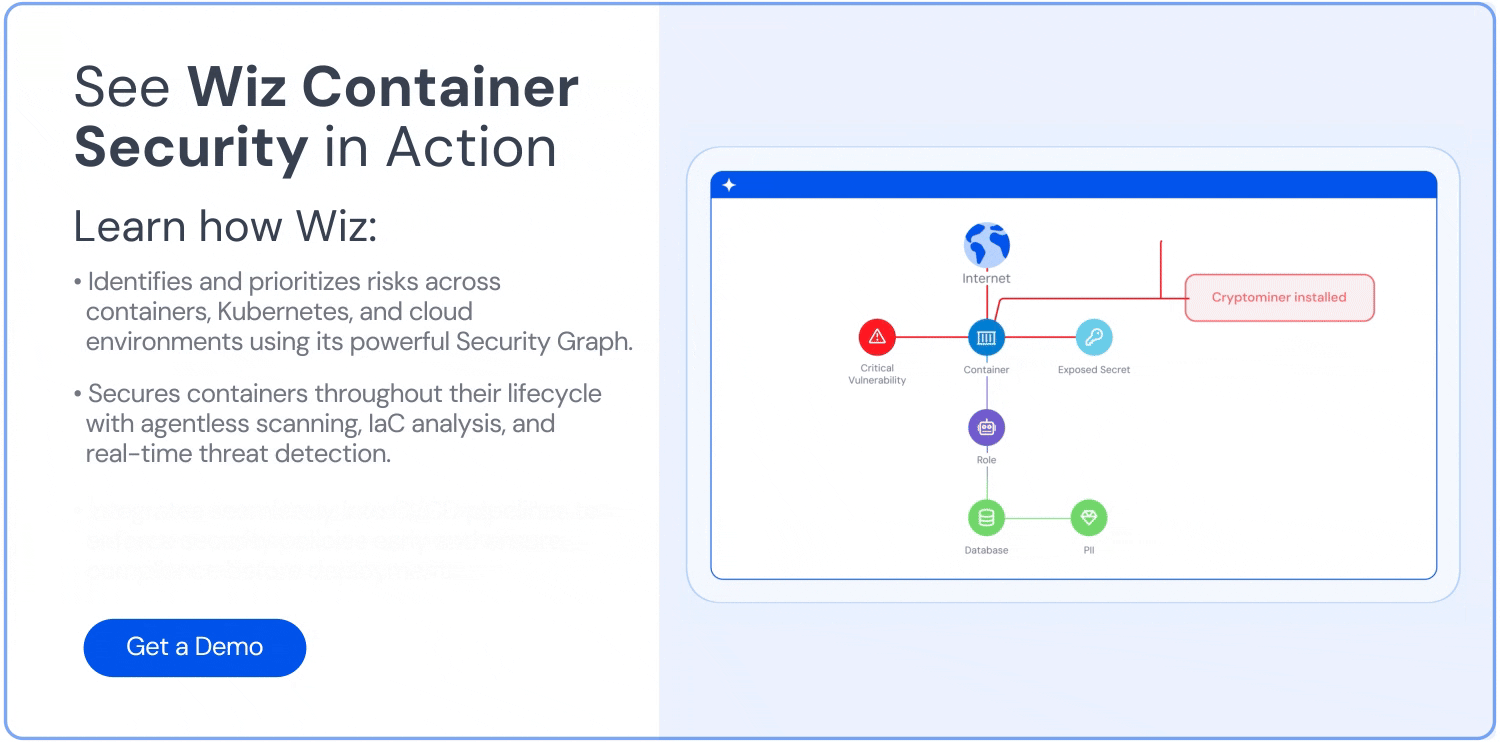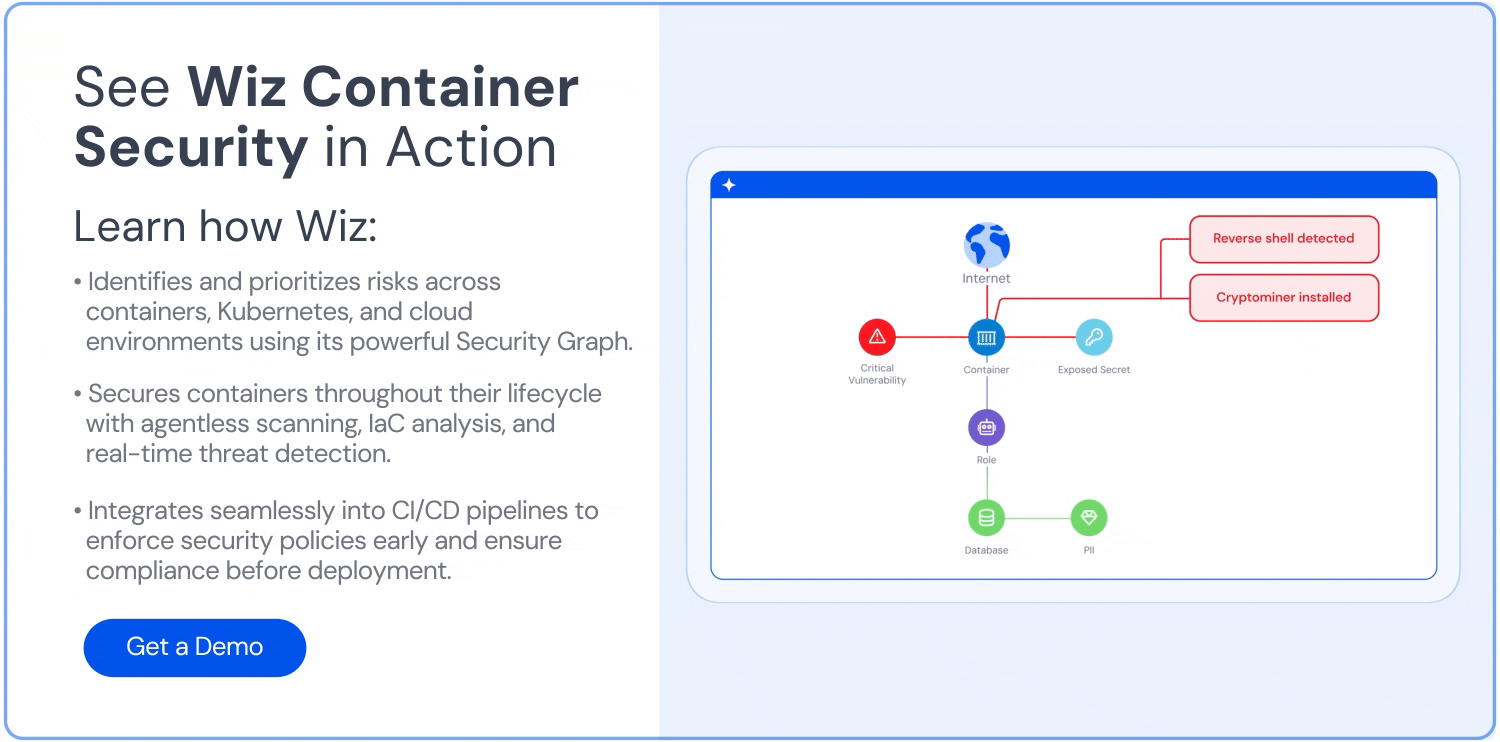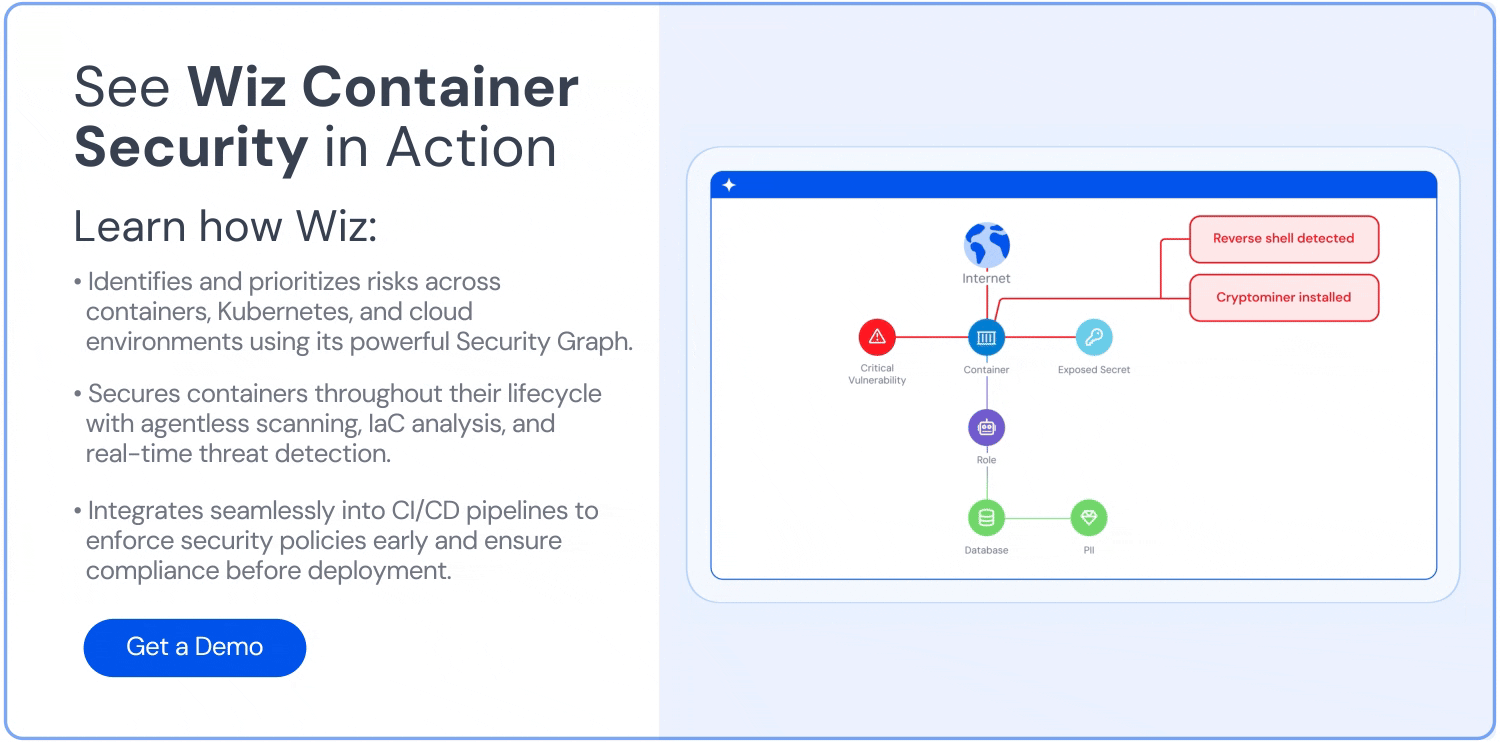
Align cost with security context: Don't optimize in a vacuum. Use a graph-based platform like Wiz to correlate cost hotspots with blast radius, public exposure, and code-level vulnerabilities—so you don’t accidentally cut something mission-critical.
Embrace advanced techniques: Explore emerging solutions, like on-demand controllers that run in WebAssembly (to minimize memory footprints), and use pod deschedulers to regularly rebalance workloads and reduce node fragmentation for real cloud cost savings.
Kubernetes Security Report 2025
The Wiz Kubernetes Security Report 2025 reveals that attackers start probing new clusters in as little as 18 minutes.The Wiz Kubernetes Security Report 2025 reveals that attackers start probing new clusters in as little as 18 minutes.

Cluster-level optimization strategies
Putting the principles we’ve discussed into practice starts with clusters.
Optimizing at the cluster level is about getting your foundations right. If your nodes and cluster configurations are inefficient, you'll be fighting an uphill battle, no matter how much you fine-tune your workloads.
Efficient node types
Stop treating all nodes as generic resources. A one-size-fits-all approach is a recipe for waste. Instead, think about using a mix of heterogeneous node types: Some workloads are CPU-intensive, others are memory-heavy. Advanced teams are even exploring convex-optimization models to dynamically select the most cost-effective node type based on the pending pod queue.
For any workloads that can handle interruptions, you absolutely should be using spot or preemptible instances—the cost savings are too significant to ignore. But here’s a crucial point: You need to ensure your autoscaler is intelligent enough to account for potential delays in acquiring spot capacity and can gracefully handle node teardowns.
Control cluster sprawl
Cluster sprawl is a silent budget killer. That dev cluster someone spun up for a two-day project and forgot about has now been running for six months. That’s why it’s essential to decommission development and testing clusters on a routine schedule (for instance, by using automation to tear them down every Friday and bring them back up Monday morning).
Another important tip? Use deschedulers strategically during off-hours. Before your morning traffic spike triggers a scale-up event, run a rebalancing job overnight. This packs existing pods tightly, freeing up as much space as possible and potentially preventing the need for new nodes when the day begins.


Kubernetes cost optimization in cloud-hosted environments
Here's a high-level look at the key optimization levers for each major cloud provider:
| Cloud provider | Key optimization strategies |
|---|---|
| Amazon EKS |
|
| Azure AKS |
|
| Google GKE |
|
Kubernetes cost optimization techniques
Once your cluster is in good shape, shift the spotlight to your workloads. Tiny, targeted tweaks here can snowball into serious savings.
Tune resource requests and limits
Start by pulling real usage numbers from Prometheus, the Metrics Server, or whatever observability stack you run. That baseline shows how far your current requests miss the mark—and where to trim the fat.
Prefer letting automation handle the math? Hand the job to the Vertical Pod Autoscaler (VPA) or experiment with the still‑developing Multidimensional Pod Autoscaler (MPA). VPA learns from past behavior to resize CPU and memory on the fly, while MPA scales against several resources at once.
Manage idle or over-provisioned workloads
Idle pods lurk in every cluster. Define “idle” (for example, anything using under 20% of its requested CPU or memory) and track them down. Pair the Kubernetes descheduler with rules that evict or reshuffle low-utilization workloads, allowing you to reclaim that capacity.
Optimize job scheduling
Batch ETL jobs, data crunching, even CI pipelines rarely need to run the instant they’re queued. Push them to quiet hours—overnight or weekend windows—when your cluster has room to breathe. Better yet, steer them onto spot‑backed nodes via affinity or taints to shave the bill.
For the most advanced use cases, consider energy-aware scheduling. Some experimental schedulers use multi-objective models like TOPSIS to balance energy efficiency and cost, which is particularly relevant for AI and IoT workloads, where energy usage can be a significant OpEx component.
Visibility and cost allocation in Kubernetes
A basic cloud invoice isn't enough. It only shows how much you spent on services like EC2 or Compute Engine, but it doesn't explain which namespace or microservice caused those costs.
Real insight comes from knitting together live cluster metrics, autoscaler events, and—at scale—even energy telemetry, then piping everything into a dashboard that ties each dollar to the Kubernetes resource that burned it.
A growing tool stack tackles the job. Predictive autoscalers built on ML libraries like Prophet smooth out scaling curves by forecasting demand instead of chasing it; when wired into KEDA, they can act on those forecasts—some even run convex optimization to pick the cheapest node pool that still hits performance targets.
Still, numbers alone aren’t enough. You need to know who owns the spend and whether that pricey service is also a security risk. Platforms like Wiz merge cost, ownership, and risk into a graph you can query—e.g., “Show me the priciest 20% of pods that are publicly exposed and packed with critical CVEs.” That turns cost trimming into a smart, risk‑aware strategy. For day-to-day monitoring, tools such as Kubecost, Cast AI, and OpenCost break expenses down by namespace or service, so teams see—and feel—their impact.
Policy and automation best practices
The most effective way to control costs is to prevent waste from happening in the first place. This is where policy and automation become your best friends:
Admission webhooks: Use gatekeepers like OPA or Kyverno to enforce policies at the time of deployment and connect them to platforms like Wiz that enforce security and compliance gates alongside cost policies in real time. You can set resource caps, restrict which instance types can be used, or require specific labels for cost allocation. This is your first line of defense.
Automated cleanup: Don't rely on humans to remember to delete things. Use cron jobs or webhook triggers to automatically detect and clean up idle resources, empty namespaces, or old deployments.
Notifications: Integrate cost alerts directly into your team's workflow. Automatically send a message to a Slack channel or create a Jira ticket when a service's cost spikes by more than 20% week-over-week. Make the cost visible and accountable.
Shift-left cost checks: Embed cost analysis directly into your CI/CD pipelines. A tool leveraging Open Policy Agent (OPA) or Kyverno can analyze a new deployment's manifest and warn the developer if their resource requests are significantly out of line with those of the previous version.
Why context matters for Kubernetes cost optimization
The bottom line? Cost data in isolation is a liability. Looking at a billing spreadsheet without context encourages bad decisions, like shutting down a service that looks "expensive" but is business-critical. To achieve meaningful and safe cloud cost optimization, you need more.
You need visibility into which workloads are driving costs and who is responsible for them. You need to understand their security posture—is a high-cost service also your most exposed? And you need real-time scanning to catch new inefficiencies as your environment changes by the minute.
This is the philosophy behind Wiz’s Security Graph: bringing together cost, risk, ownership, and exposure in one context-aware view. With Wiz Cloud Cost, that graph also becomes a practical FinOps workspace for Kubernetes, connecting each resource to its associated costs, vulnerabilities, network exposure, and owner. That lets you move from simply asking, "What is expensive?" to "What is expensive, risky, inefficient, and safe to optimize right now?"
Wiz Cloud Cost adds the operational detail teams usually have to stitch together by hand: Cost Explorer with a dedicated Kubernetes view for cluster spend, top controllers, and allocated cost over time, plus 140+ optimization rules and Cost Monitors to catch waste and anomalous spend early. That same context is especially useful for GPU-backed AI and inference workloads running on Kubernetes, where cost, utilization, performance, and exposure need to be evaluated together before you tune or scale anything down.
Unlock intelligent and cloud-native Kubernetes cost control with Wiz Cloud Cost and the Wiz Security Graph, so engineering, FinOps, and security teams can cut waste with full operational context. Request a demo of Wiz today to see how you can gain context-aware control over Kubernetes and cloud spend!